A Fair Shootout: Evaluating Large vs. Small Models for Task Fitness
Theory is useful, but engineering is built on data. In the previous chapter, we defined the scorecard: Operational Metrics (speed, cost) and Quality Metrics (smartness, faithfulness). We also covered the “judge pattern” for using a stronger model to help evaluate and tune the use of smaller models. In this chapter, we will “firm up” our methodology for evaluating different models for fitness for RAG tasks.
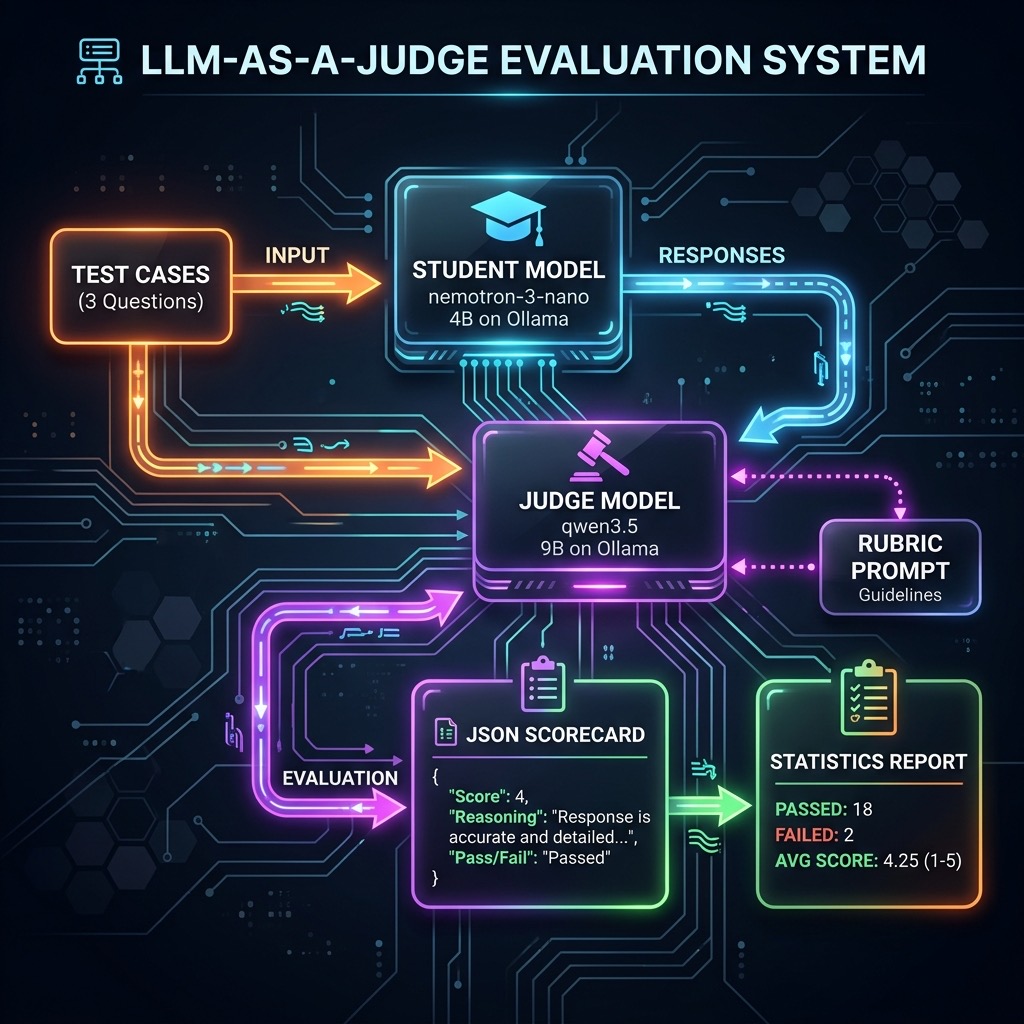
The Setup for RAG: David vs. Goliath
Let’s consider a “shootout” to compare the two models, large vs. small:
- The Goliath (Cloud Baseline): GPT-5 or Gemini-3-pro (via API). Powerful, easy to start, but expensive at scale and slower due to network round-trips.
- The David (Small AI Candidate): rnj-1-8B, gemma3-1B, or Llama-3-8B, running locally on a consumer-grade GPU (NVIDIA RTX 4090) or on Apple Silicon.
If we run a test set of 200 typical user questions through both systems the resource costs will be much lower when we use prompt caching.
We evaluate operational metrics:
- TTFT (latency)
- Cost of 10K requests/day
- Privacy
We also evaluate quality metrics (how “smart” is the model) using RAG testing:
- Context precision: How well did we find the best (or at least a good) document?
- Faithfulness: Given retrieved documents, his well did the model stick to the facts provided in preparing a summary or answer?
- Answer relevance: Did the model answer the user’s question?)
Fairness: Adjusting Problem Setups for Small vs. Large Models
When conducting a shootout between a massive frontier model and a local Small AI model, a naive “apples-to-apples” comparison can be misleading. Using the exact same prompt and context window for both often biases the results in favor of the larger model, which generally possesses better instruction-following resilience for poorly structured inputs. To conduct a fair engineering assessment, you must adjust the setup to allow each model to perform at its peak potential.
Prompt Divergence
Large models are excellent at interpreting “lazy” or conversational prompts. You can ask GPT-5, “Check this doc and tell me if it’s okay,” and it will likely infer your intent. A 7B parameter model, however, may get confused by the ambiguity:
- The Unfair Test: Using a single, vague prompt for both models.
- The Fair Test: Optimize the prompt for each model. The large model gets the conversational prompt; the Small AI gets a structured, specific instruction (e.g., “Analyze the text below. List any errors in grammar or factual consistency. Output JSON.”). We are comparing the best possible version of the Small AI system against the large one, not their ability to guess intent.
Context Window and “Lost in the Middle”
While a frontier model might handle a 128k token context window with ease, smaller models often degrade in performance as the context fills up, suffering from the “Lost in the Middle” phenomenon where information in the center of the prompt is ignored:
- The Unfair Test: Stuffing 50 documents into the context window of an 8B model and expecting it to find a needle in the haystack.
- The Fair Test: Adjusting the RAG (Retrieval Augmented Generation) strategy. For the Small AI, you might retrieve fewer, more relevant chunks (e.g., Top-3 matches instead of Top-10) or use a “reranker” step to ensure the most critical data is at the beginning or end of the context.
In summary, fairness does not mean “identical inputs.” It means “identical goals.” If the goal is to answer a user question, you should allow the Small AI architecture to use tighter prompts and focused context retrieval to achieve that goal, rather than penalizing it for not being a generalist giant.
Comparing Small vs. Large Models for NLP and Extracting Structured Data From Text
Now we look at specific text processing tasks—like summarizing text (NLP) or turning documents or emails into clean JSON (Structured Data Extraction). The performance gap between small and large models changes shape entirely. The “best” model depends heavily on whether the task requires world knowledge or mechanical consistency.
NLP Tasks: The Battle for Nuance
For general Natural Language Processing tasks like summarization, sentiment analysis, and tone adjustment, the sheer parameter count of large models often provides a distinct advantage in handling subtlety:
- Large models (Abstractive Power): Large models excel at “abstractive” tasks—reading a text and rewriting it with a new flow or voice. If you ask GPT-5 to “summarize this technical report in the style of a distinct 1940s noir detective,” it draws on a vast cultural training set to nail the stylistic nuance.
- Small models (Extractive Utility): Small models often struggle with high-concept stylistic shifts. However, they are highly effective at “extractive” tasks—identifying the key sentences and condensing them. For a business use case (e.g., “Summarize the three main blockers in this meeting transcript”), a fine-tuned 8B model is often indistinguishable from the frontier model, provided the prompt is direct.
Dear reader, for my own work and experiments, I usually use Large AI for reviewing what I write, studying and understanding philosopy, and deep research. I use Small AI for factual summarization, classification, data processing, and routing.
Extracting Structured Data: The Small AI Sweet Spot
Extracting structured data (converting unstructured text into JSON, CSV, or SQL) is arguably a “killer app” for Small AI. This task does not require reasoning about the meaning of the universe; it requires strict adherence to syntax and pattern matching.
Surprisingly, small models often rival or even outperform larger generalist models in this domain when properly constrained, largely because they are less prone to “chatty” deviations:
- The Mechanics of Extraction: If you need to parse 10,000 resumes to extract “Name,” “Years of Experience,” and “Education,” a massive model is overkill. The reasoning required to identify a date or a university name is low-level.
- Constrained Decoding (Grammars): The equalizer for Small AI in this arena is constrained decoding (often available in local runtimes like llama.cpp). You can force a local model to output only valid JSON schema tokens.
Important technique: In almost all cases, you must dear reader, provide one or two examples of the format and style of the JSON output you need and specify that you only want JSON data returned. You must also provide “guard-rail code” to strip off Markdown formatting and use a JSON parsing library to make sure that each JSON output is legally formatted and log and errors. Here is an example prompt with sample User Input at the end:
1 System Instruction: You are a helpful assistant that extracts data from text. Output ONLY valid JSON. Do not include Markdown formatting (like ```json), explanations, or conversational filler.
2
3 Example 1:
4
5 Input: "I have a meeting with Alice in Engineering on Friday at 3 PM regarding the API migration."
6
7 Output: { "event_type": "meeting", "participants": ["Alice"], "department": "Engineering", "time": "15:00", "topic": "API migration" }
8
9 Process this user Input:
10
11 "Please schedule a lunch with Bob and Mary from HR at 1PM to discuss the new hiring guidelines."
We would expect output like:
1 { "event_type": "lunch",
2 "participants": ["Bob", "Mary"],
3 "department": "HR", "time": "13:00",
4 "topic": "new hiring guidelines" }
For evaluating large vs. small models it might be sufficient to define this prompt as a template and test it for a small number of test cases and hand score the outputs from both small and large models you are evaluating.
If you have a large number of test cases, you can automate the small vs. large model evaluation by writing a test harness that captures the percentage of test cases for which the models fails to output valid JSON. Given a set of test cases that fail, spend the time to iterate on the prompt template you are using for your data extraction project.
Verdict: For high-volume data extraction, Small AI is usually superior. It is significantly faster, orders of magnitude cheaper, and when paired with grammar constraints, it offers higher reliability for automated pipelines.
Wrap Up for Evaluating Large vs. Small Models for Task Fitness
Dear reader, this is my opinion: Evaluating AI is no longer about chasing state-of-the-art benchmarks on generic leaderboards; it is about “fitness for purpose” and not any purpose, but specifically fitness to your requirements. By rigorously applying metrics—measuring TTFT for speed, RAGAS scores for quality, and watts for efficiency then you can quantify exactly what different models are trading off. Often evaluations show that a well-prompted local 8B model could deliver a “good enough” experience that was satisfactory in every operational dimension. The lesson for your projects is clear: define your pass/fail criteria first, then optimize downward to the smallest, fastest model that can clear that bar.