3. Appendix
- Appendix A: Creating Workflow in JIRA
- Appendix B: GitHub book workflow
3.1 Appendix A: Creating Workflow in JIRA
This section shows how to create the JIRA workflows without using any JIRA plugins
Key concepts of this workflow
- All tests should pass all the time
- Tests that check/confirm vulnerabilities should also pass
- The key to make this work is to:
- Make business owners understand the risks of their decisions (and click on the ‘accept risk’ button)
3.1.1 Creating-a-Jira-project
For these examples we will use the version hosted JIRA cloud called (in Oct 2016) JIRA Software.
Note that the same workflow can be created on the on-premise versions of JIRA (including the older versions)
If you don’t have a JIRA server you can use, then use can create on using the Jira evaluation page and choosing the JIRA Software option. I would also add in the Documentation (aka Confluence) module since it is a very powerful wiki (which is called Confluence)

If you don’t have an account you will need to create one.
After clicking on Start now your cloud instance of JIRA will be created (my bet is that this is a docker container with a dedicated data store for each customer/trial)

3) login
4) create new project
5) choose Kanban Software Development

6) Name it ‘RISK - AppSec’ with the key ‘RISK’,
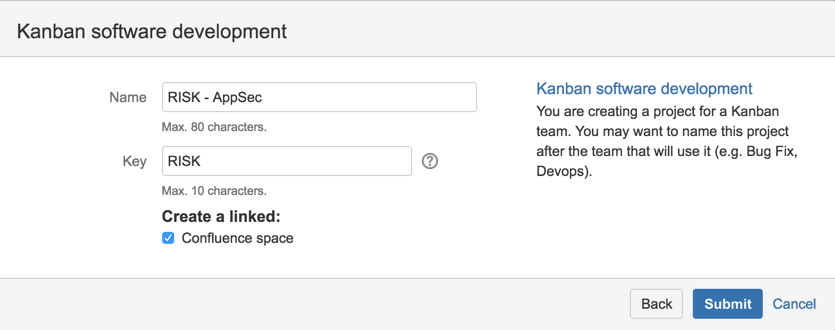
7) Your new JIRA Project dashboard should open and look something like this
3.1.2 Step-by-step instructions
Creating RISK workflow
as seen here http://blog.diniscruz.com/2016/03/updated-jira-risk-workflow-now-with.html
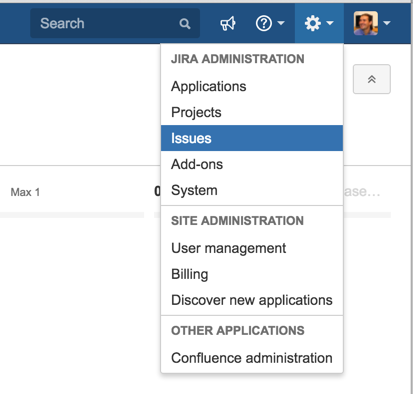
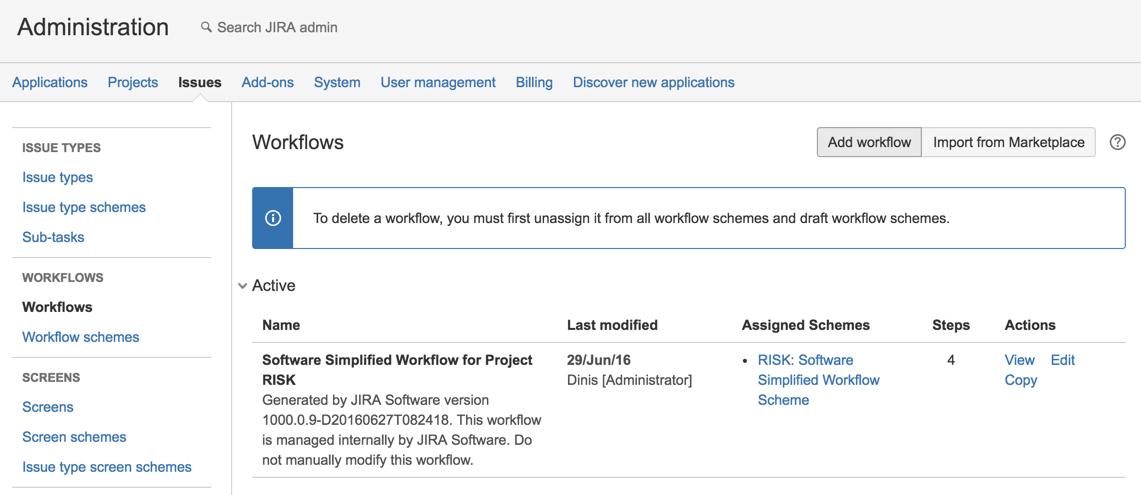
7) Go to JIRA Administration , Issues
8) Add an issue type
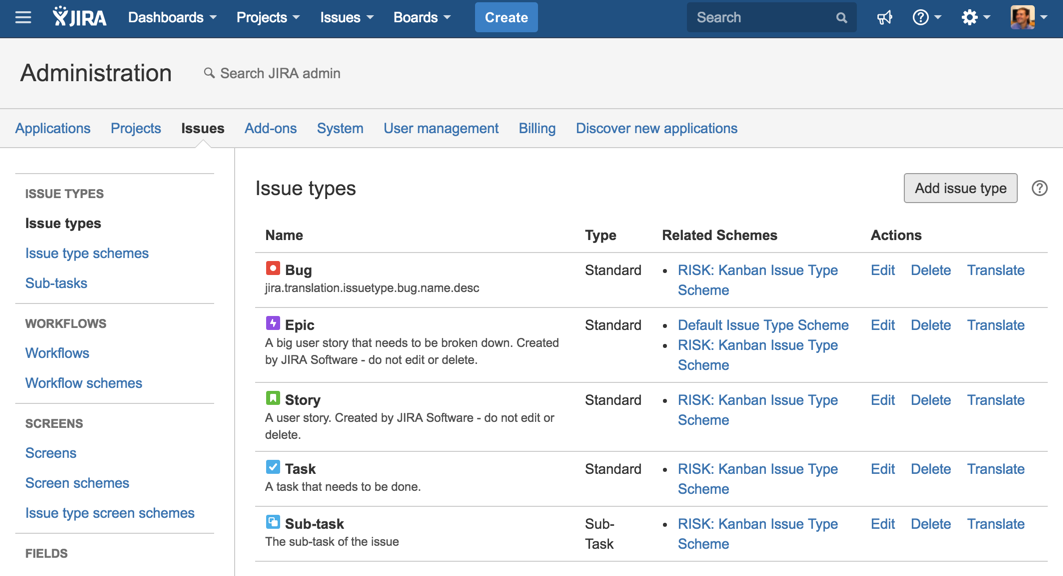
9) call it Risk
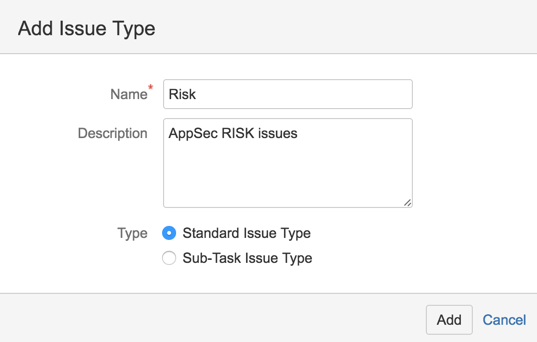
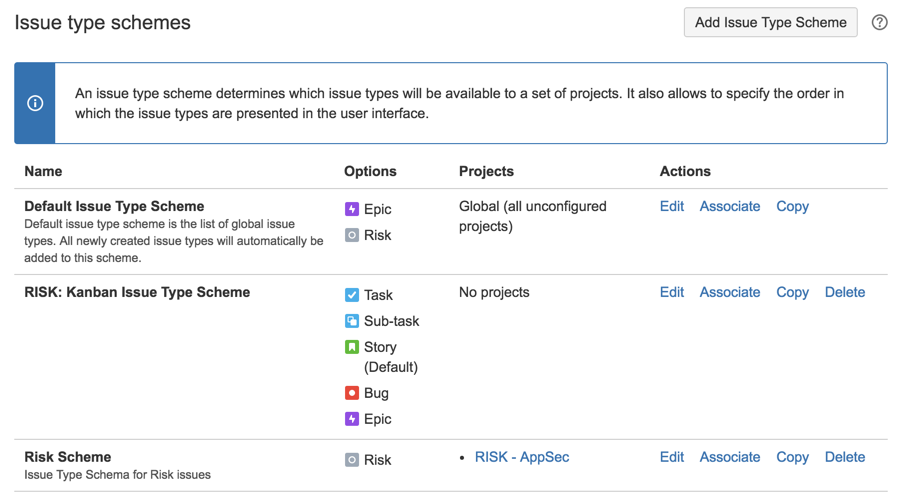
10) Go to Issue type schemes and click on ‘Add Issue Type Scheme’
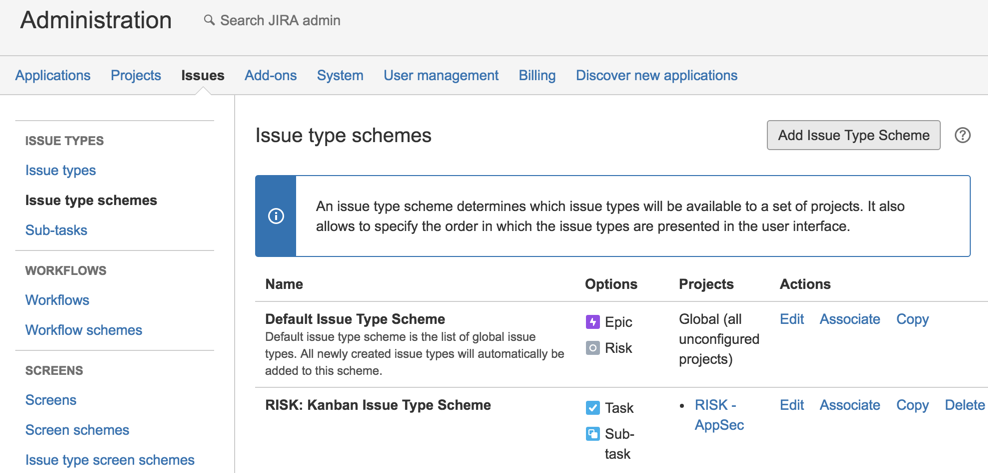
11) Call it Risk Scheme and add the Risk Issue type into to (click Save to continue)
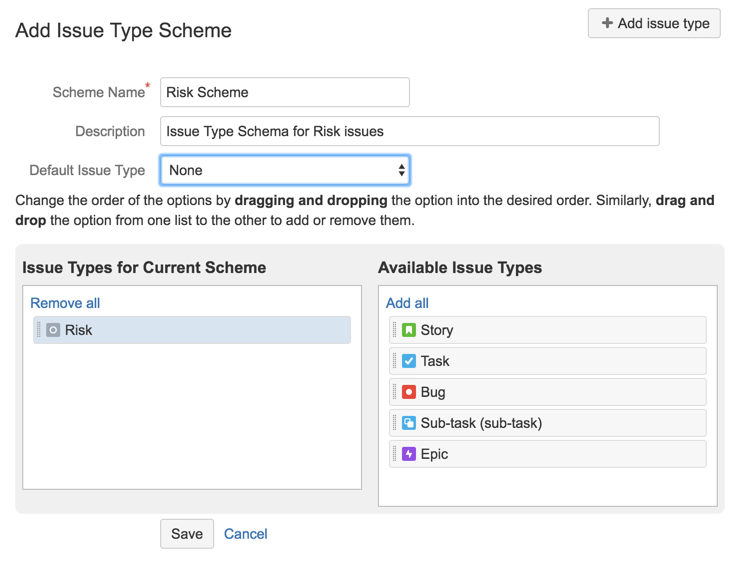
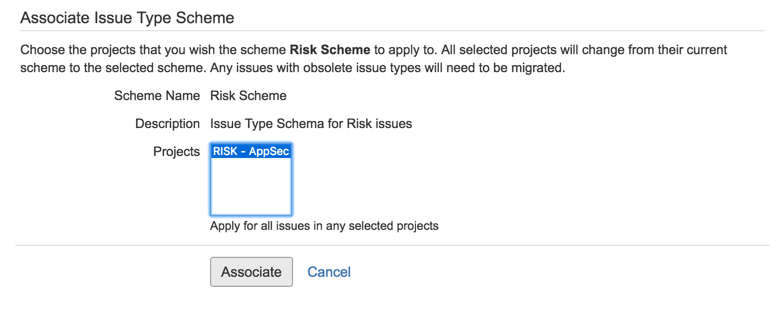
12) Associate that Risk Scheme
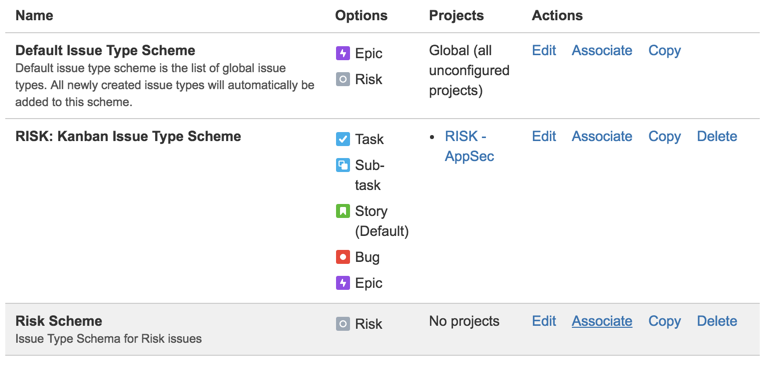
13) To the ‘RISK - AppSec’ project
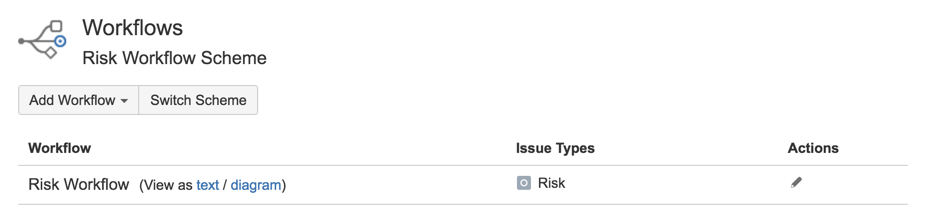
14) Go to Workflows and add new one
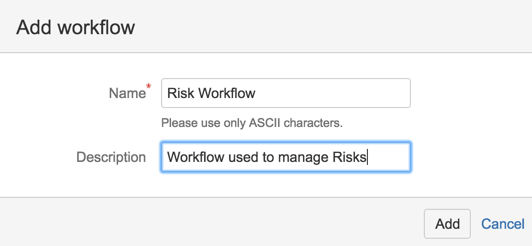
15) call it ‘Risk Workflow’
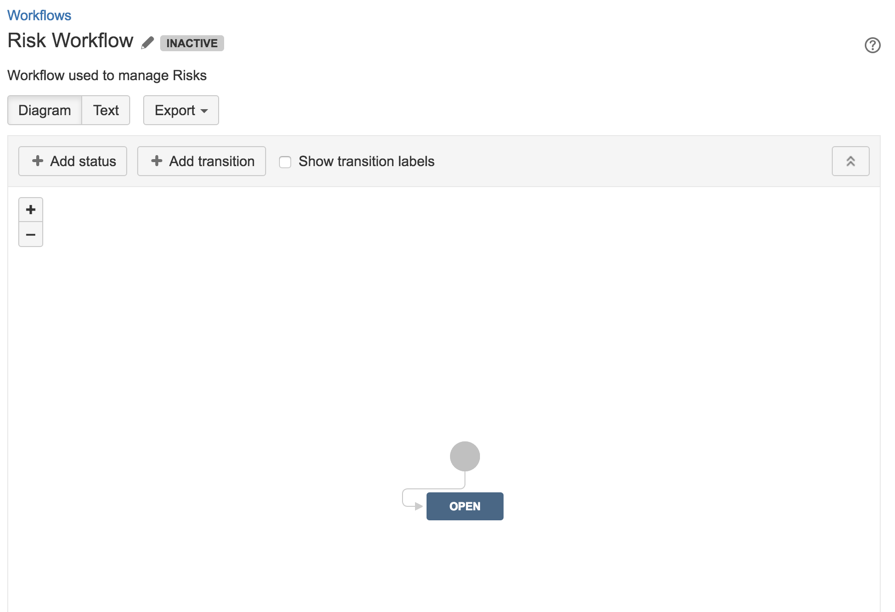
16) Add status ‘In Progress
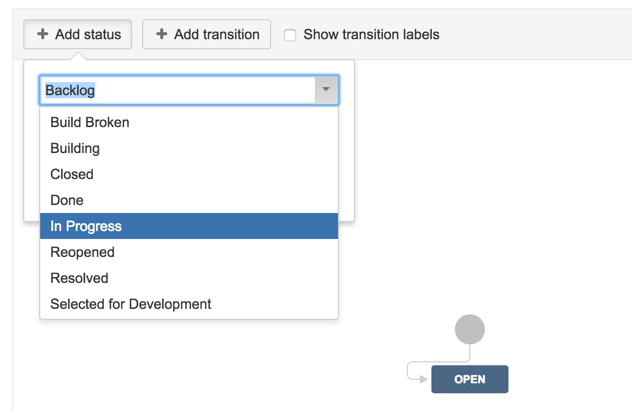
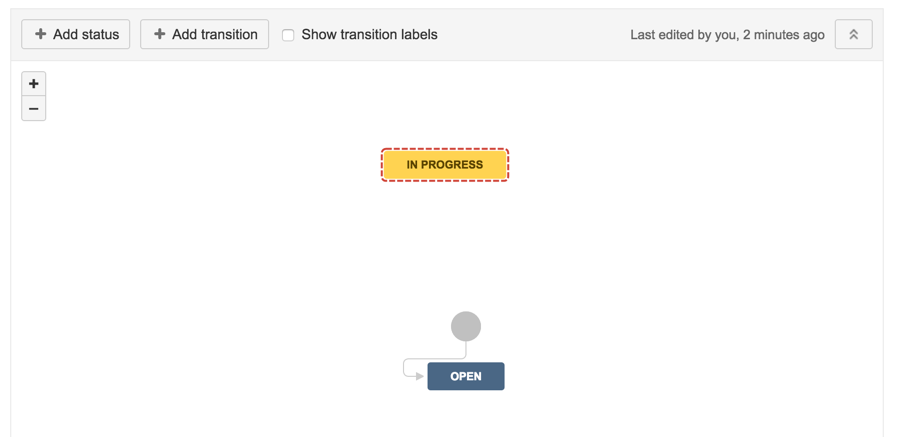
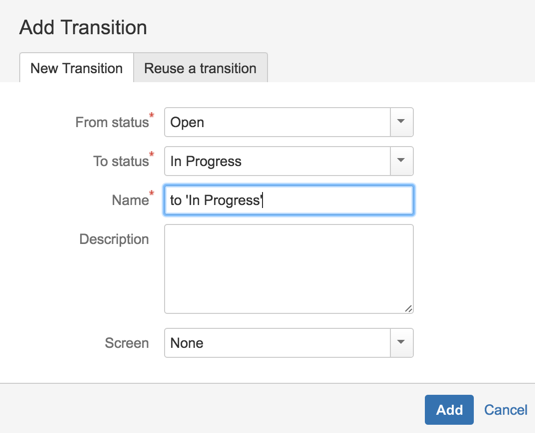
17 ) Create transition from Open to In Progress
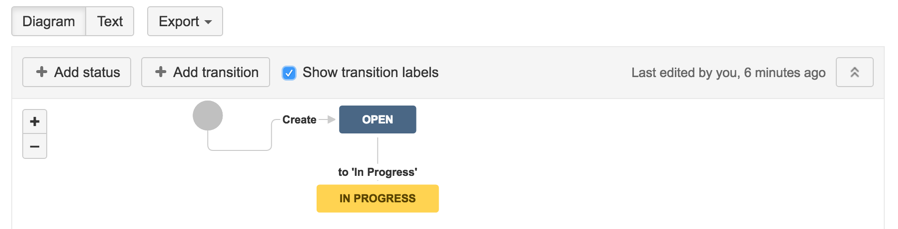
18) Create a new Status called ‘Allocated for Fix’
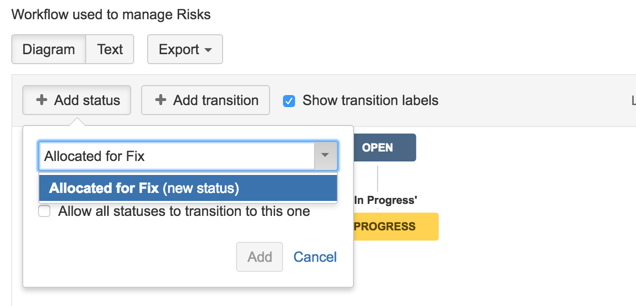
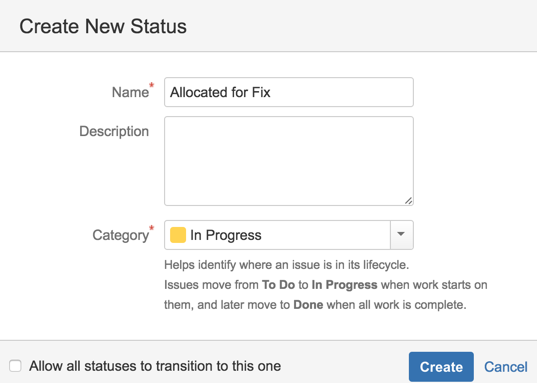
19) add a transition to ‘Allocated for Fix’ state
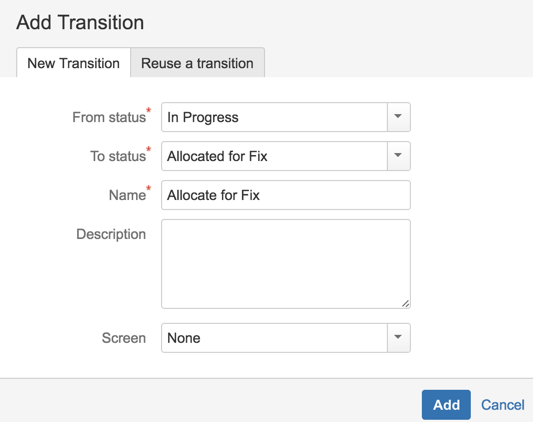
20) how workflow looks like at the moment
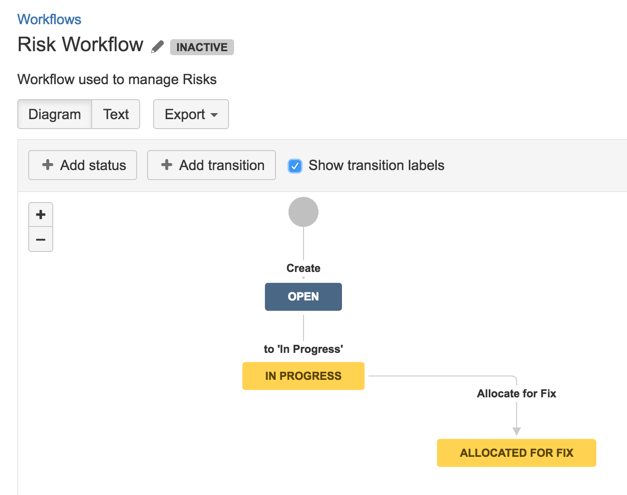
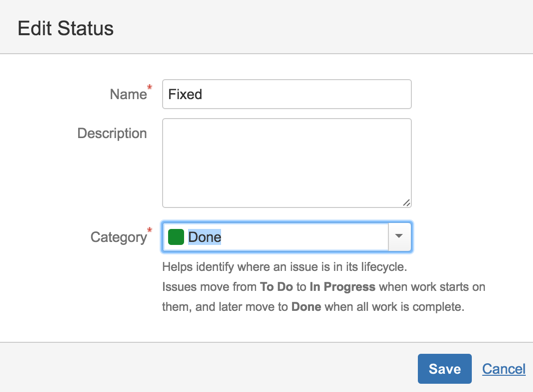
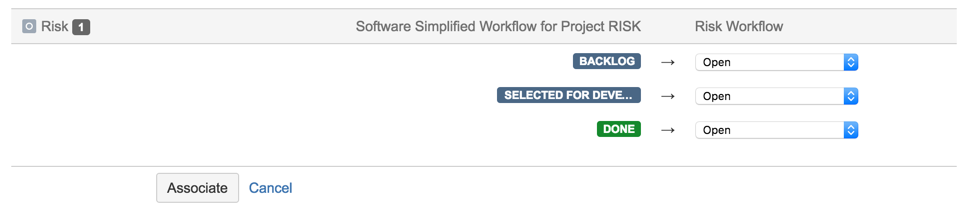
21) Add status: Fixing, Test Fix and Fixed
with fixed set to the ‘Done’ Category
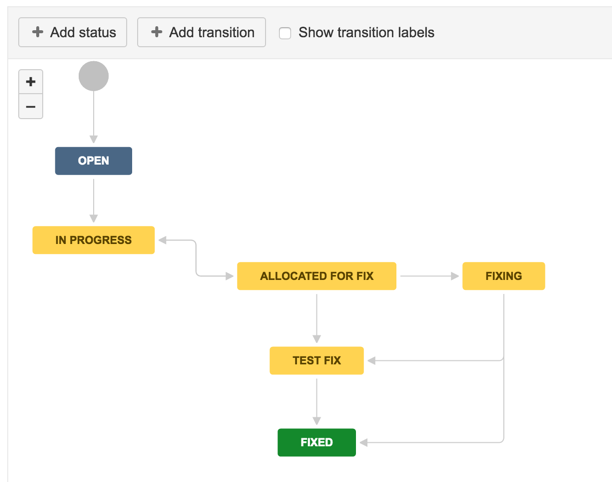
21) add transitions to those status
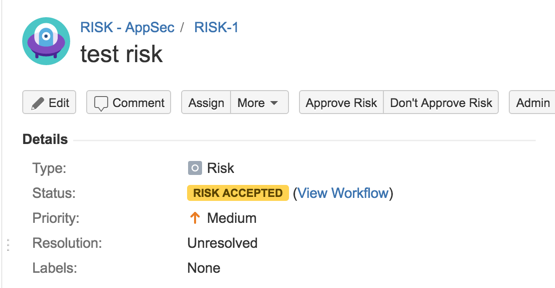
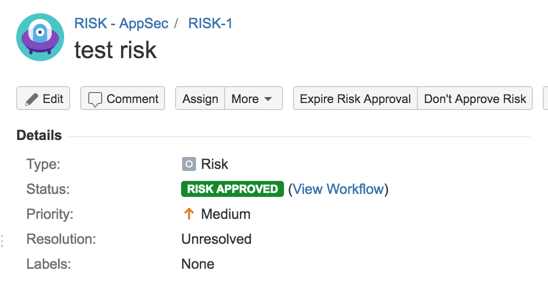
22) Add Status: Closed, ‘Awaiting Risk Acceptance’ , ‘Risk Accepted’, ‘Risk Approved’, ‘Risk Not Approved’, ‘Risk Approval Expired’
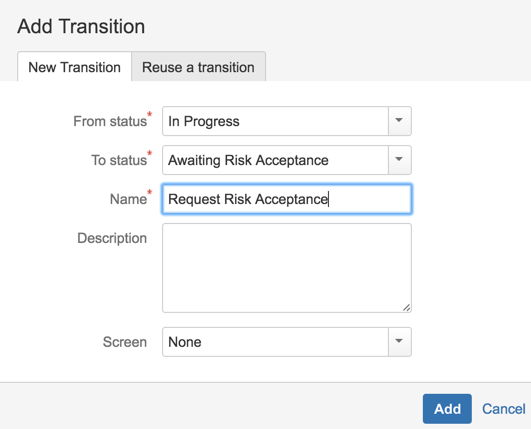
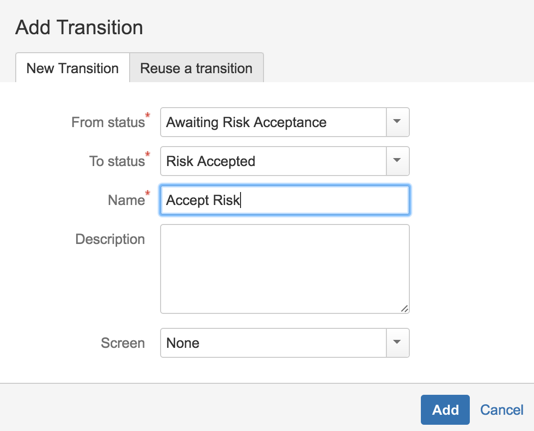
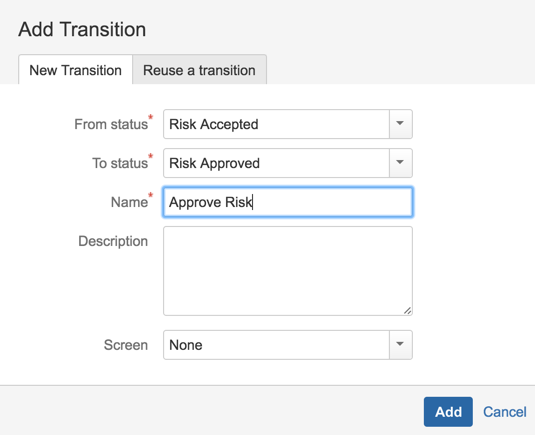
23) Add transitions (including a couple to reverse some of the steps)
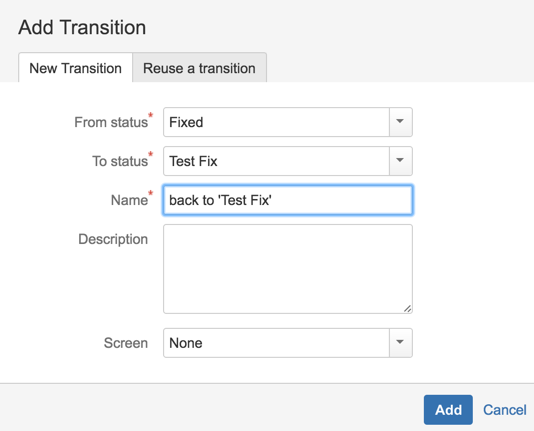
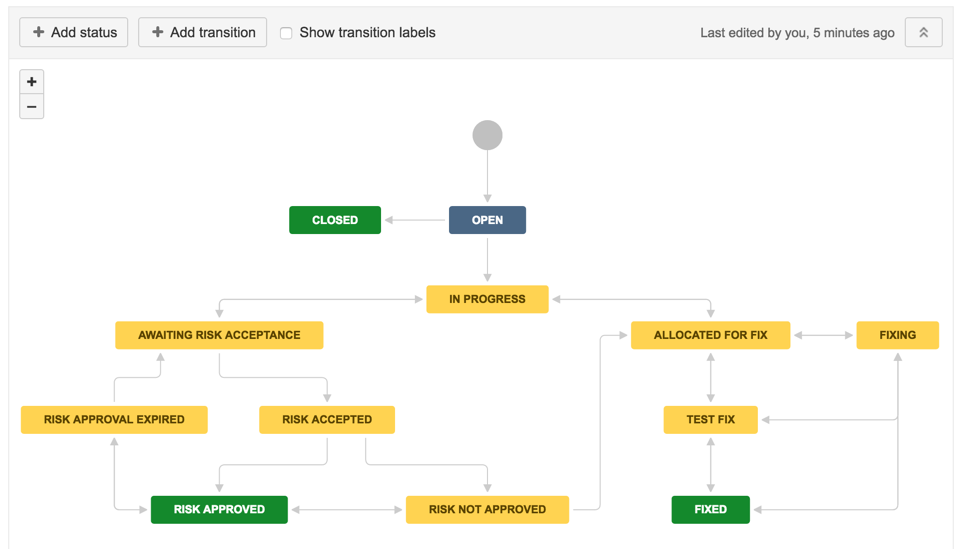
24) Completed workflow should look like this
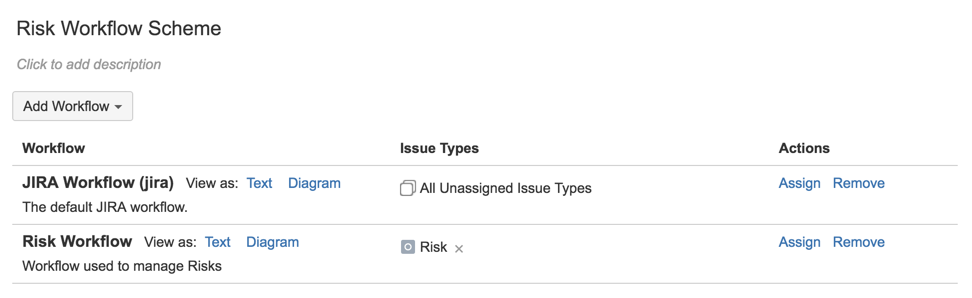
25) go to Workflow Scheme and chose to ‘Add workflow scheme’
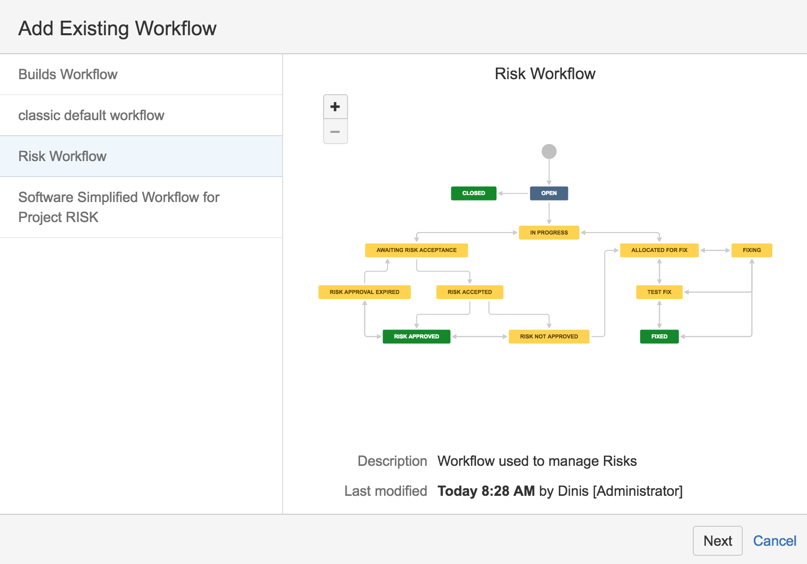
26) Add Existing Workflow
27) Assign Risk Issue type to it
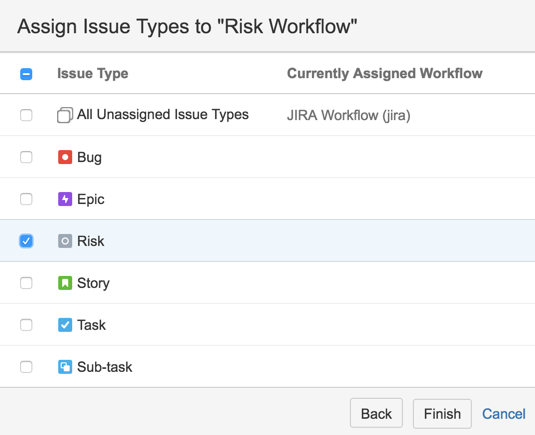
28) exit admin and go to the RISK project’s settings
29) in the Workflow page chose to Switch Scheme
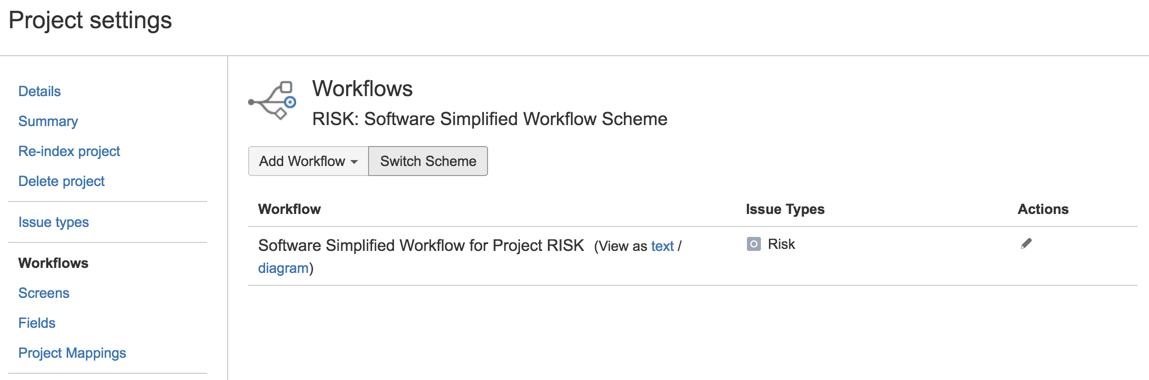
30) Pick the ‘Risk Workflow Scheme’
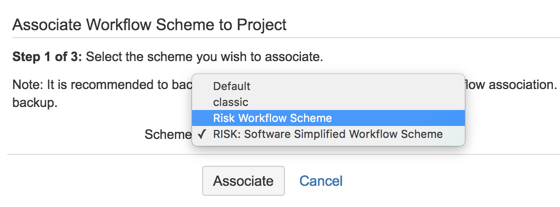
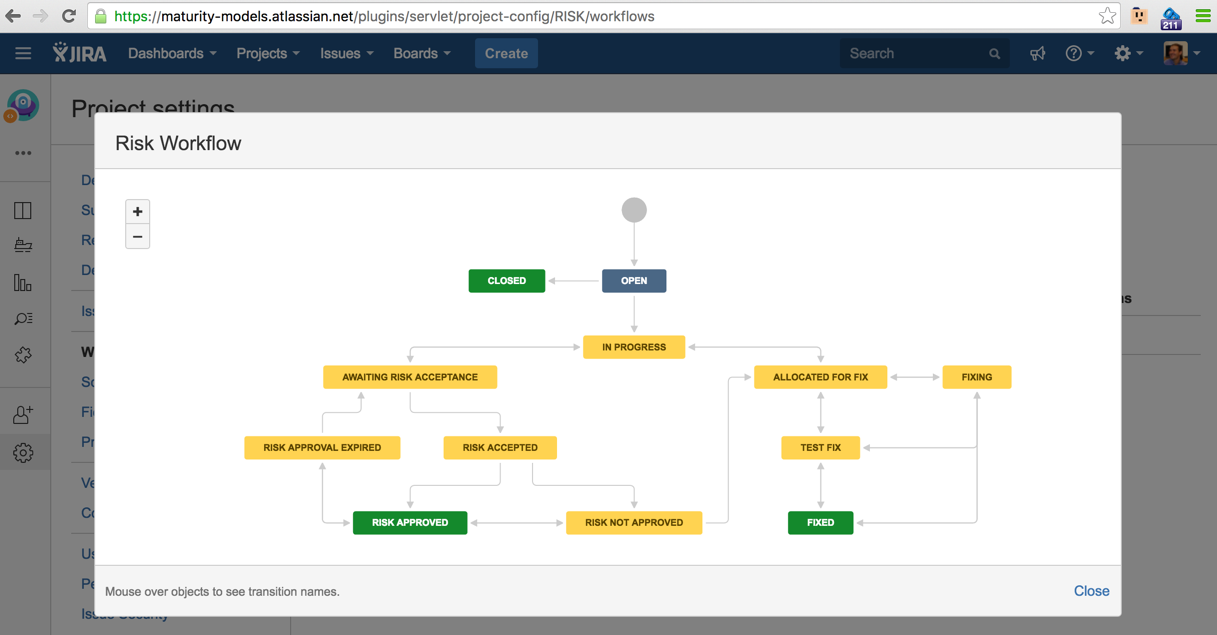
31) Test workflow (fixing path)
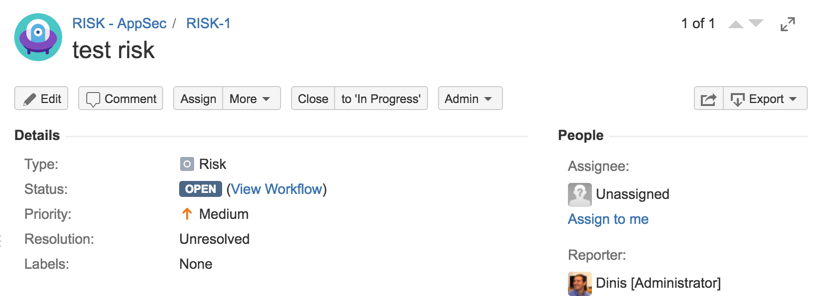
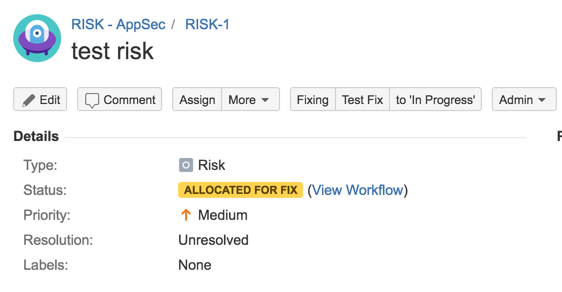
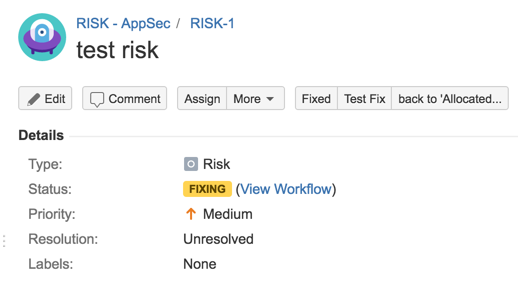
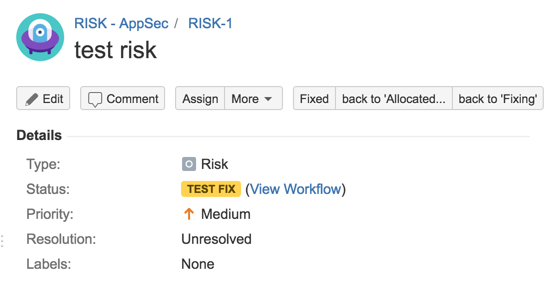
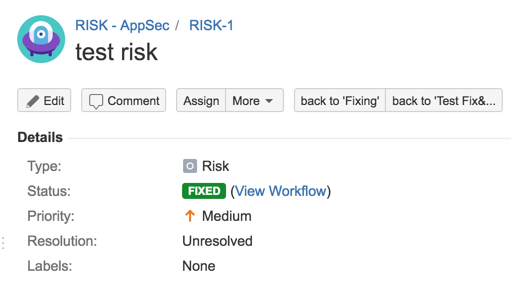
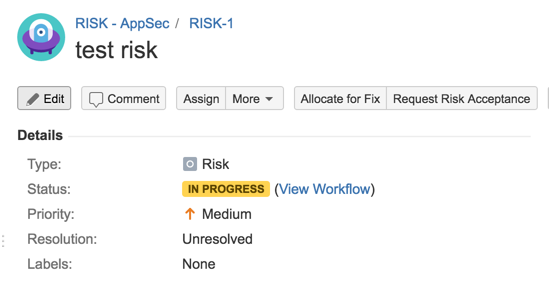
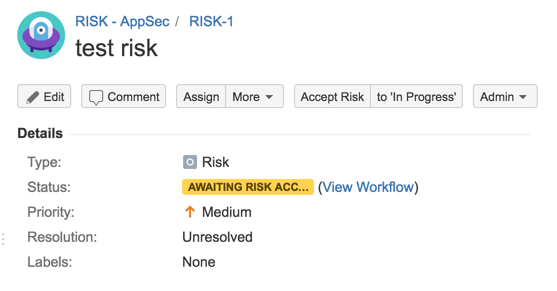
31) Test workflow (Accept Risk)
3.2 Appendix B: GitHub book workflow
- explain the workflow used to create this book
- audio transcripts and copy editing (and upwork)
- Pull requests for copy editing
- Labels for managing tasks and issues
- show how to report a problem with the book or suggest ideas
3.2.1 Book creation workflow
- what are all the actions that occur, from making a code change to having a preview done
- explain two modes (Github online editing and offline editing using Atom editor)
3.2.2 GitHub Leanpub hook
- how it works
- what it does
3.2.3 GitHub online editing
- explain how it works and the workflow used
- mention leanpub service hook and how every content change will eventually result in a new preview
3.2.4 GitHub repos used
- https://github.com/DinisCruz/Book_Jira_Risk_Workflow
- hold content and raw files
- better searching since the manuscript files are not there
- used to create the stand-alone version of the book
- https://github.com/DinisCruz/Book_Jira_Risk_Workflow_Build
- holds files in Leanpub friendly format
- hooks into leanpub via GitHub service
- every commit to this repo will trigger a build
3.2.5 Tool leanpub-book-site
- explain what it is and how it works
- rules of engagement
- folders and file structure
- auto-generation of book.txt file
- consolidation of images
- reason for doing it was : 1) solve problem of massive image folder (now each chapter is directly mapped to it’s images, which is ok as long as the image’s name are not repeated) 2) solve problem of having to maintain the Book.txt file 3) allow splitting of manuscript folder into separate repo
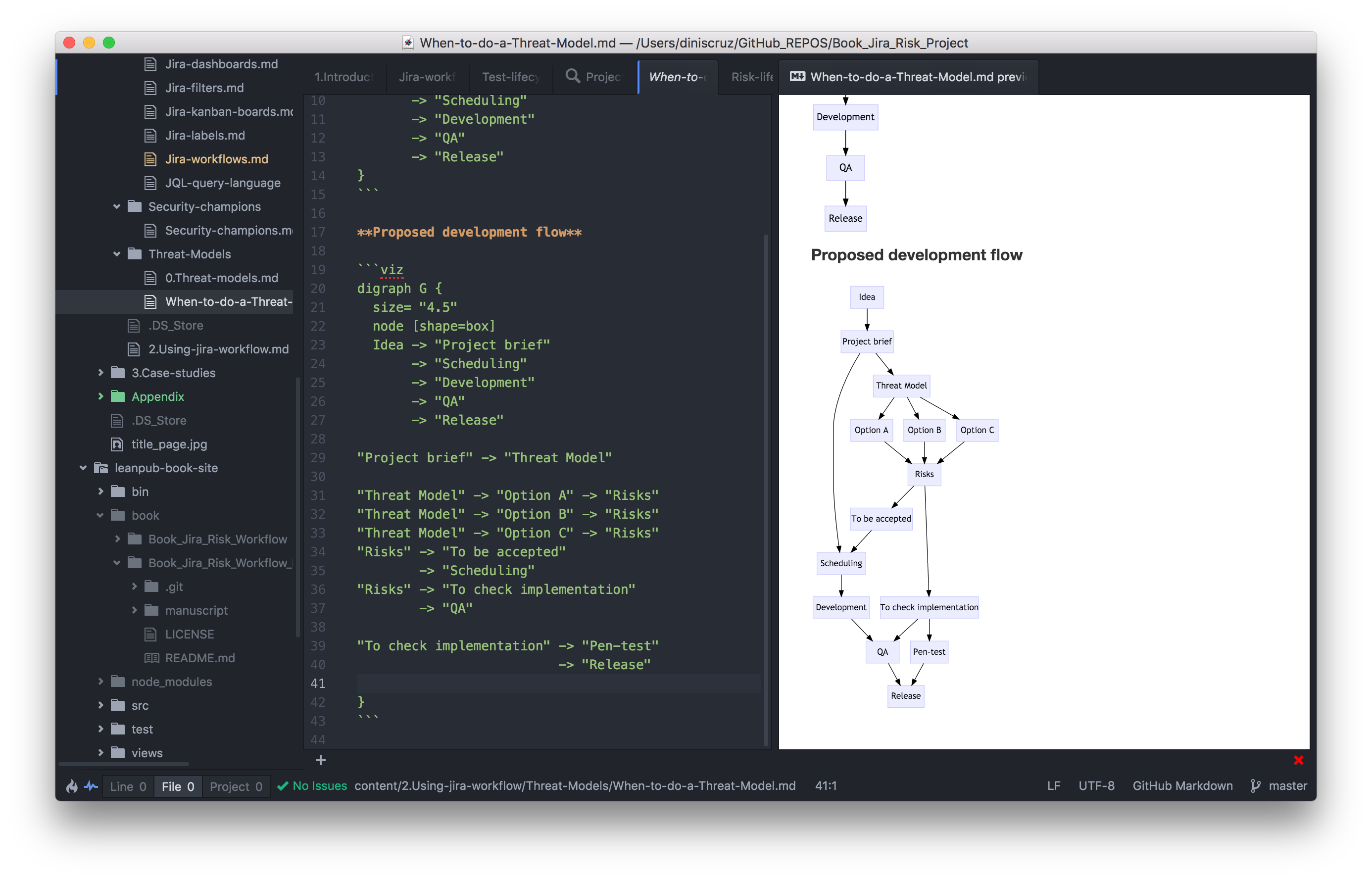
3.2.6 Atom, Markdown, Graphiz, DOT
Editing and diagram creation was done on Atom editor with the markdown-preview-enhanced plugin
Text was written in markdown
Diagrams where created using DOT Language , rendered by GraphWiz and Viz.js
This is what the IDE looks like:
References:
- GraphWiz and Dot:
3.3 Appendix C: Security Tests Examples
- add multiple examples of security tests
- in node/coffee script
- HSTS header check
- detecting attack surface changes
- performance tests
- in Javascript
- emberjs safehtml issue
- in java
- random() lack of randomness
- detecting methods calls
- in .net
- email regex issue
- using reflection to check api usage
- testing XSS on HTML Elements
- android
- query SQL Injection
- in node/coffee script
3.4 Appendix D: Case Studies
3.4.1 File Upload
- public competition where external users where supposed to upload their work (this was aimed at University grads)
- lots of moving parts in original design
- better solution was to use GitHub for file submissions
- massive difference in the risk and complexity of each solution
3.4.2 HTML editing
- common request/feature in web-apps
- massive attack surface and security issues (equivalent to XSS) i
- prevents clients to protecting themselves (unless they can use CSP)
- good example of not answering the real business need
- which tends to be ‘edit text, with images, some formatting (bold, italics), links and tables’
- all these can be meet if using Markdown (which can be even better for the user, due to its easy of use, ease of diff and readability)
- lots of un-intended side-effects, for example with copy-and-paste
- trying to create ‘safe html’ is very dangerous due to the crazy stuff that HTML allows and the ‘cleverness of some browsers’ (which are able to fix broken HTML and Javascript)
3.5 Appendix E: GitHub Issue worklfow
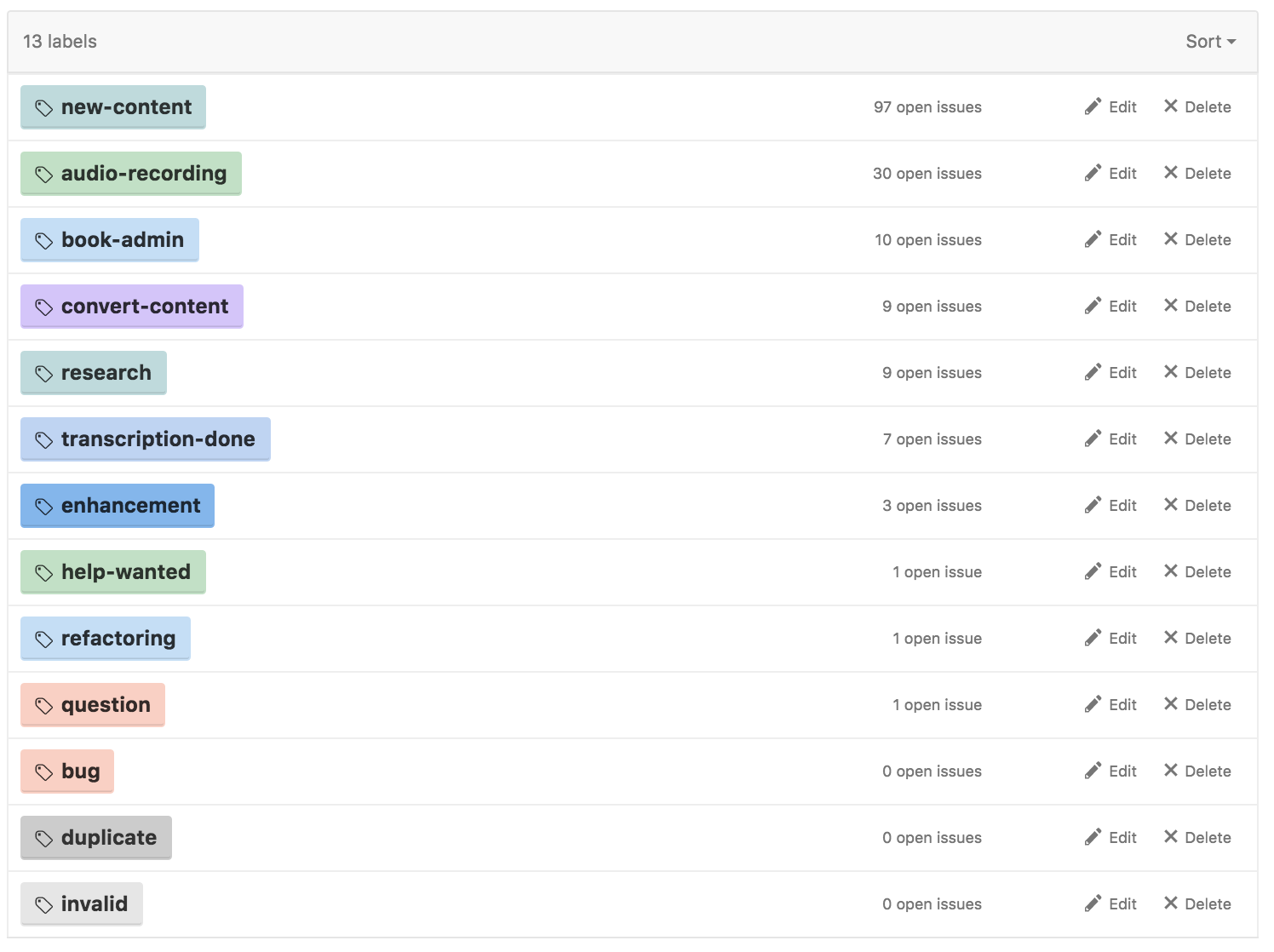
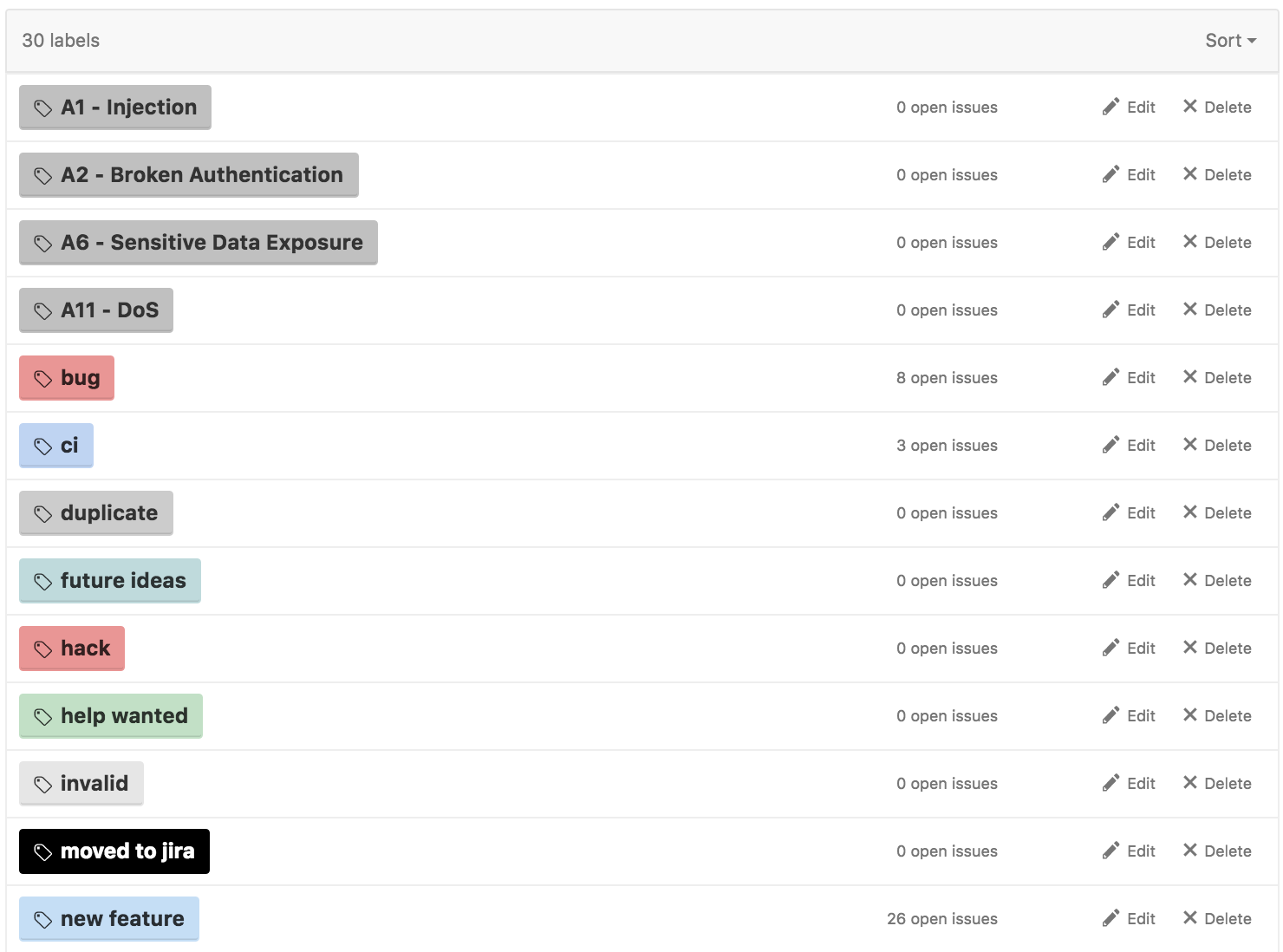
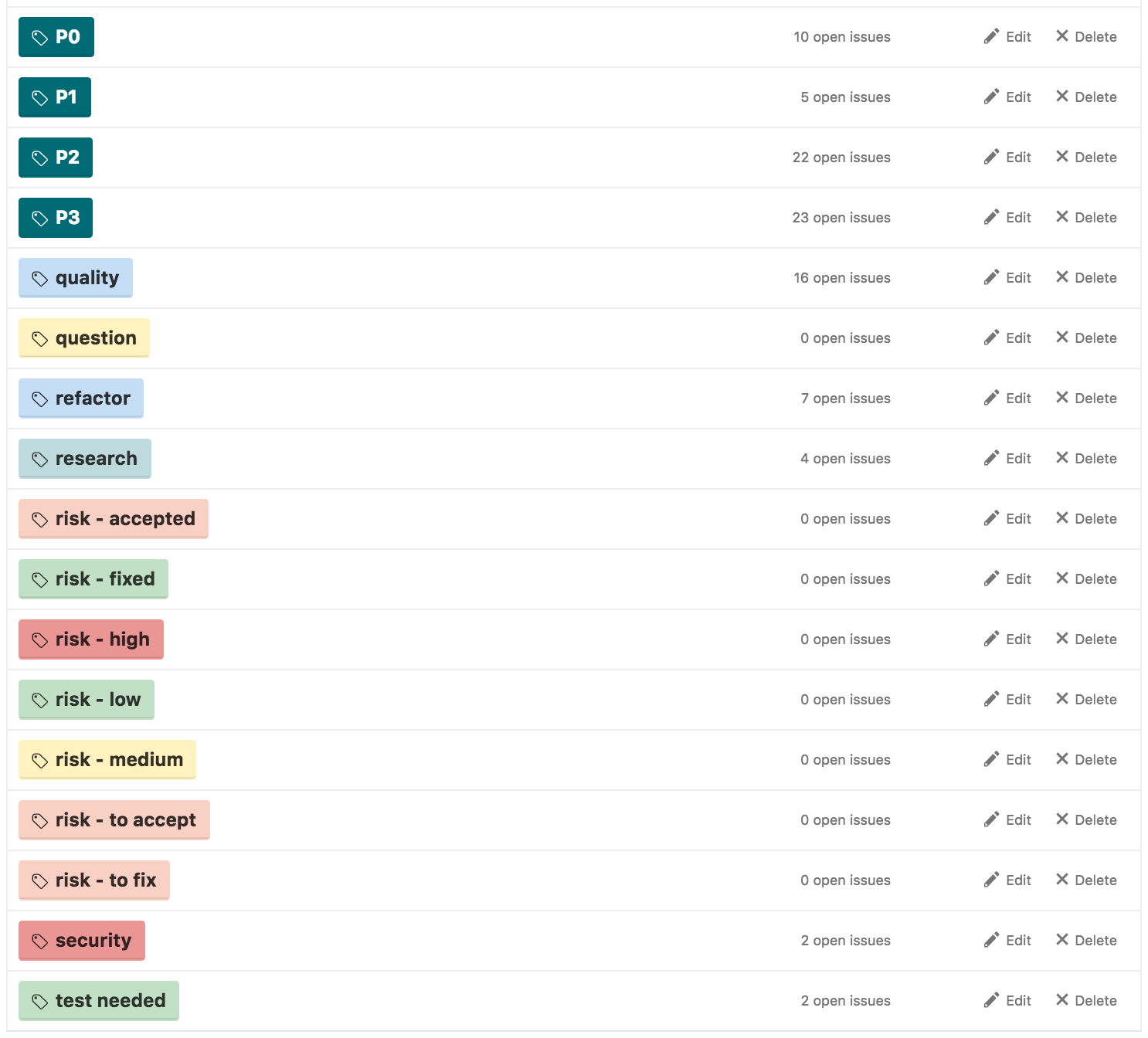
3.5.1 GitHub Labels
- Below are some examples of the use Labels
Labels on book generation
Labels on complex software development
3.5.2 Reporting issues
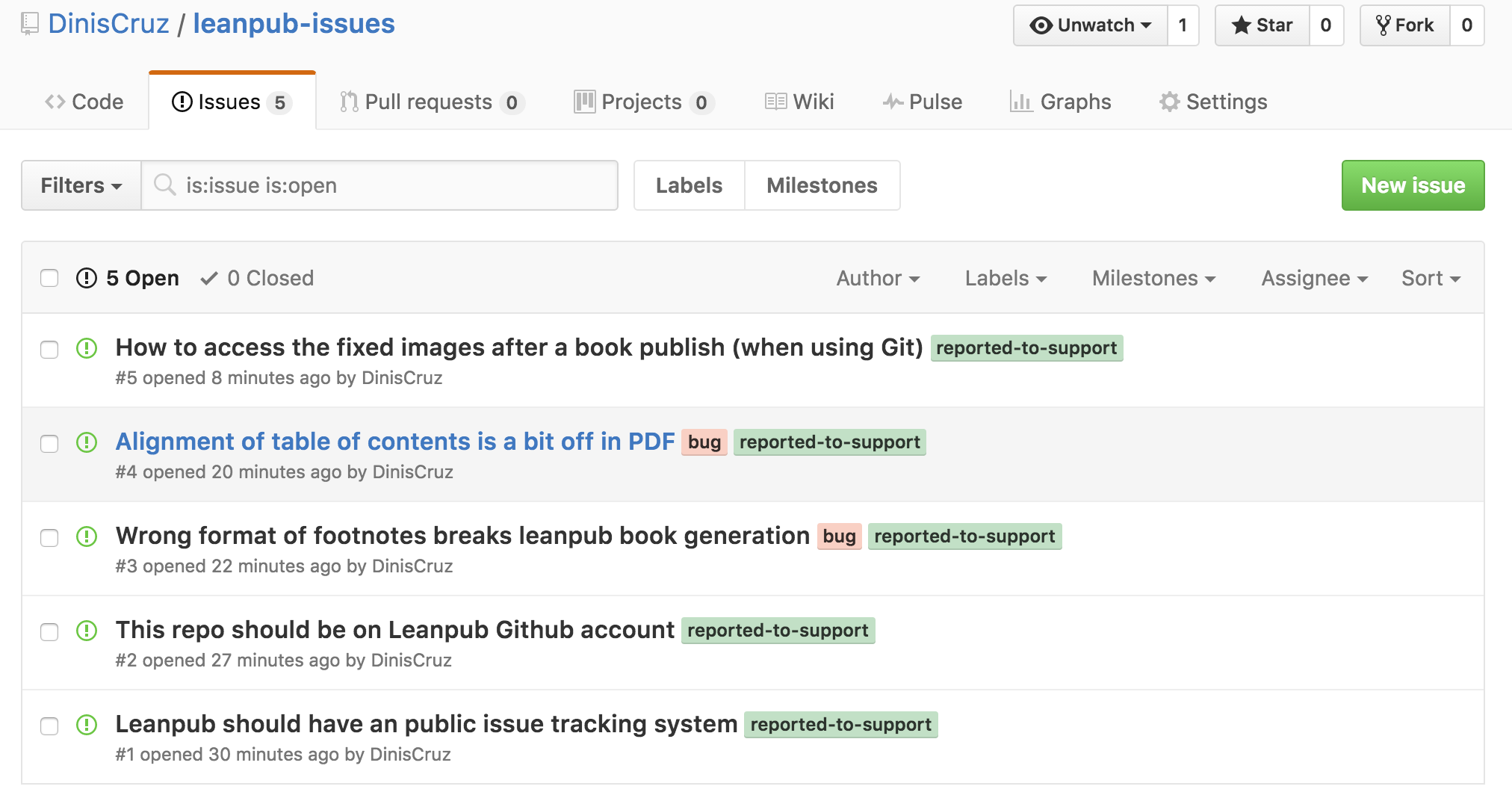
- GitHub can also be used to create similar risk (and other) workflows
- Leanpub Issues
- Veracode Issues
3.6 Draft Notes
These are a mix bag of notes made on real notebooks which need to be normalized, converted into paragraphs and placed in the right location
There might be some repeated content which has already been covered in the book
3.6.1 Draft notes - AppSec Tools
- The false positive and false negative problem in tools and in code review
- when doing code reviews, for me the issue (and vulnerability) starts in a line of code or in a method (even if it not being used at the moment, or exposed to an malicious source)
- desired SAST workflow
- scan every app and component in the company
- for each app scan all their versions
- find versions with vulnerabilities (which should be banned from being used)
- mode where they sell concurrent scans (change more for speed, performance) not number of apps
- apps get created and deleted with every scan
- results are stored in git
- for some apps it might make sense to have apps live longer (specially if the ui helps with remediation)
- allow custom rules
- expose internal objects and graphs
- personalize and timing of the delivery of SAST (or other) tools knowledge (i.e. findings)
- this can be as important as the content since the recipient must be in a position to consume/understand that guidance
- this will need to customized to the developer’s skills, appsec experience, status of mind and stage of SDL (planing, architecture, development, testing, qa, bug fixing)
3.6.2 Draft notes - Code Quality
- Bad code and lack of testing has to be measured, since it has to have side effects.
- If code has not tests but always works, all releases are smooth and there are no major incidents, then it is OK not to have tests,
- … now back in the real world … lack of tests and weak CI will always have side effects:
- problematic releases
- customers finding bugs
- long time to create features requested by business
- quality issues on deliverables
- weak and ever-changing briefs
3.6.3 Draft notes - DevOps
Stages of AppSec automation
Start with static analysis which don’t need a live environment to deploy the application
- Have a CI that builds code automatically for every commit of every branch
- Ran ‘a’ tool after build (doesn’t really matter which one what matters is that it uses the materials created on step 1)
- use for example FindBugs with FindSecBugs 7
- Find tune scan targets (i.e. exactly what needs to be scanned)
- Filter results, customize rules to reduce noise
- Gather reports and scans and put them on git repo
- create a consolidated dashboard (for management and business owners)
- add more tools
- loop from 5
after this is mature, add a step to deploy the app to a live environment (or simulator)
3.6.4 Draft notes - Developers
- developers can be disconnected from their future-self
- why are they accept and make decisions that will hurt them in the future
- idea of showing the real cost of technological & coding decisions
- Positive & Negative impact
- one-off vs recurring cost/benefit analysis
- we need developers to act more inline with their (and the apps) long-term interests
- usually business owners are not made accountable for their technological decisions (they get the bonus for ‘delivering’ and move on to another project or company )
- developers need to start picking fights on what is better for the business in the long run.
- when they overruled, that needs to be ‘on the record’, which is better done with the JIRA Risk Workflow
- best strategy to do this is to align yourself with the values and direction of the organization or company you are working for
- We should be able to predict when a developers is about to create a security vulnerability
- based on similar patterns/code-graphs of other developers/code-changes in the past
- Google and StackOverflow queries
- detect bad results (maybe with even security vulnerabilities) and provide better recommendations
- detect what questions they will ask next and suggest better results (proactive code-complete like, AI technology will help)
- Detect when code is one degree away from and exploit/vulnerability
- Defense concept: always be or three degrees of separation from an serious vulnerably/exploits
3.6.5 Draft notes - Government
- In the ‘open letter to president’ (find link) there is no mention of secure coding or secure apps
- but all our technology runs on code and until we control it, we will not really be solving the root causes
3.6.6 Draft notes - PoCs
- related to ‘why exploits are important’
- example for demos to perform ‘management and C-level execs’
- When XSS/JS-injection is possible
- Replace website logo with their competitor’s logo , or
- Add the competitor logo after an ‘… a division of company Y…’ tag (Y are their competitor)
- capture session tokens via insecure cookies and use session tokens to perform visible action (change user details, make transactions, delete user assets)
- logout the user (continuously) via CSRF, so that the legit user is not able to login
- Clickjacking that performs action on target website
- DoS/DDoS the site (for a little bit) using small amounts of traffic (discovered after profiling the app via integration tests, which identified a number of expensive calls)
- When XSS/JS-injection is possible
3.6.7 Draft notes - Threat Models
- Do Threat Models in layers
- identify each STRIDE issue per layer
- each layer it built on top of the previous one
- connect the threats
- map the Urls and Data objects and connect them across layers
- created ‘refactored’ and ‘collapsed’ views of the diagrams (specially when there are ‘web services that act like proxies’ in the middle)
- Introduce the concept of Sinks in Threat Modeling
- how to connect the multiple threats (one for each layer) so that they are chained
- map this concept with the concept of Attack Trees
- how to connect the multiple threats (one for each layer) so that they are chained
- Idea to create a Book focused on “Threat Modeling examples and patterns”
3.7 Audio Transcriptions
These files are a first pass at a particular topic, done as audio files, recorded on my mobile, and transcribed verbatim.
Some say that you know the vulnerability where user and account ID was received from the outer world that was basically passed into the back end and user and he was able to just use easy to be data.
The root cause of those problems tend to be the fact that the controller is actually able to access and make those calls. So you need to open a risk for that. Then you also need to open another risk for the fact that your need to create an account ID from the front end from user data.
So there is already implication of that dangerous operation. And the third one is that actually step of actually using that you know the one that creates a vulnerability, passing the risk directly to the back end with the violation.
Now when you fix this a lot of times to fix is done at the control level so you add the method there to say, “hey this user has access to this, this user has access to this account”.
The problem that is the wrong fix, it is a hack so you need to create a risk to that. Because the real fix should be done at the back end servers the real fix should be you should pass for example the user token or the back end and then use that to make a decision whether the user can access that information or not.
So that is a good example situation though the fix was formed, you actually the hack and also need to review other cases where that occurred. So you need to create a new ticket to be accepted to saying hey although we solved the problem it is actually not, we didn’t fix the root cause of the problem and then add that as code references.
How to deal with teams that say they are already secure and don’t have time for security.
So, every now and then you will find a team that has a lot of power to live with the level of applications.
And it is able to push back even at the very senior levels of the company to say we don’t need these security stuff, we don’t need these threat models, we don’t need all these security tasks, all these activities that you guys are asking us to do.
Assuming that the security isn’t really in attack space reading dragged by a team that is actually trying to do the right thing and is trying to push good practices and is actually trying to add value then the way to deal with these guys is to basically call their bluff.
The way to deal with that is to basically play them at their own game and to basically say well if you don’t do that it means that you are better reproducing really high secure code, you better have no security vulnerabilities, you better have no security exploits, you better fully understand your attack surface, you better have no side effects, very clean deployments all that jazz because those are all side effects of bad security practices.
So, basically what we then need to do is to document them, make them accept all those parts of risks, and then wait for Murphy’s Law to come along and to do that.
The other thing that is very important is that you also need to challenge the assumptions. So for example if they have pen tests, make sure they understand pen tests aren’t worth unless they are full white box.
The solution is to make them click on that accept to be supported. What is important to understand is that that isn’t the moment that they will accept the risk that is the moment where they will actually read it.
So that is very interesting long term gain that you play where it is all about changing the culture, it is all about finding ways to create a positive work flow.
So, sometimes you have to be aggressive, sometimes you have to be harsh and make teams accountable, because remember this game has already been played the question is whether you control instruments over the rules of the game or not.
And the thing to understand is that most people will only actually read it, and only actually pay attention the moment they have to be accountable.
So take that into account, don’t be frustrated when you have had [inaudible 00:01:13] about a topic and then only at that moment they actually realize what you are saying, realize that everybody is very busy, everybody has parts of stuff to do so actually the fact they aren’t paying attention isn’t really bad than what you were before.
As the insurance industry matures, and there are more and more companies that will choose to insure their risks instead of actually writing secure code and fix the applications is key that those values and those insurance premiums are made public. Because, those contracts will be a great measurement of how secure a company is.
The problem is we need ways to measure company’s security. We need ways to measure what they are doing so that we reward the client, so that the entity making a purchasing decision can choose A, B, and C.
So, we can’t have a situation where the only measuring sticks are features, reputation, cost and maybe some performance. We need security to be in there, we need companies to have in a way to pay a cost for not doing security.
Now, if the customer chooses to go with a particular vendor that clearly doesn’t have application security practices, clear is not doing the right thing that is fine that is okay that is market economics at work.
But my experience is that won’t happen, my experience is these days more and more the clients are getting way more savvy. And if they can make sure the multiple products that they are consuming, then they will put pressure and in a way they will vote with their decisions which is really what you want to see happening.
And a great way this will occur is as the insurance company gets along which will push a much better validation of the issues which will bring a huge amount of rationality and data points and data analysis into what is at risk, how you can measure, how you name it, how you define it, we need to make sure that those mappings and that information is all public.
And this is something that can easily not happen, but I feel that because the industry is still immature and is so young, we can actually point it in the right direction from now on.
Reducing risk to a number, a very interesting idea given to me by a CISO friend is to reduce all of AppSec and InfoSec activities into one number, which gets presented to the board, which then can be used to measure what is the current risk profile.
In a way the number is a collation of multiple numbers which are then easy to understand and easy to map. And this actually is very tightly connected to the idea of maturity models where you use different…you measure the maturity of the multiple teams or multiple systems or multiple products and then understand better who is doing what.
What I really like about the maturity models is that it allows the temperature to be defined in the actual model, so it allows the temperature much more objective and much more pragmatic way of actually looking at the problem and looking at the issues and that is basically a really nice way of controlling the temperature and applying pressure on the right places.
And also knowing where to act because when you look at the multiple patterns and the multiple activities in the maturity model, you see which activities are working or it isn’t working or is being done or not being done and that is a great way of analyzing the organization.
In fact even the individual items of the maturity model needs sometimes maturity models because when you say you have a security champion, the whole security champion world has in a way its own maturity model where in the beginning it is the binary, do you have one or not?
Then you start to look at how effective they are, how knowledgeable they are, how actually able they are to perform their duties same thing with code reviews, same thing with path chain, same thing with management of dependencies, same thing with threat analysis, all sorts of stuff.
All of those are basically things that you should measure the maturity model eventually leading to a higher one which eventually leads to a number.
So it is quite a nice work flow to do across the enterprise, it also scales really, really well.
As the majority of the AppSec world grows up, it is very key to make very clear to business that a typical black box pen-test i.e. test of website from the outside world who know inner knowledge is at most a waste of money, at best just a check to see if a kid or a non specific attacker has a go at your application whether you will find the job or the pen-test is to find the blind spot.
In fact the job of the security assessment is to find the blind spot. Is to take everything you know about the application or their threat models or the assumptions, in fact all those ticket items that your security champs have raised as being the problem we don’t have enough evidence and then find it.
So, in a way the job of security assessment is to improve your evidence, improve your evidence of the problem, or improve your evidence of how secure you are.
Which basically means that they need to have access to everything. And also it means that you need to capture everything they do, you need to capture in a way even the tests that they do which actually don’t produce the findings they are very important because they in a way are your regression tests.
And if you can capture that it means that the pen-tests or security assessment has added a lot more value to your system.
It also means you scale more, it means that they are something that you can introduce more often because it is something that you actually get a lot of business return versus this issue that you are going throw over the fence that you do it.
So this is also very good for pen-testing teams because they can move up the food chain, they can actually be a lot more valuable to the company versus being some disposable entity and you are going to have this race to the bottom to see who can do it cheaper and who can do it in a way that looks good, doesn’t necessarily mean that it is actually good.
And as attacks become much more real, as things become much more serious, you actually want to start to have the assurance of the pen-testing, companies need to move into a world where they provide assurance, where they provide proof of what they just found.
And that is why they need to be able to provide evidence on what they performed and that is why they need to have access to everything that exists on the application.
Then once you have the findings you can make a risk based decisions whether you think your current level of attackers are actually able to discover the vulnerabilities and which is more important are able to actually perform those actions in a way they can detect.
Because if you can detect how certain vulnerabilities that you have are exploited, and you can very quickly mitigate and prevent that for the damage then that is okay, then you can argue that you can actually leave them on because it is actually not a big deal.
An interesting thread that I have been having recently with security champions is that they really need to provide evidence for the tickets they open.
So it is quite nice when you have this work flow with the security champion opening up issues and they have been pract about it. In a way the next step is to start to provide very strong evidence about it and if they can that is an issue in itself.
And a good exercise for example for hackathons or for get togethers is actually come to the table. So for the security champions to come to the table and say, “hey, I think there is a problem, I think there is an issue can we prove it?”
Because that is the key of the game, you have to build a proof, you have to be able to provide evidence for the findings you are actually opening up. And you need to basically be able to allow the person who will actually accept the risk or make a decision to really understand what is going on.
Which is why the exploits these are critical, see the power of exploits there because that is so critical, you really need to have evidence and sometimes you need an exploit to really show this is how it could happen, this is how the problem is and sometimes you do in production, sometimes you do in QA it depends on the impact. The key of all this is evidence and proof.
Once you get high degree of code coverage, a really powerful technique that you can start to use is to start to run specific suite of tests and specific slices of the application and see what gets covered and what doesn’t get covered.
It is very important especially on things like APIs where you are able to understand what actually is tabled from the outside world and now you argue that especially from an API that is maintained as exposed, you want to make sure that you have no functionality in the application that actually doesn’t exist.
And this could be a problem with some of the code coverage techniques, code coverage practices where it is easier to leave code there that doesn’t get used any more but because it is tested, it is still in the application.
Basically you want to have almost zero tolerance for code that is currently not being used, any code that instead has no code paths or not being evoked should be eliminated from the application because you really want to make sure that the app is really in sync with its current capability and expectations and extra code be maintained, be reviewed and get rid if you don’t want it there.
The problem with users having all access all the time. One legacy that we still have from our days of running everything with admin and everything with a couple of users is this lack of segmentation of user access and especially user data access and in this case it can be a database access from a real application is what we really want is a situation where whenever somebody needs a particular asset, needs a particular resource, they ask for it and then they get unit token which are given use to access the resource.
The power of this is not only it enforces some of those access more explicit, it allows you place to control abuses.
So at the moment, the reason why there are sometimes so many data leaks and data dump is because it is possible for an application to dump all the data in one go or to just keep asking for it and nobody will probably notice it.
Where if that particular application or user had to generate tones or hundreds of tones or millions of tokens to access that that will be easy to monitor.
Because this is key, you cannot generate good visualization or good understanding of what is going on at the edges because there is too much there that is not easy.
What you can do is to visualize the patterns in a way the web services call the sequence of events or specific things which then will allow you to much better understand what is going on.
So if we did that for assets and accessing assets, we would be in a much better situation to understand when abuses occur.
The key challenges of becoming a developer are understanding concepts that are intrinsic to the development work flow. And in a way I would say version controls is probably one of the most important ones. And one area that I find a huge weakness in students and IT professionals is version control where because they have a lack of development experience, they have not experienced the power of version control.
And this is something that it is hard to explain until you experience this. It is one of those things that only when you do it, you really understand the power of a particular technology. In this case, of how to manage content in a distributive way.
The power of git and the reason it has been so successful for data version controls is that it radically changes the way you think, it radically changes the way you collaborate with creating the original source code but it could be anything. In fact there is amazing case all over the world of using git to manage laws to manage all sorts of things.
So it is already spreading but in a way not fast enough. So I think how to recommend somebody who is stuck in a loop of for example managing a word document or a spreadsheet to use git as a version control system. So even if in the beginning all they are doing is using git to manage the binaries either the files itself, they will already be exposed to central repositories, pushing data, git flows, git flow or git lap flow, pull requests, merge requests, etc.
Now, eventually what you want to see is a move into native and tech space data storage. So even for example somebody has excel spreadsheet, you would want to see a move to storing the actual data points into a format that can easily be read.
And it is important because lots of things I read, I mean easily be stored in a text format that is humanly read. And the reason this is important is because diffing and versionning is key when you have a team collaborating a real challenge is not in the first review, a real challenge is the second, third, fourth, fifth reviews where you don’t want to read the whole thing again you just want to see what changed, especially when you asked for changes to be made, at that time you are just verifying that did the person that made the change understand your request and did they make the change where you expect them to be.
At that moment in time reading the whole thing doesn’t work. And the same thing happens with code changes, if you think about that technology which is basically quite successful in track changes, you can track changes to really get how that works that is great but that is also like one or two levels you need a lot more than that.
And it also doesn’t have one of the peers of git which is push it the person making the request of the change to actually clean up and really make it easy for the person that is going to read and change through the work.
So when you store the data natively, or when you store the data in a text based format, you can then store the digitization part into spreadsheet. Which the logic will be that your visualization hasn’t really changed most of the time, what will change is the data points and recapturing so again that will scale.
And then eventually what you really want to do is move into more web based again code based kind of format where instead of using excel, using another web inter phase, using a website, using some technology like D3 or Vis, .js, and in a way that is a great part of the program where you are just taking a spreadsheet and codifying it on a git repo or on a website is already a great programming task.
So I highly recommend students and info-sec practitioners who want to get to coding to start there.