2. Risk Workflow
2.1 Concepts
2.1.1 Abusing the concept of RISK
As you read this book you will notice liberal references to the concept of RISK, especially when I discuss anything that has security or quality implications.
The reason is I find that RISK is a sufficiently broad concept that can encompass issues of security or quality in a way that makes sense.
I know that there are many, more formal definitions of RISK and all its sub-categories that could be used, but it is most important that in the real world we keep things simple, and avoid a proliferation of unnecessary terms.
Fundamentally, my definition of RISK is based on the concept of ‘behaviors’ and ‘side-effects of code’ (whether intentional or not). The key is to map reality and what is possible.
RISKs can also be used in multi-dimensional analysis, where multiple paths can be analyzed, each with a specific set of RISKs (depending on the chosen implementation).
For example, every threat (or RISK) in a threat model needs to have a corresponding RISK ticket, so that it can be tracked, managed and reported.
Making it expensive to do dangerous actions
A key concept is that we must make it harder for development teams to add features that have security, privacy, and quality implications.
On the other hand, we can’t really say ‘No’ to business owners, since they are responsible for the success of any current project. Business owners have very legitimate reasons to ask for those features. Business wishes are driven by (end)user wishes, (possibly defined by the market research department and documented in a MRD (Market requirement Document). Saying no to the business means saying no to the customer. The goal, therefore, is to enable users to do what they want, with an acceptable level of risk.
By providing multiple paths (with and without additional or new RISKs) we make the implications of specific decisions very clear.
What usually happens is that initially, Path A might look easier and faster than either of Paths B or C, but, after creating a threat model, and mapping out Path A’s RISK, in many cases Path B or C might be better options due to their reduced number of RISKs.
It is important to have these discussions before any code is written and while there is still the opportunity to propose changes. I’ve been involved in many projects where the security/risk review only occurs before the project goes live, which means there is zero opportunity to make any significant architectural changes.
Release Management (RM) should be the gating factor. RM should establish quality gates based on business and security team minimum bar.
2.1.2 Accepting risk
Accepting risk is always a topic of discussion, mostly caused by lack of information. The JIRA Workflow aims to make this process more objective and pragmatic.
Risks can be accepted for a variety of reasons:
- the system containing the risk will be decommissioned in the short term, and does not handle or process sensitive information
- the risk can only occur under very specific circumstances
- the cost of fixing (both money and other resources) is much higher than the cost of fixing operational issues
- the business is okay with the probability of occurrence and its financial/commercial impact
- the system is still under development and it is not live
- the assets managed/exposed by the affected risks are not that important
- the risk represents the current state of affairs and a significant effort would be required to change it
Risks should never be accepted for issues that
- threaten the operational existence of the company (e.g. losing a banking license)
- have significant financial impact (e.g. costs, fines due to data leaks)
- have significant business impact (e.g. losing customers)
- greatly impact the company’s reputation (e.g. front page news)
Not being attacked is both a blessing and a curse. It’s a blessing for a company that has not gone through the pain of an attack, but a curse because it is easy to gain a false sense of security.
The real challenge for companies that have NOT been attacked properly, or publicly, and don’t have an institutional memory of those incidents, is to be able to quantify these risks in real business, financial, and reputational terms.
This is why exploits are so important for companies that don’t have good internal references (or case studies) on why secure applications matter.
As one staff member or manager accepts risk on behalf of his boss, and this action is replicated throughout a company, all the way to the CTO, risks are accumulated. If risks are accepted throughout the management levels of a company, then responsibility should be borne in a similar way if things go wrong. Developers should be able to ensure that it is their manager who will get fired. That manager should make sure that his boss will get fired, and so on, all the way to the CTO and the CISO.
- business owners (or who controls the development pipeline) make large number of decisions with very little side effects
- add explanation of why pollution is a much better analogy than ‘Technical Debt’ (in measuring the side effects of coding and management decisions).
- Risk is a nice way to measure this polution
- ”…you are already being played in this game, so you might as well expose the game and tilt the rules in your favour…“ *
There is a video by Host Unknown, that lays out the consequences of thoughtlessly accepting risk. It is a comic piece, but with a very serious message. (Host Unknown presents: Accepted the Risk)
2.1.3 Can’t do Security Analysis when doing Code Review
One lesson I have learned is that the mindset and the focus that you have when you do security reviews are very different than when you work on normal feature and code analysis.
This is very important because as you accelerate in the DevOps world, it means that you start to ship code much faster, which in turn means that code hits production much faster. Logically, this means that vulnerabilities also hit production much faster.
In the past, almost through inertia, you prevented major vulnerabilities from propagating into production and being exposed to production data. Now, as you accelerate, vulnerabilities, and even maliciously introduced vulnerabilities, will be exposed into production more quickly.
This means that you must have security checks in place. The problem is, implementing those security checks requires a completely different mindset than implementing code reviews.
When you do a code review, you tend to visualize a slice of a model of the application. Your focus is fixed entirely on the problem at hand, and it is hard to think outside of that.
When you implement a security review, this approach becomes counter-intuitive, because many of the security reviews that you do are about following rabbit holes, and finding black spots. Your brain is not geared for this kind of work if you are more used to working on code reviews.
It doesn’t help that we still don’t have very good tests, which don’t focus on the behavior or the side effects of the components. Instead, tests tend to focus more on specific code changes which might be a subset of the behavior changes of the code change.
You need systems that can flag when something is a problem, or needs to be reviewed. Then, with a different mindset or even different people, or different times, go through the code and ask, “What are the unintended side effects? Does this match the threat model that was created?”
In a way, the point of the threat models is to determine and confirm the expected behavior. Ultimately, in security reviews you double-check these environments.
This requires a different mindset, because now you must follow the rabbit holes, and you must ask the following questions:
a] how does data get in here? b] what happens from here? c] who consumes this? d] how much do I trust this?
You ask the STRIDE questions, where you go through proofing, tampering, information disclosure, repudiation, denial of service, and you ask those questions across the multiple layers, and across multiple components. The better the test environment, and the better the technology you have to support you, the easier this task becomes. Of course, it becomes harder, if not impossible, when you don’t have a good test environment, or good technology, because you don’t have enough visibility.
Ideally, the static analysis should significantly help the execution of a security analysis task. The problem is, they still don’t expose a lot of the internal models and they don’t view themselves as tools to help with this analysis. This is crazy when you think about their assets.
2.1.4 Creating Small Tests
When opening issues focused on quality or security best practices (for example, a security assessment or a code review), it’s better to keep them as small as possible. Ideally, these issues are placed on a separate bug-tracking project (like the Security RISK one), since they can cause problems for project managers who like to keep their bug count small.
Since this type of information only exists while AppSec developers are looking at code, if the information isn’t captured, it will be lost, either forever, or until that bug or issue becomes active. It is very important that you have a place to put all those small issues, examples, and changes.
Capturing the small issues also helps to capture the high-level and critical security issues that are made of multiple low or medium issues. Their capture also helps to visualize the patterns that occur across the organization, for example, in an issue that effects dozens of teams or products.
This approach also provides a way to measure exactly what will occur during a quality pass or sprint, for example, when focusing on cleaning and improving the quality of the application.
The smaller the issue, the smaller the commit, the smaller the tests will be. As a result, the whole process will be smoother and easier to review.
It also creates a great two-way communication system between Development and AppSec, since it provides a great place for the team to collaborate.
When a new developer joins the team, they should start with fixing bugs and creating tests for them. This can be a great way for the new team member to understand what is going on, and how the application works.
Fixing these easy tests is also a good preparation for tackling more complex development tasks.
2.1.5 Creating Abuse Cases
Developer teams tend to focus on the ‘Happy Paths’, where everything works out exactly as expected. However, in agile environments, creating evil user stories linked to a user story can be a powerful technique to convey higher level threats.
Evil user stories (Abuse cases)
Evil user stories have a dependency with threat modeling and can be an effective way of translating higher level threats and mitigations. They can be imagined as a kind of malicious Murphy’s law 3.
Take for example a login flow. After doing a threat model on this flow one should have identified the following information:
Attackers: * registered users * unregistered users
Assets: * credentials * customer information
With this information, the following threats can be constructed:
- unregistered users bypassing the login functionality
- unregistered users enumerating accounts
- unregistered users brute-forcing passwords
- registered users accessing other users’ information
At the same time the team has constructed the following user stories that should be implemented: * “as a registered user I want to be able to login with my credentials so I can access my information”
Combined with the outcome of the threat model, the following evil user stories can be constructed: * “as an unregistered user I should not be able to login without credentials, and access customer information” * “as an unregistered user I should not be able to identify existing accounts and use them to attempt to login” * “as a user I should not be able to have unlimited attempts to log in and hijack someone’s account” * “as an authenticated user I should not be able to access other users’ information”
2.1.6 Deliver PenTest reports using JIRA
Using JIRA to deliver PenTest reports is much more efficient than creating a PDF to do so. Using JIRA allows for both a quick validation of findings, and direct communication between the developers and the AppSec team.
If customized properly, there are a number of tools that can act as triage tools between PenTest results and JIRA:
- ‘defect dojo’
- ‘bag of holding’
- ThreadFix
- Other…
Threat Modeling tools could also work well between PenTest results and JIRA.
2.1.7 Email is not an Official Communication Medium
Emails are conversations, they are not official communication mediums. In companies, there is a huge amount of information and decisions that is only communicated using emails, namely:
- risks
- to-dos
- non-functional requirements
- re-factoring needs
- post-mortem analysis
This knowledge tends to only exist on an email thread or in the middle of a document. That is not good enough. Email is mostly noise, and once something goes into an email, it is often very difficult to find it again.
If information is not at the end of a link, like on a wiki page, bug-tracking system or source control solution like Git, it basically doesn’t exist.
It is especially important not to communicate security risks or quality issues in email, where it is not good enough to say to a manager, ”… by the way, here is something I am worried about…“.
You should create and send a JIRA RISK ticket to the manager.
This will allow you to track the situation, the information collected and the responses; in short, you can track exactly what is going on. This approach also gets around the problem of someone moving to other teams or companies. Their knowledge of a particular issue remains behind for someone else to use if they need to.
Emails are not a way to communicate official information; they are just a nice chat, and they should be understood as such. Important official information, in my view, should be hyperlinked.
The hyperlinkability of a piece of information is key, because once it has a hyperlinked location, you can point others to it, and a track record is created.
The way I look at it, if information is not available on the hyperlink, it doesn’t exist.
The Slack revolution
There is a Real-time messaging revolution happening, driven by tools like Slack or Matter-most, which are quickly becoming central to development and operational teams (some still use old-school tools like Basecamp, Jabber, IRC, IM or Skype).
One of the real powers of this new generation of collaboration tools is the integration with CI/CD and their ability to become the glue between teams and tools.
The problem is that all data is short-lived, and will soon disappear (there are some limited search capabilities, which are as bad as email).
Using Wikis as knowledge capture
JIRA issues can also be hard to find, especially since they tend to be focused on specific topics.
Labels, queries and reports help, but the best model is capture their knowledge by linking to them on Wikis (e.g. MediaWiki or Confluence) or document management tools (e.g. Umbraco or Sharepoint). The idea is to document lessons learned, how-to’s, and best practice.
2.1.8 Good Managers are not the Solution
When we talk about risk, workflows, business owners making decisions about development, and QA teams that don’t write tests, we often hear the comment, “If we had good managers, we wouldn’t have this problem”.
That statement implies that if you had good managers, you wouldn’t have the problem, because good managers would solve the problem. That is the wrong approach to the statement. Rather, if you had good managers, you wouldn’t have the problem, because good managers would ask the right questions before the problem even developed.
These workflows aren’t designed for when you have a good manager, a manager who pushes testing, who demands good releases, who demands releases every day, or who demands changes to be made immediately.
These workflows are designed for bad managers (I use the term reluctantly). Bad managers are not knowledgeable, or they are exclusively focused on the short-term benefits of business decisions, without taking to account the medium-term consequences of the same decisions. This goes back to the idea of pollution, where the manager says “Just ship it now, and we will deal with the pollution later”. With start-ups, sometimes managers will even say, “Push it out or we won’t have a company”.
The risk workflow, and the whole idea of making people accountable is exactly because of these kinds of situations, where poor decisions by management can cause huge problems.
We want to empower developers, the technical guys who are writing code and have a very good grasp of reality and potential side effects. They are the ones who should make technical decisions, because they are the ones who spend their time coding, and they understand what is going on.
2.1.9 Hyperlink Everything you do
Whether you are a developer or a security person, it is crucial that you link everything you do to a location where somebody can just click on a link and hit it. Make sure whatever you do is hyperlinkable.
This means that what you create is scalable, and it can be shared and found easily. It forms part of a workflow that is just about impossible if you don’t hyperlink your material.
An email is a black box, a dump of data which is a wasted opportunity because once an email is sent, it is difficult to find the information again. Yes, it is still possible to create a mess when you start to link things, connect things, and generate all sorts of data, but you are playing a better game. You are on a path that makes it much easier in the medium term for somebody to come in, click on the link, and make sure it is improved. It is a much better model.
Let others to help you.
If you share something with a link, in the future somebody can proactively find it, connect to it and do something about it. That is how you scale. Once you send enough links out to people, they learn where to look for information.
Every time I write something that is more than a couple of paragraphs long I try to include a link so that my future self, or somebody else in the future, will be able to find it and propagate that information without my active involvement.
Putting information in a public hyperlinked position encourages a culture of sharing. Making information available to a wider audience, either to the internet or internally in a company, sends the message that it is okay to share.
Sharing through hyperlinking is a powerful concept because when you send information to somebody directly it is very unlikely that you will note on each file whether it is okay to share.
But if you put data on a public, or on an internal easy-to-access, system, then you send a message to other players that it is okay to share this information more widely. Sending that link to other people has a huge impact on how that idea, or that concept, will propagate across the company and across your environment.
The thing to remember is that you are playing a long game. Your priority is not to get an immediate response, it is to change the pattern, stage the flows.
2.1.10 Linking source code to Risks
If you add links to risk as source code comments, you deploy a powerful and very useful technique with many benefits.
When you add links to the root cause location, and all the places where the risk exists, you make the risk visible. This reinforces the concept of cost (i.e. pollution) when insecure, or poor quality, code is written. Linking the source code to risk becomes a positive model when fixes delete the comments. When the comments are removed, the AppSec team is alerted to the need for a security review. Finally, tools can be built that will scan for these comments and provide a ‘risk pollution’ indicator.
- add coffee-script example from ‘Start with tests’ presentation
2.1.11 Mitigating Risk
One strategy to handle risk is to mitigate it.
Sometimes, external solutions, such as a WAF, provide a more effective solution.
If a WAF fixed the issue, and there are tests that prove it, then it is a valid fix. In this case, it is important to create a new RISK which says “Number of security vulnerabilities are currently being mitigated using a WAF. If that WAF is disabled, or if there is a WAF bypass exploit, then the vulnerabilities will become exploitable”
2.1.12 Passive aggressive strategy
Keep zooming in on the answers to refine the scope and focus of the issue.
Not finding something is a risk, and not having time to research something is a risk.
Sometimes, it is necessary to open tickets that state the obvious: * when we are not using SSL (or have an HTTP to HTTPS transition), then we should open a risk to be accepted with: “Our current SSL protection only works when the attacker we are trying to protect against (via man-in-the-middle) is not there“
2.1.13 Reducing complexity
The name of the game is to reduce the moving parts of a particular solution, its interactions, inputs, and behaviours.
Essentially, the aim is to reduce the complexity of what is being done.
2.1.14 Start with passing tests
- add content from presentation
2.1.15 Ten minute hack vs one day work
- 10m hacks vs 1 day proper coding will create more RISK tickets and source comments
- I get asked this a lot from developers
- There has to be a quantitive difference, which needs to be measured
That code sucks
- Ok can you prove it?
- Code analysers in IDE can help identify known bad patterns and provide awareness
- Why is it bad?
In new code legacy - if it also hard to refactor and change, then yes
2.1.16 The Pollution Analogy
When talking about risks, I prefer to use an pollution analogy rather than technical debt. The idea is that we measure the unintended negative consequences of creating something, which in essence is pollution.
In the past, pollution was seen an acceptable side effect of the industrial revolution. For a long time, pollution wasn’t seen as a problem in the same way that we don’t see security vulnerability as a problem today. We still don’t understand that gaping holes in our infrastructure, or in our code, are a massive problem for current and future generations.
We are still in the infancy of software security, where we are in the 1950s in terms of pollution. David Rice gave a great presentation4 where he talks about the history of pollution and how it maps perfectly with InfoSec and AppSec.
Finding a security vulnerability is questioning the entire development pipeline and quality control. How it is possible that these massive gaps, these massive security vulnerabilities and code patterns weren’t picked up before. Weren’t they understood by the development teams, by the testers, by QA, by the clients?
Even worse, can’t the current NOC and log monitoring detect those when those vulnerabilities are initially probed and ultimately exploited?
We need to make this pollution visible.
I view the proposed risk model as a way to measure that pollution, and to measure the difference between app A and app B.
One positive side of using the pollution analogy, is that security doesn’t need to say no all time. Instead of saying “You can’t do XYZ”, AppSec says “If you want to go for feature A in a specific timeline, in a specific scope with a specific brief, then you will have this residual pollution, and these unintended consequences”.
You could also have a situation where security says, “Well, if you go in ‘that’ direction, currently we don’t know what are its consequences or security site-effects, so the business owner will have to accept the risk that there is an unknown set of risks which are also not clearly understood”.
The path of using pollution as an analogy is an evolution from the current status quo. At least with it we can measure and label different apps using common metrics. But ideally we want to create a clean code that doesn’t pollute
This is analogous to the evolution of pollution.
The first phase of industrial pollution saw pollution as a necessary side effect of progress, with some fines for the worse offenders (the ‘polluter pay’ model).
The second phase established the green movement where business had to behave decently, pollute less and be rewarded by the market.
The third phase is most interesting to this analogy, because in the third phase companies started to produce things in different ways, which not only created better products, but also dramatically reduced or eliminated pollution.
This is where we want to get to in application security. We want to get to the point where we create software that is better, faster, cheaper and secure (i.e. without pollution)
2.1.17 Triage issues before developers see them
Issues identified in vulnerability scans, code analysers, and penetration tests, must be triaged by the AppSec team to prevent overloading developers with duplicate issues or false positives. Once triaged, these issues can be pushed to issue trackers, and exposed to the developers.
Unfortunately, this is still an underdeveloped part of the AppSec pipeline. Even commercial vendors’ UI don’t really support the customisation and routing of the issues they ‘discover’.
The following tools are attempting to do just that:
- Bag of Holding https://github.com/aparsons/bag-of-holding
- Defect Dojo https://github.com/OWASP/django-DefectDojo
- ThreadFix
With these triage tools, AppSec specialists can identify false positives, accepted risks, or theoretical vulnerabilities that are not relevant in the context of the system. This ensures that developers should only have to deal with the things that need fixing.
Create JIRA workflow to triage raw issues
The creation of a security JIRA workflow for the raw issues to act as a triage tool, and push them to team boards after reviewing, would be another good example of the power of JIRA for workflows.
2.1.18 Using AppSec to measure quality
- add content from presentation AppSec and Software Quality
- academic research
2.1.19 Employ Graduates to Manage JIRA
One of the challenges of the JIRA RISK workflow is managing the open issues. This can be a considerable amount of work, especially when there are 200 or more issues to deal with.
In large organizations, the number of risks opened and managed should be above 500, which is not a large quantity. In fact, visibility into existing risks starts to increase, and improve, when there are more than 500 open issues.
The solution to the challenge of managing issues isn’t to have fewer issues.
The solution is to allocate resources, for example to graduates, or recently hired staff.
These are inexpensive professionals who want to develop their careers in AppSec, or they want to get a foot in the company’s door. Employing them to manage the open issues is a win-win situation, as they will learn a great deal on the job, and they will meet a lot of key people.
By directing graduate employees or new hires to manage the open issues, developers’ time is then free to fix the issues instead of maintaining JIRA.
The maintenance of issues is critical for the JIRA RISK workflow to work, because one of its key properties is that it is always up-to-date and it behaves as a ‘source of truth’.
It is vital that risks are accepted and followed up on and that issues are never moved into the developer’s backlog where they will be lost forever.
We can’t have security RISKs in backlog; issues must either be fixed or accepted.
2.1.20 Risk Dashboards and emails
It is critical that you create a suite of management dashboards that map the existing security metrics and the status of RISK tickets:
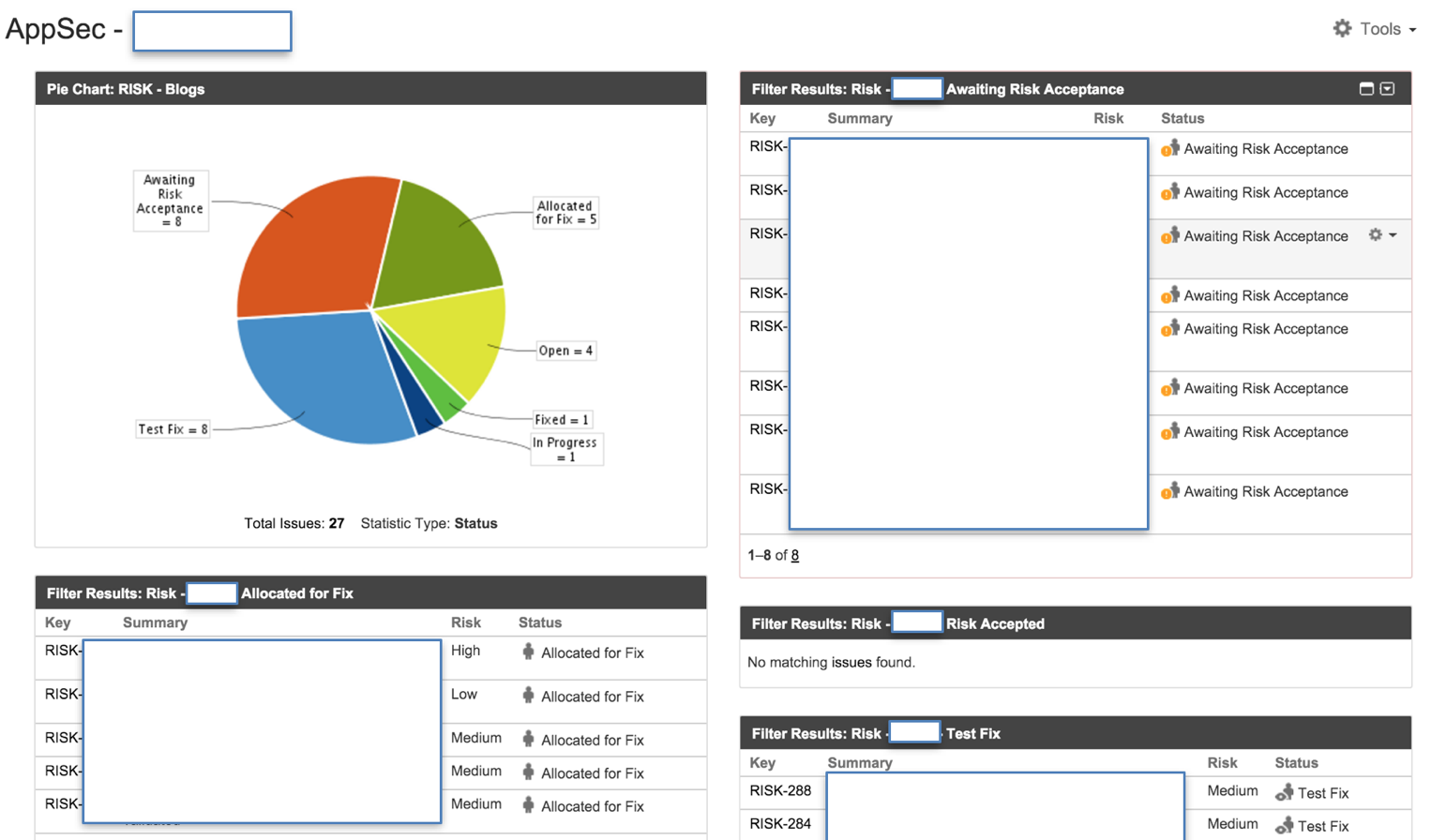
- Open, In Progress
- Awaiting Risk Acceptance, Risk Accepted
- Risk Approved, Risk not Approved, Risk Expired
- Allocated for Fix, Fixing, Test Fix
- Fixed
Visualizing this data makes it real and creates powerful dashboards. The dashboards need to be provided to all players in the software development lifecycle.
You should create a sequence of dashboards that starts with the developer (who maps the issues that he is responsible for), then his technical architect, then the business owner, the product owner … all the way to the CTO and CISO.
Each dashboard clarifies which risks they are responsible for, and the status of application security for those applications/projects.
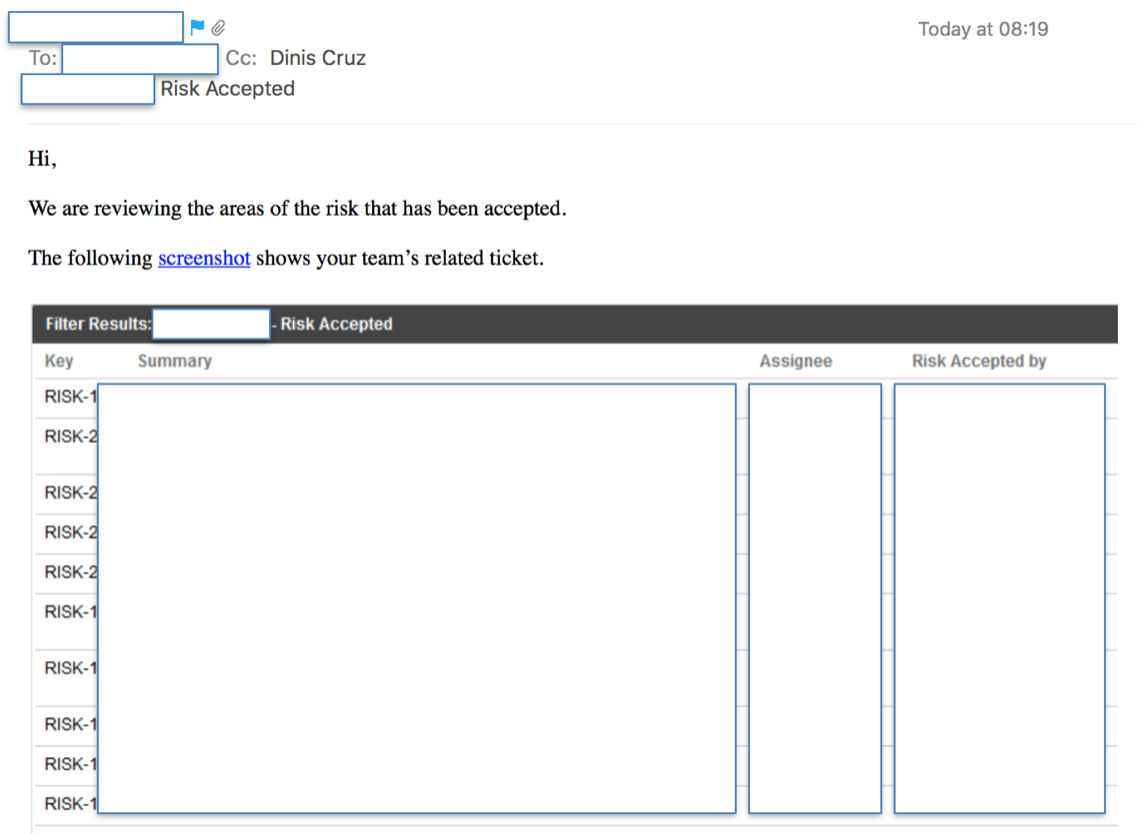
To reinforce ownership and make sure the issues/risks don’t ‘disappear’, use either the full dashboard, or specific tables/graphs, to create emails that are sent regularly to their respective owners.
The power of risk acceptance is that each layer accepts risk on behalf of the layer above. This means that the higher one is in the company structure, the more risks are allocated and accepted (all the way to the CISO and CTO).
The CISO plays a big part in this workflow, since it is his job to approve all ‘Risk Accepted’ issues (or raise exceptions that need to be approved by higher management).
This workflow drives many security activities because it motivates each player to act in his own best interests (which is to reduce the number of allocated Risk Accepted items).
The idea is to social-engineer the management layer into asking the developers to do the non-function-requirements tasks that the developers know are important, but seldom get the time to do.
2.2 For Developers
2.2.1 5000% code coverage
A big blind spot in development is the idea that 100% code coverage is ‘too much’.
100% or 99% code coverage isn’t your summit, your destination. 100% is base camp, the beginning of a journey that will allow you to do a variety of other tests and analysis.
The logic is that you use code coverage as an analysis tool, and to understand what a particular application, method, or code path is doing.
Code coverage allows you to answer code-related questions in much greater detail.
Let’s look at MVC Controller’s code coverage as an example. We must be certain that there is 100% code coverage on all exposed controllers. Usually, there are traditional ‘unit tests’ for those controllers which give the impression that we have a good coverage of their behavior. However, that level of coverage might not be good enough. You need the browser automation, or network http-based QA tests, to hit 100% of those controllers multiple times, from many different angles and with all sorts of payloads.
You need to know what happens in scenarios when only a couple of controllers are invoked in a particular sequence. You need to know how deep into the code we get, and what parts of the application are ‘touched’ by those requests or workflows.
This means that you don’t need 100% code coverage. Instead, you need 1000%, or 2000%, or even 5000% coverage. You need a huge amount of code coverage because ultimately, each method should be hit more than once, with each code-path invoked with multiple values/payloads.
In fact, the code coverage should ideally match the use cases, and every workflow that exists.
This brings us to another interesting question. If you take all client-accepted use cases which are invoked and simulated with tests, meaning that you have matched the expected ‘user contract’, (everything the user expects to happen when interacting with an application) if the coverage of the application is not at 100%, what else is there?
Maybe the executed tests only covered the happy paths?
Now let’s add the abuse and security use cases. What is the code coverage now?
If, instead of 100%, you are now at 70% coverage of a web application or a backend API, what is the rest of the code doing?
What code cannot currently be invoked using external requests? In most cases, you will find dead code or even worse, high-risk vulnerabilities that exist there, silently waiting to be invoked.
This is the key question to answer with tests: “Is there any part of the code that will not be triggered by external actions?”. We need to understand where those scenarios are, especially if we want to fix them. How can we fix something if we don’t even understand where it is, or we are unable to replicate the abuse cases?
2.2.2 Backlog Pit of Despair
In lots of development teams, especially in agile teams, the backlog has become a huge black hole of issues and features that get thrown into it and disappear. It is a mixed bag of things we might want to do in the future, so we store them in the backlog.
The job of the product backlog is to represent all the ideas that anyone in the application food chain has had about the product, the customer, and the sales team. The fact that these ideas are in the backlog means they aren’t priority tasks, but are still important enough that they are captured. Moving something into the backlog in this way, and identifying it as a future task, is a business decision.
However, you cannot use the backlog for non-functional requirements, especially the ones that have security implications. You have to have a separate project to hold and track those tickets, such as a Jira or a GitHub project.
Security issues or refactoring needs, still exist, regardless of whether the product owner wants to pursue them, whether they are a priority, or whether customers are asking for them.
Security and quality issues should either be in a fixed state, or in a risk acceptance state.
The difference is that quality and security tickets represents reality, whereas the backlog represents the ideas that could be developed in the future. That is why they have very different properties, and why you shouldn’t have quality and security tickets in the backlog Pit of Despair 5.
2.2.3 Developer Teams Need Budgets
Business needs to trust developer teams.
Business needs to trust that developers want to do their best for their projects, and for their company.
If business doesn’t learn to trust its developer teams, problems will emerge, productivity will be affected and quality/security will suffer.
A great way to show trust is to give the developer team a budget, and with it the power to spend money on things that will benefit the team.
This could include perks for developers such as conference attendance, buying books, or buying things which are normally a struggle to obtain. It is often the case that companies will purchase items for a team when requested, but first the team must struggle to overcome the company’s apathy to investing in the developer team. The balance of power never lies with the team, and that imbalance makes it hard to ask for items to be purchased. Inconsistencies are also a problem: sometimes it can be easier to ask for £5,000, or for £50,000, than it is to ask for £50 .
Companies need to treat developer teams as the adults they are, and they need to trust them. My experience in all aspects of organizations is that it is difficult to spend money.
When you spend money, especially in an open-ended way, your expenditure is recorded and it becomes official. If your investment doesn’t yield good results for the company, you will be held accountable.
Therefore, allocating a budget to the developer teams will keep the teams honest, and will direct their focus to productive investments. Purchases could range from buying some tools for the developers, to buying a trip, or even to outsourcing some work to a freelancer.
Spending on the operational expenses for the team will yield benefits both to developer teams and to business.
2.2.4 Developers should be able to fire their managers
Many problems developer teams deal with arise from the inverted power structure of their working environment. The idea persists that the person managing the developers is the one who is ultimately in charge, responsible, and accountable.
That idea is wrong, because sometimes the person best-equipped to make the key technological decisions, and the difficult decisions, is the developer, who works hands-on, writing and reading the code to make sure that everything is correct.
A benefit of the ‘Accept Risk’ workflow, is that it pushes the responsibility to the ones that really matter. I’ve seen cases when upper-layers of management realise that they are not the ones that should be accepting that particular risk, since they are not the ones deciding on it. In theses cases usualy the decision comes down to the developers, who should use the opportunity to gain a bigger mandate to make the best decisions for the project.
Sometimes, a perverse situation occurs where the managers are no longer coding. They may have been promoted in the past because they used to be great programmers, or for other reasons, but now they are out of touch with programming and they no longer understand how it works.
Their job is to make the developers more productive. They work in customer liaison, they manage the team and its results, they organise, review, handle business requirements and expectations, and make sure everything runs smoothly. That is the job of the manager, and that manager also acts as the voice of the developer team.
This situation promotes inefficiencies and makes the managers more difficult to work with. They don’t want to share information, but they do want to take ownership of developers’ work or ideas that they didn’t have themselves. This environment gets very political very fast, and productivity is effected.
The manager I describe above should ideally be defending the developer team, and should act like an agent for that team. Logically, a developer, or a group of developers, should therefore have the power to nominate, appoint, and sack the manager if necessary.
The developers should hold the balance of power.
Developers should also be able to take decisions on pay, perks, and budgets. Business should treat the developer teams as the grownups they are, because the developer teams are ultimately accountable for what is created within the company.
2.2.5 Every Bug is an Opportunity
The power of having a very high degree of code coverage (97%+) is that you have a system where making changes is easy.
The tests are easy to fix, and you don’t have an asymmetric code fixing problem, where a small change of code gives you a nightmare of test changes, or vice versa.
Instead, you get a very interesting flow where every bug, every security issue, or every code change is an opportunity to check the validity of your tests. Every time you make a code change, you want the tests to break. In fact you should worry if the tests don’t break when you make code changes.
You should also worry if the tests break at a different location than expected. This means that the change you made is not having the desired effect. Either your tests are wrong, or you don’t have the right coverage, because you expected the test to break in one location but it broke somewhere else, maybe even on a completely different test that happened to pass that particular path.
To enforce the quality of your test, especially when you have a high degree of coverage, use every single bug fix, and every single code change as opportunities to confirm that your tests are still effective.
Every code change gives the opportunity to make sure that the understanding of what should change is what did change. Every bug allows you to ask the questions, “Can I replicate this bug? Can I correctly identify all that is needed to replicate the creation, or the expectation of this bug?”
2.2.6 Every project starts with 100% code coverage
Every application starts with 100% code coverage because by definition, when you start coding, you cover all the code.
You must ensure that you have a very high degree of code coverage right from the beginning. Because if you don’t, as you add code, it is easier to let code coverage slip, and then you realise that large chunks of your code base are not tested (any code that is changed without being tested, is just a random change).
Reasons why code coverage slips:
- code changes are not executed using tests
- code coverage is not being used as a debug tool
- code coverage is not shown in the IDE in real-time
- demo or go-live deadline
- mocks and interfaces are used to isolate changes (ironic side effect)
- certain parts of the application are hard to test
- weak testing technology and workflows
- tests are written by separate teams (for example separate dev and QA teams)
- lack of experience by developers, testers and management on the value and power of 100% code coverage
All of these are symptoms of insecure development practices, and will have negative side effects in the medium term.
It is very important to get back to 100% code coverage as soon as possible. This usually will require significant efforts in improving the testing technology, which is usually where the problems start (i.e. lack of management support for this effort)
Some of unmanaged languages, or even managed languages (like Java with the way exceptions are handled), have difficulties in measuring certain code paths. There is nothing wrong in changing coding patterns or conventions to improve an tool’s capabilities, in this case the code coverage technology’s ability to detect code execution paths.
It is very important that the development team has the discipline and habit of always keeping the application on 100% code coverage. Having the right tools and worlflows will make a massive difference (for example Wallaby for Javascript or NCunch for .NET)
For the teams that are really heavy into visualisation and measuring everything, it is very powerful to use dashboards like the ones created by Kibana to track code coverage in real-time (i.e. see test’s execution as they occur in multiple target environments: dev, qa, pre-prod and prod).
2.2.7 Feedback Loops
The key to DevOps is feedback loops. The most effective and powerful DevOps environments are environments where feedback loops, monitoring, and visualizations are not second-class citizens. The faster you release, the more you need to understand what is happening.
DevOps is not a silver bullet, and in fact anyone saying so is not to be trusted. DevOps are a profound transformation of how you build and develop software.
DevOps are all about small interactions, small development cycles, and making sure that you never make big changes at any given moment. The feedback loop is crucial to this because it enhances your understanding and allows you to react to situations very quickly.
The only way you can react quickly is if you have programmatically codified your infrastructure, your deployment, and your tests. What you want is automation of your understanding, and of your tests. The feedback loops you get make this possible.
The success stories of DevOps are all about the companies who moved from waterfall style, top-down development, to a more agile way of doing things. The success of DevOps has also allowed teams that were agile but weren’t working very well, to ship faster.
I like the idea of pushing as fast as possible to production. It is essential to have the two pipelines I mention elsewhere in the book, where, if you codify with specific patterns that you know, you go as fast as possible. If you add changes that introduce new patterns or change the attack surface, you must have a separate pipeline that triggers manual or automated reviews.
The feedback loops allow you to understand this. The feedback loops allow you to understand how to modify your attack surface, how to change how your application behaves, and how to change key parts of how everything works.
2.2.8 Make managers accountable
Managers need to be held accountable for the decisions they make, especially when those decisions have implications for quality and security. There are several benefits to increased accountability. Organisations will be encouraged to accept risk, and, before they click on the ‘Accept Risk’ button, managers will be compelled to ‘read’ the ticket information. However, the introduction and development of a more accountable management structure is a long game, to be played out over many months, or even years. Sometimes, it requires a change in management to create the right dynamic environment.
Usually, a new manager will not be too enthusiastic when he sees the risks that are currently accepted by a business and are now his responsibility. He knows he has a limited window, of a few months perhaps, where he can blame his predecessor for any problems. After that time has passed, he ‘owns’ the risk, and has accepted it himself.
This workflow creates historical records of decisions, which supports and reinforces a culture of accountability.
In agile environments, the Product Owner is responsible for making the right decisions.
2.2.9 Risk lifecycle
Here are the multiple stages of Risks:
1 digraph {
2 size ="3.4"
3 node [shape=underline]
4
5 "Risk" -> "Test (reprod\
6 uces issue)" [label = "write test"]
7 "Test (reproduces issue)" -> "Risk Accept\
8 ed" [label = "accepts risk"]
9 "Test (reproduces issue)" -> "Fixing" \
10 [label = "allocated for fix"] \
11
12 "Test (reproduces issue)" -> "Regression \
13 Tests" [label = "fixed"]
14 }
It is key that a test that replicates the issue reported is created.
The tests result for each of the bottom layers mean different things:
- Risk Accepted : Issues that will NOT be fixed and represent the current accepted Risk profile of the target application or company
- Fixing: Issues that are currently being actively addressed (still real Risks)
- Regression Tests: Past issues that are now being tested to confirm that they no longer exist. Some of these tests should run against production.
2.2.10 Risk profile of Frameworks
Many frameworks work as a wrapper around a ‘raw’ language and have built in mechanisms to prevent vulnerabilities.
Examples are:
- Rails for Ruby
- Django for Python
- AngularJS, Ember, ReactJS for javascript
- Razor for .Net
Using these frameworks can help less experienced developers and act as a ‘secure by default’ mechanism.
This means that when using the ‘secure defaults’ of these frameworks, there will be less Risk tickets created. Ideally Frameworks will make it really easy to write secure code, and really hard (and visible) to write dangerous/insecure code (for example how AngularJS handles raw HTML injection from controllers to views).
This can backfire when Frameworks perform complex and dangerous operations ‘automagically’. In those cases it is common for the developers to not really understand what is going on under the hood, and high risk vulnerabilities will be created (sometimes even using the code based on the Framework’s own code samples)
- Add case-studies on issues created by ‘normal’ framework usage:
- SpringMVC Auto-Binding (also called over-posting)
- Razor controls vulnerable to XSS on un-expected locations (like label)
- Ember SafeHtml
- OpenAM SQL Query Injection on code sample (and see in live app)
- Android query SQL Injection (on some parameters)
2.2.11 Security makes you a Better Developer
When you look at the development world from a security angle, you learn very quickly that you need to look deeper than a developer normally does. You need to understand how things occur, how the black magic works, and how things happen ‘under the hood’. This makes you a better developer.
Studying in detail allows you to learn in an accelerated way. In a way, your brain does not learn well when it observes behavior, but not cause. If you are only dealing with behavior, you don’t learn why something is happening, or the root causes of certain choices that were made in the app or the framework.
Security requires and encourages you to look deeper, to find ways to learn the technology, to understand how the technology works, and how to test it. I have a very strong testing background because I spend so much time trying to replicate things, to make things work, to connect A to B, and to manipulate data between A and B.
What interests me is that when I return to a development environment, I realize that I have a bigger bag of tricks at my disposal. I always find that I have greater breadth, and depth, of understanding of technology than a lot of developers.
I might not be the best developer at some algorithms, but I often have a better toolkit and a more creative way of solving problems than more intelligent and more creative developers. The nature of their work means that their frames of reference are narrower.
Referencing is important in programming because often, once you know something is possible, you can easily carry out the task. But when you don’t know if something is possible, you must consider how you investigate the possibilities, how long your research will take, and how long it might be before you know if something will succeed or not. Whereas, if you know something is possible, you know that it is X hours away and you can see its evolution, or if it is a lost cause.
Having those references makes a big difference because when you look at a problem it is important to know which rabbit holes you can follow and which ways will create good and sound solutions and which ones don’t. This is especially important when we talk about testing the app: there tends to be a lot of interesting lateral thinking and creative thinking required to come up with innovative solutions to test specific things.
My argument is that when you do application security, you become a better developer. Your toolkit expands, your mind opens, and you learn a lot. In the last few months alone, I had to learn and review different languages and frameworks such as Golang, Spark, Camel, Objective C, Swift and OpenIDM.
After a while learning new systems becomes easier, and the ability to make connections makes you a better developer because you are more skilled at observing concepts and technologies.
2.2.12 Test lifecycle
- explain test flow from replicating the bug all the way to regression tests
1 digraph {
2 size ="3.4"
3 node [shape=box]
4 "Bug"-> "Test Reproduces Bug"
5 -> "Root cause analysis"
6 -> "Fix"
7 -> "Test is now Regression test"
8 -> "Release"
9 }
2.2.13 The Authentication micro-service cache incident
A good example of why we need tests across the board, not just normal unit tests, but integration tests, and tests that are spawned as wide as possible, is the story of a authentication module that was developed as an re-factoring into a separate micro-service.
When the module was developed, it contained a high degree of code coverage, in fact it had 100% unit test coverage. The problems arose when it went live, and several issues occurred. One of the original issues occurred because the new system was designed to improve the way the database or the passwords were stored. This meant that once it was fully deployed some of existing dependent services stopped working.
For example, one of the web services used by customer service stopped working. Suddenly, they couldn’t reset passwords, and the APIs were no longer available. Because end-to-end integration tests weren’t carried out when the website started, some of the customer service failed, which had real business impact.
But the worst-case example occurred when a proxy was used in one of the systems, and the proxy cached the answer from the authentication service. In that website, anybody could log in with any password because the cache was caching the ‘yes you are logged in’.
This illustrates the kind of resilience you want these authentication systems to have. You want a situation where, when you connect to a web service, you don’t just get, for example, a 200 which means okay, you should get the equivalent of an cross-site-request-forgery token. Ideally you would get an transaction token in the response received, i.e. “authentication is ok for this XYZ transaction, this user and here is an user object with user details”.
(todo: add example of 2fA exploit using Url Injection)
When you make a call to a web service and ask for a decision, and the only response you get is yes or no, this is quite dangerous. You should get a lot more information.
The fundamental problem here is the lack of proper end-to-end testing. It is a QA and development problem. It is the fact that in this environment you cannot spin off the multiple components. If you want to test the end-to-end user log in a journey, you should be able to spin off every single system that uses that functionality at any given time (which is what DevOps should also be providing).
If that had been done from the moment the authentication module was available, these problems would have been identified months in advance, and several incidents, security problems, and security vulnerabilities would have been prevented from occurring.
2.2.14 Using Git as a Backup Strategy
When you code, you inevitably go on different tangents. Git allows you to keep track of all those tangents, and it allows you to record and save your progress.
In the past, we used to code for long periods of time and commit everything at the end. The problem with this approach is that sometimes you follow a path to which you might want to return, or you might follow a path that turns out to be inefficient. If you commit both early and often, you can keep track of all such changes. This is a more efficient way of programming.
Of course, before you make the final commit, and before you send the push to the main repository, you should clean up and ensure the code has a certain degree of quality and testing.
I find that every time I code, even for a short while, my instinct is to write a commit, and keep track of my work. Even if I add only a part of the code, or use the staging capabilities to do some selective commits, I find that Git gives me a much cleaner workflow. I can be confident in my changes from start to end, and I rarely lose any code or any snippet with which I was happy.
2.2.15 Creating better briefs
Developers should use the JIRA workflow to get better briefs and project plans from management. Threat Models are also a key part of this strategy.
Developers seldom find the time to fulfil the non-functional requirements of their briefs. The JIRA workflow gives developers this time.
The JIRA workflow can help developers to solve many problems they have in their own development workflow (and SDL).
2.3 For management
2.3.1 Annual Reports should contain a section on InfoSec
Annual reports should include sections on InfoSec and AppSec, which should list their respective activities, and provide very detailed information on what is going on.
Most companies have Intel dashboards of vulnerabilities, which measure and map risk within the company. Companies should publish that data, because only when it is visible can you make the market work and reward companies. Obliging companies to publish security data will make them understand the need to invest, and the consequences of the pollution that happens when you have rented projects with crazy deadlines and inadequate resources, but somehow manage to deliver.
The ability to deliver in such chaotic circumstances is often due to the heroic efforts of developers, who work extremely hard to deliver high quality projects, but get rewarded only by being pushed even more by management. This results in extraordinary vulnerabilities and risks being created and bought by the company. Of course, the company doesn’t realize this until the vulnerabilities are exploited.
In agile environments, it’s important to provide relative numbers such as:
- Risk issues vs velocity
- Risk issues vs story points
By analyzing these numbers over time, the tipping point, where quality and security are no longer in focus, can become painfully clear.
2.3.2 Cloud Security
One way in which cloud security differs from previous generations of security efforts, such as software security and website security, is that in the past, both software and website security were almost business disablers. The more features and the more security people added, the less attractive the product became. There are very few applications and websites that make the client need more security to do more business, which results in the best return on investment.
What’s interesting about cloud security is that it might be one of the occasions where security is a business requirement, because a lack of security would slow down the adoption rate and prevent people from moving into the cloud. Accordingly, people care about cloud security, and they invest in it.
While thinking about this I realized that the problem with security vulnerabilities in the cloud is that any compromise doesn’t just affect one company, it affects all the companies hosted in the cloud. It’s a much bigger problem than the traditional scenario, where security incidents resulted in one company being affected, and the people in that company worked to resolve the problem. When an incident happens in the cloud, the companies or assets affected are not under the control of their owners. The people hosting them must now manage all these external parties, who don’t have any control over their data, but who can’t work because their service is down or compromised. The problem is horizontal; a Company A-driven attack will affect Companies B, C, D, E, F, all the way to X, Y, Z. As a result, it’s a much tougher problem to solve.
While catastrophic failures are tolerated in normal websites and applications, cloud-based worlds are much less tolerant. A catastrophic failure, where everything fails or all the data is compromised or removed, means the potential loss of that business. That hasn’t happened yet, but doubtless it will happen. Cloud service companies will then have to show that they care more about security than the people who own the data.
Cloud providers care more than you
One of the concepts that Bruce Schneier talked about at the OWASP IBWAS conference in Spain is that a cloud service cares more about the security of their customers than the customer does. This makes sense since their risk is enormous.
In the future, cloud companies will be required to demonstrate this important concept. They should be able to say, “Look, I have better systems in place than you, so you can trust me with your data. I can manage more data for you than you can”. This will be akin to the regulatory compliance that handles data in the outside world.
One way to do this is with publishing of RISK data and dashboards (see OWASP Security Labelling System Project).
You can imagine a credit card company wanting or needing to demonstrate this. But you can also see the value of it to the medical industry, or any kind of industry that holds personal information. If a company can’t provide this type of service it must outsource the service, but to be able to do that the security industry must become more transparent. We need a lot more maturity in our industry, because companies need to show that they have adequate security controls. It is not sufficient to be declared compliant by somebody who goes for the lowest common denominator, gets paid, and tells the company it’s compliant.
Genuinely enhanced visibility of what’s going on will allow people to measure what’s happening, and then make decisions based on that information. The proof of the pudding will not be how many vulnerabilities the cloud companies have, but how they recover from incidents.
The better a company can sustain an attack, the better that company can protect data. A company who says, “I received x, y, z number of attacks and I was able to sustain them and protect them this way” is more trustworthy than the company that is completely opaque. The key to making this work is to create either technology, or standards of process, that increase the visibility of what is going on.
2.3.3 Code Confidence Index
Most teams don’t have confidence in their own code, in the code that they use, in the third parties, or the soup of dependencies that they have on the application. This is a problem, because the less confidence you have in your code, the less likely you are to want to make changes to that code. The more you hesitate to touch it, the slower your changes, your re-factoring, and your securing of the code will be.
To address this issue, we need to find ways to measure the confidence of code, in a kind of Code Confidence Index (COI).
If we can identify the factors that allow us to measure code confidence, we would be able to see which teams are confident in their own or other code, and which teams aren’t.
Ultimately, the logic should be that the teams with high levels of Code Confidence are the teams who make will be making better software. Their re-factoring is better, and they ship faster.
2.3.4 Feedback loops are key
A common error occurs when the root cause of newly discovered issues or exploits receives insufficient energy and attention from the right people.
Initially, operational monitoring or incident response teams identify new incidents. They send the incidents are to the security department, and after some analysis the development teams receive them as tickets. The development teams receive no information about the original incident, and are therefore unable to frame the request in the right perspective. This can lead to suboptimal fixes with undesired side effects.
It is beneficial to include development teams in the root cause analysis from the start, to ensure the best solutions can be identified.
2.3.5 Getting Assurance and Trust from Application Security Tests
When you write an application security test, you ask a question. Sometimes the tests you do don’t work, but the tests that fail are as important as the tests that succeed. Firstly, they tell you that something isn’t there today so you can check it for the future. Secondly, they tell you the coverage of what you do.
These tests must pass, because they confirm that something is impossible. If you do a SQL injection test, in a particular page or field, or if you do an authorization test, and it doesn’t work, you must capture that.
If you try something, and a particular vulnerability or exploit isn’t working, the fact that it doesn’t work is a feature. The fact that it isn’t exploitable today is something that you want to keep testing. Your test confirms that you are not vulnerable to that and that is a powerful piece of information.
You should have tests for both the things you know are problems, and the things you know are not problems. Such tests give you confidence that you have tested your application for certain things.
Be sure that you have enough coverage of those tests. You also want to relate this to code coverage and to functionality, because you want to make sure that there is direct alignment between what is possible on the application and what is invoked by the test they should match.
The objective is to have much a stronger assurance of what is happening in the application, and to detect future vulnerabilities (created in locations that were not vulnerable at the time of the last security assessment).
2.3.6 I don’t know the security status of a website
Lack of data should affect decision-making about application security.
Recently, I looked at a very interesting company that provides VISA compatible debit-card for kids, which allows kids to get a card whose budget can be controlled online by their parents. There is even a way to invest in the company online via a crowdfunding scheme.
I looked at this company as a knowledgeable person, able to process security information and highly technical information about the application security of any web service. But I was not able to make any informed security decision about whether this service is safe for my kids. I couldn’t understand the company’s level of security because they don’t have to publish it and, therefore, I don’t have access to that data.
As a result, I must take everything on the company’s website at face value. And because there is no requirement to publish any real information about their product, the information given is shaped by the company’s marketing strategy. I have no objective way of measuring whether the company has good security across their SDL, has good SecDevOps capabilities, if are there are any known security risks I should be aware, or more importantly, if my kids’ data is protected and secure.
This means that my friends who recommended that service to me are even worse off than I am. They are not security savvy users and they can only rely on the limited information given on the company’s website.
If there are three or four competing services at any moment in time, they will not be able to compete on the security of their product. It is not good enough if a company only invests in security in case security becomes a problem, or causes embarrassment in the future. It is like saying, “Oh, let’s not pollute our environment because we might get caught”.
In business today, security issues are directly related to quality issues. Application security could be used to gain a good understanding of what is going on in the company, and whether it is a good company to invest in, or a good company to use as a consumer.
This approach could scale. If I found problems, or if data was open, I could publish my analysis, others could consume it, and this would result in a much more peer-reviewed workflow for companies.
This reflects my first point: if I can’t understand a company’s level of security because they don’t have to publish it, this should change. And if it does, it will change the market.
Having a responsible disclosure program or public bug bounty program is also a strong indicator of quality and security.
In fact, a company that doesn’t have a public bug bounty program is telling the world that they don’t have an AppSec team.
2.3.7 Inaction is a risk
Lacking the time to perform ‘root cause analysis’, or not understanding what caused a problem, are valid risks in themselves.
It is key that these risk are accepted
This is what makes them ‘real’, and what will motivate the business owner to allocate resources in the future. Specially when a similar problem occur.
2.3.8 Insurance Driven Security
- insurance companies are starting to operate in the AppSec work
- they will need objective way to measure RISK
- workflows like this one could provide that
2.3.9 Is the Decision Hyperlinked?
I regularly hear the following statements: “The manager knows about it”, “I told you about this in the meeting”, “Everyone is aware of this”, and so on. However, if a decision is not in a hyperlinkable location, then the decision doesn’t exist. It is vital that you capture decisions, because without a very clear track of them, you cannot learn from experience.
Capturing decisions is most important for the longer term. When you deal with your second and third situations, you start building the credibility to say, “We did this in the past, it didn’t work then, and here are the consequences. Here is the real cost of that particular decision, so let’s not repeat this mistake”.
It is essential to do postmortems and understand the real cost of decisions. If a comment is made along the lines of, “Oh, we don’t have time to do this now because we have a deadline”, after a huge amount of manpower and time has been spent fixing the problem, you need to be able to say, “Was that decision the correct one? Let’s now learn from that, and really quantify what we are talking about”.
Completing this exercise will give you the knowledge to say the next time, “We need a week, or two weeks, or a month to do this”. Or you could say, “Last time we didn’t do this and we lost six months”. So, it is key not only to capture the decisions, but also to ensure you do a very good postmortem analysis of what happens after risks are accepted.
When there are negative consequences because of a bad decision, such as security issues or problems of technical debt, it is important that the consequences are hyperlinked back to the original issue for future reference.
In a way, the original issues are the foundations of the business case for why a problem occurred, and why you don’t want to repeat the problem in the future.
2.3.10 Measuring companies’ AppSec
Reviewing a company’s technology allows us to understand its future. As more and more companies depend on their technology, and as more investment is directly connected to software developed by companies, there is a need for companies to provide independent analysis of their technology stacks.
Typically, this is something an analyst does, where they should be measuring both the maturity of the company’s software development, and the maturity of its environment. The analyst should use public information to compile their evidence, and they should then use this evidence to support their data. Having good evidence means having explicit data on the record which clearly supports the analysis.
The power of the analyst is that they can take the time, and have the ability to create peer-reviewed, easy-to-measure, easy-to-understand analysis of companies.
Let’s look at investments, as it is now easier and easier for people to invest in companies. If your idea is to invest in technology at the earliest stages of a company’s growth, you want to be really sure it is going in the right direction. You should be able to get good metrics of what is going on, and you need a good understanding of what is happening inside these companies. Questions to ask include the following:
- Are they using an old technology stack?
- How much are they really investing in it?
- How much are they really busking the whole thing? (because you know that is something that can easily happen, where marketing paints a very different rosy picture of reality)
- Are they having have scalability problems caused by past architectural decisions?
- Are they able to refactor the code and keep it clean/lean and focused on the target domain models?
If you have a company which is growing very fast, it makes a massive difference if the company is on a scalable platform or not.
In the past, companies could afford to let their site ‘blow up’ and then address problems after they occurred. That is no longer possible, due to the side effects, and particularly the security side effects, of any crashes or instability. Today, the more successful a company becomes, the more attackers will focus on it. If there are serious security vulnerabilities, they will be exploited faster than the company can address them, and this will affect real users and real money. We can see this happening with cars and the IoT (Internet of Things).
There is still a huge amount of cost in moving away from products/technologies, which is I call the ‘lock-in index’, and is whatever ‘locks’ the customer to the software.
The idea is that investors and users should have a good measure of how ‘locked-in’ a company is, and the technological quality of the application/service they are about to invest into.
2.3.11 OWASP Top 10 Risk methodology
- add details about Risk methodology that in included with the OWASP Top 10
- mention other Risks methodologies
- applying OWASP ASVS allows for a more risk based approach
- OwaspSAMM and BSIMM can measure the maturity level of an organisation
2.3.12 Relationship with existing standards
It is important have a good understanding of how a company’s Risk profile maps to existing security standards alike PCI DSS, HIPAA, and others.
Most companies will fail these standards when their existing ‘real’ RISKs are correctly identified and mapped. This explains the difference between being ‘compliant’ and being ‘secure’.
Increasingly, external regulatory bodies and laws require some level of proof that companies are implementing security controls.
To prevent unnecessary delays or fines, these requirements should be embedded in the process in the form of regular scans, embedded controls (e.g. in the default infrastructure), or in user stories.
For example, in DevOps environments all requirements related to OS hardening should be present in the default container. Development teams should not have to think about them.
2.3.13 Responsible disclosure
Having a responsible disclosure process and/or participating in programs like HackerOne or Bugcrowd have several advantages:
- it shows a level of confidence to the customers
- it provides additional testing cycles
- it sends a message that they have an AppSec program
2.3.13.1 JIRA workflow for bug bounty’s submissions
- add diagram (from XYZ)
- real world example of using an JIRA workflow to manage submissions received
2.3.13.2 Bug bounties can backfire
http://www.forbes.com/sites/thomasbrewster/2016/07/13/fiat-chrysler-small-bug-bounty-for-hackers/#58cc01f4606f
2.3.14 Third party components and outsourcing
- these dependencies need to be managed
- lots of control lost to 3rd parties
- open source and close source are very similar
- at least with open source there is the chance to look at the code (doesn’t mean that somebody will)
- companies need developers that are core contributors of FOSS
- outsource code tends to have lots of ‘pollution’ and RISKs that are not mapped (until it is too late)
- liability and accountability of issues is a big problem
- see OWASP Legal project for an idea of AppSec clauses to include in outsourcing contracts.
- copyright infringes will become more of a problem in the future; this can be hard to identify in 3rd party components
2.3.14.1 Tools to help manage dependencies
- OWASP Dependency checker can identify vulnerable components in use
- several commercial tools exist that can identify copyright infringements in components
- Veracode has it
- Sourceclear
- Sonar (check which version)
- nsp node security
- … add more (see 13 tools for checking the security risk of open-source dependencies)
2.3.15 Understand Every Project’s Risks
It is essential that every developer and manager know what risk game they are playing. To fully know the risks, you must learn the answers to the following questions:
- what is the worst-case scenario for the application?
- what are you defending, and from whom?
- what is your incident response plan?
Always take advantage of cases when you are not under attack, and you have some time to address these issues.
2.3.16 Using logs to detect risks exploitation
Are your logs and dashboards good enough to tell you what is going on? You should know when new and existing vulnerabilities are discovered or exploited. However, this is a difficult problem that requires serious resources and technology.
It is crucial that you can at least detect known risks without difficulty. Being able to detect known risks is one reason to create a suite of tests that can run against live servers. Not only will those tests confirm the status of those issues across the multiple environment, they will provide the NOC (Network Operations Centre) with case studies of what they should be detecting.
2.3.16.1 Beware of the security myth
Often, no special software or expertise is needed to identify basic, potential, bad behavior. Usually, companies already have all the tools and technology they need in-house. The problem is making those tools work in the company’s reality. For example, if someone accesses 20 non-existing pages per second for several minutes, it is most likely they are brute-forcing the application. You can easily identify this by monitoring for 404 and 403 errors per IP address over time.
2.3.17 Using Tests to Communicate
Teams should talk to each other using tests. Teams usually have real problems communicating efficiently with each other. You might find an email, a half-baked bug-tracking issue opened, a few paragraphs, a screen shot, and if you are lucky, a recorded screencast movie.
This is a horrible way to communicate. The information isn’t reusable, the context isn’t immediately clear, you can’t scale, you can’t expand on the topic, and you can’t run it automatically to know if the problem is still there or not. This is a highly inefficient way to communicate.
The best way for teams to communicate is by using Tests.
Both within and across teams; top-down and bottom-up, from managers and testers to teams.
Tests should become the lingua franca of companies. Their main means of communication.
This has tremendous advantages, since in order for it to work, it requires really very good test APIs, and very good execution environments.
One must have an easy-to-develop, easy-to-install, and easy-to-access development environment in place, something that very rarely occurs.
By making tests the principal way teams communicate, you create an environment that not only rewards good APIs, it rewards good solutions for testing the application. Another advantage is that you can measure how many tests have been written across teams and you can review the quality of the tests.
Not only is this a major advantage to a company, it is also a spectacular way to review changes. If you send a test that says, “Hey! I would like XYZ to occur”, or “Here is a problem”, then the best way to review the quality of the change is to review the test that was modified in order to solve the problem.
In this scenario, you have a test that reflects the fixed state of a behaviour, and you have a test that communicates the changes you want to make. A review of both tests is often the best way to evaluate if the requested changes have been made and are working as desired.
2.3.18 Who is actually making decisions?
One of the interesting situations that occurs when we play the risk acceptance game at large organisations, is how we are able to find out exactly who is making business and technical decisions.
Initially, when a ‘Risk Accepted’ request is made, what tends to happen is that the risk is pushed up the management chain, where each player pushes to their boss to accept risk. After all, what is at stake is who will take responsibility for that risk, and in some cases, who might be fired for it.
Eventually there is a moment when a senior director (or even the CTO) resists accepting the risk and pushes it down. What he is saying at that moment in time, is that the decision to accept that particular risk, has to be made by someone else, who has been delegated (officially or implicitly) that responsibility.
In some cases this can now go all the way down to the actual developer/team doing the coding. Paradoxically, usually the developer didn’t realise until that moment, that he is one that is actually deciding how and when to fix it (or not).
Developers often hold a huge amount of power, but they just don’t know it.
Playing the risk acceptance game, and identifying who is deciding on risk, is a way of empowering the actual decision-maker. Once the person realises their role and power, they can make sure they have realistic time-scales to fix the issue accordingly, and when required, make the case for more time, more resources, or even a more defined role as a decision-maker.
This exercise is very important because, until you discover who clicks on the ‘Accept Risk’ button, there is little knowledge about who (if anybody at all) is making important decisions.
Risk issues can only be on one of two moving paths: ‘Fixing path’ and ‘Risk Acceptance path’. Since deciding not to act on a particular issue is a decision in itself, the Risk workflow makes sure that issues don’t ‘disappear’ in informal conversions, emails or documents.
This is also a good example why Pollution is a better analogy than Technical Debt. Features that are pushed with un-realistic deadlines or bad briefs will create a higher number of Risk tickets (i.e. pollution) which will have to be accepted by the business owners (who agreed on the development brief and time-scales)
2.4 For security Teams
2.4.1 Defensible findings
A big lesson I have learned from my consulting work is that every time you present evidence of a security issue or a vulnerability, you must have highly defensible findings.
So, I always use the same thinking: I must present data and information that are completely accurate and truthful.
This is very important, because if you present a report, especially if you present in an adversarial situation, where you have a team on the other side that doesn’t want to hear your findings, or will dispute every single line of them, everything must be true.
It doesn’t matter whether you are talking to the developer, the business owner, or the board; everything you do, and everything you say must be evidence-based.
And you can produce great evidence, but if finding number 17 contains exaggerations, or is less than watertight, that is exactly what your audience will focus on. And your credibility (and your hard work) will go down the drain.
Therefore, you must make sure that your approach is both pragmatic and objective. Without objectivity, you will lose your credibility. You must be certain that the statements that you have make sense from a business point of view. You can’t say the house is on fire if it isn’t on fire. You can’t say this is a highly critical vulnerability, when at the end of the day a compromise won’t bring the business down or cause too many problems.
In security, you do have vulnerabilities, data compromises, data confidentiality or integrity issues that will bring the business down, so you must put the problem you describe into perspective.
One of the things I find very interesting is that from my position in security and risk analysis I can express strong opinions about architectural and design issues. I give those opinions from my point of view: “Here are the side effects, here are a couple of threat models on features, look at the difference between A and B. You can go with that architecture, fine, but here are the side effects. If you go with this different architecture it is much simpler, there are fewer things to do, and less difficult situations to deal with”.
I have learned that everything you do must be supported by evidence, so you can prove your point and defend your findings. Ensure everything is hyperlinked, because when you hyperlink you build a body of evidence.
Having a thorough list of issues, for example via 500+ JIRA risk’s issues, is key to make this work. You start to build historical evidence that you can use to say “I worked on the same problem in the past, here are the patterns we should follow. Although I can’t prove why X, Y, Z is a problem today, this A, B, C issue had similar characteristics and it eventually blew up. So if you are going to accept the risks, be aware that the last time this happened it didn’t end well”.
It is a passive-aggressive way to deal with a problem. You aren’t saying “Don’t do it!”, but you are drawing their attention to the potential consequences of taking a particular course of action. They can choose to ignore your advice, but this is where you can elevate the issue, and make it a decision for the business owner.
2.4.2 Do security reviews every sprint
If you have an agile development environment, you need to implement security procedures and security reviews at the end of every sprint. In the period between the sprint finishing and going live, you need to do a push to get a sense of whether the original threats and issues, that were highlighted in the threat model, were done, or exist, in a verifiable way.
The central AppSec team shouldn’t do this test.
The target application security champion(s) should do this ‘smaller’ review, in their one-day-a-week allocated to AppSec activities. They should only ask the central AppSec team for help if they need it.
When you create a threat model before the application or feature is built, you know in advance which apps will need a more in-depth security review or analysis. This will depend on the size of the changes, what is being changed, or the assets being handled. This allows scheduling of the more experienced and knowledgeable AppSec professionals, who can be internal or external entities.
Note that these ‘sprint reviews’ are not meant to replace a final security push, or, when required, pentests (i.e. Application Security assessments).
2.4.3 Risk Workflow for Software Vendors
A software vendor is someone who delivers a software application that is executed by a client. The same concept applies to web applications and web apps, but let’s start by looking at a traditional software package.
The risk workflow in this case is very important, and there are multiple angles to consider. Let’s start with a simple one.
The first items to consider are the issues that evolve during the development of the software. Already, two types of risks exist. There are the risks that exist on the application, which should be known and captured on the risk register. The business owner must accept these risks, because ultimately he/she must decide how to prioritize the risks, and whether to fix them or not, depending on the priorities of the business.
Secondly, there are the risks that the company is willing to disclose to their customers. A mix between legal, governance, business and even marketing must decide on disclosure, because in most companies, security is still a marketing-driven exercise, as there is no regulation or requirement to disclose the truth.
There will be a list of security issues that the business will be willing to expose to customers, specially to clients that have signed NDAs, since those clients cannot disclose or talk about those issues publicly.
If you work on the software producer’s security team, you should know every risk that exists. To do so, you must go through the process of capturing, prioritizing, and understanding information, and then you must convince your business owners to accept the risk that is the flow.
Another grey area of responsibility are the insecure-by-design features, that are enabled by default, or are so key to the value of the software, that most clients will enable them.
This process raises a lot of interesting, ethical dilemmas. If you have a risk that no customer will notice, and is unlikely to be attacked, and nobody will pay attention to it, do you need to fix it?
Of course, you know you should fix the risk because it is the right thing to do. But, you also know that business is about making decisions, and about making risk decisions, and a lot of companies would choose not to address this kind of issue.
In fact, there is even a perverse reward system in some companies, where staff get rewarded for not knowing in situations where they plead ignorance of a problem and therefore evade accountability.
I would argue that ignorance is no longer a valid excuse, especially if you are dealing with vulnerabilities or problems that are widely known, and have been disclosed in different places.
If you are a client of those software packages, the situation is tricky because if the product is open-sourced, you have the code and you can do a security review. Of course, this doesn’t mean you are going to do a security review, but the option is there.
In most traditional products, the code is proprietary and you won’t be able to access it. You are therefore dependent on the vendor for information, which is usually limited. Your only option is to pay for an independent security review, which is something I have often done.
When you do discover a security problem with a product, you log it in your own risk register, where you acknowledge the problems that existed, and you discovered, in that product.
You report the problem to the vendor. Of course, the vendor should already know about the problem, and should have a solution for it. If they don’t know about it, this highlights the fact that they don’t have a risk process, and they weren’t paying attention to that problem.
If you are the vendor, and you receive those issues disclosed to you, you are now in a very weak position. Your client now has more power, and more leverage, than you do. In a way, you have switched from being the senior player, to the junior player, at the table.
A big problem we have as an industry is the fact that when client A discloses a problem, the vendor has no legal responsibility to disclose it to client B. The vendor can do a business and a marketing exercise for client A to keep him happy, give him more licenses, and control the damage limitation because they don’t have to tell all the other clients.
The client should ask the following questions:
a] Do you know about this? b] How many more of these do you have? c] Why didn’t you tell me in the first place?
If clients asked these questions, and vendors answered them, we would have a much better working market, and a much better model.
If I am working for the client, and we find issues, I ask a lot of questions on how fit-for-purpose the software is, especially if I start to find basic vulnerabilities and I know that the vendor doesn’t have a security team, or a good security posture.
This is an interesting, multi-dimensional problem and the risk workflows, and the mapping of the risks, will be a great way to measure this problem.
If you look at the insurance industry, and its ability to understand the real risk creative applications, although one might argue that not all these risks should be disclosed publicly, at least until they are fixed, the industry should at least disclose how many they have identified.
It goes back to the concept of a labelling system, where you create labels for software. In the same way that a label on a food product lists its ingredients, security labels on software products should list the security vulnerabilities that exist within.
2.4.4 Create an Technology Advisory Board
One of the biggest challenges in Agile and DevOps environments is the adoption rate of new technologies. In order to be as agile as possible there is a tendency to adopt new technology whenever it appears to have an advantage.
Common examples are cloud technology, analytic tools, continuous integration tools, container technology, web platforms and frameworks, and client-side frameworks.
To prevent the adoption of immature, insecure, or privacy violating components it is important to review desires and proposed solutions. The technology advisory board should take up this role. It should consist of people with security, privacy, and (some) legal knowledge.
It is important to not make this a new ‘Change advisory board’ with monthly review sessions doing a complete business impact analysis. Rather it should be in the form of a guild that is able to identify the maturity of the technology and possible impact on the ecosystem when things go wrong.
It can also guard for implementing multiple tools with the same purpose.
In this way the total ecosystem can be as lean and secure as possible.
2.5 JIRA RISK Workflow
2.5.1 Capture knowledge when developers look at code
It is vital that when a developer is looking at code, he can create tickets for ‘things noticed’ without difficulty. For example, ‘things noticed’ include methods that need refactoring, complex logic, weird code, hard-to-visualize architecture, etc. If this knowledge is not captured, it will be lost.
The developer who notices an issue, and opens a ticket for the issue, will be unable to do anything about it at that moment in time, since he will already be focused on resolving another bug.
Instead, more junior developers, graduate employees or interns could take responsibility for opening and managing these tickets.
They could even try to address the issues in the first instance, because the developer is responsible for merging the PRs.
2.5.2 Describe Risks as Features rather than as Wishes
When opening a risk JIRA ticket, it is essential to describe the exact behavior of that issue as a feature, rather than describing what you would like to see happening (i.e. your wish list).
For example:
- instead of saying ‘application should encode XYZ value’, you should say ‘XYZ value is not encoded’
- instead of saying ‘application shouldn’t be vulnerable to XSS or SQL injection’, you should say ‘application is vulnerable to SQL injection’. In this case, SQL Injection is a feature of the application, and while the application allows SQL Injection, the application is working as designed (whether that is intended or not is a different story).
When we describe vulnerabilities, we describe features, because vulnerability is a feature of an application.
If an application has a direct object reference vulnerability (OWASP Top 10), then that is a feature that allows User A to access user B data (by design, using the capabilities of the application).
For each of these cases, you should open risk tickets, since those risks represent existing features. Sometimes you open multiple risks for the same issue, allowing technical and business audiences to understand what is going on (SQL Injection doesn’t mean a lot to management, but ‘Access and modify all customer data’ does).
I remember a funny story where we found SQL injection in a pentest, and when we presented the findings, the business responded: ’… well, that is not a critical issue, we have good backups, so that SQL injection is not dangerous’. When we asked ‘what if we can drop all tables?’ , they said ‘We can recover from that very fast, no problem.’
We argued ‘well … we can modify data’ and they came back with, ‘We have read-only access and we can protect it from there.’. But finally, when we stated ‘we can log in as any user with a typical SQL Injection payload of: or 1=1’ that connected the dots, and the business said ‘we will fix that ASAP’
The reason that example clicked was because we showed them how to bypass the business logic of the application using the SQL Injection ‘feature’. They could tolerate, to a degree, data corruption or content changes. However, they reacted when they saw that the SQL Injection could bypass the application’s business logic and break their non-repudiation capabilities (i.e. they would lose the ability to understand what a user did on the site).
2.5.3 Git for security
- Why Git and DVCS (Distributed Version Control Systems (check name)) are so important for Quality and Security
- Why migrating to git is a good idea
- Analogy with Docker
How git workflows can be used for security
- add explation
git and svn
- The Git Svn story
- ‘Kinda’ the same workflows, just different
- Git developers to decision to make the opposite decision of Svn
- why? … not just a dig at Svn. concept represents different approaches and focus
- speed of git checkouts
- virtual file systems
- nightmare of moving files in svn ()
- the power of one .git folder
2.5.4 Issue tracking solution
The issue tracking solution you choose is highly important.
To ensure maximum productivity always perform the following tasks:
- copy and paste your screenshots
- hyperlink your issues
- use markdown or wikitext
2.5.5 Risk accepting threat model
If you have trouble getting developer teams to create threat models, or to spend time on those threat models, then the solution is to make them accept the risk incurred from not having a threat model for the application.
The idea is not to be confrontational. Instead, stating that a feature has no threat model is a very pragmatic, focused, and objective statement.
The idea is that the developer team must accept that they don’t have a threat model. The logic is to create a ticket that says there is no threat model, and the ticket will be closed when the threat model is created. Alternatively, if the developers and their management team don’t want to spend the time creating a threat model, they must accept the risk of not having one.
This can be difficult to accept, but it’s an important part of the exercise.
2.5.6 Storing risk issues on JIRA
Is a JIRA ticket system a security risk
- Are they zero days?
- Is it increasing the attack surface
- ‘If it is on fire, fix it and document it later, if not on fire, document it’
- … better to know about it and to make it explicit that it will be exposed
- … in reality that info already exists on JIRA (maybe not so obvious)
- Monitoring the JIRA access could provide info about an attacker
2.5.7 The smaller the ticket scope the better
For bugs and tasks, the smaller the bug the better.
Having many small bugs and issues can be an advantage for the following reasons:
- easier to code
- easier to delegate (between developers)
- easier to outsource
- easier to test
- easier to roll back
- easier to merge into upstream or legacy branches
- easier to deploy
It is better to put them in a special JIRA project(s) which can be focused on quality or non-functional requirements.
Of course, this needs to be rational and kept in context. You should only create a couple of each instance/pattern, particularly when they are not being fixed. In such cases, create a ‘holding ticket’ that will store references to all the individual issues, which is good for systemic vulnerabilities.
You should also aggregate issues in Stories.
2.5.8 Key concepts
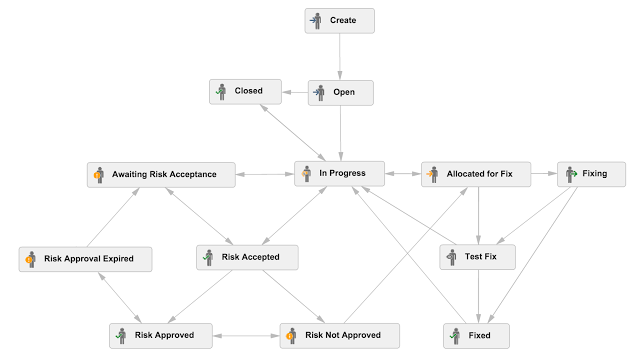
The following are the key concepts of this workflow:
- All tests should pass all the time
- Tests that check or confirm vulnerabilities should also pass
- Business owners must understand the risks of their decisions, and they must click on the ‘accept risk’ button
This workflow is about empowerment and assigning responsibility; it is not about apportioning blame.
Although I use JIRA for these examples, these concepts also apply to any bug-tracking system.
2.6 JIRA Technologies
This section covers the multiple technologies used
2.6.1 Confluence
- Atlassian wiki solution
- Tight integration with JIRA
- useful for reporting and Threat modeling
- used to create the materials used in weekly/monthly reports to owners of RISKs (i.e. the ones that have accepted the Risk)
2.6.2 JQL Query Language
- how it works
- security implications
- power examples of queries
2.6.3 Jira components
- used to map issues to specific projects
- allow easy filer per project
2.6.4 Copy and paste of images
- only available in the most recent version of JIRA but a feature that makes a massive difference
- the file attachment of images also works quite well
2.6.5 JIRA dashboards
- how to create them
- pie chart and issues list
2.6.6 JIRA Filters
- how to use them
- saving them
2.6.7 JIRA Kanban boards
- really good to track specific projects
- show couple examples
- add how to create on
2.6.8 JIRA Labels
- show examples
- how to use them
- common workflow
- using them to map OWASP Top 10 issues
2.6.9 JIRA workflows
- explain what they are what makes them powerful
- key components of it
- a good workflow tells a story and guides the user down specific paths
Tidy up your diagrams
It is important that your diagrams have layouts that look good and make sense.
The Diagram UI allows a bit of flexibility on where the Stages appear, so make use it and create nice diagrams
- show where they can be seen in the UI
- makes big difference when they are easy to read and understand
- I hide the labels since I find that they are harder to position and don’t provide that much more information
- add example of two diagrams diagrams. Same content: one messy and one clean
- note how the clean one is much easier to read
Naming of states
- This is very important since they need to convey the desired action
- names have to be short or they don’t look good in the UI
Other workflows
Add screenshots for: - bug bounty - development - other …
A simple workflow
- add example of a simple workflow
2.7 Security Champions
- The Security Champions concept
- What is an Security Champion and what do they do?
- Becoming A Security Champion
- Do you have an heartbeat, you qualify!
- If you don’t have an Security Champion, get a mug
- Make sure your Security Champions are given time
- Making Security Champions AppSec Specialists
- Involvement in senior technical discussions
- Security Champions Don’t Take it Personally
- Supported by central AppSec
- Public references to Security Champions teams
2.7.1 AppSec memo from God
Having a board-level mandate is very important since it underlines the importance of AppSec.
The best way to provide a mandate to the existing AppSec team is to send a memo to the entire company, providing a vision for AppSec and re-enforcing its board-level visibility.
Sometimes called the ‘Memo from God’, the most famous one is Bill Gates’ ‘Trustworthy computing’ memo from January 2002 (responsible for making Microsoft turn the corner on AppSec)
2.7.1.1 Example of an AppSec memo
Here is a version of a memo I wrote for a CTO (in a project where I led the AppSec efforts) which contains the key points to make. Note that the contents of this book are released under a Creative Commons license (CC BY 3.0), which means you can reuse this text, in its entirety, in your organization.
From: CTO (or jointly with CEO)
As you must have noticed from the news, ‘cyber security’ is becoming a very hot topic, with daily reports of companies being exploited and assets compromised. At XYZ we have been lucky to have not (yet) been the target of such attacks, but as we grow and increase our visibility (and assets), we will become a target.
We are a digital company and everything we do happens via the applications we write and use. Historically, the focus of development has been in getting things done as fast as possible, with security being an afterthought and further down the ‘real’ priority list, which is typical of fast-growing companies like XYZ.
This is about to change, and we will be making a significant effort to improve the security of all aspects of XYZ operations and development.
In addition to the current network and physical security activities that we already have in place (firewalls, anti-virus, password management, user accounts restrictions, etc.), we will start a new Application Security practice which will focus on the enablement of our developers to write Secure and Resilient code/applications.
The key to writing secure code is to embed security into the SDL (Software Development Lifecycle) and to ensure that Application Security is an enabler, that allows development to happen faster and more efficiently.
Usually, security is seen as a tax, and as something that is always saying “No”, which explains why security is often avoided or bypassed. For Application Security, the analogy I would like you to think of is ‘Brakes in cars’ (i.e. technology that allows the car to go faster).
What this means is that for us to implement security correctly, we will need to improve our current development and deployment practices (aka Continuous Integration/Deployment) even more, so that all, or most, changes become small, incremental, and fully tested.
The test(ing) component is an area where significant efforts occur, where high-levels of code-coverage and testing are not just important, but a key requirement to have Application Security Assurance. We can’t protect something we don’t understand, visualize and control.
From a practical point of view, and looking at day to day development, we are kick-starting several activities which are outlined below:
1) Security Champions
The key to making Application Security scale is the existence of Security Champions in each team.
Security Champions are active members of development teams and act as their ‘voice’ on security issues.
We already have several Security Champions (see wiki) and if your team doesn’t have one, I strongly advise you to step up and volunteer to become one (this will give you a huge opportunity to learn and to improve your skills).
2) Secure Coding Standards
One of the most important development questions that needs to have a simple answer is ‘How do I code xyz securely?’. Using our existing development stack/tools (and maybe new ones), we aim to create an environment where such guidance is available in the IDE or at the distance of a link.
This kind of guidance only works if it is actively maintained, and I expect everybody to share their knowledge and help to create highly focused and accurate secure coding guidance that are relevant to XYX coding practices.
3) Application Security Automation
Since we ship code every day, we need to do security reviews every day, which means that we need to automate the discovery, and even the mitigation, of security vulnerabilities as much as possible.
The key objective is that when, not if, one of you creates a security vulnerability (which is as inevitable as bugs), we have systems, technology, and workflows in place to detect the vulnerability before that code hits a live server.
This means that we will be introducing Static (SAST) and Dynamic (DAST) software analysis tools and will be looking to expand our current Unit/Integration/E2E testing to incorporate ‘attack patterns’ and ‘architectural checks’.
4) Security data classification and Attack Surface
Another area we need to focus on is the mapping of the data we use, and the inputs and outputs of each of our applications.
When you look at the application you are currently working on, or have worked on in the past, I want you to think:
- ‘Do I need this data?
- ‘What would happen if this data was exposed to the public (or sold on the Dark Net)?’
- ‘What is the impact to our brand?’
- ‘Will this impact our partners and suppliers?’
- ‘How much money will we lose?’
- ‘What happens if this data is modified?’
- ‘Do I know my attack surface?’
- ‘Do I trust the data that I receive?’ (very relevant for ‘internal’ systems)
Note the reference to ‘internal’ systems, since Application Security is not only something that applies to our more outward-facing code. We need to remember that our attackers are getting more sophisticated, and the most dangerous ones will go after our money and assets.
Ironically, the further you go into the network, the more sophisticated and focused the attacker will be, and what matters is the value and exploitability of the application’s assets, unless the code lives in a completely isolated network and doesn’t talk with anything else.
5) JIRA based Risk/Issue acceptance and security visualization
Some of the key challenges when dealing with Application Security include ‘understanding what needs to be done’, ‘what are the risks?’ and ‘what should be the priority?’.
To help answer these questions, a new JIRA project (called RISK) has been created and will be used to hold all currently known security issues/vulnerabilities/compromises.
The workflow of these issues is the following:
- Issue is opened (by anybody)
- Issue is reviewed and expanded (for example to provide risk mappings, exploit details, references to similar issues)
- Technical/business owners decide if a) the issue should be fixed asap (one to two weeks), or b) the issue is NOT going to be fixed (in the short term) and its risk needs to be accepted
- The issues to be fixed will be:
- moved into a ‘To Fix’ JIRA issue stage
- linked into issues that are focused on fixing the issue (in their respective repos)
- closed when there is verification (by Security Champions) that the issue has been fixed
- The issues NOT to be fixed will be:
- moved into a ‘To Accept Risk’ JIRA issue stage
- assigned to the respective business/technical owner (who will have a button called ‘Accept Risk’ to click)
The key to this workflow is to improve visibility into the reality of Application Security compromises. As a company, our objective is not to create 100% secure applications, but to create applications and code whose risk is aligned with the current threat landscape and business risk appetite.
The other major advantage of mapping security issues like this is that we will be able to have an accurate visualization of the risk profile of our applications. For example, we will expand our use of tools like ELK to visualize (in quasi-real-time) the exploitation of these ‘accepted risk’ security issues, and ideally detect similar security vulnerabilities as they are being exploited.
6) Secure architecture, threat models and nonfunctional requirements
Application Security reviews and practices will also highlight a number of ‘nonfunctional requirements’ or ‘technical debt’ issues. These will not have the ‘the house is on fire’ risk profile, but will need development time to ensure the quality and resilience of our code base.
One practice that we will introduce is the creation of threat models for existing applications and new features. The Security Champions will help to create these threat models, and I expect you all to contribute, since although security-focused, they tend to promote a better understanding of the ‘real architecture’; they will help us to understand better how out technology works and interacts.
7) Hack anything that moves at XYZ
On the topic of security vulnerabilities we need a culture change where we celebrate and reward the discovery of security issues. Collectively, we need to understand that every issue we discover, and mitigate, is one less available to our attackers.
Therefore, you have my permission to (responsibly) hack anything XYZ-related, from external websites, to internal applications, networked resources, printers, cars, etc.
We will create an internal reward system and ensure there are some good professional perks for finding and reporting issues.
The word ‘responsibly’ means that if you find a way to blow up one of our websites, or access confidential data to which you shouldn’t have access, we expect you to create a ‘non-destructive’ PoC and use test accounts, not real customer data. Of course, we know that accidents happen, and we will use common sense.
Eventually, we will create a public ‘bug bounty’ program (after we’ve done a couple of internal rounds), so if you feel that your app will struggle with a public call for ‘..please hack XYZ…’, then you better start finding those issues.
…in conclusion
Times are changing and XYZ is changing. When faced with a scenario where security will be affected by a feature, we need to choose security, or clearly understand the trade-offs.
Security is now a board-level issue and if you feel that any area of our coding/technological world is not receiving the focus it requires, then your duty is to escalate it and fight for it. After all, XYZ is your company too.
These changes represent a great opportunity to make our technology stack and code even better. I hope that you are as excited as me to take XYZ to the next level.
2.7.2 AppSec Technologies and tools
The AppSec community and industry has some really powerful technologies and tools that not only help to find security issues, but can also be spectacular developer productivity tools.
(todo: expand on each technology, mention best players (open Source and proprietary) and provide examples of how they can be used very effectively)
- DAST - Dynamic scanning (Blackbox)
- SAST - Static scanning (WhiteBox)
- IAST - Interactive scanning
- WAF - Web Application Firewall
- Reporting
- Consolidation
2.7.3 Collaboration Technologies
The following technologies are crucial for Security Champions and JIRA workflows to work efficiently:
- Email - good when used in moderation, especially when emails contain links to online resources
- Mailing lists - still the best collaboration tool, as they scale a lot, are easy to filter, they reach a wide audience, are a great way to motivate new Security Champions when they see their name on the list, and they allow interested parties (and older non-active Security Champions) to stay connected to what is going on
- JIRA issues - discussion threads provide a lot of information and details about specific topics
- Wiki - key to capture knowledge in a more structured and long-term environment. Remember that wikis require maintenance and should be curated so that they remain relevant and don’t fall for the ‘tragedy of the commons’ problem. Wiki’s should use JIRA issues as evidence of what is said.
- Confluence - when integrated with JIRA, it creates a powerful way to create dashboards that present the data stored in the JIRA tickets
- Video conferences - tools like Join.me, BlueJeans, Google Hangouts, and Skype are great ways to make remote working and participation possible
- Slack - real-time collaboration tools are key to allow questions to be easily asked, and to allow for asynchronous collaboration, and catching up on specific topics
-
Slack integrations - very powerful workflows can occur when SDL tools (and CI pipelines) feed data into specific channels. This is not only a good way to get a sense of what is going on, but also a good way to alert for possible issues or attacks. It gets even better when these integrations are interactive:
- Hubot(s) - is a great example of this (where it can listen to messages posted and respond to them)
- Log visualization - tools like Splunk, ELK or Graphite, when supported by strong dashboards and visualizations, are one of the best ways to present information and collaborate
- Diagram technologies - Visio has been the gold standard for a long time (draw.io is a recent new player), but the problem is their lack of non-human readable data storage format. To promote collaboration and allow for ‘revision of what changed since last analysis’ (i.e. Diffs), diagramming technologies, created from textual descriptions, are much more powerful and useful, for example PlantUML or DOT (Graphwiz), which are easier to read (in source format) and can be stored in git (i.e. versioned controlled)
2.7.4 Conference for Security Champions
Every 6 to 12 months, it is a good idea to hold a conference exclusively dedicated to security champions, particularly for companies that have multiple locations, where its security champions don’t meet regularly in person.
At the conference, external speakers should present on specific topics.
If there are already several external AppSec consulting companies under contract to the hosting company, the consultants involved in existing projects are perfect candidates to present to the conference. They can use their own examples and stories, and it is easier to present internal materials if all participants are signed-up to the same NDA (Non-Disclosure Agreement).
Never underestimate the power of team collaboration, or of team members getting to know each other. Social events are important, and the model of the OWASP Summit is also a good example of a conference for security champions, as is the Microsoft Blue Hat security conference.
(find other examples)
2.7.5 If you have a heartbeat, you qualify!
It is important to understand that AppSec skills are not a key requirement to become a security champion. The essential quality is to want to become one.
I can make a good developer, who is interested and dedicated, into a good AppSec specialist in 6 months. If the developer is an expert in AppSec, then he should join the central AppSec team.
2.7.6 How to review Applications as a Security Champion
When you review applications as a security champion, you need to start by looking at the application from the point of view of an attacker. In the beginning, this is the best way to learn.
You should start thinking about data inputs, about everything that goes into the database, the application, all the entry points of the application. In short, think about everything an attacker could control, which could be anything from headers, to cookies, to sockets, to anything that enters the application.
Authorization is also a great way to look at the application. Just looking at how you handle data, and how you authorize things, is a great way to understand how the application works.
- add info about how this is best done using Threat Models and asking the STRIDE questions
2.7.7 Involvement in senior technical discussions
Involvement in senior technical discussions provides a great opportunity, and a perk, to security champions. Once a SC program is established, if the SCs should be involved in senior technical discussions. If they aren’t, it means that security is not being taken into consideration, and this is a problem.
2.7.8 Learning-resources
Books to learn from
- Hacking Exposed, both the normal version and Hacking Exposed: Web Applications.
- The Shellcoder’s Handbook is a great book from an application security point of view, and it walks you through the vulnerabilities.
- The Web Application Hackers Handbook provides a solid overview of problems in web applications and how to identify them
- (todo: add more books with a small description each)
- Kevin Kelly books
- The Circle
- The Phoenix Project
- Improving Web Application Security and Secure Code (from MS)
- Geekonomics
- Cathedral and the bazaar
(todo: add links to Amazon)
OWASP Materials
- Cheat Sheet series - one of the best AppSec resources on the internet
- Testing guide - good resource to start you AppSec skills.
- SAMM (Software Assurance Maturity Model)
- Developers Guide
- Code Review guide
- Top 10
- Top 10 for Mobile
- Top 10 Proactive Controls
- ASVS (Application Security Verification Standard)
- AppSensor guide
- Automated Threats Handbook
(todo: add links to projects)
Vulnerable by design applications
Another great resource is the OWASP WebGoat Project which just released a new version, and it has a selection of exercises in vulnerabilities so you can learn how they work and you can get clues if you get stuck. The first thing is to do the exercises and hack into these applications.
- Add more examples of apps, split by technology
- .Net - WebGoat.Net, HackmeBank
- Java - WebGoat
- Node - NodeGoat, JuiceShop
- Ruby - Railsgoat
- php - Damn Vulnerable Web Application
- Android - GoatDroid
- iOS - iGoat
- OWASP Broken Web Applications Project
- [OWASP Vulnerable Application Directory] (https://www.owasp.org/index.php/OWASP_Vulnerable_Web_Applications_Directory_Project)
Hack your apps
You can hack anything that moves in your company, because you have an implicit mandate to protect your own company.
Go for your own application, or go for your colleague’s application. Sometimes that’s a bit easier to digest :)
BugBounties
Also go for things like bug bounties, which are basically companies that give you permission to hack them and find security issues.
(todo: mention existing programs like https://hackerone.com/)
2.7.9 Make sure your Security Champions are given time
It is very important that security champions get the time, the space, the mandate, and the information required to do their jobs.
The good news is, now that you have security champions (at least one per team), their work will allow you to see the differences between the teams and the parts of the company who can make it work, and those who struggle to make it happen.
To participate successfully in the security of their projects, security champions must execute the following tasks:
- review code
- fix code
- write tests
- know what is going on
- maintain the JIRA tickets
- create Threat Models
- be involved in the security practices of the teams
Adherence to these tasks leads to better code, better project briefs, up-to-date documentation and tests for the application.
Security champions should spend at least one day a week on these activities. Although allocating this time is easy for management to accept in theory, it is much harder to put into practice.
In the beginning, security champions will barely be able to spend a couple of hours a week at this work.
One of the things you should know from a central point of view is who is doing this kind of work, and who can spend the time doing it.
Fortunately, these things can be measured and tracked from the point of view of all the teams (using dashboards and graphs from the JIRA Risk Project).
2.7.10 Making Security Champions AppSec Specialists
- once you have SCs you need to grown them
- training is very important
2.7.11 Regular Hackathons
Regular hackathons have many benefits for security champions, teams and companies.
Security Champions should organize the hackathons, as hackathons are the next level of SCs applications. SCs can use them to find issues and learn new features.
They should be held every Friday or Monday afternoon, preferably with some drinks and pizza.
Ideally, a hackathon would happen every week, but if not it should be held every two, three, or four weeks. The important thing is to have movement.
The hackathon model fits well into the 10% of time developers need for research.
Inviting external experts, such as pentesters that regularly test the applications, has the benefit of providing new insights. Trying to do something, and then watching a more experienced and knowledgeable person do the same task, is one of the best ways to learn your job. You benefit from observing the workflow and strategies they employ to discover and exploit an issue.
Organizing teams into red (attackers) and blue (defenders) can also be very effective. However, planning your hackathon around teams makes it harder to organize, and needs a lot more preparation.
2.7.12 Rewarding Security Champions
- budget to sponsor the best one in last month (or week, if there is a lot of activity)
- Participation in conferences (ticket + travel expenses)
- Books
- Bonus (some companies prefer old fashioned cash prices)
- How to measure who is the best of the month
- Number of JIRA tickets: opened, fixed, tested
- Number of Threat Models
- Highest improvement
- Innovative research
- Shipped code (of an module used by multiple teams)
- Above average documentation (Secure coding standards)
- provide presentation opportunities (for example at the company wide Security Champions conference, or to senior directors (a couple levels above the current developer’s position in the org chart))
- basically anything that you can do to a developer that he/she can put on the CV is a good reward
- It is very important to create explicit and open rules about these rewards, since the worse situation is when a particular Security Champions receives an award not because of his achievements but due to other (political or friendship based) decision.
2.7.13 Security Champions activities
What do Security Champions do in they allocated day-to-day time (4h to 8th)
- it is very important that JIRA tickets are use to map, track and allocate these tasks
- the number of these tickets is what justifies the work the SC does
- it also provides movement and management information about what is being done
- it is important to have a good number of actionable (in the ‘Allocated for Fix’) stage (30 to 50 are a good number, as long as they are realistic and real)
- you know the model is working when the managers start asking: “Do you have enough time of those SC activities?”, “Do you need help from other team members (i.e. more resources)”
- eventually the SC should also be managing the AppSec tasks that are performed by other team members
- the time allocation is better if done in blocks of 4h (over two days), or 2h every day (at the same time)
2.7.13.1 Other AppSec projects to be involved in
- Map Attack Surface tool
- Web Services Visualisation tool
- Standard Schemas across the company
2.7.14 Security Champions Don’t Take it Personally
If you are a Security Champion, don’t take it personally if teams aren’t listening to you. Don’t think that you are the problem, that you aren’t good enough or that you are failing to communicate in some way.
In most cases, the problem isn’t you. The problem is actually the system; the company isn’t structured in a way that allows the security champion’s questions to be prioritised and answered. In other cases the Security Champion is not included in security-relevant architectural meetings and decisions.
So, if you find that you are struggling to get traction from a team, the team isn’t responding, or it fights you, then drop those requests (as long as the Risk as been accepted). If they treat you as a TAX, as somebody who is giving them work they don’t want to do, then also drop it.
In the Risk ticket, explain that you tried to persuade the team to accept the risks of not doing security, and that they are now responsible for their security, because you cannot help them.
In such cases, the problem lies not with the Security Champion, but with the company and the organisation, maybe even sometimes with the team itself. This is why it is important to have success stories you can point to and say, “Hey! It worked with that team, and it worked with that team. If it doesn’t work with this team, then I am not the problem”.
2.7.15 Involve Security Champions in Decision-making
Once a program starts being placed, security champions will often give feedback that they are not involved in the workflows and decisions. The job of the security champion is to ask, “What is this? Do I trust this? What happens with this?”, but they often don’t get the opportunity to ask these questions, because decisions are made without their input.
To illustrate this problem, a situation occurred recently where the security champion started to create threat models across a product, and thereby managed to retroactively involve himself in some of the decision-making.
He created a threat model with a lot of the developers and the other systems owners, and they found a couple of end points that were problematic. Once the teams were aware of the problems, realizing that data wasn’t trustworthy, and identifying vulnerabilities, then the developers themselves started to question the methods.
They found a nasty, exposed method that nobody knew about. It was a powerful and toxic method, that allowed a lot of data to be erased with very little accountability.
That method should never have got there; it wasn’t even validated, and there were other components missing.
This is exactly the kind of exercise you want security champions to be involved in, because you want them to question those things before they hit development, before they go live. You want to catch those problems as early as possible.
This is not to say “No” to functionality. It is rather to say, “If you want to do this, here are the side effects, here are the compromises, and here is how we should protect it”. At the very least you should say, “If you do this, you do it without due regard being given to the security implications. You must accept the fact that this feature has no security thinking behind it”.
It is very hard for a project owner to accept that the feature being pushed has not benefitted from the consideration of security implications and side effects. This leaves him accountable for how it works, and this makes project owners uncomfortable.
2.7.16 Supported by central AppSec
They need to be supported by a central AppSec team, but it is key that each team has one. If there are not enough champions they can create a guild or chapter and rotate over teams. It is also important that they are backed in their decisions by corporate security like e.g. the CISO.
Tasks (expand) * Code Reviews and Pen-tests (internally or via external managed services) * AppSec Automation (SAST and other tools) * Secure coding standards * Incident Response * Recruitment and Training
2.7.17 The Security Champions Concept
“If everyone is responsible for security, then nobody is” 6
- What are Security Champions?
- Why Security Champions
- challenges to scale and propagate AppSec Knowledge
- Keep AppSec focus and energy
- have somebody responsible for AppSec
- What is the target audience of this section
- … you want to become an SC …
- … you want to set you a SC network …
- There is an heavy AppSec focus, but this is applicable to all of IT, Dev and Risk management practices
- explain how JIRA Risk Workflow is connected to the Security champions
“If everything is important, then nothing is.” from Patrick Lencioni
2.7.18 Threat Modeling workshops
- to happen every week
- or every other week, alternating with a Security Champions meeting (this way there is always an SC activity happening every week at the same time and place)
- good place to ask questions and to present Threat Models created during the previous week
- If there are not a lot of materials to present or show, that indicates that the quantify of Threat models being created is quite low (note that the objective is to create Threat Models for new features, which are happening all the time)
- another great learning resource, specially for new SCs (who are still getting their head around the workflow)
- see Threat Models section for more details
2.7.19 Training Security Champions
- Training is key to improve SC skills
- Best training is done on top of languages and frameworks they use
- Wiki pages with links to actual issues and relevant resources make a massive difference
- Using vulnerable by design apps (or older versions of current main apps with known vulnerabilities) are a great way to learn (by exploiting them)
- Writing exploits and finding vulnerabilities is a key step of the required accelerated learning curve
2.7.20 Weekly meetings
- explain why these meetings are so important
- what happens at one of these meetings
- what is the normal agenda
- who turns up
- should happen every week, but a good compromise is for them to occur every other week
- everything shown and discussed at the Security Champions meeting needs to be done via one or more slides (to be added to that week’s slide deck)
- these slides are VERY important when creating learning materials
- create wiki pages with a full list of all past SC meetings (each entry is categorised by labels)
- there are a great way to teach Security Champions and to call their attention to areas to research in their own apps
- I’ve seen many cases where Security Champions will see a presentation on a topic/technology relevant to their current domain and think/say “Humm… I think we might be vulnerable to THAT vulnerability”
- there are a great way to teach Security Champions and to call their attention to areas to research in their own apps
Initially, it will take considerable effort to generate content for these meetings; to find presenters; and to keep it engaging / interesting.
- think of the money that it costs the company to have all those resources in there. Make it count and don’t waste participants time
- the developers are very busy and if the meetings are not relevant or not interesting they will just don’t turn up
- central AppSec team (to help kickstarting the meetings) and to keep the energy level up) must always be looking for topics to present at the next SC meeting. For example:
- Threat Models
- AppSec Questions
- AppSec ideas
- events from a point of view on an attacker
- attacks
- AppSec news,
- basically any AppSec related topic that has not been presented recently)
2.7.20.1 Contents for weekly meetings
Here are some examples of what to present at these meetings:
- Latest news on AppSec (DDos, exploits, etc..)
- Latest bug-bounty findings and payments (a really good source of real-world examples)
- Issues found and issues fixed (on the SC’s application or service)
- Secure coding techniques
- Security tools and technologies (e.g. OWASP ZAP Project, OWASP dependency checker)
- Tools/techniques to improve the Developer’s Productivity (e.g. WallabyJS, NCrunch)
- Hack challenges
- Security reviews current in place
- Other OWASP tools and documents (ASVS, OwaspSAMM, AppSensor, Testing Guide)
- Testing techniques, workflows and technologies used (which might be different from the current development stack)
2.7.21 What is a Security Champion and what do they do?
Security Champions are a key element of an AppSec team, since they create an cross-functional team focused on Application Security
What is a Security Champion?
- Security Champions are active members of a team that may help to make decisions about when to engage the Security Team
- Act as the “voice” of security for the given product or team
- Aim to bridge the gap between security and dev teams
- Assist in the triage of security bugs for their team or area
What do they do?
- Actively participate in the AppSec JIRA and WIKI
- Collaborate with other security champions
- Review impact of ‘breaking changes’ made in other projects
- Attend weekly meetings
- Are the single point of contact for their assigned team
- Ensure that security is not a blocker on active development or reviews
- Assist in making security decisions for their team
- Low-Moderate security impact
- Empowered to make decisions
- Document decisions made in bugs or wiki
- High-Critical security impact
- Work with AppSec team on mitigations strategies
- Low-Moderate security impact
- Help with QA and Testing * Write Tests (from Unit Tests to Integration tests) * Help with development of CI (Continuous Integration) environments
2.7.22 What it takes to be a Security Champion
To become a security champion, it is essential that you want to be one.
You need a mandate from the business that will give you at least half a day, if not one full day per week, to learn the role. The business should also provide the means to educate and train you and others who wish to become security champions. Increasing and spreading knowledge will increase awareness and control.
You need to be a programmer, and understand code, because your job is to start looking at your application and understand its security properties. You should also know ‘the tools of the trade’, and how to implement them, in the most efficient way. Lastly, you must be able to identify useful metrics and instruct on how to obtain them.
2.7.23 To Add
add references to
2.7.24 Security Champions
- So you want to be an SC?
- … here is how you do it…
- Need to be a developer
2.7.25 Becoming a Security Champion
To become a security champion, the most important property is that you want to be one.
You need a mandate from the business that will give you at least half a day, if not one day.
You need to be a developer who understands code, as it is difficult to be an AppSec SC and not be able to code.
Your job is to study your application and understand its security properties.
You need to look at the application from the point of view of an attacker. In the beginning the best way to get your head around it is to think about all the entry points of the application (i.e. inputs).
This includes everything the attacker can control: from GET/POST parameters, to WebServices calls, to headers, to cookies, to websockets, to anything that actually enters the application.
After that, authorization is also a great way to take a look.
Basically, start with creating threat models :)
Looking at how you handle data and how you authorize is a great way to understand how the application works.
2.7.26 Hack anything that moves
You should hack anything that moves in your company, because you have a mandate to protect your own company (in some companies it might be better to get this ‘hack everything’ authorization via official channels).
In terms of targets, you can go for your own company, for your own application or for your colleague’s application (which sometimes it’s a bit easier to digest).
2.7.27 BugBounties
Also go for bug bounties, which is a nice list of companies that give you permission to ‘hack/attack’ them and find security stuff.
2.7.28 Developers we need YOU in AppSec
- big oportunity for existing developers to move into appsec
2.7.29 Big market demand for AppSec Professionals
At the moment there is huge demand for AppSec devs. Historically the path info InfoSec via Network Security, which means that the majority of InfoSec professionals cannot move to AppSec, because they can’t code professionally (i.e. no real knowledge on how to build, test and ship software/apps)
It is also possible to learn on the job since there is such a shortage, which makes it easier to hire Devs who like AppSec and then train them up.
- add stats on salaries for: AppSec and projects that mention OWASP
- http://blog.diniscruz.com/2009/09/owasp-driven-jobs.html
- http://www.indeed.com/salary?q1=appsec&l1=
2.7.30 If you don’t have a Security Champion, get a mug
If your developer team doesn’t have an assigned security team champion, get one of these mugs.

That ‘Security Expert’ mug represents the fact that, without a security champion, when a developer has an application security question, he might as well ask the dude on that mug for help.
I also like the fact that the mug reinforces the idea that for most developer teams, just having somebody assigned to application security is already a massive step forward!!
Basically, we have such a skill shortage in our industry for application security developers that ‘if you have a heartbeat you qualify’
2.7.30.1 How to create the SC Mug
- Get a mug with lots of white space on the front and back
- write Security Champion at the front in large letters (but not so big that the text can’t be read from a distance)
- Alternatively, at the back write: It’s me, or Google, or Stack Overflow
- Or, if you have a small company stuffed animal or object, put it inside the mug
Put the mug in a central location, visible place to the team. It is important that the mug is in a neutral place, and not ‘assigned’ to anybody.
In some teams, I’ve observed a ritual when a Security Champion is appointed, presented with the mug, and expected to keep it on his/her desk.
2.7.31 Public references to Security Champions teams
Microsoft
The Microsoft Agile SDL describes them as Team Champions
In Simplified Implementation of the Microsoft SDL
Team Champions. The team champion roles should be filled by SMEs from the project team. These roles are responsible for the negotiation, acceptance, and tracking of minimum security and privacy requirements and maintaining clear lines of communication with advisors and decision makers during a software development project. * Security Champion/Privacy Champion. This individual (or group of individuals) does not have sole responsibility for ensuring that a software release has addressed all security issues, but is responsible for coordinating and tracking security issues for the project. This role also is responsible for reporting status to the security advisor and to other relevant parties (for example, development and test leads) on the project team. * Combination of Roles. As with the security and privacy advisor role, the responsibilities vested in the champion role may be combined if an individual with the appropriate skills and experience can be identified.
In “The Microsoft SDL Process Template – Making Secure Code Easier” Brian Harry blog entry says this about Security Champions
With the SDL Process Template, a security owner can easily tackle that initial question of “where do I start”? The Process Guidance page provides a security owner (and the entire team) with a brief overview of the SDL, five steps for Getting Started on an SDL project, and details on customizing the template and extending it for third party security tools. There is even more material supporting SDL implementation and customizing the SDL Process Template in the SharePoint library.
and
A security owner can accelerate the task of defining security requirements by opening up a query that includes all of the default SDL requirements – ready to triage and assign! There is also a custom work item to add your own requirements or recommendations
Mozilla
Mozilla has a good pages at Security and Security/Champions.
In the SC page they mention other types of Security Contributors:
- Contributor
- Security Contributor (Bug Bounty Reporters/Patch submitters)
- Security Mentors
- Security Group
Unfortunately this program has ended in 2012 following an internal reorganisation
OwaspSAMM
Owasp SAMM (Software Assurance Maturity Model) uses the term Team Champions

BSIMM
In BSIMM security champions are named ‘satellites’ and described in section 2.3 > The satellite begins as a collection of people scattered across the organization who show an above-average level of security interest or skill. Identifying this group is a step towards creating a social network that speeds the adoption of security into software development.
…others?
… add more
2.7.32 Draft notes - Threat Models
- Do Threat Models in layers
- identify each STRIDE issue per layer
- each layer it built on top of the previous one
- connect the threats
- map the Urls and Data objects and connect them across layers
- created ‘refactored’ and ‘collapsed’ views of the diagrams (specially when there are ‘web services that act like proxies’ in the middle)
- Introduce the concept of Sinks in Threat Modeling
- how to connect the multiple threats (one for each layer) so that they are chained
- map this concept with the concept of Attack Trees
- how to connect the multiple threats (one for each layer) so that they are chained
- Idea to create a Book focused on “Threat Modeling examples and patterns”
2.7.33 Capture the success stories of your threat models
One of the key elements of threat modeling is it’s ability to highlight a variety of interesting issues and blind spots, in particular within the architecture of the threat model. One of my favorite moments occurs when the developers and the architects working on a threat model realize something that they hadn’t noticed before.
In such cases, sometimes it is the developer who says, “Oh, I never realized that is how it worked!”. Other times when the architect says, “Well, this is how app was designed”, and the developer responds “Yeah, but that didn’t work, so we did it like this.”
What is actually happening when such exchanges take place is the mapping of reality, and the creation of a much better understanding of what that reality actually means within the company. Truth is being mapped, and the threat model becomes a single source of truth for the company.
It is very important not only to capture these success stories, but also to advertise and promote them. Promoting them allows you to explain one of the reasons why you want to work in threat modeling; because you want to understand what is going on, and you want to make sure that everybody working on a threat model is on the same page in terms of development, QA, testing, and so on.
2.7.34 Chained threat models
When you create threat models per feature or per component, a key element is to start to chain them, i.e. create the connections between them. If you chain them in a sequence you will get a much better understanding of reality. You will be able to identify uber-vulnerabilities, or uber-threats, that are created by paths that exist from threat model, A to threat model B, to threat model C.
For example, I have seen threat models where one will say, “Oh, we get data from that over there. We trust their system, and they are supposed to have DOS protections, and they rate limit their requests”.
However, after doing a threat model of that system, we find that it does not have any DOS protections, even worse, it doesn’t do any data validation/sanitisation. This means that the upstream service (which is ‘trusted’) is just glorified proxy, meaning that for all practices purposes, the ‘internal’ APIs and endpoints are directly connected to the upstream service callers (which is usually the internet, or other ‘glorified proxies’ services).
This example illustrates how, when you start chaining threat models, you can identify data that shouldn’t be trusted, or data that is controlled by the attacker. Usually the reverse also applies, where when you go downstream and check their threat models, you will find that they also trust your data and actions far too much.
Of course, the opposite of this scenario could also be true. One of the threat models might say, ”…we have a huge number of issues at this layer”. However, when you look at the layers above, you find they are doing a good job at validating, authorising and queuing the requests; they are all working to protect the more vulnerable layer, so the risk is low overall.
When you chain a number of threat models, you track them, document them, and you greatly increase your understanding of the threats. You can use this new knowledge in the future to ensure that you don’t expose that particular threat into new systems or new features.
2.7.35 Developers need data classification
Every type of data that exists in an organisation, especially the data that is consumed by applications, needs to have a Data Classification mapping.
Developers need to know if a particular piece of data is sensitive, and what value it holds for the business.
A good way to determine the expected level of confidentiality and integrity, is to ask what would happen ‘If a particular set of data were to be fully disclosed?’ (for example uploaded to PasteBin) or ‘If some of the data was being maliciously modified over a period of months?’.
These are really hard questions, and only by answering them, the developers (and business owners) can start to understand the value of an particular data set (given-to or generated-by their application).
Developers need to understand what they are dealing with, what is valuable to the business, and what needs to be protected.
See Microsoft’s Data Classification Wizard for a good list of data types that exist on large organisations (this will need to be tweaked per application)
todo: add references to Threat Modeling
2.7.36 Threat Models as better briefs
- diagrams created (DfDs for example) will represent reality much better than existing documentation
- It is key that Threat Models are used as ‘sources of truth’ (which are then maintained as code/architecture changes)
2.7.37 Threat Model Case Studies
- for each case study, add list of Risks that need to be added
- Examples of Case Studies to add:
- Source code, Keys and passwords stored in Developer’s laptop
- HTTP to HTTPS transition, lack of HSTS header, insecure cookies
- Homeopathic Apigee127 web service
- Smart-carts that control door access in buildings
- Login brute of accounts
- 4 version of HTML editing and Rendering
- raw HTML
- raw HTML with CSP
- using Markdown
- using Markdown with CSP
- File upload solution vs GitHub fork
- QA team with bad test environment
- Insecure APIs with vulnerable by design methods
2.7.38 Threat Model Community
There is currently (late 2016) space within the application security world to develop a community focused on Threat Modeling. Such community would allow the many parties working on Threat Modeling to share information and provide a voice to all different stakeholders.
Questions to be considered by this community include:
- What are common patterns and threats across projects?
- What do developers understand about it?
- How are Threat Models consumed by managers?
- What do we name an issue/threat/risk?
- What schema can be used to store the data?
- How to version control the artifacts created?
These questions are important because they are the ones that really allow us to plan and understand the best way to structure Threat Models.
Open up the models
At the moment, 99.9% of Threat Models exist within companies in proprietary/closed environments. This doesn’t mean that these companies don’t want to share their models. It may just be that the information isn’t in a format that is easy to share.
One of the advantages of approaching this as a community, in an open way, with clear licenses and clear open standards on how to communicate, is that it forces us to solve the problem of separating confidential data from generic public data.
This community effort will also help to resolve the issue of data versioning, which is a very complex problem.
Version the models
Today, versioning (of Threat Models) is either done using the file system (for example appending v1.x to the file name), or even worse, not done at all (note: existing Threat Models applications, desktop or online based, don’t have an historical view of data).
This is not an effective way to work, doesn’t promote collaboration and doesn’t scale.
More importantly, this way of (quasi manual) versioning of Threat Models, prevents us from understanding the evolution of a particular Threat Model.
For example, imagine a Threat Model that starts is small, then grows bigger and then shrinks again, all depending on the desired (or implemented) features. To understand the present and future threats it is important to know the past.
Let’s say that you have a particular Threat Model of a particular feature of an application that is reasonably self-contained, or in a fairly good state. However, the addition of a new feature will cause the whole thing to explode. Essentially, what you are now dealing with is a situation where the new feature has either created a number of issues, or it hosts a number of vulnerabilities. These are much easier to visualise in a state where you can actually see the new connections and the impact of the change/feature request (by the business owner).
Reviewing Threat Models is much easier when only looking at what changed since the last version.
Existing efforts
Note: OWASP currently has an active Slack channel and an inactive project on Threat Modeling
2.7.39 Threat Model Confirms Pentest
A key objective of pentest should be to validate the threat model. Pentests should confirm whether the expectations and the logic defined in the threat model are true. Any variation identified is itself an important finding because it means there is a gap in the company’s understanding of how the application behaves.
There are three important steps to follow:
- Take the threat models per feature, per layer and confirm that there is no blind spots or variations on the expectation
- Check the code path to improve the understanding of the code path and what is happening in the threat model
- Confirm that there are no extra behaviors
2.7.40 Threat Model per Feature
Creating and following a threat model for a feature is a great way to understand a threat model journey.
First, take a very specific path, a very specific new feature that you are adding, or take a property, such as a new field, or a new functionality.
Next, you want to create a full flow of that feature. Look at the entry point and the assets, and look at what is being used in that feature.
Now, you can map the inputs of the feature; you can map the data paths given by the data schema, and then you follow the data.
You can see for example how the data go into the application, what it ends up with, who calls who. This means you have a much tighter brief, and a much better view of the situation.
2.7.41 Threat Models mapped to Risks
- every risk identified in the Threat Model needs to be opened and tracked in the JIRA Risk project
- using Confluence to host the Threat Model content and have ‘live’ queries with the relevant risks (makes a massive difference in the maintainability of these Threat Models)
- When special views are needed, Jira’s JQL Queries can be used to create some of the queries
2.7.42 Draft notes - Threat Models
- Do Threat Models in layers
- identify each STRIDE issue per layer
- each layer it built on top of the previous one
- connect the threats
- map the Urls and Data objects and connect them across layers
- created ‘refactored’ and ‘collapsed’ views of the diagrams (specially when there are ‘web services that act like proxies’ in the middle)
- Introduce the concept of Sinks in Threat Modeling
- how to connect the multiple threats (one for each layer) so that they are chained
- map this concept with the concept of Attack Trees
- how to connect the multiple threats (one for each layer) so that they are chained
- Idea to create a Book focused on “Threat Modeling examples and patterns”
2.7.43 When to do a threat Model
normal development flow
1 digraph G {
2 size= "3.0"
3 node [shape=box]
4 Idea -> "Project brief"
5 -> "Scheduling"
6 -> "Development"
7 -> "QA"
8 -> "Release"
9 }
Proposed development flow
1 digraph G {
2 size= "4.5"
3 node [shape=box]
4 Idea -> "Project brief"
5 -> "Scheduling"
6 -> "Development"
7 -> "QA"
8 -> "Release"
9
10 "Project brief" -> "Threat Model" \
11
12
13 "Threat Model" -> "Option A" -> "Risks"
14 "Threat Model" -> "Option B" -> "Risks"
15 "Threat Model" -> "Option C" -> "Risks"
16 "Risks" -> "To be accepted"
17 -> "Scheduling"
18 "Risks" -> "To check implementation"
19 -> "QA"
20
21 "To check implementation" -> "Pen-test"
22 -> "Release"
23
24 }