6. Tipos de datos de Scalaz
¿Quién no ama una buena estructura de datos? La respuesta es nadie, porque las estructuras de datos son increíbles.
En este capítulo exploraremos los tipos de datos en Scalaz que son similares a colecciones, así como los tipos de datos que aumentan Scala, como lenguaje, con semántica y seguridad de tipos adicional.
La razón principal por la que nos preocupamos por tener muchas colecciones a nuestra disposición es por rendimiento. Un vector y una lista pueden hacer lo mismo, pero sus características son diferentes: un vector tiene un costo de búsqueda constante mientras que una lista debe ser recorrida.
Todas las colecciones presentadas aquí son persistentes: si agregamos o removemos un elemento todavía podemos usar la versión anterior. Compartir estructuralmente es esencial para el rendimiento de las estructuras de datos persistentes, de otra manera la colección entera se reconstruye con cada operación.
A diferencia de las colecciones de Java y Scala, no hay jerarquía de datos en Scalaz: estas colecciones son mucho más simples de entender. La funcionalidad polimórfica se proporciona por instancias opmitizadas de typeclases que estudiamos en el capítulo anterior. Esto simplifica cambiar implementaciones por razones de rendimiento, y proporcionar la propia.
6.1 Variancia de tipo
Muchos de los tipos de datos de Scalaz son invariantes en sus parámetros de tipo.
Por ejemplo, IList[A] no es un subtipo de IList[B] cuando A <: B.
6.1.1 Covariancia
El problema con los tipos de parámetro covariantes, tales como class List[+A], es
que List[A] es un subtipo de List[Any] y es fácil perder accidentalmente información
de tipo.
Note que la segunda lista es una List[Char] y que el compilador ha inferido
incorrectamente el LUB (Least Upper Bound, o límite mínimo inferior) es Any.
Compare con IList, que requiere una aplicación explícita de .widen[Any] para
ejecutar el crimen atroz:
De manera similar, cuando el compilador infiere el tipo como
with Product with Serializable es un indicador fuerte de que un
ensanchamiento accidental ha ocurrido debido a la covariancia.
Desafortunadamente debemos ser cuidadosos cuando construimos tipos de datos invariantes debido a que los cálculos LUB se realizan sobre los parámetros:
Otro problema similar surge a partir del tipo Nothing, el cuál es un subtipo del resto
de tipos, incluyendo ADTs selladas (sealed), clases finales (final), primitivas y
null.
No hay valores de tipo Nothing: las funciones que toman un Nothing como un parámetro
no pueden ejecutarse y las funciones que devuelven Nothing nunca devuelven un valor
(o terminan). Nothing fue introducido como un mecanismo para habilitar los tipos de
parámetros covariantes, pero una consecuencia es que podemos escribir código que no puede
ejecutarse, por accidente. Scalaz dice que no necesitamos parámetros de tipo covariantes
lo que significa que nos estamos limitando a nosotros mismos a escribir código práctico
que puede ser ejecutado.
6.1.2 Contrarivarianza
Por otro lado, los tipos de parámetro contravariantes, tales como trait Thing[-A]
pueden poner de manifiesto
errores devastadores en el compilador.
Considere la demostración de Paul Phillips’ (ex miembro del equipo del compilador
scalac) de lo que él llama contrarivarianza:
Como era de esperarse, el compilador está encontrando el argumento más específico
en cada invocación de f. Sin embargo, la resolución implícita da resultados
inesperados:
La resolución implícita hace un intercambio de su definición de “más específico” para los tipos contravariantes, logrando que sean inútiles para los typeclases o para cualquier cosa que requiera funcionalidad polimórfica. Este comportamiento es fijo en Dotty.
6.1.3 Las limitaciones del mecanismo de subclases
scala.Option tiene un método .flatten que los dejará convertir Option[Option[B]]
en un Option[B]. Sin embargo, el sistema de tipos de Scala es incapaz de dejarnos
escribir la signatura de tipos requerida. Considere lo siguiente que parece correcto,
pero que tiene un error sutil:
The A introducida en .flatten está ocultando la A introducida por la clase.
Es equivalente a escribir
que no es la restricción deseada.
Para resolver esta limitación, Scala define clases infijas <:< y =:= junto
con la evidencia implícita que siempre crea un testigo (witness).
=:= puede usarse para requerir que dos parámetros de tipo sean exactamente iguales y
<:< se usa para describir relaciones de subtipo, dejandonos implementar .flatten como
Scalaz mejora sobre <:< y =:= con Liskov (que tiene el alias <~<) y
Leibniz (====).
Además de los métodos generalmente útiles y las conversiones implícitas,
la evidencia de Scalaz <~< y === usa mejores principios que en la librería estándar.
6.2 Evaluación
Java es un lenguaje con evaluación estricta: todos los parámetros para un método
deben evaluarse a un valor antes de llamar el método. Scala introduce la noción de
parámetros por nombre (by-name) en los métodos con la sintaxis a: => A. Estos
parámetros se envuelven en una finción de cero argumentos que se invoca cada vez que
se referencia la a. Hemos visto por nombre muchas veces en las typeclases.
Scala también tiene por necesidad (by-need), con la palabra lazy: el cómputo se
evalúa a lo sumo una vez para producir el valor. Desgraciadamente, Scala no soporta
la evaluación por necesidad de los parámetros del método.
Scalaz formaliza los tres estrategias de evaluación con un ADT
La forma de evaluación más débil es Name, que no proporciona garantías
computacionales. A continuación está Need, que garantiza la evaluación
como máximo una vez.
Si deseamos ser super escrupulosos podríamos revisar todas las typeclases y hacer
sus métodos tomar parámetros por Name, Need o Value. En vez de esto, podemos
asumir que los parámetros normales siempre pueden envolverse en un Value, y que
los parámetros (by-name) por nombre pueden envolverse con Name.
Cuando escribimos programas puros, somos libres de reemplazar cualquier Name con
Need o Value, y viceversa, sin necesidad de cambiar lo correcto del programa.
Esta es la esencia de la transparencia referencial: la habilidad de cambiar un
cómputo por su valor, o un valor por su respectivo cómputo.
En la programación funcional casi siempre deseamos Value o Need (también conocido
como estricto y perezoso): hay poco valor en Name. Debido a que no hay soporte
a nivel de lenguaje para parámetros de método perezosos, los métodos típicamente
solicitan un parámetro por nombre y entonces lo convierten a Need de manera
interna, proporcionando un aumento en el rendimiento.
Name proporciona instancias de las siguientes typeclases
MonadComonadTraverse1Align-
Zip/Unzip/Cozip
6.3 Memoisation
Scalaz tiene la capacidad de memoizar funciones, formalizada por Memo, que no
hace ninguna garantía sobre la evaluación debido a la diversidad de implementaciones:
memo nos permite crear implementaciones de Memo, nilMemo no memoiza,
evaluando la función normalmente. Las implementaciones resultantes interceptan
llamadas a la función y guardan en cache los resultados obtenidos en
una implementación que usa colecciones de la librería estándar.
Para usar Memo simplemente envolvemos una función con una implementación de
Memo y entonces invocamos a la función memoizada:
Si la función toma más de un parámetro, entonces debemos invocar .tupled
sobre el método, con la versión memoisada tomando una tupla.
Memo típicamente se trata como un artificio especial y la regla usual sobre
la pureza se relaja para las implementaciones. La pureza únicamente requiere
que nuestras implementaciones de Memo sean referencialmente transparentes en
la evaluación de K => V. Podríamos usar datos mutables y realizar I/O en la
implementación de Memo, por ejemplo usando un LRU o un caché distribuido, sin
tener que declarar un efecto en las signaturas de tipo. Otros lenguajes de
programación funcional tienen memoización manejada por el ambiente de runtime y
Memo es nuestra manera de extender la JVM para tener un soporte similar, aunque
desgraciadamente únicamente de una manera que requiere opt-in.
6.4 Tagging (etiquetar)
En la sección que se introdujo Monoid construimos un Monoid[TradeTeamplate] y
nos dimos cuenta de que Scalaz no hace lo que desearíamos con Monoid[Option[A]].
Este no es una omisión de Scalaz, con frecuencia podemos notar que un tipo de datos
puede implementar una tipeclass fundamental en múltiples formas válidas y que la
implementación por default no hace lo que deseariamos, o simplemente no está
definida.
Los ejemplos básicos son Monoid[Boolean] (la conjunción && vs la disjunción ||)
y Monoid[Int] (multiplicación vs adición).
Para implementar Monoid[TradeTemplate] tuvimos que romper la coherencia de typeclases, o usar una typeclass distinta.
scalaz.Tag está diseñada para lidiar con el problema de coherencia que surge con múltiples implementaciones de typeclases, sin romper la coherencia de las
typeclases.
La definición es algo compleja, pero la sintáxis al usar scalaz.Tag es bastante
limpia. Así es como logramos convencer al compilador para que nos permita definir
el tipo infijo A @@ T que es borrado en A en tiempo de ejecución:
Algunas etiquetas/tags útiles se proporcionan en el objeto Tags
First/Last se usan para seleccionar instancias d Monoid que escogen el primero
o el último (diferente de cero) operando. Multiplication es para multiplicación
numérica en vez de adición. Disjunction/Conjuntion son para seleccionar && o
||, respectivamente.
En nuestro TradeTemplate, en lugar de usar Option[Currency] podríamos usar
Option[Currency] @@ Tags.Last. En verdad, este uso es tan común que podemos usar
el alias previamente definido, LastOption.
y esto nos permite escribir una implementación mucho más limpia de
Monoid[TradeTemplate]
Para crear un valor de tipo LastOption, aplicamos Tag a un Option. Aquí
estamos invocando Tag(None).
En el capítulo sobre derivación de typeclases, iremos un paso más allá y derivaremos
automáticamente el monoid.
Es tentador usar Tag para marcar tipos de datos para alguna forma de validación
(por ejemplo, String @@ PersonName), pero deberíamos evitar esto porque no existe
un chequeo del contenido en tiempo de ejecución. Tag únicamente debería ser usado
para propósitos de selección de typeclases. Prefiera el uso de la librería Refined,
que se introdujo en el Capítulo 4, para restringir valores.
6.5 Transformaciones naturales
Una función de un tipo a otro se escribe en Scala como A => B, y se trata de una
conveniencia sintáctica para Function1[A, B]. Scalaz proporciona una conveniencia
sintáctica F ~> G para funciones sobre los constructores de tipo F[_] a G[_].
Esta notación, F ~ G, se conoce como transformación natural y son universalmente
cuantificables debido a que no nos importa el contenido de F[_].
Un ejemplo de una transformación natural es la función que convierte una IList
en una List.
O, de manera más concisa, usando las conveniencias sintácticas proporcionadas por
el plugin kind-projector:
Sin embargo, en el desarrollo del día a día, es mucho más probable que usemos una
transformación natural para mapear entre álgebras. Por ejemplo, en
drone-dynamic-agents tal vez deseemos implementar nuestra álgebra de Machines
que usa Google Container Engine con una álgebra ad-hoc, BigMachines. En lugar de
cambiar toda nuestra lógica de negocio y probar usando esta nueva interfaz
BigMachines, podríamos escribir una transformación natural de
Machines ~> BigMachines. Volveremos a esta idea en el capítulo de Mónadas Avanzadas.
6.6 Isomorphism (isomorfismos)
Algunas veces tenemos dos tipos que en realidad son equivalentes (la misma cosa), lo que ocasiona problemas de compatibiliad debido a que el compilador no sabe lo que nosotros sí sabemos. Esto pasa típicamente cuando usamos código de terceros que tiene algo que ya tenemos.
Ahí es cuando Isomorphism nos puede ayudar. Un isomorfismo define una relación
formal “es equivalente a” entre dos tipos. Existen tres variantes, para
Los aliases de tipos IsoSet, IsoFunctor e IsoBifunctor cubren los casos
comunes: una función regular, una transformación natural y binatural. Las funciones
de conveniencia nos permiten generar instancias de funciones existentes o
transformaciones naturales. Sin embargo, con frecuencia es más fácil usar una de
las clases abstractas Template para definir un isomorfismo. Por ejemplo:
Si introducimos un isomorfismo, con frecuencia podemos generar muchas de las typeclases estándar. Por ejemplo,
lo que nos permite derivar un Semigroup[F] para un tipo F si ya tenemos un
isomorfismo F <=> G y un semigrupo Semigroup[G]. Casi todas las typeclases
en la jerarquía proporcionan una invariante isomórfica. Si nos encontramos en la
situación en la que copiamos y pegamos una implementación de una typeclass,
es útil considerar si Isomorphism es una mejor solución.
6.7 Contenedores
6.7.1 Maybe
Ya nos hemos encontrado con la mejora de Scalaz sobre scala.Option, que se llama
Maybe. Es una mejora porque es invariante y no tiene ningún método inseguro como
Option.get, el cual puede lanzar una excepción.
Con frecuencia se usa para representar una cosa que puede o no estar presente sin proporcionar ninguna información adicional de porqué falta información.
Los métodos .empty y .just en el objeto compañero son preferidas en lugar de
usar Empty o Just debido a que regresan Maybe, ayudándonos con la inferencia
de tipos. Este patrón con frecuencia es preferido a regresar un tipo suma, que
es cuando tenemos múltiples implementaciones de un sealed trait pero nunca usamos
us subtipo específico en una signatura de método.
UNa clase implícita conveniente nos permite invocar.just sobre cualquier valor y
recibir un Maybe.
Maybe tiene una instancia de typeclass para todas las cosas
AlignTraverse-
MonadPlus/IsEmpty Cobind-
Cozip/Zip/Unzip Optional
e instancias delegadas que dependen de A
-
Monoid/Band -
Equal/Order/Show
Además de las instancias arriba mencionadas, Maybe tiene funcionalidad que no es
soportada por una typeclass polimórfica.
.cata proporciona una alternativa más simple para .map(f).gerOrElse(b) y tiene
la forma más simple | si el mapeo es identity (es decir, simplemente
.getOrElse).
.toLeft y .toRight, y sus aliases simbólicos, crean una disjunción (explicada
en la sección siguiente) al tomar un valor por default para el caso Empty.
.orZero toma un Monoid para definir el valor por default.
.orEmpty usa un ApplicativePlus para crear un elemento único o un contenedor
vacío, sin olvidar que ya tenemos soporte para las colecciones de la librería
estándar con el método .to que viene de la instancia Foldable.
6.7.2 Either
La mejora de Scalaz sobre scalaz.Either es simbólica, pero es común hablar de este
caso como either o una Disjunction.
con la sintaxis correspondiente
y permite una construcción sencilla de los valores. Note que los métodos de extensión
toman el tipo del otro lado. De modo que si deseamos crear un valor de tipo
String \/ Int y tenemos un Int, debemos pasar String cuando llamamos .right.
La naturaleza simbólica de \/ hace que sea de fácil lectura cuando se muestra con
notación infija. Note que los tipos simbólicos en Scala se asocian desde el lado
izquierdo y que \/ deben tener paréntesis, por ejemplo
(A \/ (B \/ (C \/ D)).
\/tiene instancias sesgadas a la derecha (es decir,flatMapaplica a\/-) para:
-
Monad/MonadError -
Traverse/Bitraverse PlusOptionalCozip
y dependiendo del contenido
-
Equal/Order -
Semigroup/Monoid/Band
Además, hay métodos especiales
.fold es similar a Maybe.cata y requiere que tanto el lado derecho como el
lado izquierdo se mapeen al mismo tipo.
.swap intercambia los lados izquierdo y derecho.
El alias | para getOrElse parece similar a Maybe.
The | alias to getOrElse appears similarly to Maybe. We also get
||| as an alias to orElse.
+++ es para combinar disjunciones con los lados izquierdos tomando precedencia
sobre los lados derechos:
-
right(v1) +++ right(v2)daright(v1 |+| v2) -
right(v1) +++ left (v2)daleft (v2) -
left (v1) +++ right(v2)daleft (v1) -
left (v1) +++ left (v2)daleft (v1 |+| v2)
.toEither está para proporcionar compatibilidad hacia atrás con la librería
estándar de Scala.
La combinación de :?>> y <<? son una sintáxis conveniente para ignorar el
contenido de una \/, pero escoger un valor por default basándose en su tipo.
6.7.3 Validation
A primera vista, Validation (con alias simbólico \?/, Elvis feliz) aparece
ser un clon de Disjunction:
Con sintáxis conveniente
Sin embargo, la estructura de datos no es la historia completa. En Scalaz,
Validation no tiene una instancia de ninguna Monad, y esto es intencional,
restringiéndose a versiones sesgadas a la derecha de:
Applicative-
Traverse/Bitraverse CozipPlusOptional
y dependiendo del contenido
-
Equal/Order Show-
Semigroup/Monoid
La gran ventaja de restringirnos a Applicative es que Validation es
explícitamente para situaciones donde deseamos reportar todas las fallas,
mientras que Disjunction se usa para detenernos en el primer fallo. Para
The big advantage of restricting to Applicative is that Validation
is explicitly for situations where we wish to report all failures,
whereas Disjunction is used to stop at the first failure. To
accommodate failure accumulation, a popular form of Validation is
ValidationNel, having a NonEmptyList[E] in the failure position.
Consider performing input validation of data provided by a user using
Disjunction and flatMap:
Si usamos la sintáxis |@|
Todavía obetenemos el primer error. Esto es porque Disjuntion es una
Monad, y sus métodos .applyX deben ser consistentes con .flatMap y
no asumir que ninguna operación pueden realizarse fuera de orden.
Compare con:
Esta vez, tenemos todas las fallas!
Validation tiene muchos de los métodos en Disjunction, tales como .fold,
.swap y +++, además de algunas extra:
.append (con el alias simbólico +|+) tiene la misma signatura de tipo que
+++ pero da preferencia al caso de éxito
-
failure(v1) +|+ failure(v2)dafailure(v1 |+| v2) -
failure(v1) +|+ success(v2)dasuccess(v2) -
success(v1) +|+ failure(v2)dasuccess(v1) -
success(v1) +|+ success(v2)dasuccess(v1 |+| v2)
.disjunction convierte un valor Validated[A, B] en un A \/ B. Disjunction
tiene los métodos .validation y .validationNel para convertir en una
Validation, permitiendo la fácil conversión entre acumulación sequencial y
paralela de errores.
\/ y Validation son las versiones de PF con mayor rendimiento, equivalentes a
una excepción de validación de entrada, evitando tanto un stacktrace y requiriendo
que el que realiza la invocación lidie con las fallas resultando en sistemas más
robustos.
6.7.4 These
Encontramos These, un codificación en forma de datos de un OR lógicamente
inclusivo, cuando aprendimos sobre Align
y con una sintáxis para una construcción conveniente
These tiene instancias de una typeclass para
MonadBitraverseTraverseCobind
y dependiendo del contenido
-
Semigroup/Monoid/Band -
Equal/Order Show
These (\&/) tiene muchos de los métodos que que esperamos de ``Disjunction
(\/) y Validation (?/`)
.append tiene 9 posibles arreglos y los datos nunca se tiran porque los casos de
This y That siempre pueden convertirse en Both.
.flatMap está sesgado hacia la derecha (Both y That), tomando un Semigroup
del contenido de la izquierda (This) para combinar en lugar de fallar temprano.
&&& es una manera conveniente de hacer un binding sobre dos valores de tipo
These, creando una tupla a la derecha y perdiendo datos si no está presente en
cada uno de estos (these).
Aunque es tentador usar \&/ en los tipos de retorno, el uso excesivo es un
antipatrón. La razón principal para usar \&/ es para combinar o dividir streams
de datos potencialmente infinitos en memoria finita. En el objeto compañero existen
funciones convenientes para lidiar con EphemeralStream (con un alias para que quepan en una sola línea) o cualquier cosa con un MonadPlus.
6.7.5 Higher Kinded Either
El tipo de datos Coproduct (no confunda con el concepto más general de un coproducto en un ADT) envuelve una Disjunction para los constructores de tipo:
Las instancias de un typeclass simplemente delegan a aquellos de F[_] y G[_].
El caso de uso más popular para un Coproduct es cuando deseamos crear un
coproducto anónimo de múltiples ADTs.
6.7.6 No tan estricta
Las tuplas de Scala integradas, y los tipos de datos básicos como Maybe y la
Disjunction son tipos de valores evaluados de manera estricta.
Por conveniencia, las alternativas por nombre para Name se proporcionan,
teniendo las instancias de typeclass esperadas:
El lector astuto notará que Lazy no está bien nombrado, y estos tipos de datos
quizá deberían ser: ByNameTupleX, ByNameOption y ByNameEither.
6.7.7 Const
Const, para constante, es un envoltorio para un valor de tipo A, junto con
un parámetro de tipo B.
Const proporciona una instancia de Applicative[Const[A, ?]] si hay un
Monoid[A] disponible:
La cosa más importante sobre este Applicative es que ignora los parámetros B,
continuando sin fallar y únicamente combinando los valores constantes que encuentra.
Volviendo atrás a nuestra aplicación de ejemplo drone-dynamic-agents, deberíamos
refactorizar nuestro archivo logic.scala para usar Applicative en lugar de Monad. Escribimos logic.scala antes de que supieramos sobre Applicative y
ahora lo sabemos mejor:
Dado que nuestra lógica de negocio únicamente requiere de un Applicative, podemos
escribir implementaciones simuladas con F[a] como Const[String, a]. En tal caso,
devolvemos los nombres de la función que se invoca:
Con nuestra interpretación de nuestro programa, podemos realizar aserciones sobre los métodos que son invocados:
De manera alternativa, podríamos haber contado el total de métodos al usar
Const[Int, ?] o en un IMap[String, Int].
Con esta prueba, hemos ido más allá de realizar pruebas con implementaciones
simuladas con una prueba Const que hace aserciones sobre lo que se invoca sin
tener que proporcionar implementaciones. Esto es útil si nuestra especificación
demanda que hagamos ciertas llamadas para ciertas entradas, por ejemplo, para
propósitos de contabilidad. Además, hemos conseguido esto con seguridad en tiempo
de compilación.
Tomando esta línea de pensamiento un poco más allá, digamos que deseamos monitorear
(en tiempo de producción) los nodos que estamos deteniendo en act. Podemos crear
implementaciones de Drone y Machines con Const, invocándolos desde nuestra
versión envuelta de act
Podemos hacer esto porque monitor es puro y ejecutarlo no produce efectos
laterales.
Esto ejecuta el programa con ConstImpl, extrayendo todas las llamadas a
Machines.stop, entonces devolviéndolos junto con la WorldView. Podemos
hacer pruebas unitarias así:
Hemos usado Const para hacer algo que es como la Programación Orientada a Aspectos (Aspect Oriented Programming), que alguna vez fue popular en Java. Construimos
encima de nuestra lógica de negocios para soportar una preocupación de monitoreo,
sin tener que complicar la lógica de negocios.
Se pone incluso mejor. Podemos ejecutar ConstImpl en producción para reunir lo que
deseamos para detenernos (stop), y entonces proporcionar una implementación
optimizada de act que puede usar llamadas por batches/lotes que puede ser
de implementación específica.
El héroe siliencioso de esta historia es Applicative. Const nos deja ver lo que
es posible. Si necesitamos cambiar nuestro programa para que requiera una Monad,
no podemos seguir usando Const y es necesario escribir mocks completos para poder
hacer aserciones sobre lo que se llama sobre ciertas entradas. La Regla del Poder Mínimo demanda que usemos Applicative en lugar de Monad siempre que podamos.
6.8 Colecciones
A diferencia de la API de colecciones de la librería estándar, Scalaz describe
comportamientos en las colecciones en la jerarquía de typeclases, por ejemplo,
Foldable, Traverse, Monoid. Lo que resta por estudiar son las implementaciones
en términos de estructuras de datos, que tienen características de rendimiento
distintas y métodos muy específicos.
Esta sección estudia detalles de implementación para cada tipo de datos. No es esencial recordar todo lo que se presenta aquí: la meta es ganar entendimiento a un nivel de abstracción alto de cómo funciona cada estructura de datos.
Debido a que los tipos de datos de todas las colecciones nos proporcionan más o menos la misma lista de instancias de typeclases, debemos evitar repetir la lista, que siempre es una variación de la lista:
Monoid-
Traverse/Foldable -
MonadPlus/IsEmpty -
Cobind/Comonad -
Zip/Unzip Align-
Equal/Order Show
Las estructuras de datos que es posible probar que no son vacías pueden proporcionar:
-
Traverse1/Foldable1
y proporcionar Semigroup en lugar de Monoid, Plus en lugar de IsEmpty.
6.8.1 Listas
Ya hemos usado IList[A] y NonEmptyList[A] tantas veces al momento que a estas
alturas deberían ser familiares. Codifican una estructura de datos clásica, la lista ligada:
La ventaja principal de IList sobre List de la librería estándar es que no hay
métodos inseguros, como .head que lanza una excepción sobre listas vacías.
Adicionalmente, IList es mucho más simple, sin tener una jerarquía de clases y
un tamaño del bytecode mucho más pequeño. Además, List de la librería estándar
tiene una implementación terrible que usa var para parchar problemas de
rendimiento en el diseño de las colecciones de la librería estándar:
La creación de una instancia de List requiere de la creación cuidadosa, y lenta,
de sincronización de Threads para asegurar una publicación segura. IList no
requiere de tales hacks y por lo tanto puede superar a List.
6.8.2 EphemeralStream
Stream de la librería estándar es una versión perezosa de List, pero está
plagada con fugas de memoria y métodos inseguros. EphemeralStream no mantiene
referencias a valores calculados, ayudando a mitigar los problemas de retención de
memoria, removiendo los métodos inseguros en el mismo espíritu que IList.
.cons, .unfold e .iterate son mecanismos para la creación de streams, y la
sintaxis conveniente ##:: pone un nuevo elemento en la cabeza de una referencia
por nombre EStream. .unfold es para la creación de un stream finito (pero
posiblemente infinito) al aplicar repetidamente una función f para obtener el
siguiente valor y la entrada para la siguiente f. .iterate crea un stream
infinito al aplicar repetidamente una función f en el elemento previo.
EStream puede aparecer en patrones de emparejamiento con el símbolo ##::,
haciendo un match para la sintaxis para .cons.
Aunque EStream lidia con el problema de retención de valores de memoria, todavía
es posible sufrir de fugas de memoria lentas si una referencia viva apunta a la
cabeza de un stream infinito. Los problemas de esta naturaleza, así como la
necesidad de realizar composición de streams con efectos, es la razón de que fs2
exista.
6.8.3 CorecursiveList
La correcursión es cuando empezamos de un estado base y producimos pasos
subsecuentes de manera determinística, como el método EphemeralStream.unfold
que acabamos de estudiar:
Contraste con una recursion, que pone datos en un estado base y entonces termina.
Una CorecursiveList es una codificación de datos de un EphemeralStream.unfold,
ofreciendo una alternativa a EStream que puede lograr un rendimiento mejor en
algunas circunstancias:
La correcursión es útil cuando estamos implementando Comonad.cojoin, como en
nuestro ejemplo de Hood. CorecursiveList es una buena manera de codificar ecuaciones con recurrencia no lineales como las que se usan en el modelado de
poblaciones de biología, sistemas de control, macro economía, y los modelos de
inversión de bancos.
6.8.4 ImmutableArray
Un simple wrapper alrededor del Array mutable de la librería estándar, con
especializaciones primitivas:
Array no tiene rival en términos de rendimiento al hacer lectura y el tamaño del
heap. Sin embargo, no se está comportiendo memoria estructuralmente cuando se crean
nuevos arreglos, y por lo tanto los arreglos se usan típicamente cuando no se espera
que los contenidos cambien, o como una manera segura de envolver de manera segura
datos crudos de un sistema antiguo/legacy.
6.8.5 Dequeue
Un Dequeue (pronunciado como en “deck of cards”) es una lista ligada que permite
que los elementos se coloquen o se devuelvan del frente (cons) o en la parte
trasera (snoc) en tiempo constante. Remover un elemento de cualquiera de los extremos es una operación de tiempo constante, en promedio.
La forma en la que funciona es que existen dos listas, una para los datos al frente
y otra para los datos en la parte trasera. Considere una instancia para mantener los
símbolos a0, a1, a2, a3, a4, a5, a6
que puede visualizarse como
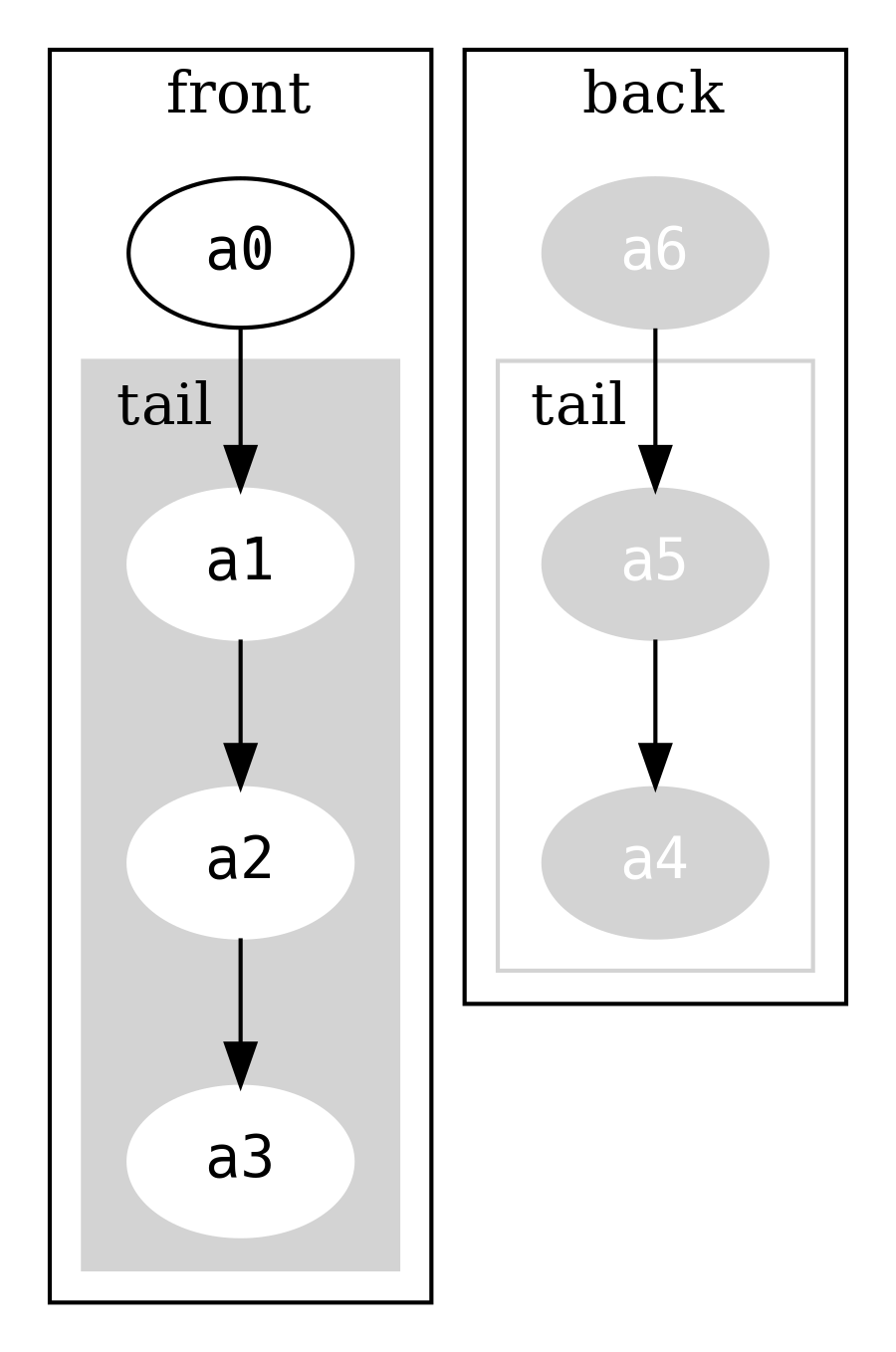
Note que la lista que mantiene back está en orden inverso.
Leer el elemento final, snoc, es una simple lectura en back.head. Añadir un
elemento al final del Dequeue significa añadir un nuevo elemento al frente de
la lista back, y recrear el envoltorio FullDequeue (que incrementará el
tamaño de backSize en uno). Casi toda la estructura original es compartida.
Compare a agregar un nuevo elemento al final de una IList, que envolvería
recrear la estructura completa.
El frontSize y el backSize se usan para rebalancear el front y el back de
modo que casi siempre son del mismo tamaño. Rebalancear significa que algunas
operaciones sean más lentas que otras (por ejemplo, cuando la estructura de datos
debe ser reconstruida) pero debido a que únicamente ocurre ocasionalmente, podríamos
tomar el promedio del costo y decir que es constante.
6.8.6 DList
Las listas ligadas tienen características de rendimiento muy pobres cuando se añaden grandes listas. Considere el trabajo que está envuelto en evaluar lo siguiente:
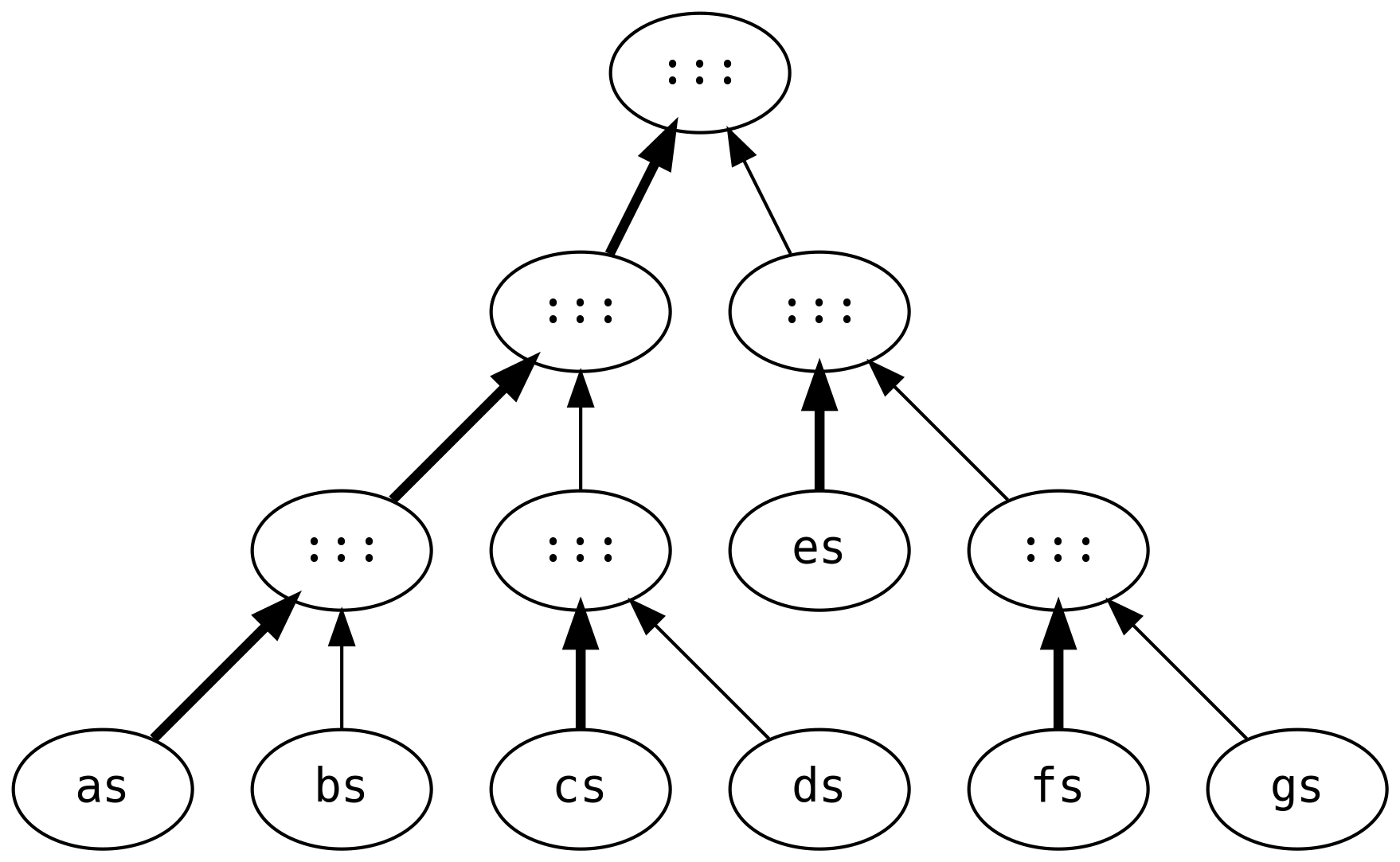
Esto crea seis listas intermedias, recorriendo y reconstruyendo cada lista tres veces
(con la excepción de gs que se comparte durante todas las etapas).
La DList (de lista por diferencias) es la solución más eficiente para este
escenario. En lugar de realizar cálculos en cada etapa, es representada como la
función IList[A] => IList[A]
El cálculo equivalente es (los símbolos son creados a partir de DList.fromIList)
que reparte el trabajo en appends asociativos a la derecha (es decir, rápidos)
utilizando el constructor rápido sobre IList.
Como siempre, no hay nada gratis. Existe un costo extra de asignación (alocación)
dinámica de memoria que puede reducir la velocidad del código que resulta
naturalmente en appends asociativos a la derecha. El incremento de velocidad más
grande ocurre cuando operaciones IList son asociativas hacia la izquierda,
por ejemplo
Las listas de diferencia sufren de un marketing malo. Tal vez si su nombre fuera
ListBuilderFactory estarían en la librería estándar.
6.8.7 ISet
Las estructuras de árboles son excelentes para almacenar datos ordenados, con cada nodo binario manteniendo elementos que son menores en una rama, y mayores en la otra. Sin embargo, implementaciones ingenuas de la estructura de datos árbol pueden desbalancearse dependiendo del orden de inserción. Es posible mantener un árbol perfectamente balanceado, pero es increíblemente ineficiente dado que cada inserción efectivamente reconstruye el árbol completo.
ISet es una implementación de un árbol con balanceo acotado, significando que
está aproximadamente balanceado, usando el tamaño (size) de cada rama para
balancear el nodo.
ISet requiere que A tenga un Order. La instancia Order[A] debe permanecer
igual entre llamadas o las invariantes internas serán inválidas, llevándonos a tener
datos corrompidos: es decir, estamos asumiendo la coherencia de typeclases tales que
Order[A] es única para cualquier A.
La ADT ISet desgraciadamente permite árboles inválidos. Nos esforzamos por escribir
ADTs que describan completamente lo que es y no es válido usando restricciones de
tipo, pero algunas veces tenemos situaciones donde únicamente es posible lograrlo
con el toque inspirado de un inmortal. En lugar de esto, Tip / Bin son private,
para evitar que los usuarios construyan, accidentalmente, árboles inválidos.
.insert es la única manera de construir un ISet, y por lo tanto definir lo que
es un árbol válido.
Los métodos internos .balanceL y .balanceR son espejos uno del otro, de modo que
únicamente estudiamos .balanceL, que también se llama cuando el valor que estamos
insertando es menor que el nodo actual. También se invoca por el método .delete.
El balanceo requiere que clasifiquemos los escenarios que pueden ocurrir.
Estudiaremos cada posible escenario, visualizando (y, left, right) al lado
izquierdo de la página, con la estructura balanceada a la derecha, también conocido
como el árbol rotado.
- círculos llenos visualizan un
Tip - tres columbas visualizan los campos
left | value | rightdeBin - los diamantes visualizan cualquier
ISet
El primer escenario es el caso trivial, que es cuando, tanto el lado left y
el right son Tip. De hecho, nunca encontraremos este escenario a partir de
.insert, pero lo encontramos en .delete.
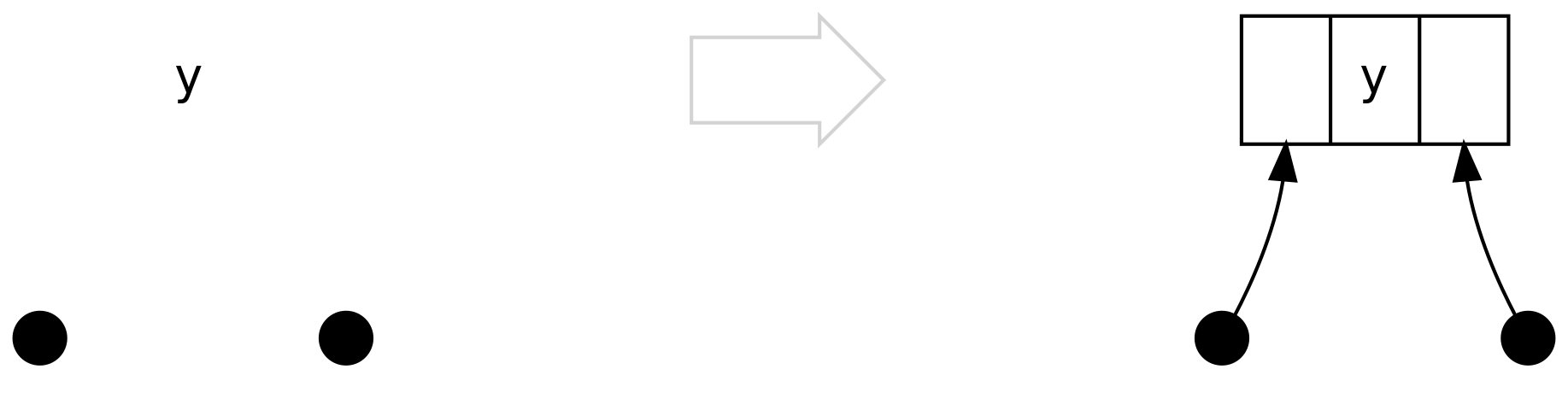
El segundo caso es cuando left es un Bin que contiene únicamente a Tip, y no
necesitamos balancear nada, simplemente creamos la conexión obvia:
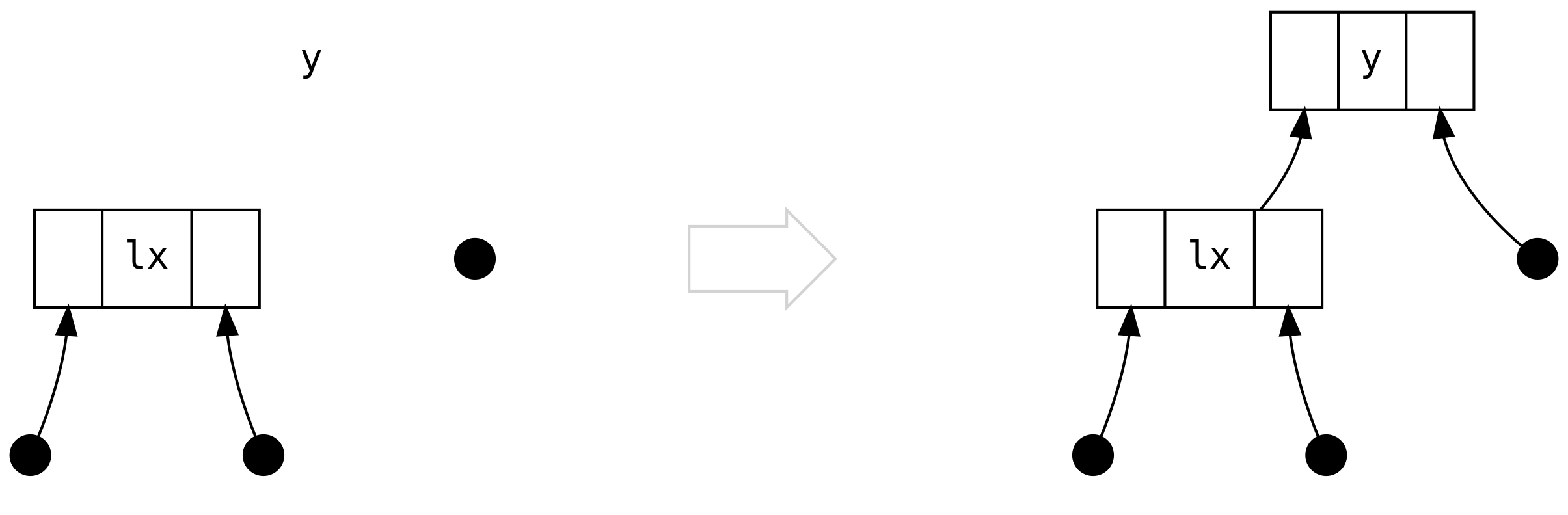
El tercer caso es cuando esto empieza a ponerse interesante: left es un Bin
conteniendo únicamente un Bin a su right.
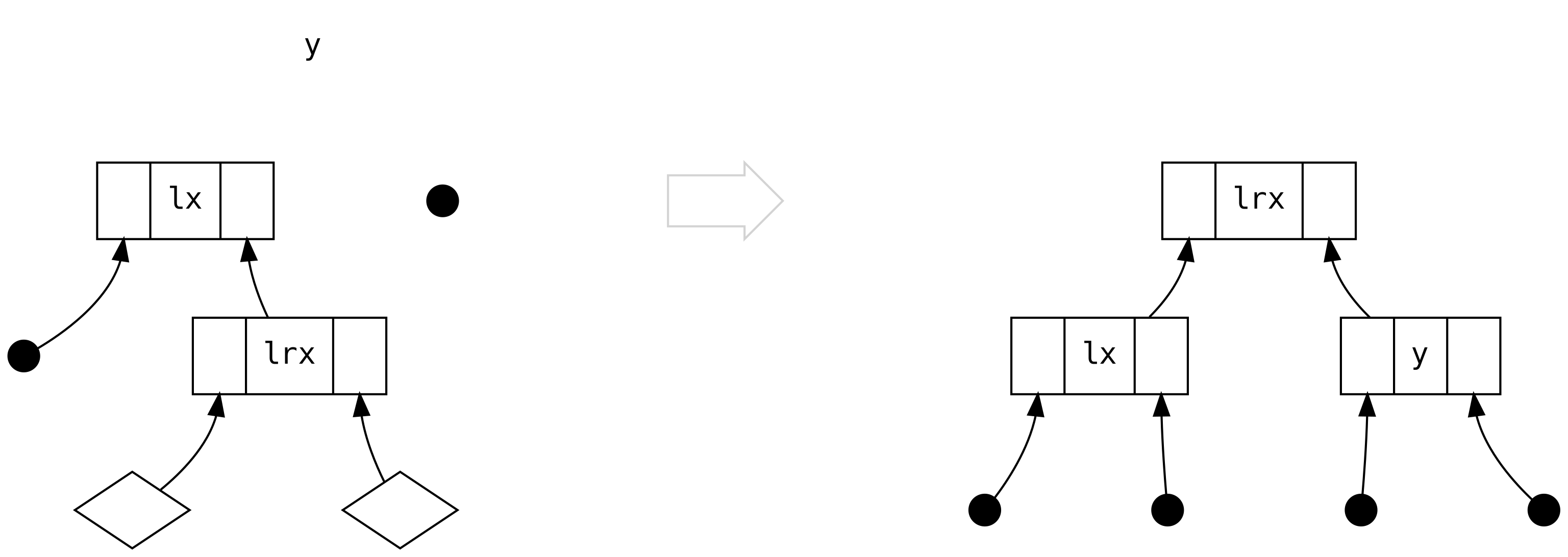
Pero qué ocurrió a los dos diamantes que están debajo de lrx? No acabamos de perder
información? No, no perdimos información, porque podemos razonar (basándonos en el
balanceo del tamaño) que siempre son Tip! No hay regla en cuanto a cualquiera de
los siguientes escenarios (o en .balanceR) que pueden producir un árbol donde los
diamantes son Bin.
El cuarto caso es el opuesto del tercer caso.

El quinto caso es cuando tenemos árboles completos en ambos lados del lado left y
de todos modos debemos usar sus tamañaos relativos para decidir cómo rebalancear.
Para la primera rama, 2*ll.size > lr.size

y para la segunda rama 2*ll.size <= lr.size
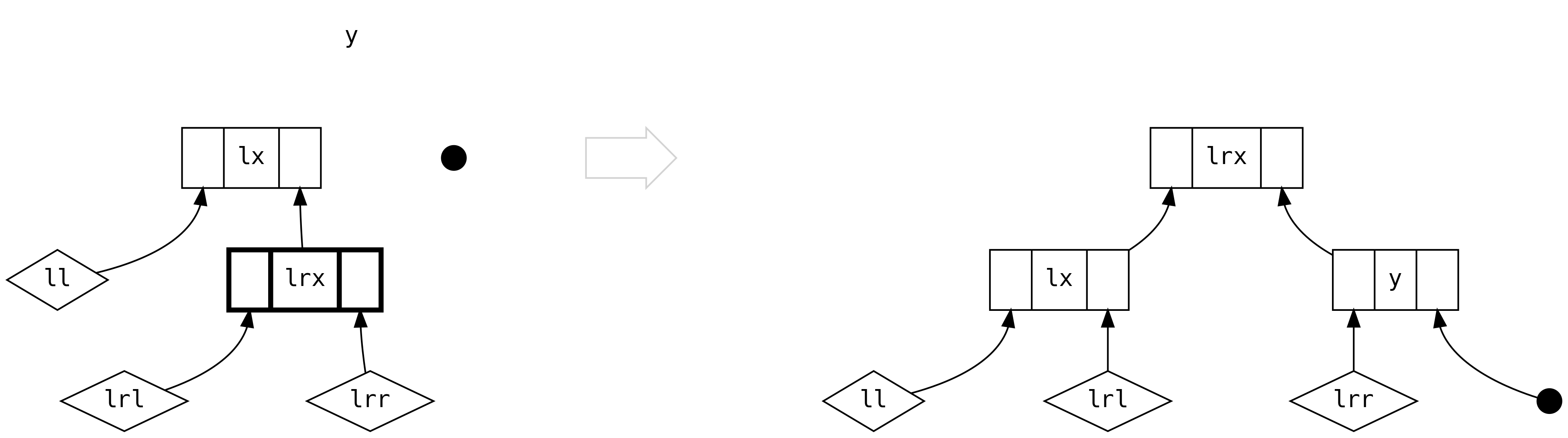
El sexto escenario introduce un árbol en lado (derecho) right. Cuando el lado
left está vacío creamos la conexión obvia. Ese escenario nunca surge a partir de
.insert porque el lado .left siempre está no vacío:

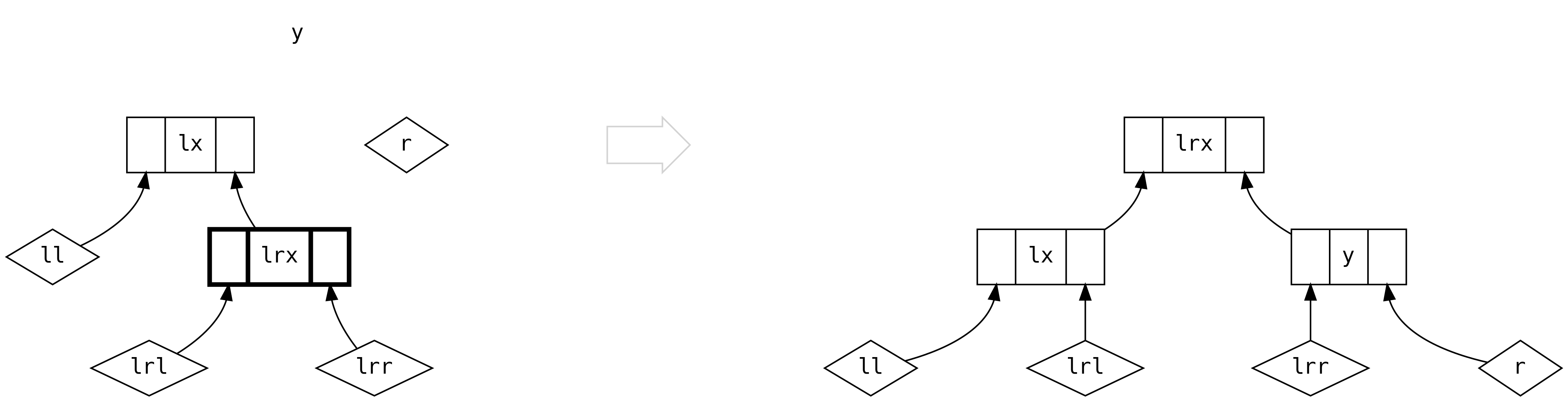
El escenario final ocurre cuando tenemos árboles no vacíos en ambos lados. A menos
que el lado left sea tres veces o más el tamaño del lado right, podemos hacer
lo más sencillo y crear un nuevo Bin.

Sin embargo, si el lado left debiera tener más de tres veces el tamaño del lado
right, debemos balancear basándonos en los tamaños relativos de ll y lr, como
en el escenario cinco.

Esto concluye nuestro estudio del método .insert y cómo se construye un ISet.
No debería ser sorpresivo que Foldable esté implementado en términos de una
búsqueda en lo profundo, junto con left y right, como es apropiado. Métodos
tales como .minimum y .maximum son óptimos porque la estructura de datos
ya codifica el orden.
Es valioso hacer ntar quealgunos métodos de typeclass no pueden ser implementados
de manera tan eficiente como quisieramos. Considere la signatura de
Foldable.element
Una implememntación obiva para .element es (de manera práctica) delegar a la
búsqueda binaria ISet.contains. Sin embargo, no es posible debido a que
.element proporciona Equal mientras que .contains requiere de Order.
ISet es incapaz de proporcionar un Functor por la misma razón. En la práctica
esto es una restricción sensible: realizar un .map significaría reconstruir toda
la estructura de datos completa. Tiene sentido convertir a un tipo de datos distinto,
tales como IList, realizando el .map, y convirtiendo de vuelta. Una consecuencia
es que ya no es posible tener un Traverse[ISet] o Applicative[Set].
6.8.8 IMap
¡Esto es muy familiar! En realidad, IMap (un alias para el operador de la
velocidad de la luz) es otro árbol balanceado en tamaño, pero con un campo extra
value: B en cada rama del árbol binario, permitiendo almacenar pares de
llave/valor. Únicamente el tipo clave A necesita un Order y una clase
conveniente de métodos son proporcionados para permitir una actualización fácil de
entradas.
Tree es una versión by need (por necesidad) de StrictTree con constructores
convenientes
Se espera que el usuario de un Rose Tree lo balancee manualmente, lo que lo hace adecuado para casos donde es útil codificar conocimiento especializado de cierta jerarquía del dominio en la estructura de datos. Por ejemplo, en el campo de la inteligencia artificial, un árbol de Rose puede ser usado en algoritmos de agrupamiento para organizar datos en una jerarquía de cosas cada vez más similares. Es posible representar documentos XML con un árbol Rose.
Cuando trabajamos con datos jerárquicos, considere usar un árbol Rose en lugar de hacer una estructura de datos a la medida.
6.8.9 FingerTree
Los árboles de dedo son secuencias generalizadas con un costo de búsqueda amortizado
y concatenación logarítmica. A es el tipo de datos, ignore V por ahora:
Visualizando FingerTree como puntos, Finger como cajas y Node como cajas dentro
de cajas:
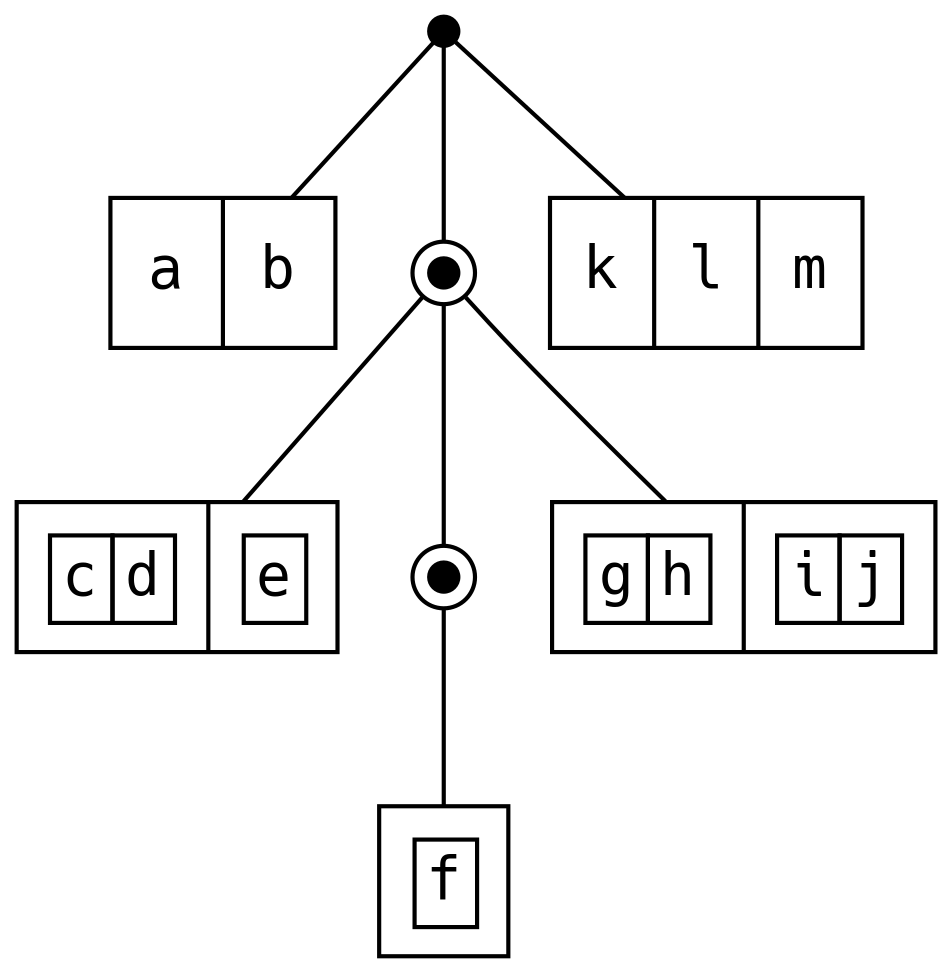
Agregar elementos al frente de un FingerTree con +: es eficiente porque Deep
simplemente añade un nuevo elemento al dedo del lado left. Si el dedo es un Four,
reconstruimos la espina (spine) para tomar 3 de los elementos como un Node3.
Agregando al final, :+, es lo mismo pero en reversa.
Agregar cosas |+| (también <++>) es más eficiente que agregar un elemento a la vez
debido a que el caso de dos árboles Deep pueden retener las ramas externas,
reconstruyendo la espina basándose en las 16 posibles combinaciones de los dos valores
Finger en la mitad.
En la discusión anterior nos saltamos V. En la descripción de la ADT no se muestra una
implicit measurer: Reducer[A, V] en cada elemento de la ADT.
Reducer es una extensión de Monoid que permite que un solo elemento se agregue a una
M.
Por ejemplo, Reducer[A, IList[A]] puede proporcionar un .cons eficiente
6.8.9.1 IndSeq
Si usamos Int como V, podemos obtener una secuencia indexada, donde la medida
es el tamaño, permitiéndonos realizar una búsqueda basada en el índice al comparar
el índice deseado con el tamaño de cada rama en la estructura:
Otro uso de FingerTree es una secuencia ordenada, donde la medida almacena el valor
más largo contenido en cada rama:
6.8.9.2 OrdSeq
OrdSeq no tiene instancias de typeclases de modo que únicamente es útil para construir
incrementalmente una secuencia ordenada, con duplicados. Podemos acceder al FingerTree
subyacente cuando sea necesario.
6.8.9.3 Cord
El caso más común de FingerTree es un almacén intermedio para representaciones de String
en Show. Construir una sola String puede ser miles de veces más rápido que la
implementación default de case class de .toString anidadas, que construye una String
para cada capa en la ADT.
Por ejemplo, la instancia Cord[String] devuelve una Three con la cadena a
la mitad y comillas en ambos lados
Por lo tanto una String se muestra tal y como se escribe en el código fuente
6.8.10 Cola de prioridad Heap
Una cola de prioridad es una estructura de datos que permite una rápida inserción de elementos ordenados, permitiendo duplicados, con un rápido acceso al valor mínimo (la prioridad más alta). La estructura no es necesaria para almacenar los elementos no mínimos en orden. Una implementación ingenua de una cola de prioridad podría ser
Este push es muy rápido O(1), pero el reorder (y por lo tanto pop) depende de
IList.sorted con un costo de O(n log n).
Scalaz codifica una cola de prioridad con una estructura de árbol donde cada nodo
tiene un valor menor que sus hijos. Heap tiene un operaciones rápidas push (insert),
union, size, pop (uncons) y peek (minimumO):
Heap está implementado con un Rose Tree de valores Ranked, donde rank
es la profundidad del sub-árbol, permitiéndonos balancear la profundidad del árbol.
Manualmente mantenemos el árbol de modo que el valor mínimo está en la raíz.
Una ventaja de que se codifique el valor mínimo en la estructura de datos es que
minimum0 (conocido también como peek) es una búsqueda inmediata y sin costo
alguno:
Cuando insertamos una nueva entrada, comparamos el valor mínimo actual y lo reemplazamos si la nueva entrada es más pequeña:
Las inserciones de valores que no son mínimos resulta en una estructura de datos desordenada en las ramas del nodo mínimo. Cuando encontramos dos o más subárboles de rango idéntico, colocamos el valor mínimo de manera optimista al frente:
Al evitar un ordenamiento completo del árbol hacemos que insert sea muy
rápido, O(1), de modo que los productores que agregan elementos a la cola
no son penalizados. Sin embargo, el consumidor paga el costo cuando invoca
uncons, con deleteMin teniendo un costo O(log n) debido a que debe
buscar el valor mínimo, y removerlo del árbol al reconstruirlo. Esto es
rápido cuando se compara con una implementación ingenua.
La operación union también retrasa el ordenamiento permitiéndo que se
realice en O(1).
Si Order[Foo] no captura correctamente la prioridad que deseamos para el
Heap[Foo], podemos usar Tag y proporcionar un Order[Foo @@ Custom]
ad-hoc para un Heap[Foo @@ Custom].
6.8.11 Diev (Discrete Intervals)
Podemos codificar eficientemente los valores enteros (desordenados)
6, 9, 2, 13, 8, 14, 10, 7, 5 como intervalos inclusivos
[2, 2], [5, 10], [13, 14]. Diev tiene una codificación eficiente
de intervalos para elementos A que tienen un Enum[A], haciéndose
más eficientes a medida que el contenido se hace más denso.
Cuando actualizamos el Diev, los intervalos adyacentes se fusionan
(y entonces ordenados) tales que hay una representación única para un conjunto
dado de valores.
Un gran caso de uso para Diev es para almacenar periodos de tiempo. Por
ejemplo, en nuestro TradeTemplate del capítulo anterior
si encontramos que los payments son muy densos, tal vez deseemos intercambiar
a una representación Diev por razones de rendimiento, sin ningún cambio en
nuestra lógica de negocios porque usamos un Monoid, no ningún método específico
de List. Sin embargo, tendríamos que proporcionar un Enum[LocalDate], que de
otra manera sería algo útil y bueno que tener.
6.8.12 OneAnd
Recuerde que Foldable es el equivalente de Scalaz de una API de colecciones y que
Foldable1 es para colecciones no vacías. Hasta el momento hemos revisado únicamente
NonEmptyList para proporcionar un Foldable1. La estructura de datos simple OneAnd
envuelve cualquier otra colección y la convierte en un Foldable1.
NonEmptyList[A] podría ser un alias a OneAnd[IList, A]. De manera similar, podemos
crear Stream no vacío, y estructuras DList y Tree. Sin embargo, podría terminar
con las características de ordenamiento y unicidad de la estructura de datos subyacente:
un OneAnd[ISet, A] no es un ISet no vacío, se trata de un ISet con la garantía de
que se tiene un primer elemento que también puede estar en el ISet.
6.9 Sumario
En este capítulo hemos revisado rápidamente los tipos de datos que Scalaz tiene que ofrecer.
No es necesario recordad todo lo estudiado en este capítulo: piense que cada sección es la semilla o corazón de una idea.
El mundo de las estructuras de datos funcionales es una área activa de investigación. Publicaciones académicas aparecen regularmente con nuevos enfoques a viejos problemas. La implementación de una estructura de datos funcionales a partir de la literatura sería una buena contribución al ecosistema de Scalaz.