Automatically Routing to the ‘Best’ Model Using RouteLLM Library
In the pursuit of performance, developers often default to the most powerful models available, yet this “frontier-first” approach frequently leads to unnecessary costs and latency for trivial queries. As we explore the paradigm of “Winning Big With Small AI,” the challenge becomes identifying exactly when a lightweight, local model is sufficient and when the heavy lifting of a GPT-4 or Claude 3.5 Sonnet is truly required. This chapter introduces RouteLLM, an open-source framework designed to automate this decision-making process. By using an intelligent controller to score incoming prompts, RouteLLM acts as a high-speed traffic cop, seamlessly diverting simpler tasks to your local hardware while reserving cloud-based API calls for the most complex reasoning tasks. This hybrid architecture doesn’t just save money—it optimizes the entire lifecycle of an AI application by ensuring every prompt is handled by the most efficient tool for the job.
Here we use the package https://github.com/lm-sys/RouteLLM.
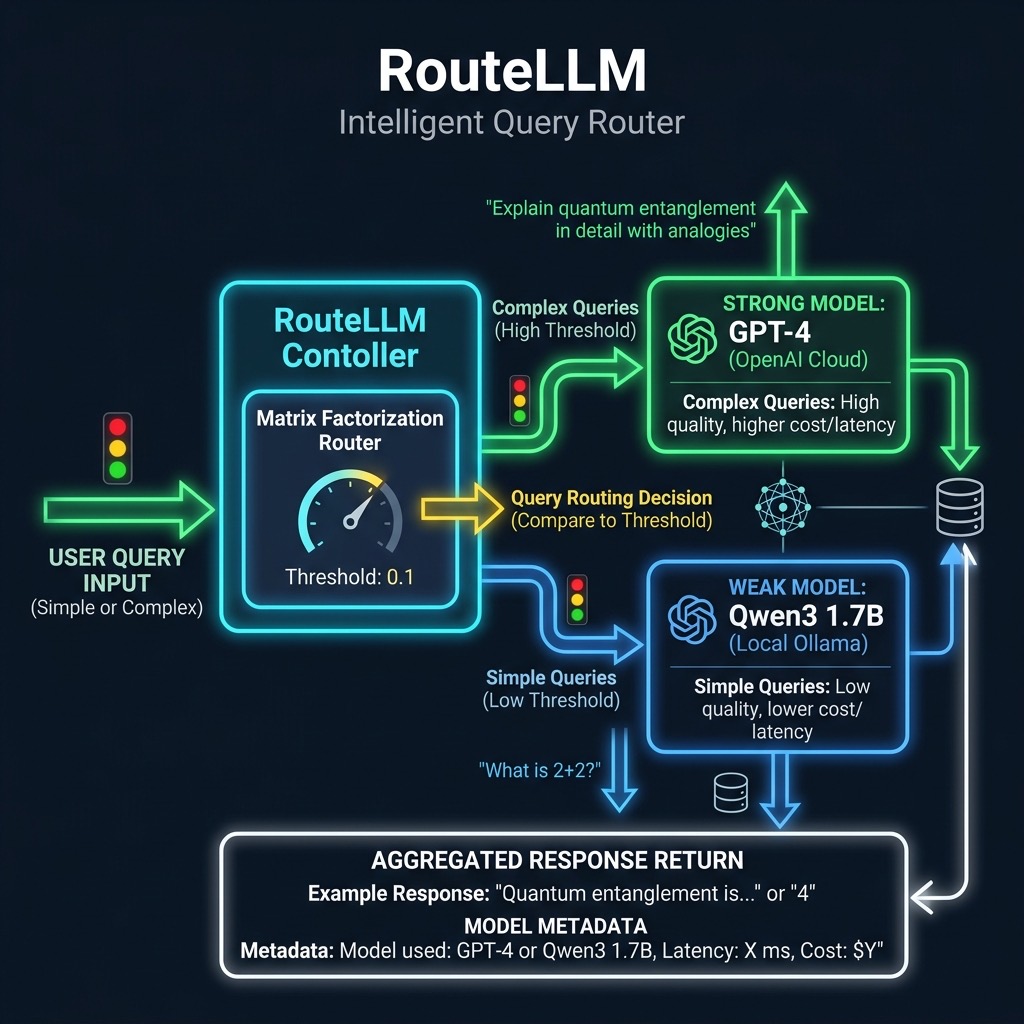
The provided Python script demonstrates how to implement an intelligent routing layer using the routellm library to optimize for both cost and performance by dynamically selecting between a high-capability “strong” model and a local “weak” model. By leveraging the Matrix Factorization (MF) router, the application evaluates the complexity of an incoming user prompt and directs it to either OpenAI’s GPT-4 for nuanced reasoning or a local Ollama instance running Qwen 3 for simpler tasks. This architectural pattern is essential for developers looking to maintain high-quality outputs while drastically reducing API latency and operational expenses, as it ensures that expensive tokens are only consumed when the difficulty of the request justifies the cost. The code covers the initial controller setup, environmental configuration for local hosting, and the execution of a threshold-based routing call that returns both the generated response and metadata identifying which model was ultimately selected to handle the query.
The implementation begins by initializing a Controller that bridges two distinct environments: the OpenAI cloud and a local Ollama server. By setting the OLLAMA_API_BASE environment variable, the script ensures that the “weak” model requests are directed to the local hardware rather than a remote endpoint. The core logic resides in the router-mf-0.1 model string, where the Matrix Factorization algorithm uses a calibrated threshold to decide if the prompt is sufficiently complex to require GPT-4.
Once the query is processed, the script prints the specific model name used for the generation alongside the response content. This transparency is crucial for debugging and fine-tuning the routing threshold, as a lower threshold will lean toward the strong model while a higher one favors the weak model. This approach provides a flexible foundation for building “local-first” AI applications that can seamlessly escalate to the frontier models when local resources reach their reasoning limits.
Implementation of a Command Line Query Utility Using RouteLLM
The following script Winning-with-Small-AI-book/source-code/auto-route/ask.py demonstrates how to implement an intelligent routing layer using the routellm library to optimize for both cost and performance by dynamically selecting between a high-capability “strong” model and a local “weak” model. By leveraging the Matrix Factorization (MF) router, the application evaluates the complexity of an incoming user prompt and directs it to either OpenAI’s GPT-4 for nuanced reasoning or a local Ollama instance running Qwen 3 for simpler tasks. This architectural pattern is essential for developers looking to maintain high-quality outputs while drastically reducing API latency and operational expenses, as it ensures that expensive tokens are only consumed when the difficulty of the request justifies the cost. The code covers the initial controller setup, environmental configuration for local hosting, and the execution of a threshold-based routing call that returns both the generated response and metadata identifying which model was ultimately selected to handle the query.
1 import sys
2 import os
3 from routellm.controller import Controller
4 import litellm
5
6 # 1. SETUP (Hardcode your preferred chain here)
7 # This example uses GPT-4 (Strong) and Ollama (Weak/Local)
8 #os.environ["OPENAI_API_KEY"] = "your-key-here"
9
10 # Set OLLAMA_API_BASE to ensure the weak model uses localhost,
11 # while the strong model (OpenAI) continues to use the official API.
12 os.environ["OLLAMA_API_BASE"] = "http://localhost:11434"
13
14 client = Controller(
15 routers=["mf"],
16 strong_model="openai/gpt-4",
17 weak_model="ollama_chat/qwen3:1.7b", # Connects to your local Ollama
18 )
19
20 print(client)
21 print(sys.argv)
22
23 # 2. GET INPUT
24 if len(sys.argv) < 2:
25 print("Usage: uv run ask.py 'Your query here'")
26 sys.exit()
27
28 query = sys.argv[1]
29
30 # 3. RUN ROUTER
31 # model THRESHOLD of 0.11593 is the default balance (~50% routing split)
32 # Making THRESHOLD smaller has the effect of perferring the stronger model.
33 # Making THRESHOLD larger has the effect of perferring the weaker model.
34
35 THRESHOLD = str(0.1) # slight preference for the stronger model
36
37 response = client.chat.completions.create(
38 model="router-mf-" + THRESHOLD,
39 messages=[
40 {"role": "system", "content": "Your answers are very concise"},
41 {"role": "user", "content": query}
42 ]
43 )
44
45 # 4. PRINT RESULT
46 print(f"[{response.model}]")
47 print(response.choices[0].message.content)
The implementation begins by initializing a Controller that bridges two distinct environments: the OpenAI cloud and a local Ollama server. By setting the OLLAMA_API_BASE environment variable, the script ensures that the “weak” model requests are directed to the local hardware rather than a remote endpoint. The core logic resides in the router-mf-0.1 model string, where the Matrix Factorization algorithm uses a calibrated threshold to decide if the prompt is sufficiently complex to require GPT-5, Claude, Gemini 3 Pro, etc.
Once the query is processed, the script prints the specific model name used for the generation alongside the response content. This transparency is crucial for debugging and fine-tuning the routing threshold, as a lower threshold will lean toward the strong model while a higher one favors the weak model. This approach provides a flexible foundation for building “local-first” AI applications that can seamlessly escalate to the frontier models when local resources reach their reasoning limits.
Optional Practice Problems
- Dynamic Threshold Tuning: Write a Python script to send a batch of 10-20 standard prompts (some simple, some highly complex) to RouteLLM using different threshold values (e.g., 0.05, 0.15, 0.3). Log the routed model for each prompt at each threshold, and analyze the trade-offs between API costs and speed.
- Local-to-Local Routing: Configure the RouteLLM controller to route between two different local models running via Ollama (e.g., a tiny model like
gemma3:1bas the “weak” model, and a larger model likeqwen3.5:9bas the “strong” model). Verify how the router handles complexity classification without any cloud calls. - Model Routing Dashboard: Create a logging mechanism that writes the user query, the routed model name, the response time, and the threshold setting to a CSV file. Use this log to compute the percentage of queries routed locally over time.