Разработка Bash-скриптов
Мы изучили основные приёмы для работы с файловой системой на Bash. Пришло время перейти от составления отдельных команд к программам. Программы, написанные на языке Bash, называют сценариями оболочки (shell scripts) или скриптами.
Инструменты для разработки
В прошлой главе мы работали с Bash в интерактивном режиме. Порядок работы в этом режиме выглядит так:
- Вы вводите команду в окне эмулятора терминал.
- Процесс Bash получает команду и сохраняет её в оперативную память.
- Bash исполняет команду и передаёт терминалу её вывод.
- Bash удаляет команду из оперативной памяти.
Оперативная память не подходит для хранения программы. Она предназначена для временного хранения информации. Память очищается каждый раз, когда вы выключаете компьютер.
Если вы написали программу, её надо сохранить на жёстком диске. Диск предназначен для длительного хранения информации.
Чтобы создать или отредактировать файлы с исходным кодом, вам нужна специальная программа. Она называется редактор исходного кода.
Рассмотрим, какие редакторы подходят для работы с Bash.
Редактор исходного кода
Писать Bash-скрипты можно в любом текстовом редакторе. Для этого подойдёт даже стандартное приложение Windows под названием Блокнот (Notepad). Но работать с ним будет неудобно. У Блокнота нет дополнительных возможностей для редактирования исходного кода. Эти возможности значительно ускорят вашу работу.
Сегодня в интернете доступно много редакторов исходного кода. Некоторые из них распространяются бесплатно, а некоторые требуют лицензии. Чтобы выбрать подходящий вам редактор, попробуйте несколько вариантов.
Мы рассмотрим три популярных редактора исходного кода. Для начала попробуйте поработать с одним из них.
Notepad++ — это быстрый и минималистичный редактор с открытым исходным кодом. Он запускается только на ОС Windows. Поэтому для macOS или Linux, лучше рассмотреть другие варианты. Последнюю версию Notepad++ можно загрузить с официального сайта.
Sublime Text — это проприетарный кроссплатформенный редактор. Кроссплатформенность означает, что программа запускается на разных ОС и аппаратных платформах. Sublime Text можно использовать бесплатно без активации и лицензии. Но в этом режиме редактор регулярно выводит диалоговое окно с предложением купить лицензию. Загрузить программу можно с официального сайта.
Visual Studio Code — это кроссплатформенный редактор от компании Microsoft с открытым исходным кодом. Он работает на Windows, Linux и macOS. Для работы с ним лицензия не нужна. Редактор можно загрузить с официального сайта.
Для работы с исходным кодом у всех трёх редакторов есть следующие возможности:
- Подсветка синтаксиса.
- Автодополнение.
- Поддержка широко распространённых кодировок символов.
Редактировать исходный код можно и без этих возможностей. Но они ускоряют работу, облегчают редактирование программы и поиск ошибок в ней. Кроме того они помогут вам быстрее освоиться с синтаксисом Bash.
Запуск редактора
Есть несколько способов запустить редактор исходного кода. Первый вариант — через графический интерфейс ОС. В случае Windows, используйте иконку программы на рабочем столе или в меню Пуск. Скорее всего, так вы запускаете все программы на вашем компьютере.
Второй вариант — запустить редактор из командной оболочки. Этот способ удобнее в некоторых случаях. Например, когда вы ищете файлы с помощью утилиты find. Результаты поиска можно передать на вход редактору. Он откроет все найденные файлы в разных вкладках. Такой приём работает, потому что все современные редакторы имеют интерфейс командной строки.
Запустить приложение из Bash можно тремя способами:
- По имени исполняемого файла.
- По абсолютному пути.
- По относительному пути.
Первый способ самый удобный. Чтобы он заработал, добавьте каталог установки приложения в переменную Bash под названием PATH. Тогда интерпретатор сможет найти и запустить исполняемый файл программы.
Для примера запустим редактор Notepad++ по имени исполняемого файла. Путь установки редактора по умолчанию следующий:
В окружении MSYS2 тот же путь установки редактора выглядит так:
Если запустить Notepad++ по этому абсолютному пути, Bash сообщит об ошибке. Она показана на иллюстрации 3-1.
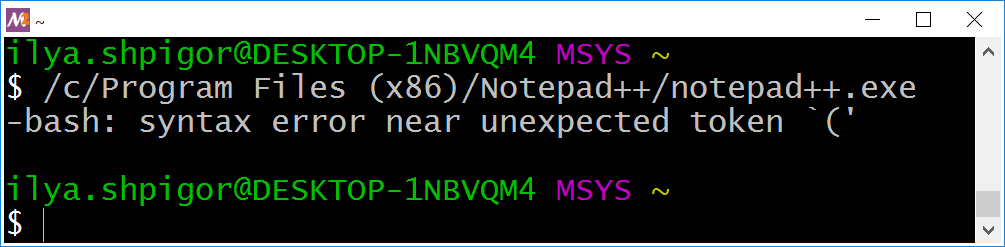
У команды на иллюстрации 3-1 есть несколько проблем. Рассмотрим их по порядку. Команда cd может дать подсказку о первой проблеме. Вызовем cd так:
cd /c/Program Files
Результат команды приведён на иллюстрации 3-2.
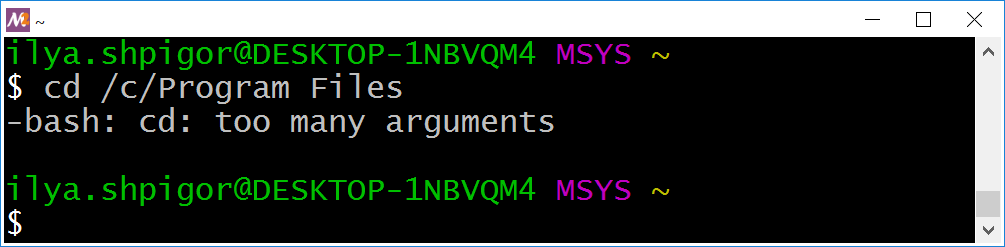
Bash сообщает следующее: команда cd получила больше параметров, чем ей нужно. Она ожидает на вход только один параметр — путь к целевому каталогу. В нашем случае передано два параметра.
Ошибка возникла из-за механизма Bash под названием word splitting. Он разделяет пробелом путь к редактору Notepad++ на две части. Таким образом в команду cd передаются два пути: /c/Program и Files.
Есть два способа отключить механизм word splitting:
1. Заключить путь в двойные кавычки:
cd "/c/Program Files"
2. Экранировать все пробелы с помощью обратного слэша:
cd /c/Program\ Files
После отключения word splitting, Bash правильно исполнит команду cd.
Теперь вызовем команду cd, чтобы перейти по пути /c/Program Files (x86). Такой вариант не сработает:
cd /c/Program Files (x86)
Мы выяснили, что Bash разделяет входной параметр на части. Отключим word splitting с помощью обратного слэша. Получим следующую команду:
cd /c/Program\ Files\ (x86)
Эта команда завершится с ошибкой, как на иллюстрации 3-3.
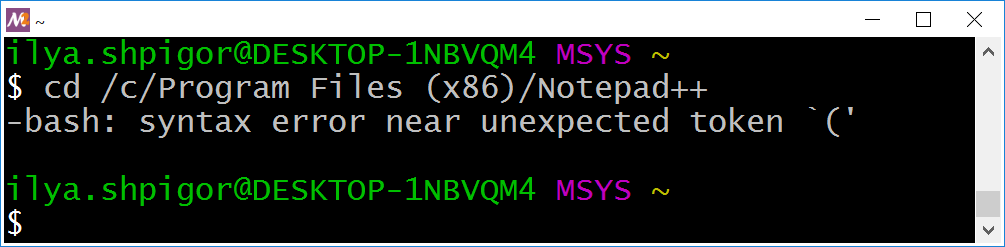
Точно такую же ошибку вывел Bash на иллюстрации 3-1, когда мы запускали Notepad++. Проблема в том, что кавычки ( и ) являются частью синтаксиса Bash. Поэтому интерпретатор обрабатывает их как конструкцию языка. Мы уже сталкивались с этой проблемой, когда группировали выражения утилиты find. Экранирование обратным слэшем или двойные кавычки решат эту проблему. Например, так:
1 cd /c/Program\ Files\ \(x86\)
2 cd "/c/Program Files (x86)"
Применим кавычки и получим следующую команду для запуска Notepad++ по абсолютному пути:
"/c/Program Files (x86)/Notepad++/notepad++.exe"
Теперь Bash запустит редактор.
Каждый раз набирать полный путь установки редактора неудобно. Было бы лучше запускать Notepad++ по имени исполняемого файла. Чтобы этот способ заработал, добавьте путь установки редактора в переменную PATH. Для этого в конец файла ~/.bash_profile добавьте следующую строку:
PATH="/c/Program Files (x86)/Notepad++:${PATH}"
Перезапустите терминал MSYS2. Теперь Notepad++ запускается следующей командой:
Вместо редактирования переменной PATH можно использовать псевдонимом (alias). Этот механизм Bash заменяет введённую вами команду на другую. Таким образом можно сократить набор длинных строк.
У нас есть следующая команда для запуска Notepad++:
"/c/Program Files (x86)/Notepad++/notepad++.exe"
Объявим для неё псевдоним notepad++. Для этого вызовем Bash-команду alias так:
alias notepad++="/c/Program\ Files\ \(x86\)/Notepad++/notepad++.exe"
Теперь встретив команду notepad++, Bash заменит её на абсолютный путь до исполняемого файла редактора.
У псевдонима есть одна проблема. Его надо объявлять каждый раз после запуска терминала MSYS2. Чтобы это происходило автоматически, добавьте объявление псевдонима в конец файла ~/.bashrc. Bash исполняет все команды из этого файла при каждом запуске терминала.
После объявления псевдонима станет удобнее запускать Notepad++ из Bash. Вот пример команды, которая открывает в редакторе файл test.txt:
Если файла test.txt не существует, редактор предложит его создать.
Фоновый режим
Предположим, что вы запустили графическое приложение из терминала. После этого терминал перестанет принимать ваши команды. Его контролирует запущенное приложение. Оно выводит в терминал свои сообщения. Терминал заработает в обычном режиме только после завершения приложения.
Графическое приложение можно запустить в фоновом режиме (background). Тогда окно терминала останется активным.
Чтобы запустить программу в фоновом режиме, добавьте амперсанд & в конец команды. Например, так:
&
Эта команда откроет файл test.txt в редакторе. Notepad++ по-прежнему будет выводить свои сообщения в терминал. При этом терминал будет принимать и выполнять ваши команды. Такой режим ввода команд неудобен.
Вы можете полностью отделить графическое приложение от терминала. Для этого вызовите Bash-команду disown с опцией -a следующим образом:
&
disown -a
Теперь редактор не выводит свои сообщения в терминал. Кроме этого команда disown позволит Notepad++ работать, если вы закроете окно терминала. Без вызова disown редактор закроется вместе с терминалом.
Команды запуска Notepad++ и disown можно объединить в одну. Например, так:
& disown -a
Параметр -a команды disown отделяет все приложения запущенные в фоновом режиме.
Предположим вам нужно отделить от терминала не все приложения, а только одно. Для этого вы должны знать идентификатор процесса (PID) этого приложения. Идентификатор процесса — это уникальный номер, который ОС назначает процессу каждой запущенной программы.
Когда вы запускаете приложение в фоновом режиме, Bash выводит идентификатор его процесса. Вот пример такого вывода:
&
[1] 600
Вторая строка содержит два числа. Второе число 600 — это PID. Первое число [1] — это идентификатор задачи (job ID). Идентификатор задачи нужен, чтобы перевести приложение из фонового режима в обычный. Это делает Bash-команда fg. Вот пример её вызова для нашего случая:
fg %1
Чтобы отделить процесс Notepad++ от терминала, вызовите команду disown так:
disown 600
Вы можете вывести список всех приложений, запущенных в фоновом режиме. Это делает Bash-команда jobs. Передайте ей опцию -l, чтобы получить идентификаторы задачи и процесса для каждого запущенного приложения. Вот пример вызова jobs:
jobs -l
Можно запустить редактор Notepad++ и отделить только его от терминала одной командой. Для этого вам понадобится переменная Bash с именем $!. Она хранит PID последней выполненной команды. Передайте этот PID в disown следующим образом:
& disown $!
Зачем нужны скрипты?
В прошлой главе мы научились писать сложные Bash-команды с использованием конвейеров и логических операторов. Конвейеры объединяют несколько команд в одну. Так получается линейный алгоритм. Логические операторы добавляют в него ветвление. В результате получается настоящая программа.
Почему для программирования на Bash средств командного интерпретатора оказывается недостаточно? Bash-скрипты — это программы, хранящиеся на жёстком диске. Разберёмся, зачем они нужны.
Команда резервного копирования
Для примера напишем команду резервного копирования фотографий на внешний жёсткий диск. Команда будет состоять из двух действий: архивирования и копирования. Предположим, что фотографии хранятся в каталоге ~/photo, а /d — это точка монтирования внешнего диска. Тогда команда может быть такой:
&& cp -f ~/photo.tar.bz2 /d
Благодаря логическому И (&&), копирование выполняется только после успешного архивирования. Если утилита bsdtar вернула ошибку, копирования не будет.
Предположим, что наша команда резервного копирования будет запускаться автоматически (например, по расписанию). Тогда вы не сможете прочитать сообщение об ошибке, если что-то пойдёт не так. В таких случаях поможет вывод в лог-файл. Добавим этот вывод для вызова утилиты bsdtar. Получим:
1 bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
2 echo "bsdtar - OK" > results.txt ||
3 echo "bsdtar - FAILS" > results.txt
Bash-команду можно разбить на несколько строк. Есть два способа переноса строк:
- Перенос строки сразу после логического оператора (&& или ||).
- Перенос строки после обратного слеша .
Второй вариант выглядит так:
1 bsdtar -cjf ~/photo.tar.bz2 ~/photo \
2 && echo "bsdtar - OK" > results.txt \
3 || echo "bsdtar - FAILS" > results.txt
Теперь выведем в лог-файл результат утилиты cp. Получим:
1 cp -f ~/photo.tar.bz2 /d &&
2 echo "cp - OK" >> results.txt ||
3 echo "cp - FAILS" >> results.txt
Резервное копирование должно выполняться одной командой. Поэтому попробуем объединить вызовы bsdtar и cp логическим И. Получится следующее:
&&
echo "bsdtar - OK" > results.txt ||
echo "bsdtar - FAILS" > results.txt &&
cp -f ~/photo.tar.bz2 /d &&
echo "cp - OK" >> results.txt ||
echo "cp - FAILS" >> results.txt
Что будет делать эта команда? Для удобства перепишем её в виде логического выражения. Заменим каждый вызов команды или утилиты на букву латинского алфавита. Получится следующее:
&& O1 || F1 && C && O2 || F2
Буквы B и C обозначают вызовы утилит bsdtar и cp. O1 и F1 — это вывод в лог-файл строк “bsdtar - OK” и “bsdtar - FAIL”. Аналогично, O2 и F2 — это вывод результата cp.
Если B истинно, порядок исполнения команд очевиден. Последовательность действий будет такой:
- B
- O1
- C
- O2 или F2
Если же bsdtar вернёт ошибку, значение B будет ложь. Тогда выполнятся такие действия:
- B
- F1
- C
- O2 или F2
Операция копирования не имеет смысла, если архивирование завершилось с ошибкой. Лишние проблемы создаёт поведение утилиты bsdtar. Если указанного каталога или файла не существует, утилита создаст пустой архив. В этом случае cp успешно его скопирует. После этого в лог-файл запишется строка “cp - OK”. Тогда лог-файл будет таким:
1 bsdtar - FAILS
2 cp - OK
Такой вывод только запутает пользователя.
Вернёмся к нашему выражению:
&& O1 || F1 && C && O2 || F2
Почему утилита cp вызывается после ошибки в bsdtar? Дело в том, что команда echo всегда выполняется успешно. Её код возврата всегда истинен. Это значит, что значения O1, F1, O2 и F2 — истина.
Рассмотрим только команду вызова bsdtar и вывод её результата в лог-файл. Ей соответствует следующая часть логического выражения:
&& O1 || F1
Заключим левую часть выражения в скобки:
(B && O1) || F1
Теперь мы получили логическое ИЛИ для операндов (B && O1) и F1. F1 — всегда истина. Поэтому и всё выражение всегда истинно.
Проблему можно решить, если инвертировать результат вызова F1 с помощью логического НЕ. Оно обозначается как восклицательный знак !. Получим такое выражение:
Теперь в случае ошибки утилиты bsdtar в лог-файл будет выведено “bsdtar - FAIL”. Но оставшаяся часть выражения всё равно будет обработана. Операции C и O2 не будут выполнены. Они связаны логическим И с результатом F1, который всегда ложен. Но после них идёт действие F2. Оно будет выполнено.
Для удобства добавим к нашему выражению скобки. Получим:
Теперь очевидно, что если выражение в скобках ложно, Bash выполнит действие F2. Иначе ему не вывести значение всего выражения.
В результате выполнения всей команды в лог-файл будет выведено:
1 bsdtar - FAILS
2 cp - FAILS
Такой вывод лучше предыдущего. Теперь утилита cp не вызывается и пустой архив не копируется. Но представьте, что в нашей команде резервного копирования 100 действий. Если ошибка произойдёт на 50-ом действии, результаты всех оставшихся всё равно попадут в лог-файл. Этот вывод только помешает найти проблему. Лучшим решением было бы прекратить выполнение команды после первой же ошибки. Для этого сгруппируем вызовы утилит и выводы их результатов в лог-файл. Получим:
Проверим, что теперь произойдёт если B ложно. В этом случае выполнится действие F1. Его результат инвертируется. Поэтому вся левая часть выражения будет ложной:
Дальше из-за короткого замыкания правый операнд логического И не вычисляется. Это значит, что все действия в правой части выражения не выполнятся:
Мы получили нужное нам поведение.
Добавим последний штрих. Результат действия F2 нужно инвертировать. Тогда всё выражение будет ложным, если C ложно. Это значит, что команда резервного копирования завершилась ошибкой, если утилита cp не смогла отработать. Звучит логично. Кроме того, это полезно при интеграции нашей команды с другими командами.
Конечный вариант нашего выражения будет таким:
Теперь вернёмся к реальному коду на Bash. Наша команда резервного копирования стала такой:
1 (bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
2 echo "bsdtar - OK" > results.txt ||
3 ! echo "bsdtar - FAILS" > results.txt) &&
4 (cp -f ~/photo.tar.bz2 /d &&
5 echo "cp - OK" >> results.txt ||
6 ! echo "cp - FAILS" >> results.txt)
Как это часто бывает в программировании, такую команду несложно написать, но трудно прочитать и понять.
Плохое техническое решение
Мы написали длинную и сложную Bash-команду резервного копирования. Если она выполняется регулярно, её надо где-то сохранить. Иначе каждый раз придётся набирать команду вручную в окне терминала.
Все выполненные в терминале команды автоматически сохраняются в файле истории. У каждого пользователя он свой по пути ~/.bash_history. По комбинации клавиш Ctrl+R в этом файле можно быстро найти нужную команду.
Что если мы просто сохраним команду резервного копирования в файле истории? Там её можно будет быстро найти и исполнить. Это решение кажется надёжным и удобным. Но не торопитесь с выводами. Давайте рассмотрим возможные проблемы.
Прежде всего размер файла истории ограничен. По умолчанию сохраняются только 500 последних выполненных команд. Если превысить это число, то каждая новая команда будет записана вместо самой старой. Из-за этого команда резервного копирования может быть случайно удалена из истории.
Максимальный размер файла истории можно увеличить. Но сразу возникает вопрос: увеличить на сколько? Какой размер не выберем, есть риск его переполнения. Можно вообще снять ограничение на размер. Тогда будут сохраняться все введённые команды, а старые никогда не будут удаляться.
Кажется, нам удалось найти решение задачи: файл истории с неограниченным размером. Могут ли с ним возникнуть какие-то проблемы? Давайте подумает. Предположим, что вы используйте Bash год или два. Все введённые за это время команды попадут в файл .bash_history. Учтите, что одни и те же команды в нём дублируются. Например, каждая команда cd ~ будет записана в этот файл, даже если она там уже есть. Скорее всего за год размер файла достигнет нескольких сотен мегабайт. При этом большая часть информации в нём не нужна. Нас интересует небольшой набор команд, которые мы используем регулярно. В результате возникает первая проблема: нерациональное использование места на жёстком диске.
Вы можете возразить, что хранить лишние две-три сотни мегабайт — не проблема для современных компьютеров. Да, это так. Но не забывайте, что по нажатию Ctrl+R Bash ищет нужную команду по всему файлу .bash_history. Чем он больше, тем дольше длится поиск. Со временем вы станете ждать десятки секунд даже на мощном компьютере. Дальше с ростом файла время ожидания станет только больше.
Разрастание файла истории увеличивает время поиска. Не только потому, что Bash приходится перебирать больше строк в нём. По нажатию Ctrl+R надо ввести начало искомой команды. Представьте, что история огромна. Тогда в ней много команд, которые начинаются одинаково. Это значит, что вам придётся набрать больше символов, чтобы найти из них нужную. Неудобство вызова команды — это вторая проблема нашего решения.
Предположим, у вас появились новые альбомы фотографий. Они хранятся не в каталоге ~/photo, а например в ~/Documents/official_photo. Наша команда резервного копирования работает только с путём ~/photo. Чтобы скопировать фотографии из другого пути, команду надо переписать. Выполните новую команду. Теперь она тоже сохранилась в файле истории .bash_history. Это опять увеличит время её поиска. Итак, сложность расширения функций — третья проблема.
Возможно у вас уже есть несколько команд для резервного копирования. Одна копирует фотографии, а другая документы. Объединить их будет проблематично. Вам придётся написать новую команду, в которую войдут действия из уже существующих.
Какой можно сделать вывод? Файл истории не подходит для долговременного хранения команд. Причина всех возникших проблем одна. Мы пытаемся использовать механизм файла истории не по назначению. Он создавался не для этого. В результате мы пришли к плохому техническому решению.
От плохих решений не застрахован никто. Профессионалы с большим опытом тоже нередко к ним приходят. Почему? Причины бывают разные. В нашем случае сыграл роль недостаток знаний. Мы освоились с работой Bash в режиме командного интерпретатора. Эти знания мы применили для новой задачи. Но всех её требований не учли. Как оказалось, просто заархивировать и скопировать файлы недостаточно.
Полный список требований выглядит так:
- Команда должна храниться неограниченно долго.
- Команда должна быстро вызываться.
- Нужна возможность для её расширения.
- Нужна возможность для сочетания её с другими командами.
Для начала оценим свои знания Bash. Их просто недостаточно, чтобы удовлетворить всем этим требованиям. Все известные нам механизмы не подходят. Может быть нам бы помог Bash-скрипт? Предлагаю изучить его возможности. Затем проверим, подходит ли он для нашей задачи.
Запуск скрипта
Создадим Bash-скрипт с нашей командой для резервного копирования. Для этого сделайте следующее:
1. Откройте редактор исходного кода и создайте в нём новый файл. Если вы интегрировали Notepad++ в Bash, выполните команду:
2. Скопируйте команду резервного копирования в файл:
(bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
echo "bsdtar - OK" > results.txt ||
! echo "bsdtar - FAILS" > results.txt) &&
(cp -f ~/photo.tar.bz2 /d &&
echo "cp - OK" >> results.txt ||
! echo "cp - FAILS" >> results.txt)
- Сохраните файл с именем
photo-backup.shв домашнем каталоге пользователя. - Закройте редактор.
Мы получили файл Bash-скрипта. Чтобы его исполнить, запустите интерпретатор и передайте скрипт первым параметром. Запустить интерпретатор можно по имени его исполняемого файла — bash:
Мы только что написали и запустили наш первый Bash-скрипт. Он представляет собой последовательность команд, записанных в файл. Команды исполняются в том же порядке, как если бы вы читали их из скрипта и вводили вручную.
Запускать скрипты с явным вызовом интерпретатора Bash неудобно. Есть способ запускать их так же как и любую GNU-утилиту: по относительному или абсолютному пути. Для этого скрипт придётся изменить. Вот порядок действий:
1. В окне терминала выполните команду:
2. Откройте файл скрипта в редакторе и добавьте в начало следующую строку:
#!/bin/bash
3. Сохраните изменённый файл и закройте редактор.
Теперь скрипт запускается по относительному или абсолютному пути.
Разберём наши действия. Первое, что мешает запустить скрипт после его создания — это права доступа. По умолчанию все новые файлы получают следующие права:
Это значит, что владелец и его группа могут читать и изменять файл. Все остальные могут только читать. Запускать файл не может никто.
Утилита chmod меняет права указанного файла. Мы передали ей опцию +x. В результате все пользователи смогут запускать файл. Его битовая маска прав стала такой:
Теперь файл можно запустить по относительному или абсолютному пути. В этом случае ваш командный интерпретатор попробует его исполнить. Если вы используете Bash, скрипт выполнится корректно.
Если ваш командный интерпретатор не Bash (например, C shell), скрипт вероятно завершится с ошибкой. Проблема в том, что скрипт написан на языке одного интерпретатора, а исполняется другим.
В скрипте можно явно указать интерпретатор, который должен его исполнять. Для этого в начале файла напечатайте шебанг. Шебангом называются символы решётка и восклицательный знак #!. После них идёт абсолютный путь до файла интерпретатора. В нашем случае получится такая строка:
#!/bin/bash
Теперь Bash будет исполнять скрипт, независимо от выбранного пользователем командного интерпретатора.
Если в скрипте не указан интерпретатор для запуска, утилита file определит его как обычный текстовый файл:
После добавления строки #!, тот же файл определится как Bash-скрипт:
В некоторых системах Unix (например, FreeBSD) путь к Bash отличается от стандартного /bin/bash. Если вам важна переносимость скриптов, то вместо абсолютного пути до интерпретатора указывайте следующее:
#!/usr/bin/env bash
С помощью утилиты env исполняемый файл Bash будет найден по одному из путей переменной PATH.
Последовательность команд
Листинг 3-1 демонстрирует наш скрипт.
1 #!/bin/bash
2 (bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
3 echo "bsdtar - OK" > results.txt ||
4 ! echo "bsdtar - FAILS" > results.txt) &&
5 (cp -f ~/photo.tar.bz2 /d &&
6 echo "cp - OK" >> results.txt ||
7 ! echo "cp - FAILS" >> results.txt)
Команда резервного копирования слишком длинная. Из-за этого её трудно читать и изменять. Попробуем разбить её на две отдельные команды. Результат приведён в листинге 3-2.
1 #!/bin/bash
2
3 bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
4 echo "bsdtar - OK" > results.txt ||
5 ! echo "bsdtar - FAILS" > results.txt
6
7 cp -f ~/photo.tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Поведение скрипта изменилось. Теперь команды не связаны логическим И. Поэтому утилита cp будет вызываться независимо от результата bsdtar. Такое поведение неправильно.
Исправим скрипт. Он должен завершаться при ошибке утилиты bsdtar. Чтобы завершить скрипт, воспользуемся командой exit. В качестве параметра она принимает код возврата. Скрипт вернёт этот код после своего завершения.
Листинг 3-3 демонстрирует скрипт с вызовом exit.
1 #!/bin/bash
2
3 bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
4 echo "bsdtar - OK" > results.txt ||
5 (echo "bsdtar - FAILS" > results.txt ; exit 1)
6
7 cp -f ~/photo.tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Мы внесли два изменения в команду вызова утилиты bsdtar. Сначала она соответствовала такому выражению:
После добавления exit выражение стало выглядеть так:
Команда exit обозначена как E. Теперь если bsdtar вернёт ошибку, будет вычислен правый операнд логического ИЛИ. Он равен (F1 ; E). Мы удалили отрицание результата команды echo. Этот результат больше не важен. Не зависимо от него после echo будет вызван exit. Команды, разделённые точкой с запятой, выполняются друг за другом без каких-либо условий.
С нашим решением есть одна проблема. Когда интерпретатор встречает круглые скобки в скрипте или команде, он запускает сам себя в дочернем процессе. Такой дочерний процесс называется subshell. Он исполняет указанные в скобках команды. После этого управление передаётся обратно родительскому процессу Bash, породившему subshell. Родительский процесс продолжает исполнение скрипта или команды.
В нашем случае команда exit означает выход из subshell. Выполняющий скрипт родительский процесс Bash продолжит работу. Чтобы решить эту проблему, надо заменить круглые скобки на фигурные. Указанные в них команды будут выполняться в текущем процессе Bash без создания subshell. Исправленная версия скрипта приведена в листинге 3-4.
1 #!/bin/bash
2
3 bsdtar -cjf ~/photo.tar.bz2 ~/photo &&
4 echo "bsdtar - OK" > results.txt ||
5 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
6
7 cp -f ~/photo.tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Обратите внимание на обязательную точку с запятой перед закрывающей фигурной скобкой }. Также обязательны пробелы после открывающей скобки.
Есть решение изящнее, чем вызов команды exit. Предположим, что скрипт нужно завершить после первой команды, вернувшей ненулевой код возврата. Для этого используйте встроенную команду set. Она изменяет параметры работы интерпретатора. В нашем случае команду надо вызвать с опцией -e:
set -e
Эту же опцию -e можно указать при явном запуске Bash. Например:
У опции -e есть несколько проблем. Опция меняет поведение только текущего процесса Bash. Порождённые им subshell работают как обычно.
Каждая команда в конвейере или логическом операторе выполняется в отдельном subshell. Поэтому опция -e никак не повлияет на поведение этих команд. В нашем случае такое решение не подойдёт.
Параметризация
Предположим, что вы перенесли фотографии из каталога ~/photo в ~/Documents/Photo. Тогда в нашем скрипте резервного копирования тоже придётся поменять путь. После изменения мы получим код как на листинге 3-5.
1 #!/bin/bash
2
3 bsdtar -cjf ~/photo.tar.bz2 ~/Documents/Photo &&
4 echo "bsdtar - OK" > results.txt ||
5 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
6
7 cp -f ~/photo.tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Каждый раз при смене каталога фотографий придётся редактировать скрипт. Это неудобно. Лучше сделать скрипт универсальным. Для этого он должен принимать путь к каталогу с фотографиями в качестве параметра.
При запуске любого Bash-скрипта в него можно передать параметры командной строки. Это работает точно так же как и для любой GNU-утилиты. Просто укажите параметры через пробел после имени скрипта. Например:
Запустите наш скрипт этой командой. Интерпретатор Bash передаст в него путь к фотографиям ~/Documents/Photo. Этот путь будет доступен в коде скрипта через переменную $1. Если передать больше параметров, они будут доступны через переменные $2, $3, $4 и т. д. в зависимости от их количества. Эти параметры называются позиционными (positional parameters).
В переменную $0 запишется относительный путь к скрипту ./photo-backup.sh.
Перепишем наш скрипт. Пусть путь до каталога фотографий читается из первого параметра. Получим код как в листинге 3-6.
1 #!/bin/bash
2
3 bsdtar -cjf ~/photo.tar.bz2 "$1" &&
4 echo "bsdtar - OK" > results.txt ||
5 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
6
7 cp -f ~/photo.tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Путь до фотографий хранится в переменной $1. Мы подставляем её значение в вызов утилиты bsdtar. При этом обращение к переменной заключается в кавычки. Если их не поставить, сработает механизм word splitting. Тогда путь содержащий пробелы будет разделён на несколько параметров.
Предположим, что фотографии хранятся в каталоге ~/photo album. Тогда команда запуска скрипта будет такой:
"~/photo album"
Если передать параметр $1 без кавычек в утилиту bsdtar, её вызов будет таким:
&&
echo "bsdtar - OK" > results.txt ||
{ echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
В этом случае утилита bsdtar получит строку “/photo album" по частям. Вместо одного параметра будет два: "/photo” и “album”. Таких каталогов не существует. Поэтому скрипт завершится с ошибкой.
Заключать пути в кавычки только при вызове скрипта недостаточно. Кавычки надо применять во всех местах подстановки переменной $1 . При вызове скрипта они обрабатываются и отбрасываются командным интерпретатором Bash. Наш скрипт выполняет не этот процесс. Вместо этого он запускает дочерний процесс Bash, который читает и исполняет скрипт. Дочерний процесс Bash не знает про кавычки в команде вызова скрипта.
Итак, что нам дала параметризация скрипта? Вместо решения для резервного копирования фотографий мы сделали универсальную программу. Она работает с любыми входными файлами: документами, медиафайлами, исходным кодом программ и т.д.
У нашего скрипта есть ещё одна проблема. Она связана с именем архива. Предположим, что наш скрипт вызывается дважды для копирования фотографий и документов:
1 ./photo-backup.sh ~/photo
2 ./photo-backup.sh ~/Documents
Обе эти команды создают архив с именем photo.tar.bz2 в домашнем каталоге пользователя. Обе копируют архив на диск D. Очевидно, что результат второй команды полностью перезапишет результат первой. Это не то, что нам нужно.
Попробуем исправить ошибку. Для этого подставим первый параметр скрипта не только в качестве пути к архивируемым данным, но и вместо имени архива. Отредактированный скрипт приведён в листинге 3-7.
1 #!/bin/bash
2
3 bsdtar -cjf "$1".tar.bz2 "$1" &&
4 echo "bsdtar - OK" > results.txt ||
5 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
6
7 cp -f "$1".tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Теперь имя архива будет соответствовать каталогу с архивируемыми данными. Допустим, вы вызовите скрипт так:
1 ./photo-backup.sh ~/Documents
Тогда будет создан архив с именем Documents.tar.bz2. Он будет скопирован на диск D. При этом его имя не конфликтует с именем архива фотографий photo.tar.bz2.
Исправим последний недочёт скрипта. Заменим копирование архива на переименование. Тогда ненужный промежуточный архив в каталоге пользователя будет удалён. Результат приведён в листинге 3-8.
1 #!/bin/bash
2
3 bsdtar -cjf "$1".tar.bz2 "$1" &&
4 echo "bsdtar - OK" > results.txt ||
5 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
6
7 mv -f "$1".tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
Теперь у нас есть универсальный скрипт для резервного копирования. Его старое имя photo-backup.sh больше не подходит. Ведь скрипт умеет копировать любые данные. Переименуем его на make-backup.sh.
Сочетание с утилитами и командами
Наш универсальный скрипт для резервного копирования можно сочетать с GNU-утилитами, Bash-командами и другими скриптами.
Сейчас скрипт вызывается только по абсолютному или относительному пути. Если интегрировать его в Bash, вы сможете вызывать скрипт по имени. Тогда его станет удобнее сочетать с другими программами.
Нам знакомы два способа интеграции приложения с Bash по опыту настройки Notepad++. Кроме них есть ещё третий способ. Вот полный список вариантов:
- Добавить путь до скрипта в переменную
PATH. Для этого отредактируйте файл~/.bash_profile. - Определить псевдоним alias с абсолютным путём до скрипта. Это можно сделать в файле
~/.bashrc. - Скопировать скрипт в каталог
/usr/local/bin. Путь до него по умолчанию добавляется в переменнуюPATH. Если в вашем окружении MSYS2 этого каталога нет — создайте его.
unalias make-backup.sh
После интеграции с Bash скрипт запускается по имени. Например, так:
Скрипт можно использовать в конструкциях с конвейерами и логическими операторами также, как любую встроенную команду Bash или GNU-утилиту.
Рассмотрим пример. Предположим, что нужно создать резервную копию всех PDF документов из каталога ~/Documents. Эти документы можно найти с помощью утилиты find. Например, так:
"*.pdf"
Заархивируем и скопируем каждый найденный файл с помощью нашего скрипта. Команда для этого выглядит так:
"*.pdf" -exec make-backup.sh {} \;
В результате на диск D будут скопированы архивы с каждым найденным PDF файлом. То есть каждый файл окажется в отдельном архиве. Это неудобно. Будет лучше собрать все PDF файлы в один архив.
Попробуем обработать нашим скриптом все найденные файлы за раз. Получится такая команда:
{} +
В результате на диске D мы получим архив только первого найденного PDF файла. Куда делись остальные документы? Рассмотрим вызов утилиты bsdtar в нашем скрипте. Для простоты опустим выводы echo в лог-файл. Вызов выглядит так:
"$1".tar.bz2 "$1"
Проблема в том, что мы обрабатываем только первый позиционный параметр, переданный на вход скрипта. Он сохраняется в переменной $1. При этом игнорируются все дальнейшие параметры в переменных $2, $3 и т.д. Но именно в них передаются результаты поиска утилиты find, когда после действия -exec идёт знак +.
Чтобы решить проблему, воспользуемся переменной $@. Интерпретатор сохраняет в неё все параметры, переданные в скрипт. Перепишем вызов bsdtar следующим образом:
"$1".tar.bz2 "$@"
Теперь вместо первого параметра $1 мы передаём утилите bsdtar все входные параметры скрипта $@. Обратите внимание, что в качестве имени архива по-прежнему подставляется первый параметр $1.
Листинг 3-9 демонстрирует исправленный скрипт. Он обрабатывает произвольное число входных параметров.
1 #!/bin/bash
2
3 bsdtar -cjf "$1".tar.bz2 "$@" &&
4 echo "bsdtar - OK" > results.txt ||
5 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
6
7 mv -f "$1".tar.bz2 /d &&
8 echo "cp - OK" >> results.txt ||
9 ! echo "cp - FAILS" >> results.txt
В Bash есть переменная $*. Она очень похожа на $@. Если строку из переменной $* заключить в двойные кавычки при подстановке, Bash интерпретирует её как одно слово. В этом же случае строка в переменной $@ интерпретируется как набор слов.
Рассмотрим пример. Предположим, наш скрипт вызывается так:
"one two three"
Тогда при подстановке “$*” в скрипте мы получим:
"one two three"
Подстановка же “$@” даст следующее:
"one" "two" "three"
Возможности скриптов
На примере задачи резервного копирования мы рассмотрели возможности Bash-скриптов.
Напомним требования к задаче:
- Команда должна храниться неограниченно долго.
- Команда должна быстро вызываться.
- Нужна возможность для её расширения.
- Нужна возможность для сочетания её с другими командами.
Наш финальный скрипт make-backup.sh удовлетворяет всем этим требованиям. Проверим каждое из них:
- Скрипт хранится на жёстком диске. Это долговременная память.
- Скрипт легко интегрировать с Bash. Благодаря этому, его так же удобно вызывать, как и любую GNU-утилиту.
- Скрипт представляет собой последовательность команд. Каждая из них начинается с новой строки. Его удобно читать и редактировать. Благодаря параметризации, его легко обобщить для решения однотипных задач.
- За счёт интеграции с Bash скрипт удобно сочетать с другими командами, в том числе с помощью конвейеров и логических операторов.
Если ваша задача требует любую из перечисленных возможностей — пишите Bash-скрипт.
Переменные и параметры
В этой книге не раз упоминались переменные в Bash. Нам уже знаком список системных путей в переменной PATH. Мы использовали позиционные параметры в скрипте для резервного копирования. Настало время хорошо разобраться в этой теме.
Сначала выясним, что называется переменной в программировании. Это область памяти, в которой хранится значение. Обычно переменная находится в кратковременной памяти: RAM, регистры или кэш процессора.
Первые языки программирования (например, ассемблер) имели ограниченную поддержку переменных. В этих языках все обращения к памяти происходят по адресу. Чтобы записать новое значение переменной или прочитать текущее, надо указать адрес памяти.
В 32-разрядных процессорах длина адреса памяти 4 байта. Это число от 0 до 4294967295. В 64-разрядных процессорах длина адреса в два раза больше. Работать с такими большими числами неудобно. Поэтому современные языки программирования позволяют заменять адреса переменных на их имена. Эти имена в процессе компиляции или интерпретации программы транслируются в адреса памяти. Таким образом всю работу по “запоминанию” больших чисел берёт на себя компилятор или интерпретатор.
Зачем нужны переменные? Наш опыт работы с PATH и позиционными параметрами показал, что переменные хранят какие-то данные. Это нужно для одной из следующих целей:
- Передать информацию из одной части программы или системы в другую.
- Сохранить промежуточный результат вычислений для дальнейшего использования.
- Сохранить текущее состояние программы или системы. Это состояние может определять дальнейшее поведение.
- Задать константное значение, которое позже будет многократно использоваться.
Для каждой цели в языках программирования вводится специальный тип переменной. Язык Bash не исключение.
Классификация переменных
У интерпретатора Bash есть два режима работы: интерактивный (командная оболочка) и неинтерактивном (исполнение скриптов). В каждом режиме переменные решают сходные задачи. Но контексты этих задач различаются. Поэтому признаков для классификации переменных в Bash больше, чем в других интерпретируемых языках.
Упростим терминологию для удобства. Это не совсем правильно, но позволит избежать путаницы. Когда говорим о скриптах, будем использовать термин “переменная” (variable). Когда речь о командной оболочке и аргументах командной строки, будем применять термин “параметр” (parameter). В английской литературе эти термины часто используют как синонимы.
Для классификации переменных в Bash есть четыре признака. Они приведены в таблице 3-1.
| Признак классификации | Типы | Определение | Примеры |
|---|---|---|---|
| Механизм установки | Пользовательские переменные | Устанавливаются пользователем. | filename="README.txt" ; echo "$filename" |
| Зарезервированные (системные) переменные | Устанавливаются интерпретатором и нужны для его корректной работы. | echo "$PATH" |
|
| Специальные параметры | Устанавливаются интерпретатором и доступны только для чтения. | echo "$?" |
|
| Область видимости | Переменные окружения (или глобальные) | Доступны в любом экземпляре интерпретатора. Выводятся утилитой env, запущенной без параметров. |
echo "$PATH" |
| Локальные переменные | Доступны только в конкретном экземпляре интерпретатора. | filename="README.txt" ; echo "$filename" |
|
| Содержимое | Строка | Хранит строку. | filename="README.txt" |
| Число | Хранит целое число. | declare -i number=10/2 ; echo "$number" |
|
| Индексируемый массив | Хранит нумерованный список строк. | cities=("London" "New York" "Berlin") ; echo "${cities[1]}" |
|
cities[0]="London" ; cities[1]="New York" ; cities[2]="Berlin" ; echo "${cities[1]}" |
|||
| Ассоциативный массив | Структура данных, каждый элемент которой — это пара ключ-значение. Ключом и значением являются строки. | declare -A cities=( ["Alice"]="London" ["Bob"]="New York" ["Eve"]="Berlin" ) ; echo "${cities[Bob]}" |
|
| Возможность изменения | Константны | Не могут быть удалены. Хранят значения, которые нельзя переопределить. | readonly CONSTANT="ABC" ; echo "$CONSTANT" |
declare -r CONSTANT="ABC" ; echo "$CONSTANT" |
|||
| Переменные | Могут быть удалены. Их значения можно переопределить. | filename="README.txt" |
Рассмотрим каждый тип переменных.
Механизм установки
Пользовательские переменные
Назначение пользовательских переменных очевидно из названия. Их объявляет пользователь для своих целей. Такие переменные обычно хранят промежуточные результаты работы скрипта, его состояние и часто используемые константы.
Чтобы объявить пользовательскую переменную, укажите её имя, поставьте знак равно и наберите значение переменной.
Рассмотрим пример. Объявим переменную с именем filename. В ней хранится имя файла README.txt. Объявление переменной выглядит так:
filename="README.txt"
Пробелы до и после знака равно не ставятся. Другие языки программирования это допускают, но не Bash. Это значит, что интерпретатор не сможет обработать следующее объявление:
filename = "README.txt"
Bash интерпретируют эту строку как вызов команды filename с двумя параметрами = и "README.txt"
В именах переменных допустимы только символы латинского алфавита, числа и знак подчёркивания _. Имя не должно начинаться с числа. Регистр букв важен. Это значит, что filename и FILENAME — две разные переменные.
Предположим, что мы объявили переменную filename. В результате для неё выделилась область в памяти процесса интерпретатора. В этой области сохранилась строка README.txt. Чтобы прочитать строку из памяти, к переменной надо обратиться по имени. При этом интерпретатор Bash должен понять, что вы имеете в виду. Если поставить знак доллара $ перед словом filename, Bash обработает его как имя переменной.
Обращение к переменной в команде или скрипте должно выглядеть так:
$filename
Bash обрабатывает слова со знаком доллара по-особенному. Встретив такое слово в команде, интерпретатор запускает механизм подстановки переменных (parameter expansion). Этот механизм заменяет все вхождения имени переменной на её значение. Рассмотрим следующую команду:
$filename ~
После подстановки переменных она будет выглядеть так:
Всего интерпретатор совершает девять видов подстановок. Порядок их выполнения важен. Если его не учесть, могут возникнуть ошибки. Рассмотрим пример такой ошибки. Предположим, что в скрипте мы работаем с файлом “my file.txt”. Для удобства поместим его имя в переменную. Её объявление выглядит так:
filename="my file.txt"
Далее переменная используется в вызове утилиты cp. Команда её вызова выглядит так:
$filename ~
После подстановки переменных Bash выполняет word splitting. Это другой механизм подстановки. После него вызов утилиты cp станет таким:
Эта команда завершится с ошибкой. Вместо одного параметра с именем файла, в утилиту cp передаются два: my и file.txt. Таких файлов не существует.
Если в значении переменной встречается специальный символ, опять возникнет проблема. Например:
1 filename="*file.txt"
2 rm $filename
В результате вызова утилиты rm будут удалены все файлы, заканчивающиеся на file.txt. В этом виноват механизм globbing. Он тоже выполняется после подстановки переменных. После globbing в утилиту rm будут переданы все файлы из текущего каталога, имена которых соответствуют шаблону поиска *file.txt. Это может привести к неожиданному результату. Например, такому:
Чтобы избежать нежелательных подстановок Bash, заключайте все обращения к переменным в двойные кавычки “. Например, так:
1 filename1="my file.txt"
2 cp "$filename1" ~
3
4 filename2="*file.txt"
5 rm "$filename2"
Благодаря кавычкам, значение переменной будет подставлено без дальнейших изменений:
1 cp "my file.txt" ~
2 rm "*file.txt"
Мы уже знаем несколько подстановок, которые выполняет Bash. Таблица 3-2 приводит их полный список и порядок выполнения.
| Порядок выполнения | Подстановка | Комментарий | Пример |
|---|---|---|---|
| 1 | Brace Expansion | Подстановка фигурных скобок. | echo a{d,c,b}e |
| 2 | Tilde Expansion | Подстановка символа тильда ~. | cd ~ |
| 3 | Parameter Expansion | Подстановка параметров и переменных. | echo "$PATH" |
| 4 | Arithmetic Expansion | Подстановка вместо арифметических выражений их результатов. | echo $((4+3)) |
| 5 | Command Substitution | Подстановка вместо команды её вывода. | echo $(< README.txt) |
| 6 | Process Substitution | Подстановка вместо команды её вывода. В отличие от Command Substitution эта подстановка выполняется асинхронно. Ввод и вывод команды привязаны к временному файлу. | diff <(sort file1.txt) <(sort file2.txt) |
| 7 | Word Splitting | Разделение аргументов командной строки на слова и передача их в качестве отдельных параметров. | cp file1.txt file2.txt ~ |
| 8 | Filename Expansion (globbing) | Подстановка имён файлов вместо шаблонов. | rm ~/delete/* |
| 9 | Quote Removal | Удаление всех неэкранированных символов \, ‘ и “, которые не были получены в результате одной из предыдущих подстановок. | cp "my file.txt" ~ |
Знак $ перед именем переменной — это сокращенная форма подстановки переменных. В полном виде она выглядит так:
${filename}
Используйте полную форму, чтобы избежать неоднозначности. Например, если сразу за именем переменной следует текст:
1 prefix="my"
2 name="file.txt"
3 cp "$prefix_$name" ~
Тогда интерпретатор ищет переменную с именем prefix_. То есть он приклеит символ подчёркивания к имени переменной. Полная форма записи подстановки переменных решит эту проблему:
"${prefix}_${name}" ~
Альтернативное решение — заключить каждое имя переменной в кавычки. Например, так:
"$prefix"_"$name" ~
Полная форма записи подстановки переменных устраняет неоднозначности. Кроме этого она поможет, когда переменная не была определена. В этом случае можно подставить некоторое значение по умолчанию. Например:
"${directory:-~}"
При обработке этой команды Bash проверит, определена ли переменная directory и имеет ли она непустое значение. Если это так, выполнится обычная подстановка. В противном случае Bash подставит значение, следующее за символом минус -. В нашем примере — это домашний каталог пользователя ~.
Задать значение по умолчанию можно несколькими способами. Все они приведены в таблице 3-3.
| Форма записи | Описание |
|---|---|
${parameter:-word} |
Если переменная parameter не объявлена или имеет пустое значение, будет подставлено значение по умолчанию word. В противном случае подставляется значение переменной. |
${parameter:=word} |
Если переменная не объявлена или имеет пустое значение, ей будет присвоено значение по умолчанию. Затем она будет подставлена. В противном случае подставляется значение переменной. Переопределение позиционных и специальных параметров таким способом недопустимо. |
${parameter:?word} |
Если переменная не объявлена или имеет пустое значение, значение по умолчанию будет выведено в стандартный поток ошибок. После этого выполнение скрипта будет завершено с кодом возврата отличным от 0. В противном случае подставляется значение переменной. |
${parameter:+word} |
Если переменная не объявлена или имеет пустое значение, подстановки не будет. В противном случае подставляется значение по умолчанию. |
Зарезервированные переменные
Переменные может объявлять не только пользователь, но и сам интерпретатор. В этом случае они называются зарезервированными (reserved) или переменными оболочки (shell variables). Интерпретатор присваивает им значение по умолчанию. Значение некоторых переменных оболочки можно изменить.
Зарезервированные переменные исполняют две функции:
- Передача информации от командного интерпретатора в запускаемое им приложение.
- Хранение текущего состояния самого интерпретатора.
Переменные оболочки делятся на две группы:
- Переменные Bourne Shell.
- Переменные Bash.
Первая группа унаследована из Bourne Shell и нужна Bash для POSIX-совместимости. Часто используемые из этих переменных представлены в таблице 3-4.
| Имя | Значение |
|---|---|
HOME |
Домашний каталог текущего пользователя. Значение переменной используется при вызове встроенной команды cd без параметров и подстановке символа тильда ~. |
IFS |
Список следующих друг за другом символов-разделителей. Вводимые строки будут разделены этими символами на слова (например, при word splitting). По умолчанию разделители такие: пробел, табуляция, перевод строки. |
PATH |
Список путей, по которым интерпретатор ищет вызываемые утилиты и программы. Пути в списке разделены двоеточиями. |
PS1 |
Приглашение командной строки. Может включать управляющие символы. Перед выводом на экран они заменятся на конкретные значения (например, имя текущего пользователя). |
Кроме унаследованных переменных оболочки Bourne Shell в Bash появились новые. Они приведены в таблице 3-5. Кроме перечисленных есть и другие переменные Bash, но они используются редко.
| Имя | Значение |
|---|---|
BASH |
Полный путь до исполняемого файла Bash. Этот файл соответствует текущему процессу Bash. |
BASHOPTS |
Список дополнительных опций текущего процесса Bash. Опции в списке разделены двоеточиями. |
BASH_VERSION |
Версия запущенного Bash интерпретатора. |
GROUPS |
Список групп, к которым относится текущий пользователь. |
HISTCMD |
Номер текущей команды в истории команд. |
HISTFILE |
Файл, в котором сохраняется история команд. По умолчанию это ~/.bash_history. |
HISTFILESIZE |
Максимально допустимое число строк в файле истории команд. Значение по умолчанию 500. |
HISTSIZE |
Максимально допустимое число команд в файле истории команд. Значение по умолчанию 500. |
HOSTNAME |
Имя текущего компьютера как узла вычислительной сети. |
HOSTTYPE |
Строка с описанием аппаратной платформы, на которой запущен Bash. |
LANG |
Региональные настройки пользовательского интерфейса. Некоторые из них переопределяются переменными LC_ALL, LC_COLLATE, LC_CTYPE, LC_MESSAGES, LC_NUMERIC, LC_TYPE. |
MACHTYPE |
Строка с описанием системы, на которой запущен Bash. Включает в себя информацию из переменных HOSTTYPE и OSTYPE. |
OLDPWD |
Предыдущий рабочий каталог, который устанавливала встроенная команда cd. |
OSTYPE |
Строка с описанием ОС, на которой запущен Bash. |
POSIXLY_CORRECT |
Если эта переменная определена, Bash работает в режиме POSIX-совместимости. |
PWD |
Текущий каталог, который установила встроенная команда cd. |
RANDOM |
Каждый раз при чтении этой переменной возвращается случайное число от 0 до 32767. При записи переменной назначается инициализирующее число (seed) для генератора псевдослучайных чисел. |
SECONDS |
Количество секунд, прошедших с момента запуска текущего процесса Bash. |
SHELL |
Полный путь к исполняемому файлу командного интерпретатора для текущего пользователя. |
SHELLOPTS |
Список дополнительных опций комндного интерпретатора. Опции в списке разделены двоеточиями. |
SHLVL |
Уровень вложенности текущего экземпляра Bash. Эта переменная увеличивается на единицу каждый раз при запуске Bash из командного интерпретатора. |
UID |
Идентификатор текущего пользователя. |
Зарезервированные переменные делятся на три группы в зависимости от допустимых над ними действий:
- При запуске интерпретатор назначает переменной значение. В течении всей сессии оно остаётся неизменным. Пользователь может его прочитать, но не изменить. Примеры:
BASHOPTS,GROUPS,SHELLOPTS,UID. - При запуске интерпретатор назначает переменной значение по умолчанию. Оно меняется в результате выполнения пользователем команд или иных событий. Значение некоторых переменных можно переобъявить явно, но это может нарушить работу интерпретатора. Примеры:
HISTCMD,OLDPWD,PWD,SECONDS,SHLVL. - При запуске интерпретатор назначает переменной значение по умолчанию. Единственный способ его изменить — это переобъявить. Примеры:
HISTFILESIZE,HISTSIZE
Специальные параметры
Специальные параметры назначаются интерпретатором, как и переменные оболочки. Некоторые параметры хранят состояние запущенного экземпляра Bash (например, PID). Другие нужны для передачи параметров командной строки в вызываемые приложения и чтения их кода возврата. Все позиционные параметры относятся к специальным.
Часто используемые специальные параметры приведены в таблице 3-6.
| Имя | Значение |
|---|---|
$* |
Строка со всеми позиционными параметрами, переданными в скрипт. Параметры начинаются с первого $1, а не с нулевого $0. Без двойных кавычек ($*) каждый позиционный параметр подставляется как отдельное слово. С двойными кавычками (“$*”) Bash подставляет все параметры как одну строку с кавычками. Эта строка содержит все параметры, разделённые первым символом из зарезервированной переменной IFS. |
$@ |
Массив строк со всеми позиционными параметрами, переданными в скрипт. Параметры начинаются с первого ($1). Без двойных кавычек ($@) Bash обрабатывает каждый элемент массива как строку без кавычек. В этом случе выполняется word splitting. С двойными кавычками (“$@”) Bash обрабатывает каждый элемент массива как строку с кавычками. Word splitting не происходит. |
$# |
Число позиционных параметров, переданных в скрипт. |
$1, $2… |
Содержит значение соответствующего позиционного параметра. $1 соответствует первому параметру, $2 — второму и т.д. Номера указываются в десятичной системе. |
$? |
Код возврата последней выполненной команды в активном режиме (foreground). Если команды выполнялись в конвейере, параметр хранит код возврата последней из них. |
$- |
Содержит опции текущего экземпляра интерпретатора. |
$$ |
Идентификатор процесса текущего экземпляра интерпретатора. При подстановке в subshell, возвращает PID родительского процесса. |
$! |
Идентификатор процесса PID последней команды, запущенной в фоновом режиме. |
$0 |
Имя текущего командного интерпретатора или выполняемого в данный момент скрипта. |
Специальные параметры нельзя менять непосредственно. Например, следующее перезапись параметра $1 не сработает:
1="new value"
Позиционные параметры можно изменять командой set. Она перезаписывает не один параметр, а сразу все. Форма вызова set в этом случае следующая:
set -- НОВОЕ_ЗНАЧЕНИЕ_$1 НОВОЕ_ЗНАЧЕНИЕ_$2 НОВОЕ_ЗНАЧЕНИЕ_$3...
Что делать, если нужно изменить только один параметр? Предположим, ваш скрипт вызывается с четырьмя параметрами. Например, так:
Заменим третий параметр arg3 на значение new. Это сделает такой вызов set:
set -- "${@:1:2}" "new" "${@:4}"
Первый аргумент set — подстановка первых двух элементов из массива $@. Второй аргумент — новое значение третьего параметра. Дальше подставляются все параметры, начиная с четвертого.
Все специальные параметры из таблицы 3-6 доступны в режиме POSIX-совместимости.
Область видимости
Переменные окружения
В любой программе и программной системе переменные разделены по областям видимости (scope). Область видимости — это часть программы или системы, в которой имя переменной остаётся связанным с её значением. Другими словами конвертировать имя переменной в её адрес можно только в области видимости этой переменной. За пределами области видимости то же самое имя может быть связано с другой переменной.
Область видимости называется глобальной (global scope), если распространяется на всю систему. То есть переменные этой области видимости доступны из любой части программы или системы.
Все зарезервированные переменные Bash находятся в глобальной области видимости. Переменные в этой области видимости называются переменными окружения (environment variables). Получается, что все зарезервированные переменные являются переменными окружения. Пользовательские переменные также можно объявлять в глобальной области видимости. Тогда они станут переменными окружения.
Зачем интерпретатор хранит переменные в глобальной области видимости? Дело в том, что в Unix есть специальный набор настроек. Они влияют на поведение запускаемых пользователем приложений. Например, региональные настройки. Согласно им каждое запущенное приложение адаптирует свой интерфейс. Именно такие настройки передаются через переменные окружения.
Предположим, что один процесс порождает дочерний процесс. В этом случае дочерний процесс копирует все переменные окружения родителя. Таким образом все утилиты и приложения, запущенные из командного интерпретатора, наследуют его переменные окружения. Так глобальные настройки передаются во все запускаемые пользователем программы.
Дочерние процессы могут изменять свои переменные окружения. В результате порождённые ими процессы унаследуют эти изменения. Однако, это никак не отразится на соответствующих переменных родительского процесса.
Чтобы объявить переменную окружения, используйте встроенную команду export. Например:
export BROWSER_PATH="/opt/firefox/bin"
Переменную можно сначала объявить, а потом поместить в глобальную область видимости. Например:
1 BROWSER_PATH="/opt/firefox/bin"
2 export BROWSER_PATH
Переменные окружения можно объявлять и переопределять для каждого запускаемого приложения отдельно. Для этого в команде вызова программы перечислите их имена и значения через пробел. Например, следующим образом:
MOZ_WEBRENDER=1 LANG="en_US.UTF-8" /opt/firefox/bin/firefox
Такое решение работает для интерпретатора Bash. Для других интерпретаторов (например, Bourne Shell) придётся использовать утилиту env. Вызовите утилиту, перечислите через пробел переменные окружения и добавьте команду запуска приложения. Например, так:
MOZ_WEBRENDER=1 LANG="en_US.UTF-8" /opt/firefox/bin/firefox
Вызовите утилиту env без параметров. Она выведет все объявленные переменные окружения для текущего экземпляра интерпретатора. Попробуйте получить этот вывод в своём терминале:
Команда export и утилита env выводят одно и то же, если вызвать их без параметров. Предпочтительней использовать export. Во-первых, вывод команды отсортирован. Во-вторых, все значения переменных заключены в двойные кавычки. Это убережёт вас от ошибки, если в значении переменной встретится перевод строки.
Исторически сложилось так, что имена переменных окружения пишутся буквами в верхнем регистре. Поэтому давать имена локальным переменным в нижнем регистре считается хорошей практикой. Таким образом вы предотвратите случайное использование одной переменной вместо другой.
Локальные переменные
Мы познакомились с пользовательскими переменными. В зависимости от способа их объявления они могут быть локальными или переменными окружения (глобальными).
Добавить переменную в глобальную область видимости можно одним из следующих способов:
- Добавить команду export в объявление переменной.
- Передать переменную при запуске программы. Это можно сделать как с помощью утилиты env, так и без неё.
Если вы не сделали ничего из перечисленного, переменная будет локальной. Она будет доступна только в текущем экземпляре интерпретатора. Говорят, что локальная переменная имеет ограниченную область видимости (local scope). При этом никакие дочерние процессы (кроме subshell) её не наследуют.
Рассмотрим пример. Предположим, что вы объявили переменную в окне терминала MSYS2 следующим образом:
filename="README.txt"
Теперь в этом же окне терминала вы можете вывести её значение:
echo "$filename"
Та же самая команда отработает корректно, если выполнить её в subshell:
(echo "$filename")
Однако, если прочитать значение переменной из дочернего процесса, получится пустое значение. Чтобы запустить дочерний процесс, вызовите новый экземпляр интерпретатора в окне терминала. Например, так:
'echo "$filename"'
В опции -c передаётся команда, которая выполнится дочерним процессом Bash. Аналогичный вызов Bash происходит неявно при запуске скрипта из командного интерпретатора.
Обратите внимание на одинарные кавычки ‘, в которые мы поместили вызов echo. Они отключают все подстановки для строки в них. У двойных кавычек поведение отличается. Они разрешают только подстановку команд и параметров. Если в нашем вызове bash использовать двойные кавычки, то произойдёт подстановка параметров. В результате команда запуска дочернего процесса Bash станет такой:
"echo README.txt"
Это совсем не то, что нам нужно. Мы проверяем, как дочерний процесс прочитает значение локальной переменной. В данном случае родительский процесс уже подставил это значение в вызов bash.
При изменении локальной переменной в subshell, её значение в родительском процессе не изменится. Например, в результате следующих команд напечатается строка “README.txt”:
1 filename="README.txt"
2 (filename="CHANGELOG.txt")
3 echo "$filename"
То есть присвоение переменной filename нового значения в subshell никак не отразилось на родительском процессе.
После объявления локальной переменной она попадает в список переменных оболочки (shell variables). К ним относятся все локальные переменные и переменные окружения, доступные в текущем экземпляре интерпретатора. Их можно вывести встроенной командой set, если запустить её без параметров. Попробуйте найти нашу переменную filename следующим образом:
set | grep filename=
В выводе этой команды вы увидите следующую строку:
filename=README.txt
Это значит, что переменная filename попала в список переменных оболочки.
Содержимое переменной
Типы переменных
В компилируемых языках программирования (например, C) принято использовать статическую типизацию. Это означает, что при объявлении переменной указывается, как хранить её значение в памяти. Рассмотрим пример, чтобы лучше понять о чём речь.
Предположим, что мы объявляем переменную с именем number. В объявлении обязательно надо указать её тип. Например, целое беззнаковое (положительное) число размером два байта. В результате на эту переменную в памяти будет отведено ровно два байта. Далее переменной присваиваем значение 203 или 0xCB в шестнадцатеричной системе. В памяти это значение сохранится в следующем виде:
00 CB
Чтобы хранить значение 203, достаточно и одного байта. Но при объявлении переменной мы зарезервировали два. Неиспользуемый байт в нашем случае останется равным нулю. Во всей области видимости переменной number никто не сможет использовать этот байт. Если переменная находится в глобальной области видимости, на протяжении работы программы этот байт будет зарезервирован и не использован.
Если переменной присвоить значение 14037 или 0x36D5, в отведённую ей область памяти запишутся следующие два байта:
36 D5
Теперь предположим, что в переменной нужно сохранить значение 107981 или 0x1A5CD. Это число не помещается в два байта. Размер переменной определён при её объявлении и не может быть автоматически расширен. Поэтому записываемое значение будет обрезано до двух байтов. В результате в памяти окажется следующее:
Старшая единица была отброшена. Теперь если вы прочитаете значение переменной number, то получите 42445 или 0xA5CD. Это значит, что записанное в number число 107981 потеряно и его невозможно восстановить. Такая проблема называется переполнением.
Рассмотрим другой пример статической типизации. Предположим, что нам нужно сохранить имя пользователя в переменной username. Для этого объявляем переменную строкового типа. Во многих компилируемых языках программирования при объявлении строки надо указать её допустимую длину. Для примера длина составляет десять символов. После объявления переменной присваиваем ей значение “Alice” в ASCII-кодировке. Если использовать компилятор языка C, строка в памяти будет выглядеть так:
41 6C 69 63 65 00 00 00 00 00
Для хранения строки “Alice” достаточно шести байтов: пять для каждой буквы плюс один для нуль-терминатора (00) на конце. Однако, мы зарезервировали десять байтов, поэтому неиспользуемая память будет заполнена нулями или случайными значениями.
Динамическая типизация — это альтернатива статической типизации. При динамической типизации способ хранения переменной выбирается иначе. Это происходит не в момент объявления переменной, а в момент присваивания ей нового значения. При присваивании переменной назначается метаинформация о её текущем типе. Пока программа исполняется, значение переменной и соответствующая метаинформация могут меняться. Таким образом представление переменной в памяти также меняется. Динамическая типизация обычно применяется в интерпретируемых языках программирования (например, Python).
Строго говоря, в языке Bash нет системы типов. Его нельзя считать языком со статической или динамической типизацией. В Bash все скалярные переменные являются строками.
Скалярной называется переменная, которая хранит данные примитивного типа. Это минимальные строительные блоки из которых собираются данные более сложных составных типов. Как правило, скалярная переменная — это просто имя для адреса памяти, по которому хранится её значение.
Рассмотрим, как Bash представляет свои скалярные переменные в памяти. Есть следующее объявление:
declare -i number=42
В памяти переменная number будет сохранена как строка:
34 32 00
В языке с системой типов достаточно одного байта для хранения этого числа. Но в Bash нам потребовалось три: по байту для каждого символа (4 и 2) плюс нуль-терминатор на конце.
В Bourne Shell есть только скалярные переменные. В Bash появились два новых составных типа: индексируемый массив и ассоциативный массив.
Индексируемый массив представляет собой пронумерованный набор строк. В нём каждой строке соответствует порядковый номер. Массивы этого типа хранятся в памяти в виде связанного списка. Связанный список — это структура данных, состоящая из узлов. Каждый узел содержит данные (в нашем случае строку) и адрес в памяти следующего узла.
Ассоциативный массив устроен сложнее. Он представляет собой набор элементов. Каждый элемент состоит из двух строк. Первая из них называется ключом, а вторая — значением. Чтобы прочитать или записать строку в массив, нужно указать соответствующий ей ключ. Точно так же в индексируемом массиве для доступа к строке указывается её порядковый номер. Очевидно, что под одним номером может храниться только одна строка. Аналогично один ключ в ассоциативном массиве соответствует только одной строке. В памяти такой массив хранится в виде хеш-таблицы.
Почему “массивы” в Bash называются массивами? Ведь фактически они представляют собой связанные списки и хэш-таблицы. Настоящий массив — это структура данных, элементы которой хранятся в памяти последовательно друг за другом. У каждого элемента есть порядковый номер, называемый индексом (index) или идентификатором. Элементы “массивов” в Bash хранятся в памяти не последовательно. Значит согласно определению, это не массивы.
Рассмотрим, как элементы настоящего массива хранятся в памяти. Предположим, у нас есть массив с числами от пяти до девяти. Каждый его элемент занимает один байт. Тогда размер массива равен пяти байтам. В памяти он будет выглядеть следующим образом:
05 06 07 08 09
Индексы начинаются с нуля. Тогда элемент с порядковым номером ноль равен пяти, а с номером три — восьми. Элементы в памяти следуют друг за другом. Индекс представляет собой смещение в памяти относительно начала массива.
Вернёмся к вопросу о названиях структур данных в Bash. Ответ на него знают только авторы языка. Однако, мы можем предположить. Название “массив” даёт пользователю подсказку о том, как следует работать с этой структурой. Имея опыт в других языках (например, C) пользователь знает, что читать и писать отдельные элементы массива надо по индексу. Поэтому он сможет использовать уже знакомый ему синтаксис языка C в Bash. При этом пользователю совсем необязательно знать, как на самом деле “массив” Bash хранится в памяти.
Атрибуты
У языка Bash нет системы типов. В нём все скалярные переменные хранятся в памяти как строки. Но в Bash есть составные типы — массивы. Они представляют собой комбинации строк.
Тип переменной (скалярная или составная) выбирается при её определении. Для этого надо указать метаинформацию, которая в Bash называется атрибутами. Кроме типа атрибуты определяют константность и область видимости переменной.
Чтобы указать атрибуты переменной, используйте встроенную команду declare. Если вызвать её без параметров, она выведет имена и значения всех объявленных в данный момент переменных: локальных и окружения. Эту же информацию выводит команда set.
У команды declare есть опция -p. Она добавляет в вывод атрибуты переменных.
Если вам нужна информация по конкретной переменной, передайте команде declare её имя. Например, так:
declare -p PATH
Команда declare без параметров выводит информацию не только об объявленных переменных, но и о доступных подпрограммах. В Bash они называются функциями. Функция — это фрагмент программы или самостоятельный блок кода, который выполняет определённую задачу.
Чтобы команда declare вывела только информацию о функциях, используйте опцию -f. Например, так:
declare -f
Если вас интересует конкретная функция, укажите её имя после опции -f. Пример для функции quote:
declare -f quote
Эта команда выведет на экран определение функции.
"this is a 'test' string"
Без опции -f declare не сможет вывести определение конкретной функции. То есть следующая команда не сработает:
declare quote
Команда declare не только выводит информацию об уже объявленных переменных и функциях. Она также устанавливает атрибуты при объявлении новой переменной.
Часто используемые опции команды declare приведены в таблице 3-7.
| Опция | Значение |
|---|---|
-a |
Объявленная переменная является индексируемым массивом. Элементы такого массива доступны по целочисленным номерам. |
-A |
Объявленная переменная является ассоциативным массивом. Каждому элементу такого массива соответствует ключ-строка. |
-g |
Объявление переменной в глобальной области видимости скрипта. При этом переменная не попадает в окружение. |
-i |
Объявление целочисленной переменной. Присваиваемое ей значение обрабатывается как арифметическое выражение. |
-r |
Объявление константы. После объявления ей нельзя присвоить другое значение. |
-x |
Объявление переменной окружения. |
Рассмотрим примеры объявлений с атрибутами. Начнём с целочисленных и строковых переменных. Выполните в окне терминала следующее:
1 declare -i sum=11+2
2 text=11+2
Мы объявили две переменные с именами sum и text. Первая из них объявлена как целочисленная. Её значение равно 13 (сумма чисел 11 и 2). Значение второй переменной text равно строке “11+2”.
Обратите внимание, что обе переменные хранятся в памяти в виде строк. Опция -i не задаёт тип переменной, а ограничивает её допустимые значения.
Попробуйте присвоить переменной sum строку. Например, одним из следующих способов:
1 declare -i sum="test"
2 sum="test"
В результате переменная sum станет равна нулю.
Предположим, вы объявили переменную как целочисленную. Тогда для арифметических операции над ней не нужны дополнительные подстановки Bash. Например, следующие команды выполнятся корректно:
1 sum=sum+1 # 13 + 1 = 14
2 sum+=1 # 14 + 1 = 15
3 sum+=sum+1 # 15 + 15 + 1 = 31
В комментариях к командам приводятся их результаты.
Выполним те же самые операции со строковой переменной. Результаты будут отличаться:
1 text=text+1 # "text+1"
2 text+=1 # "text+1" + "1" = "text+11"
3 text+=text+1 # "text+11" + "text" + "1" = "text+11text+1"
Вместо арифметических операций над числами произошло склеивание строк. Чтобы выполнить эти операции над текстовой переменной, нужна арифметическая подстановка. Например:
1 text=11
2 text=$(($text + 2)) # 11 + 2 = 13
Опция -r команды declare объявляет переменную константой. Например, так:
declare -r filename="README.txt"
Теперь при каждой попытке изменить значение переменной filename или удалить её, Bash выводит сообщение об ошибке. Поэтому следующие команды завершатся с ошибкой:
1 filename="123.txt"
2 unset filename
Команда declare с опцией -x объявляет переменную окружения. То же самое объявление делает команда export. Следующие два объявления переменной BROWSER_PATH эквивалентны:
1 export BROWSER_PATH="/opt/firefox/bin"
2 declare -x BROWSER_PATH="/opt/firefox/bin"
Хорошей практикой считается использовать команду export вместо declare с -x. Это улучшает читаемость кода. Вам не нужно вспоминать, что значит опция -x. По этой же причине предпочитайте использовать команду readonly вместо declare с -r. Она тоже объявляет константу и её проще запомнить.
Обратите внимание, что команда readonly объявляет переменную в глобальной области видимости скрипта. Команда declare с -r даст другой результат. Если использовать declare в теле функции, объявленная переменная будет локальной. Вне функции она недоступна. Чтобы переменная стала глобальной (как с readonly), используйте опцию declare -g. Например, так:
declare -gr filename="README.txt"
Индексируемые массивы
В Bourne Shell есть только скалярные переменные (строки). В Bash по просьбам пользователей разработчики добавили массивы. Когда они могут понадобиться?
У строкового типа есть серьёзное ограничение. При записи в скалярную переменную какого-то значения, логически получается один элемент. Например, вы сохраняете в переменную с именем files список файлов. Элементы списка разделены пробелами. В результате files хранит одну строку с точки зрения Bash. Это может привести к ошибкам.
Как мы выяснили, стандарт POSIX разрешает любые символы в именах файлов, кроме нуль-терминатора (NUL). NUL означает конец имени файла. Этот же самый символ в Bash означает конец строки. Поэтому строковая переменная может содержать NUL не в произвольном месте, а только в конце. Получается, у вас нет надёжного способа разделить имена файлов в списке. NUL использовать нельзя. Любой другой символ-разделитель может встретиться в этих именах.
Именно проблема разделителя мешает надёжно обработать вывод утилиты ls. Утилита find позволяет разделять элементы своего вывода с помощью NUL, а ls - нет. Никакой символ кроме NUL не будет надёжным разделителем. Поэтому не объявляйте переменные так:
files=$(ls Documents/*.txt)
В результате в переменную files будет записана строка со всеми TXT файлами каталога Documents. Если в именах файлов встречаются пробелы или символы переноса строки, восстановить исходную информацию будет проблематично.
Массивы добавлены в Bash для решения этой проблемы. Массив хранит список отдельных элементов. Прочитать их в исходном виде не составляет труда. Поэтому вместо присваивания переменной вывода утилиты ls, используйте массив. Например:
declare -a files=(Documents/*.txt)
Инициализацией массива называется определение его элементов. Массив можно инициализировать при объявлении или после. В примере выше инициализация files происходит при объявлении.
Bash способен вывести тип переменной самостоятельно. Этот механизм работает, когда вы присваиваете значение переменной при объявлении. В зависимости от значения Bash добавляет соответствующий атрибут. В таком случае команду declare можно опустить. Например, наш массив files можно объявить без declare:
files=(Documents/*.txt)
Предположим, что элементы массива получаются не в результате подстановки, а известны заранее. В этом случае их можно задать явно при объявлении. Это будет выглядеть так:
files=("/usr/share/doc/bash/README" "/usr/share/doc/flex/README.md" "/usr/share/doc/\
xz/README")
Элементы массива можно читать из значений других переменных. Например:
1 bash_doc="/usr/share/doc/bash/README"
2 flex_doc="/usr/share/doc/flex/README.md"
3 xz_doc="/usr/share/doc/xz/README"
4 files=("$bash_doc" "$flex_doc" "$xz_doc")
Элементами массива files станут текущие значения переменных bash_doc, flex_doc и xz_doc. Изменение этих переменных после объявления массива, никак не отразится на его содержимом.
При объявлении массива для каждого его элемента можно явно указать индекс. Например:
1 bash_doc="/usr/share/doc/bash/README"
2 flex_doc="/usr/share/doc/flex/README.md"
3 xz_doc="/usr/share/doc/xz/README"
4 files=([0]="$bash_doc" [1]="$flex_doc" [5]="/usr/share/doc/xz/README")
Обратите внимание на отсутствие пробелов до и после каждого знака равно. Запомните простое правило: при объявлении переменных в Bash пробелы до и после знака равно не ставятся.
Вместо инициализации всего массива за раз, можно определять его элементы по отдельности. Например, так:
1 files[0]="$bash_doc"
2 files[1]="$flex_doc"
3 files[5]="/usr/share/doc/xz/README"
В последних двух объявлениях массива files нумерация индексов идёт не по порядку. Это не ошибка. Bash допускает массивы с пропусками (sparse arrays).
Вывести все элементы массива можно с помощью следующей подстановки:
1 $ echo "${files[@]}"
2 /usr/share/doc/bash/README /usr/share/doc/flex/README.md /usr/share/doc/xz/README
Иногда бывает полезно вывести только индексы элементов. Для этого в подстановке добавьте восклицательный знак перед именем массива. Например:
1 $ echo "${!files[@]}"
2 0 1 5
При подстановке индекс элемента можно рассчитать по формуле. Просто укажите в квадратных скобках арифметическое выражение для его вычисления. Например, так:
1 echo "${files[4+1]}"
2 files[4+1]="/usr/share/doc/xz/README"
В арифметическом выражении можно использовать переменные. Причём они могут быть объявлены и как целочисленные, и как строковые. Например:
1 i=4
2 echo "${files[i+1]}"
3 files[i+1]="/usr/share/doc/xz/README"
Следующие подряд элементы можно подставить одной командой. Для этого после двоеточия укажите стартовый индекс и число элементов. Например, так:
1 $ echo "${files[@]:1:2}"
2 /usr/share/doc/flex/README.md /usr/share/doc/xz/README
Эта команда выведет два элемента начиная с первого. Обратите внимание, что индексы элементов в этом случае не важны. Мы прочитали имена файлов под номерами 1 и 5.
Bash, начиная с версии 4, предоставляет встроенную команду readarray (также известную как mapfile). Она читает содержимое текстового файла в массив. Рассмотрим, как её использовать.
Предположим, что у нас есть файл с именем names.txt. Его содержимое такое:
1 Alice
2 Bob
3 Eve
4 Mallory
Создадим массив со строками из этого файла. Для этого достаточно выполнить следующую команду:
В результате содержимое файла будет записано в массив с именем names_array.
Мы научились объявлять и инициализировать индексируемые массивы. Теперь разберёмся, как их использовать. Предположим, что массив files содержит список имён файлов. Вам нужно скопировать первый файл в списке. Для этого воспользуемся утилитой cp:
"${files[0]}" ~/Documents
Для чтения элемента массива нужна полная форма подстановки параметров с фигурными скобками. После имени переменной в квадратных скобках указывается индекс нужного элемента. Для подстановки всех элементов используйте символ @ вместо индекса. Например, так:
"${files[@]}" ~/Documents
Чтобы получить размер массива, поставьте символ решётка # перед его именем. Например:
echo "${#files[@]}"
При подстановке элементов массива всегда используйте двойные кавычки, чтобы предотвратить word splitting.
Чтобы удалить элемент массива, используйте встроенную команду unset. Например, удаление четвёртого элемента (не забывайте про нумерацию с нуля) выглядит так:
unset 'files[3]'
Обратите внимание на обязательные одинарные кавычки. Они выключат все возможные подстановки интерпретатора.
С помощью команды unset можно также очистить весь массив:
unset files
Ассоциативные массивы
Мы рассмотрели индексируемые массивы. В них элементами являются строки, а индексами — целые положительные числа. Массивы этого типа по указанному индексу возвращают соответствующую ему строку.
В Bash версии 4 добавили ассоциативные массивы. В них индексы — это не числа, а строки. Такая строка-индекс называется ключом (key). Ассоциативный массив по указанной строке-индексу возвращает соответствующую ей строку-значение. Когда это может быть полезно? Рассмотрим пример.
Предположим, нам нужен скрипт для хранения контактов. Скрипт позволяет добавить в список имя человека, его email или номер телефона. Для простоты можно опустить фамилию и хранить только имя. По запросу скрипт выводит контактные данные человека.
Если для нашей задачи применить индексируемый массив, поиск контактов будет неэффективным. Придётся перебирать элементы массива друг за другом и сравнивать имя человека с искомым. Если нужное имя найдено, скрипт выведет на экран соответствующие контактные данные.
Ассоциативный массив сделает поиск по контактам быстрее и проще. В этом случае перебирать элементы массива не нужно. Достаточно указать ключ и получить соответствующий элемент массива. Рассмотрим это решение подробнее.
Объявление и инициализация ассоциативного массива с контактами выглядит так:
declare -A contacts=(["Alice"]="alice@gmail.com" ["Bob"]="(697) 955-5984" ["Eve"]="(\
245) 317-0117" ["Mallory"]="mallory@hotmail.com")
Ассоциативный массив всегда объявляется с командой declare и её опцией -A. Bash не сможет правильно вывести тип переменной, даже если указать в качестве индексов строки. Поэтому в результате следующего объявления вы получите индексируемый массив, а не ассоциативный:
contacts=(["Alice"]="alice@gmail.com" ["Bob"]="(697) 955-5984" ["Eve"]="(245) 317-01\
17" ["Mallory"]="mallory@hotmail.com")
Проверим, чему равна переменная contacts в этом случае:
1 $ declare -p contacts
2 declare -a contacts='([0]="mallory@hotmail.com")'
Мы получили индексируемый массив с одним элементом. Bash сконвертировал все строки-ключи в индекс ноль. Поэтому в нулевой элемент записался только контакт последнего человека в списке инициализации.
Элементы массива можно задавать по отдельности. Например, так:
1 declare -A contacts
2 contacts["Alice"]="alice@gmail.com"
3 contacts["Bob"]="(697) 955-5984"
4 contacts["Eve"]="(245) 317-0117"
5 contacts["Mallory"]="mallory@hotmail.com"
Итак, мы объявили ассоциативный массив. Его элементы доступны по ключам. В нашем случае ключ — это имя человека.
Чтобы прочитать элемент массива по его ключу, выполните такую подстановку:
1 $ echo "${contacts["Bob"]}"
2 (697) 955-5984
Для вывода всех элементов массива просто укажите в качестве ключа символ @:
1 $ echo "${contacts[@]}"
2 (697) 955-5984 mallory@hotmail.com alice@gmail.com (245) 317-0117
Чтобы вывести список всех ключей, поставьте восклицательный знак ! перед именем массива. Например:
1 $ echo "${!contacts[@]}"
2 Bob Mallory Alice Eve
Размер массива выводится с помощью символа решётка #. Например, так:
1 $ echo "${#contacts[@]}"
2 4
Поместим ассоциативный массив с контактами в скрипт. Тогда имя интересующего человека можно передать через параметр командной строки. В ответ скрипт выведет соответствующий email или телефон.
Листинг 3-10 демонстрирует скрипт с контактами.
1 #!/bin/bash
2
3 declare -A contacts=(
4 ["Alice"]="alice@gmail.com"
5 ["Bob"]="(697) 955-5984"
6 ["Eve"]="(245) 317-0117"
7 ["Mallory"]="mallory@hotmail.com")
8
9 echo "${contacts["$1"]}"
Для редактирования контактов измените инициализацию массива в скрипте.
Удалить ассоциативный массив или его элемент можно командой unset:
1 unset contacts
2 unset 'contacts[Bob]'
Подстановка нескольких элементов ассоциативного и индексируемого массивов работает аналогично. Например, так:
1 $ echo "${contacts[@]:0:2}"
2 mallory@hotmail.com (245) 317-0117
В этом случае Bash подставит первые два элемента массива. Проблема в том, что порядок следования элементов в памяти не соответствует порядку их инициализации. Индекс каждого элемента рассчитывается хеш-функцией. На вход она принимает строку-ключ, а на выходе возвращает уникальное целое число. Из-за этой особенности подстановка нескольких элементов ассоциативного массива мало полезна на практике.
Условные операторы
Работая с утилитой find, мы впервые познакомились с условными конструкциями. Затем мы выяснили, что у Bash есть собственные логические операторы И (&&) и ИЛИ (||). Это не единственные формы ветвления в языке Bash.
В этом разделе мы рассмотрим операторы if и case. Они часто используются в скриптах. Эти операторы взаимозаменяемы. Но каждый из них лучше справляется с определёнными задачами.
Оператор if
Представьте, что вы пишете однострочную команду. При этом вы стараетесь сделать её как можно компактнее. Короткая команда удобнее длинной. Её проще набрать и меньше вероятность ошибиться.
Теперь представьте, что вы пишете скрипт. Он хранится на жёстком диске. При этом вы вызываете его регулярно и иногда изменяете. Здесь компактность не так важна. В первую очередь скрипт должен быть удобен для чтения и редактирования.
Операторы && и || хорошо подходят для однострочных команд. Но для скриптов есть альтернативы получше. На самом деле всё зависит от конкретного случая. Иногда операторы && и || вписываются в код скрипта без проблем. Но зачастую они приводят к трудночитаемому коду. Поэтому лучше заменять их на операторы if или case. Рассмотрим эти случаи подробнее.
Ещё раз обратимся к скрипту для резервного копирования из листинга 3-9. Вызов утилиты bsdtar в этом скрипте выглядит так:
1 bsdtar -cjf "$1".tar.bz2 "$@" &&
2 echo "bsdtar - OK" > results.txt ||
3 { echo "bsdtar - FAILS" > results.txt ; exit 1 ; }
Чтобы улучшить читаемость скрипта, мы разбили вызовы утилит bsdtar и mv на отдельные команды. Это помогло, но лишь отчасти. Вызов bsdtar всё ещё слишком длинный. При его изменении легко допустить ошибку. Такой подверженный ошибкам код называется хрупким (fragile). Это верный признак плохого технического решения, принятого при его разработке.
Распишем алгоритм вызова bsdtar по шагам:
- Прочитать из переменной
$@список файлов и каталогов. Архивировать и сжать их. - Если архивирование и сжатие прошло успешно, записать в лог-файл строку “bsdtar - OK”.
- Если произошла ошибка, записать в лог-файл строку “bsdtar - FAILS” и завершить работу скрипта.
Вопросы вызывает третий пункт. При успешном завершении bsdtar выполняется только одно действие. В случае же ошибки — действий два и они объединены в блок команд с помощью фигурных скобок .
Конструкция if введена в язык Bash как раз для удобства работы с блоками команд. В общем случае она выглядит так:
1 if УСЛОВИЕ
2 then
3 ДЕЙСТВИЕ
4 fi
Эту конструкцию можно записать и в одну строку. Для этого перед then и fi добавьте по точке с запятой:
if УСЛОВИЕ; then ДЕЙСТВИЕ; fi
УСЛОВИЕ и ДЕЙСТВИЕ в операторе if представляют собой команду или блок команд. Если УСЛОВИЕ завершилось успешно с кодом возврата 0, будут выполнены команды, соответствующие ДЕЙСТВИЮ.
Рассмотрим следующий пример конструкции if:
1 if cmp file1.txt file2.txt &> /dev/null
2 then
3 echo "Файлы file1.txt и file2.txt идентичны"
4 fi
Здесь в качестве УСЛОВИЯ вызывается утилита cmp. Она побайтово сравнивает содержимое двух файлов. Если они отличаются, cmp напечатает в стандартный поток вывода позицию первого различающегося символа. При этом код возврата утилиты будет отличным от нуля. Если содержимое файлов совпадает — утилита вернёт ноль.
В конструкции if нас интересует только код возврата утилиты cmp. Поэтому мы перенаправляем её вывод в файл /dev/null. Это специальный системный файл. Запись в него всегда проходит успешно, а все записанные данные удаляются.
Итак, если содержимое файлов file1.txt и file2.txt совпадает, утилита cmp вернёт код ноль. Тогда условие конструкции if будет истинно. В этом случае команда echo выведет сообщение на экран.
Мы рассмотрели пример, когда действие совершается при выполнении условия. Но бывают случаи, когда с помощью условия выбирается одно из двух действий. Именно так работает конструкция if-else. В общем виде она выглядит так:
1 if УСЛОВИЕ
2 then
3 ДЕЙСТВИЕ_1
4 else
5 ДЕЙСТВИЕ_2
6 fi
Запись if-else в одну строку выглядит так:
if УСЛОВИЕ; then ДЕЙСТВИЕ_1; else ДЕЙСТВИЕ_2; fi
В этой конструкции блок команд ДЕЙСТВИЕ_2 выполнится, если УСЛОВИЕ вернёт код ошибки отличный от нуля. В противном случае выполнится блок ДЕЙСТВИЕ_1.
Конструкцию if-else можно дополнить условиями и действиями с помощью блоков elif. Рассмотрим пример. Предположим, в зависимости от значения переменной вы выбираете одно из трёх действий. Следующая конструкция if даст такое поведение:
1 if УСЛОВИЕ_1
2 then
3 ДЕЙСТВИЕ_1
4 elif УСЛОВИЕ_2
5 then
6 ДЕЙСТВИЕ_2
7 else
8 ДЕЙСТВИЕ_3
9 fi
Количество блоков elif неограниченно. Добавляйте их в конструкцию if-else столько, сколько вам нужно.
Дополним наш пример сравнения двух файлов. Будем выводить сообщение не только при их совпадении, но и при их различии. Для этого воспользуемся конструкцией if-else. Получится следующее:
1 if cmp file1.txt file2.txt &> /dev/null
2 then
3 echo "Файлы file1.txt и file2.txt идентичны"
4 else
5 echo "Файлы file1.txt и file2.txt различаются"
6 fi
Вернёмся к нашему скрипту резервного копирования. В нём в зависимости от результата утилиты bsdtar выполняется блок команд. Поэтому операторы && и || стоит заменить на конструкцию if.
Перепишем вызов и обработку результата bsdtar. Для этого применим конструкцию if-else. Получится следующее:
1 if bsdtar -cjf "$1".tar.bz2 "$@"
2 then
3 echo "bsdtar - OK" > results.txt
4 else
5 echo "bsdtar - FAILS" > results.txt
6 exit 1
7 fi
Согласитесь, что теперь читать и редактировать код стало проще. Его можно упростить ещё. Применим технику раннего возврата и заменим конструкцию if-else на if:
1 if ! bsdtar -cjf "$1".tar.bz2 "$@"
2 then
3 echo "bsdtar - FAILS" > results.txt
4 exit 1
5 fi
6
7 echo "bsdtar - OK" > results.txt
Поведение кода осталось таким же. С помощью логического отрицания ! мы инвертировали результат утилиты bsdtar. Теперь если она завершится с ошибкой, условие оператора if станет истинным. В этом случае выводится сообщение “bsdtar - FAILS” и вызывается команда exit. Если утилита bsdtar отработает корректно, блок команд конструкции if не выполнится. В результате в лог-файл напечатается строка “bsdtar - OK”.
Рассмотрим технику раннего возврата. Это полезный приём, который сделает ваш код проще и понятнее для чтения. Его идея в том, чтобы в случае ошибки завершить программу как можно раньше. Если этого не сделать, вам не избежать вложенных конструкций if.
Рассмотрим пример. Представьте, что некоторый алгоритм состоит из пяти действий. Каждое последующее действие выполняется только при успешном завершении предыдущего. Этот алгоритм можно реализовать с помощью вложенных конструкций if. Например, так:
1 if ДЕЙСТВИЕ_1
2 then
3 if ДЕЙСТВИЕ_2
4 then
5 if ДЕЙСТВИЕ_3
6 then
7 if ДЕЙСТВИЕ_4
8 then
9 ДЕЙСТВИЕ_5
10 fi
11 fi
12 fi
13 fi
Такое вложение выглядит запутанным. Добавьте в него блоки else с обработкой ошибок и читать код станет ещё сложнее.
Вложенные операторы if — это серьёзная проблема для читаемости кода. Она решается техникой раннего возврата. Применим её для нашего алгоритма. Получим следующее:
1 if ! ДЕЙСТВИЕ_1
2 then
3 # обработка ошибки
4 fi
5
6 if ! ДЕЙСТВИЕ_2
7 then
8 # обработка ошибки
9 fi
10
11 if ! ДЕЙСТВИЕ_3
12 then
13 # обработка ошибки
14 fi
15
16 if ! ДЕЙСТВИЕ_4
17 then
18 # обработка ошибки
19 fi
20
21 ДЕЙСТВИЕ_5
Поведение программы не изменилось. Алгоритм по-прежнему состоит из пяти действий. Ошибка при выполнении любого из них прерывает работу программы. Но благодаря раннему возврату, код стал проще и понятнее.
В последнем примере мы используем комментарии. Они выглядят так: “# обработка ошибки”. Комментарий — это строка или её часть, которую игнорирует интерпретатор. В Bash комментарием является всё, что идёт после символа решётка #.
Предположим, что каждому действию алгоритма соответствует одна короткая команда. Все ошибки обрабатываются командой exit без вывода в лог-файл. В этом случае конструкции if можно заменить на оператор ||. При этом код останется простым и понятным. Он будет выглядеть, например, так:
1 ДЕЙСТВИЕ_1 || exit 1
2 ДЕЙСТВИЕ_2 || exit 1
3 ДЕЙСТВИЕ_3 || exit 1
4 ДЕЙСТВИЕ_4 || exit 1
5 ДЕЙСТВИЕ_5
Операторы && и || выразительнее чем if только тогда, когда действия и обработка ошибок выполняются короткими командами.
Перепишем скрипт резервного копирования с использованием конструкции if. Листинг 3-11 демонстрирует результат.
1 #!/bin/bash
2
3 if ! bsdtar -cjf "$1".tar.bz2 "$@"
4 then
5 echo "bsdtar - FAILS" > results.txt
6 exit 1
7 fi
8
9 echo "bsdtar - OK" > results.txt
10
11 mv -f "$1".tar.bz2 /d && echo "cp - OK" >> results.txt || ! echo "cp - FAILS" >> res\
12 ults.txt
В скрипте мы заменили операторы && и || в вызове bsdtar на конструкцию if. Поведение скрипта при этом не изменилось.
В общем случае логические операторы и конструкция if не эквивалентны. Рассмотрим пример. Предположим, есть выражение из трёх команд A, B и C:
Может показаться, что следующая конструкция if-else даст такое же поведение:
if A
then
B
else
C
fi
В этой конструкции если A истинно, то выполняется B. Иначе выполняется C. Но в выражении с операторами && и || поведение иное! В нём если A истинно, выполняется B. Далее выполнение C зависит от результата B. Если B истинно, C выполняться не будет. Если же B ложно, C исполнится. Таким образом исполнение C зависит и от результата A, и от результата B. В конструкции if-else такой зависимости нет.
Оператор [[
Мы познакомились с оператором if. В качестве условия в нём вызывается встроенная команда Bash или сторонняя утилита.
Например, вызовем утилиту grep и в зависимости от её результата выберем действие. Если использовать grep в условии оператора if, нам пригодится опция утилиты -q. С ней grep не станет выводить результат на стандартный поток вывода. Вместо этого при первом вхождении искомой строки или шаблона вернётся код ноль. Условие if с вызовом grep может выглядеть так:
1 if grep -q -R "General Public License" /usr/share/doc/bash
2 then
3 echo "Bash распространяется под лицензией GPL"
4 fi
Теперь предположим, что в условии if сравниваются две строки или числа. Для этой цели в Bash есть специальный оператор [[. Двойные квадратные скобки являются зарезервированным словом интерпретатора. Это значит, что интерпретатор обрабатывает его самостоятельно.
Начнём с простого примера использования оператора [[. Надо сравнить две строки. В этом случае условие if выглядит так:
1 if [[ "abc" = "abc" ]]
2 then
3 echo "Строки равны"
4 fi
Выполните этот код. На экран будет выведено сообщение, что строки равны. Подобная проверка не слишком полезна. Чаще значение какой-то переменной сравнивается со строкой. В этом случае оператор [[ выглядит так:
1 if [[ "$var" = "abc" ]]
2 then
3 echo "Переменная равна строке \"abc\""
4 fi
В этом условии двойные кавычки необязательны. Globbing и word splitting не выполняются при подстановке переменной в операторе [[. То есть интерпретатор никак не обрабатывает значение переменной var, а использует его как есть. Проблема возникнет, только если пробелы встречаются не в значении переменной, а в строке справа. Например:
1 if [[ "$var" = abc def ]]
2 then
3 echo "Переменная равна строке \"abc def\""
4 fi
Выполнение такого условия завершится с ошибкой.
Чтобы избежать подобных проблем, всегда используйте кавычки при работе со строками. Последуем этому правилу и перепишем прошлый пример так:
1 if [[ "$var" = "abc def" ]]
2 then
3 echo "Переменная равна строке abc def"
4 fi
В операторе [[ можно сравнить значения двух переменных друг с другом. Например, так:
1 if [[ "$var" = "$filename" ]]
2 then
3 echo "Переменные равны"
4 fi
В таблице 3-8 приведены все операции сравнения строк, допустимые в операторе [[.
| Операция | Описание | Пример |
|---|---|---|
| > | Строка слева больше строки справа в порядке лексикографической сортировки. | [[ “bb” > “aa” ]] && echo “Строка bb больше чем aa” |
| < | Строка слева меньше строки справа в порядке лексикографической сортировки. | [[ “ab” < “ac” ]] && echo “Строка ab меньше чем ac” |
| = или == | Строки равны. | [[ “abc” = “abc” ]] && echo “Строки равны” |
| != | Строки не равны. | [[ “abc” != “ab” ]] && echo “Строки не равны” |
| -z | Строка пустая. | [[ -z “$var” ]] && echo “Строка пустая” |
| -n | Строка не пустая. | [[ -n “$var” ]] && echo “Строка не пустая” |
| -v | Переменная объявлена с любым значением. | [[ -v var ]] && echo “Переменная объявлена” |
| = или == | Поиск в строке слева подстроки по шаблону справа. В этом случае шаблон не заключается в кавычки. | [[ “$filename” = READ* ]] && echo “Имя файла начинается с READ” |
| != | Проверка, что шаблон справа не встречается в строке слева. В этом случае шаблон не заключается в кавычки. | [[ “$filename” != READ* ]] && echo “Имя файла не начинается с READ” |
| =~ | Поиск в строке слева подстроки по регулярному выражению справа. | [[ “$filename” =~ ^READ.* ]] && echo “Имя файла начинается с READ” |
В операторе [[ можно использовать логические операции И, ИЛИ и НЕ. Они комбинируют несколько выражений в одно условие. Таблица 3-9 приводит примеры таких условий.
| Операция | Описание | Пример |
|---|---|---|
| && | Логическое И. | [[ -n “$var” && “$var” < “abc” ]] && echo “Строка не пустая и меньше чем abc” |
| || | Логическое ИЛИ. | [[ “abc” < “$var” || -z “$var” ]] && echo “Строка больше чем abс или пустая” |
| ! | Логическое НЕ. | [[ ! “abc” < “$var” ]] && echo “Строка не больше чем abc” |
Выражения в операторе [[ можно группировать с помощью круглых скобок. Например, так:
[[ (-n "$var" && "$var" < "abc") || -z "$var" ]] && echo "Строка не пустая и меньше \
чем abc или строка пустая"
В операторе [[ можно сравнивать не только строки. У него есть операции для проверки файлов и каталогов на различные условия. Эти операции приведены в таблице 3-10.
| Операция | Описание | Пример |
|---|---|---|
| -e | Файл существует. | [[ -e “$filename” ]] && echo “Файл $filename существует” |
| -f | Указанный объект является обычным файлом. Это не каталог и не файл устройства). | [[ -f “~/README.txt” ]] && echo “README.txt - это обычный файл” |
| -d | Указанный объект является каталогом. | [[ -f “/usr/bin” ]] && echo “/usr/bin - это каталог” |
| -s | Файл не пустой. | [[ -s “$filename” ]] && echo “Файл $filename не пустой” |
| -r | Файл существует и доступен для чтения. | [[ -r “$filename” ]] && echo “Файл $filename существует и доступен для чтения” |
| -w | Файл существует и доступен для записи. | [[ -w “$filename” ]] && echo “Файл $filename существует и доступен для записи” |
| -x | Файл существует и доступен для исполнения. | [[ -x “$filename” ]] && echo “Файл $filename существует и доступен для исполнения” |
| -N | Файл существует и был модифицирован с момента последнего чтения. | [[ -N “$filename” ]] && echo “Файл $filename существует и был модифицирован” |
| -nt | Файл слева от оператора новее, чем файл справа. Либо файл слева существует, а справа - нет. | [[ “$file1” -nt “$file2” ]] && echo “Файл $file1 новее чем $file2” |
| -ot | Файл слева от оператора старее, чем файл справа. Либо файл справа существует, а слева — нет. | [[ “$file1” -ot “$file2” ]] && echo “Файл $file1 старее чем $file2” |
| -ef | Слева и справа от оператора указан путь или жёсткая ссылка до одного и того же файла. | [[ “$file1” -ef “$file2” ]] && echo “Файлы $file1 и $file2 совпадают” |
Кроме строк оператор [[ может сравнивать целые числа. Соответствующие операции приведены в таблице 3-11.
| Операция | Описание | Пример |
|---|---|---|
| -eq | Число слева равно числу справа. | [[ “$var” -eq 5 ]] && echo “Переменная равна 5” |
| -ne | Не равно. | [[ “$var” -ne 5 ]] && echo “Переменная не равна 5” |
| -gt | Больше (>). | [[ “$var” -gt 5 ]] && echo “Переменная больше 5” |
| -ge | Больше или равно. | [[ “$var” -ge 5 ]] && echo “Переменная больше или равна 5” |
| -lt | Меньше (<). | [[ “$var” -lt 5 ]] && echo “Переменная меньше 5” |
| -le | Меньше или равно. | [[ “$var” -le 5 ]] && echo “Переменная меньше или равна 5” |
Таблица 3-11 вызывает вопросы. Эти операции сложнее запомнить чем привычные знаки сравнения чисел (<, > и =). Почему в операторе [[ не используются знаки сравнения? Чтобы ответить на этот вопрос, обратимся к истории оператора [[.
Оператор [[ пришёл в Bash на замену устаревшего test. В первой версии Bourne shell 1979 года test был сторонней утилитой. Только начиная с версии System III shell 1981 года, он стал встроенной командой интерпретатора. Но это изменение не затронуло синтаксис test. Дело в том, что к этому времени было написано много кода на старом синтаксисе. Поэтому новая версия интерпретатора вынуждена была его поддерживать.
Рассмотрим синтаксис оператора test. Когда он был сторонней утилитой, формат его входных параметров подчинялся правилам Bourne shell. Например, вот типичный вызов test для сравнения значения переменной var и числа пять:
test "$var" -eq 5
Эта команда не вызывает вопросов. В утилиту test передаются три параметра: значение переменной var, опция -eq и число 5. Если этот вызов использовать как условие конструкции if, получим следующее:
1 if test "$var" -eq 5
2 then
3 echo "Переменная равна 5"
4 fi
В Bourne shell для оператора test добавили синоним [. Единственное отличие между ними — это наличие закрывающей скобки ]. Для test она не нужна. С помощью синонима перепишем условие конструкции if так:
1 if [ "$var" -eq 5 ]
2 then
3 echo "Переменная равна 5"
4 fi
Синоним [ добавили для лучшей читаемости кода. Благодаря ему, конструкция if в Bourne shell стала больше походить на if в других языках программирования (например, C). Проблема в том, что операторы [ и test эквивалентны. Этот факт легко упустить из виду, особенно имея опыт программирования на других языках. Такое несоответствие ожидаемого и реального поведения приводит к ошибкам.
Например, программисты часто забывают пробел между скобкой [ и следующим далее символом. То есть получается подобное условие:
1 if ["$var" -eq 5]
2 then
3 echo "Переменная равна 5"
4 fi
Просто замените в условии скобку [ на test и ошибки станет очевидна:
1 if test"$var" -eq 5
2 then
3 echo "Переменная равна 5"
4 fi
Между именем команды и её параметрами всегда должен стоять пробел.
Вернёмся к нашему вопросу о знаках сравнения для чисел. Представьте себе следующий вызов test:
test "$var" > 5
Как вы помните, символ > является сокращением для перенаправления стандартного потока вывода 1>. Поэтому наш вызов test выполнит следующее:
- Вызовет встроенную команду test и передаст ей на вход переменную
var. - Перенаправит вывод test в файл с именем
5в текущем каталоге.
Мы ожидаем совсем другое поведение. Подобную ошибку легко допустить и сложно обнаружить. Чтобы её избежать и были введены двухбуквенные операции для сравнения чисел. Эти операции перекочевали в новый Bash-оператор [[. По идее, ничто не мешало заменить их на знаки сравнения. Но такое решение усложнило бы портирование старого кода с Bourne shell на Bash. Рассмотрим пример.
Представьте, что в вашем старом коде есть следующая конструкция if:
1 if [ "$var1" -gt 5 -o 4 -lt "$var2" ]
2 then
3 echo "Переменная var1 больше 5 или var2 больше 4"
4 fi
Намного безопаснее поставить по дополнительной скобке в начале и в конце выражения, чем менять -gt на >, а -lt на <. При таких заменах легко допустить ошибку.
В операторе [[ знаки сравнения можно использовать только для строк. Почему? Для сравнения строк не было задачи обеспечить обратную совместимость. Первая версия утилиты test вообще не поддерживала лексикографического сравнения строк. То есть знаков сравнения < и > не было. Они появились только в расширении POSIX-стандарта и только для строк. Для чисел добавлять их было уже поздно. Стандарт говорит, что знаки сравнения должны быть экранированы /< и />. Из стандарта они попали в оператор [[, но уже без экранирования.
Оператор case
В программах выполняемые действия часто зависят от каких-то значений. Если значение одно, выбирается первое действие. Если значение другое, то — второе действие. Именно так работают условные операторы. Мы уже познакомились с конструкцией if. Кроме неё в Bash есть конструкция case. В некоторых случаях она удобнее чем if.
Рассмотрим пример. Предположим, что вы пишете скрипт для архивации документов. У скрипта есть три режима работы: архивация со сжатием, архивация без сжатия и разархивация. Нужное действие выбирается с помощью опции скрипта. Один из вариантов опций предлагает таблица 3-12.
| Опция | Режим работы |
|---|---|
-a |
Архивация без сжатия |
-c |
Архивация со сжатием |
-x |
Разархивация |
Проверить опцию скрипта можно в конструкции if. Например, как в листинге 3-12.
1 #!/bin/bash
2
3 operation="$1"
4
5 if [[ "$operation" == "-a" ]]
6 then
7 bsdtar -c -f documents.tar ~/Documents
8 elif [[ "$operation" == "-c" ]]
9 then
10 bsdtar -c -j -f documents.tar.bz2 ~/Documents
11 elif [[ "$operation" == "-x" ]]
12 then
13 bsdtar -x -f documents.tar*
14 else
15 echo "Указана недопустимая опция"
16 exit 1
17 fi
Опция скрипта передаётся в позиционном параметре $1. Он сохраняется в переменной operation для удобства. Дальше в зависимости от её значения вызывается утилита bsdtar с теми или иными параметрами. Значение переменной operation проверяется в конструкции if. Попробуем заменить её на конструкцию case. Листинг 3-13 демонстрирует результат.
1 #!/bin/bash
2
3 operation="$1"
4
5 case "$operation" in
6 "-a")
7 bsdtar -c -f documents.tar ~/Documents
8 ;;
9
10 "-c")
11 bsdtar -c -j -f documents.tar.bz2 ~/Documents
12 ;;
13
14 "-x")
15 bsdtar -x -f documents.tar*
16 ;;
17
18 *)
19 echo "Указана недопустимая опция"
20 exit 1
21 ;;
22 esac
Назовём наш скрипт archiving-case.sh. Тогда его можно запустить одним из следующих способов:
1 ./archiving-case.sh -a
2 ./archiving-case.sh -c
3 ./archiving-case.sh -x
Если передать в скрипт любые другие параметры, он завершится с ошибкой. Скрипт выведет сообщение: “Указана недопустимая опция”.
В общем случае конструкция case сравнивает переданную в неё строку со списком шаблонов. В зависимости от совпадения с шаблоном выполняется один из блоков case.
Каждый блок case состоит из следующих элементов:
- Шаблон или список шаблонов, разделённых символом |.
- Правая круглая скобка ).
- Набор команд, которые выполняются при совпадении шаблона и переданной в case строки.
- Два знака точка с запятой ;;. Они означают окончание набора команд.
Проверка шаблонов происходит последовательно. Сначала проверяется первый, потом — второй и так далее. Если строка совпала с первым шаблоном, будет выполнен соответствующий ему блок. После этого остальные шаблоны и их блоки игнорируются. Bash продолжит исполнение скрипта с команды, следующей за конструкцией case.
Шаблон * без кавычек соответствует любой строке. Обычно он идёт в конце списка. В его блоке обрабатываются случаи, когда ни один из шаблонов не подошёл. Как правило, это означает ошибку.
На первый взгляд может показаться, что конструкции if и case эквивалентны. Это не так. Они лишь позволяют добиться одинакового поведения.
Для удобства запишем конструкции if и case из нашего примера в общем виде. Вариант с if выглядит так:
1 if УСЛОВИЕ_1
2 then
3 ДЕЙСТВИЕ_1
4 elif УСЛОВИЕ_2
5 then
6 ДЕЙСТВИЕ_2
7 elif УСЛОВИЕ_3
8 then
9 ДЕЙСТВИЕ_3
10 else
11 ДЕЙСТВИЕ_4
12 fi
Вариант с case выглядит так:
1 case СТРОКА in
2 ШАБЛОН_1)
3 ДЕЙСТВИЕ_1
4 ;;
5
6 ШАБЛОН_2)
7 ДЕЙСТВИЕ_2
8 ;;
9
10 ШАБЛОН_3)
11 ДЕЙСТВИЕ_3
12 ;;
13
14 ШАБЛОН_4)
15 ДЕЙСТВИЕ_4
16 ;;
17 esac
Теперь различия между конструкциями стали очевиднее. Прежде всего, if проверяет результаты логических выражений. Конструкция case проверяет совпадение строки с шаблонами. Это значит, что нет смысла передавать в case логическое выражение. Так вы обработаете только два случая: когда выражение истинно и когда — ложно. Конструкция if намного удобнее для подобной проверки.
Второе различие if и case заключается в количестве условий. В if каждая ветвь конструкции (if, elif и else) проверяет новое логическое выражение. В общем случае эти выражения никак не связаны. В нашем примере они проверяют значения одной и той же переменной, но это частный случай. Конструкция case работает с одной-единственной переданной в неё строкой.
Операторы if и case принципиально отличаются. Они не взаимозаменяемы. В каждом конкретном случае используйте конструкцию в зависимости от характера проверки. Следующие вопросы помогут вам сделать правильный выбор:
- Сколько условий надо проверить?
- Требуются ли составные логические выражения или достаточно сравнения одной строки?
Блоки case можно отделять друг от друга двумя знаками точка с запятой ;; или точкой с запятой и амперсандом ;&. Синтаксис с амперсандом допустим в Bash, но не является частью POSIX-стандарта. Он означает выполнение следующего блока case без проверки его шаблона. Это может быть полезно, если требуется начать выполнение алгоритма с определённого шага в зависимости от какого-то условия. Также синтаксис с амперсандом позволяет избежать дублирования кода.
Рассмотрим пример проблемы дублирования кода. Напишем скрипт, который архивирует PDF документы и копирует результат в специальный каталог. Для выбора действия в скрипт передаётся опция. Например, -a для архивации и -c для копирования. Допустим, что после архивации всегда надо выполнять копирование. В этом случае возникнет дублирование кода.
Листинг 3-14 демонстрирует конструкцию case, в которой команда копирования архива дублируется.
1 #!/bin/bash
2
3 operation="$1"
4
5 case "$operation" in
6 "-a")
7 find Documents -name "*.pdf" -type f -print0 | xargs -0 bsdtar -c -j -f document\
8 s.tar.bz2
9 cp documents.tar.bz2 ~/backup
10 ;;
11
12 "-c")
13 cp documents.tar.bz2 ~/backup
14 ;;
15
16 *)
17 echo "Указана недопустимая опция"
18 exit 1
19 ;;
20 esac
Дублирование кода можно избежать, если поставить разделитель ;& между блоками обработки -a и -c. Исправленный скрипт приведён в листинге 3-15.
1 #!/bin/bash
2
3 operation="$1"
4
5 case "$operation" in
6 "-a")
7 find Documents -name "*.pdf" -type f -print0 | xargs -0 bsdtar -c -j -f document\
8 s.tar.bz2
9 ;&
10
11 "-c")
12 cp documents.tar.bz2 ~/backup
13 ;;
14
15 *)
16 echo "Указана недопустимая опция"
17 exit 1
18 ;;
19 esac
Разделитель ;& может быть полезным. Но используйте его только в случае крайней необходимости. Проблема в том, что визуально его легко спутать с разделителем ;; и неправильно прочитать и понять код.
Альтернатива оператору case
Конструкция case и ассоциативный массив решают сходные задачи. Массив даёт соотношение между данными (ключ-значение). Конструкция case — между данными и командами (значение-действие).
Обычно работать с данными удобнее, чем с кодом. Их проще изменять и проверять на корректность. Поэтому в некоторых случаях конструкцию case стоит заменить на ассоциативный массив. По сравнению с другими языками программирования в Bash легко конвертировать данные в команды.
Рассмотрим пример. Напишем скрипт-обёртку для утилит архивации. В зависимости от переданной в скрипт опции вызывается либо программа bsdtar, либо tar. Листинг 3-16 демонстрирует такой скрипт. В нём опция обрабатывается с помощью конструкции case.
1 #!/bin/bash
2
3 utility="$1"
4
5 case "$utility" in
6 "-b"|"--bsdtar")
7 bsdtar "${@:2}"
8 ;;
9
10 "-t"|"--tar")
11 tar "${@:2}"
12 ;;
13
14 *)
15 echo "Указана недопустимая опция"
16 exit 1
17 ;;
18 esac
Здесь для первых двух блоков case мы используем список шаблонов. Команда первого блока выполняется при совпадении переменной utility со строкой -b или --bsdtar. Аналогично второй блок выполнится при совпадении переменной с -t или --tar.
Вот пример запуска скрипта:
В этом случае скрипт вызовет утилиту tar для архивации каталога Documents. Чтобы вызвать bsdtar, замените опцию --tar на -b или на --bsdtar. Например:
Первый параметр скрипт обрабатывает самостоятельно. Все последующие параметры передаются в утилиту архивации без изменений. Для такой передачи мы используем параметр $@. Это не массив. Но он поддерживает синтаксис для подстановки следующих подряд элементов массива. В скрипте мы подставляем в вызов утилиты архивации все элементы $@ начиная со второго.
Перепишем скрипт-обёртку с помощью ассоциативного массива.
Прежде всего разберёмся в механизмах Bash для конвертации данных в команды. Команду и её параметры надо сохранить в качестве значения какой-то переменной. Чтобы вызвать эту команду, Bash должен подставить переменную в каком-то месте скрипта. При этом важно, чтобы Bash после подстановки правильно выполнил получившуюся команду.
Мы рассмотрели алгоритм для конвертирования данных в команду. Выполним его по шагам в командном интерпретаторе Bash. Сначала объявим переменную. Для примера её значение соответствует вызову утилиты ls:
ls_command="ls"
Теперь подставим значение этой переменной. Bash выполнит его как команду:
$ls_command
В результате выполнится команда ls. Она выведет на экран содержимое текущего каталога. Что произошло? Bash подставил значение переменной ls_command. После этого команда стала выглядеть так:
После подстановки Bash просто исполнил получившуюся команду.
Почему мы не используем двойные кавычки “ при подстановке переменной ls_command? Чтобы ответить на этот вопрос, сделаем небольшое изменение. Добавим опцию в вызов утилиты ls. Например, объявим переменную ls_command так:
ls_command="ls -l"
В этом случае подстановка с двойными кавычками приведёт к ошибке:
1 $ "$ls_command"
2 ls -l: command not found
Проблема в том, что двойные кавычки предотвращают word splitting. Из-за этого после подстановки получится такая команда:
"ls -l"
Другими словами Bash должен выполнить команду или утилиту с именем “ls -l”, вызванную без параметров. Как вы помните, POSIX-стандарт допускает пробелы в именах файлов. Поэтому “ls -l” является корректным именем исполняемого файла. Мы столкнулись с одним из редких случаев, когда при подстановке переменной двойные кавычки не нужны.
Если двойные кавычки при подстановке всё-таки нужны, эту проблему можно решить. Используйте встроенную команду интерпретатора eval. Она принимает на вход параметры и формирует из них команду для исполнения. При этом для полученной команды выполняется word splitting независимо от двойных кавычек.
Выполним значение переменной ls_command с помощью eval:
eval "$ls_command"
Перепишем наш скрипт-обёртку с использованием ассоциативного массива. Листинг 3-17 демонстрирует результат.
1 #!/bin/bash
2
3 option="$1"
4
5 declare -A utils=(
6 ["-b"]="bsdtar"
7 ["--bsdtar"]="bsdtar"
8 ["-t"]="tar"
9 ["--tar"]="tar")
10
11 if [[ -z "$option" || ! -v utils["$option"] ]]
12 then
13 echo "Указана недопустимая опция"
14 exit 1
15 fi
16
17 ${utils["$option"]} "${@:2}"
Здесь массив utils хранит допустимые опции скрипта и соответствующие им команды вызова утилит. С помощью массива можно по опции легко найти команду.
Рассмотрим команду вызова утилиты:
${utils["$option"]} "${@:2}"
В ней Bash подставляет вызов утилиты из массива utils. В качестве ключа элемента выступает опция скрипта option. Если указанного ключа нет, произойдёт ошибка. Вместо элемента массива Bash подставит пустую строку. Чтобы это избежать, мы проверяем переданную в скрипт опцию в конструкции if.
В конструкции if вычисляются два логических выражения:
- Переменная
optionсо значением параметра$1не пустая. - В массиве
utilsесть элемент, соответствующий значениюoption.
Во втором выражении используется опция -v оператора [[. Она проверяет, была ли переменная объявлена. Если при объявлении переменной присвоили пустую строку, проверка всё равно пройдёт.
Наш скрипт-обёртка показал, что массив в некоторых случаях даёт более компактный и удобный для чтения код. Всегда рассматривайте возможность заменить конструкцию case на массив в своих программах.
Арифметические выражения
Интерпретатор Bash может выполнять математические операции над целыми числами. К таким операциям относятся простые арифметические действия: сложение, вычитание, умножение и деление. Кроме них есть битовые и логические операции. Они часто применяются в программировании. Поэтому в этом разделе мы рассмотрим их подробнее.
Представление целых чисел
Рассмотрим способы представления целых чисел в памяти компьютера. Это поможет лучше понять, как работают математические операции в Bash.
Целые числа могут быть положительными и отрицательными. Соответствующий им тип данных называется целое (integer).
Если переменная целого типа принимает только положительные значения, она называется беззнаковой (unsigned). Если допустимы как положительные, так и отрицательные значения — это переменная со знаком (signed).
Наиболее распространены три способа представления целых в памяти компьютера:
- Прямой код (signed magnitude representation или SMR).
- Обратный код (ones’ complement).
- Дополнительный код (two’s complement).
Прямой код
Все числа в памяти компьютера представляются в двоичном виде. То есть любое число — это последовательность нулей и единиц. Что означают эти нули и единицы, зависит от способа представления числа.
Начнём с самого простого представления чисел — прямого кода. Его можно использовать двумя способами:
- Для записи только положительных целых (беззнаковых).
- Для записи как положительных, так и отрицательных целых (со знаком).
Под любое число отводится фиксированный блок памяти. В первом варианте прямого кода все биты этой памяти используются одинаково. В них хранится значение числа. Таблица 3-13 приводит примеры такого способа хранения.
| Десятичное число | Шестнадцатеричный формат | Прямой код |
|---|---|---|
| 0 | 0 | 0000 0000 |
| 5 | 5 | 0000 0101 |
| 60 | 3C | 0011 1100 |
| 110 | 6E | 0110 1110 |
| 255 | FF | 1111 1111 |
Предположим, что на число выделен один байт памяти. Тогда в прямом коде можно сохранить целые беззнаковые числа от 0 до 255.
Прямой код можно использовать вторым способом. Он позволяет хранить целые числа со знаком. Для этого старший бит числа резервируется для знака. Поэтому на значение числа остаётся меньше битов. Например, отведём для хранения числа один байт памяти. Один бит уйдёт на знак. Останется только семь битов на значение числа.
Таблица 3-14 демонстрирует представление целых со знаком в прямом коде.
| Десятичное число | Шестнадцатеричный формат | Прямой код |
|---|---|---|
| -127 | FF | 1111 1111 |
| -110 | EE | 1110 1110 |
| -60 | BC | 1011 1100 |
| -5 | 85 | 1000 0101 |
| -0 | 80 | 1000 0000 |
| 0 | 0 | 0000 0000 |
| 5 | 5 | 0000 0101 |
| 60 | 3C | 0011 1100 |
| 110 | 6E | 0110 1110 |
| 127 | 7F | 0111 1111 |
Обратите внимание, что старший (первый) бит всех отрицательных чисел равен единице, а положительных — нулю. Из-за знака теперь нельзя сохранить числа больше 127 в одном байте. По этой же причине минимальное отрицательное число равно -127.
Прямой код не получил широкого распространения в компьютерной технике по двум причинам:
- Арифметические операции над отрицательными числами требуют усложнения архитектуры процессора. Модуль процессора для суммирования положительных чисел не подходит для отрицательных.
- Существует два представления нуля: положительное (0000 0000) и отрицательное (1000 0000). Это осложняет операцию сравнения, так как в памяти эти значения не равны.
Постарайтесь разобраться в принципе работы прямого кода. Без этого вы не поймёте другие два способа представления целых.
Обратный код
У прямого кода есть два недостатка. Они привели к техническим проблемам при использовании кода в компьютерах. Это заставило инженеров искать альтернативное представление чисел в памяти. Так появился обратный код.
Первая проблема прямого кода связана с операциями над отрицательными числами. Прямой код решает именно её. Разберёмся, почему вообще возникла эта сложность.
Для примера сложим числа 10 и -5. Представим их в прямом коде. Предположим, что на каждое число отводится один байт в памяти компьютера. Тогда получим следующий результат:
10 = 0000 1010
-5 = 1000 0101
Теперь возникает вопрос — как процессору сложить эти числа? У любого современного процессора есть стандартный модуль под названием сумматор. Он побитово складывает два числа. Если применить его для нашей задачи, получим следующее:
10 + (-5) = 0000 1010 + 1000 0101 = 1000 1111 = -15
Результат неверный. Это означает, что сумматор не подходит для сложения целых в прямом коде. Проблема в том, что при сложении не учитывается старший бит числа.
Проблема решается двумя способами:
- Добавить в процессор специальный модуль для операций над отрицательными числами.
- Изменить способ представления отрицательных целых так, чтобы сумматор смог их складывать.
Развитие компьютерной техники пошло по второму пути. Он дешевле, чем усложнение процессора.
Принцип работы обратного кода очень похож на прямой код. Старший бит отводится под знак. Остальные биты хранят значение числа. Отличие в том, что для отрицательных чисел все биты значения инвертируются. То есть нули становятся единицами, а единицы — нулями. Биты значения положительных чисел не инвертируются.
Таблица 3-15 демонстрирует представление чисел в обратном коде.
| Десятичное число | Шестнадцатеричный формат | Обратный код |
|---|---|---|
| -127 | 80 | 1000 0000 |
| -110 | 91 | 1001 0001 |
| -60 | C3 | 1100 0011 |
| -5 | FA | 1111 1010 |
| -0 | FF | 1111 1111 |
| 0 | 0 | 0000 0000 |
| 5 | 5 | 0000 0101 |
| 60 | 3C | 0011 1100 |
| 110 | 6E | 0110 1110 |
| 127 | 7F | 0111 1111 |
Вместимость памяти при использовании прямого и обратного кодов одинакова. В одном байте по-прежнему можно сохранить числа от -127 до 127.
Что дало инвертирование битов значения для отрицательных чисел? Проверим, как теперь будет работать сложение чисел. Представим 10 и -5 в обратном коде. Затем сложим их с помощью сумматора.
Числа в обратном коде выглядят так:
10 = 0000 1010
-5 = 1111 1010
Сложение даст следующее:
10 + (-5) = 0000 1010 + 1111 1010 = 1 0000 0100
Обратите внимание, что в результате сложения произошло переполнение. Старшая единица не поместилась в один байт, отведённый под число. В этом случае она отбрасывается. Тогда результат сложения станет таким:
0000 0100
Отброшенная единица влияет на конечный результат. Нужен второй этап вычисления, чтобы её учесть. На этом этапе просто добавим единицу к результату:
0000 0100 + 0000 0001 = 0000 0101 = 5
Мы получили правильный результат сложения чисел 10 и -5.
Если в результате сложения получилось отрицательное число, второй этап вычисления не нужен. Для примера сложим числа -7 и 2. Сначала представим их в обратном коде:
Выполним первый этап сложения:
Старший бит равен единице. Это значит, что мы получили отрицательное число. В этом случае второй этап сложения не нужен.
Проверим корректность результата. Для удобства переведём число из обратного кода в прямой. Чтобы это сделать, инвертируем все биты значения числа. Знаковый бит оставляем без изменений. В результате получим следующее:
1111 1010 -> 1000 0101 = -5
Мы снова получили верный результат.
Обратный код решил одну проблему. Если представить числа в нём, стандартный сумматор сможет их сложить независимо от знака. Недостаток такого решения в том, что сложение происходит в два этапа. Это замедляет работу компьютера.
У прямого кода есть вторая проблема: представление нуля двумя способами. Её обратный код решить не смог.
Дополнительный код
Дополнительный код решает обе проблемы прямого кода. Во-первых, он позволяет стандартному сумматору складывать отрицательные числа. В обратном коде это действие выполняется в два этапа. В дополнительном коде достаточно одного. Во-вторых, ноль представляется одним единственным способом.
Положительные числа в дополнительном коде выглядят так же, как и в прямом. Старший знаковый бит равен нулю. Остальные биты хранят значение числа. У отрицательных чисел старший бит равен единице. Биты значения инвертируются, как в обратном коде. Затем к результату прибавляется единица.
Представление чисел в дополнительном коде приведено в таблице 3-16.
| Десятичное число | Шестнадцатеричный формат | Дополнительный код |
|---|---|---|
| -128 | 80 | 1000 0000 |
| -127 | 81 | 1000 0001 |
| -110 | 92 | 1001 0010 |
| -60 | C4 | 1100 0100 |
| -5 | FB | 1111 1011 |
| 0 | 0 | 0000 0000 |
| 5 | 5 | 0000 0101 |
| 60 | 3C | 0011 1100 |
| 110 | 6E | 0110 1110 |
| 127 | 7F | 0111 1111 |
Вместимость памяти при использовании дополнительного кода увеличивается на единицу. Причина в том, что ноль представляется в единственной форме 0000 0000. Понятия “отрицательного нуля” в дополнительном коде нет. Поэтому в одном байте можно сохранить числа от -128 до 127.
Рассмотрим сложение отрицательных чисел в обратном коде. Для примера сложим 14 и -8. Сначала представим каждое число в дополнительном коде. Получим:
14 = 0000 1110
-8 = 1111 1000
Теперь выполним сложение:
14 + (-8) = 0000 1110 + 1111 1000 = 1 0000 0110
В результате сложения произошло переполнение. Старшая единица не поместилась в один байт. Её надо отбросить. Тогда конечный результат будет таким:
0000 0110 = 6
Если результат сложения отрицательный, то отбрасывать старший бит не нужно. Для примера сложим числа -25 и 10. В дополнительном коде они выглядят так:
Сложение чисел даст:
Переведём результат из дополнительного кода в обратный, а потом в прямой. Для этого выполним следующие преобразования:
1111 0001 - 1 = 1111 0000 -> 1000 1111 = -15
При переводе из обратного кода в прямой мы инвертируем все разряды кроме старшего со знаком. В итоге мы получим правильный результат сложения чисел -25 и 10.
Дополнительный код позволил стандартному сумматору складывать отрицательные числа. Результат сложения вычисляется за один этап. Поэтому в отличие от обратного кода нет потери производительности.
Дополнительный код решил проблему представления нуля. Все биты этого числа — нули. Других вариантов нет. Поэтому сравнивать числа стало проще.
Во всех современных компьютерах целые представляются в дополнительном коде.
Конвертирование чисел
Мы узнали, как числа представляются в памяти компьютера. Когда это может пригодиться вам на практике?
Современные языки программирования берут на себя конвертирование чисел в правильный формат. Например, вы объявляете целую знаковую переменную в десятичной системе счисления. Вам не надо заботиться о том, в каком виде она хранится в памяти компьютера. Компьютер автоматически переводит все числа в дополнительный код.
В некоторых случаях с переменной надо работать как с набором битов. Тогда объявите её положительным целым. Все операции над ней выполняйте в шестнадцатеричной системе счисления. Главное — не переводите её в десятичную систему. Так вы обойдёте задачу конвертирования чисел.
Проблема возникает, когда необходимо интерпретировать данные с устройства. Такая задача часто возникает в системном программировании. К нему относится разработка драйверов устройств, ядер и модулей ОС, системных библиотек и стеков сетевых протоколов.
Рассмотрим пример. Предположим, что вы пишете драйвер для периферийного устройства. Устройство периодически отправляет на CPU данные (например, результаты измерений). Возникает задача интерпретировать их правильно. Представление чисел на устройстве и компьютере может отличаться (например, порядком байтов). В этом случае вам понадобятся знания о представлении чисел в памяти.
Ещё одна задача, с которой сталкивается каждый программист, — это отладка. Отладкой программы называется поиск и устранение в ней ошибок. Для примера в арифметическом выражении происходит переполнение. Зная как числа представляются в памяти, вам будет легче обнаружить проблему.
Оператор ((
Bash выполняет целочисленную арифметику в математическом контексте (math context).
Предположим, что результат сложения двух чисел надо сохранить в переменной. Объявим её с целочисленным атрибутом -i. Затем сразу присвоим ей значение. Например, так:
declare -i var=12+7
В результате переменная будет равна числу 19, а не строке “12+7”. Если объявить переменную с атрибутом -i, присваиваемое ей значение всегда будет вычисляться в математическом контексте. Это и произошло в нашем примере.
Математический контекст можно объявить явно. Это делает встроенная Bash-команда let.
Предположим, что переменная объявлена без атрибута -i. Тогда команда let позволит присвоить ей значение арифметического выражения. Например, так:
let text=5*7
В результате переменная text будет равна 35.
Если переменная объявлялась с атрибутом -i, команда let не нужна. Например:
declare -i var
var=5*7
Значением переменной var будет 35.
Объявление переменной с атрибутом -i неявно создаёт математический контекст. Это может стать источником ошибок. Поэтому старайтесь не использовать атрибут -i. Независимо от него, значение переменной хранится в памяти в виде строки. Конвертирование строки в число и обратно происходит каждый раз при присвоении.
Команда let позволяет работать со строковой переменной как с целочисленной. Например, так:
1 let var=12+7
2 let var="12 + 7"
3 let "var = 12 + 7"
4 let 'var = 12 + 7'
Результат всех четырёх команд одинаков. Переменной var будет присвоено значение 19.
Команда let принимает на вход параметры. Каждый из них должен быть корректным арифметическим выражением. Если в выражении встречаются пробелы, оно будет разделено на части из-за word splitting. В этом случае let вычислит каждую часть выражения по отдельности. Это может привести к ошибке.
Для примера рассмотрим такую команду:
let var=12 + 7
Здесь в результате word splitting команда let получит на вход три выражения: “var=12”, “+” и “7”. Вычисление второго из них “+” приведёт к ошибке. Плюс означает арифметическую операцию сложения. Она требует двух операндов. Но в нашем случае операндов нет.
Предположим, что все переданные в команду let выражения корректны. Тогда они вычисляются друг за другом. Например:
1 let a=1+1 b=5+1
2 let "a = 1 + 1" "b = 5 + 1"
3 let 'a = 1 + 1' 'b = 5 + 1'
В результате всех трёх команд переменной a будет присвоено значение 2, а переменной b — 6.
Чтобы предотвратить word splitting в параметрах команды let, заключайте их в одинарные или двойные кавычки.
У команды let есть синоним — оператор ((. В нём word splitting не выполняется. Поэтому выражения в операторе не требуют кавычек. Всегда используйте оператор (( вместо let. Это поможет избежать ошибки.
Оператор (( имеет две формы. Первая форма называется арифметической оценкой (arithmetic evaluation). Это синоним команды let. Арифметическая оценка выглядит так:
((var = 12 + 7))
Здесь вместо команды let ставятся открывающие скобки ((. В конце добавляются закрывающие скобки )). Эта форма оператора (( возвращает код ноль при успешном выполнении и единицу в случае ошибки. Вычислив выражение, Bash подставит вместо него код возврата.
Вторая форма оператора (( называется арифметической подстановкой (arithmetic expansion). Она выглядит так:
var=$((12 + 7))
Здесь перед оператором (( ставится знак доллара $. В этом случае Bash вычислит значение выражения. Затем он подставит это значение вместо выражения. Это отличается от поведения первой формы оператора ((, при которой подставляется код возврата.
В операторе (( имена переменных можно указывать без знака доллар $. Bash всё равно правильно подставит их значения. Например, следующие два выражения для вычисления result эквивалентны:
1 a=5 b=10
2 result=$(($a + $b))
3 result=$((a + b))
В обоих случаях переменная result станет равна 15.
Не используйте знак доллара в операторе ((. Это сделает ваш код чище и понятнее.
Таблица 3-17 демонстрирует операции, допустимые в арифметических выражениях.
| Операция | Описание | Пример |
|---|---|---|
| Вычисления | ||
* |
Умножение | echo "$((2 * 9)) = 18" |
/ |
Деление | echo "$((25 / 5)) = 5" |
% |
Остаток от деления | echo "$((8 % 3)) = 2" |
+ |
Сложение | echo "$((7 + 3)) = 10" |
- |
Вычитание | echo "$((8 - 5)) = 3" |
** |
Возведение в степень | echo "$((4**3)) = 64" |
| Битовые операции | ||
~ |
Побитовое НЕ (NOT) | echo "$((~5)) = -6" |
<< |
Битовый сдвиг влево | echo "$((5 << 1)) = 10" |
>> |
Битовый сдвиг вправо | echo "$((5 >> 1)) = 2" |
& |
Побитовое И (AND) | echo "$((5 & 4)) = 4" |
| |
Побитовое ИЛИ (OR) | echo "$((5 | 2)) = 7" |
^ |
Побитовое исключающее ИЛИ (XOR) | echo "$((5 ^ 4)) = 1" |
| Присваивания | ||
= |
Обычное присваивание | echo "$((num = 5)) = 5" |
*= |
Умножение и присваивание результата | echo "$((num *= 2)) = 10" |
/= |
Деление и присваивание результата | echo "$((num /= 2)) = 5" |
%= |
Остаток от деления и присваивание результата | echo "$((num %= 2)) = 1" |
+= |
Сложение и присваивание результата | echo "$((num += 7)) = 8" |
-= |
Вычитание и присваивание результата | echo "$((num -= 3)) = 5" |
<<= |
Битовый сдвиг влево и присваивание результата | echo "$((num <<= 1)) = 10 |
>>= |
Битовый сдвиг вправо и присваивание результата | echo "$((num >>= 2)) = 2" |
&= |
Побитовое И (AND), затем присваивание результата | echo "$((num &= 3)) = 2" |
^= |
Побитовое исключающее ИЛИ (XOR), затем присваивание результата | echo "$((num^=7)) = 5" |
|= |
Побитовое ИЛИ (OR), затем присваивание результата | echo "$((num |= 7)) = 7" |
| Сравнения | ||
< |
Меньше | ((num < 5)) && echo "переменная num меньше 5" |
> |
Больше | ((num > 5)) && echo "переменная num больше 3" |
<= |
Меньше или равно | ((num <= 20)) && echo "переменная num меньше или равна 20" |
>= |
Больше или равно | ((num >= 15)) && echo "переменная num больше или равна 15" |
== |
Равно | ((num == 3)) && echo "переменная num равна 3" |
!= |
Не равно | ((num != 3)) && echo "переменная num не равна 3" |
| Логические операции | ||
! |
Логическое НЕ (NOT) | (( ! num )) && echo "переменная num имеет значение ЛОЖЬ" |
&& |
Логическое И (AND) | (( 3 < num && num < 5 )) && echo "переменная num больше 3, но меньше 5" |
|| |
Логическое ИЛИ (OR) | (( num < 3 || 5 < num )) && echo "переменная num меньше 3 или больше 5" |
| Другие операции | ||
num++ |
Постфикс-инкремент | echo "$((num++))" |
num-- |
Постфикс-декремент | echo "$((num--))" |
++num |
Префикс-инкремент | echo "$((++num))" |
--num |
Префикс-декремент | echo "$((--num))" |
+num |
Унарный плюс или умножение числа на 1 | a=$((+num))" |
-num |
Унарный минус или умножение числа на -1 | a=$((-num))" |
УСЛОВИЕ ? ДЕЙСТВИЕ1 : ДЕЙСТВИЕ2 |
Тернарная условная операция | a=$(( b < c ? b : c )) |
ДЕЙСТВИЕ1, ДЕЙСТВИЕ2 |
Список выражений | ((a = 4 + 5, b = 16 - 7)) |
( ДЕЙСТВИЕ1 ) |
Группирование выражений (подвыражение) | a=$(( (4 + 5) * 2 )) |
Все операции выполняются в порядке их приоритета. Операции с большим приоритетом исполняются первыми.
Таблица 3-18 демонстрирует порядок операций.
| Порядок выполнения | Операция | Описание |
|---|---|---|
| 1 | ( ДЕЙСТВИЕ1 ) |
Группирование выражений |
| 2 | num++, num-- |
Постфиксный инкремент и декремент |
| 3 | ++num, --num |
Префиксный инкремент и декремент |
| 4 | +num, -num |
Унарный плюс и минус |
| 5 | ~, ! |
Побитовое и логическое отрицание |
| 6 | ** |
Возведение в степень |
| 7 | *, /, % |
Умножение, деление, нахождение остатка |
| 8 | +, - |
Сложение и вычитание |
| 9 | <<, >> |
Битовые сдвиги |
| 10 | <, <=, >, >= |
Сравнения |
| 11 | ==, != |
Равенство и неравенство |
| 12 | & |
Побитовое И |
| 13 | ^ |
Побитовое исключающее ИЛИ |
| 14 | | |
Побитовое ИЛИ |
| 15 | && |
Логическое И |
| 16 | || |
Логическое ИЛИ |
| 17 | УСЛОВИЕ ? ДЕЙСТВИЕ1 : ДЕЙСТВИЕ2 |
Тернарная условная операция |
| 18 | =, *=, /=, %=, +=, -=, <<=, >>=, &=, ^=, |= |
Присваивания |
| 19 | ДЕЙСТВИЕ1, ДЕЙСТВИЕ2 |
Список выражений |
Порядок выполнения можно изменить с помощью круглых скобок “( )”. Их содержимое называется подвыражением (subexpression). Bash вычисляет значения подвыражений в первую очередь. Если подвыражений несколько, они вычисляются по порядку.
Предположим, в вашем коде используется числовая константа. Её значение можно указать в произвольной системе счисления. Для выбора системы счисления используйте префикс. Список допустимых префиксов приведён в таблице 3-19.
| Префикс | Система счисления | Пример |
|---|---|---|
0 |
Восьмеричная | echo "$((071)) = 57" |
0x |
Шестнадцатеричная | echo "$((0xFF)) = 255" |
0X |
Шестнадцатеричная | echo "$((0XFF)) = 255" |
<основание># |
Система с указанным основанием от 2 до 64 | echo "$((16#FF)) = 255" |
echo "$((2#101)) = 5" |
При выводе на экран или в файл Bash всегда переводит значения чисел в десятичную систему. Встроенная команда printf меняет формат вывода чисел. Её можно вызвать, например, так:
printf "%x\n" 250
Эта команда выведет на экран число 250 в шестнадцатеричной системе.
Аналогично можно вывести и значение переменной:
printf "%x\n" $var
Арифметические действия
Начнём с самых простых математических операций — арифметических. В языках программирования они обозначаются привычными символами:
-
+сложение -
-вычитание -
/деление -
*умножение
Кроме них в программировании часто встречаются ещё два действия: возведение в степень и вычисление остатка от деления.
Возведение в степень принято записывать в виде ab. Здесь a является основанием, а b — показателем степени. Например, два в степени семь записывается как 27. В Bash это арифметическое действие обозначается двумя звёздочками:
2**7
Вычисление остатка от деления — это сложная, но важная в программировании операция. Рассмотрим её подробнее. Предположим, что мы разделили одно целое число на другое. В результате получилось дробное число. Тогда говорят, что при делении появился остаток.
Например, разделим 10 (делимое) на 3 (делитель). Если округлить результат, получим 3,33333 (частное). В этом случае остаток от деления равен 1. Чтобы его найти, умножим делитель 3 на целую часть частного 3 (неполное частное). Результат вычтем из делимого 10. Получим остаток 1.
Запишем наши вычисления в виде формул. Для этого введём следующие обозначения:
- a — делимое
- b — делитель
- q — неполное частное
- r — остаток
Тогда делимое вычисляется по формуле:
Отсюда выведем формулу для нахождения остатка:
Выбор неполного частного q вызывает вопросы. Иногда на его роль подходят несколько чисел. Выбрать из них правильное помогает ограничение. Частное q должно быть таким, чтобы остаток от деления r по абсолютной величине оказался меньше делителя b. Другими словами должно выполняться неравенство:
Операция нахождения остатка в Bash обозначается знаком процент %. В некоторых языках этим же символом обозначается операция modulo. Это два разных действия. Когда знаки делимого и делителя совпадают, они дают одинаковый результат.
Для примера вычислим остаток и modulo при делении 19 на 12 и -19 на -12. Получим:
19 % 12 = 19 - 12 * 1 = 7
19 modulo 12 = 19 - 12 * 1 = 7
-19 % -12 = -19 - (-12) * 1 = -7
-19 modulo -12 = -19 - (-12) * 1 = -7
Теперь рассмотрим случаи, когда знаки делимого и делителя различаются:
19 % -12 = 19 - (-12) * (-1) = 7
19 modulo -12 = 19 - (-12) * (-2) = -5
-19 % 12 = -19 - 12 * (-1) = -7
-19 modulo 12 = -19 - 12 * (-2) = 5
Остаток и modulo различаются.
Для расчёта modulo применяется та же формула, что и для остатка. Отличается только выбор неполного частного q. Для нахождения остатка, частное вычисляется по формуле:
Результат округляется к меньшему по модулю числу. То есть все знаки после запятой отбрасываются.
Неполное частное для modulo считается по-разному в зависимости от знаков a и b. Если знаки совпадают, формула для частного та же:
Если знаки разные, формула другая:
В обоих случаях результат округляется к меньшему по модулю числу.
Когда говорят об остатке от деления r, обычно предполагают, что и делимое a и делитель b положительны. Поэтому в справочниках часто встречается такое условие для остатка:
0 ≤ r < |b|
Однако при делении чисел с разными знаками остаток может быть отрицательным. Запомните простое правило: у остатка r всегда такой же знак, что и у делимого a. Если знаки различаются, значит вы нашли modulo.
Всегда помните о различии остатка от деления и modulo. Одни языки программирования вычисляют остаток в операторе %, другие — modulo. Это приводит к путанице.
Если сомневаетесь в своих вычислениях, проверьте их. Bash в операторе % всегда считает остаток от деления. Предположим, что нужно найти остаток деления 32 на -7. Следующая команда выведет результат:
echo $((32 % -7))
Остаток от деления равен четырём.
Теперь найдём modulo для этой же пары чисел. Воспользуйтесь онлайн-калькулятором. В поле “Expression” введите 32, в поле “Modulus” — 7. Нажмите кнопку “CALCULATE”. Вы получите два результата:
- “Result” равен 4.
- “Symmetric representation” равно -3.
Второй ответ -3 и есть modulo.
Для чего в программировании используют остаток от деления? Самая распространённая задача — это проверка числа на чётность. С её помощью контролируется целостность переданных данных в компьютерных сетях. Такая проверка называется бит контроля чётности.
Другая задача, в которой не обойтись без вычисления остатка, — это преобразование единиц времени. Рассмотрим пример. Предположим, что 128 секунд надо перевести в минуты. Для этого подсчитаем целое число минут в 128 секундах. Затем добавим к результату остаток.
Чтобы найти целое число минут, разделим 128 на 60. Получим неполное частное 2. То есть в 128 секундах — 2 минуты. Чтобы найти оставшиеся секунды, вычислим остаток от деления 128 на 60:
Остаток равен 8. Получается, что 128 секунд равны двум минутам и восьми секундам.
Вычисление остатка будет полезно и при работе с циклами. Например, если нужно выполнять действие на каждой N-ой итерации цикла. Предположим, что нас интересует каждая 10 итерация. Тогда надо проверять остаток от деления счётчика цикла на 10. Если остаток равен нулю, значит текущая итерация кратна 10.
Операция modulo широко применяется в криптографии.
Битовые операции
Битовые операции — это ещё один тип математических действий. Эти операции активно используется в программировании. Своё название они получили потому, что выполняются над каждым битом числа по отдельности.
Побитовое отрицание
Начнём с самой простой битовой операции — отрицания. В компьютерной литературе она иногда обозначается как НЕ или NOT. В Bash отрицание обозначается знаком тильда ~.
Чтобы выполнить побитовое отрицание, замените значение каждого бита числа на противоположное. То есть каждая единица заменяется на ноль и наоборот.
Например, выполним побитовое отрицание числа 5. Получим:
5 = 101
~5 = 010
Если ограничиться чистой математикой, побитовое отрицание — это очень простая операция. В программировании же с ней возникают сложности. Прежде всего встаёт вопрос: сколько байтов отводится под число? Предположим, что в нашем примере число 5 хранится в двухбайтовой переменной. Тогда в памяти в двоичном виде оно выглядит так:
00000000 00000101
После побитового отрицания значение переменной станет таким:
11111111 11111010
Как интерпретировать полученный результат? Если переменная объявлена как беззнаковое целое, результатом будет число 65530 в прямом коде. Если же переменная знаковая, её значение хранится в дополнительном коде. В этом случае результатом будет -6.
Команды и операторы Bash представляют целые по-разному. Например, echo всегда выводит числа как знаковые. Команда printf позволяет указать формат вывода: знаковое или беззнаковое целое.
В языке Bash нет типов. Все скалярные переменные хранятся в виде строк. Поэтому интерпретация целых чисел происходит в момент их подстановки в арифметические выражения. В зависимости от контекста они подставляются как знаковые или как беззнаковые.
В Bash под целые числа отводится 64 бита независимо от наличия знака. Таблица 3-20 демонстрирует их максимальные и минимальные допустимые значения.
| Целое число | Шестнадцатеричная система | Десятичная система |
|---|---|---|
| Максимальное положительное знаковое | 7FFFFFFFFFFFFFFF | 9223372036854775807 |
| Минимальное отрицательное знаковое | 8000000000000000 | -9223372036854775808 |
| Максимальное беззнаковое | FFFFFFFFFFFFFFFF | 18446744073709551615 |
Следующие примеры демонстрируют интерпретацию целых в командах echo, printf и операторе ((:
1 $ echo $((16#FFFFFFFFFFFFFFFF))
2 -1
3
4 $ printf "%llu\n" $((16#FFFFFFFFFFFFFFFF))
5 18446744073709551615
6
7 $ if ((18446744073709551615 == 16#FFFFFFFFFFFFFFFF)); then echo "ok"; fi
8 ok
9
10 $ if ((-1 == 16#FFFFFFFFFFFFFFFF)); then echo "ok"; fi
11 ok
12
13 $ if ((18446744073709551615 == -1)); then echo "ok"; fi
14 ok
Последний пример со сравнением чисел 18446744073709551615 и -1 показывает, что знаковые и беззнаковые целые хранятся в памяти одинаково. Но в зависимости от контекста они интерпретируются по-разному.
Вернёмся к примеру с побитовым отрицанием числа 5. В Bash его результатом будет 64 битное число 0xFFFFFFFFFFFFFFFA в шестнадцатеричной системе. Число можно вывести как положительное или как отрицательное целое:
1 $ echo $((~5))
2 -6
3
4 $ printf "%llu\n" $((~5))
5 18446744073709551610
Числа 18446744073709551610 и -6 равны с точки зрения Bash. Потому что все их биты в памяти совпадают.
Побитовое И, ИЛИ, исключающее ИЛИ
Операция побитового И также известна как AND. Она напоминает логическое И.
В логическом И результат выражения истинен, когда оба операнда истинны. Для остальных значений операндов результатом будет ложь.
Побитовое И выполняется над двумя числами. Они представляются в двоичном виде. Затем над каждой соответствующей парой битов двух чисел выполняется логическое И.
Запишем подробнее алгоритм для выполнения побитового И:
- Представить оба операнда в двоичном виде.
- Если число битов в одном операнде меньше чем в другом, дополнить его слева нулями.
- Применить логическое И к каждой паре битов, которые стоят на одинаковых позициях. То есть выполнить логическое И с первым битом первого числа и с первым битом второго числа. Затем перейти ко второму биту и т.д.
Рассмотрим пример. Вычислим побитовое И для чисел 5 и 3. В двоичном виде они выглядят так:
5 = 101
3 = 11
У числа 3 оказалось меньше битов, чем у 5. Поэтому дополним его двоичное представление одним нулём слева. Получим:
3 = 011
Если число отрицательное, переведите его в дополнительный код после добавления нулей.
Теперь выполним операцию логического И для каждой пары битов чисел 5 и 3. Для удобства запишем двоичное представление чисел в столбик. Получим следующее:
101
011
---
001
Переведём результат в десятичную систему:
001 = 1
Это значит, что результат побитового И для чисел 5 и 3 равен 1.
В Bash операция побитового И обозначается знаком амперсанд &. Выполним наше вычисление и выведем результат на экран:
echo $((5 & 3))
Операция побитового ИЛИ (OR) выполняется аналогично побитовому И. Только вместо логического И над каждой парой битов чисел выполняется логическое ИЛИ.
Вычислим побитовое ИЛИ для чисел 10 и 6. В двоичном виде они выглядят так:
10 = 1010
6 = 110
Число 6 надо дополнить нулём до четырёх битов:
6 = 0110
Теперь выполним логическое ИЛИ над каждой парой битов чисел 10 и 6:
1010
0110
----
1110
Переведём результат в десятичную систему:
1110 = 14
В Bash побитовое ИЛИ обозначается знаком |. Выведем результат для нашего примера:
echo $((10 | 6))
Операция побитового исключающего ИЛИ (XOR) похожа на побитовое ИЛИ. В ней над каждой парой битов операндов выполняется логическое исключающее ИЛИ. Исключающее ИЛИ возвращает ложь если операнды не равны. В противном случае результат операции — истина.
Вычислим исключающее ИЛИ для чисел 12 и 5. Переведём числа в двоичный вид:
12 = 1100
5 = 101
Дополним число 5 до четырёх битов:
5 = 0101
Выполним побитовое исключающее ИЛИ для каждой пары битов:
1100
0101
----
1001
Переведём результат в десятичную систему:
1001 = 9
В Bash исключающее ИЛИ обозначается символом ^. Расчёт нашего примера будет выглядеть так:
echo $((12 ^ 5))
Битовые сдвиги
Битовым сдвигом называется смена позиций битов числа.
Есть три типа сдвигов:
- Логический
- Арифметический
- Циклический
Самый простой из них — это логический. Рассмотрим сначала его.
Операция битового сдвига принимает два операнда. Первый — это число, над которым выполняется операция. Второй — количество битов, на которое происходит сдвиг.
Чтобы выполнить логический сдвиг, представьте исходное число в двоичном виде. Предположим, что выполняется сдвиг вправо на два бита. Тогда два крайние бита числа справа отбрасываются. Вместо них слева добавляются нули. Аналогично выполняется сдвиг влево. Два бита слева отбрасываются. Два нуля справа добавляются.
Рассмотрим пример. Выполним логический сдвиг беззнакового однобайтового целого 58 вправо на три бита. Сначала представим число в двоичном виде:
58 = 0011 1010
Теперь отбросим три бита справа:
0011 1010 >> 3 = 0011 1
Затем дополним результат нулями слева:
0011 1 = 0000 0111 = 7
Результат сдвига — число 7.
Попробуем сдвинуть число 58 на три бита влево. Получим следующее:
0011 1010 << 3 = 1 1010 = 1101 0000 = 208
Алгоритм аналогичен сдвигу вправо. Сначала отбрасываем крайние биты слева, а затем добавляем нули справа.
Рассмотрим второй тип сдвига — арифметический. Влево он выполняется точно так же, как и логический сдвиг.
Арифметический сдвиг вправо отличается от логического. Чтобы его выполнить, отбросьте нужное количество битов справа. Затем дополните результат битами слева. Их значение должно совпадать со старшим битом числа. Если он равен единице, добавляем справа единицы. В противном случае добавляем нули. Благодаря этому, после сдвига знак числа не меняется.
Для примера выполним арифметический сдвиг знакового однобайтового целого -105 вправо на два бита.
Сначала представим число в дополнительном коде:
Теперь выполним арифметический сдвиг вправо на два бита. Получим:
1001 0111 >> 2 -> 1001 01 -> 1110 0101
В нашем случае старший бит равен единице. Поэтому мы дополняем результат слева двумя единицами.
Мы получили отрицательное число в дополнительном коде. Переведём его в прямой:
1110 0101 = 1001 1011 = -27
Результат сдвига — число -27.
Операции << и >> интерпретатора Bash выполняют арифметические сдвиги. Рассмотренные нами примеры можно вычислить с помощью следующих команд:
1 $ echo $((58 >> 3))
2 7
3
4 $ echo $((58 << 3))
5 464
6
7 $ echo $((-105 >> 2))
8 -27
Результат сдвига 58 влево на три бита отличается от нашего, потому что Bash оперирует восьмибайтовыми целыми.
Циклический сдвиг редко применяется в программировании. Поэтому большинство языков не имеет для него встроенного оператора.
В циклическом сдвиге отброшенные биты появляются на освободившемся месте с другого конца числа.
Например, выполним циклический сдвиг числа 58 вправо на три бита. Результат будет следующим:
0011 1010 >> 3 = 010 0011 1 = 0100 0111 = 71
Отброшенные справа биты 010 оказались в левой части результата.
Применение битовых операций
Битовые операции широко применяются в системном программировании. Часто при работе с компьютерной сетью и периферийными устройствами приходится переводить данные из одного формата в другой.
Рассмотрим пример. Предположим, вы работаете с периферийным устройством. На устройстве порядок байтов от старшего к младшему (big-endian). Ваш компьютер использует другой порядок — от младшего к старшему (little-endian).
Устройство посылает на компьютер целое беззнаковое число. В шестнадцатеричной системе оно равно 0xAABB. Чтобы компьютер правильно прочитал это число, надо изменить порядок байтов в нём. После преобразования число 0xAABB станет равно 0xBBAA.
Для изменения порядка байтов сделаем следующее:
- Прочитаем младший байт числа (крайний справа) и сдвинем его влево на восемь битов, т.е. на один байт. Это делает следующая Bash-команда:
little=$(((0xAABB & 0x00FF) << 8))
- Прочитаем старший байт числа (крайний слева) и сдвинем его вправо на восемь битов. Команда:
big=$(((0xAABB & 0xFF00) >> 8))
3. Соединим старший и младший байты с помощью побитового ИЛИ:
result=$((little | big))
В результате в переменную result запишется число 0xBBAA.
Все шаги нашего вычисления можно выполнить одной командой:
value=0xAABB
result=$(( ((value & 0x00FF) << 8) | ((value & 0xFF00) >> 8) ))
Другой пример применения битовых операций. Они незаменимы для вычисления масок. Нам уже знакомы маски с правами доступа к файлам в Unix-окружении. Предположим, что файл имеет права -rw-r--r--. В двоичном виде эта маска выглядит так:
0000 0110 0100 0100
Проверим, имеет ли владелец файла право на его исполнение. Для этого вычислим побитовое И с маской 0000 0001 0000 0000. Получим:
0000 0110 0100 0100 & 0000 0001 0000 0000 = 0000 0000 0000 0000 = 0
Результат равен нулю. Это значит, что владелец не может исполнять файл.
Для добавления битов в маску применяется побитовое ИЛИ. Добавим владельцу файла право на исполнение. Вычисление выглядит так:
0000 0110 0100 0100 | 0000 0001 0000 0000 = 0000 0111 0100 0100 = -rwxr--r--
Мы выполнили побитовое ИЛИ маски с числом 0000 0001 0000 0000. В нём восьмой бит равен единице. С его помощью мы меняем восьмой бит маски. При этом значение бита маски неважно. Он будет выставлен в единицу не зависимо от текущего значения. Все биты числа кроме восьмого равны нулям. Благодаря этому, биты маски в тех же позиция не изменятся.
Для удаления битов из маски применяется побитовое И. Например, удалим право владельца файла на запись. Получим следующее:
0000 0111 0100 0100 & 1111 1101 1111 1111 = 0000 0101 0100 0100 = -r-xr--r--
Чтобы выставить девятый бит маски в ноль, мы выполнили побитовое И с числом 1111 1101 1111 1111. В нём девятый бит равен нулю, а все остальные — единицам. Поэтому в результате побитового И изменится только девятый бит маски. Все остальные сохранят свои значения.
Операционная система выполняет операции с масками каждый раз, когда вы обращаетесь к файлу. Так она проверяет ваши права на доступ.
Рассмотрим последний пример использования битовых операций. До недавнего времени битовые сдвиги широко применялись как альтернатива умножения и деления на степень двойки. Например, сдвиг влево на два бита соответствует умножению на 22 (т.е. четыре). Проверим это утверждение такой Bash-командой:
1 $ echo $((3 << 2))
2 12
Результат правильный. Умножение 3 на 4 даст 12.
Для примера сдвиг вправо на три бита соответствует делению на 23 (т.е. восемь). Проверим:
1 $ echo $((16 >> 3))
2 2
Подобные трюки сокращают число тактов процессора на выполнение операций умножения и деления. Сейчас эти оптимизации стали ненужны из-за развития компиляторов и процессоров. Компиляторы при генерации кода автоматически выбирают самые “дешевые” по числу тактов ассемблерные инструкции. Процессоры выполняют эти инструкции параллельно в несколько потоков. Поэтому сегодня программисты склонны писать более удобный для чтения и понимания код, а не более оптимальный. Операции умножения и деления с этой точки зрения лучше, чем битовые сдвиги.
Битовые операции также активно применяются в криптографии и компьютерной графике.
Логические операции
Для сравнения целых чисел в конструкции if оператор [[ неудобен. В нём отношения между числами обозначают двухбуквенные сокращения. Например, -gt для отношения больше. Удобнее использовать оператор (( в форме арифметической оценки. Тогда сокращения заменяются на привычные символы сравнения чисел (>, <, =).
Рассмотрим пример. Предположим, что значение переменной надо сравнить с константой 5. Это сделает следующая конструкция if:
1 if ((var < 5))
2 then
3 echo "Значение var меньше 5"
4 fi
Оператор (( можно заменить на команду let. В результате получим то же поведение:
1 if let "var < 5"
2 then
3 echo "Значение var меньше 5"
4 fi
Однако оператор (( использовать всегда предпочтительнее.
Обратите внимание на важное отличие арифметической оценки и подстановки. Согласно POSIX-стандарту, любая программа или команда при успешном выполнении возвращает ноль. При ошибке возвращается код возврата от 1 до 255. Этот код интерпретируется так: ноль означает истину, а не ноль — ложь. В этом смысле результат арифметической подстановки инвертирован, а оценки нет.
Арифметическая оценка — это синоним команды let. Значит она подчиняется требованиям POSIX-стандарта, как и любая другая команда. Арифметическая подстановка выполняется в контексте другой команды. Поэтому результат её работы зависит от реализации интерпретатора. В Bash если условие в операторе (( в форме подстановки истинно, будет возвращена единица. В противном случае оператор возвращает ноль. Такое поведение соответствует правилам вывода логических выражений языка C.
Рассмотрим пример. Предположим, есть команда для вывода результата сравнения переменной с числом. Она выглядит так:
((var < 5)) && echo "Значение var меньше 5"
Здесь используется арифметическая оценка. Поэтому если значение переменной меньше 5, оператор (( выполнится успешно. Тогда, согласно стандарту POSIX, он вернёт код ноль.
Если использовать оператором (( в форме арифметической подстановки, результат будет отличаться. Например:
echo "$((var < 5))"
Если условие истинно, команда echo выведет число 1. Такой результат согласуется с правилами вывода языка C.
Логические операции обычно применяют в форме арифметической оценки оператора ((. Они работают так же, как логические операторы Bash.
Для примера сравним значение переменной с двумя константами:
1 if ((1 < var && var < 5))
2 then
3 echo "Значение var меньше 5, но больше 1"
4 fi
В этом случае условие истинно, когда выполняются оба неравенства.
Аналогично работает логическое ИЛИ:
1 if ((var < 1 || 5 < var))
2 then
3 echo "Значение var меньше 1 или больше 5"
4 fi
Выражение истинно, если хотя бы одно из неравенств выполняется.
Логическое НЕ редко применяется к самим числам. Чаще его используют для отрицания выражения. Если применить НЕ к числу, вывод результата соответствует POSIX-стандарту. Другими словами ноль означает истинна, а не ноль — ложь. Например:
1 if ((! var))
2 then
3 echo "Значение var равно истина или ноль"
4 fi
Это условие выполнится только, если переменная равна нулю.
Инкремент и декремент
Операции инкремента и декремента впервые появились в языке программирования B. Кен Томпсон и Денис Ритчи разработали его в 1969 году, работая в Bell Labs. Позднее Денис Ритчи перенёс эти операции в свой новый язык C. Оттуда их скопировали в Bash.
Начнём с операций присваивания. Тогда смысл инкремента и декремента станет понятнее.
Обычное присваивание в арифметической оценке выглядит так:
((var = 5))
В результате значение переменной var станет равно 5.
Bash позволяет объединить присваивание с арифметическим действием или битовой операцией. Например, одновременное сложение и присваивание выглядит так:
((var += 5))
Здесь выполняются два действия:
- К текущему значению переменной
varприбавляется число 5. - Результат сложения записывается в переменную
var.
Аналогично работают остальные операции присваивания. Сначала выполняется действие, затем результат записывается в переменную. Такой синтаксис позволяет сократить код и сделать его нагляднее.
Теперь рассмотрим операции инкремента и декремент. У них есть две формы: постфиксная и префиксная. Они записываются по-разному. В постфиксной форме знаки ++ и – идут после имени переменной, а в префиксной — до.
Рассмотрим префиксный инкремент:
((++var))
Результат этой команды такой же, как у следующей операции присваивания:
((var+=1))
Инкремент увеличивает значение переменной на единицу. Декремент — уменьшает на единицу.
Зачем вводить отдельные операции для прибавления и вычитания единицы? Ведь есть достаточно компактные операции сложения и вычитания, совмещённые с присваиванием (+= и -=).
Скорее всего дело в счётчике цикла. Он часто используется в программировании. Счётчик отсчитывать номер итерации цикла. Это нужно, чтобы вовремя прервать его выполнение. Инкремент и декремент упрощают работу со счётчиком. Кроме того современные процессоры выполняют эти операции на аппаратном уровне. Поэтому они работают быстрее, чем сложение и вычитание с присваиванием.
Чем отличаются префиксный и постфиксный инкременты? Если выражение состоит только из операции инкремента, то результат будет одинаковым для обеих форм.
Например, следующие команды увеличат значение переменной на единицу:
1 ((++var))
2 ((var++))
Разница между формами инкремента появляется, при присваивании результата переменной.
Рассмотрим следующий пример:
1 var=1
2 ((result = ++var))
В результате значения обеих переменных result и var станут двум. Это означает, что префиксный инкремент сначала прибавляет единицу, а потом возвращает результат сложения.
Если расписать префиксный инкремент по отдельным командам, получится следующее:
1 var=1
2 ((var = var + 1))
3 ((result = var))
Поведение постфиксного инкремента отличается. Заменим форму инкремента в нашем примере:
1 var=1
2 ((result = var++))
После выполнения команд в переменную result запишется единица, а в var — двойка. Постфиксный инкремент сначала возвращает значение, а потом прибавляет единицу.
Распишем постфиксный инкремент по отдельным командам:
1 var=1
2 ((tmp = var))
3 ((var = var + 1))
4 ((result = tmp))
Обратите внимание на порядок выполнения постфиксного инкремента. Сначала var увеличивается на единицу. Только после этого её прошлое значение возвращается в качестве результата. Поэтому прошлое значение var пришлось сохранить во временную переменную tmp.
Постфиксная и префиксная формы декремента работают аналогично инкременту.
Всегда используйте префиксную форму инкремента и декремента вместо постфиксной. Во-первых, она быстрее выполняется процессором. Потому что не надо сохранять текущее значение переменной. Во-вторых, с постфиксной формой легче допустить ошибку из-за неочевидного порядка присваивания.
Тернарная условная операция
Тернарная условная операция также известна как тернарный оператор. Она впервые появилась в языке Алгол. Операция оказалась удобной и востребованной программистами. Поэтому её добавили в языки следующего поколения: BCPL и C. Дальше её переняли почти все современные языки: C++, C#, Java, Python, PHP и т.д.
Тернарный оператор представляет собой компактную форму конструкции if.
Для примера рассмотрим такой оператор if:
1 if ((var < 10))
2 then
3 ((result = 0))
4 else
5 ((result = var))
6 fi
Здесь переменной result присваивается ноль, если var меньше 10. В противном случае result присваивается значение var.
Такое же поведение даст тернарный оператор. Он выглядит так:
((result = var < 10 ? 0 : var))
Одна строка заменила шесть строк конструкции if.
Тернарный оператор состоит из условного выражения и двух действий. В общем случае он выглядит так:
Если УСЛОВИЕ истинно, выполняется ДЕЙСТВИЕ 1. Иначе — ДЕЙСТВИЕ 2. Такое поведение полностью совпадает с условным оператором if. Запишем его тоже в общем виде:
1 if УСЛОВИЕ
2 then
3 ДЕЙСТВИЕ 1
4 else
5 ДЕЙСТВИЕ 2
6 fi
Сравните тернарный оператор и конструкцию if.
К сожалению, Bash допускает тернарный оператор только в арифметической оценке и подстановке. Это означает, что в качестве условия и действий можно указать только арифметические выражения. Вызов команд Bash или внешних утилит из тернарного оператора невозможен. Такого ограничения нет в других языках программирования.
Используйте тернарный оператор как можно чаще. Это считается хорошей практикой. С ним код станет компактнее и удобнее для чтения. Также считается, что в меньшем объёме кода меньше места для возможной ошибки.
Операторы цикла
Условные операторы управляют порядком выполнения программы. Порядок выполнения — это последовательность исполнения операторов, команд и инструкций программы.
Условный оператор выбирает ветвь исполнения в зависимости от логического выражения. Иногда этого недостаточно. Нужны дополнительные средства для управления порядком выполнения. Операторы цикла решают задачи, с которыми не справляются условные операторы.
Оператор цикла многократно повторяет один и тот же блок команд. Однократное выполнение этого блока называется итерацией цикла. На каждой итерации проверяется условие цикла. В зависимости от результата, цикл продолжается или прекращается.
Повторение команд
Зачем в программе повторять один и тот же блок команд? Чтобы ответить на этот вопрос, рассмотрим несколько примеров.
Утилита find нам уже знакома. Она ищет файлы и каталоги на жёстком диске. Если в вызов утилиты добавить опцию -exec, можно указать действие. Оно выполнится над каждым найденным объектом.
Например, следующая команда удалит все PDF документы пользователя в каталоге ~/Documents:
"*.pdf" -exec rm {} \;
В этом случае find несколько раз вызовет утилиту rm. На каждом вызове ей передаётся очередной результат поиска find. Получается, что утилита find выполняет оператор цикла. Цикл завершится после обработки всех найденных файлов.
Утилита du — это ещё один пример повторения действий. Утилита оценивает объём использованного дискового пространства на дисках. У du есть необязательный параметр. Это путь, с которого начинается оценка.
Вот пример вызова утилиты:
Для выполнения этой команды утилита рекурсивно обойдёт все подкаталоги ~/Documents. Размер каждого найденного файла добавится к конечному результату. Это означает, что инкремент результата оценки повторяется снова и снова.
Утилита du выполняет цикл для прохода по всем файлам в каждом найденном ею каталоге. Размер каждого файла читается и прибавляется к конечному результату.
Повторение операций часто встречается в математических расчётах. Каноничный пример — это вычисление факториала. Факториалом числа N называется произведение последовательных натуральных чисел от 1 до N включительно.
Например, факториал числа 4 вычисляется так:
4! = 1 * 2 * 3 * 4 = 24
Факториал легко вычислить с помощью оператора цикла. Для этого цикл должен последовательно перебрать целые числа от 1 до N. Каждое число умножается на конечный результат. В этом случае повторяется операция умножения.
В качестве последнего примера повторения действий рассмотрим события в компьютерной системе.
Представьте, что вы пишете программу. Она загружает на компьютер файлы из интернета. Для начала программа устанавливает соединение с сервером. Если сервер не отвечает, у программы есть два варианта действий. Первый — завершить выполнение с ненулевым кодом возврата. Второй — ожидать ответа. Второй вариант предпочтительнее. Есть много причин, по которым ответ от сервера задерживается. Например, перегружена сеть или сам сервер. Двух-трёхсекундного ожидания будет достаточно, чтобы получить ответ. Тогда наша программа продолжит работу.
Возникает вопрос: как в программе ожидать наступление события? Самый простой способ — использовать оператор цикла. Условием выхода из него будет наступление ожидаемого события. В нашем примере цикл завершится при получении ответа от сервера. Цикл продолжается пока событие не наступило. При этом его блок команд пустой. Такая техника называется активным ожиданием событий или busy-waiting.
Вместо пустого блока команд в цикле ожидания можно останавливать программу на короткое время. Тогда ОС сможет работать над другой задачей, пока ваша программа остановлена.
Мы рассмотрели несколько примеров, когда программа повторяет одни и те же действия. Запишем задачи, решаемые в каждом примере:
- Однообразная обработка нескольких сущностей. Например, результатов поиска утилиты find.
- Накопление конечного результата из промежуточных данных. Например, сбор статистики утилитой du.
- Математические расчёты. Например, вычисление факториала.
- Ожидание наступления какого-либо события. Например, получение ответа от сервера по сети.
Список далеко не полный. Это наиболее часто встречающиеся в программировании задачи, для решения которых требуются оператор цикла.
Оператор while
В Bash есть два оператора цикла: while и for. Сначала познакомимся с оператором while. Он проще чем for.
Синтаксис while напоминает условный оператор if. В общем виде он выглядит так:
1 while УСЛОВИЕ
2 do
3 ДЕЙСТВИЕ
4 done
Оператор можно записать в одну строку:
while УСЛОВИЕ; do ДЕЙСТВИЕ; done
В конструкции while УСЛОВИЕМ и ДЕЙСТВИЕМ может быть одна команда или блок команд. Точно так же как в операторе if. ДЕЙСТВИЕ называется телом цикла (loop body).
Выполнение while начинается с проверки УСЛОВИЯ. Если команда УСЛОВИЯ вернула нулевой код, оно считается истинным. В этом случае выполняется ДЕЙСТВИЕ. Дальше опять проверяется УСЛОВИЕ. Если оно по-прежнему истинно, снова выполняется ДЕЙСТВИЕ. Цикл прервётся тогда, когда УСЛОВИЕ станет ложным.
Используйте цикл while, когда количество итераций заранее неизвестно. Например, при активном ожидании какого-то события.
Для примера напишем скрипт. Он проверит доступность сервера в интернете. Для такой проверки отправим серверу запрос. Как только сервер пришлёт ответ, наш скрипт выведет сообщение и завершится.
Чтобы отправить серверу запрос, вызовем утилиту ping. Утилита использует ICMP протокол. Протокол — это соглашение о формате сообщений между компьютерами в сети. ICMP протокол описывает формат сообщений для обслуживания сети. Они нужны, например, чтобы проверить доступность какого-то компьютера.
В качестве входного параметра утилита ping принимает URL или IP-адрес целевого хоста. Хостом называется любой подключённый к сети компьютер или устройство.
Команда для вызова утилиты ping выглядит так:
В качестве целевого хоста мы указали сервер Google. Утилита будет отправлять ему ICMP-сообщения. Сервер будет отвечать на каждое из них. Вывод утилиты выглядит так:
1 PING google.com (172.217.21.238) 56(84) bytes of data.
2 64 bytes from fra16s13-in-f14.1e100.net (172.217.21.238): icmp_seq=1 ttl=51 time=17.\
3 8 ms
4 64 bytes from fra16s13-in-f14.1e100.net (172.217.21.238): icmp_seq=2 ttl=51 time=18.\
5 5 ms
Это информация о каждом отправленном ICMP-сообщении и ответе на него. Сейчас утилита работает в бесконечном цикле. Чтобы её остановить, нажмите комбинацию клавиш Ctrl+C.
Чтобы проверить доступность сервера, достаточно отправить ему одно ICMP-сообщение. Укажем это с помощью опции -c утилиты ping. Команда станет выглядеть так:
1 google.com
Если сервер google.com доступен, утилита вернёт код ноль. В противном случае код будет ненулевым.
Утилита ping ожидает ответ от сервера, пока её не прервёт пользователь. С помощью опции -W ограничим время ожидания одной секундой. Получится такая команда:
1 -W 1 google.com
У нас готово условие для конструкции while. Запишем конструкцию целиком:
1 while ! ping -c 1 -W 1 google.com &> /dev/null
2 do
3 sleep 1
4 done
Нас не интересует вывод утилиты ping. Поэтому перенаправим его в файл /dev/null.
В условии цикла результат вызова ping инвертирован. Поэтому тело цикла выполняется до тех пор, пока утилита возвращает отличный от нуля код. Другими словами цикл выполняется, пока сервер недоступен.
В теле цикла вызывается утилита sleep.
Она останавливает выполнение скрипта на указанное количество секунд. В нашем примере остановка длится одну секунду.
Листинг 3-18 демонстрирует полный скрипт для проверки доступности сервера.
1 #!/bin/bash
2
3 while ! ping -c 1 -W 1 google.com &> /dev/null
4 do
5 sleep 1
6 done
7
8 echo "Сервер google.com доступен"
У конструкции while есть альтернативная форма until. В ней ДЕЙСТВИЕ выполняется до тех пор, пока УСЛОВИЕ ложно. То есть цикл выполняется, пока УСЛОВИЕ возвращает отличный от нуля код. С помощью формы until можно инвертировать условие while.
В общем виде конструкция until выглядит так:
1 until УСЛОВИЕ
2 do
3 ДЕЙСТВИЕ
4 done
Запись unitl в одну строку похожа на while:
until УСЛОВИЕ; do ДЕЙСТВИЕ; done
Заменим конструкцию while на until в листинге 3-18. Для этого удалим отрицание результата утилиты ping. Получится скрипт, приведённый в листинге 3-19.
1 #!/bin/bash
2
3 until ping -c 1 -W 1 google.com &> /dev/null
4 do
5 sleep 1
6 done
7
8 echo "Сервер google.com доступен"
Поведение скриптов в листингах 3-18 и 3-19 полностью совпадает.
Выбирайте форму while или until в зависимости от условия цикла. Старайтесь составлять условия без отрицаний. Отрицания усложняют чтение кода.
Бесконечный цикл
Конструкция while часто применяется в бесконечных циклах. Такие циклы выполняются всё время, пока работает программа.
Бесконечные циклы встречаются в системном ПО, которое работает до отключения питания компьютера. Например, в ОС или прошивках микроконтроллеров. Такие циклы также применяются в компьютерных играх и программах-мониторах для сбора статистики.
Цикл while станет бесконечным, если его условие всегда истинно. Самый простой способ задать такое условие — вызвать встроенную команду интерпретатора true. Например, так:
1 while true
2 do
3 sleep 1
4 done
Команда true всегда возвращает истину. То есть её код возврата ноль. У true есть симметричная команда false. Она всегда возвращает единицу, то есть ложь.
Команду true в условии while можно заменить на двоеточие. Тогда получим следующее:
1 while :
2 do
3 sleep 1
4 done
Команда двоеточие — это синонимом true. Она нужна для совместимости с Bourne shell. В нём команды true и false отсутствуют. В POSIX-стандарт включены все три команды: двоеточие, true и false.
Рассмотрим пример бесконечного цикла. Напишем скрипт для вывода статистики об использовании дискового пространства. Для этого воспользуемся утилитой df. При вызове без параметров она выведет следующее:
1 $ df
2 Filesystem 1K-blocks Used Available Use% Mounted on
3 C:/msys64 41940988 24666880 17274108 59% /
4 Z: 195059116 110151748 84907368 57% /z
Занятое (Used) и свободное (Available) дисковое пространство указано в байтах. Добавим в вызов утилиты опцию -h. Тогда вместо байтов получим килобайты, мегабайты, гигабайты и терабайты. Также добавим опцию -T. Она покажет тип файловой системы для каждого диска. Вывод утилиты станет таким:
1 $ df -hT
2 Filesystem Type Size Used Avail Use% Mounted on
3 C:/msys64 ntfs 40G 24G 17G 59% /
4 Z: hgfs 187G 106G 81G 57% /z
Чтобы вывести информацию обо всех точках монтирования, добавьте опцию -a.
Напишем бесконечный цикл, в теле которого вызывается утилита df. Получится простейший скрипт для наблюдения за файловой системой. Скрипт приведён в листинге 3-20.
1 #!/bin/bash
2
3 while true
4 do
5 clear
6 df -hT
7 sleep 2
8 done
В начале цикла вызывается утилита clear. Она очищает окно терминала от текста. Благодаря этому, в окне останется вывод нашего скрипта без лишней информации.
При работе с Bash часто возникает задача циклического выполнения команды. Для этого есть специальная утилита watch. Она входит в состав пакета procps. Чтобы установить этот пакет в окружение MSYS2, выполните следующую команду:
Теперь скрипт из листинга 3-20 можно заменить одной командой:
2 "df -hT"
Опция -n утилиты watch задаёт интервал между вызовами команды. Команда для исполнения указывается после всех опций.
Опция watch -d подсвечивает разницу в выводе команды, выполненной на текущей итерации и на прошлой. Благодаря этому, легче отследить произошедшие изменения.
Чтение стандартного потока ввода
Цикл while хорошо подходит для обработки потока ввода. Рассмотрим пример такой задачи. Напишем скрипт, который прочитает ассоциативный массив из текстового файла.
Листинг 3-10 демонстрирует скрипт для работы с контактами. Они хранятся в коде скрипта. Из-за этого контакты неудобно редактировать. Пользователь должен знать синтаксис Bash. Иначе он допустит ошибку при инициализации элемента массива, и скрипт перестанет работать.
Проблему редактирования можно решить. Поместим контакты в отдельный текстовый файл. При старте скрипт будет загружать из него все контакты. Так мы разделим данные и код.
Листинг 3-21 демонстрирует один из вариантов формата файла с контактами.
contacts.txt1 Alice=alice@gmail.com
2 Bob=(697) 955-5984
3 Eve=(245) 317-0117
4 Mallory=mallory@hotmail.com
Напишем скрипт для чтения этого файла. Удобнее читать контакты сразу в ассоциативный массив. Тогда механизм поиска контакта по имени останется таким же эффективным, как и раньше.
Для чтения файла нам понадобится цикл. Перед его выполнением мы не знаем, сколько итераций понадобиться. Значит, нам нужен цикл while.
Почему число итераций цикла неизвестно? Файл контактов надо читать построчно. Каждая его строка хранит одну запись. Скрипт читает запись, добавляет её в ассоциативный массив и переходит к следующей строке файла. Получается, что число итераций цикла равно числу строк. Но размер файла нам неизвестен, пока мы не прочитаем его полностью. Поэтому число итераций также неизвестно.
Для чтения строк файла применим встроенную команду интерпретатора read. Она читает строку из стандартного потока ввода. Затем сохраняет строку в переменную. Имя переменной передаётся в команду как параметр. Например:
read var
После запуска этой команды пользователь должен ввести строку и нажать Enter. Она сохранится в переменной var. Если вызвать read без параметров, введённая строка сохранится в зарезервированной переменной REPLY.
Команда read читает введённую пользователем строку. При этом read удаляет из строки символы обратного слэша . Они экранируют специальные символы. Поэтому read считает слэши ненужными. Чтобы отключить эту функцию, используйте опцию -r. В противном случае некоторые символы из ввода могут потеряться.
Команде read можно передать на вход несколько имён переменных. В этом случае введённый пользователем текст разделится на части. Разделителями будут символы из зарезервированной переменной IFS. По умолчанию это пробел, знак табуляции и перевод строки.
Рассмотрим пример. Предположим, что вводимые пользователем строки сохраняются в двух переменных с именами path и file. Вызов read в этом случае выглядит так:
read -r path file
Дальше пользователь вводит следующий текст:
Тогда путь ~/Documents попадёт в переменную path, а имя файла report.txt в file.
Если путь содержит пробелы, произойдёт ошибка. Предположим, пользователь ввёл следующее:
Тогда в переменную path попадёт строка ~/My. В file запишется всё остальное: Documents report.txt. Не забывайте про такое поведение команды read.
Проблему разделения строки можно решить. Для этого переопределим зарезервированную переменную IFS. В качестве разделителя укажем только запятую:
В этом примере мы применили специфичный для Bash вид кавычек $'...'. В них не выполняются никакие подстановки. Но некоторые управляющие последовательности разрешены: \n (новая строка), \\ (экранированный обратный слэш), \t (табуляция) и \xnn (байты в шестнадцатеричной системе).
Теперь следующий ввод пользователя обработается корректно:
1 ~/My Documents,report.txt
Путь и имя файла разделены запятой. При этом она не встречается ни в пути, ни в имени. Поэтому ввод пользователя обработается корректно. Строка ~/My Documents попадёт в переменную path, а report.txt — в file.
Команда read читает данные со стандартного потока ввода. Это значит, что ей на вход можно перенаправить содержимое файла.
Для примера прочитаем первую строку файла contacts.txt из листинга 3-21. Это сделает следующая команда:
read -r contact < contacts.txt
После выполнения этой команды в переменную contact запишется строка “Alice=alice@gmail.com”.
Имя и контактные данные можно записать в разные переменные. Для этого в качестве разделителя укажем знак равно =. Получим такую команду read:
IFS=$'=' read -r name contact < contacts.txt
Теперь имя Alice запишется в переменную name, а адрес электронной почты в contact.
Чтобы прочитать весь файл contacts.txt, напишем такой цикл while:
1 while IFS=$'=' read -r name contact < "contacts.txt"
2 do
3 echo "$name = $contact"
4 done
К сожалению, это не сработает. Произойдёт зацикливание. Зацикливанием называется бесконечное повторение тела цикла из-за ошибки. Причина проблемы в том, что read всегда читает только первую строку файла и возвращает нулевой код возврата. Нулевой код в условии цикла приведёт к повторному выполнению его тела снова и снова.
Чтобы цикл while последовательно прошёл по всем строкам файла, запишем его в следующей форме:
1 while УСЛОВИЕ
2 do
3 ДЕЙСТВИЕ
4 done < ФАЙЛ
Чтобы обработать ввод пользователя с клавиатуры, в качестве файла укажите /dev/tty. Тогда цикл будет обрабатывать ввод до тех пор, пока пользователь не нажмёт сочетание клавиш Ctrl+D.
Правильный вариант цикла while для чтения файла contacts.txt выглядит так:
1 while IFS=$'=' read -r name contact
2 do
3 echo "$name = $contact"
4 done < "contacts.txt"
Этот цикл выведет на экран всё содержимое файла контактов.
Нам остался последний шаг. На каждой итерации цикла будем добавлять в массив элемент, соответствующий значениям переменных name и contact.
Конечный вариант скрипта для работы с файлом контактов приведён в листинге 3-22
1 #!/bin/bash
2
3 declare -A array
4
5 while IFS=$'=' read -r name contact
6 do
7 array[$name]=$contact
8 done < "contacts.txt"
9
10 echo "${array["$1"]}"
Мы получили такое же поведение, как у скрипта из листинга 3-10.
Оператор for
Кроме while в Bash есть оператор цикла for. Используйте его, когда количество итераций известно заранее.
У оператора for есть две формы. Первая нужна для последовательной обработки слов в строке. Во второй форме условием цикла выступает арифметическое выражение.
Первая форма for
Начнём с первой формы for. В общем виде она выглядит так:
1 for ПЕРЕМЕННАЯ in СТРОКА
2 do
3 ДЕЙСТВИЕ
4 done
В однострочном виде эта же конструкция записывается так:
for ПЕРЕМЕННАЯ in СТРОКА; do ДЕЙСТВИЕ; done
ДЕЙСТВИЕМ в конструкции for может быть одна команда или блок команд. Точно так же как в операторе while.
Перед первой итерацией цикла Bash выполнит все подстановки в условии конструкции for. Что это значит? Предположим, что вместо СТРОКИ вы указали команду. Тогда перед началом цикла команда выполнится и её вывод заменит СТРОКУ. Если указать шаблон — он будет развёрнут.
Дальше СТРОКА разделяется на слова. Разделители читаются из переменной IFS. Затем выполняется первая итерация цикла. Во время итерации первое слово из СТРОКИ будет доступно в теле цикла как значение ПЕРЕМЕННОЙ. На второй итерации в ПЕРЕМЕННУЮ запишется второе слово СТРОКИ и т.д. Цикл завершится после прохода по всем словам СТРОКИ.
Рассмотрим пример цикла for. Напишем скрипт для обработки слов в строке. Строка передаётся в скрипт первым параметром.
Листинг 3-23 демонстрирует код скрипта.
1 #!/bin/bash
2
3 for word in $1
4 do
5 echo "$word"
6 done
Обратите внимание, что позиционный параметр $1 не надо заключать в кавычки. Если это сделать, не сработает word splitting. Входная строка не разделится на слова. Тогда тело цикла выполнится один раз. При этом в переменную word запишется вся входная строка. Это не то, что нам нужно. Скрипт должен обработать каждое слово строки по отдельности.
Передаваемую в скрипт строку надо заключить в кавычки. Тогда она целиком попадёт в позиционный параметр $1. Например:
"this is a string"
Проблему кавычек при передаче строки в скрипт можно решить. Замените в условии цикла позиционный параметр $1 на $@. Получится такая конструкция for:
1 for word in $@
2 do
3 echo "$word"
4 done
Теперь сработают оба варианта вызова скрипта:
1 ./for-string.sh this is a string
2 ./for-string.sh "this is a string"
У условия цикла for есть краткая форма. Она перебирает все входные параметры скрипта. Мы записали условие цикла так:
for word in $@
Тот же самый результат даст следующее условие:
1 for word
2 do
3 echo "$word"
4 done
Мы просто отбросили “in $@” в условии. Поведение цикла от этого не изменилось.
Немного усложним задачу. Предположим, что скрипт получает на вход список путей. Их разделяют запятые. В самих путях могут встречаться пробелы. Чтобы правильно обработать такой ввод, переопределим переменную IFS.
Листинг 3-24 демонстрирует цикл for для обработки списка путей.
1 #!/bin/bash
2
3 IFS=$','
4 for path in $1
5 do
6 echo "$path"
7 done
Через переменную IFS мы указали единственный разделитель слов — запятую. Поэтому цикл for при разделении строки $1 будет ориентироваться на запятые, а не на пробелы.
Скрипт можно вызвать например так:
"~/My Documents/file1.pdf,~/My Documents/report2.txt"
В этом случае кавычки для строки с путями обязательны. Если их опустить и заменить в скрипте параметр $1 на $@, возникнет ошибка. Во время вызова скрипта произойдёт word splitting. При этом разделители прочитаются из переменной IFS окружения. То есть до нашего переопределения IFS в скрипте. Поэтому строка с путями разделится пробелами.
Если в одном из путей встретится запятая, опять же возникнет ошибка.
Цикл for позволяет пройти по элементам индексируемого массива. Это работает так же, как перебор слов в строке. Листинг 3-25 демонстрирует пример.
1 #!/bin/bash
2
3 array=(Alice Bob Eve Mallory)
4
5 for element in "${array[@]}"
6 do
7 echo "$element"
8 done
Предположим, вам нужны только первые три элемента. Тогда в условии цикла можно подставить не весь массив, а только нужные элементы. Например, как в листинге 3-26.
1 #!/bin/bash
2
3 array=(Alice Bob Eve Mallory)
4
5 for element in "${array[@]:0:2}"
6 do
7 echo "$element"
8 done
Другой вариант — перебирать в цикле не сами элементы, а их индексы. Запишем индексы нужных элементов через пробел. Затем пройдём по ним в цикле. Получится следующее:
1 array=(Alice Bob Eve Mallory)
2
3 for i in 0 1 2
4 do
5 echo "${array[i]}"
6 done
Цикл пройдёт только по элементам с индексами 0, 1 и 2.
Нужные индексы элементов можно указать через подстановку фигурных скобок. Например, так:
1 array=(Alice Bob Eve Mallory)
2
3 for i in {0..2}
4 do
5 echo "${array[i]}"
6 done
Результат будет тем же — скрипт выведет первые три элемента массива.
Не используйте индексы элементов при обработке массивов с пропусками. Вместо этого подставляйте нужные элементы массива в условии цикла, как в листингах 3-25 и 3-26.
Обработка списка файлов
Цикл for подходит для обработки списка файлов. Для решения этой задачи важно правильно составить условие цикла. При этом часто совершают ряд типичных ошибок. Рассмотрим их на примерах.
Напишем скрипт для вывода типов файлов в текущем каталоге. Вывести тип файла можно утилитой file.
Главная ошибка при составлении условия цикла for — пренебрежение шаблонами (globbing). Вместо шаблона в качестве СТРОКИ часто подставляют вывод утилит ls или find. Например, так:
1 for filename in $(ls)
2 for filename in $(find . -type f)
Это неправильно. Такое решение приведёт к следующим проблемам:
- Word splitting разделит на части имена файлов и каталогов с пробелами.
- Если имя файла содержит символ звёздочка *, перед итерацией цикла выполнится подстановка шаблонов. Результат подстановки запишется в переменную
filenameвместо настоящего имени файла. - Вывод утилиты ls зависит от региональных настроек. Из-за этого некоторые символы национального алфавита в именах файлов могут поменяться на знаки вопроса. Тогда цикл for не сможет обработать эти файлы.
Всегда используйте шаблоны в цикле for для перебора имён файлов. Это единственное правильное решение задачи.
Для нашей задачи условие цикла выглядит так:
for filename in *
Листинг 3-27 демонстрирует полную версию скрипта.
1 #!/bin/bash
2
3 for filename in *
4 do
5 file "$filename"
6 done
Не забывайте про двойные кавычки при подстановке переменной filename. Это предотвратит word splitting в именах файлов с пробелами.
Шаблон в условии цикла for сработает, если надо пройти по файлам из конкретного каталога. Такой шаблон выглядит, например, так:
for filename in /usr/share/doc/bash/*
Шаблон может отфильтровать файлы с определённым расширением или именем. Например:
for filename in ~/Documents/*.pdf
В Bash начиная с версии 4 шаблоны позволяют обходить каталоги рекурсивно. Например:
1 shopt -s globstar
2
3 for filename in **
Чтобы это сработало, включите опцию интерпретатора globstar с помощью команды shopt.
Вместо шаблона ** Bash подставит список всех подкаталогов и файлов в них, начиная с текущего каталога. Этот механизм можно совмещать с обычными шаблонами.
Например, пройдём по всем файлам с расширением PDF из домашнего каталога пользователя. Условие цикла for для этого выглядит так:
1 shopt -s globstar
2
3 for filename in ~/**/*.pdf
Скрипт из листинга 3-27 можно заменить следующим вызовом утилиты find:
1 -exec file {} \;
Такое решение эффективнее, чем цикл for. Оно компактнее и работает быстрее из-за меньшего числа операций.
Когда стоит обрабатывать файлы в цикле for, а когда утилитой find? Используйте find, когда файлы можно обработать одной короткой командой. Если для обработки нужны условные операторы или блок команд, вызов find становится громоздким. В этом случае цикл for предпочтительнее.
В скрипте из листинга 3-27 конструкцию for можно заменить на while. Чтобы получить список файлов для обработки, вызовем утилиту find. При этом важно использовать её опцию -print0. Листинг 3-28 демонстрирует результат.
1 #!/bin/bash
2
3 while IFS= read -r -d '' filename
4 do
5 file "$filename"
6 done < <(find . -maxdepth 1 -print0)
В этом скрипте есть несколько важных решений. Рассмотрим их подробнее. Первый вопрос: зачем переменной IFS присваивать пустое значение? Без этого word splitting разделит вывод команды find пробелами, табуляцией и переводом строк. Тогда имена файлов с этими символами обработаются неправильно.
Второе важное решение — опция -d команды read. Она определяет символ для разделения текста на входе команды. В переменную filename запишется часть текста до очередного разделителя.
В нашем примере разделитель для команды read пустой. Это означает NUL-символ. Его можно указать и явно. Например, так:
while IFS= read -r -d $'\0' filename
Благодаря опции -d, команда read правильно обработает вывод утилиты find. Утилита вызвана с опцией -print0. Это значит, что найденные файлы в выводе разделит NUL-символ.
Обратите внимание, что указать NUL-символ в качестве разделителя через переменную IFS нельзя. Другими словами следующий вариант не сработает:
while IFS=$'\0' read -r filename
Проблема в особенности интерпретации переменной IFS. Если её значение пустое, Bash вообще не выполняет word splitting.
В скрипте из листинга 3-28 осталось ещё одно неочевидное решение. Вывод утилиты find передаётся в цикл while через подстановку процесса. Почему не подходит подстановка команды? Например, такая:
1 while IFS= read -r -d '' filename
2 do
3 file "$filename"
4 done < $(find . -maxdepth 1 -print0)
Так перенаправить результат выполнения команды нельзя. Оператор < связывает поток ввода с указанным файловым дескриптором. Но при подстановке команды никакого дескриптора нет. Bash вызывает утилиту find и подставляет её вывод вместо $(...). При подстановке процессов вывод find запишется во временный файл. У него есть дескриптор. Поэтому перенаправление потоков сработает.
У подстановки процессов есть одна проблема. Эта подстановка не входит в POSIX-стандарт. Если вам важно следовать стандарту, используйте конвейер. Листинг 3-29 демонстрирует такое решение.
1 #!/bin/bash
2
3 find . -maxdepth 1 -print0 |
4 while IFS= read -r -d '' filename
5 do
6 file "$filename"
7 done
Комбинация цикла while и утилиты find предпочтительнее for в одном случае: если вы обрабатываете файлы и условие их поиска сложное.
При комбинации while и find всегда используйте NUL-символ в качестве разделителя. Так вы избежите проблем обработки имён файлов с пробелами.
Вторая форма for
Во второй форме оператора for условием цикла выступает арифметическое выражение. Разберёмся, в каких случаях оно понадобится. Рассмотрим примеры.
Предположим, нам нужен скрипт для расчёта факториала. Решение задачи зависит от способа ввода данных. Первый вариант — число для расчёта известно заранее. Тогда подойдёт первая форма цикла for. Листинг 3-30 демонстрирует такой вариант скрипта.
1 #!/bin/bash
2
3 result=1
4
5 for i in {1..5}
6 do
7 ((result *= $i))
8 done
9
10 echo "Факториал числа 5 равен $result"
Второй вариант — пользователь передаёт число для расчёта через входной параметром скрипта. Для решения такой задачи попробуем следующий вариант условия цикла for:
for i in {1..$1}
Ожидается, что Bash выполнит подстановку фигурных скобок для целых чисел от одного до значения параметра $1. Это не сработает.
Согласно таблице 3-2, подстановка фигурных скобок выполняется до подстановки параметров. Поэтому в условии цикла вместо строки “1 2 3 4 5” получится строка "{1..$1}". Bash не распознал подстановку фигурных скобок, потому что верхняя граница диапазона — не число. Дальше строка "{1..$1}" запишется в переменную i. Из-за этого оператор (( не сможет обработать её корректно.
Утилита seq решит нашу проблему. Она генерирует последовательность целых или дробных чисел.
Таблица 3-21 демонстрирует способы вызова утилиты seq.
| Число параметров | Описание параметров | Пример команды | Результат |
|---|---|---|---|
| 1 | Последнее число в генерируемой последовательности. Последовательность начинается с единицы. | seq 5 |
1 2 3 4 5 |
| 2 | Первое и последнее число в последовательности. | seq -3 3 |
-2 -1 0 1 2 |
| 3 | Первое число, шаг и последнее число в последовательности. | seq 1 2 5 |
1 3 5 |
Числа в выводе утилиты seq разделяются переводом строки \n. Опция -s позволяет указать другой разделитель. Перевод строки входит в список стандартных разделителей переменной IFS. Поэтому в конструкции for опция -s для seq не нужна.
В таблице 3-21 перевод строки заменён на пробел в столбце “Результат” для удобства.
Воспользуемся утилитой seq, чтобы написать параметризуемый скрипт для расчёта факториала. Он приведён в листинге 3-31.
1 #!/bin/bash
2
3 result=1
4
5 for i in $(seq $1)
6 do
7 ((result *= $i))
8 done
9
10 echo "Факториал числа $1 равен $result"
Это решение работает. Однако, его нельзя назвать эффективным. В условии цикла for вызывается внешняя утилита. Такой вызов сравним с запуском обычной программы. Например, калькулятора. Для создания нового процесса ядро ОС выполняет несколько сложных операций. По меркам процессора они занимают значительное время. Поэтому старайтесь обходиться встроенными средствами Bash везде, где это возможно.
Для решения задачи нам пригодится вторая форма оператора for. В общем виде она выглядит так:
1 for (( ВЫРАЖЕНИЕ_1; ВЫРАЖЕНИЕ_2; ВЫРАЖЕНИЕ_3 ))
2 do
3 ДЕЙСТВИЕ
4 done
В однострочном виде эта конструкция записывается так:
for (( ВЫРАЖЕНИЕ_1; ВЫРАЖЕНИЕ_2; ВЫРАЖЕНИЕ_3 )); do ДЕЙСТВИЕ; done
Цикл for с арифметическим условием работает так:
- ВЫРАЖЕНИЕ_1 выполняется однократно перед первой итерацией цикла.
- Цикл выполняется до тех пор, пока ВЫРАЖЕНИЕ_2 остаётся истинным. Как только оно вернуло ложь в качестве результата, цикл завершается.
- В конце каждой итерации выполняется ВЫРАЖЕНИЕ_3.
Заменим вызов утилиты seq на арифметическое выражение в листинге 3-31. Результат приведён в листинге 3-32.
1 #!/bin/bash
2
3 result=1
4
5 for (( i = 1; i <= $1; ++i ))
6 do
7 ((result *= i))
8 done
9
10 echo "Факториал числа $1 равен $result"
Скрипт стал работать быстрее. Теперь он использует только встроенные операторы Bash. Для их исполнения не нужно создавать новые процессы.
Рассмотрим алгоритм конструкции for в скрипте:
- Перед первой итерацией цикла объявляется переменная
i. Это счётчик цикла. Ему присваивается единица. - Счётчик цикла сравнивается с входным параметром: “i <= $1”. Если условие выполняется, возвращается нулевой код возврата.
- Если условие вернуло ноль, выполняется первая итерация цикла. В противном случае цикл завершается.
- В теле цикла вычисляется арифметическое выражение “result *= i”. В результате значение переменной
resultбудет умножено наi. - После выполнения первой итерации, вычисляется третье выражение
++iв условии цикла. В результате значение переменнойiстанет равно двум. - Переход ко второму шагу алгоритма с проверкой условия “i <= $1”. Если условие по-прежнему истинно, выполняется следующая итерация цикла.
В цикле мы используем префиксную форму инкремента. Она выполняется быстрее, чем постфиксная.
Используйте вторую форму оператора for, если счётчик цикла рассчитывается по формуле. Других эффективных решений в этом случае нет.
Управление циклом
Цикл завершается согласно своему условию. Кроме условия есть дополнительные средства для управления циклом. Они позволяют прервать его выполнение или пропустить текущую итерацию. Рассмотрим их подробнее.
break
Встроенная команда break немедленно прекращает выполнение цикла. Она полезна для обработки ошибок или выхода из бесконечного цикла.
Для примера напишем скрипт. Он ищет элемент индексируемого массива с определённым значением. Как только элемент найден, нет смысла продолжать цикл. Можно сразу выйти из него. Листинг 3-33 демонстрирует такой скрипт.
1 #!/bin/bash
2
3 array=(Alice Bob Eve Mallory)
4 is_found="0"
5
6 for element in "${array[@]}"
7 do
8 if [[ "$element" == "$1" ]]
9 then
10 is_found="1"
11 break
12 fi
13 done
14
15 if [[ "$is_found" -ne "0" ]]
16 then
17 echo "Элемент со значением $1 есть в массиве"
18 else
19 echo "Элемента со значением $1 нет в массиве"
20 fi
Искомый элемент массива передаётся в скрипт в параметре $1.
Результат поиска хранится в переменной is_found. В конструкции if сравнивается текущий элемент массива и искомый. Если они равны, переменной is_found присваивается единица. Затем выполнение цикла прерывается командой break.
После цикла в операторе if проверяется значение is_found. В зависимости от результата выводится сообщение.
Используйте команду break, чтобы вынести из тела цикла всё лишнее. Чем меньше тело цикла, тем проще его прочитать и понять. Например, в листинге 3-33 можно вывести результат поиска прямо в цикле. Тогда переменная is_found не нужна. С другой стороны обработка найденного элемента может быть сложной. Помещать такую обработку в тело цикла — плохая идея.
Если не имеет смысла выполнять скрипт после завершения цикла, команда break не подойдёт. Вместо неё используйте команду exit. Например, если во входных данных скрипта обнаружилась ошибка. Также exit подойдёт, если результат работы цикла обрабатывается в его теле.
Заменим команду break на exit в листинге 3-33. Результат приведён в листинге 3-34.
1 #!/bin/bash
2
3 array=(Alice Bob Eve Mallory)
4
5 for element in "${array[@]}"
6 do
7 if [[ "$element" == "$1" ]]
8 then
9 echo "Элемент со значением $1 есть в массиве"
10 exit 0
11 fi
12 done
13
14 echo "Элемента со значением $1 нет в массиве"
С помощью команды exit мы обработали результат поиска в теле цикла. В данном случае это сократило наш код и сделало его проще. Но при сложной обработке результата эффект будет обратный.
Скрипты из листингов 3-33 и 3-34 дают одинаковый результат.
continue
Встроенная команда continue прекращает исполнение текущей итерации цикла. При этом цикл не завершится. Он продолжит выполняться со следующей итерации.
Рассмотрим пример. Предположим, что надо рассчитать сумму положительных чисел в массиве. Отрицательные числа нас не интересуют. С помощью конструкции if проверим знак в теле цикла. Если знак положительный — добавим число к результату. Получим скрипт, как в листинге 3-35.
1 #!/bin/bash
2
3 array=(1 25 -5 4 -9 3)
4 sum=0
5
6 for element in "${array[@]}"
7 do
8 if (( 0 < element ))
9 then
10 ((sum += element))
11 fi
12 done
13
14 echo "Сумма положительных чисел равна $sum"
Если element больше нуля, его значение добавляется к результату sum.
Воспользуемся командой continue, чтобы получить такое же поведение. Результат приведён в листинге 3-36.
1 #!/bin/bash
2
3 array=(1 25 -5 4 -9 3)
4 sum=0
5
6 for element in "${array[@]}"
7 do
8 if (( element < 0))
9 then
10 continue
11 fi
12
13 ((sum += element))
14 done
15
16 echo "Сумма положительных чисел равна $sum"
Мы инвертировали условие конструкции if. Теперь оно истинно для отрицательных чисел. В этом случае вызовется команда continue. Она прервёт текущую итерацию цикла. Операция сложения после if не выполнится. Вместо этого начнётся следующая итерация со следующим элементом массива.
На самом деле мы применили технику раннего возврата в контексте цикла. Используйте команду continue, чтобы обработать ошибки. Также она пригодится для условий, когда выполнять тело цикла до конца не имеет смысла. Так вы избежите вложенных конструкций if. В результате код станет понятнее и чище.
Функции
Bash относится к процедурным языкам программирования. Процедурные языки позволяют разделить программу на логические части — подпрограммы. Подпрограмма — это самостоятельный блок кода, который решает конкретную задачу. Подпрограммы вызываются из основной программы.
В современных языках подпрограммы называются функциями. Мы уже сталкивались с ними, когда знакомились с командой declare. Теперь рассмотрим подробнее, как функции устроены и для чего нужны.
Парадигмы программирования
Для начала разберёмся с терминологией. Она поможет понять, зачем вообще нужны функции.
Что такое процедурное программирование? Это одна из парадигм разработки ПО. Парадигма — это набор идей, методов и принципов, которые определяют способ написания программ.
Современные языки следуют одной из двух доминирующих сегодня парадигм:
- Императивное программирование. Разработчик явно указывает, как программе изменять своё состояние. Другими словами он задаёт полный алгоритм вычисления результата.
- Декларативное программирование. Разработчик указывает свойства желаемого результата, но не алгоритм его вычисления.
Bash следует первой парадигме. Это императивный язык.
Императивная и декларативная парадигмы определяют общие принципы написания программы. В рамках одной парадигмы есть различные методологии (подходы). Методология предлагает конкретные приёмы программирования. Так у императивной парадигмы есть две основных методологии:
- Процедурное программирование.
- Объектно-ориентированное программирование.
Эти методологии предлагают по-разному структурировать исходный код программы. Bash следует первой методологии.
Рассмотрим процедурное программирование подробнее. Процедурный язык предоставляет средства для объединения наборов команд в независимые блоки кода. Эти блоки кода называются процедурами или функциями. Функцию можно вызвать из любого места программы. На вход она принимает параметры. Этот механизм похож на передачу параметров командной строки в скрипт. Поэтому функцию иногда называют программой в программе или подпрограммой.
Основная задача функций — управление сложностью программ. Чем больше объём исходного кода, тем сложнее его сопровождать и поддерживать в рабочем состоянии. Ситуацию усугубляют повторяющиеся фрагменты кода. Они разбросаны по всей программе и могут содержать ошибки. После исправления ошибки в одном таком фрагменте, надо найти и исправить все остальные. Если фрагмент вынести в функцию, то достаточно исправить ошибку только в ней.
Рассмотрим пример повторяющегося фрагмента кода. Представьте, что вы пишете большую программу. Чтобы обработать ошибки, программа выводит в поток ошибок текстовые сообщения. Тогда в исходном коде появится много мест с вызовом команды echo. Например, таких:
&2 echo "Произошла ошибка N"
В какой-то момент вы решаете, что лучше записывать все ошибки в файл. Тогда анализировать их станет легче. Пользователи вашей программы могут перенаправить поток ошибок в лог-файл сами. Но, предположим, что не все умеют пользоваться перенаправлением. Поэтому программа должна сама писать сообщения в лог-файл.
Внесём изменение в программу. Для этого нужно пройти по всем местам обработки ошибок. Каждый вызов команды echo надо заменить на следующий:
echo "Произошла ошибка N" >> debug.log
Если по невнимательности пропустить и не исправить какой-то вызов echo, его вывод не попадёт в лог-файл. Этот вывод может оказаться важным. Без него вы не поймёте, почему программа не работает у пользователя.
Мы рассмотрели одну из сложностей сопровождения программ. Она часто встречается при изменении кода, написанного ранее. В нашем примере проблема возникла из-за нарушения принципа разработки “не повторяйся” (don’t repeat yourself или DRY). Один и тот же код вывода ошибок копировался снова и снова в разные места программы. Так делать нельзя.
Функции решают проблему дублирования кода. Чем-то это решение напоминает циклы. Отличие в том, что цикл многократно исполняет набор команд в одном месте программы. В отличие от цикла функция позволяет исполнять одни и те же команды в разных местах программы.
Функция улучшит читаемость кода программы. Она объединяет набор команд в единый блок. Если дать блоку говорящее имя, станет очевидна решаемая им задача. В программе функция вызывается по своему имени. Благодаря этому, программу станет легче читать. Вместо десятка строк тела функции, будет стоять её имя. Оно объяснит читателю, что происходит в функции.
Функции в командном интерпретаторе
Функции доступны в обоих режимах Bash: командный интерпретатор и исполнение скриптов. Начнём с командного интерпретатора.
В общем виде функция объявляется так:
1 ИМЯ_ФУНКЦИИ()
2 {
3 ДЕЙСТВИЕ
4 }
В одну строку функцию можно объявить так:
() { ДЕЙСТВИЕ ; }
Обратите внимание на обязательную точку с запятой перед закрывающей фигурной скобкой }.
Тело функции ДЕЙСТВИЕ может быть одной командой или блоком команд.
На имена функций в Bash накладываются те же ограничения, что и на имена переменных. В них допустимы только символы латинского алфавита, числа и знак подчёркивания _. Имя не должно начинаться с числа.
Рассмотрим, как объявлять и использовать функции в командном интерпретаторе. Предположим, вам нужна статистика использования оперативной памяти. Эта информация доступна через файловую систему proc или procfs. Через proc можно узнать список работающих процессов, состояние ОС и оборудования компьютера. Эта информация доступна через файлы, находящихся по системному пути /proc.
Статистика использования оперативной памяти доступна в файле /proc/meminfo. Прочитаем его с помощью утилиты cat:
Вывод команды зависит от вашей системы. Для окружения MSYS2 он даст меньше информации, для Linux-системы — больше.
Для MSYS2 содержимое файла meminfo будет примерно таким:
1 MemTotal: 6811124 kB
2 MemFree: 3550692 kB
3 HighTotal: 0 kB
4 HighFree: 0 kB
5 LowTotal: 6811124 kB
6 LowFree: 3550692 kB
7 SwapTotal: 1769472 kB
8 SwapFree: 1636168 kB
Таблица 3-22 объясняет значение каждого поля.
| Поле | Значение |
|---|---|
| MemTotal | Объём доступной в системе RAM. |
| MemFree | Объём не используемой в данный момент RAM. Считается как LowFree + HighFree. |
| HighTotal | Объём доступной памяти в области RAM выше 860 мегабайтов. |
| HighFree | Объём не используемой памяти в области RAM выше 860 мегабайтов. |
| LowTotal | Объём доступной памяти в области RAM ниже 860 мегабайтов. |
| LowFree | Объём не используемой памяти в области RAM ниже 860 мегабайтов. |
| SwapTotal | Объём доступной памяти в области подкачки на жёстком диске. |
| SwapFree | Объём не используемой памяти в области подкачки. |
Подробнее значения полей файла meminfo рассматриваются в статье.
Чтобы не набирать команду чтения файла meminfo каждый раз, объявим функцию с коротким именем. Например, так:
() { cat /proc/meminfo; }
Это однострочное объявление функции с именем mem. Её можно вызвать так же, как любую Bash-команду. Например:
Функция выведет статистику использования памяти.
Команда unset удаляет объявленную ранее функцию. Удалим нашу функцию mem следующей командой:
unset mem
Предположим, что переменная и функция объявлены с одинаковыми именами. Чтобы удалить именно функцию, используйте опцию -f команды unset. Например, так:
unset -f mem
Объявление функции можно добавить в файл ~/.bashrc. Тогда функция будет доступна при каждом запуске командной оболочки.
В командной строке мы объявили функцию mem в однострочном формате. Его удобнее и быстрее набирать. В файле ~/.bashrc важна наглядность. Там функцию mem лучше объявить в стандартном виде. Например, так:
1 mem()
2 {
3 cat /proc/meminfo
4 }
Отличие функций от псевдонимов
Мы объявили функцию mem для вывода статистики использования оперативной памяти. То же поведение даст следующий псевдоним:
alias mem="cat /proc/meminfo"
Если функции и псевдонимы работают одинаково, что выбрать?
Функции и псевдонимы похожи в одном — это встроенные механизмы Bash. С точки зрения пользователя они сокращают ввод длинных команд. Но принцип работы этих механизмов принципиально различается.
Псевдоним заменяет один текст на другой во введённой пользователем команде. Другими словами Bash находит в команде текст, который совпадает с именем alias. Затем заменяет этот текст на значение псевдонима и исполняет получившуюся команду.
Предположим, вы определили псевдоним для утилиты cat. Он добавляет опцию -n в вызов утилиты. Благодаря опции, в вывод добавляются номера строк. Псевдоним выглядит так:
alias cat="cat -n"
Теперь каждый раз когда команда начинается со слова “cat”, Bash подставит вместо него “cat -n”. Например, вы вводите команду:
После подстановки псевдонима она выглядит так:
Подстановка заменила только слово “cat” на “cat -n”. Следующий далее путь до файла не изменился.
Теперь рассмотрим, как работают функции. В отличие от псевдонима тело функции не подставляется в команду. Когда Bash встречает имя функции в команде, он исполняет её тело.
Пример. Попробуем с помощью функции получить то же поведение, как у псевдонима для утилиты cat. Если бы функции работали как alias, такое определение решило бы задачу:
() { cat -n; }
Мы ожидаем, что в следующей команде Bash просто добавит опцию -n:
Но это не сработает. Bash не подставляет тело функции в команду. Bash его исполняет и подставляет в команду результат.
В нашем случае утилита cat будет вызвана с опцией -n, но без параметра ~/.bashrc. Это совершенно не то что нужно.
Чтобы решить задачу, передадим имя файла в функцию в качестве параметра. Это работает так же, как передача параметра в команду или скрипт. После вызова функции укажите список параметров, разделённых пробелами.
В общем виде вызов функции и передача в неё параметров выглядит так:
Чтобы прочитать параметры в теле функции, используйте переменные $1, $2, $3 и т.д. Прочитать сразу все параметры можно через переменную $@.
Исправим объявление функции cat. Все её входные параметры передадим в утилиту cat:
() { cat -n $@; }
Такая функция тоже не заработает. Дело в том, что при её выполнении произойдёт рекурсия. Рекурсией называется вызов функции из неё же самой.
Перед выполнением команды “cat -n $@” Bash проверит список объявленных функций. В списке будет функция с именем cat. Её тело выполняется в данный момент, но это не важно. Поэтому вместо вызова утилиты Bash вызовет функцию cat. Этот вызов повторится снова и снова. Возникнет бесконечная рекурсия, которая похожа на бесконечный цикл.
Рекурсия — вовсе не ошибка в поведении интерпретатора. Это мощный механизм, который значительно упрощает сложные алгоритмы (например, обход графа или дерева).
Ошибка в нашем объявлении функции cat. Рекурсивный вызов произошел случайно и привел к зацикливанию. Решить эту проблему можно двумя способами:
- Использовать встроенную команду command.
- Переименовать функцию так, чтобы её имя отличалось от имени утилиты.
Рассмотрим первое решение. В качестве параметров command получает команду. Если в команде встречаются имена псевдонимов и функций, Bash не станет их обрабатывать. Тело псевдонима не подставится. Функция не вызовется.
Применим команду command в объявлении функции cat. Получим следующее:
() { command cat -n "$@"; }
Второе решение — просто переименовать функцию. Такой вариант сработает:
() { cat -n "$@"; }
Всегда помните о проблеме случайной рекурсии. Не давайте функциям имена, совпадающие с именами команд интерпретатора и GNU-утилит.
Подведём итоги сравнения функций и псевдонимов в командном интерпретаторе. Если нужно просто сократить длинную команду, используйте alias.
Функция нужна только в следующих случаях:
- Для выполнения действия нужны условные операторы, циклы или блок команд.
- Параметры команды находятся не в конце.
Рассмотрим пример второго случая — команду, которую нельзя заменить псевдонимом. Сократим вызов утилиты find для поиска файлов в указанном каталоге. Поиск в домашнем каталоге выглядит так:
С помощью псевдонима для этой команды параметризовать путь не получится. Следующий вариант не заработает:
alias="find -type f"
Проблема в том, что путь должен идти до опции -type.
Заменим псевдоним на функцию. В её теле можно выбрать позицию для подстановки параметра в вызов find. Например, так:
() { find $1 -type f; }
Функции в скриптах
В скриптах функции объявляются точно так же, как в командном интерпретаторе. Допускаются оба варианта объявления: стандартный и однострочный.
Для примера вернёмся к проблеме обработки ошибок в большой программе. Объявим следующую функцию для вывода сообщений об ошибках:
1 print_error()
2 {
3 >&2 echo "Произошла ошибка: $@"
4 }
Текст, объясняющий причину ошибки, передаётся в функцию через параметр. Допустим, наша программа читает файл на диске. Но файл оказался недоступен. Тогда сообщить о проблеме можно так:
"файл readme.txt не найден"
Предположим, что требования к программе изменились. Теперь сообщения об ошибках нужно выводить в лог-файл. Для этого достаточно исправить объявление функции print_error. Команда echo изменится на следующую:
1 print_error()
2 {
3 echo "Произошла ошибка: $@" >> debug.log
4 }
После изменения функции все сообщения об ошибках выводятся в файл debug.log. Менять что-либо в местах вызова функции не нужно.
Встречаются ситуация, когда одна функция должна вызвать другую. Это допустимо в Bash. В общем случае функцию можно вызвать из любого места программы.
Рассмотрим пример. Предположим, интерфейс программы надо перевести на другой язык. Такая процедура называется локализацией. Сообщения об ошибках лучше выводить на понятном пользователю языке. Для этого продублируем текст всех сообщений на всех языках, поддерживаемых программой. Как это сделать?
Самое простое решение — присвоить каждой ошибке уникальный код. Такая практика часто встречается в системном программировании. Применим этот подход в нашей программе. Тогда функция print_error в качестве параметра будет принимать код ошибки.
Код ошибки можно выводить прямо в лог-файл. Но тогда пользователю понадобится информация о значениях кодов. Удобнее выводить текст сообщения, как и раньше. Для этого код ошибки надо конвертировать в текст на нужном языке. Для этой задачи объявим специальную функцию.
Напишем функцию для конвертирования кода ошибки в сообщение. Для конвертирования применим конструкцию case. Каждый блок case соответствует определённому коду ошибки. Объявление функции выглядит так:
1 code_to_error()
2 {
3 case $1 in
4 1)
5 echo "Не найден файл"
6 ;;
7 2)
8 echo "Нет прав для чтения файла"
9 ;;
10 esac
11 }
Теперь перепишем объявление функции print_error так:
1 print_error()
2 {
3 echo "$(code_to_error $1) $2" >> debug.log
4 }
Вызов функции print_error выглядит, например, так:
1 "readme.txt"
В результате вызова в лог-файл запишется строка:
Первым параметром в функцию передаётся код ошибки. Вторым параметром — имя файла, который привёл к проблеме.
Сопровождать механизм вывода сообщений об ошибках в нашей программе стало проще. Предположим, надо добавить вывод ошибок на другом языке. Для этого достаточно объявить две функции:
-
code_to_error_ruдля сообщений на русском. -
code_to_error_enдля сообщений на английском.
Чтобы выбрать правильную функцию, можно проверить значение переменной LANGUAGE в функции print_error.
Наше решение с конвертированием кода ошибок — это учебный пример. Для локализации скриптов у Bash есть специальный механизм. В нём используются PO-файлы с текстами на разных языках. Подробнее об этом механизме читайте в статье BashFAQ.
Возврат результата функции
Чтобы вернуть результат функции, процедурные языки имеют встроенную команду. Обычно она называется return. В Bash эта команда тоже есть. Но её поведение отличается. Команда return в Bash не возвращает значение. Она передаёт код возврата, то есть целое число от 0 до 255.
Полный алгоритм вызова и выполнения функции выглядит так:
- При выполнении команды встречается имя функции.
- Интерпретатор переходит в тело функции и исполняет его с первой команды.
- Если в теле функции встречается команда return, выполнение функции прекращается. Bash переходит в место её вызова. В специальный параметр
$?записывается код возврата функции. Это параметр команды return. - Если в теле функции нет return, Bash выполняет его до последней команды. После этого интерпретатор переходит в место вызова функции.
В других процедурных языках команда return возвращает переменную любого типа: число, строку или массив. Такое же поведение можно получить и в Bash. Для этого есть три способа:
- Подстановка команд.
- Глобальная переменная.
- Вызывающая сторона указывает глобальную переменную.
Рассмотрим пример каждого из трёх способов.
В прошлом разделе мы написали функции code_to_error и print_error для вывода сообщений об ошибках. Они выглядят так:
1 code_to_error()
2 {
3 case $1 in
4 1)
5 echo "Не найден файл"
6 ;;
7 2)
8 echo "Нет прав для чтения файла"
9 ;;
10 esac
11 }
12
13 print_error()
14 {
15 echo "$(code_to_error $1) $2" >> debug.log
16 }
Здесь работает первый способ возврата значения. Вызов функции code_to_error помещается в подстановку команды. Благодаря этому, Bash подставит в место вызова функции всё, что она выведет на консоль.
В нашем примере функция code_to_error выводит сообщение об ошибке через команду echo. Далее Bash подставляет этот вывод в тело функции print_error. В результате получается команда echo, состоящая из двух частей:
- Вывод функции
code_to_error. Это сообщение об ошибке. - Входной параметр
$2функцииprint_error. Это имя файла, доступ к которому вызвал ошибку.
Составная команда в функции print_error выводит полное сообщение об ошибке в лог-файл.
Второй способ вернуть значение из функции — записать его в глобальную переменную. Такая переменная доступна в любом месте скрипта. То есть и в теле функции, и в месте её вызова.
Перепишем функции code_to_error и print_error. Сохраним результат code_to_error в глобальной переменной. Затем прочитаем эту переменную в функции print_error. Получится следующее:
1 code_to_error()
2 {
3 case $1 in
4 1)
5 error_text="Не найден файл"
6 ;;
7 2)
8 error_text="Нет прав для чтения файла"
9 ;;
10 esac
11 }
12
13 print_error()
14 {
15 code_to_error $1
16 echo "$error_text $2" >> debug.log
17 }
Результат функции code_to_error записывается в переменную error_text. Затем значения параметра $2 и error_text подставляются в команду echo в функции print_error. Так получается сообщение для вывода в лог-файл.
Возвращать значение из функции через глобальную переменную опасно. Это чревато конфликтом имён. Для примера предположим, что в скрипте есть другая переменная error_text. Она никак не связана с выводом в лог-файл. Тогда любой вызов функции code_to_error перезапишет значение этой переменной. Это приведёт к ошибкам во всех местах использования error_text вне функции.
Решить проблему конфликта имён поможет соглашение об именовании переменных. Такое соглашение — это один из пунктов стандарта оформления кода (coding style). Любой крупный программный проект должен иметь такой стандарт.
Вот пример соглашения об именовании переменных:
Все глобальные переменные, через которые функции возвращают значения, имеют префикс знак подчёркивания _.
Будем следовать этому соглашению. Тогда переменная для возврата значения из функции code_to_error должна называться _error_text. Проблема решится, но лишь отчасти. Предположим, одна функция вызывает другую (вложенный вызов). Случайно они возвращают свои значения через переменные с одинаковыми именами. Это приведёт к ошибке.
Третий способ возврата значения из функции решает проблему конфликта имён. Вызывающая сторона задаёт имя глобальной переменной. Функция записывает свой результат в переменную с этим именем.
Как работает передача имени переменной в функцию? Имя передаётся через параметр функции, как и любое другое значение. Дальше, функция использует команду eval. Эта команда конвертирует текст в Bash-команду. Имя переменной хранится в виде текста. Поэтому без eval обратиться к переменной не получится.
Перепишем функцию code_to_error. Вместо одного параметра будем передавать в неё два:
- Код ошибки в
$1. - Имя глобальной переменной для возврата значения в
$2.
Получится такой код:
1 code_to_error()
2 {
3 local _result_variable=$2
4
5 case $1 in
6 1)
7 eval $_result_variable="'Не найден файл'"
8 ;;
9 2)
10 eval $_result_variable="'Нет прав для чтения файла'"
11 ;;
12 esac
13 }
14
15 print_error()
16 {
17 code_to_error $1 "error_text"
18 echo "$error_text $2" >> debug.log
19 }
На первый взгляд код мало отличается от предыдущего варианта. Но это не так. Мы получили дополнительную гибкость поведения. Теперь вызывающая сторона выбирает имя глобальной переменной для возврата значения. Это имя явно указывается в коде вызова. Поэтому обнаружить конфликт и решить его стало проще.
Область видимости переменных
Конфликт имён — это серьёзная проблема. Она возникает в Bash, когда функции объявляют переменные в глобальном пространстве имён. В результате имена двух переменных могу совпасть. Тогда к ним обращаются разные функции в разные моменты времени. Это приводит к путанице и потере данных.
Чтобы решить конфликт имён в Bash, ограничивайте область видимости переменных. Рассмотрим этот механизм подробнее.
Если объявить переменную с ключевым словом local, её область видимости ограничится телом функции. Другими словами, переменная будет доступна только в теле функции.
Наш последний вариант функции code_to_error выглядит так:
1 code_to_error()
2 {
3 local _result_variable=$2
4
5 case $1 in
6 1)
7 eval $_result_variable="'Не найден файл'"
8 ;;
9 2)
10 eval $_result_variable="'Нет прав для чтения файла'"
11 ;;
12 esac
13 }
Здесь переменная _result_variable объявлена как локальная. Это значит, что она доступна для чтения и записи только в теле code_to_error и любых вызываемых ею функциях.
В Bash область видимости локальной переменной ограничена временем исполнения функции, в которой она объявлена. Такая область видимости называется динамической. В современных языках чаще встречается лексическая область видимости. При этом подходе переменная доступна только в теле функции, но не за его пределами (например, в вызываемых функциях).
Локальные переменные не попадают в глобальную область видимости. Это гарантирует, что никакая функция не перезапишет их случайно.
1 #!/bin/bash
2
3 bar()
4 {
5 echo "bar1: var = $var"
6 var="bar_value"
7 echo "bar2: var = $var"
8 }
9
10 foo()
11 {
12 local var="foo_value"
13
14 echo "foo1: var = $var"
15 bar
16 echo "foo2: var = $var"
17 }
18
19 echo "main1: var = $var"
20 foo
21 echo "main2: var = $var"
Неосторожное обращение с локальными переменными приводит к ошибкам. Проблема в том, что локальная переменная скрывает глобальную с тем же именем. Рассмотрим пример.
Предположим, вы пишете функцию для обработки файла. Например, она с помощью утилиты grep ищет шаблон в файле. Функция выглядит так:
1 check_license()
2 {
3 local filename="$1"
4 grep "General Public License" "$filename"
5 }
Теперь допустим, что в начале скрипта объявлена глобальная переменная с именем filename. Например:
1 #!/bin/bash
2
3 filename="$1"
Выполнится ли функция check_license корректно? Да выполнится, благодаря сокрытию глобальной переменной. Сокрытие работает так. При обращении к имени filename в теле функции Bash подставит локальную переменную, а не глобальную. Это происходит потому, что локальная переменная объявлена позже глобальной. Из-за сокрытия в теле функции нельзя получить доступ к глобальной переменной filename.
Случайное сокрытие переменных приводит к ошибкам. Старайтесь исключить саму возможность такой ситуации. Для этого добавляйте префикс или постфикс для имён локальных переменных. Например, символ подчёркивания в конец имени.
Глобальная переменная становится недоступна в теле функции только после объявления локальной переменной с тем же именем. Рассмотрим следующий вариант функции check_license:
1 #!/bin/bash
2
3 filename="$1"
4
5 check_license()
6 {
7 local filename="$filename"
8 grep "General Public License" "$filename"
9 }
Здесь локальная переменная filename инициализируется значением глобальной переменной с тем же именем. Причина в том, что подстановка переменных выполняется до операции присваивания. То есть в момент присваивания подставляется значение параметра скрипта $1. Например, если в скрипт передать имя файла README, то присваивание выглядит так:
local filename="README"
В Bash начиная с версии 4.2 изменилось ограничение области видимости массивов. Если объявить индексируемый или ассоциативный массив в функции, он по умолчанию попадёт в локальную область видимости. Чтобы объявить массив глобальным, используйте опцию -g команды declare.
Вот пример объявления локального массива files:
1 check_license()
2 {
3 declare files=(Documents/*.txt)
4 grep "General Public License" "$files"
5 }
В следующем примере массив files попадёт в глобальную область видимости:
1 check_license()
2 {
3 declare -g files=(Documents/*.txt)
4 grep "General Public License" "$files"
5 }
Мы познакомились с функциями в Bash. Вот общие рекомендации по их использованию:
- Тщательно выбирайте имена для функций. Каждое имя сообщает читателю кода, что делает функция.
- В функциях объявляйте только локальные переменные. Используйте соглашение об их именовании. Так вы решите конфликт имён локальных и глобальных переменных.
- Не используйте глобальные переменные в функциях. Вместо этого передавайте значение глобальной переменной в функцию через параметр.
- Не используйте ключевое слово function при объявлении функций. Оно есть в Bash, но отсутствует в POSIX-стандарте.
Рассмотрим подробнее последний совет. Следующий вариант объявления функции не рекомендуется:
1 function check_license()
2 {
3 declare files=(Documents/*.txt)
4 grep "General Public License" "$files"
5 }
Ключевое слово function полезно только в одном случае. Оно решает конфликт между именем функции и псевдонимом (alias).
Например, следующее объявление функции не заработает без слова function:
1 alias check_license="grep 'General Public License'"
2
3 function check_license()
4 {
5 declare files=(Documents/*.txt)
6 grep "General Public License" "$files"
7 }
После такого объявления функцию можно вызвать, если поставить перед ней слэш . Например, так:
\check_license
Без слэша Bash подставит значение псевдонима:
В скриптах имена псевдонимов и функций конфликтуют редко. Каждый скрипт запускается в новом процессе Bash. В нём нет пользовательских alias из файла .bashrc. Конфликт имён может произойти по ошибке в режиме командного интерпретатора.