Общая информация
В этом разделе мы рассмотрим основные принципы работы компьютера. Начнём с операционных систем и истории их возникновения. Познакомимся с возможностями и семействами современных ОС. Затем рассмотрим, что представляет собой компьютерная программа, как она запускается и исполняется.
Операционные системы
Предпосылки возникновения ОС
Большинство пользователей компьютера понимает, зачем нужна операционная система (ОС). Покупая или загружая из интернета приложение, вы проверяете его системные требования. В них указаны минимальные параметры аппаратной части компьютера. Кроме этого в требованиях указана ОС.
Получается, что ОС — это программная платформа на которой работают приложения. Но откуда взялось это требование? Почему нельзя просто купить компьютер и запустить на нём приложение без ОС?
Эти вопросы кажутся бессмысленными только на первый взгляд. Подумайте сами: современные ОС универсальны и предлагают пользователю множество функций. Большинство из них каждому конкретному пользователю не нужно. Но эти функции зачастую невозможно отключить. Для их обслуживания ОС активно использует ресурсы компьютера. В результате приложениям пользователя достаётся меньше ресурсов. Из-за этого они работают медленно и зависают.
Обратимся к истории, чтобы выяснить назначение ОС. Первая коммерческая ОС GM-NAA I/O появилась только в 1956 году для компьютера IBM 704. Все ранние модели компьютеров обходились без ОС. Почему в них не было необходимости?
Главная причина заключается в быстродействии. Для примера рассмотрим первый электромеханический компьютер. Его сконструировал Герман Холлерит в 1890 году. Компьютер получил название табулятор. Для работы ему не нужна ОС и программы в современном смысле этих терминов. Табулятор выполняет ограниченный набор арифметических операций. Эти операции определяет конструкция компьютера. Данные для вычислений загружаются с перфокарт. Перфокарты представляют собой листки плотной бумаги с пробитыми отверстиями. Оператор компьютера вручную подготавливает и укладывает эти листки в специальные приёмные устройства. Там они нанизываются на иглы. В местах отверстий иглы соприкасаются и электрическая цепь замыкается. Каждое замыкание увеличивает механический счётчик. Счётчиком служит вращающийся цилиндр. Результаты вычислений выводятся на циферблаты, напоминающие часы.
Иллюстрация 1-1 демонстрирует табулятор, построенный Германом Холлеритом.

По современным меркам вычисления на табуляторе выполняются очень медленно. Первая причина заключается в ручном обслуживании. Оператор должен самостоятельно пробить перфокарты. Во времена табулятора не было способа делать это автоматически. Далее надо загрузить перфокарты в приёмное устройства и выгрузить их по окончании работы. На эти действия уходило много времени.
Вторая причина медленной работы табулятора связана с конструкцией. Большая часть его деталей механическая: иглы для считывания данных, счётчики из вращающихся цилиндров, циферблаты для вывода результата. Вся эта механика работает медленно. Выполнение одной элементарной операции занимает порядка одной секунды. Никакая автоматизация не способна ускорить такой процесс вычисления.
Для вычислений табулятор использует вращающиеся цилиндры. Их заменили на реле в компьютерах следующего поколения. Реле — это электромеханический элемент. Он меняет своё состояние под воздействием электрического тока.
Один из первых релейных компьютеров Z2 сконструировал немецкий инженер Конрад Цузе в 1939 году. Этот компьютер был усовершенствован в 1941 году и получил название Z3. Переход на реле сократил время выполнения одной элементарной операции до нескольких миллисекунд.
Кроме возросшей скорости вычислений, компьютеры Цузе отличает ещё одна особенность. В них появилось понятие программы. Теперь на перфокартах пробивались не исходные данные задачи, а алгоритм её решения. Для ввода данных использовалась клавиатура. Её конструкция отдалённо напоминает печатную машинку.
Компьютеры с возможностью ввода алгоритмов стали известны как программируемые или универсальные.
Появление программируемых компьютеров стало важным шагом в развитии вычислительной техники. Машины предыдущих поколений выполняли только узкоспециализированные задачи. Их создание обходилось дорого и редко себя оправдывало. Поэтому проекты по конструированию компьютеров не привлекали инвесторов. Такие проекты ограничивались военными разработками в годы Второй мировой войны. Новые универсальные компьютеры заинтересовали бизнес.
Следующим шагом развития компьютеров стало создание ENIAC (см. иллюстрацию 1-2). Его сконструировала группа инженеров под руководством Джона Эккерта и Джона Мокли в 1946 году. Его рабочими элементами стали не реле, а электровакуумные лампы. То есть электромеханические компоненты с большим временем отклика заменили на более быстрые электронные. Это увеличило быстродействие компьютера на порядок. Время выполнения одной элементарной операции сократилось до 200 микросекунд.

В 1940-е годы многие инженеры скептически относились к электровакуумным лампам. Они были не надёжны и потребляли много энергии. Мало кто верил, что сконструированная на них машина вообще сможет работать. ENIAC использовал около 18000 ламп. Они часто выходили из строя. Но между отказами компьютер успешно справлялся с вычислениями. ENIAC убедил многих конструкторов в перспективности ламп.
ENIAC — это программируемый компьютер. В нём алгоритм вычислений задаётся с помощью комбинации переключателей и перемычек на коммутационных панелях. Такое программирование требует много времени и сил. С ней может справиться только группа операторов. На иллюстрации 1-3 изображена одна из панелей для программирования ENIAC.

ENIAC использует перфокарты для ввода исходных данных и вывода результатов. Предыдущие модели компьютеров обрабатывали ввод-вывод аналогично. Но в ENIAC появилась новая возможность. Перфокарты могли хранить промежуточные расчёты. Если исходная задача не решалась сразу из-за высокой сложности, она разбивалась на несколько подзадач. После выполнения каждой подзадачи её результаты выгружались на перфокарты. Затем компьютер перепрограммировался. После этого перфокарты загружались обратно в качестве входных данных.
Опыт эксплуатации ENIAC показал, что производительность компьютера ограничивают все механические операции. Например, ручное перепрограммирование с помощью переключателей и перемычек, а также чтение и пробивание перфокарт. ENIAC обладал небывалой по тем временам производительностью. Но несмотря на это, прикладные задачи решались на нём медленно. Большую часть времени компьютер простаивал, ожидая программы или входных данных. Опыт работы с ENIAC привел к разработке новых средств ввода и вывода данных.
Следующий скачок производительности компьютеров произошёл после перехода с электровакуумных ламп на транзисторы. Вместе с усовершенствованными средствами ввода-вывода это привело к более интенсивной эксплуатации компьютеров и их частому перепрограммированию.
С приходом транзисторов вычислительные машины распространились за пределы военных проектов. Их стали использовать крупные банки и корпорации. В результате возросло число и разнообразие запускаемых программ.
Коммерческое использование компьютеров потребовало исключить простой оборудования. Любые задержки в исполнении программ приводили к финансовым потерям. В этом случае покупка компьютера не оправдывала себя.
Чтобы удовлетворить новым требованиям, требовались новые решения. Дольше всего компьютеры простаивали в ожидании переключения между программами. Идея автоматизировать этот процесс пришла к инженерам General Motors и North American Aviation. Они разработали первую операционную систему GM-NAA I/O в 1955 году. Эта ОС позволила выполнять программы друг за другом без помощи оператора.
Интенсивное использование компьютеров и разнообразие программ привело к ещё одной проблеме. Загруженная программа определяла доступные возможности аппаратуры. Например, если программа содержит код управления устройствами ввода-вывода, они доступны. В противном случае устройства не работают.
Компании покупали один компьютер и использовали его продолжительное время. При этом загружаемые программы менялись часто, но аппаратура оставалась неизменной. В результате код управления аппаратурой менялся редко. Программисты просто копировали его из одной программы в другую.
Постоянное копирование кода управления устройствами привело к идее создания служебной программы. Она загружалась в память компьютера вместе с основной программой и обеспечивала поддержку оборудования. Постепенно эти служебные программы вошли в состав первых ОС.
Вернёмся к нашему вопросу о необходимости операционных систем. Мы выяснили, что приложения могут работать и без них. Такие программы используются и сегодня. Например, это утилиты проверки памяти и разбивки диска, а также некоторые антивирусы. Однако, разработка таких программ требует больше времени и сил. В них приходится включать код для поддержки оборудования, который обычно предоставляет ОС. Разработчики предпочитают использовать возможности ОС. Это уменьшает объём работы и ускоряет выпуск программы.
Современные ОС очень сложны. Кроме поддержки оборудования и запуска программ, они предоставляют много других возможностей. Рассмотрим их подробнее.
Возможности ОС
Почему мы начали изучать программирование с обсуждения операционных систем? Возможности ОС являются фундаментом для любой программы.
Иллюстрация 1-4 демонстрирует схему взаимодействия ОС с прикладными программами и аппаратным обеспечением. Прикладные программы — это приложения, которые решают задачи пользователя. Примеры приложений: текстовый редактор, калькулятор, браузер. Аппаратным обеспечением называются все электронные и механические компоненты компьютера. Среди этих компонентов клавиатура, монитор, центральный процессор, видеокарта.
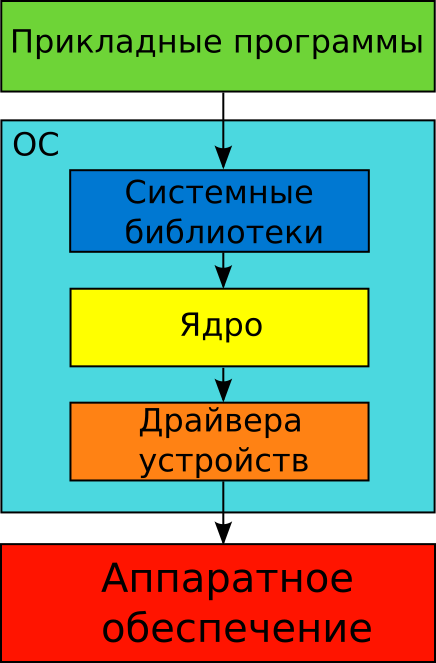
Рассмотрим схему. Приложения обращаются к аппаратным ресурсам не напрямую, а через системные библиотеки. Эти библиотеки являются частью ОС. Для работы с ними приложение должно следовать строгим правилам.
Интерфейс прикладного программирования определяет правила работы приложения с системными библиотеками. Он также известен как API (Application Programming Interface).
Интерфейс — это набор соглашений о взаимодействии компонентов информационной системы. Такие соглашения со временем превращаются в стандарты. Например, POSIX стандарт описывает переносимый API для целого семейства ОС. Стандарты важны, поскольку гарантируют совместимость компонентов системы.
Помимо системных библиотек ОС включает в себя ядро и драйвера устройств. Они определяют какие возможности аппаратуры доступны приложению. Драйвер — это специальная программа, которая предоставляет доступ к устройству. Когда приложение обращается к системной библиотеке, библиотека перенаправляет запрос в ядро ОС или драйвер. В некоторых случаях библиотека может выполнить запрос самостоятельно.
При обращении к системной библиотеке приложение вызывает одну из её функций. Функция — это фрагмент программы, который выполняет одну задачу. Представьте себе API как набор всех функций, доступных приложению. Кроме этого API определяет следующие аспекты взаимодействия приложения с ОС:
- Какую операцию выполнит ОС при вызове конкретной системной функции?
- Какие данные функция ожидает на вход?
- Какие данные функция вернёт в качестве результата?
Следовать интерфейсу должна как ОС, так и приложение. Например, в документации к API сказано: “ОС создаёт файл при вызове функции X”. Не зависимо от версии, ОС всегда должна следовать этому правилу. Оно гарантирует совместимость разных версий приложений и ОС. Такая совместимость невозможна без хорошо документированного и стандартизированного интерфейса.
Мы уже выяснили, что приложения могут работать без ОС. Однако, ОС предлагает готовые решения для работы с аппаратными ресурсами компьютера. Без этих решений разработчики приложений берут на себя работу с оборудованием. Такой подход требует много времени и сил. Представьте всё разнообразие комплектующих современных компьютеров. Приложение должно поддерживать все модели устройств (например, видеокарт). В противном случае оно не заработает у некоторых пользователей.
Рассмотрим возможности, которые предоставляет ОС через API интерфейс. Все электронные и механические компоненты компьютера можно рассматривать как ресурсы. Программы используют эти ресурсы для вычислений. Другими словами аппаратное обеспечение выполняет программы. API отражает возможности оборудования, которые доступны программе. Также интерфейс определяет порядок взаимодействия между несколькими программами и оборудованием.
Например, две программы не могут одновременно записывать данные на жёсткий диск в одну и ту же область. На это есть две причины:
- Запись выполняется единственной магнитной головкой жёсткого диска. Она выполняет одну операцию за раз.
- После записи данных первым приложением их может затереть второе приложение.
Чтобы избежать ошибок при записи, запросы к диску надо упорядочить. Обычно их помещают в очередь и исполняют друг за другом. За это отвечает ОС, а точнее её ядро (см. иллюстрацию 1-4).
В ядре реализован механизм для управления доступом к жёсткому диску. Этот механизм называется файловой системой. Похожим образом ОС упорядочивает доступ ко всем периферийным и внутренним устройствам компьютера. Этот доступ предоставляют драйвера устройств.
Что такое периферийные устройства, и чем они отличаются от внутренних? К периферийным относятся все устройства, отвечающие за ввод-вывод информации и её постоянное хранение. Вот несколько примеров:
- Клавиатура
- Мышь
- Микрофон
- Монитор
- Колонки
- Жёсткий диск
Внутренние устройства отвечают за обработку информации, то есть непосредственное исполнение программ. К ним относятся:
- Центральный процессор (central processing unit, CPU)
- Оперативная память (random-access memory, RAM)
- Видеокарта (graphics processing unit, GPU)
Доступ к аппаратным ресурсам — это одна из возможностей ОС. Кроме аппаратных есть ещё и программные ресурсы самой ОС. Это повторяющийся код, ставший со временем служебными программами. Впоследствии его оформили в системные библиотеки (см. иллюстрацию 1-4). Некоторые из библиотек обслуживают устройства. Другие выполняют сложные алгоритмы для обработки данными.
Например, у Windows есть компонент под названием интерфейс графических устройств (Graphical Device Interface или GDI). Он позволяет приложению манипулировать графическими объектами. Используя GDI, разработчики создают пользовательский интерфейс для своих программ.
Системные библиотеки с полезными алгоритмами (например, GDI) являются программными ресурсами ОС. Они уже установлены на вашем компьютере и готовы к использованию. Кроме них ОС предоставляет доступ к алгоритмам сторонних приложений и библиотек.
ОС не только управляет ресурсами. Она организует совместную работу нескольких приложений. Их запуск — уже нетривиальная задача. Её выполняет служебная программа ОС. После запуска приложения, ОС контролирует его выполнение. Если приложение нарушает какое-то ограничение, его принудительно завершают. Например, нарушением считается чтение недоступной памяти. В следующем разделе мы подробно рассмотрим запуск и исполнение программы.
Если ОС многопользовательская, она контролирует доступ к данным. Благодаря этому, каждый пользователь может работать только со следующими объектами файловой системы:
- Файлы и каталоги, принадлежащие пользователю.
- Файлы и каталоги, к которым кто-то предоставил доступ.
Подведём итог. Современная ОС выполняет следующие функции:
- Предоставляет и упорядочивает доступ к аппаратным ресурсам компьютера.
- Предоставляет собственные программные ресурсы в виде системных библиотек.
- Запускает приложения.
- Организует взаимодействие приложений друг с другом.
- Контролирует доступ пользователей к данным.
Посмотрите внимательно на перечисленные функции ОС. Наверное, вы догадались, что без ОС нельзя запустить несколько приложений одновременно. Проблема в том, что их разработчики не знают, в каком сочетании программы будут выполняться. Только ОС имеет достаточно информации, чтобы эффективно распределить ресурсы компьютера.
Современные ОС
Мы познакомились с основными возможностями ОС. Теперь рассмотрим современные ОС. Выберите любую из них, и вы получите примерно одни и те же функции. Основные отличия заключаются в способах реализации этих функций. Такие особенности реализации и решения, которые к ним привели, называются архитектурой.
У современных ОС есть две особенности. Они определяют поведение системы и способ её взаимодействия с пользователем. Речь идёт о многозадачности и графическом интерфейсе. Рассмотрим их подробнее.
Многозадачность
Большинство современных ОС многозадачны. Это означает, что они исполняют несколько программ одновременно. Системы с этим свойством вытеснили ОС без него. Почему это свойство оказалось таким важным?
В 1960-е годы возникла проблема эффективного использования компьютеров. В то время они представляли собой шкафы с электроникой и стоили дорого. Компьютер такого типа называется мейнфреймом. Только крупные компании и университеты могли позволить себе такое оборудование. Из-за высокой цены любой простой компьютера был неприемлем.
Первые операционные системы исполняли программы друг за другом без задержек. В таких ОС программы и их входные данные подготавливались заранее. Они записывались на устройство хранения (например, магнитную ленту). Эта лента подавалась на устройство ввода. Компьютер последовательно исполнял программы и выводил их результаты на устройство вывода (например, принтер). Такой режим работы называется пакетная обработка (batch processing). Его главное преимущество — экономия времени на переключение между задачами.
Пакетная обработка позволила эффективно использовать мейнфреймы в 1960-е годы. Она автоматизировала загрузку программ. Оператор стал не нужен для этой работы. Однако, у системы оставалось узкое место. Вычислительная мощность процессоров значительно возрастала ежегодно. Скорость работы периферийных устройств почти не менялась. Из-за этого процессор быстро выполнял вычисления и дальше ждал ввода-вывода данных. Таким образом компьютер работал не на полную мощность.
Почему процессору приходится ждать периферийные устройства? Рассмотрим пример. Представьте, что мейнфрейм последовательно выполняет программы. Он считывает данные с магнитной ленты и печатает результаты на принтере. ОС загружает программу и исполняет её инструкции. Затем загружается следующая программа и так далее.
Проблема возникает на этапах чтения данных и печати результата. Время доступа к данным на магнитной ленте огромно в масштабах центрального процессора. Между двумя операциями чтения, он успел бы выполнить ряд вычислений. Но он этого не делает. Причина в том, что все ресурсы компьютера использует только одна программа. Она загружена в память в данный момент. То же происходит при выводе результатов на печать. Принтер — это электромеханическое устройство. Поэтому он работает очень медленно.
Проблема простоя центрального процессора привела к идее мультипрограммирования. Суть идеи в одновременной загрузке нескольких программ в память компьютера. Первая из них выполняется до тех пор, пока доступны все необходимые ей ресурсы. Как только один из ресурсов оказывается занят, выполнение программы останавливается. Тогда ОС переключается на следующую программу.
Рассмотрим пример переключения программ. Предположим, что приложение читает данные с жёсткого диска. Пока контроллер диска читает первую часть данных, он занят и не может обработать запрос на чтение следующей части. Поэтому приложение ожидает, когда освободится контроллер. ОС останавливает работу приложения и переключается на другую программу. Она исполняется до конца или до момента, когда нужный ей ресурс окажется занят. После этого ОС опять переключается на другую программу.
Мультипрограммирование стало прототипом многозадачности, которую используют современные ОС. Мультипрограммирование хорошо справляется с режимом пакетной обработки. Однако, этот принцип распределения нагрузки не подходит для систем с интерактивным взаимодействием. В таких системах действия пользователя являются событиями. Например, нажатие клавиши. ОС должна обработать каждое событие сразу. Если не выполнить это требование, пользователь не сможет работать с системой.
Рассмотрим пример работы с интерактивной системой. Представьте, что вы набираете текст в редакторе MS Office. Вы нажимаете клавишу и ожидаете, что соответствующий символ отобразится на экране. Если задержка между нажатием и отображением увеличится до нескольких секунда, вы не сможете эффективно работать. Большую часть времени вы будете ожидать отображение символа, а не набирать текст. Печатать вслепую не получится из-за возможных ошибок.
Мультипрограммирование не справляется с обработкой событий в интерактивных системах. Причина в том, что момент переключения задач непредсказуем. Переключение происходит при завершении программы или её обращении к занятому ресурсу. Представьте, что редактор MS Office не активен в данный момент. Тогда вы не можете предсказать, когда он обработает нажатие клавиши. Это может случиться через секунду или несколько минут. Такое поведение неприемлемо для интерфейса пользователя.
Многозадачность решает проблему быстрого отклика в интерактивных системах. Способ её реализации постепенно развивался и усложнялся. В современных ОС применяется вытесняющая многозадачность с псевдопараллельной обработкой задач. Это означает, что ОС самостоятельно выбирает программу для выполнения. При выборе учитываются приоритеты всех запущенных приложений. Более приоритетные приложения получают аппаратные ресурсы чаще, чем низкоприоритетные. Механизм переключения задач реализован в ядре ОС. Он называется планировщиком задач.
Псевдопараллельность означает, что в каждый момент времени выполняется только одна задача. При этом ОС переключается между задачами так быстро, что пользователь этого не замечает. Ему кажется, что компьютер выполняет одновременно несколько программ. Но на самом деле, каждая программа и компонент ОС получают аппаратные ресурсы в строго определённые моменты времени. Такой подход позволяет ОС немедленно реагировать на любое действие пользователя.
Одновременное выполнение программ возможно только на компьютерах с несколькими процессорами или с многоядерными процессорами. На таких компьютерах число одновременно работающих программ примерно равно числу ядер всех процессоров. При этом также применяется механизм вытесняющей многозадачности с постоянным переключением задач. Он универсален и балансирует нагрузку на любых системах, независимо от числа ядер. Так выдерживается приемлемое время отклика на действия пользователя.
Интерфейс пользователя
Современные ОС решают широкий круг задач. В зависимости от задачи выбирается компьютер и ОС к нему. Вот основные типы современных компьютеров:
- Персональные компьютеры (ПК) и ноутбуки.
- Мобильные телефоны и планшеты.
- Сервера.
- Встраиваемые системы.
Мы рассмотрим ОС только для ПК и ноутбуков. Помимо механизма многозадачности они предоставляют графический интерфейс пользователя (graphical user interface или GUI). Здесь термин интерфейс означает способ взаимодействия человека с системой. Так пользователь запускает приложения, настраивает устройства компьютера и компоненты ОС. Рассмотрим подробнее историю возникновения графического интерфейса.
До 1960 года коммерческие компьютеры не имели интерактивного режима работы. Его впервые реализовала компания Digital Equipment Corporation для своего нового мини-компьютера PDP-1 в 1959 году. Это был принципиально новый подход к работе с компьютером.
До появления PDP-1 на рынке доминировали мейнфреймы от IBM. Это продолжалось все 1950-е годы. Мейнфреймы работали в режиме пакетной обработки и хорошо справлялись с вычислительными задачами. Их операционные системы с поддержкой мультипрограммирования автоматизировали загрузку программ и обеспечивали высокую производительность. Но этих возможностей не хватало для новых задач с которыми столкнулись компьютерные инженеры.
Идея интерактивной работы с компьютером появилась при разработке военного проекта SAGE. Он выполнялся по заказу ВВС США. ВВС была нужна автоматизированная система ПВО для обнаружения советских бомбардировщиков.
Инженеры проекта SAGE столкнулись с проблемой. Оператор системы должен был получать данные с радаров в реальном времени. Если он замечал угрозу, он отдавал команду на перехват бомбардировщиков. Однако, существующие тогда методы работы с компьютером не подходили для этой задачи. Они не позволяли выводить информацию в реальном времени и обрабатывать ввод пользователя в любой момент.
Тогда инженеры SAGE предложили идею нового способа работы с компьютером. Его назвали интерактивный режим. Этот режим использовал компьютер AN/FSQ-7 (см иллюстрацию 1-5). Его разработали в рамках проекта для управления системой ПВО. Данные с радаров выводились на электронно-лучевой монитор. Оператор давал команды с помощью светового пера.

Метод интерактивной работы с компьютером стал известен и популярен в научных кругах. Пакетная обработка успешно справлялась с выполнением программ. Но в этом режиме их разработка и отладка была неудобной.
Вот как выглядела разработка программы для мейнфрейма. Программист составлял алгоритм и записывал его на устройство хранения. Это устройство он передавал оператору компьютера. Оператор добавлял задачу на выполнение программы в очередь. Ожидание в очереди занимало часы. Если программа исполнялась с ошибкой, программист её исправлял и снова ожидал свой очереди на исполнение. В результате тестирование даже небольшой программы занимало дни.
Интерактивный режим полностью изменил процесс разработки программ. Теперь программист мог запустить программу и сразу получить её результат. Такой процесс на порядок ускорил разработку и отладку приложений. За несколько часов выполнялась работа, требовавшая раньше нескольких дней.
Интерактивный режим работы повысил требования к ОС. Теперь она должна сразу реагировать на действия пользователя. Новый механизм многозадачности решил эту проблему.
Интерактивный режим поддерживают не только многозадачные ОС, но и однозадачные. Пример такой системы — MS-DOS. Её разработала компания Microsoft для относительно дешёвых персональных компьютеров 1980-х годов.
Интерактивный и однозадачный режимы можно совместить. Однако, такое решение не применялось для мейнфреймов 1960-х годов. Причина в том, что выделять все ресурсы мейнфрейма для одной программы было слишком дорого. Вместо этого применялся режим разделение времени (time-sharing). Он позволял нескольким пользователям работать с компьютером одновременно.
Когда в 1980-х появились первые персональные компьютеры, на них устанавливались однозадачные ОС. Эти компьютеры уступали по производительности мейнфреймам. Их аппаратных ресурсов не хватало для запуска многозадачных ОС того времени. Однозадачные ОС были проще и не так требовательны к производительности. Несмотря на свою простоту, они поддерживали интерактивную работу. Этот режим стал особенно привлекательным для пользователей ПК.
Для интерактивного режима понадобился новый способ балансировки нагрузки системы. Кроме этого надо было заменить существующие устройства ввода-вывода: магнитные ленты и принтеры. Их использовали на протяжении 1950-х и в начале 1960-х годов. Для нового интерактивного режима они не подходили.
Телетайп (teletype) стал прототипом устройства для интерактивной работы с компьютером. Иллюстрация 1-6 демонстрирует телетайп Model 33. Он представляет собой электромеханическую печатную машинку. С помощью проводов она подключается к такой же машинке. После соединения двух телетайпов их операторы могут передавать друг другу текстовые сообщения. Отправитель набирает текст на своём устройстве. Нажатия клавиш передаются на устройство получателя. Оно печатает каждую принятую букву на бумаге.

Телетайп стали подключать к мейнфреймам. На его клавиатуре пользователь набирал команды. Мейнфрейм их получал, исполнял и отправлял результат обратно. Этот результат печатался на бумаге. Такой способ взаимодействия с компьютером стал известен как интерфейс командной строки (command-line interface или CLI).
В качестве устройства вывода телетайп использует принтер. Он работает медленно. Вывод одной строки занимает около 10 секунд. Со временем принтер заменили на монитор. Это ускорило вывод данных в несколько раз. Новое устройство с клавиатурой и монитором получило название терминал. Он вытеснил телетайпы в 1970-х годах.
Иллюстрация 1-7 демонстрирует современный интерфейс командной строки. Перед вами окно эмулятора терминала. Это приложение имитирует настоящий терминал. Он нужен для работы некоторых программ. Благодаря эмулятору решается задача совместимости этих программ и современной ОС.
Эмулятор терминала на иллюстрации 1-7 называется Terminator. В нём запущен интерпретатор командной строки Bash. Интерпретатор выполнил программы ping и ls. Вы видите их результаты в окне терминала.
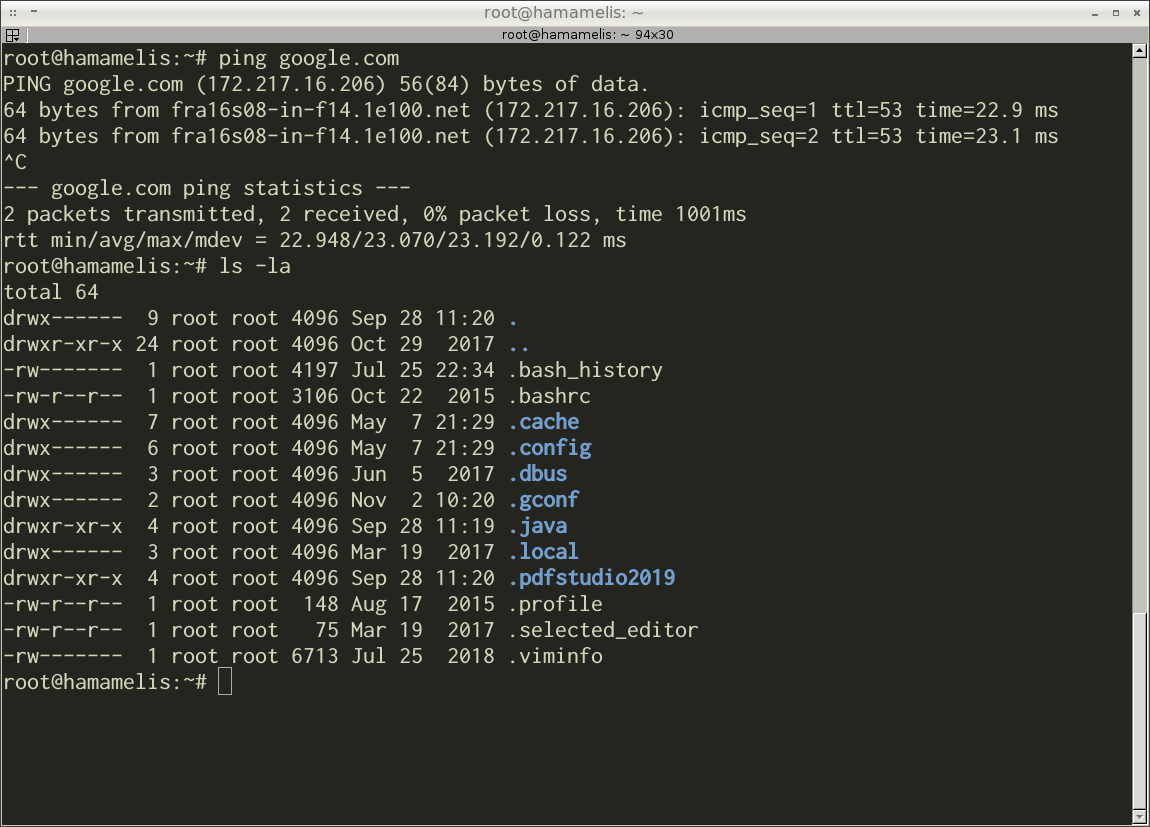
Интерфейс командной строки появился в середине 1960-х. Однако, он востребован и сегодня. У него есть ряд преимуществ по сравнению с графическим интерфейсом. Одно из них — низкие требования к вычислительным ресурсам. CLI надёжно работает и на низкопроизводительных встраиваемых компьютерах, и на мощных серверах. Если использовать CLI для удалённого доступа к компьютеру, скорость соединения может быть низкой. Сервер всё равно получит команды пользователя.
У интерфейса командной строки есть и недостатки. Главная его проблема в сложности освоения. Пользователю доступны сотни команд. У каждой из них есть несколько входных параметров. Эти параметры задают разные режимы работы. Чтобы запомнить хотя бы основные команды и их режимы, нужно время и практика.
Проблему наглядного представления доступных команд решает текстовый интерфейс пользователя (textual user interface или TUI). В нём наряду с буквенными и цифровыми символами используется псевдографика. Псевдографикой называются специальные символы для изображения графических примитивов. Примитивы — это линии, прямоугольники, треугольники и т.д.
Иллюстрация 1-8 демонстрирует пример текстового интерфейса. Это вывод статистики использования системных ресурсов программой htop.
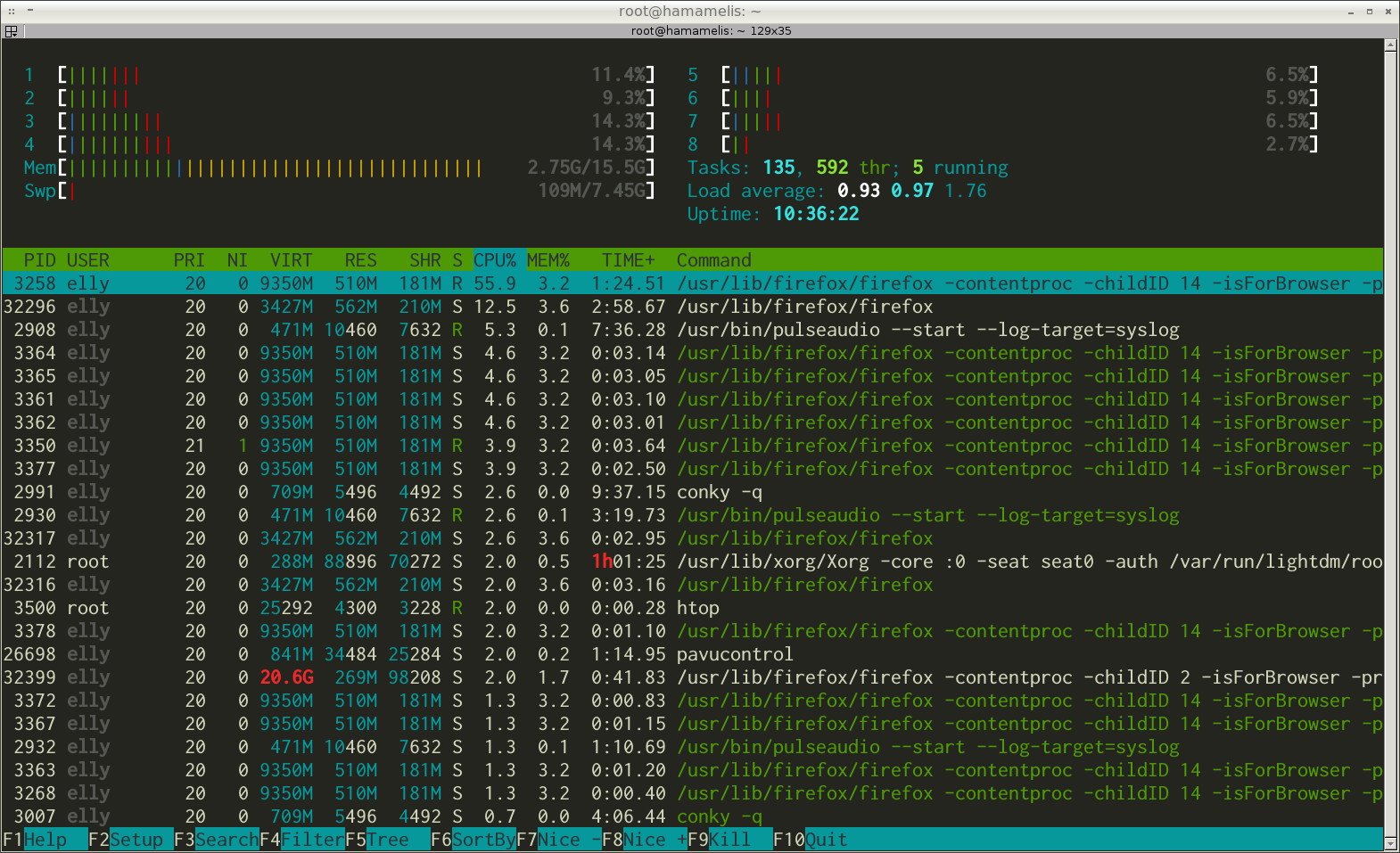
В 1980-е производительность ПК стремительно росла. Это позволило заменить псевдографику на реальные графические элементы. Примеры таких элементов: окна, иконки, кнопки и т.д. В результате появился полноценный графический интерфейс. Он применяется в современных ОС.
Первый графический интерфейс предназначался для мини-компьютера Xerox Alto (см. иллюстрацию 1-10). Его разработали в 1973 году в исследовательском центре Xerox PARC. Однако, интерфейс не получил широкого распространения до 1980-х годов. Он требовал много памяти и высокой производительности компьютера. В то время ПК с такими характеристиками стоили слишком дорого для рядовых пользователей.
Первый недорогой ПК с графическим интерфейсом выпустила компания Apple в 1983 году. Он назывался Lisa.

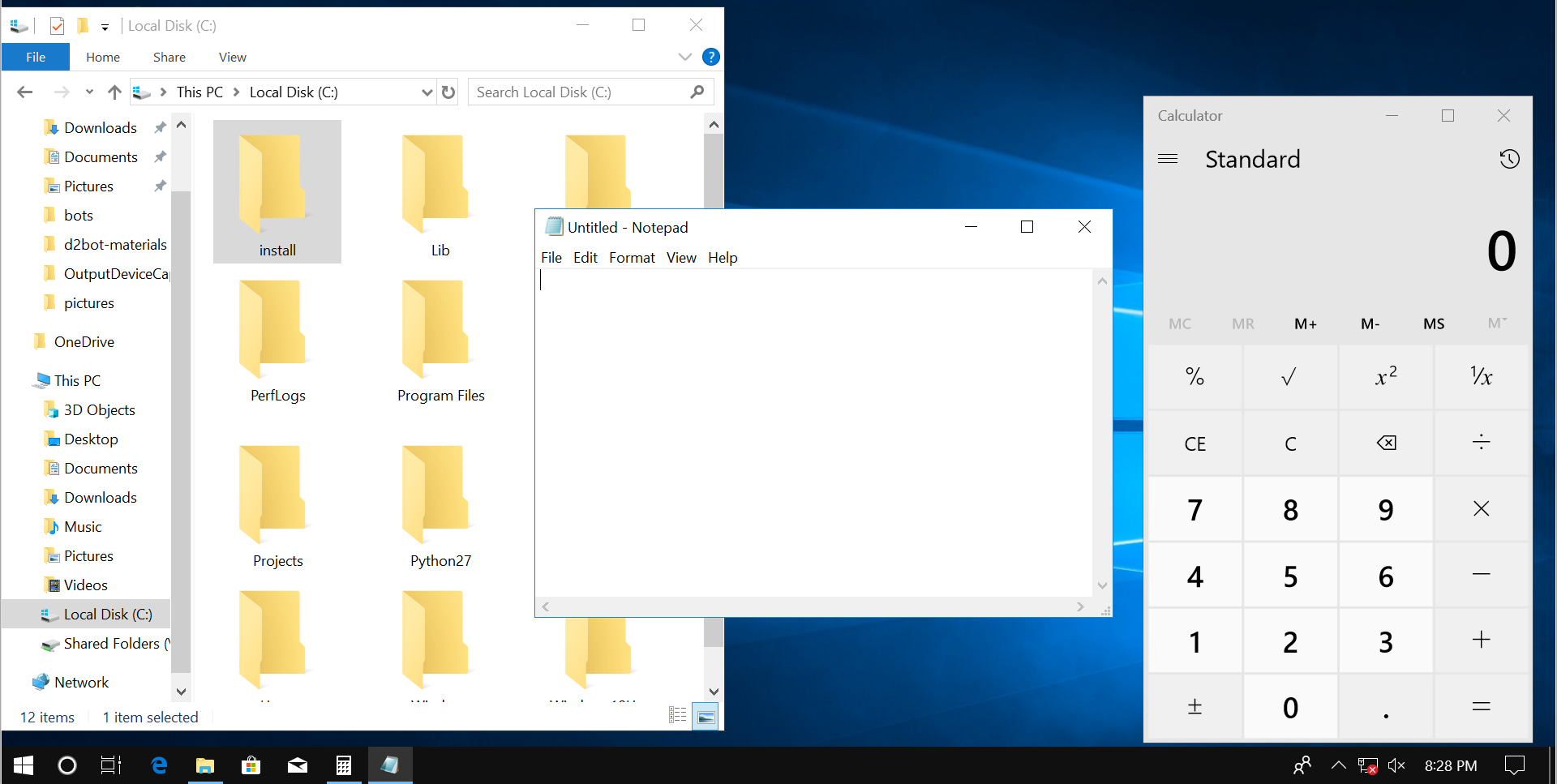
Иллюстрация 1-9 демонстрирует графический интерфейс ОС Windows. Это скриншот рабочего стола. На нём открыты окна трёх приложений: Проводник, Блокнот и Калькулятор. Они работают одновременно.
Семейства ОС
Сегодня на рынке персональных компьютеров доминируют три семейства ОС:
Термин “семейство” означает ряд версий ОС, которые следуют одним и тем же архитектурным решениям. Кроме того большинство функций в этих ОС реализованы одинаково.
Разработчики ОС склонны придерживаться одной и той же архитектуры. Они не предлагают что-то принципиально новое в следующих версиях своего продукта. Почему?
На самом деле изменения в современных ОС происходят, но постепенно и медленно. Причина этого в обратной совместимости. Такая совместимость означает, что новые версии ОС повторяют функции старых версий. Эти функции нужны для работы существующих программ. На первый взгляд это требование кажется необязательным. Однако, это серьёзное ограничение для разработки программного обеспечения. Давайте разберёмся, почему это так.
Представьте, что вы написали программу для Windows и продаёте её. Иногда пользователи обнаруживают в программе ошибки. Вы их исправляете. Время от времени вы добавляете новые функции.
Теперь представьте, что вышла новая версия Windows. В ней компания Microsoft полностью изменила архитектуру ОС. Поэтому ваша программа на ней не работает. У пользователей программы есть два решения:
- Перейти на новую версию Windows и ждать исправления вашей программы.
- Отказаться от обновления Windows.
Если ваша программа нужна пользователям для ежедневной работы, они откажутся от обновления Windows. Для них будет разумнее подождать, пока вы исправите программу для работы с новой версией ОС. Тогда они смогут обновить и программу, и ОС без ущерба для своей работы.
Предположим, что новая Windows принципиально отличается от предыдущей. Это значит, что вам придётся полностью переписать программу. Подсчитайте всё время, которое вы уже потратили на исправление ошибок и добавление новых функций. Эту работу придётся повторить в полном объёме. Скорее всего, вы откажетесь от этой идеи и предложите пользователям оставаться на старой версии Windows.
Windows самая популярная ОС для ПК и ноутбуков. Поэтому для неё написано много программ, подобных вашей. Их разработчики придут к тому же решению, что и вы. В результате новая версия Windows окажется никому не нужна. В этом суть проблемы обратной совместимости. Из-за неё разработчики ОС относятся к изменениям с осторожностью. Лучшее решение для них — разработать и поддерживать семейство похожих ОС.
Приложения оказывают огромное влияние на развитие и распространение ОС. Например, ОС Windows и персональные компьютеры от IBM обязаны своим успехом табличному процессору Lotus 1-2-3. Он запускался только на ОС Windows, которая работала только на ПК от IBM. Ради Lotus 1-2-3 пользователи покупали и компьютер, и ОС. Комбинация аппаратуры и программного обеспечения называется компьютерной платформой. Популярное приложение, которое выводит платформу на широкий рынок, получило название killer application (букв. убойное приложение).
Табличный процессор VisiCalc — ещё один пример убойного приложения. Он содействовал распространению компьютеров Apple II. Точно так же бесплатные компиляторы языков C, Fortran и Pascal подогрели интерес к Unix в университетских кругах.
За каждой из трёх доминирующих сегодня ОС стоит убойное приложение. Они дали начальный рывок в конкуренции за новыми пользователями. Далее срабатывал сетевой эффект. Его суть в том, что разработчики новых приложений выбирали самую распространённую платформу.
Чем отличаются семейства ОС между собой? Windows и Linux примечательны тем, что не привязаны к конкретной аппаратной платформе. Это значит, что они устанавливаются на любой персональный компьютер или ноутбук. В отличие от них macOS запускается только на компьютерах Apple. Чтобы установить macOS на другую аппаратную платформу, понадобится неофициальная модифицированная версия ОС.
Совместимость с аппаратной платформой — это пример архитектурного решения. Таких решений много. Все вместе они определяют особенности каждого семейства.
Предположим, что вы выбираете ОС для своего нового приложения. Кроме популярности системы и её архитектуры, вам следует учесть её инфраструктуру для разработки. Инфраструктурой называются доступные инструменты. К ним относится IDE, компилятор, система сборки, система контроля версий.
Инфраструктура и архитектура ОС навязывают разработчикам приложений определённые решения. Эти решения называются культурой разработки под конкретную ОС. Обратите внимание на важный момент: под разные ОС программы следует разрабатывать по-разному. Постарайтесь это учитывать.
Рассмотрим различие культур разработки программ на примере Windows и Linux.
Windows
Windows — это проприетарная ОС. Исходный код проприетарных программ закрыт. Вы не можете его прочитать и изменить без специальных средств. Другими словами нет законного способа узнать про такое ПО больше, чем рассказывает его документация.
Чтобы установить Windows на компьютер, вы должны купить её у компании Microsoft. Есть и другой способ. Производители компьютеров часто сами устанавливают Windows на свои устройства. В этом случае цена на ОС входит в конечную стоимость компьютера.
Целевой платформой Windows были и остаются относительно дешёвые ПК и ноутбуки. Многие могут позволить себе купить такое устройство. Поэтому рынок потенциальных пользователей Windows огромен. Microsoft стремится сохранить конкурентное преимущество на этом рынке. Компания опасается появления аналогов Windows с такими же возможностями. Чтобы это предотвратить, Microsoft защищает свою интеллектуальную собственность не только техническими, но и юридическими путями. Например, пользовательское соглашение запрещает вам исследовать внутреннее устройство ОС.
Первая версия Windows была разработана в 1985 году. С тех пор семейство этих ОС развивается более 30 лет. Благодаря его популярности многие разработчики выбирают Windows в качестве платформы для своих программ. Однако, первые приложения разработала сама компания Microsoft. Например, это офисный пакет Microsoft Office и стандартные приложения Windows. Они задали некий стандарт и стали образцом для подражания.
Microsoft придерживалась того же принципа при разработке приложений, что и для ОС. Это принцип закрытости:
- Исходный код недоступен для пользователей
- Форматы данных недокументированны
- Сторонние утилиты не имеют доступа к возможностям ПО.
Эти решения хорошо защищают интеллектуальную собственность Microsoft.
Разработчики программ последовали примеру Microsoft. Они придерживались той же философии закрытости. В результате их приложения получались самодостаточными и независимы друг от друга. Форматы их данных закодированы и недокументированны.
Если вы опытный пользователь компьютера, то сразу узнаете типичное Windows-приложение. Это окно с элементами интерфейса вроде кнопок, полей ввода, вкладок и т.д. С их помощью пользователь манипулирует некоторыми данными. Например, это может быть текст, изображение или звуковая запись. Результат работы сохраняется на жёсткий диск. Его можно открыть снова в этом же приложении. Если вы напишете собственную Windows-программу, она будет выглядеть и работать похожим образом. Такая преемственность решений и называется культурой разработки под ОС.
Linux
Linux заимствовал идеи и решения ОС Unix. Обе системы следуют набору стандартов POSIX (Portable Operating System Interface). POSIX определяет интерфейсы взаимодействия прикладных программ с ОС. Linux и Unix получились похожи из-за следования одному стандарту. Обратимся к истокам Unix, чтобы лучше понять его архитектурные решения.
ОС Unix разработали два инженера из компании Bell Labs в конце 1960-х годов. Это был хобби-проект Кена Томпсона и Денниса Ритчи. В Bell Labs они работали над проектом Multics.
ОС Multics была совместной разработкой Массачусетского технологического института (MIT), компании General Electric (GE) и Bell Labs. Она предназначалась для нового мейнфрейма GE-645 компании General Electric. Иллюстрация 1-11 демонстрирует этот компьютер.

В Multics разработчики применили ряд инновационных решений. Одним из них было разделение времени. Так мейнфрейм GE-645 стал первым компьютером, на котором могли одновременно работать несколько пользователей. Для разделения аппаратных ресурсов между ними применялась многозадачность.
ОС Multics оказалась слишком сложной из-за многочисленных инноваций и высоких требований. На её разработку потребовалось больше времени и денег, чем планировалось изначально. Из-за этого компания Bell Labs вышла из проекта в 1969 году.
Проект Multics был интересен с технической стороны. Поэтому многие инженеры Bell Labs продолжили работу над ним самостоятельно. Одним из них был Кен Томпсон. Он решил создать собственную ОС для компьютера GE-645. Томпсон начал писать ядро системы и продублировал некоторые механизмы Multics. Однако, скоро General Electric потребовала вернуть свой компьютер GE-645. Bell Labs получила его во временное пользование для работы на Multics. В результате Кен Томпсон остался без аппаратной платформы для разработки. Из-за этого он не смог больше развивать свой проект.
Параллельно с работой над аналогом Multics Томпсон писал компьютерную игру Space Travel как хобби. Она запускалась на мейнфрейме General Electric прошлого поколения GE-635. Этот компьютер работал под управлением ОС GECOS. GE-635 представлял собой шкафы с электроникой стоимостью около 7500000$. Его активно использовали инженеры Bell Labs и Томпсону редко удавалось с ним работать.
Ограниченный доступ к компьютеру GE-635 стал проблемой. Для её решения Томпсон перенёс свою игру на относительно недорогой мини-компьютер PDP-7 (см. иллюстрацию 1-12). Он стоил около 72000$. Сотрудники Bell Labs использовали его редко и большую часть рабочего времени он был доступен. При переносе Space Travel на другую платформу возникла одна проблема. Игра использовала возможности GECOS, но ОС компьютера PDP-7 их не предоставляла.
В этот момент к Томпсону присоединился его коллега Деннис Ритчи. Вмести они реализовали необходимые для игры возможности GECOS на PDP-7. Это был набор библиотек и подсистем. Со временем они развились в самостоятельную ОС, получившую название Unix. В ней разработчики применили некоторые инновационные идеи Multics.

Томпсон и Ритчи не собирались продавать свои разработки. Поэтому вопрос о защите интеллектуальной собственности даже не обсуждался. Они разрабатывали Unix для собственных нужд. Когда система заработала, её распространяли с открытым исходным кодом. Все сотрудники Bell Labs могли скопировать и использовать Unix в своих проектах. Это вполне естественное решение для передачи полезной системы коллегам.
ОС Unix стала популярна среди инженеров Bell Labs. Томпсон и Ритчи представили её на конференции по операционным системам под названием “Symposium on Operating Systems Principles” в 1973 году. ОС понравилась участникам конференции и многие захотели её приобрести. Проблема была в том, что Bell Labs принадлежала компании AT&T. Поэтому сотрудники Bell Labs не имели права распространять программное обеспечение.
В компании AT&T заметили успех Unix. Руководство решило продавать ОС вместе с исходным кодом высшим учебным заведениям США. Сумма лицензии составляла $20000. Эта цена была слишком высокой для коммерческих пользователей, но подъёмной для университетов. Так ОС Unix распространилась среди учебных заведений и продолжала развиваться там.
Линус Торвальдс познакомился с Unix во время учёбы в Хельсинкском университете. Unix произвела на него впечатление и привела к идее создать собственную ОС. Впоследствии она получила название Linux. Эта работа не была хобби для развлечения. Торвальдс решал практическую задачу. Ему нужна была Unix-совместимая ОС, чтобы выполнять университетские задания дома на ПК. В то время подходящей ему ОС не существовало.
В Хельсинкском университете студенты работали на мини-компьютере MicroVAX под управлением Unix. У многих из них был дома персональный компьютер. Но Unix на ПК не запускалась. Единственной альтернативой Unix для домашнего использования была Minix.
Эндрю Таненбаум разработал Minix в 1987 году для ПК от IBM с процессором Intel 80268. Minix создавалась исключительно для учебных целей. Поэтому Эндрю отказывался вносить в неё изменения для поддержки более современных компьютеров. Эти изменения сделали бы систему сложнее. Тогда она стала бы не пригодна для обучения студентов.
Торвальдс задался целью написать Unix-совместимую ОС для своего нового компьютера IBM с процессором Intel 80386. Для разработки он использовал Minix. Однако, никакие её части не вошли в состав новой ОС.
Торвальдс разработал ОС для собственных нужд. У него не было коммерческих интересов, как и у создателей Unix. Вместо этого Торвальдс свободно поделился ею со всеми желающими. Это привело к тому, что Linux стала бесплатной. Она свободно распространялась с исходным кодом через интернет. Доступность и отсутствие Unix-совместимых альтернатив для новых ПК от IBM сделало ОС популярной.
Торвальдс разработал только ядро ОС. Оно предоставляло функции управления памятью, файловую систему, драйвера устройств и планировщик задач. Для полноценной ОС не хватало интерфейса, через который пользователи получили бы доступ к этим возможностям. Поэтому Linux не был готов к использованию в своём исходном виде.
Решение проблемы пришло из проекта GNU. Ричард Столлман начал работу над ним в Массачусетском технологическом институте (MIT) в 1983 году. Он поставил себе задачу разработать основное программное обеспечение для компьютера и сделать его бесплатным. Главные программы проекта GNU следующие:
- GCC компилятор
- Системная библиотека glibc
- Системные утилиты
- Оболочка Bash.
Торвальдс включил эти программы в свой проект и выпустил первый дистрибутив Linux в 1991 году.
У первых версий Linux не было графического интерфейса. Пользователь запускал все приложения из командной строки. Только некоторые сложные приложения имели текстовый интерфейс. GUI появился в Linux в середине 1990-х годов. Он использовал бесплатную оконную систему X Window System. X Window позволила разработчикам писать приложения с графическим интерфейсом.
Unix и Linux развивались в особых условиях. Они отличались от обычного жизненного цикла проприетарных систем. Эти условия породили особую культуру разработки. Обе системы дорабатывались в университетских кругах. Преподаватели и студенты ИТ специальностей использовали эти ОС в своей ежедневной работе. Они хорошо разбирались в работе программного обеспечения и охотно вносили исправления в обе системы.
Разберёмся, что отличает культуру разработки под Unix. Пользователи этой ОС предпочитают использовать узкоспециализированные утилиты командной строки. Так для каждой прикладной задачи есть своя утилита. Она хорошо написана, многократно протестирована и работает максимально эффективно. При этом все возможности утилиты нацелены на решение одной задачи. Это не универсальная программа, которая подходит для нескольких целей.
Предположим, что вы решаете сложную задачу. Одна узкоспециализированная утилита не в состоянии с ней справится. Но если скомбинировать несколько утилит, задача решается быстро и эффективно. Такое взаимодействие программ стало возможным благодаря простому формату данных. Большинство Unix утилит работают с текстовыми данными. Такой формат очевиден и не нуждается в документации.
Культура разработки Linux во многом повторяет традиции Unix. Она отличается от стандартов, принятых в Windows.
В Windows каждое приложение монолитно и самостоятельно выполняет все свои задачи. Оно не полагается на сторонние утилиты. Причина в том, что большинство Windows-программ платные и могут быть недоступны для пользователя. Поэтому каждый разработчик полагается только на себя. Для работы своего приложения он не в праве требовать от пользователя купить что-то дополнительное.
В Linux программы зависят друг от друга. Большинство утилит бесплатны, взаимозаменяемы и легко доступны через интернет. Поэтому вполне естественно, что одно приложение требует загрузить и установить недостающий ему системный компонент или другое приложение.
Взаимодействие программ принципиально важно в Linux. Даже монолитные графические Linux-приложения обычно предоставляют дополнительный интерфейс командной строки. Таким образом они органично вписываются в экосистему ОС. Используя командный интерфейс, вы можете интегрировать их с другими утилитами и приложениями.
В Linux решение сложной задачи часто строится на сочетании узкоспециализированных программ. Таким образом алгоритм вычисления собирается по частям. Для этого в Linux и Unix есть специальный инструмент — командная оболочка. Она позволяет пользователю исполнять команды и сохранять их в скрипты. Первая версия командной оболочки Bourne shell для Unix появилась в 1979 году. Сегодня она считается устаревшей. В современных Linux дистрибутивах её вытеснил Bash. В этой книге мы с ним познакомимся.
Мы кратко рассмотрели культуры разработки Windows и Linux. Нельзя отдать однозначное предпочтение одной из них. Их сравнение давно служит поводом для бесконечных споров. Каждая из культур имеет свои достоинства и недостатки. Например, типичные для Windows монолитные приложения лучше справляются с задачами, требующими интенсивных расчётов. При комбинации узкоспециализированных Linux-утилит в этом случае появляются накладные расходы. Они связаны с запуском утилит и передачей данных между ними. Всё это требует дополнительного времени. В результате задача выполняется дольше.
Сегодня мы наблюдаем синтез культур Windows и Linux. Компания Microsoft начала активно принимать участие в разработке открытого ПО. Среди таких проектов ядро Linux, сетевой протокол Samba, библиотека для машинного обучения PyTorch, браузер Chromium и т.д. Microsoft также выложила в открытый доступ некоторые из своих проектов: программную платформу .NET, оболочку PowerShell, среду разработки VS Code и др.
С другой стороны всё больше коммерческих приложений переносятся на Linux: браузеры, инструменты для разработки программ, игры, мессенджеры и т.д. При этом их разработчики часто не готовы вносить изменения, продиктованные Linux-культурой. Такие изменения требуют времени и сил. Кроме того, они усложняют сопровождение продукта. Вместо одного приложения получается два: под каждую платформу разная версия. Поэтому разработчики переносят свои приложения с минимальными изменениями. В результате под Linux всё чаще встречаются приложения, выполненные в типичном Windows-стиле.
О плюсах и минусах синтеза культур можно спорить. Но очевидно одно: чем больше приложений запускается на ОС, тем популярнее она становится благодаря сетевому эффекту.
Компьютерная программа
Мы познакомились с операционными системами. Они отвечают за запуск и выполнение компьютерных программ. Программы решают прикладные задачи пользователя. Например, текстовый редактор позволяет работать с текстом.
Программа представляет собой набор элементарных шагов. Они называются инструкциями. Компьютер последовательно выполняет эти шаги. Так он справляется со сложными задачами. Рассмотрим подробнее, как происходит запуск и исполнение программы.
Память компьютера
Инструкции компьютерной программы хранятся на жёстком диске или другом носителе информации. Небольшая программа помещается в один файл. Сложное приложение может состоять из десятков файлов.
Предположим, что у вас есть файл с программой. При его запуске ОС загружает содержимое файла в оперативную память компьютера. Затем ОС выделяет часть процессорного времени на исполнение новой программы. Тогда процессор получает и исполняет инструкции вашей программы по частям. Эти части чередуются с остальными запущенными приложениями и компонентами ОС.
Первый шаг запуска программы — загрузка её инструкций в оперативную память. Чтобы лучше понять этот шаг, рассмотрим устройство памяти современного компьютера.
Память компьютера измеряется в байтах. Байт — это минимальный блок информации, на который процессор может ссылаться и загружать в свою память. Процессор способен оперировать и меньшими объёмами информации — битами. Бит — это минимальная единица информации, которую нельзя разложить на составные части.
Бит представляет собой логическое состояние с двумя возможными значениями. Есть несколько способов интерпретировать эти значения:
- 0 или 1
- Истина или ложь
- Да или нет
- + или —
- Включено или выключено.
Представьте себе бит, как выключатель лампы. Выключатель находится в одном из двух состояний:
- Он замыкает цепь и лампа горит.
- Он размыкает цепь и лампа выключена.
Восемь битов составляют блок памяти в один байт. Такая упаковка битов в байты вызывает вопросы. Процессор может оперировать отдельными битами. Почему тогда он не может ссылаться на конкретный бит в памяти?
Процессор не работает с битами напрямую. У этого ограничения есть исторические причины. Первые компьютеры использовались для арифметических вычислений. Например, они рассчитывали баллистические таблицы для артиллерии. При решении подобных задач компьютер оперировал целыми и дробными числами. Чтобы сохранить число в памяти, одного бита недостаточно. Поэтому понадобились блоки памяти из нескольких битов. Такими блоками стали байты.
Объединение битов в байты отразилось на архитектуре процессоров. Их производители предположили, что компьютеры и дальше будут оперировать только числами. Поэтому инженеры позволили процессору загружать и обрабатывать все биты одного числа за раз. Это решение на порядок увеличило производительность компьютеров. В то же время загрузка отдельного бита в память процессора выполнялась редко. Поддержка этой возможности требовала аппаратных ресурсов и не оправдывала себя. В результате от неё отказались.
Есть ещё один вопрос. Почему байт состоит именно из восьми бит? Так было не всегда. В первых компьютерах размер байта равнялся шести битам. Этого блока памяти хватало для кодирования всех символов английского алфавита в верхнем регистре, цифр, знаков пунктуации и математических операций.
Со временем блока в шесть битов стало недостаточно. Байт расширили до семи битов в начале 1960-х годов. Этот момент совпал с появлением ASCII-кодировки. Она стала стандартом для представления символов в памяти компьютера. ASCII определяет символы для кодов от 0 до 127. Максимальное семибитное число 127 ограничивает этот диапазон.
В 1964 году IBM выпустила мейнфрейм IBM System/360. В нём размер байта равнялся восьми битам. Такой размер позволял поддерживать старые кодировки символов из прошлых проектов IBM. Мейнфрейм IBM System/360 стал популярен и широко использовался. Это привело к тому, что упаковка восьми битов в байт стала отраслевым стандартом.
Таблица 1-1 демонстрирует часто используемые единицы измерения информации.
| Название | Сокращение | Число байтов | Число битов |
|---|---|---|---|
| килобайт | Кбайт | 1000 | 8000 |
| мегабайт | Мбайт | 1000000 | 8000000 |
| гигабайт | Гбайт | 1000000000 | 8000000000 |
| терабайт | Тбайт | 1000000000000 | 8000000000000 |
В таблице 1-2 приведены распространённые устройства хранения информации и их объёмы.
| Устройство хранения | Объём |
|---|---|
| Дискета 3.5” | 1.44 Мбайт |
| Компакт-диск | 700 МБайт |
| DVD-диск | до 17 Гбайт |
| USB-флеш-накопитель | до 2 Тбайт |
| Жёсткий диск | до 16 Тбайт |
| Твердотельный накопитель | до 100 Тбайт |
Мы познакомились с единицами измерения информации и устройствами хранения. Теперь вернёмся к исполнению программы. Зачем загружать её инструкции в оперативную память? Ведь процессор может читать их напрямую с жёсткого диска.
В современном компьютере вся память делится на четыре уровня. Они изображены на иллюстрации 1-13 красными прямоугольниками. Каждому уровню соответствуют разные устройства. Единственное исключение из этого правила — процессор. В его кристалле находятся и регистры, и кэш память. Им соответствуют разные модули кристалла.
Стрелки на иллюстрации 1-13 означают потоки данных. Передача происходит только между соседними уровнями памяти.
Предположим, процессор собирается обработать данные с диска. Для этого их надо загрузить в регистры процессора. Он работает только с содержимым своих регистров.
Если процессору нужны данные из дисковой памяти, они загружаются так:
- Дисковая память -> Оперативная память
- Оперативная память -> Кэш процессора
- Кэш процессора -> Регистры процессора
Данные из регистров записываются на диск в обратном порядке:
- Регистры процессора -> Кэш процессора
- Кэш процессора -> Оперативная память
- Оперативная память -> Дисковая память
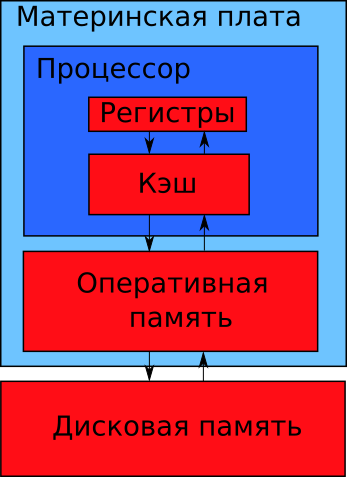
Устройства хранения информации отличаются друг от друга следующими параметрами:
- Скорость доступа — сколько данных читается или пишется на устройство в единицу времени. Единицы измерения — байты в секунду (байт/с).
- Объём — максимальное количество данных, которое может хранить устройство. Измеряется в байтах.
- Стоимость — цена устройства в соотношении к его объёму. Измеряется в долларах или центах за байт или бит.
- Время доступа — время между моментами, когда данные с устройства понадобились процессору и когда он их получил. Измеряется в тактовых сигналах процессора.
На разных уровнях иерархии памяти параметры устройств существенно различаются. Таблица 1-3 приводит соотношение этих параметров.
| Уровень | Устройство | Объём | Скорость доступа | Время доступа | Стоимость |
|---|---|---|---|---|---|
| 1 | Регистры процессора. | до тысячи байтов | — | 1 такт | — |
| 2 | Кэш память процессора. | от одного килобайта до нескольких мегабайтов | от 700 до 100 гигабайт/сек | от 2 до 100 тактов | — |
| 3 | Оперативная память | десятки гигабайтов | 10 гигабайт/сек | до 1000 тактов | $10-9/байт |
| 4 | Дисковая память (жёсткие диски и твёрдотельные накопители) | терабайты | 2000 мегабайт/сек | до 10000000 тактов | $10-12/байт |
Таблица 1-3 вызывает вопросы. У дисковой памяти высокая скорость доступа. Почему нельзя читать данные из неё напрямую в регистры процессора? Это возможно технически, но приведёт к высоким накладным расходам.
На практике быстродействие определяет не скорость, а время доступа к памяти. Это время простаивания процессора, пока он не получит нужные ему данные. Оно измеряется в числе тактовых сигналов или тактах. Такт синхронизирует выполнение всех операций процессора. На выполнении одной инструкции программы уходит от 1 до 10 тактов.
Высокое время доступа приводит к низкой производительности. Рассмотрим пример. Допустим, что процессор читает инструкции программы напрямую с жёсткого диска. Объём регистров процессора мал. Поэтому все инструкции программы в них не поместятся. Процессору придётся загружать и выполнять программу по частям. Каждая такая загрузка занимает 10000000 тактов. Другими словами загрузка инструкций длится дольше, чем их выполнение. Большую часть времени процессор простаивает в ожидании. Иерархия памяти компьютера решает именно эту проблему простоя.
Рассмотрим передачу данных между уровнями иерархии памяти. Представьте, что вы запустили простую программу. Она читает файл с жёсткого диска и выводит его содержимое на экран. Данные с диска читаются в несколько шагов. Эти шаги выполняются на аппаратном уровне.
Первый шаг — чтение данных с диска в оперативную память, как показывает иллюстрация 1-13. Затем по частям они загружаются в кэш процессора. Специальный механизм кэширования предугадывает, какие данные из оперативной памяти понадобятся процессору дальше. Такое предугадывание сокращает ожидание загрузки данных процессором.
Процессор получает доступ к данным только тогда, когда они попадают в его кэш. Нужные данные загружаются из кэша в регистры. Инструкции программы проходят тот же путь загрузки, что и данные.
В нашем примере программа выводит данные на экран. Для этого вывода она вызывает API функцию из системной библиотеки ОС. Выполняя API функцию, библиотека меняет картинку на экране. При этом большую часть работы выполняет процессор. Он загружает инструкции системной библиотеки и драйвера видеокарты. Затем он применяет эти инструкции к данным в своих регистрах. Эти данные соответствуют содержимому файла, который надо вывести. Драйвер видеокарты обращается к самой видеокарте и передаёт ей данные для вывода на экран.
В нашем примере процессор простаивает, если необходимые ему данные не были загружены заранее. Вот несколько примеров, когда это происходит. Процессору нужны данные файла для обработки их в коде драйвера видеокарты. Допустим, что эти данные загружены кэш процессора, но не в его регистры. Тогда процессор проведёт в ожидании от 2 до 100 тактов. Если данные ещё не загружены в кэш из оперативной памяти, время ожидания увеличивается на порядок до 1000 тактов.
Наша программа способна выводить содержимое больших файлов. Размер файла может превышать объём оперативной памяти. Тогда в память загрузится только его часть. В случае если процессору понадобится незагруженная часть файла, время простоя увеличится на четыре порядка до 10000000 тактов. Для сравнения: за это время процессор мог бы исполнить около 1000000 инструкций программы.
Аппаратный механизм кэширования есть и у процессора, и у жёсткого диска. Механизм диска использует дополнительный контроллер памяти с относительно низким временем доступа. В него сохраняются данные, которые предположительно загрузятся в оперативную память следующими. На программном уровне есть свой механизм кэширования. За него отвечает операционная система.
Аппаратные и программные механизмы кэширования значительно повышают производительность компьютера. Ошибка одного из них приводит к простою процессора. Такая ошибка называется промах кэша (cache miss). Каждый промах дорого обходится с точки зрения производительности.
Помните об иерархии памяти и механизмах кэширования. Учитывайте их при разработке своих алгоритмов. Некоторые алгоритмы и структуры данных приводят к промахам кэша чаще, чем другие.
Устройства памяти из разных уровней иерархии находятся на разном физическом расстоянии от процессора. Чем короче это расстояние, тем меньше время доступа к устройству. Иллюстрация 1-14 демонстрирует этот принцип.
Например, регистры и кэш процессора (CPU) находятся внутри его кристалла. Оперативная память (RAM) расположена на материнской плате рядом с процессором. Их соединяет высокочастотная шина данных. Она обеспечивает низкое время доступа.
Материнская плата — эта печатная плата, которая соединяет компоненты компьютера. Некоторые из них вставляются в саму материнскую плату. Например, это процессор и оперативная память. Другие устройства подключаются к плате через кабели. Один из примеров — дисковая память. Для неё используется относительно медленный интерфейс. Он следует одному из следующих стандартов: ATA, SATA, SCSI, PCI Express.
За загрузку данных из оперативной памяти в кэш процессора отвечает системный контроллер. Он называется северный мост. До 2011 года это был отдельный компонент материнской платы. Благодаря развитию технологии изготовления интегральных схем, северный мост встраивается в кристалл современных процессоров.
За чтение данных с жёсткого диска в оперативную память отвечает контроллер под названием южный мост. Он организует обмен данными с устройствами, подключёнными через относительно медленные интерфейсы: PCI, USB, SATA и т.д. Южный мост до сих пор является отдельным компонентом материнской платы.

Машинный код
Предположим, что ОС загрузила содержимое исполняемого файла в оперативную память. В этом файле хранятся инструкции программы и данные для её работы. Примеры таких данных: текстовые строки, символы псевдографики, предопределённые константы и т.д.
Инструкции программы записаны в машинном коде. Этот код представляет собой набор команд, которые исполняет процессор. Каждая инструкция соответствует элементарной операции над данными в регистрах процессора.
У процессора есть разные логические блоки. Каждый блок выполняет только определённый тип инструкций. Набор блоков определяет, какие операции поддерживает процессор. Если специального блока для выполнения инструкции нет, она выполняется комбинацией блоков. Такое исполнение занимает больше времени и вычислительных ресурсов.
После загрузки программы в оперативную память ОС выделяет часть времени процессора на её исполнение. С этого момента программа становится вычислительным процессом (process). Процесс — это запущенная программа вместе с ресурсами, которые она использует. Примеры ресурсов: область памяти и объекты ОС.
Как выглядят инструкции программы? Вы можете прочитать их в исполняемом файле. Для работы с такими файлами есть специальные hex-редакторы. Эти редакторы представляют машинные инструкции программы в шестнадцатеричной системе счисления. На самом деле в исполняемом файле хранится двоичный код. Он представляет собой последовательность нулей и единиц. Именно в таком формате процессор получает инструкции и данные программы. Hex-редактор переводит их в шестнадцатеричный формат для удобства чтения.
Для работы с машинными кодом есть и более мощные средства, чем hex-редакторы. Одно из них — это программа под названием дизассемблер. Дизассемблер анализирует машинные инструкции и переводит их в язык ассемблера. Этот язык понятнее для человека. Он даёт более точное представление об алгоритме анализируемой программы.
Мы столкнулись с термином система счисления. Рассмотрим его подробнее.
Одно и то же число можно представить в разных системах счисления. При этом оно будет выглядеть по-разному. Система счисления определяет, какие символы и в каком порядке используются при записи числа. Например, двоичная система допускает только символы 0 и 1.
Таблица 1-4 приводит соответствие чисел в двоичной (binary, BIN), десятичной (decimal, DEC) и шестнадцатеричной (hexadecimal, HEX) системах счисления.
| Десятичная | Шестнадцатеричная | Двоичная |
|---|---|---|
| 0 | 0 | 0000 |
| 1 | 1 | 0001 |
| 2 | 2 | 0010 |
| 3 | 3 | 0011 |
| 4 | 4 | 0100 |
| 5 | 5 | 0101 |
| 6 | 6 | 0110 |
| 7 | 7 | 0111 |
| 8 | 8 | 1000 |
| 9 | 9 | 1001 |
| 10 | A | 1010 |
| 11 | B | 1011 |
| 12 | C | 1100 |
| 13 | D | 1101 |
| 14 | E | 1110 |
| 15 | F | 1111 |
Почему программисты используют и двоичную, и шестнадцатеричную системы? Было бы гораздо удобнее применять только одну из них. Чтобы ответить на этот вопрос, выясним как работает оборудование современного компьютера.
На двоичной системе и булевой алгебре строится вся современная цифровая техника. В цифровой технике элементарный носитель информации — это электрический сигнал. Чтобы работать с сигналами, их нужно кодировать. Кодирование означает сопоставление определённых чисел с состояниями сигнала.
У цифрового сигнала есть два состояния. Сигнал либо есть, либо его нет. Поэтому для представления его состояния можно взять два первых целых числа: ноль и единицу. Тогда ноль означает отсутствие сигнала, а единица — его наличие. Такая кодировка очень компактна. Одного бита достаточно, чтобы сохранить состояние одного сигнала.
Базовый элемент в цифровой технике — это логический вентиль. Он преобразовывает электрические сигналы. Логическим вентилем могут быть разные физические устройства. Вот несколько примеров: электромагнитное реле, электровакуумная лампа, транзистор. Каждое из этих устройств работает по-разному с точки зрения физики. Однако, все они одинаковы с точки зрения обработки сигналов.
Логический вентиль обрабатывает сигналы в два шага:
- Получает на вход один или более сигналов.
- Передаёт результирующий сигнал на выход.
Внутреннее устройство вентиля определяет, каким будет результирующий сигнал.
Булева алгебра предлагает математический аппарат для вычисления результатов обработки сигналов. Она также известна как алгебра логики.
Для логического вентиля каждого типа в булевой алгебре есть соответствующая операция. Если соединить выходы одних вентилей с входами других, получится составной вентиль. Его поведение может быть достаточно сложным. Результат его работы можно рассчитать с помощью выражения булевой алгебры. Пример составного вентиля — центральный процессор компьютера. Он представляет собой огромную сеть логических вентилей.
Для работы с цифровой техникой нужна двоичная система счисления. В ней есть только два числа: 0 и 1. Они как раз соответствуют состоянию сигналов. Числа 0 и 1 легко перевести в логические значения “ложь” и “истина”, которыми оперирует булева алгебра. Используя булеву алгебру, можно рассчитать результат преобразования сигналов.
Вся компьютерная аппаратура работает на уровне цифровых сигналов и логических вентилей. Иногда при разработке программы приходится переходить на этот уровень. Получается, что устройство аппаратуры навязывает программисту двоичную систему.
Аппаратура работает в двоичной системе счисления. Зачем тогда понадобилась шестнадцатеричная система? На самом деле программисты в своей работе используют либо десятичную систему, либо двоичную. Первая удобна при написании высокоуровневой логики программы. Например, для подсчёта повторений одного и того же действия.
Двоичная система нужна для работы с оборудованием. Например, для подготовки и передачи данных на устройство. У двоичной системы есть две проблемы. Во-первых, её неудобно записывать, читать, запоминать и произносить. Во-вторых, перевод из десятичной системы в двоичную сложен. Шестнадцатеричная система решает обе проблемы. Она так же компактна и удобна, как и десятичная. При этом перевод из шестнадцатеричной в двоичную систему выполняется в уме.
Перевод числа из двоичной системы в шестнадцатеричную выполняется так:
- Разбейте число на группы по четыре разряда, начиная с конца.
- Если последняя группа оказалась меньше четырёх разрядов, дополните её слева нулями.
- Каждую четвёрку разрядов замените на шестнадцатеричное число по таблице 1-4.
Вот пример перевода двоичного числа 110010011010111:
1 110010011010111 = 110 0100 1101 0111 = 0110 0100 1101 0111 = 6 4 D 7 = 64D7
В последнем разделе книги вы найдёте ответы на все упражнения. Если вы не уверены в своём результате, сверьтесь с ответами.
Вернёмся к выполнению программы. ОС загружает её исполняемый файл с диска в оперативную память. Затем ОС загружает все библиотеки, которые использует программа. Эти две операции выполняет загрузчик программ Windows. Благодаря предварительной загрузке библиотек, процессору не приходится ждать, когда программа обращается к ним. Инструкции и данные нужной библиотеки уже находится в оперативной памяти. Они доступны процессору в течении нескольких сотен тактов. После окончания работы загрузчика Windows программа становится процессом. Процессор исполняет её, начиная с первой инструкции.
Каждая записанная в машинном коде инструкция называется операционным кодом или опкодом. Опкод указывает процессору, какие логические вентили использовать и из каких регистров загружать данные для них. После выполнения операции, опкод определяет регистр для сохранения результата. Опкоды передаются в процессор в двоичной системе счисления.
Пока программа выполняется, её инструкции, данные, ресурсы и библиотеки занимают область оперативной памяти. После завершения программы эта область очищается. С этого момента её могут использовать другие приложения.
Исходный код
Машинный код — это низкоуровневый язык для представления программы. Такой формат инструкций и данных удобен для процессора. Однако, человеку трудно писать программу на машинном коде. Именно так разрабатывались программы для первых компьютеров. По сравнению с ними современные компьютеры гораздо мощнее и сложнее. Программы для них огромны и состоят из большого числа модулей.
Чтобы решить проблему работы с машинным кодом, компьютерные инженеры разработали два типа приложений. Эти приложения называются компиляторы и интерпретаторы. Они переводят программу из понятного человеку языка в машинный код. Компиляторы и интерпретаторы делают это по-разному.
Сегодня программы пишут на языках программирования. Написанный на таком языке текст программы передаётся на вход компилятору или интерпретатору. Далее он переводит этот текст в машинный код.
Люди общаются на естественных языках. Например, это может быть русский или английский. По сравнению с ними языки программирования очень формальны и ограниченны. Они позволяют выразить только те действия, которые способен выполнить компьютер. Чтобы записать эти действия, вы должны следовать строгим правилам языка. Пример правила — строгий порядок употребления слов.
Исходный код — это текст программы, записанный на языке программирования.
Компилятор и интерпретатор работают с исходным кодом по-разному. Компилятор читает текст программы целиком, генерирует по нему машинные инструкции и сохраняет их в файл на диске. Компилятор не исполняет получившуюся программу.
Интерпретатор читает исходный код программы по частям, генерирует машинные инструкции и сразу же их исполняет. Интерпретатор временно сохраняет свои результаты в оперативную память. При завершении программы эта память очищается.
Рассмотрим работу компилятора по шагам. Предположим, что вы написали программу и сохранили её исходный код в файл на жёстком диске. Затем вы запустили подходящий компилятор. Для каждого языка программирования есть свой компилятор или интерпретатор.
Компилятор читает файл с диска, обрабатывает его и записывает машинные инструкции вашей программы в исполняемый файл на диск. Теперь у вас есть два файла: с исходным кодом и с машинными инструкциями. Каждый раз когда вы меняете исходный код программы, вы должны сгенерировать новый исполняемый файл. Чтобы выполнить программу, вы запускаете исполняемый файл.
Иллюстрация 1-15 демонстрирует процесс компиляции программы, написанной на языке C или C++.
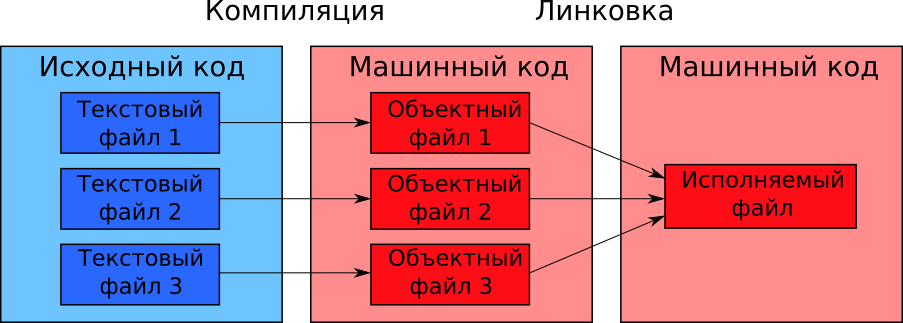
Компиляция происходит в два этапа. Первый этап выполняет компилятор. Второй этап называется компоновка или линковка. Его выполняет специальная программа компоновщик.
Компилятор создаёт промежуточные объектные файлы. Из них компоновщик собирает исполняемый файл.
Почему компиляция программы выполняется в два этапа? Компилятор и компоновщик можно скомбинировать в одну программу. Однако, у такого решения есть несколько проблем.
Первая проблема связана с ограниченным размером оперативной памяти. Исходный код программы принято разбивать на несколько файлов. Каждый файл содержит часть программы, которая отвечает за определённую функциональность. Такое разделение облегчает работу с исходным кодом больших проектов. Компилятор обрабатывает файлы программы по отдельности. Для каждого из них компилятор генерирует объектный файл. В нём хранится промежуточный результат компиляции.
Если объединить компилятор и компоновщик, сохранять промежуточные результаты на диск станет неэффективно. Такое сохранение замедлит весь процесс компиляции из-за высокого времени доступа к диску. Вместо этого все данные можно хранить в оперативной памяти. К сожалению, такой подход не сработает при компиляции больших приложений. Их исходный и объектный код не поместится в оперативную память. В этом случае компилятор завершится с ошибкой.
Предположим, что после объединения компилятора и компоновщика, вы сохраняете промежуточные результаты на диск. За это вы платите временем, которое процессор простаивает ожидая доступ к диску. Такое решение не приносит вам никакой выгоды. Единственное чего вы достигли, это обошли проблему переполнения оперативной памяти. Если вы разделите компилятор и компоновщик, вы получите два простых приложения вместо одного сложного. Простые приложения легче сопровождать. Поэтому разработчики компиляторов предпочли такое разделение.
Вторая проблема объединения компилятора и компоновщика заключается в разрешении зависимостей. В исходном коде программы есть блоки команд, которые обращаются друг к другу. Такие обращения называются зависимостями. Отслеживание зависимостей — это задача компоновщика.
Компилятор генерирует объектные файлы. Они содержат машинные инструкции, а не исходный код. Компоновщик принимает на вход эти объектные файлы. Следовательно, он отслеживает зависимости в машинном коде. Этот код компактнее, чем исходный. Поэтому в нём быстрее искать нужные блоки команд.
Предположим, что вы совместили компилятор и компоновщик. Тогда для разрешения зависимостей понадобятся дополнительные проходы по всему исходном коду программы. Компилятору требуется намного больше времени на один такой проход, чем компоновщику для прохода по машинному коду. Поэтому разделив компилятор и компоновщик, вы уменьшаете общее время компиляции программы.
Программа может вызвать блоки кода из библиотеки. В этом случае компоновщик обрабатывает файл библиотеки вместе с объектными файлами компилируемой программы. Компилятор не может обработать файл библиотеки, потому что он содержит машинный код. Разделение компилятора и компоновщика решает задачу использования библиотек.
Мы рассмотрели процесс компиляции. Теперь предположим, что вы предпочли интерпретатор для запуска своей программы. В этом случае файл с исходным кодом уже готов для исполнения. Чтобы его запустить, ОС сначала загружает интерпретатор. Далее интерпретатор читает файл с исходным кодом с диска в оперативную память. Затем он исполняет этот файл строка за строкой. При этом перевод команд исходного кода в машинные инструкции выполняется в оперативной памяти.
Некоторые интерпретаторы сохраняют на диск файлы с промежуточным представлением программы. Это ускоряет её выполнение в случае перезапуска. Но так или иначе для исполнения программы всегда нужен интерпретатор.
Иллюстрация 1-16 демонстрирует процесс интерпретации программы.
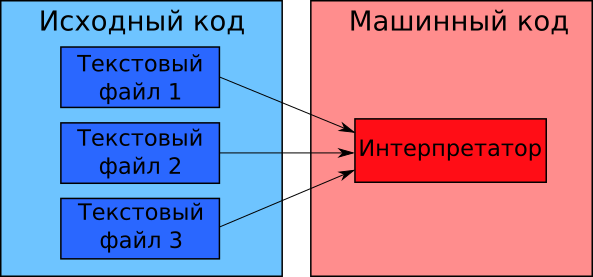
Схема на иллюстрации 1-16 выглядит так, словно интерпретатор работает как объединённый компилятор и компоновщик. Интерпретатор загружает текстовые файлы в оперативную память и переводит их в машинный код. Почему при этом память не переполняется? Как интерпретатор справляется с зависимостями?
Интерпретатор обходит проблемы объединённого компилятора и компоновщика потому, что он обрабатывает исходный код не так как компилятор. Интерпретатор читает и выполняет программу строка за строкой. Поэтому ему не нужно хранить в памяти исходный или машинный код всего приложения. Достаточно обрабатывать части файлов с исходным кодом по мере надобности. Интерпретатор исполняет и сразу выгружает эти части из оперативной памяти.
Интерпретация программ выглядит удобнее чем компиляция. Однако, у интерпретации есть свои недостатки.
Прежде всего, все интерпретаторы работают медленно. Причина в том, что каждый раз при запуске программы, интерпретатор должен перевести её исходный код в машинный. Это долгий процесс по меркам компьютера. Другая причина медленной работы интерпретаторов связана с доступом к диску. Загрузка исходного кода программы в оперативную память приводит к простоям процессора. Согласно таблице 1-3, простои могут длиться до 10000000 тактов.
Вторая проблема интерпретации в том, что сам интерпретатор — это сложная программа. Для работы она требует часть аппаратных ресурсов компьютера. Получается, что одновременно с вашей программой компьютер выполняет машинные инструкции интерпретатора. Это лишние накладные расходы. Они замедляют работу вашей программы.
Мы выяснили, что интерпретация программы выполняется медленно. Значит ли это, что компиляция лучше? Компилятор генерирует исполняемый файл с машинными инструкциями. Поэтому скорость выполнения скомпилированной программы такая же, как и у написанной вручную на машинном коде. Однако, вы платите за удобство языка программирования на этапе компиляции. Чтобы скомпилировать небольшую программу, достаточно пары секунд. Но компиляция больших проектов (например, ядра Linux) занимает несколько часов. При любом изменении в исходном коде, компиляцию надо перезапустить и снова ждать несколько часов.
Помните про накладные расходы компиляторов и интерпретаторов, при выборе языка программирования. Интерпретатор подойдёт вам в следующих случаях:
- Вам нужно написать программу как можно быстрее.
- Вам не важна скорость выполнения программы.
- Вы работаете над небольшим и простым проектом.
В следующих случаях вам стоит выбрать компилятор:
- Вы работаете над большим и сложным проектом.
- Ваша программа должна исполняться максимально быстро.
- Вам важно быстро находить ошибки в программе.
Накладные расходы есть и у компиляторов, и у интерпретаторов. Стоит ли вообще использовать языки программирования? Не лучше ли писать программы на машинном коде как раньше? В этом случае вы не теряете время, ожидая завершения компиляции. При этом ваша программа работает максимально быстро. Эти доводы звучат разумно. Но не торопитесь с выводами.
Простой пример поможет вам оценить преимущество языков программирования. Листинг 1-1 демонстрирует исходный код программы на языке C. Она выводит на экран текст “Hello world!”.
1 #include <stdio.h>2
3 int main(void)
4 {
5 printf("Hello world!\n");
6 }
Листинг 1-2 приводит машинные инструкции той же программы в шестнадцатеричном представлении.
1 BB 11 01 B9 0D 00 B4 0E 8A 07 43 CD 10 E2 F9
2 CD 20 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21
Даже если вы не знаете язык C, вы предпочтёте работать с кодом из листинга 1-1. По крайней мере, его можно быстро прочитать и изменить. Чтобы разобраться в числах из листинга 1-2 вам понадобится время.
Возможно, профессиональный программист с большим опытом работы сможет написать небольшую программу на машинном коде. Но чтобы разобраться в ней, другому программисту понадобиться много времени и сил. Разработка большого проекта на машинном коде — очень сложная задача для программиста любого уровня.
Использование языков программирования экономит ваше время и силы. Также это сокращает затраты на поддержку уже написанных программ. Разрабатывать современные сложные программы на машинном коде просто неэффективно.