Introduction
Deep Learning has been dominating recent machine learning competitions with better predictions. Unlike the neural networks of the past, modern Deep Learning has cracked the code for training stability and generalization and scales on big data. It is the algorithm of choice for highest predictive accuracy.
This documentation presents the Deep Learning framework in H2O, as experienced through the H2O R interface. Further documentation on H2O’s system and algorithms can be found at http://docs.h2o.ai, especially the “R User documentation”, and fully featured tutorials are available at http://learn.h2o.ai. The datasets, R code and instructions for this document can be found at the H2O GitHub repository at https://github.com/h2oai/h2o/tree/master/docs/deeplearning/DeepLearningRVignetteDemo. This introductory section provides instructions on getting H2O started from R, followed by a brief overview of deep learning.
Installation
To install H2O, follow the “Download” link on at H2O’s website at http://h2o.ai/. For multi-node operation, download the H2O zip file and deploy H2O on your cluster, following instructions from the “Full Documentation”. For single-node operation, follow the instructions in the “Install in R” tab. Open your R Console and run the following to install and start H2O directly from R:
1 # The following two commands remove any previously installed H2O packages for R.
2 if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
3 if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
4
5 # Next, download, install and initialize the H2O package for R
6 #(filling in the *'s with the latest version number obtained from the H2O downlo\
7 ad page)
8 install.packages("h2o", repos=(c("http://s3.amazonaws.com/h2o-release/h2o/ maste\
9 r/****/R", getOption("repos"))))
10 library(h2o)
Initialize H2O with
h2o_server = h2o.init(nthreads = -1)
With this command, the H2O R module will start an instance of H2O automatically at localhost:54321. Alternatively, to specify a connection with an existing H2O cluster node (other than localhost at port 54321) you must explicitly state the IP address and port number in the h2o.init(nthreads = -1) call. An example is given below, but do not directly paste; you should specify the IP and port number appropriate to your specific environment.
h2o_server = h2o.init(ip = "192.555.1.123", port = 12345, startH2O = FALSE, nthreads = -1)
An automatic demo is available to see h2o.deeplearning at work. Run the following command to observe an example binary classification model built through H2O’s Deep Learning.
demo(h2o.deeplearning)
Support
Users of the H2O package may submit general inquiries and bug reports to the H2O.ai support address. Alternatively, specific bugs or issues may be filed to the H2O JIRA.
Deep Learning Overview
First we present a brief overview of deep neural networks for supervised learning tasks. There are several theoretical frameworks for deep learning, and here we summarize the feedforward architecture used by H2O.
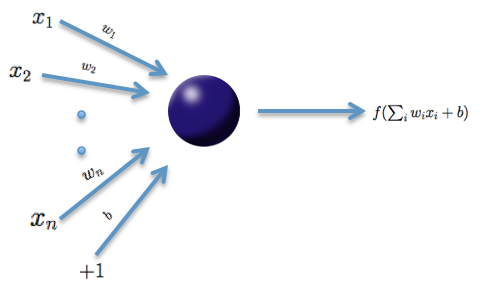
The basic unit in the model (shown above) is the neuron, a biologically inspired model of the human neuron. For humans, varying strengths of neurons’ output signals travel along the synaptic junctions and are then aggregated as input for a connected neuron’s activation. In the model, the weighted combination 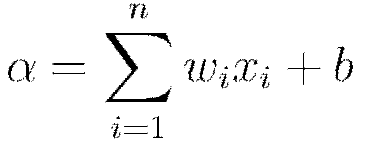 of input signals is aggregated, and then an output signal
of input signals is aggregated, and then an output signal 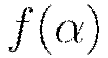 transmitted by the connected neuron. The function
transmitted by the connected neuron. The function 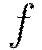 represents the nonlinear activation function used throughout the network, and the bias
represents the nonlinear activation function used throughout the network, and the bias 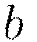 accounts for the neuron’s activation threshold.
accounts for the neuron’s activation threshold.
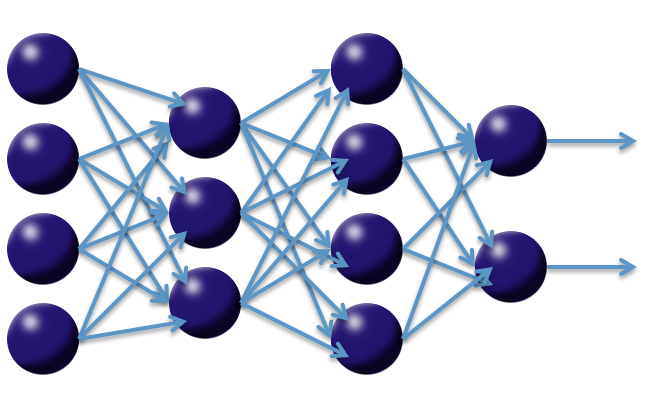
Multi-layer, feedforward neural networks consist of many layers of interconnected neuron units: beginning with an input layer to match the feature space; followed by multiple layers of nonlinearity; and terminating with a linear regression or classification layer to match the output space. The inputs and outputs of the model’s units follow the basic logic of the single neuron described above. Bias units are included in each non-output layer of the network. The weights linking neurons and biases with other neurons fully determine the output of the entire network, and learning occurs when these weights are adapted to minimize the error on labeled training data. More specifically, for each training example  the objective is to minimize a loss function
the objective is to minimize a loss function
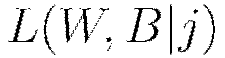
Here 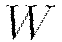 is the collection
is the collection 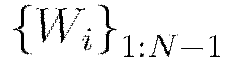 , where
, where 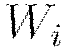 denotes the weight matrix connecting layers
denotes the weight matrix connecting layers  and
and  for a network of
for a network of 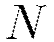 layers; similarly
layers; similarly 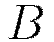 is the collection
is the collection 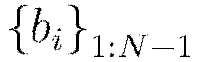 , where
, where 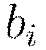 denotes the column vector of biases for layer
denotes the column vector of biases for layer 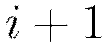 .
.
This basic framework of multi-layer neural networks can be used to accomplish deep learning tasks. Deep learning architectures are models of hierarchical feature extraction, typically involving multiple levels of nonlinearity. Such models are able to learn useful representations of raw data, and have exhibited high performance on complex data such as images, speech, and text (Bengio 2009).