Командный интерпретатор Bash
Программирование — это прикладной навык. Чтобы его освоить, выберите язык программирования и начните решать на нём задачи. Только так вы научитесь программировать.
В этой книге мы будем писать на Bash. Он удобен для автоматизации задач администрирования компьютера. Вот несколько примеров таких задач:
- Создать резервную копию данных.
- Копировать и удалять каталоги и файлы.
- Запустить программу и передать в неё данные.
Bash появился в ОС Unix. Он несёт на себе отпечаток Unix-философии. Bash также доступен для ОС Windows и macOS.
Инструменты для разработки
Для запуска примеров из этой главы вам понадобится интерпретатор Bash и эмулятор терминала. Их можно установить на все современные ОС. Рассмотрим, как это сделать.
Интерпретатор Bash
Bash — это скриптовый язык программирования. Такие языки имеют следующие отличительные черты:
- Они интерпретируются, а не компилируются.
- Оперируют готовыми программами или высокоуровневыми командами.
- Интегрированы в командную оболочку или ОС.
Язык Bash является частью ОС Linux и macOS. В них он выполняет роль командной оболочки (shell).
Если вы используете Windows, вам нужно установить минимальное Unix-окружение. Без него Bash не сможет корректно работать. Рассмотрим два способа установки такого окружения.
Первый вариант — установить набор инструментов MinGW. Помимо интерпретатора Bash он предоставляет свободный набор компиляторов GCC. Для примеров этой книги будет достаточно компонента MinGW под названием MSYS (Minimal SYStem). Этот компонент включает: интерпретатор Bash, эмулятор терминала и утилиты командной строки GNU. Вместе они составляют минимальное Unix-окружение.
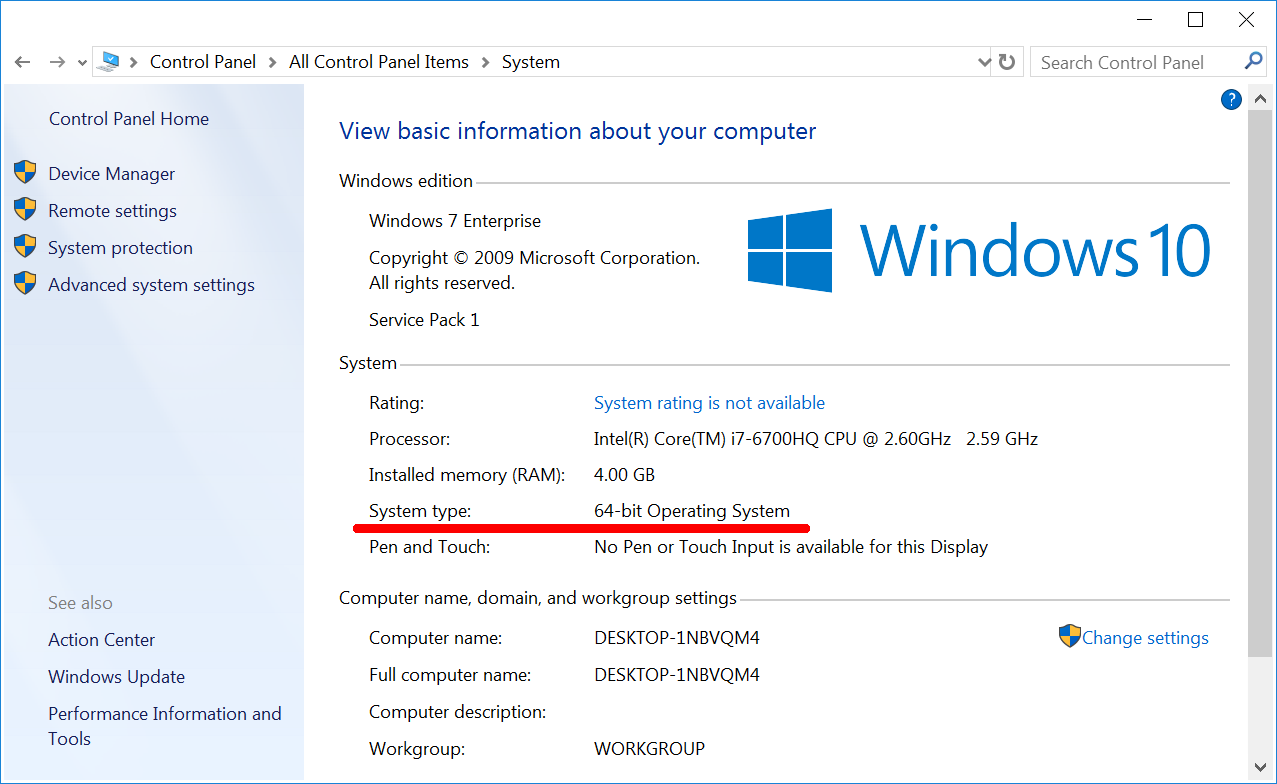
Перед установкой новых программ проверьте разрядность вашей ОС Windows. Для этого выполните следующее:
- Если на вашем рабочем столе есть иконка “Компьютер”, нажмите на неё правой кнопкой мыши и выберите пункт “Свойства”.
- Если на рабочем столе нет иконки “Компьютер”, нажмите кнопку “Пуск”. Найдите в открывшемся меню пункт “Компьютер”. Нажмите на него правой кнопкой мыши и выберите “Свойства”.
- В открывшемся окне “Система” найдите пункт “Тип системы” как на иллюстрации 2-1. В этом окне указана разрядность вашей ОС Windows.
Теперь установим Unix-окружение под названием MSYS2. Скачайте программу установщик MSYS2 с официального сайта. Файл установщика зависит от разрядности вашей ОС:
-
msys2-i686-20190524.exeдля 32-разрядной Windows. -
msys2-x86_64-20190524.exeдля 64-разрядной Windows.
Число 20190524 в имени файла означает дату сборки. В нашем случае это 24 мая 2019 года. Выберите самую новую из доступных версий.
Теперь установим MSYS2. Для этого выполните следующее:
1. Запустите программу установщик. Откроется окно, как на иллюстрации 2-2.
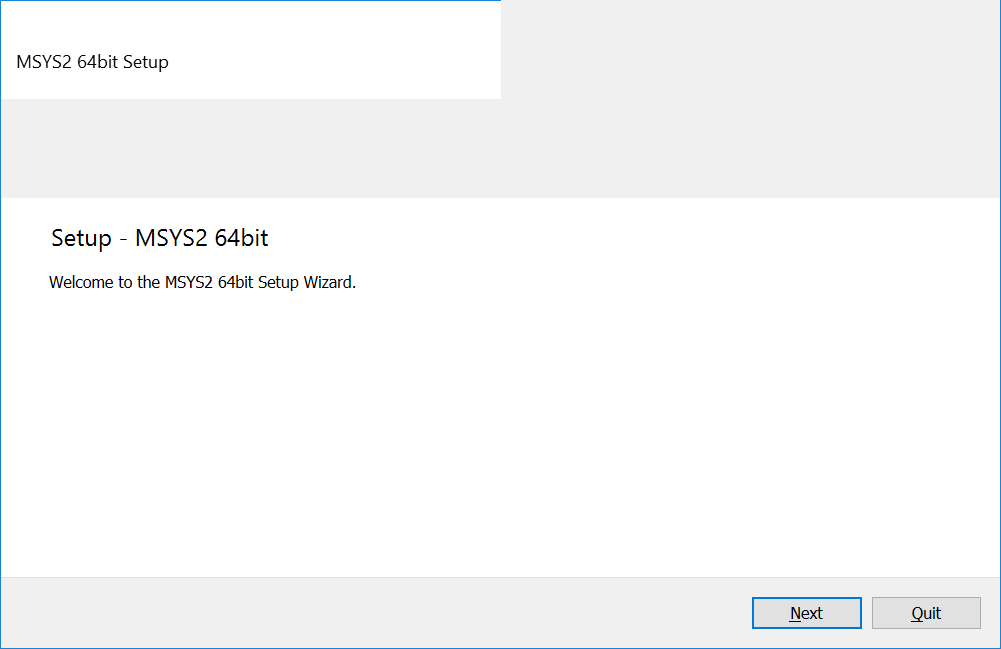
- Нажмите кнопку “Next” (далее). Откроется окно как на иллюстрации 2-3.
- Выберите путь установки и нажмите кнопку “Next”.
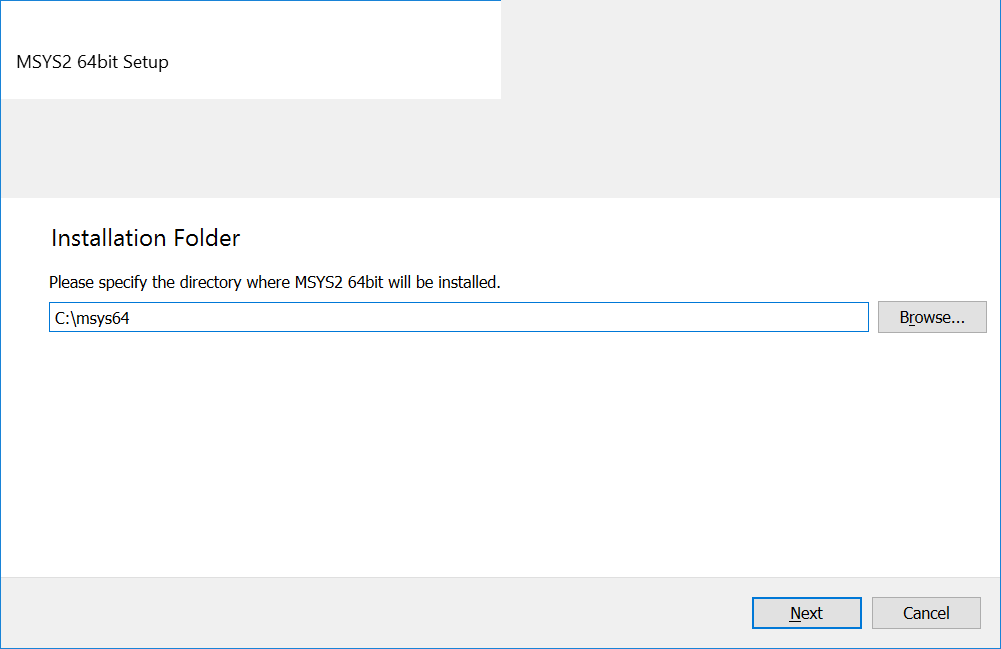
- Следующее окно предлагает выбрать имя приложения для меню “Пуск”. Оставьте его без изменений и нажмите “Next”. После этого начнётся процесс установки.
- После завершения установки нажмите кнопку “Finish” (завершить). Окно закроется.
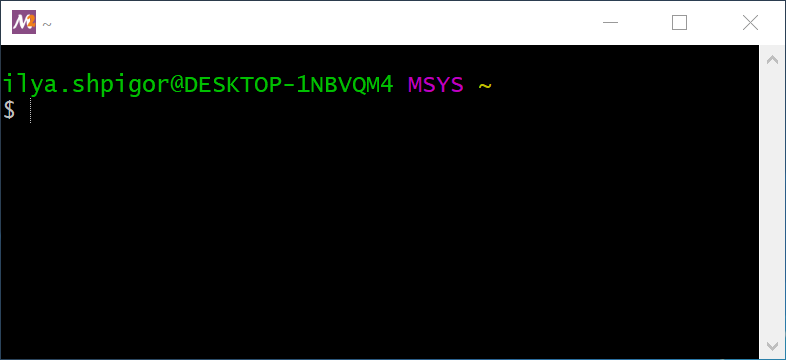
Unix-окружение MSYS2 установлено на ваш жёсткий диск. Его файлы находятся в каталоге C:\msys64, если вы оставили путь установки по умолчанию. Перейдите в этот каталог и запустите файл msys2.exe. Откроется окно с интерпретатором командной строки Bash как на иллюстрации 2-4.
Второй вариант — установить Unix-окружение от Microsoft под названием Windows-подсистема для Linux (Windows subsystem for Linux или WSL). Это окружение доступно только для Windows 10. Оно не заработает на Windows 8 и 7. Инструкция установки WSL доступна на сайте Microsoft.
Пользователям Linux и macOS не надо устанавливать Bash. Он входит в состав этих систем.
Чтобы открыть окно с интерпретатором Bash в Linux, нажмите комбинацию клавиш Ctrl+Alt+T.
Для запуска Bash в macOS сделайте следующее:
- Запустите программу поиска Spotlight. Для этого нажмите на иконку лупы в правом верхнем углу экрана.
- Появится диалог. Введите в нём текст “Terminal”.
- В открывшемся списке приложений щёлкните мышью на первой строчке с именем “Terminal”.
Эмулятор терминала
Командный интерпретатор Bash не похож на обычное Windows-приложение. У него даже нет собственного окна. Когда вы запускаете файл msys2.exe, открывается окно эмулятора терминала.
Эмулятор — это программа, которая имитирует поведение другой программы, ОС или устройства. Эмуляторы нужны для совместимости. Например, вы хотите запустить Windows-программу на Linux. Для этого вам нужен эмулятор Windows-окружения. Один из таких эмуляторов называется Wine. Он предоставляет свою версию системных библиотек Windows. Запущенная на нём Windows-программа будет использовать эти библиотеки.
Эмулятор терминала тоже решает задачу совместимости. Приложения с интерфейсом командной строки предназначены для работы через устройство терминал. Сегодня это устройство не используется. Его вытеснили персональные компьютеры и ноутбуки. Однако, есть много программ, для работы которых нужен терминал. Эмулятор терминала позволяет запускать такие программы на современном оборудовании.
Чтобы передать данные в программу, эмулятор терминала использует командную оболочку. После завершения программы, оболочка передаёт её результаты терминалу. После этого терминал выводит их в своём окне.
Иллюстрация 2-5 демонстрирует взаимодействие устройств ввода-вывода, эмулятора терминала, командной оболочки и программы.
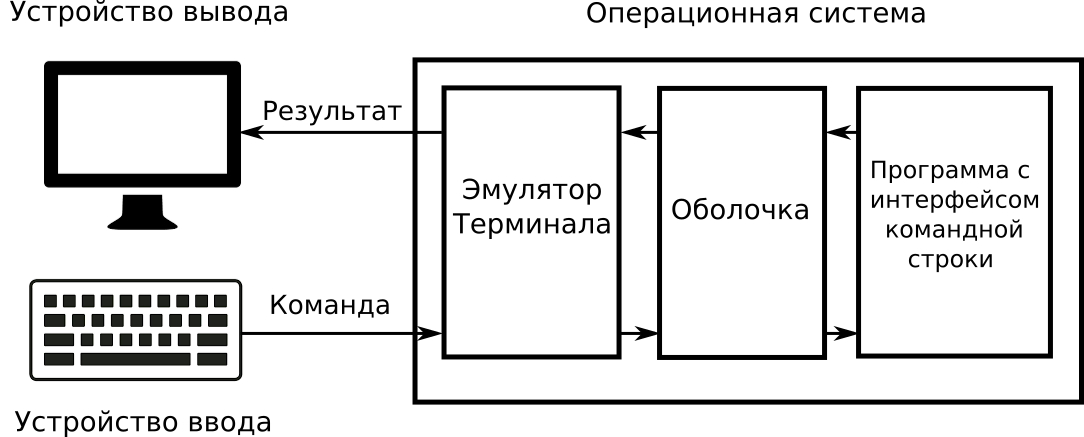
В качестве командной оболочки эмулятор терминала MSYS2 использует Bash.
После запуска Bash выводит следующие две строки как на иллюстрации 2-4:
ilya.shpigor@DESKTOP-1NBVQM4 MSYS ~$Первая строка начинается с имени пользователя. В моём случае это ilya.shpigor. Далее после символа @ указано имя компьютера: DESKTOP-1NBVQM4. Его можно изменить в настройках Windows. Затем через пробел идёт слово MSYS. Это название платформы, на которой запущен Bash. В конце строки стоит символ ~. Это путь до текущего каталога.
Командный интерпретатор
Интерпретаторы работают в двух режимах: не интерактивном и интерактивном. В первом режиме интерпретатор исполняет программу. Программа загружается с диска в оперативную память. Затем она построчно исполняется.
В интерактивном режиме пользователь вводит команды в окне эмулятора терминала. После нажатия клавиши Enter, команда исполняется. Интерпретатор с интерактивным режимом работы называется командной оболочкой (shell).
Командная оболочка часто встраивается в ОС. Она предоставляет доступ к настройкам и функциям ОС. В Linux через оболочку запускаются программы и системные сервисы, управляются периферийные и внутренние устройства, происходят обращения к ядру ОС.
Востребованность
Зачем сегодня изучать интерфейс командной строки (CLI)? Его создавали 40 лет назад для компьютеров, которые в тысячи раз медленнее современных. На ПК и ноутбуках давно доминирует графический интерфейс.
Кажется, что CLI — устаревшая технология, давно отжившая свой век. Это утверждение ошибочно. Не просто так Bash входит во все дистрибутивы macOS и Linux. В Windows тоже есть командный интерпретатор Cmd.exe. В 2006 году компания Microsoft заменила его на новый PowerShell. Задумайтесь над этим фактом. Разработчик самой популярной ОС для ПК создаёт новую командную оболочку. Значит, польза от CLI всё-таки есть.
Какие задачи решает командная оболочка в современных ОС? Прежде всего это инструмент для администрирования системы. В состав ОС кроме ядра входят программные модули: библиотеки, сервисы и утилиты. У них есть настройки и специальные режимы работы. Большинство настроек и режимов не нужны рядовому пользователю. Это дополнительные возможности. Поэтому графический интерфейс не даёт к ним доступа.
Если ОС выходит из строя, дополнительные возможности нужны для её восстановления. Кроме того при сбое системы графический интерфейс часто не работает. Поэтому все утилиты восстановления имеют интерфейс командной строки.
Кроме задач администрирования командный интерфейс нужен для подключения к компьютерам по сети. Для такого подключения есть графические программы: TeamViewer, Remote Desktop и другие. Но они требуют стабильного и быстрого сетевого соединения. Если соединение ненадёжное, эти программы работают медленно и связь постоянно теряется. Командный интерфейс не требователен к качеству соединения. Даже с медленным каналом связи удалённый компьютер получит и исполнит команду.
Знание командного интерфейса полезно не только администраторам, но и рядовым пользователям. С командной оболочкой намного быстрее выполнять ежедневные задачи. Например, следующие:
- Операции над файлами и каталогами.
- Создание резервных копий данных.
- Загрузка файлов из интернета.
- Сбор статистики об использовании ресурсов компьютера.
Рассмотрим пример. Предположим, вы переименовываете файлы на диске. К их именам добавляется один и тот же суффикс. Для десятка файлов это легко сделать через графическое приложение Проводник Windows. Но допустим, что файлов несколько тысяч. Тогда работа через Проводник займёт целый день. С помощью оболочки эта задача решается одной командой за пару секунд.
Пример с переименованием файлов показал сильную сторону CLI — масштабируемость. Масштабируемость в общем смысле означает, что одно и то же решение одинаково хорошо справляется с большим и малым объёмом входных данных. В случае командной оболочки решение — это команда. Она одинаково быстро обрабатывает десять файлов и тысячу.
Знание командного интерфейса пригодится программисту. Разрабатывая сложное приложение, приходится изменять много файлов с исходным кодом. Для работы с ними есть редакторы с графическим интерфейсом. Но иногда одно и то же изменение надо внести в несколько файлов. Например, изменить заголовок с информацией о лицензии. В этом случае работа с редактором неэффективна. Утилиты командной строки решат эту задачу намного быстрее.
Навыки работы с CLI нужны для запуска компиляторов и интерпретаторов. Эти программы, как правило, не имеют графического интерфейса. Они запускаются через командную строку. На вход они принимают имена файлов с исходным кодом. Файлов может быть много, поэтому графический интерфейс плохо подходит для их обработки.
Интегрированные среды разработки (integrated development environment или IDE) компилируют программы через графический интерфейс. На самом деле IDE — это только обёртка над командным интерфейсом компилятора. Он вызывается, когда вы нажимаете кнопку в IDE. Чтобы изменить режим работы компилятора в этом случае, придётся столкнуться с интерфейсом командной строки.
Если вы опытный программист, командная строка поможет вам разработать вспомогательные утилиты. Дело в том, что приложение с текстовым интерфейсом быстрее и проще писать чем аналогичное с GUI. Скорость разработки важна, когда решаются одноразовые задачи.
Допустим, у вас появилась задача. Она решается многократным повторением одного и того же действия. В этом случае посчитайте: сколько времени нужно на ручную работу и сколько на написание утилиты для автоматизации. Писать утилиту с графическим интерфейсом долго. Решить задачу вручную окажется быстрее. Но если выбрать командный интерфейс, автоматизировать задачу станет выгоднее. Так вы сэкономите время и исключите ошибки из-за ручной работы.
Стоит ли изучать интерфейс командной строки, решать вам. Я только привёл примеры из практики, которые говорят о пользе этого навыка. Перейти с графического интерфейса на командную строку тяжело. Придётся заново научиться многим вещам, которые вы привыкли делать через Проводник Windows. Но освоившись с командной оболочкой, вы удивитесь насколько продуктивнее стала ваша работа на компьютере.
Навигация по файловой системе
Знакомство с Unix-окружением и Bash мы начнём с файловой системы (ФС). Файловой системой называется способ хранения и чтения информации с дисков. Сначала рассмотрим отличия структуры каталогов в Unix и Windows. Затем познакомимся с Bash-командами для навигации по файловой системе.
Структура каталогов
В верхней части окна Windows Проводника находится адресная строка. Она выводит абсолютный путь к текущему каталогу. Абсолютным называется путь к одному и тому же объекту файловой системы вне зависимости от текущего каталога.
Другой способ указать место объекта в файловой системе — использовать относительный путь. Он определяет, где находится объект относительно текущего каталога.
Каталог — это объект файловой системы, который может содержать файлы и другие каталоги. Каталоги нужны, чтобы группировать другие объекты. Это облегчает навигацию по файловой системе. В терминологии Windows каталоги называются папками. Оба названия обозначают один и тот же объект файловой системы.
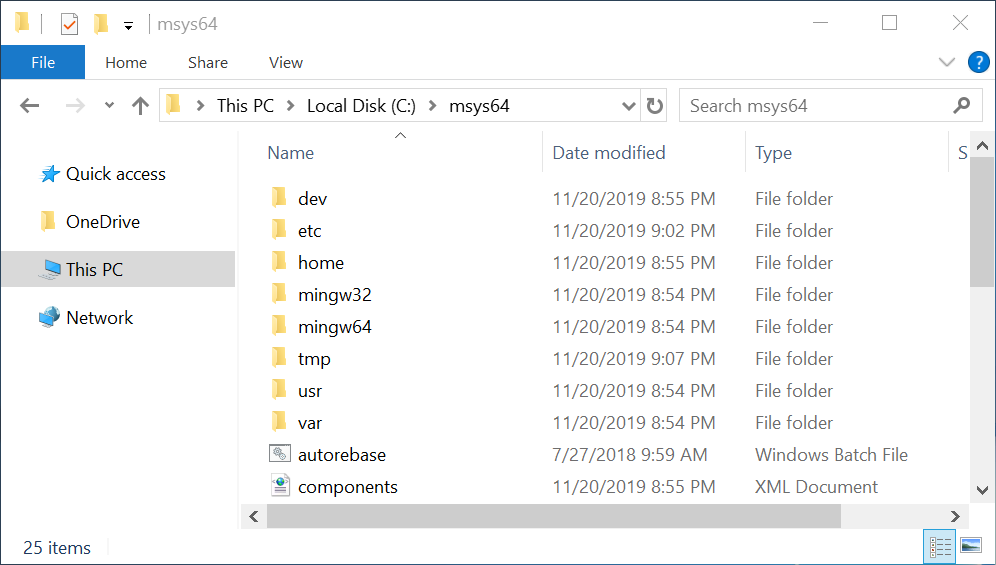
Иллюстрация 2-6 приводит окно Проводника. В нём открыт путь This PC > Local Disk (C:) > msys64. Это каталог msys64 на диске C. Буква C обозначает локальный системный диск. Локальный означает физически подключённый к компьютеру. Системный диск — это тот, на который установлена ОС Windows. Если перевести адресную строку Проводника в абсолютный путь, получим C:\msys64.
В окне терминала выводится текущий абсолютный путь. Это работает так же как адресная строка Проводника. Но пути в терминале и Проводнике различаются. Причина в отличии структуры каталогов Unix-окружения и Windows.
В Windows каждому диску соответствует буква латинского алфавита. Диск открывается через Проводник как обычная папка. Тогда можно работать с его содержимым. Для примера рассмотрим системный диск C. Windows в процессе установки создаёт на нём стандартный набор каталогов:
WindowsProgram FilesProgram Files (x86)UsersPerfLogs
В этих каталогах хранятся компоненты ОС и их временные файлы.
Помимо системного диска к компьютеру можно подключить дополнительные диски. Также можно разделить диск на несколько логических разделов. Windows обозначает дополнительные диски и разделы следующими буквами латинского алфавита: D, E, F и т. д. Структуру каталогов на них задаёт пользователь. Windows не ограничивает и не контролирует эту структуру.
Структуру каталогов Windows определяет файловая система File Allocation Table (FAT). Компания Microsoft разработала её для ОС MS-DOS. Впоследствии принципы работы FAT легли в основу стандарта ECMA-107. Система NTFS сменила устаревшую FAT в современных версиях Windows. Но из-за требований обратной совместимости структура каталогов в NTFS осталась без изменений.
Структуру каталогов Unix определяет стандарт POSIX. Согласно стандарту, в системе есть каталог самого верхнего уровня. Он называется корневым каталогом и обозначается символом слэш /. Каталоги и файлы всех подключенных к компьютеру дисков находятся внутри корневого каталога.
Чтобы получить доступ к содержимому диска, его надо смонтировать. Монтированием называется встраивание содержимого диска в корневой каталог системы. После монтирования содержимое диска становится доступно по какому-то пути. Этот путь называется точкой монтирования. Если перейти в точку монтирования, вы окажетесь в файловой системе диска.
Сравним структуру каталогов Windows и Unix на примере. Предположим, что к компьютеру с Windows подключены два локальных диска C и D. Тогда структура каталогов первого уровня иерархии выглядит так, как в листинге 2-1.
В Unix эта же иерархия каталогов выглядит иначе. Её демонстрирует листинг 2-2.
Запустив терминал MSYS2, вы попадаете в Unix-окружение. В нём Windows-пути не работают. Вместо них используйте Unix-пути. Например, каталог C:\Windows теперь доступен по пути /c/Windows.
В Unix-окружении важен регистр символов. Это значит, что строки Documents и documents не равны. В Windows нет чувствительности к регистру. Поэтому если в адресной строке Проводника написать путь c:\windows, вы перейдёте в системный каталог C:\Windows. В Unix-окружении это не сработает. Все символы надо вводить в правильном регистре.
Кроме регистра символов есть ещё одно отличие. В Unix имена каталогов и файлов в пути разделяет слэш /. В Windows для этого используют обратный слэш .
Команды навигации по файловой системе
Как выполнить команду в эмуляторе терминала? Для этого переключитесь на его окно, наберите текст команды и нажмите клавишу Enter. Оболочка обработает ваш ввод. Когда она готова к вводу, на экран выводится приглашение командной строки. Приглашение — это специальный символ или строка символов. Если приглашения нет, оболочка занята и не может выполнить команду.
На иллюстрации 2-4 в приглашение обозначается символом доллара $.
Для навигации по файловой системе через Проводник Windows, возможны следующие действия:
- Вывести текущий каталог.
- Перейти в указанный каталог.
- Найти каталог или файл на диске.
Эти же действия доступны через интерфейс командной строки. Каждое из них выполняет специальная команда. Эти команды приведены в таблице 2-1.
| Команда | Описание | Примеры |
|---|---|---|
| ls | Вывести на экран содержимое каталога. | ls |
| Если каталог не указан, выводится содержимое текущего. | ls /c/Windows |
|
| pwd | Вывести на экран путь до текущего каталога. | pwd |
Ключ комнды -W выводит путь в структуре каталогов Windows |
pwd -W |
|
| cd | Перейти в каталог по относительному или | cd tmp |
| абсолютному пути. | cd /c/Windows |
|
cd .. |
||
| mount | Смонтировать диск в корневую файловую систему. При запуске без параметров выводит список всех смонтированных дисков. | mount |
| find | Найти файл или каталог. Первый параметр | find . -name vim |
| команды — это каталог, начиная с которого ведётся поиск. Если он не указан, используется текущий каталог. | find /c/Windows -name *vim* |
|
| grep | Найти файл по его содержимому. | grep "PATH" * |
grep -Rn "PATH" . |
||
grep "PATH" * .* |
Следующие команды из таблицы 2-1 Bash выполняет самостоятельно:
- pwd
- cd
Эти команды называются встроенными в интерпретатор. Если Bash не может выполнить команду сам, он ищет подходящую утилиту или программу.
В окружение MSYS2 входит набор GNU-утилит. Это вспомогательные узкоспециализированные программы. Они дают доступ к функциям ОС. Также через них пользователь работает с файловой системой. Следующие команды из таблицы 2-1 выполняются GNU-утилитами:
- ls
- mount
- find
- grep
Часто различий между командами и утилитами не делают. Любой текст после приглашения командной строки называют командой.
pwd
Рассмотрим команды из таблицы 2-1. Мы только что запустили терминал. Первым делом узнаем текущий каталог. Терминал MSYS2 выводит его перед приглашением $. Этот вывод зависит от конфигурации терминала. Если вы работаете на ОС Linux или macOS, текущий каталог не выводится без дополнительной настройки.
После запуска терминала MSYS2 откроется домашний каталог текущего пользователя. Для сокращения он обозначается символом тильда . Этот символ вы видите перед приглашением командной строки. С сокращением можно работать так же, как с любым абсолютным путём.
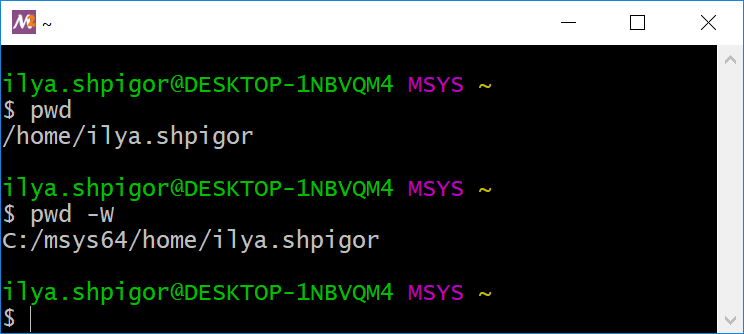
Чтобы вывести текущий каталог, выполните встроенную команду интерпретатора pwd. Иллюстрация 2-7 демонстрирует результат её выполнения. Команда вывела абсолютный путь до домашнего каталога пользователя: /home/ilya.shpigor.
Если к вызову pwd добавить опцию -W, команда выведет путь в структуре каталогов Windows. Это полезно, если вы создали файл в окружении MSYS2 и собираетесь открыть его в Windows-приложении. Результат вывода pwd с опцией -W приведён на иллюстрации 2-7.
Что такое опция команды? Если у приложения только текстовый интерфейс, способы взаимодействия с ним ограничены. При этом ему нужны входные данные для работы. Например, путь до файла или каталога. Командный интерпретатор предлагает простой способ передать эту информацию. Она указывается через пробел после команды запуска приложения. Параметром или аргументом программы называются слово или символ, которые передаются ей на вход. Опцией или ключом называется аргумент, который переключает режим работы программы. Формат опций стандартизован. Обычно они начинаются с тире - или двойного тире –.
Встроенные команды интерпретатора вызываются так же как и программы. У них тоже есть параметры и опции.
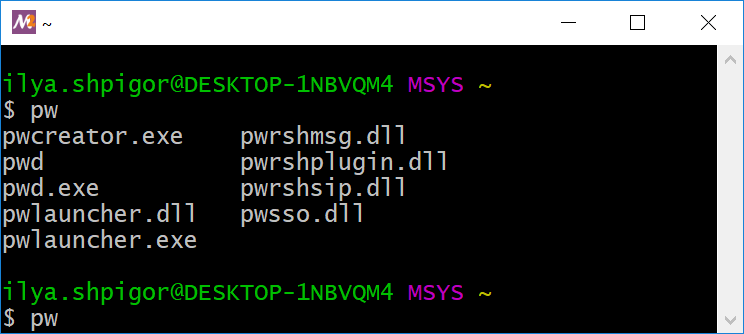
Набирать длинные команды неудобно. Поэтому в Bash есть функция автодополнения. Она вызывается по нажатию клавиши Tab. Наберите первые буквы команды и нажимаете Tab. Если Bash сможет найти команду по первым буквам, он допишет её за вас. Если несколько команд начинаются одинаково, автодополнение не произойдёт. В этом случае нажмите Tab повторно. Bash выведет список всех доступных команд.
Иллюстрация 2-8 демонстрирует список доступных команд. Bash вывел его после ввода текста pw и двойного нажатия Tab.
pwls
Мы узнали текущий каталог. Теперь выведем его содержимое. Для этого есть утилита ls. Предположим, вы только что установили окружение MSYS2. Вызовите ls без параметров в домашнем каталоге пользователя. Утилита ничего не выведет. Этот результат демонстрирует вторая строчка на иллюстрации 2-9. Обычно это означает, что каталог пуст.
В Windows есть понятие скрытых файлов и каталогов. Они есть и в Unix-окружении. Такие файлы создают приложения и ОС для своих нужд. Например, в них хранится конфигурация или временная информация. В обычном режиме работы Проводник Windows их не отображает. Чтобы увидеть скрытые файлы, измените настройки Проводника.
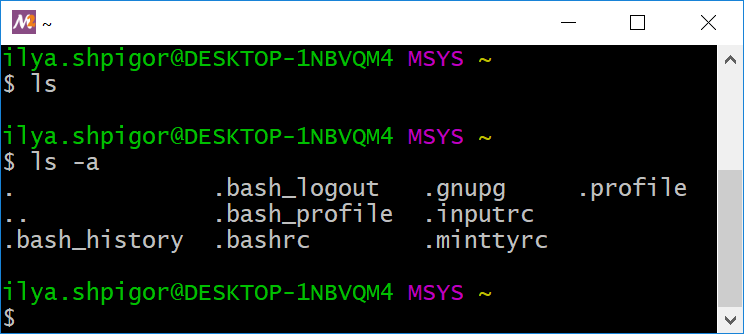
В Unix-окружении имена скрытых файлов и каталогов начинаются с точки. Утилита ls их не отображает по умолчанию. Чтобы изменить это поведение, запустите утилиту с опцией -a. Тогда в домашнем каталоге вы увидите восемь файлов. Все они начинаются с точки, как на иллюстрации 2-9.
Утилита ls может вывести содержимое каталога без перехода в него. Для этого передайте в неё абсолютный или относительный путь до каталога. Иллюстрация 2-10 демонстрирует вывод команды “ls /”. Это содержимое корневого каталога.
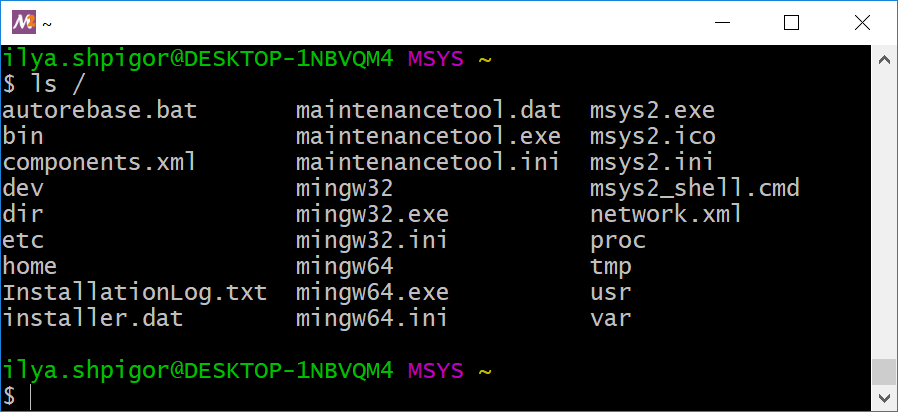
Обратите внимание, что в выводе команды “ls /” нет каталогов /c и /d. Согласно листингу 2-2, это точки монтирования дисков C и D. Они находятся в корневом каталоге. Почему их не выводит ls? Проблема в том, что в файловой системе Windows нет понятия точек монтирования. Поэтому в ней нет каталогов /c и /d. Они создаются только в Unix-окружении. Через эти каталоги вы получаете доступ к содержимому дисков. Утилита ls читает содержимое каталогов в файловой системе Windows. Поэтому точки монтирования она не отображает. В Linux и macOS такой проблемы нет. Там ls корректно выводит все точки монтирования.
mount
Если к компьютеру подключено несколько дисков, полезно вывести на экран их точки монтирования. Это делает утилита mount. Запустите её без параметров. Она выведет список точек монтирования как на иллюстрации 2-11.
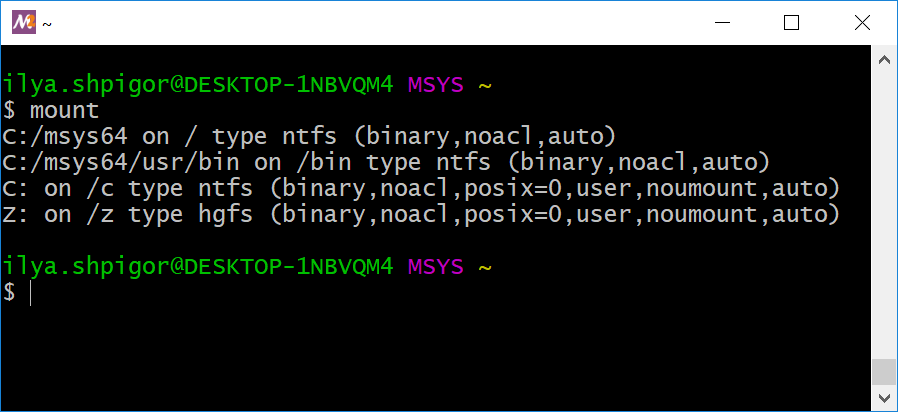
Рассматривайте этот вывод как таблицу, состоящую из четырёх столбцов. Их значения следующие:
- Диск, его раздел или каталог. Это то, что монтируется в корневую файловую систему.
- Точка монтирования. Это путь, по которому доступен смонтированный диск.
- Тип файловой системы диска.
- Параметры монтирования. Например, права доступа к диску.
Таблица 2-2 демонстрирует вывод утилиты mount с иллюстрации 2-11. Вывод разделён на столбцы.
| Монтируемый раздел | Точка монтирования | Тип ФС | Параметры монтирования |
|---|---|---|---|
C:/msys64 |
/ |
ntfs |
binary,noacl,auto |
C:/msys64/usr/bin |
/bin |
ntfs |
binary,noacl,auto |
C: |
/c |
ntfs |
binary,noacl,posix=0,user,noumount,auto |
Z: |
/z |
hgfs |
binary,noacl,posix=0,user,noumount,auto |
Таблица 2-2 вызовет недоумение у Windows-пользователей. В качестве корневого каталога в Unix-окружении монтируется каталог C:/msys64. Далее в него монтируются диски C и Z по путям /c и /z. С точки зрения Unix-окружения диск C находится по пути C:/msys64/c. Но в файловой системе Windows зависимость обратная. Там C:/msys64 — это подкаталог диска C.
В Unix-окружении это противоречие не вызывает проблем. Путь /c является точкой монтирования. Она существует только в окружении Unix. Её нет файловой системе Windows. Представьте, что каталог /c в MSYS2 — это ярлык для диска C.
Вывод утилиты mount занял на экране много места. Чтобы очистить окно терминала, нажмите комбинацию клавиш Ctrl+L.
Бывает, что запущенная команда долго выполняется или зависла. Чтобы прервать её выполнение, нажмите комбинацию клавиш Ctrl+C.
cd
Мы знаем текущий каталог. Теперь перейдём по нужному нам пути. Для примера, найдём документацию по интерпретатору Bash. Проверим системный каталог /usr. Там хранятся файлы установленных приложений. Для перехода в /usr наберите команду cd так:
cd /usr
Не забывайте про автодополнение. Оно работает как для имени команды, так и для её параметров. Достаточно набрать cd /u и нажать клавишу Tab. Имя каталога usr Bash добавит автоматически. Результат выполнения команды приводит иллюстрация 2-12.
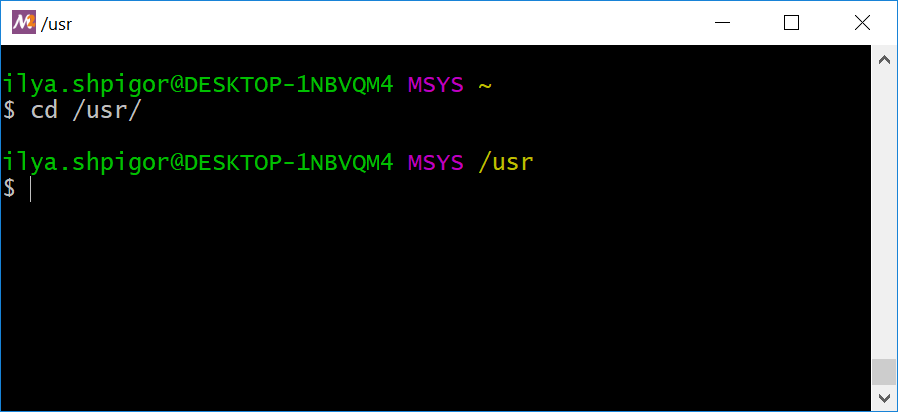
При успешном выполнении команда cd ничего не выводит. Она только меняет текущий каталог. Выполните команду и проверьте вывод перед приглашением командной строки. Теперь текущим каталогом стал /usr.
Команда cd принимает на вход и абсолютные пути, и относительные. Относительные пути короче и быстрее в наборе. Поэтому их чаще используют для навигации по файловой системе.
Мы перешли в каталог /usr. Теперь можно вывести его подкаталоги и перейти в один из них. Предположим, что вместо этого вам надо перейти на уровень выше в корневой каталог. Для этого есть два способа: перейти по абсолютному пути / или по специальному относительному пути ... Путь .. всегда указывает на родительский каталог для текущего. Команда перехода по этому пути выглядит так:
cd ..
Мы находимся в каталоге /usr. Выполним здесь утилиту ls. В её выводе есть подкаталог share. В нём — подкаталог doc с документацией по установленным приложениям. Полный путь документации по Bash такой: share/doc/bash. Перейдём в него следующей командой:
cd share/doc/bash
Теперь текущим каталогом стал /usr/share/doc/bash. Выполним команду ls. Среди прочего она выведет файл с именем README. Это и есть документация по Bash, которую мы ищем.
Выведите содержимое файла README на экран с помощью утилиты cat. Для этого выполните команду:
Иллюстрация 2-13 демонстрирует её результат.
echo "$(< README.txt)"
На иллюстрации 2-13 приводится не весь файл README, а только его последние строки. Этот файл большой. Поэтому вывод утилиты cat не поместился в окно терминала. Чтобы просмотреть начало файла, используйте полосу прокрутки в правой части окна. Для прокрутки по страницам используйте горячие клавиши Shift+PageUp и Shift+PageDown. Для прокрутки по строкам — Shift+↑ и Shift+↓.
История команд
Каждая выполненная в терминале команда сохраняется в истории команд. Чтобы повторить предыдущую команду, нажмите стрелку вверх ↑ и Enter. Нажмите стрелку вверх несколько раз, чтобы прокрутить историю дальше к началу. Для перехода к следующей команде в истории нажмите стрелку вниз ↓.
Например, вы только что ввели команду “cat README”. Чтобы её повторить, нажмите стрелку вверх и Enter.
Комбинация клавиш Ctrl+R вызывает поиск по истории. Нажмите Ctrl+R и начните набирать текст. Bash предложит вам последнюю введённую команду, которая начинается также. Чтобы исполнить её, просто нажмите Enter.
Для вывода на экран всей истории командой наберите:
history
В историю команд попадают только выполненные команды. В неё не попадают команды, которые вы набрали, а затем стёрли.
Что делать, есть в историю надо сохранить команду без её исполнения? Например, вы собираетесь исполнить её позже. Для этого есть трюк с комментарием. Если команда начинается с символа решётка #, Bash обработает её как комментарий. По нажатию Enter она попадёт в историю, но не исполнится. С этим трюком вызов утилиты cat станет таким:
#cat README
Теперь исполним команду. Для этого найдите её в истории и сотрите символ решётка в начале. Затем нажмите Enter.
В большинстве терминалов трюк с комментарием выполняет комбинация клавиш Alt+Shift+3. Работает она так:
- Наберите команду, но не нажимайте Enter.
- Нажмите Alt+Shift+3.
- Команда сохранится в истории без исполнения.
Как скопировать текст из терминала? Предположим, что часть файла README нужна в другом документе. Для копирования используйте буфером обмена. Это временное хранилище для строк. В нём сохраняется выделенный в терминале текст. Его можно вставить в любое другое окно.
Для копирования текста из терминала:
- Выделите мышью нужный текст. Для этого зажмите левую кнопку мыши и проведите курсором по тексту.
- Для вставки текста из буфера обмена в окно терминала нажмите среднюю кнопку мыши. Текст будет вставлен в текущую позицию курсора.
- Для вставки текста в другое приложение нажмите правую кнопку мыши и выберите пункт “Вставить”.
find
Искать нужный файл или каталог командами cd и ls неудобно. Для этого есть специальная утилита find.
Если запустить утилиту find без параметров, она выведет содержимое текущего каталога и его подкаталогов. В вывод попадут и скрытые объекты. На иллюстрации 2-14 результат запуска find для домашнего каталога пользователя ~.
Первый параметр утилиты find — это каталог, в котором надо искать. Утилита принимает относительный или абсолютный путь. Например, вот команда для поиска в корневом каталоге:
Со второго параметра утилиты начинаются условия поиска. Если найденный объект не удовлетворяет условиям, он не выводится на экран. Условия сочетаются друг с другом и составляют единое выражение. Для обработки этого выражения в утилиту встроен специальный интерпретатор. Например, условием поиска может быть имя файла. Тогда в вывод find попадут только файлы с этим именем.
Таблица 2-3 приводит часто используемые условия для утилиты find.
| Условие | Значение | Пример |
|---|---|---|
-type f |
Искать только файлы. | find -type f |
-type d |
Искать только каталоги. | find -type d |
-name шаблон |
Поиск файла или каталога по шаблону имени. | find -name README |
| Шаблон чувствителен к регистру. | find -name READ* |
|
find -name READ?? |
||
-iname шаблон |
Поиск файла или каталога по шаблону имени. Шаблон нечувствителен к регистру. | find -iname readme |
-path шаблон |
Поиск по шаблону пути к файлу или каталогу. Шаблон чувствителен к регистру. | find -path */doc/bash/* |
-ipath шаблон |
Поиск по шаблону пути к файлу или каталогу. Шаблон нечувствителен к регистру. | find . -ipath */DOC/BASH/* |
-a или -and
|
Скомбинировать несколько условий с помощью логического И. В вывод попадут только файлы и каталоги, удовлетворяющие всем условиям. | find -name README -a -path */doc/bash/* |
-o или -or
|
Скомбинировать несколько условий с помощью логического ИЛИ. Если файл или каталог соответствует хотя бы одному условию, он попадёт в вывод. | find -name README -o -path */doc/bash/* |
! или -not
|
Логическое отрицание (НЕ) | find -not -name README |
| последующего условия. В вывод попадут только файлы и каталоги, которые не удовлетворяют условию. | find ! -name README |
Шаблоном называется поисковый запрос. В него вместе с обычными символами входят символы подстановки (wildcard character). Всего в Bash три таких символа: *, ? и [. Звёздочка означает любое количество любых символов. Знак вопроса — один любой символ. Например, строка README соответствует следующим шаблонам:
*MEREADM?*M?R*M?
Квадратные скобки указывают набор символов в определённой позиции строки. Например, шаблон [cb]at.txt соответствует файлам cat.txt и bat.txt. Вот вызов утилиты find с поиском по этому шаблону:
"[cb]at.txt"
Применим поиск по шаблонам на практике. Вернёмся к задаче с документацией по Bash. Найдём файл README с помощью утилиты find. Предположим, что нам неизвестен диск, где хранится файл. Тогда передадим в find первым параметром корневой каталог. Так она будет искать файл на всех смонтированных дисках. В Unix-окружении документы хранятся в каталогах с именем doc. Учитывая это, вызовем следующую команду поиска:
Команда выведет список всех файлов с документацией на всех смонтированных дисках. Этот список слишком длинный. Сократим его с помощью дополнительных условий поиска. Добавим слово bash в путь искомого файла. Получится следующая команда:
Иллюстрация 2-15 демонстрирует результат. То же самое выведет следующая команда:
Отличие команд в опции -a между условиями. Она означает логическое И. Если между условиями не указывать логическую операцию, по умолчанию применяется И.
В конце вывода утилита find сообщает об ошибке. Проблема в том, что некоторые подкаталоги / являются точками монтирования Windows-дисков. Например, диск C смонтирован в /c. Утилита не может получить доступ к их содержимому при поиске с корневого каталога. Чтобы избежать ошибки, начните поиск с точки монтирования диска C:
Альтернативное решение — исключить точки монтирования из поиска. Для этого передайте опцию -mount:
В результате find выведет небольшой список документов. Среди них легко найти нужный README файл.
Искать файл документации можно и по-другому. Предположим, что его имя известно. Тогда укажем имя вместе с предполагаемым путём. Получим следующую команду
Иллюстрация 2-16 демонстрирует результат поиска.
Перед нами снова небольшой список файлов, в котором легко найти нужный.
Условия утилиты find можно группировать. Для этого используйте экранированные круглые скобки. Например, найдём файлы README с путём */doc/* или файлы LICENSE с произвольным путём. Это сделает следующая команда:
\( -path */doc/* -name README \) -o -name LICENSE
Зачем экранировать скобки в выражении утилиты find? Дело в том, что скобки — это часть синтаксиса Bash. Они используются в конструкциях языка. Встретив их в вызове утилиты, Bash выполнит подстановку. Подстановкой называется замена части команды на что-то другое. С помощью экранирования мы заставляем интерпретатор игнорировать скобки. В этом случае он передаст их как есть в утилиту find.
Утилита find умеет не только искать, но и обрабатывать файлы и каталоги. После условия поиска, можно указать действие. Утилита применит его к каждому найденному объекту.
Опции для указания действий приведены в таблице 2-4.
| Опция | Значение | Пример |
|---|---|---|
-exec команда {} \; |
Выполнить указанную команду над каждым найденным объектом. | find -name README -type f -exec cp {} ~ \; |
-exec команда {} + |
Выполнить указанную команду один раз над всеми найденными объектами. Команда получит все объекты на вход. | find -type d -exec cp -t ~ {} + |
-delete |
Удалить каждый из найденных файлов. Каталоги удаляются, только если они пустые. | find -name README -type f -delete |
Есть два варианта действия -exec. Они отличаются символами на конце: экранированная точка с запятой \; или плюс +. Действие с плюсом сработает только, если вызываемая команда способна обработать несколько входных параметров. Большинство GNU-утилит с этим справятся. Если команда принимает только один параметр, она обработает только первый найденный объект.
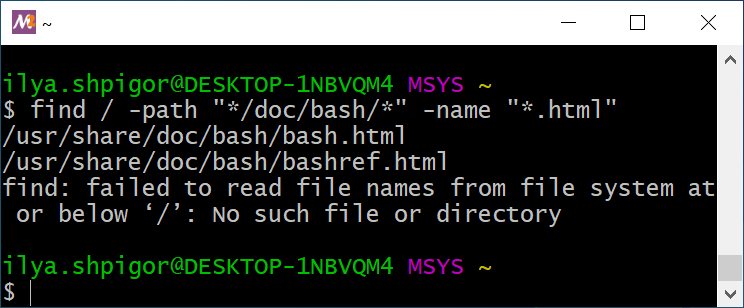
Применим действие -exec для решения практической задачи. Скопируем файлы документации по Bash с расширением HTML в домашний каталог. Для начала найдём эти файлы утилитой find. Её вызов выглядит так:
"*/doc/bash/*" -name "*.html"
Передавая шаблоны в find, заключайте их в двойные кавычки “. Кавычки делают то же, что и обратный слэш перед круглыми скобками. Они запрещают Bash интерпретировать шаблоны. Тогда утилита find получает их как есть и интерпретирует сама.
Результат поиска HTML документов приведён на иллюстрации 2-17.
Добавим к команде поиска действие -exec. Оно вызывает утилиту cp. Утилита копирует файлы и каталоги в указанный путь. Первым параметром cp принимает копируемый объект. Второй параметр — путь, куда копировать. Вызов find с действием выглядит так:
"*/doc/bash/*" -name "*.html" -exec cp {} ~ \;
Это команда выведет только ошибку с точками монтирования.
Разберёмся, что сделала команда. Она вызвала утилиту cp для каждого найденного HTML файла. Первым параметром cp получила путь до файла. Утилита find подставила путь вместо фигурных скобок {}. Она нашла два файла. Поэтому cp вызывалась дважды так:
1 cp ./usr/share/doc/bash/bash.html ~
2 cp ./usr/share/doc/bash/bashref.html ~
Каждый вызов копирует один HTML файл в домашний каталог пользователя.
Только что мы написали первую программу на языке интерпретатора утилиты find. Она работает по следующему алгоритму:
- Найти файлы с расширением HTML на всех дисках. Их пути соответствуют шаблону
*/doc/bash/*. - Скопировать каждый найденный файл в каталог пользователя.
Алгоритм программы состоит всего из двух шагов. Но это масштабируемое решение для поиска и копирования файлов. Программа обработает десятки HTML файлов так же быстро, как и два.
Действия -exec комбинируются точно так же как и условия поиска. Для примера выведем содержимое каждого из найденных HTML файлов и подсчитаем количество строк в них. С первой задачей справится утилита cat. Утилита wc подсчитает число строк. На вход wc принимает имя файла для обработки. Команда вызова find в этом случае выглядит так:
"*/doc/bash/*" -name "*.html" -exec cat {} \; -exec wc -l {} \;
Мы не указали логическую операцию между действиями -exec. По умолчанию используется логическое И. Это означает, что второе действие выполняется только при успешном исполнении первого. Если заменить логическую операцию на ИЛИ, второе действие будет выполняться всегда, независимо от результата первого.
Действия -exec группируются с помощью экранированных круглых скобок \( и \). Это работает так же как группирование условий поиска.
Логические выражения
Условия поиска утилиты find представляют собой логические выражения. Логическим выражением называется конструкция языка программирования. Выражение можно вычислить. В результате получится одно из двух значений: “истина” или “ложь”.
Условие поиска find — это конструкция встроенного в утилиту интерпретатора. Если для найденного объекта условие выполняется, его вычисление даст результат “истина”. Если условие не выполняется, его результат — “ложь”. Если условий несколько, они объединяются в составное логическое выражение.
Мы сталкивались с алгеброй логики, когда знакомились с двоичной системой счисления. Этот раздел математики изучает логические операции. Они отличаются от привычной арифметики сложения, вычитания, умножения и деления.
Вычисление логического выражения даёт только два возможных значения. Поэтому арифметические действия над двумя выражениями тривиальны и ничего не дают. Если же применить к ним логические операции, получим условия со строгими правилами вывода результата. Например, для утилиты find так составляется условие для поиска файла с заданным именем и путём. Комбинация таких условий с действиями даёт сложное поведение программы.
Операндом называется то, над чем выполняется логическая операция. Операндом может быть выражение или отдельное значение.
Для простоты разберём логические выражения на примере, не связанном с утилитой find. Представьте, что мы программируем робота для склада. Его задача — перевозить коробки из точки А в точку Б. Для этого зададим ему следующий прямолинейный алгоритм:
- Двигайся в точку А.
- Возьми коробку в точке А.
- Двигайся в точку Б.
- Положи коробку в точке Б.
В этом алгоритме нет никаких условий. Это значит, что робот выполняет каждый его шаг независимо от внешних событий.
Теперь представьте, что на пути робота в точку Б окажется препятствие. Например, другой робот. В этом случае исполнение алгоритма приведёт к столкновению. Чтобы этого не случилось, добавим условие:
- Двигайся в точку А.
- Возьми коробку в точке А.
- Если нет препятствия, двигайся в точку Б. Иначе остановись.
- Положи коробку в точке Б.
Третий шаг алгоритма называется условным оператором. Все современные языки программирования имеют такую конструкцию.
Алгоритм работы условного оператора выглядит так:
- Вычислить значение операнда.
- Если результат “истина”, выполнить первое действие.
- Если результат “ложь”, выполнить второе действие.
В нашем примере робот вычисляет значение логического выражения “нет препятствия”. Если препятствие есть, выражение будет ложно и робот остановится. В противном случае он продолжит движение в точку Б.
Логические операции позволяют скомбинировать несколько выражений. Например, робот пробует взять коробку в точке А, но её там нет. Тогда ему нет смысла двигаться в точку Б. Добавим это условие к уже существующему выражению с помощью операции логического И (конъюнкция). Теперь наш алгоритм выглядит так:
- Двигайся в точку А.
- Возьми коробку в точке А.
- Если есть коробка И нет препятствия, двигайся в точку Б. Иначе остановись.
- Положи коробку в точке Б.
Вычисление логических операций тоже даёт истину или ложь. Результатом логического И будет “истина”, когда оба операнда истинны. То есть у робота есть коробка и нет препятствия. В любом другом случае результатом операции будет “ложь”. Тогда робот остановится.
Работая с утилитой find, мы познакомились с ещё двумя логическими операциями: ИЛИ (дизъюнкция) и НЕ (отрицание).
На самом деле в нашем алгоритме для робота мы уже применили НЕ, когда написали выражение “нет препятствия”. Это отрицание: “НЕ есть препятствие”. Укажем явно логическое НЕ в алгоритме:
- Двигайся в точку А.
- Возьми коробку в точке А.
- Если есть коробка И НЕ есть препятствие, двигайся в точку Б. Иначе остановись.
- Положи коробку в точке Б.
В логическом выражении операцию И можно заменить на ИЛИ. Чтобы поведение робота не изменилось, добавим отрицание к первому условию и уберём его у второго. Также поменяем порядок действий условного оператора. Теперь если выражение будет истинным, робот остановится. Если ложным, продолжит двигаться к точке Б. В итоге получим следующий алгоритм:
- Двигайся в точку А.
- Возьми коробку в точке А.
- Если НЕ есть коробка ИЛИ есть препятствие, остановись. Иначе двигайся в точку Б.
- Положи коробку в точке Б.
Прочитайте внимательно новый условный оператор. Логика робота не изменилась. Он по-прежнему остановится, если у него нет коробки или на пути возникло препятствие.
В нашем примере логическое выражение записано в виде предложения на русском языке. Это предложение звучит неестественно. Его надо прочитать несколько раз, чтобы понять. Причина в том, что естественный язык (язык общения людей) не подходит для описания логических выражений. Он недостаточно точен. Поэтому в алгебре логики применяют математическая запись.
Кроме логических И, ИЛИ, НЕ в программировании часто используются ещё три операции:
- Эквивалентность
- Не эквивалентность
- Исключающее ИЛИ
Таблице 2-5 приводит полный список логических операций.
| Операция | Результат вычисления выражения |
|---|---|
| И (AND) | “Истина”, когда оба операнда “истина”. |
| ИЛИ (OR) | “Истина”, когда любой из операндов “истина”. “Ложь”, когда все операнды “ложь”. |
| НЕ (NOT) | “Истина”, когда операнд “ложь” и наоборот. |
| Исключающее ИЛИ (XOR) | “Истина”, когда значения операндов отличаются (истина-ложь или ложь-истина). “Ложь”, когда они совпадают (истина-истина, ложь-ложь). |
| Эквивалентность | “Истина”, когда значения операндов совпадают. |
| Не эквивалентность | “Истина”, когда значения операндов отличаются. |
Постарайтесь запомнить эту таблицу. Это несложно, если вы часто используете логические операции на практике.
grep
Утилита grep — это ещё один инструмент поиска. Она находит файлы по их содержимому.
Когда применять утилиту find, а когда grep? Используйте find, чтобы найти файл или каталог по имени, пути или метаданным. Метаданными называется дополнительная информация об объекте файловой системы. Например, размер, время создания и последней модификации, права доступа. Ищите файл утилитой grep, если известно только его содержимое.
Рассмотрим выбор утилиты поиска на примере. Мы ищем файл с документацией. Известно, что в нём встречается фраза “free software” (свободное ПО). Если применить утилиту find, алгоритм поиска будет следующим:
- Найти все файлы документации с именем
READMEс помощью find. - Открыть каждый файл в текстовом редакторе и найти в нём фразу “free software”.
Проверять содержимое файлов в текстовом редакторе долго. Утилита grep автоматизирует эту операцию. Следующая команда найдёт строку “free software” в файле README:
"free software" /usr/share/doc/bash/README
Первый параметр утилиты — это искомая строка. Не забывайте про двойные кавычки. Они гарантируют, что grep получит строку без изменений. Без кавычек Bash разделит её пробелом на два отдельных параметра. Этот механизм разделения строк называется word splitting.
Вторым параметром grep принимает относительный или абсолютный путь к файлу. Если указать список файлов через пробелы, утилита обработает их все. В примере мы передали только один путь до файла README.
Иллюстрация 2-18 приводит результат вызова утилиты grep.
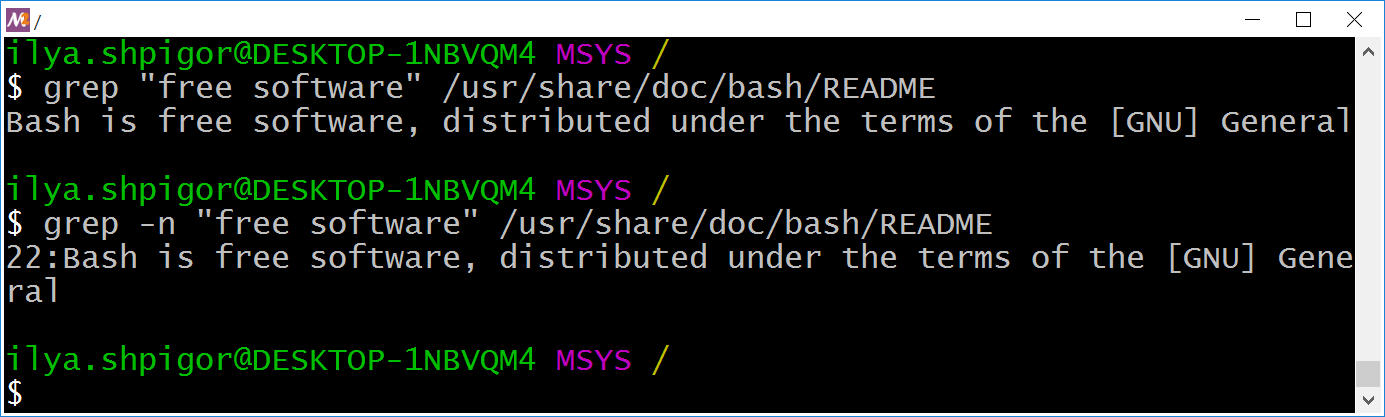
Утилита выводит на экран все строки файла, в которых встречается искомая фраза. Вывод удобнее читать, если добавить в него номера найденных строк. Для этого укажите опцию -n перед первым параметром утилиты. Результат такого вызова приведён в нижней части иллюстрации 2-18.
Мы узнали, как с помощью grep найти строку в указанных файлах. Теперь применим утилиту для решения нашей задачи. Найдём файлы документации с фразой “free software”. Это можно сделать двумя способами:
- Использовать шаблоны поиска Bash.
- Использовать механизм перебора файлов самой утилиты grep.
Рассмотрим первый способ. Предположим, что в домашнем каталоге пользователя есть два текстовых файла: bash.txt и xz.txt. Это копии README документов программ Bash и xz. Найдём, в каком из них встречается фраза “free software”. Для этого выполним следующие две команды:
1 cd ~
2 grep "free software" *
Сначала мы переходим в домашний каталог пользователя. Затем вызываем утилиту grep.
В качестве пути до целевого файла мы указали символ подстановки — звёздочку. Этот шаблон поиска означает любую строку. Bash заменит шаблон на список всех файлов из домашнего каталога. Затем он вызовет утилиту. В результате команда запуска grep станет такой:
"free software" bash.txt xz.txt
Попробуйте выполнить обе команды: grep с шаблоном и со списком файлов через пробел. Утилита даст одинаковый результат.
Попробуем обойтись без команды cd для перехода в домашний каталог. Для этого добавим путь к каталогу в шаблон поиска. Получится такой вызов grep:
"free software" ~/*
Команда echo поможет проверить результат подстановки шаблонов поиска. Посмотрим, как Bash развернёт шаблоны из наших примеров:
1 echo *
2 echo ~/*
Выполните эти команды. Первая выведет список файлов в текущем каталоге, а вторая — в домашнем.
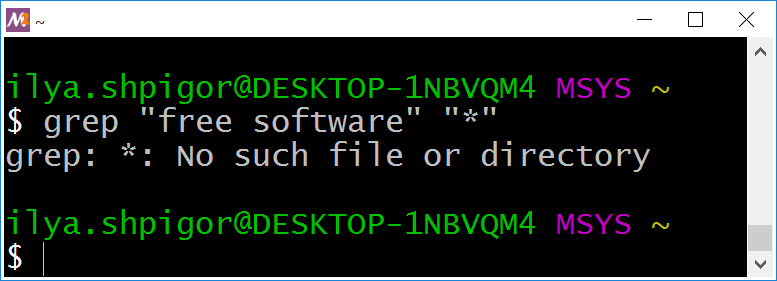
Шаблоны поиска нельзя заключать в двойные кавычки. Например, так:
"free software" "*"
Из-за кавычек Bash не развернёт шаблон, а передаст его как есть утилите grep. Она в отличие от find не умеет самостоятельно разворачивать шаблоны. Поэтому такой вызов приведёт к ошибке как на иллюстрации 2-19.
Bash не включает скрытые файлы и каталоги в подстановку шаблона *. В нашем примере это означает, что утилита grep не получит их на вход. Чтобы искать только по скрытым файлам, используйте шаблон .*. Чтобы искать по всем файлам сразу, укажите два шаблона через пробел. Например, так:
"free software" * .*
Вместо шаблонов поиска, можно использовать встроенный механизм grep. Он перебирает файлы в указанном каталоге. Опция -r включает этот режим работы утилиты. Если вы используете опцию, последним параметром укажите не имя файла, а каталог поиска.
Следующая команда найдёт строку “free software” в файлах текущего каталога:
"free software" .
Такой вызов grep обработает все файлы текущего каталога, включая скрытые.
Если вы работаете на Linux или macOS предпочитайте опцию -R. С ней утилита grep будет переходить по символическим ссылкам во время поиска. Вот пример использования этой опции:
"free software" .
Целевой каталог для поиска указывается по относительному или абсолютному пути. Вот примеры для обоих случаев:
1 cd /home
2 grep -R "free software" ilya.shpigor/tmp
3 grep -R "free software" /home/ilya.shpigor/tmp
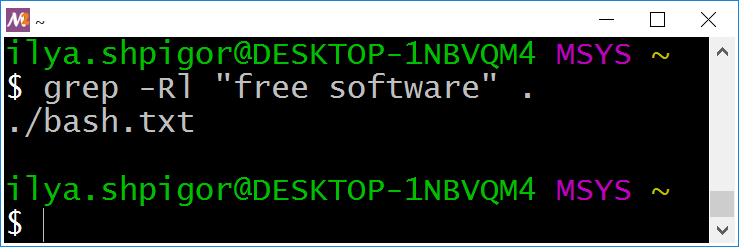
Предположим, нас интересует список файлов, в которых встречается фраза. В обычном режиме утилита grep выводит все вхождения искомой фразы. Этот вывод сейчас не нужен. Уберём его опцией -l. Например, так:
"free software" .
Иллюстрация 2-20 приводит результат этой команды.
Мы получили список файлов, в которых фраза “free software” встречается хотя бы раз. Допустим, нам нужен противоположный результат: список файлов, где фразы нет. Для такого поиска используйте опцию -L. Например, так:
"free software" .
Файлы с исходным кодом программ текстовые. Утилита grep работает только с текстовыми файлами. Поэтому grep хорошо справляется с поиском по исходному коду. Используйте её как дополнение к вашему редактору.
Возможно, вам понравилась утилита grep. Вы хотите обрабатывать ей документы в формате PDF и MS Office. К сожалению, это не сработает. Формат этих файлов не текстовый. То есть данные в них закодированы. Для обработки таких файлов, вам понадобится другая утилита. Таблица 2-6 приводит альтернативы grep для не текстовых файлов.
| Утилита | Функции |
|---|---|
| pdftotext | Конвертирует PDF-файл в текстовый формат. |
| pdfgrep | Ищет PDF-файл по его содержимому. |
| antiword | Конвертирует файл MS Office в текстовый формат. |
| catdoc | Конвертирует файл MS Office в текстовый формат. |
| xdoc2txt | Конвертирует файлы PDF и MS Office в текстовый формат. |
Некоторые из этих утилит устанавливаются в окружение MSYS2 пакетным менеджером pacman. В последней главе книги мы рассмотрим, как это сделать.
Информация о командах
Мы познакомились с командами навигации по файловой системе. Для каждой команды мы рассмотрели только часто используемые опции и параметры. Что делать, если вам нужны дополнительные функции?
Все современные ОС и программы имеют встроенную документацию. Она редко бывает нужна благодаря наглядности графического интерфейса. Назначение иконок или кнопок обычно очевидно. Поэтому большинство пользователей документацией не пользуется.
При работе с интерфейсом командной строки режимы работы программ неочевидны. Но знать их надо, поскольку небрежность может привести к потере ваших данных.
Разработчики Unix сначала распространяли документацию в бумажном виде. Но это было неудобно. Объём информации быстро рос и скоро превысил размер одной книги. Чтобы сделать документацию доступнее, была разработана система page. Она предоставляет справку по любой установленной программе.
Система man page — это центральное место для доступа к документации. Кроме этого каждая программа в Unix предоставляет краткую информацию о себе. Так например, у интерпретатора Bash есть своя система справки help. Рассмотрим её подробнее.
Чтобы вывести список встроенных команд Bash, выполните команду help без параметров. Иллюстрация 2-21 демонстрирует результат.
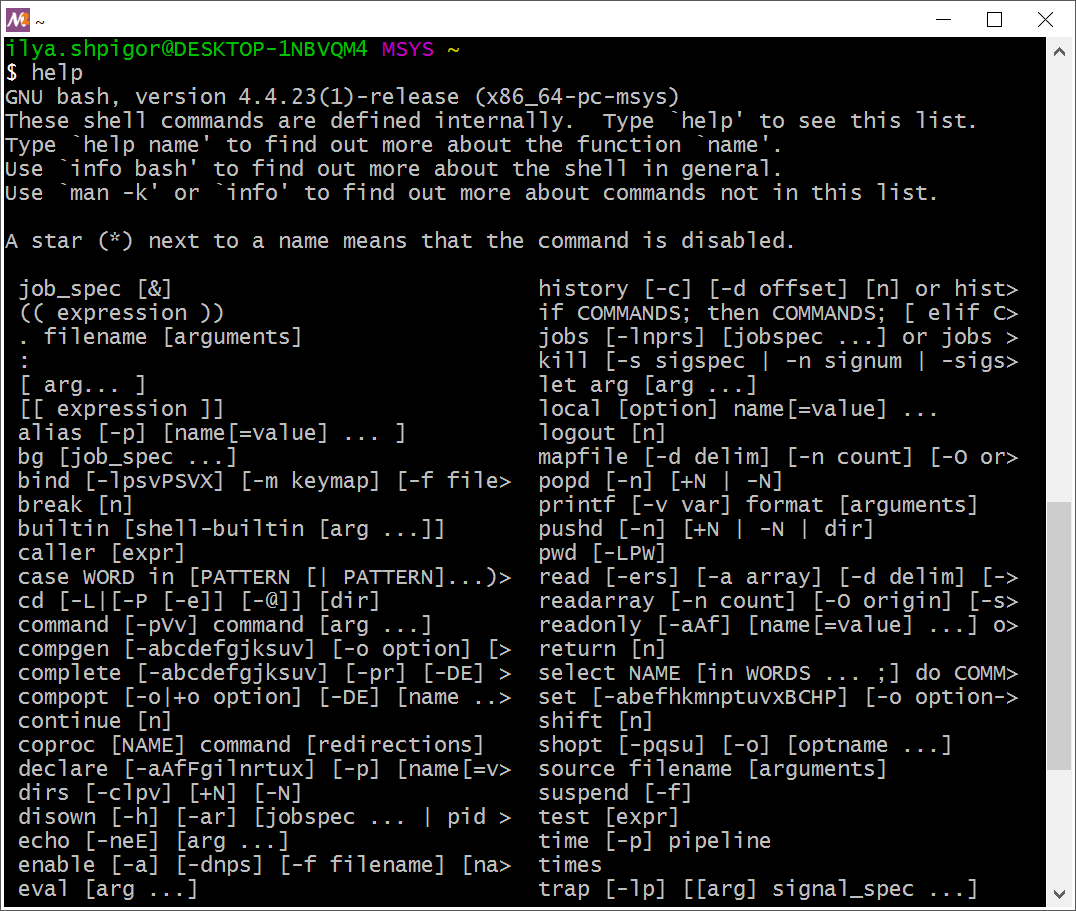
helpПеред вами команды, которые Bash исполняет самостоятельно. Если команды нет в списке, она выполняется GNU-утилитой или сторонней программой.
Например, команда cd есть в списке help. Это значит, что Bash выполнит её самостоятельно. Теперь предположим, что вы ввели команду find. Её в списке help нет. Поэтому Bash вызовет утилиту с именем find и передаст ей указанные вами параметры. Если найти find на жёстком диске не удалось, Bash сообщит об ошибке.
Где Bash ищет утилиты для выполнения команд? У него есть список системных путей, по которым устанавливаются программы. Этот список хранится в переменной окружения с именем PATH.
Переменная — это область оперативной памяти. Обычно для обращения к области памяти нужно указать её адрес. Но переменная позволяет заменить адрес на имя. Обратившись по имени переменной, вы можете записать или прочитать её область памяти. С переменными окружения мы познакомимся в следующей главе.
Представьте переменную как некоторое значение, у которого есть имя. Например, можно сказать: “время — 12 часов”. В этом случае “время” — это имя переменной, а “12 часов” — её значение. Значение хранится в памяти компьютера.
Теперь допустим, что вы читаете переменную из памяти. Для этого вы сообщаете компьютеру её имя “время”. Компьютер преобразует имя в адрес памяти. Он читает память, находит в ней значение “12 часов” и выдаёт его вам. Запись переменной происходит аналогично.
Команда echo выводит на экран не только строки, но и значения переменных. Например, следующая команда напечатает, чему равна переменная PATH:
echo "$PATH"
Зачем нам понадобился знак доллара $ перед именем переменной? Команда echo получает через входные параметры строки и выводит их на экран. Например, следующий вызов echo напечатает текст “123”:
echo 123
Знак доллара $ перед словом сообщает Bash, что это имя переменной. Когда Bash встречает знак доллара, он ищет следующее за ним слово в своём списке переменных. Если поиск удался, Bash заменяет имя на значение переменной. В противном случае имя заменяется на пустую строку.
Вернёмся к команде echo для вывода переменной PATH. Иллюстрация 2-22 демонстрирует результат её исполнения.
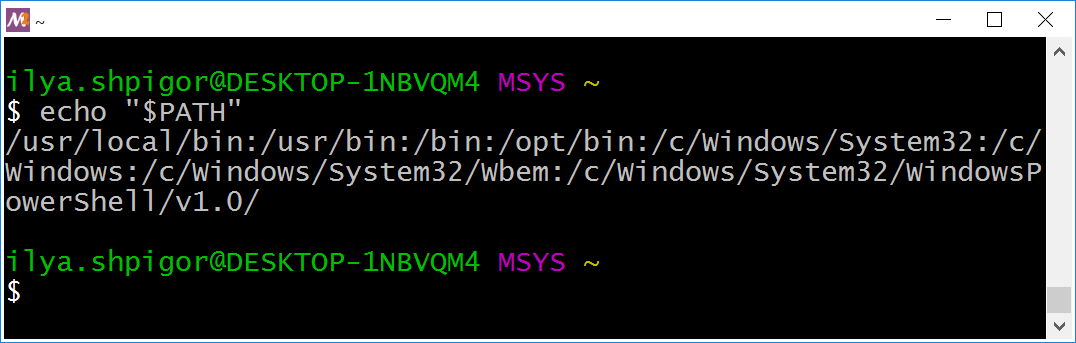
PATHЧто означает этот вывод? Перед нами список путей, разделённых двоеточиями. Если записать каждый путь с новой строки, получим следующее:
Формат переменной PATH вызывает вопросы. Почему нельзя хранить пути в виде списка с переводом строки вместо двоеточия? Тогда при выводе переменной на экран, её было бы удобнее читать. Короткий ответ: так проще программировать. Интерпретатор и некоторые GNU-утилиты обрабатывают символ перевода строки \n по-разному. Это может стать источником ошибок.
Если вы ищете утилиту или программу на диске, переменная PATH подскажет, где искать. Кроме того не забывайте про утилиту для поиска find. Например, найдём её исполняемый файл такой командой:
Файл с именем find находится в каталогах /bin и /usr/bin.
Найти программу на диске можно быстрее. Для этого у Bash есть встроенная команда type. Передайте в неё имя интересующей вас программы. Команда type выведет абсолютный путь до её исполняемого файла как на иллюстрации 2-23.
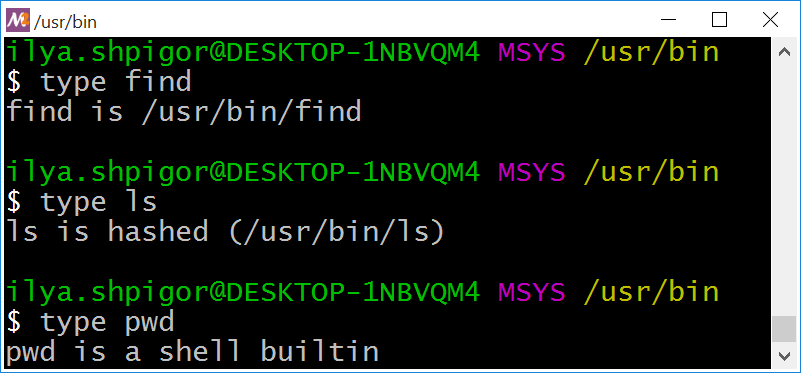
typeИз иллюстрации 2-23 мы узнали, что исполняемые файлы утилит find и ls находятся в каталоге /usr/bin. Причём путь до утилиты ls хэшируется. Bash запоминает его и не ищет исполняемый файл ls при каждом вызове. Поэтому если перенести файл ls в другое место на диске, Bash его не найдёт.
В type можно передать встроенную команду интерпретатора. Тогда type сообщит, что оболочка исполняет эту команду самостоятельно. На иллюстрации 2-23 приведён пример для команды pwd.
Мы нашли исполняемый файл нужной утилиты. Как теперь узнать, какие входные параметры она принимает? Для вывода краткой справки вызовите утилиту с опцией --help. Вы получите вывод как на иллюстрации 2-24. Это краткая справка об утилите cat.
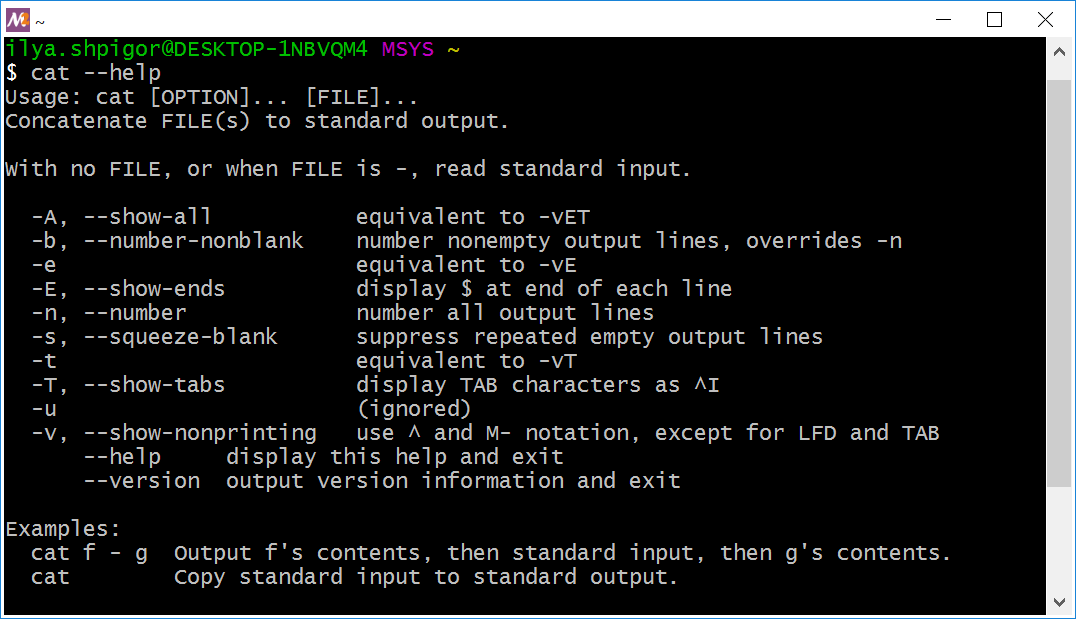
Если язык вашей системы английский, справочная информация выводится на нём. Перевод справки на русский доступен в интернете. Онлайн переводчик Google Translate или DeepL поможет перевести незнакомые английские слова. Если вы используйте Linux или macOS, переключите язык системы на русский. После этого документация станет на русском.
Если краткой справки недостаточно, обратитесь к системе документации info. Предположим, вы ищете примеры использования cat. Их выведет следующая команда:
Иллюстрация 2-25 демонстрирует результат команды info.
catПеред вами программа для чтения текстовых документов. Клавиши-стрелки либо PageUp и PageDown прокручивают текст вверх и вниз. Клавиша Q завершает программу.
Систему документацию info создали разработчики GNU-утилит. До неё все версии Unix использовали man page. Возможности info и man page похожи. В MSYS2 по умолчанию устанавливается современная система info.
В вашем Linux-дистрибутиве может быть установлена система man page. Она выводит информацию так же, как info. Вот пример вызова справки для утилиты cat:
Когда имя нужной утилиты известно, о ней легко получить справку. Но что делать, если вы не знаете, какая утилита решает вашу задачу? Лучше искать ответ на этот вопрос в интернете. Советы по использованию командной строки лаконичнее инструкций для программ с графическим интерфейсом. Вам не нужны скриншоты и видеоролики с объяснениями каждого действия. Вместо этого достаточно одной строчки с командой, которая сделает всё необходимое.
Действия над файлами и каталогами
Мы узнали, как найти файл или каталог на диске. Теперь поговорим о действиях над ними. По опыту работы с графическим интерфейсом ОС вы знаете, что любой файл или каталог можно:
- Создать
- Удалить
- Скопировать
- Перенести или переименовать
Каждое из этих действий выполняется специальной GNU-утилитой. Таблица 2-7 приводит эти утилиты.
| Утилита | Действие | Примеры |
|---|---|---|
mkdir |
Создать каталог с указанным именем и путём. | mkdir /tmp/docs |
mkdir -p tmp/docs/report |
||
rm |
Удалить указанный файл или каталог по | rm readme.txt |
| абсолютному или относительному пути. | rm -rf ~/tmp |
|
cp |
Скопировать файл или каталог. Первым | cp readme.txt tmp/readme.txt |
| параметром передаётся текущий путь, а вторым — целевой. | cp -r /tmp ~/tmp |
|
mv |
Перенести или переименовать объект, | mv readme.txt documentation.txt. |
| указанный первым параметром. | mv ~/tmp ~/backup |
У каждой утилиты есть опция --help. Она выводит краткую справку. Если нужный вам режим работы утилиты пропущен в книге, прочитайте о нём в документации. Если краткой справки окажется недостаточно, обратитесь к системе info или man.
Рассмотрим примеры использования утилит из таблицы 2-7.
mkdir
Утилита mkdir создаёт новый каталог по указанному абсолютному или относительному пути. Путь передаётся в первом параметре. Например, следующая команда создаёт каталог docs в домашнем каталоге пользователя:
Мы указали абсолютный путь до каталога docs. Его можно создать и по относительному пути. Для этого сначала перейдём в домашний каталог пользователя, а затем выполним mkdir:
1 cd ~
2 mkdir docs
Для создания вложенных каталогов у утилиты mkdir есть опция -p. Например, вы сохраняете отчёты за 2019 год по пути ∼/docs/reports/2019. Предположим, что каталогов docs и reports ещё нет. Сначала вам нужно создать их и только потом подкаталог 2019. Это делает одна команда mkdir с опцией -p:
Если каталоги docs и reports уже существуют, утилита mkdir создаст только недостающую часть пути — подкаталог 2019.
rm
Утилита rm удаляет файлы и каталоги. Они указываются по абсолютному или относительному пути.
Например, следующие две команды удаляют один и тот же файл report.txt:
1 rm report.txt
2 rm ~/docs/reports/2019/report.txt
Чтобы удалить несколько файлов за раз, передайте утилите rm их имена через пробел. Например, так:
Предположим, вы удаляете десятки файлов. Перечислять их имена в вызове утилиты неудобно. В этом случае используйте шаблон поиска Bash. Для примера удалим текстовые файлы, имена которых начинаются со слова “report”. Вызов rm для них выглядит так:
При удалении защищённого от записи файла, утилита rm выведет предупреждение как на иллюстрации 2-26.
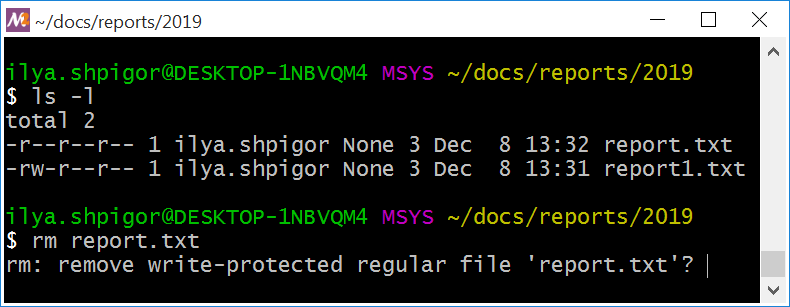
Чтобы удалить файл, нажмите клавишу Y (сокращение от yes) и Enter. Если вызвать утилиту с опцией -f или --force, она отработает без предупреждений. Вот пример такого вызова:
Утилита rm удаляет каталог, только если передать ей дополнительную опцию. Для удаления пустого каталога укажите опцию -d или --dir. Например, так:
Если в каталоге есть файлы или подкаталоги, вызовите утилиту с опцией -r или --recursive. Например:
Опция -r удаляет и пустые каталоги тоже. Чтобы проще запомнить, используйте её для любых каталогов.
cp и mv
Утилиты для копирования и переименования работают по одному принципу. Первым параметром они принимают файл или каталог, над котором выполняется действие. Второй параметр — это новый путь, где окажется копируемый или переносимый объект.
Например, скопируем файл report.txt в текущем каталоге. Для этого вызовем утилиту cp:
Эта команда создаст новый файл с именем report-2019.txt. Его содержимое такое же как у report.txt.
Предположим, что старый файл с именем report.txt не нужен. После копирования его можно удалить утилитой rm. Но лучше вместо копирования перенести файл утилитой mv. Её вызов выглядит так:
Эта команда создаст новый файл с именем report-2019.txt. При этом она удалит старый файл report.txt. Таким образом утилита mv совмещает операции копирования и удаления.
Утилиты cp и mv работают с относительными и с абсолютными путями. Например, вы копируете файл report.txt из домашнего каталога в ~/docs/reports/2019. Для этого выполните следующую команду:
Тот же результат можно получить по-другому. Перейдите в домашний каталог и вызовите утилиту cp с относительными путями. Например, так:
1 cd ~
2 cp report.txt docs/reports/2019
Имя копии можно указать явно. Это полезно, когда оно должно отличаться от имени исходного файла. Для нашего примера вызов утилиты cp выглядит так:
Перенос файлов из каталога в каталог работает точно так же как и копирование. Например, следующая команда перенесёт файл report.txt:
А эта команда перенесёт файл и переименует:
Переименовать каталог можно так же как и файл с помощью утилиты mv. Например:
Эта команда переименует каталог tmp в backup.
Утилита cp в обычном режиме работы не копирует каталоги. Предположим, вы копируете каталог /tmp с временными файлами в домашний каталог. Для этого вы выполняете такую команду:
Команда завершится с ошибкой. Чтобы копирование сработало, укажите опцию -r или --recursive. Получится такой вызов:
Предположим, вы копируете или переносите файл. Если по новому пути уже есть файл с таким же именем, утилиты cp и mv запросят подтверждение операции. В этом случае копируемый файл перезапишет существующий.
Если существующий файл не нужен, его можно перезаписать без подтверждения. Для этого используйте опцию -f или --force. Например:
1 cp -f ~/report.txt ~/tmp
2 mv -f ~/report.txt ~/tmp
Обе команды перезапишут существующий файл report.txt в каталоге tmp. Подтверждать операцию при этом не нужно.
Права доступа
Утилита rm при удалении файла или каталога проверяет его права доступа. Например, если файл защищён от записи, утилита выведет предупреждение. Что такое права доступа и для чего они нужны?
Права доступа ограничивают действия пользователя над файловой системой. За соблюдением этих прав следит операционная система. Благодаря этой функции, пользователю доступны только его файлы и каталоги. При этом доступ к данным других пользователей и компонентам ОС ограничен.
Права доступа позволяют нескольким пользователям работать на одном компьютере. До появления персональных компьютеров такой режим работы практиковался повсеместно. Вычислительные ресурсы были дороги. Поэтому эффективнее было решать несколько задач одновременно, чем ждать пока каждый пользователь закончит свою работу.
Обратимся ещё раз к иллюстрации 2-26. При вызове утилиты ls с опцией -l выводится таблица. В ней каждому файлу и каталогу соответствует строка. Значения столбцов в строке следующие:
- Права доступа.
- Число ссылок (hard link) на файл или каталог.
- Владелец.
- Группа владельца.
- Размер объекта в байтах.
- Дата и время последнего изменения.
- Имя файла или каталога.
Нас интересуют права доступа. Например, у файла report.txt они следующие: -r--r--r--. Разберёмся, что означает эта запись.
В Unix права доступа к файлу или каталогу хранятся в виде битовой маски. Битовая маска — это положительное целое число. В памяти оно представляется в двоичном виде, как последовательность нулей и единиц. Значение каждого бита маски не зависит от других битов. Поэтому одна битовая маска хранит набор значений.
Какие значения можно упаковать в битовую маску? Например, признаки объекта. Каждый признак либо у объекта есть, либо нет. Если признак есть, его представляет бит со значением единица. Если признака нет, его бит равен нулю.
Вернёмся к правам доступа к файлу. Представим эти права как следующие признаки:
- Разрешение на чтение.
- Разрешение на запись.
- Разрешение на исполнении.
Эти признаки помещаются в маску из трёх битов.
Допустим, что к файлу есть полный доступ. Его содержимое можно прочитать или изменить. Сам файл можно скопировать, удалить или исполнить. Это значит, что пользователь имеет права на чтение, запись и исполнение файла. Запись разрешает не только изменение файла, но и его удаление. В этом случае маска с правами доступа к файлу выглядит так:
111
Все три бита в маске равны единицам.
Предположим, что читать и исполнять файл нельзя. Тогда первый бит маски (доступ на чтение) станет нулём. Третий бит (разрешение на исполнение) также станет нулём. В результате получим такую маску:
010
Для правильной работы с маской надо понимать, что означает каждый её бит. Сама маска не хранит этой информации.
Мы рассмотрели упрощённый пример прав доступа. Теперь разберёмся, как эти права устроены в Unix. Утилита ls выводит следующую строку с правами для файла report.txt:
Эта строка и есть битовая маска. В ней нулям соответствуют тире, а единицам — буквы латинского алфавита. Следуя этому правилу, строка -r--r--r-- равна маске 0100100100. Если все биты маски равны единицам, утилита ls выведет строку drwxrwxrwx.
Строка прав доступа в Unix состоит из четырёх частей. Таблица 2-8 объясняет их значение.
| d | rwx | rwx | rwx |
|---|---|---|---|
| Признак каталога. | Права владельца файла или каталога. По умолчанию это тот, кто его создал. | Права группы пользователей, привязанной к файлу. По умолчанию это группа, к которой относится владелец. | Права всех остальных пользователей кроме владельца и группы, привязанной к файлу. |
Для удобства каждую часть строки прав представляют отдельной битовой маской. На каждую из них отводится по 4 бита. Поэтому строка -r--r--r-- представляется следующими четырьмя масками:
0000 0100 0100 0100
Что означают латинские буквы в строке прав доступа? Они соответствуют битам, установленным в единицу. Позиция каждого бита определяет действие пользователя над объектом: чтение, запись и исполнение. Буквы упрощают работу с битовой маской для человека. Согласитесь, что строка -rw-r--r-- проще для чтения, чем двоичное число 0000011001000100.
Таблица 2-9 объясняет смысл каждой буквы в строке прав доступа.
| Буква | Значение для файла | Значение для каталога |
|---|---|---|
| d | Если вместо буквы d первым символом стоит тире, это права для файла. | Права доступа соответствуют каталогу. |
| r | Чтение. | Вывод содержимого каталога. |
| w | Запись. | Создание, переименование или удаление файлов в каталоге. |
| x | Выполнение файла. | Переход в каталог, доступ к его файлам и подкаталогам. |
| — | Действие запрещено. | Действие запрещено. |
Предположим, что все пользователи системы имеют полный доступ к файлу. Тогда строка его прав доступа выглядит так:
Для каталога с теми же правами, первый символ тире поменяется на букву d. Его строка прав доступа выглядит так:
Теперь нам легко прочитать права доступа к файлам report.txt и report1.txt на иллюстрации 2-26. Первый файл могут читать все пользователи. Изменять и исполнять его не может никто. Файл report1.txt могут читать все. Изменять может только владелец. Исполнять не может никто.
Мы рассмотрели команды и утилиты для работы с файловой системой. Чтобы команда выполнилась успешно, запускающий её пользователь должен иметь доступ к целевому файлу или каталогу. Таблица 2-10 демонстрирует права, необходимые для каждой рассмотренной утилиты и команды.
| Команда | Маска | Права доступа | Комментарий |
|---|---|---|---|
ls |
r-- |
Чтение | Только каталоги. |
cd |
--x |
Выполнение | Только каталоги. |
mkdir |
-wx |
Запись и выполнение. | Только каталоги. |
rm |
-w- |
Запись | Для каталогов надо указывать опцию -r. |
cp |
r-- |
Чтение | Целевой каталог должен быть доступен на запись и исполнение. |
mv |
r-- |
Чтение | Целевой каталог должен быть доступен на запись и исполнение. |
| Исполнение | r-x |
Чтение и выполнение. | Только для файлов. |
Запуск файлов
В Windows есть строгие правила для определения какие файлы исполняемые, а какие нет. Расширение файла указывает его тип. Загрузчик Windows запускает только скомпилированные исполняемые файлы приложений. Они имеют расширение EXE или COM. Кроме них пользователь может запускать скрипты. Примеры их расширений: BAT, JS, PY и т.д. Каждый тип скрипта привязан к одному из установленных в системе интерпретаторов. Запустить скрипт нельзя, если для него нет подходящего интерпретатора.
Правила запуска файлов в Unix-окружении отличаются от Windows. В Unix можно запустить любой файл, если у пользователя есть права на его чтение и исполнение. В отличие от Windows расширение неважно. Например, файл с именем report.txt и расширением TXT можно исполнить, если назначить ему соответствующие права.
В Unix нет соглашения о расширении исполняемых файлов. Поэтому из имени файла нельзя однозначно определить его тип. Чтобы узнать тип, используйте утилиту file. Вот пример вызова утилиты для файла ls:
В окружении MSYS2 она выведет на экран следующее:
(console) x86-64 (stripped to external PDB), for MS Wi\
ndows
Вывод означает, что файл имеет тип PE32. Это исполняемый файл с машинным кодом. Он запускается загрузчиком Windows. Также в выводе указана разрядность файла: x86-64. Это значит, что утилита ls запустится только на 64-разрядных версиях Windows.
Если запустить ту же команду file на ОС Linux, получится другой вывод. Например, такой:
64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, in\
terpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=d0bc0fb9b\
3f60f72bbad3c5a1d24c9e2a1fde775, stripped
В Linux файл ls имеет тип ELF. Это исполняемый файл с машинным кодом. Его запускает загрузчик Linux. Разрядность файла такая же как и в MSYS2: x86-64.
Мы научились отличать исполняемые файлы в Unix-окружении от неисполняемых. Теперь выясним, где их искать.
GNU-утилиты считаются частью ОС. Поэтому они доступны сразу после установки системы. Исполняемые файлы утилит находятся в каталогах /bin и /usr/bin. Пути к ним хранятся в переменной Bash с именем PATH. Вопрос в том, куда в Unix-окружении устанавливаются новые приложения?
В Windows на системном диске есть каталоги Program Files и Program Files (x86). По умолчанию все приложения устанавливаются в них. Для каждого приложения создаётся новый подкаталог (например, C:\Program Files (x86)\Notepad++). В процессе установки в него копируются исполняемые файлы, библиотеки, файлы конфигурации и ресурсов. Без них приложение не запустится. Вместо каталогов Program Files и Program Files (x86) можно выбрать другой путь установки (например, D:\Programs). В этом случае в нём создаётся подкаталог приложения со всеми его файлами.
В Unix-окружении принято два варианта установки программ. Первый вариант напоминает подход Windows. В системном каталоге /opt создаётся подкаталог для приложения (например, /opt/teamviewer). В него копируются все файлы приложения. Этот вариант установки выбирают разработчики проприетарных программы с закрытым исходным кодом.
Утилиты и программы с открытым исходным кодом устанавливаются иначе. Приложению для работы нужны файлы различного типа. В Unix каждому типу файлов отводится свой системный каталог. Это значит, что исполняемые файлы всех приложений копируются в один каталог. Документация для них копируется в другой каталог. Файлы ресурсов всех приложений попадут в третий.
Таблица 2-11 объясняет назначение системных каталогов Unix.
| Каталог | Назначение |
|---|---|
/bin |
Исполняемые файлы системных утилит. |
/etc |
Конфигурационные файлы. |
/lib |
Библиотеки, необходимые для работы системных утилит. |
/usr/bin |
Исполняемые файлы приложений пользователя. |
/usr/lib |
Библиотеки, необходимые для приложений пользователя. |
/usr/local |
Приложения, скомпилированные пользователем самостоятельно. |
/usr/share |
Архитектурно-независимые файлы ресурсов приложений пользователя (например, иконки). |
/var |
Файлы, создаваемые приложениями в процессе работы (например, лог-файлы). |
Копирование файлов одного типа в специальные системные каталоги кажется неудачным решением. Его минус в сложности сопровождения. Например, приложение обновляется до следующей версии. Для этого надо найти и обновить все его файлы во всех системных каталогах. Если пропустить один из файлов, приложение перестанет работать.
Но у решения со специальными системными каталогами есть и сильная сторона. В Windows каждое приложение при установке копирует в свой каталог все необходимые ему файлы. Среди этих файлов есть и библиотеки с подпрограммами. Некоторым приложениям для работы нужны одни и те же библиотеки. В результате в файловой системе накапливаются десятки копий этих библиотек. У каждого приложения — своя собственная копия.
В Unix удаётся избежать копирование библиотек. Предположим, что все приложения соблюдают соглашение и устанавливают свои файлы в правильные каталоги. В этом случае каждой программе легко найти файлы другой программы. Благодаря этому, один и тот же файл используется всеми приложениями, которым он нужен. Поэтому в файловой системе достаточно хранить по одному экземпляру каждой библиотеки.
Предположим, что мы установили приложение (например, браузер). Согласно таблице 2-11 его исполняемый файл (например, firefox) копируется в каталог /usr/bin. Как запустить это приложение из командной оболочки Bash? Для этого есть несколько способов:
- По имени исполняемого файла.
- По абсолютному пути.
- По относительному пути.
Рассмотрим каждый способ подробнее.
Первый вариант нам уже знаком. Именно так вызываются GNU-утилиты. Например, запустим find из каталога /usr/bin. Для этого выполним команду:
Аналогичная команда запускает и приложение, установленное в ОС Linux. Например, браузер firefox запускается так:
Почему эта команда сработала? Исполняемый файл firefox находится в системном каталоге /usr/bin. Его путь хранится в переменной окружения Bash с именем PATH. Bash получает команду firefox. Дальше он ищет исполняемый файл с таким именем по каждому из путей переменной PATH. Bash находит файл в каталоге /usr/bin и запускает.
Порядок путей в переменной PATH важен. В этом порядке Bash проходит по системным каталогам и ищет в них файл. Предположим, что файл firefox есть в обоих каталогах /usr/local/bin и /usr/bin. Если путь /usr/local/bin идёт первым в списке PATH, Bash запустит файл из него.
Второй способ запуска приложения похож на первый. Вместо имени исполняемого файла мы указываем абсолютный путь к нему. Например, запустим браузер следующей командой:
Часто этим способом запускают проприетарные приложения. Они устанавливаются в системный каталог /opt. По умолчанию его нет в переменной PATH. Поэтому Bash не находит исполняемый файл самостоятельно. Чтобы команда сработала, вам нужно указать абсолютный путь до файла.
Третий вариант запуска приложения — это что-то среднее между первым и вторым способами. Если вы перейдёте в каталог /usr, то запустить браузер можно по относительному пути исполняемого файла:
1 cd /usr
2 bin/firefox
Теперь предположим, что исполняемый файл firefox находится в каталоге /opt/firefox/bin. Перейдём в этот каталог командой cd и запустим браузер так:
1 cd /opt/firefox/bin
2 firefox
В этом случае Bash сообщит, что файл firefox не найден. Дело в том, что мы пытаемся запустить приложение по имени исполняемого файла. Это первый способ запуска. Bash ищет файл firefox в путях переменной PATH. Но приложение установлено в /opt, которого в PATH нет.
Правильно указывать не имя файла, а относительный путь. Файл находится в текущем каталоге. Этот каталог обозначается точкой .. Учтём это и исправим команды запуска так:
1 cd /opt/firefox/bin
2 ./firefox
Теперь Bash поймёт, что исполняемый файл находится в текущем каталоге.
Рассмотрим, как добавить новый путь (например, /opt/firefox/bin) в переменную PATH. Для этого выполните следующие действия:
1. Перейдите в домашний каталог пользователя:
cd ~
- Выведите соответствующий ему Windows путь (см. пример на иллюстрации 2-7):
pwd -W
- В редакторе Блокнот или любом другом откройте файл
.bash_profileиз этого каталога. - В конец файла добавьте следующую строку:
PATH="/opt/firefox/bin:${PATH}"
Мы переобъявили переменную PATH и добавили в неё новый путь. Подробнее действия с переменными мы разберём в следующей главе.
Чтобы изменения вступили в силу, перезапустите терминал MSYS2. Теперь если вы наберёте команду firefox, Bash найдёт и запустит этот файл по пути /opt/firefox/bin.
Дополнительные возможности Bash
Мы познакомились со встроенными командами Bash и GNU-утилитами для работы с файловой системой. Теперь вы умеете запускать программы, копировать и удалять файлы из командной строки. То же самое легко сделать через графический интерфейс. Для простых задач выбор командного или графического интерфейса — это дело вкуса.
Интерпретатор Bash предлагает возможности, которых нет в графическом интерфейсе. Благодаря им, некоторые задачи выполняются быстрее и проще. Применяйте эти возможности, чтобы сэкономить время и избежать ошибок.
В этом разделе рассмотрим следующие механизмы Bash:
- Перенаправление ввода-вывода.
- Конвейеры.
- Логические операторы.
Философия Unix
Дуглас Макилрой — один из разработчиков Unix. Он обобщил философию этой ОС в трёх пунктах:
- Пишите программы, которые делают что-то одно и делают это хорошо.
- Пишите программы, которые бы работали вместе.
- Пишите программы, которые бы поддерживали текстовые потоки, поскольку это универсальный интерфейс.
Текстовый формат данных — это основа философии Unix. На нём строятся первые два правила.
Благодаря текстовому формату, данные легко передавать между программами. Предположим, что два разработчика независимо друг от друга написали две утилиты. Обе утилиты принимают на вход и выводят результаты в виде текста. Теперь вы хотите скомбинировать эти утилиты для решения своей задачи. Сделать это просто. Не нужно конвертировать данные из одного формата в другой или расширять функциональность утилит. Вместо этого передайте вывод одной утилиты на вход другой.
Когда взаимодействие программ легко наладить, незачем перегружать каждую из них дополнительными возможностями. Например, вы пишете программу для копирования файлов. Она хорошо справляется со своей задачей. Но со временем вы понимаете, что ей нужна функция поиска. Тогда находить и копировать файлы было бы быстрее. Также было бы удобно создавать каталоги прямо в программе, чтобы переносить в них файлы. Этот пример показывает, что требования к приложению быстро растут. Если программа работает самостоятельно, придётся расширять её функции.
Когда приложения работают вместе, каждое из них решает только свою задачу. Если требуется дополнительная операция, проще обратиться к другой утилите. Не надо добавлять новую функцию в приложение. Она уже есть готовая и хорошо протестированная. Просто вызовите внешнюю утилиту, которая сделает то что нужно за вас. Именно такой подход поощряет философия Unix.
Перенаправление ввода-вывода
Утилиты командной строки появились в первых версиях Unix. Большая часть этих утилит попала в POSIX-стандарт. В современных Linux дистрибутивах их заменили на GNU-утилиты. Эти утилиты предлагают больше возможностей. В то же время они следуют стандарту POSIX и обеспечивают обратную совместимость со старыми программами.
GNU-утилиты следуют философии Unix. Они используют текстовый формат для ввода и вывода данных. Поэтому их так же легко комбинировать, как и Unix-утилиты.
При комбинировании GNU-утилит возникает вопрос. Как правильно передавать текстовые данные между ними? У этой задачи есть несколько решений.
Предположим, что вывод утилиты помещается в одну строку. Вам нужно передать её на вход другой утилите. Для этого воспользуйтесь буфером обмена. Выделите мышью вывод утилиты. Затем наберите следующую команду и вставьте содержимое из буфера обмена в её конец. Это простой метод. Но он не сработает для копирования нескольких строк. При их вставке Bash интерпретирует разделители строк как нажатия клавиши Enter. По нажатию Enter команда начнёт исполняться. Из-за этого часть копируемых строк потеряется.
Другое решение — использовать файловую систему. Создайте временный файл, чтобы сохранить вывод одной утилиты. Затем передайте имя файла другой утилите. Она прочитает его содержимое и получит данные. Такой подход удобнее буфера обмена по двум причинам:
- Нет ограничения на количество передаваемых строк.
- Нет ручных операций с буфером обмена.
У Bash есть механизмы для перенаправления ввода и вывода команд в файлы. Это значит, что вашему приложению достаточно читать текстовые данные на входе и выводить результат на экран. Всю работу по перенаправлению этих данных возьмёт на себя Bash.
Рассмотрим пример. Предположим, что мы ищем файлы на диске. Результат поиска надо сохранить в файл. Для решения задачи воспользуемся утилитой find и оператором перенаправления 1>. Тогда команда вызова утилиты выглядит так:
1> readme_list.txt
После выполнения команды в текущем каталоге появится файл readme_list.txt. Утилита find запишет в него свой вывод. Формат вывода такой же, как если бы он печатался на экран. Если файл с именем readme_list.txt уже существует, find перезапишет его содержимое.
Что означает оператор 1>? Это перенаправление стандартного потока вывода. В Unix-окружении есть три стандартных потока. Таблица 2-12 объясняет их назначение.
| Номер | Название | Применение |
|---|---|---|
| 0 | Стандартный поток ввода (standard input или stdin). | Данные, которые передаются на вход программы. По умолчанию они поступают с устройства ввода типа клавиатуры. |
| 1 | Стандартный поток вывода (standard output или stdout). | Данные, которые выводит программа. По умолчанию они печатаются в окне терминала. |
| 2 | Стандартный поток ошибок (standard error или stderr). | Данные об ошибках, которые выводит программа. По умолчанию они печатаются в окне терминала. |
Приложение работает в программном окружении операционной системы. Поток представляет собой канал связи между приложением и окружением. В ранних Unix-системах информация вводилась и выводилась через физические каналы. Ввод был привязан к клавиатуре, а вывод — к монитору. Потоки ввели как абстракцию над этими каналами. Абстракция позволила работать с разными объектами по одному и тому же алгоритму. Так ввод с реального устройства можно заменить на ввод из файла. Аналогично печать на экран можно заменить на вывод в файл. При этом за ввод-вывод отвечает один и тот же код ОС.
Назначение потоков ввода и вывода понятно. Но зачем нужен поток ошибок? Представьте, что вы запустили утилиту find для поиска файлов. К некоторым каталогам у вас нет доступа. При попытке прочитать их содержимое выводится сообщение об ошибке. Если утилита нашла много файлов, сообщения об ошибках потеряются в её выводе. Разделение потоков вывода и ошибок поможет в этом случае. Перенаправьте в файл поток вывода. Тогда на экран напечатаются только сообщения об ошибках.
Чтобы перенаправить поток ошибок, используйте оператор 2>. Например, добавим его в вызов утилиты find:
2> errors.txt
Цифра перед знаком больше в операторах 2> и 1> означает номер потока.
Для перенаправления потока ввода используйте оператор 0<. Вот простой, но не правильный пример поиска шаблона Bash в файле README.txt:
"Bash" 0< README.txt
Эта команда использует интерфейс утилиты grep для обработки потока ввода. Но grep умеет сама читать содержимое указанного файла. Поэтому лучше в неё всегда передавать имя файла. Например, так:
"Bash" README.txt
Рассмотрим пример посложнее. Некоторые руководства по Bash рекомендуют команду echo для вывода содержимого файла на экран. Например, с ней вывод файла README.txt выглядит так:
echo $( 0< README.txt )
Здесь echo получает на вход результат выполнения следующей команды:
0< README.txt
Замена вызова команды на её результат называется подстановкой команды. Когда Bash встречает символы $( и ), он выполняет заключённую между ними команду и подставляет её вывод.
Из-за подстановки команд наш вызов echo выполняется в два этапа:
- Передать содержимое файла
README.txtна стандартный поток ввода. - Вывести данные из стандартного потока ввода командой echo.
При подстановке команд учитывайте порядок исполнения. Сначала Bash выполняет все подстановки по порядку. Потом он выполняет получившуюся команду целиком.
Из-за нарушения порядка исполнения следующий вызов find завершится с ошибкой:
echo $(0< {}) \;
Текст ошибки следующий:
{}: No such file or directory
Команда должна вывести содержимое файлов, найденных утилитой find. Но вместо этого Bash выдал ошибку. Проблема в том, что команда 0< {} выполнится перед вызовом утилиты find. В результате содержимое файла с именем {} перенаправляется на стандартный поток ввода. Но файла с таким именем не существует. Мы ожидали, что утилита find вместо символов {} подставит свой результат. Но она выполняется после подстановки команды 0< {}, а не до.
Чтобы вызов find сработал, замените команду echo на утилиту cat. Получится следующее:
{} \;
Команда выведет на экран содержимое найденных файлов.
Операторы перенаправления потоков ввода и вывода часто используют. Поэтому для них ввели краткую форму: ввод < и вывод >.
Вызов find с краткой формой перенаправления выглядит так:
Вот вызов echo с краткой формой перенаправления:
echo $( < README.txt )
Предположим, что вы перенаправляете поток вывода в уже существующий файл. Его содержимое нельзя удалять. В этом случае допишите результат команды в конец файла. Для этого замените оператор > на >>.
Например, приложения на вашем компьютере установлены в каталоги /usr и /opt. Тогда следующие два вызова find найдут их README файлы:
1 find /usr -path */doc/* -name README > readme_list.txt
2 find /opt -name README >> readme_list.txt
Первый вызов find создаст файл readme_list.txt и запишет в него результат. Если файл уже существует, его содержимое перезапишется. Вторая команда find допишет свой результат в конец readme_list.txt. Если бы файла ещё не было, оператор >> его бы создал.
Полная форма оператора >> выглядит как 1>>. Чтобы перенаправить поток ошибок без перезаписи файла, используйте оператор 2>>.
Иногда нужно перенаправить и поток вывода, и поток ошибок в один файл. Для этого используйте операторы &> или &>>. Первый оператор перезапишет существующий файл. Второй — допишет данные в его конец. Например:
&> result_and_errors.txt
Эта команда работает в Bash, но не в Bourne shell. Дело в том, что операторы &> и &>> — это Bash расширения. Их нет в POSIX-стандарте. Если совместимость со стандартом важна, перенаправляйте поток ошибок в поток вывода с помощью оператора 2>&1. Например, так:
2>&1
Такое перенаправление называется дублированием потоков (duplicating). Применяйте его для записи двух потоков в файл или передаче их данных через конвейер другой команде.
Будьте осторожны с дублированием потоков. Легко допустить ошибку и перепутать порядок операторов в команде. Если вы работайте на Bash, всегда используйте операторы &> или &>>.
Вот пример ошибки с дублированием потоков:
2>&1 > result_and_errors.txt
В результате поток ошибок выводится на экран, а не в файл result_and_errors.txt. Почему команда работает неправильно? Ведь мы перенаправили поток ошибок в поток вывода оператором 2>&1. Рассмотрим эту ошибку подробнее.
Стандарт POSIX вводит понятие файлового дескриптора. Дескриптор — это указатель на файл или канал коммуникации. Дескрипторы, как абстракция, нужны для эффективной работы с потоками. При запуске программы дескрипторы потоков вывода и ошибок указывают на окно терминала. Их можно связать с файлом. В этом случае дескрипторы потоков будут указывать на этот файл. Подробнее этот механизм описан в статье BashGuide.
Вернёмся к нашему вызову утилиты find. Bash выполняет перенаправления потоков слева направо. Их порядок представлен в таблице 2-13.
| Порядок | Перенаправление | Результат |
|---|---|---|
| 1 | 2>&1 |
Теперь поток ошибок указывает на то же, на что и поток вывода. В нашем случае это окно терминала. |
| 2 | > result_and_errors.txt |
Теперь поток вывода указывает на файл result_and_errors.txt. При этом поток ошибок по-прежнему связан с окном терминала. |
Исправим наш вызов find. Для этого изменим порядок операторов перенаправления. Сначала должен идти вывод в файл, а потом дублирование. Получим следующее:
2>&1
Сначала поток вывода связывается с файлом. Затем поток ошибок перенаправляется в тот же файл.
Для записи потока вывода и потока ошибок в разные файлы укажите операторы перенаправления друг за другом. Например, так:
2> errors.txt
Конвейеры
Передавать данные между утилитами через временные файлы неудобно. Во-первых, надо запоминать их пути. Во-вторых, после передачи данных файлы надо удалять, чтобы зря не расходовать место на жёстком диске.
Вместо временных файлов передавайте данные через конвейеры (pipeline). Конвейер — это механизм взаимодействия процессов. Он передаёт сообщения без использования файловой системы.
Рассмотрим пример. Предположим, что мы ищем информацию о лицензии в документации по Bash. Для этого применим утилиту grep. Выполним следующую команду в каталоге с документацией:
"GNU" /usr/share/doc/bash
Информацию о лицензии можно найти не только в каталоге с документацией, но и в info справке по Bash. Обработаем поток вывода info и найдём в нём нужное. Для этого применим конвейер и утилиту grep. Например, так:
| grep -n "GNU"
Утилита info передаёт свои данные на поток вывода. Далее в команде идёт конвейер, обозначенный символом |. Он принимает вывод команды слева и передаёт его на ввод команде справа. Таким образом утилита grep получит текст справки по Bash. В этом тексте она ищет строки со словом “GNU”. Если Bash распространяется под GNU GPL лицензией, вывод grep будет непустым.
В вызов утилиты grep мы добавили опцию -n. С ней grep выводит номера найденных строк. Это удобно для поиска конкретного места в файле.
du
Рассмотрим пример использования конвейеров посложнее. Утилита du оценивает использование дискового пространства. Запустите её без параметров в текущем каталоге. Она рекурсивно пройдёт по всем его подкаталогам и выведет их размер.
Рекурсивный обход означает повторение операции перехода в подкаталог. Алгоритм обхода выглядит так:
- Проверить содержимое текущего каталога.
- Если есть непосещённый подкаталог, перейти в него и начать с пункта 1 алгоритма.
- Если все подкаталоги посещены, перейти на уровень выше и начать с пункта 1 алгоритма.
- Если перейти на уровень выше нельзя, завершить алгоритм.
Перед запуском этого алгоритма вы должны выбрать точку старта. Это определённый путь в файловой системе. Алгоритм обойдёт все подкаталоги, начиная с указанного пути. После этого алгоритм завершится.
Мы рассмотрели универсальный алгоритм обхода. К нему можно добавить действие над каждым найденным подкаталогом. В случае утилиты du действие — это расчёт занимаемого дискового пространства.
Алгоритм работы утилиты du выглядит так:
- Проверить содержимое текущего каталога.
- Если есть непосещённый подкаталог, перейти в него и начать с пункта 1 алгоритма.
- Если все подкаталоги посещены или их нет:
3.1 Рассчитать и вывести на экран дисковое пространство, занимаемое текущим каталогом.
3.2 Перейти на уровень выше.
3.3 Начать с пункта 1 алгоритма.
- Если перейти на уровень выше нельзя, завершить алгоритм.
Утилит du принимает на вход пути до каталогов и файлов. Каталоги она обходит рекурсивно, а для файлов выводит их размер.
Вызовем утилиту du для системного каталога /usr/share следующим образом:
Вот сокращенный пример её вывода:
1 261 /usr/share/aclocal
2 58 /usr/share/awk
3 3623 /usr/share/bash-completion/completions
4 5 /usr/share/bash-completion/helpers
5 3700 /usr/share/bash-completion
6 2 /usr/share/cmake/bash-completion
7 2 /usr/share/cmake
8 8 /usr/share/cygwin
9 1692 /usr/share/doc/bash
10 85 /usr/share/doc/flex
11 ...
Перед нами таблица. Она состоит из двух столбцов. В правом указан подкаталог, а в левом — сколько байтов он занимает на диске. В этот вывод можно добавить статистику по файлам в подкаталогах. Для этого укажите опцию -a. Получится следующая команда:
Опция -h сделает вывод утилиты du нагляднее. С ней утилита будет переводить байты в килобайты, мегабайты и гигабайты.
Предположим, что мы оцениваем размер HTML файлов в каталоге /usr/share. Это сделает следующая команда:
| grep "\.html"
Здесь вывод утилиты du передаётся на вход grep через конвейер. Далее grep выводит строки, в которых встречается шаблон “.html”.
Почему в шаблоне “.html” точка экранирована обратным слэшем? Дело в том, что точка означает однократное вхождение любого символа. Если указать шаблон “.html”, в вывод утилиты grep попадут лишние файлы (например, pod2html.1perl.gz) и подкаталоги (/usr/share/doc/pcre/html). Если точку экранировать, утилита grep обработает её как символ точка.
В примере с утилитами du и grep конвейер объединяет только две команды. Однако, количество команд в конвейере не ограничено. Для примера отсортируем найденные HTML файлы в порядке убывания. Для этого добавим в конвейер утилиту sort. Получим такую команду:
| grep "\.html" | sort -h -r
По умолчанию утилита sort сортирует строки в порядке возрастания по алфавиту. Это называется лексикографической сортировкой. Например, есть файл со следующими строками:
1 abc
2 aaaa
3 aaa
4 dca
5 bcd
6 dec
Если вызвать утилиту sort без опций, она отсортирует строки файла так:
1 aaa
2 aaaa
3 abc
4 bcd
5 dca
6 dec
Чтобы обратить порядок сортировки, укажите опцию sort -r. С ней результат будет такой:
1 dec
2 dca
3 bcd
4 abc
5 aaaa
6 aaa
В выводе утилиты du в первом столбце идут размеры HTML файлов. Именно их будет сортировать sort. Размеры файлов — это числа. Лексикографическая сортировка не подходит для чисел. Чтобы понять почему, рассмотрим пример.
Есть следующий файл с числами:
1 3
2 100
3 2
Лексикографическая сортировка по возрастанию даст такой результат:
1 100
2 2
3 3
Число 100 оказалось меньше 2 и 3. Причина в том, что ASCII-код символа 1 меньше чем символов 2 и 3. Чтобы отсортировать целые числа по значению, используйте опцию sort -n.
В нашем конвейере из трёх команд утилита du вызывается с опцией -h. Это значит, что в её выводе байты будут переведены в крупные единицы измерения. Чтобы утилита sort обработала их корректно, вызовите её с той же опцией -h.
Конвейеры сочетаются с перенаправлением потоков. Например, следующая команда сохранит отфильтрованный и отсортированный вывод утилиты du в файл result.txt:
| grep "\.html" | sort -h -r > result.txt
Предположим, вы сочетаете конвейеры и перенаправление потоков. При этом поток выходных данных направляется и в файл, и на вход утилите. Как это сделать? У Bash нет встроенного механизма для этой задачи. Но её решает утилита tee. Рассмотрим пример.
Выполните следующую команду:
| tee result.txt
Команда выводит результат утилиты du на экран. Этот же результат она записывает в файл result.txt. Таким образом утилита tee продублировала свой поток ввода в указанный файл и в поток вывода. При этом содержимое уже существующего файла result.txt перезапишется. Чтобы дописать вывод tee в конец файла, используйте опцию -a.
Для тестирования бывает полезно прочитать поток данных между командами в конвейере. Утилита tee делает это. Вызовите её между командами. Например, так:
| tee du.txt | grep "\.html" | tee grep.txt | sort -h -r > resul\
t.txt
Вывод каждой команды конвейера попадёт в соответствующий файл. Эти промежуточные результаты пригодятся при поиске ошибок. Конечный результат работы конвейера по-прежнему записывается в файл result.txt.
xargs
Параметр -exec утилиты find выполняет указанную команду для каждого найденного объекта. Это напоминает конвейер тем, что find передаёт свой результат другой команде. Поведение конвейеров и опции find похоже внешне, но устроены они различно. Выбирайте подходящий механизм в зависимости от задачи.
Рассмотрим, как исполняется команда в опции -exec утилиты find. Её выполняет какая-то программа. Эту программу запускает встроенный интерпретатор find. Интерпретатор передаёт в неё найденный объект. Обратите внимание, что Bash не участвует в вызове -exec. Это значит, что в вызове нельзя использовать следующее:
- Встроенные команды Bash.
- Функции.
- Конвейеры.
- Перенаправление потоков.
- Условные операторы.
- Циклы.
Выполним следующую команду:
echo {} \;
В опции -exec утилита find вызывает встроенную команду Bash — echo. Это не приведёт к ошибке. Почему? На самом деле в нашем примере вызывается не команда Bash, а утилита. Некоторые встроенные команды Bash продублированы в виде отдельных утилит. Они хранятся в системном каталоге /bin. Среди них вы найдёте и файл /bin/echo. Именно он вызывается в нашем примере.
Предположим, что в действии -exec нельзя обойтись без Bash-команды или условной конструкции. В этом случае запустите интерпретатор явно и передайте в него команду. Например, так:
'echo {}' \;
Результат этой команды такой же, как и у предыдущей. Она выведет результаты поиска find на экран.
Вывод find можно перенаправить другой утилите через конвейер. Но тогда конвейер передаст текст, а не отдельные имена объектов. Между текстом и именами есть разница. Например, выполните следующую команду:
| grep "bash"
Её вывод выглядит например так:
1 /home/ilya.shpigor/.bashrc
2 /home/ilya.shpigor/.bash_history
3 /home/ilya.shpigor/.bash_logout
4 /home/ilya.shpigor/.bash_profile
Конвейер передал вывод find на поток ввода утилите grep. В результате grep отфильтровала текст. Она вывела только имена файлов, в которых встречается шаблон “bash”.
Когда find передаёт результаты в действие -exec, это не текст на потоке ввода. Вместо этого конструируется команда. Ей передаются имена найденных объектов как параметры. Можно ли добиться такого же поведения с помощью конвейера? Да. Для этого используйте утилиту xargs.
Применим утилиту xargs в нашем примере с find и grep. Будем фильтровать не имена файлов, а их содержимое. Для этого передадим утилите grep не текст на поток ввода, а имена файлов через параметры командной строки. Добавим вызов xargs так:
| xargs grep "bash"
Вывод этой команды выглядит так:
1 /home/ilya.shpigor/.bashrc:# ~/.bashrc: executed by bash(1) for interactive shells.
2 /home/ilya.shpigor/.bashrc:# The copy in your home directory (~/.bashrc) is yours, p\
3 lease
4 /home/ilya.shpigor/.bashrc:# User dependent .bashrc file
5 /home/ilya.shpigor/.bashrc:# See man bash for more options...
6 /home/ilya.shpigor/.bashrc:# Make bash append rather than overwrite the history on d\
7 isk
8 /home/ilya.shpigor/.bashrc:# When changing directory small typos can be ignored by b\
9 ash
10 ...
Утилита xargs конструирует команду из переданных в неё параметров и данных на потоке ввода. В этой команде сначала идут параметры xargs, а потом текст из потока ввода. Чтобы стало понятнее, обратимся к нашему примеру. Предположим, что первым файлом утилита find нашла ~/.bashrc. Тогда вызов xargs после конвейера выглядит так:
"bash"
В этот вызов передаётся два параметра: grep и “bash”. По этим параметрам xargs конструирует следующую команду:
"bash"
Дальше xargs добавляет к команде текст из потока ввода. В потоке ввода находится имя файла ~/.bashrc. Поэтому у xargs получается такая команда:
"bash" ~/.bashrc
Утилита xargs выполняет сконструированную команду самостоятельно без вызова Bash. Поэтому на неё накладываются те же ограничения, что и на действие -exec утилиты find.
Данные из потока ввода утилита xargs добавляет в конец конструируемой команды. Место добавления этих данных можно указать. Для этого используйте параметр -I.
Рассмотрим пример. Предположим, что найденные файлы надо скопировать в домашний каталог пользователя. Это сделает следующая команда:
"*.html" | xargs -I % cp % ~
Параметр -I % указывает утилите xargs, что текст из потока ввода подставляется вместо символа % в конструируемой команде. В нашем примере утилита cp вызывается для каждой строки, которую конвейер передаёт в xargs. Поэтому xargs сконструирует следующие две команды:
1 cp /usr/share/doc/bash/bash.html /home/ilya.shpigor
2 cp /usr/share/doc/bash/bashref.html /home/ilya.shpigor
Опция -t утилиты xargs выводит сконструированные команды на экран перед их исполнением. Использовать эту опцию можно так:
"*.html" | xargs -t -I % cp % ~
Мы рассмотрели примеры комбинации утилиты find и конвейеров. Это учебные примеры для образовательных целей. Не делайте так в ваших Bash-скриптах! Вместо конвейеров обрабатывайте найденные файлы действием -exec. Так вы избежите ошибок обработки файлов с пробелами и переводом строки в именах.
Один из немногих случаев, когда оправдана комбинация утилиты find и конвейера — это параллельная обработка найденных файлов.
Рассмотрим пример. Предположим, что вы вызываете утилиту cp через действие -exec. Тогда файлы копируются по очереди друг за другом. Это неэффективно, если у вашего жёсткого диска высокая скорость доступа. Копирование файлов можно ускорить, если запустить одновременно несколько процессов. Параметр -P утилиты xargs указывает максимальное количество параллельно работающих процессов. Они будут выполнять сконструированные команды одновременно.
Предположим, что у процессора вашего компьютера четыре ядра. Тогда копирование можно выполнять в четыре параллельных потока. Команда для этого выглядит так:
"*.html" | xargs -P 4 -I % cp % ~
В результате файлы копируются по четыре штуки за раз. Как только один из параллельных процессов завершается, начнётся копирование следующего файла. Это ускорит выполнение команды в несколько раз.
Для обработки данных на потоке ввода есть ряд утилит. Обычно их используют вместе с конвейерами для поиска и анализа текста. Таблица 2-14 приводит часто используемые из этих утилит.
| Утилита | Описание | Примеры |
|---|---|---|
xargs |
Конструирует команду по параметрам командной строки и тексту из стандартного потока ввода. | find . -type f -print0 | xargs -0 cp -t ~ |
grep |
Ищет текст по указанному шаблону. | grep -A 3 -B 3 "GNU" file.txt |
du /usr/share -a | grep "\.html" |
||
tee |
Перенаправляет поток ввода одновременно в поток вывода и в файл. | grep "GNU" file.txt | tee result.txt |
sort |
Сортирует строки из потока ввода в | sort file.txt |
прямом и обратном (параметр -r) порядке. |
du /usr/share | sort -n -r |
|
wc |
Считает строки (параметр -l), слова (-w), |
wc -l file.txt |
буквы (-m) и байты (-с) в указанном файле или потоке ввода. |
info find | wc -m |
|
head |
Выводит указанное число байтов | head -n 10 file.txt |
(параметр -c) или строк (-n) файла или текста из начала потока ввода. |
du /usr/share | sort -n -r | head -10 |
|
tail |
Выводит указанное число байтов | tail -n 10 file.txt |
(параметр -c) или строк (-n) файла или текста из конца потока ввода. |
du /usr/share | sort -n -r | tail -10 |
|
less |
Утилита для навигации по тексту из | less /usr/share/doc/bash/README |
| стандартного потока ввода. Для выхода из неё нажмите клавишу Q. | du | less |
Проблемы передачи имён файлов через конвейер
Конвейеры часто используют неправильно, когда обрабатывают результаты утилит ls и find. Это может привести к ошибкам. Рассмотрим их на примерах.
Ожидается, что следующие две команды для поиска HTML файлов вернут одинаковый результат:
1 find /usr/share/doc/bash -name "*.html"
2 ls /usr/share/doc/bash | grep "\.html"
В некоторых случаях их результаты будут отличаться. Дело не в том, что утилиты find и grep по-разному обрабатывают шаблон поиска. Проблема в передаче имён файлов через конвейер.
Стандарт POSIX разрешает любые символы в именах файлов, в том числе пробелы и перевод строки. Единственный запрещённый символ — это нуль-терминатор (NULL). Рассмотрим последствия этого правила.
Создайте в домашнем каталоге пользователя файл с символом перевода строки в имени. Этот символ обозначается как \n. Чтобы создать такой файл, вызовите утилиту touch:
$'test\nfile.txt'
Утилита touch обновляет время последнего изменения указанного файла. После вызова touch это время будет равно текущему. Если файла не существует, утилита создаст его пустым.
Создайте ещё два файла: test1.txt и file1.txt. Для этого выполните следующую команду:
Теперь вызовем утилиту ls в домашнем каталоге пользователя. Её вывод обработаем с помощью grep. Например, так:
1 ls ~ | grep test
2 ls ~ | grep file
Иллюстрация 2-27 приводит их вывод.
Файл test\nfile.txt попал в вывод обеих команд, но его имя оказалось обрезано. Утилита ls передаёт его поток вывода в полной форме: ‘test’$’\n’‘file.txt’. Однако, конвейер заменяет символ \n на перевод строки. Поэтому имя файла делится на две части. Дальше grep обрабатывает обе части по отдельности так, как будто это два разных имени.
Это не единственная проблема. Предположим, что вы копируете файл с пробелом в имени (например, test file.txt). Из-за пробела следующая команда завершится с ошибкой:
| xargs cp -t ~/tmp
В этом случае xargs сконструирует такой вызов утилиты cp:
test file.txt
Эта команда копирует файлы test и file.txt в каталог ~/tmp. Но в нашем случае ни одного из этих файлов не существует. Причиной ошибки стал механизм word splitting. Он разделил имя файла с пробелом на два отдельных имени. Ошибка решается двойными кавычками. Например, так:
| xargs -I % cp -t ~/tmp "%"
Но если в имени файла стоит не пробел, а перевод строки, добавление кавычек не поможет. Как тогда решить проблему? Ответ — не используйте ls. Утилита find с действием -exec справится с вашей задачей лучше. Вот пример копирования файлов:
"*.txt" -exec cp -t tmp {} \;
Иногда без конвейера и xargs не обойтись. В этом случае используйте опцию -print0 утилиты find. Например, так:
| xargs -0 -I % bsdtar -cf %.tar %
Опция -print0 меняет формат вывода find. По умолчанию утилита использует перевод строки в качестве разделителя между путями до найденных объектов. С -print0 этот разделитель заменяется на нуль-терминатор.
Если формат вывода find изменился, надо также поменять формат ввода xargs. По умолчанию утилита xargs ожидает на вход строки с разделителем \n. Если передать ей опцию -0, она станет ожидать разделитель нуль-терминатор. Таким образом мы согласовали формат вывода одной утилиты и ввода другой.
Формат вывода утилиты grep тоже настраивается для передачи через конвейер. Используйте опцию -Z. Она разделяет файлы в выводе grep нуль-терминатором. Эта опция аналогична -print0 у find. Вот пример её использования:
"GNU" . | xargs -0 -I % bsdtar -cf %.tar %
Эта команда ищет файлы в которых встречается шаблон “GNU”. Конвейер передаёт их имена утилите xargs. Она конструирует вызов утилиты bsdtar для архивации найденных файлов.
Из рассмотренных примеров следует следующее:
- При передаче имён файлов через конвейер помните о пробелах и переводах строк.
- Никогда не обрабатывайте вывод утилиты ls. Вместо неё используйте find с действием
-exec. - Если без xargs не обойтись, всегда используйте опцию
-0. На вход утилите передавайте только имена файлов, разделённые нуль-терминатором.
Логические операторы
Конвейеры позволяют сочетать несколько команд. В результате получается линейный алгоритм. В таком алгоритме действия выполняются последовательно друг за другом без каких-либо условных операторов.
Предположим, что нам нужен более сложный алгоритм. В нём результат выполнения первой команды определяет следующий шаг. Если команда выполнилась успешно, требуется одно действие. В противном случае — другое. Про такой алгоритм говорят, что он содержит ветвление. Сам алгоритм называется разветвляющимся.
Рассмотрим разветвляющийся алгоритм на примере. Напишем команду для копирования каталога. При успешном выполнении она записывает строку “OK” в лог-файл. В противном случае пишется строка “Error”.
Применим конвейер и составим такую команду:
| echo "OK" > result.log
К сожалению, команда не сработает. Она запишет строку “OK” в файл result.log независимо от результата копирования. Даже если каталога docs не существует, в лог-файле будет сообщение об успешном копировании.
Чтобы вывод echo зависел от результата утилиты cp, применим оператор &&. Получим такую команду:
&& echo "OK" > result.log
Теперь команда печатает строку “OK” в файл, только если утилита cp успешно скопирует каталог.
Что такое оператор &&? На самом деле это операция логического И. Но в данном случае она выполняется не над выражениями (условиями), а над командами Bash (действиями). Возникает вопрос: какой смысл выполнять логическую операцию над двумя действиями? Давайте разберёмся.
Стандарт POSIX требует, чтобы каждая запущенная программа при завершении выдавала код возврата (exit status). При успешном завершении этот код равен нулю. В противном случае он принимает любое значение от 1 до 255.
Когда логический оператор применяется к команде, он работает с её кодом возврата. Поэтому сначала команда исполняется, а потом её код возврата используется в логическом выражении.
Вернёмся к нашему примеру:
&& echo "OK" > result.log
Предположим, что утилита cp завершилась успешно. В этом случае она вернёт ноль. В Bash ноль соответствует значению “истина”. Поэтому левая часть нашего оператора && будет истинной. Этой информации ещё не достаточно, чтобы вычислить значение всего выражения. Оно может быть истинным или ложным в зависимости от правого операнда. Чтобы узнать его значение, оператор && должен выполнить команду echo. Она всегда завершается успешно и возвращает код ноль. Таким образом результатом работы оператора && будет “истина”.
Возникает следующий вопрос: как мы используем результат оператора && в нашем примере? Ответ — никак. Логические операторы нужны для вычисления выражений. Но в Bash их часто применяют ради побочного эффекта, а именно — порядка вычисления операндов.
Рассмотрим случай, когда утилита cp в нашей команде завершилась с ошибкой. Тогда её код возврата не ноль. Для Bash это эквивалентно значению “ложь”. В этом случае оператор && уже может вычислить значение всего выражения. Ему не нужно вычислять правый операнд. Вспомните: если хотя бы один операнд логического И ложный, всё выражение будет ложным. Таким образом код возврата команды echo не важен. Поэтому она не выполняется и записи в файл result.log не происходит.
Вычисление только тех операндов, которые достаточны для вывода значения всего выражения, называется коротким замыканием (short-circuit).
echo $?
В условии задачи говорится, что при ошибке в лог-файл выводится строка “Error”. Дополним нашу команду оператором логического ИЛИ. В Bash он обозначается как ||. Получим следующее:
&& echo "OK" > result.log || echo "Error" > result.log
Мы получили разветвляющийся алгоритм. Если утилита cp выполнится успешно, в лог-файл запишется “OK”. В противном случае запишется “Error”. Почему это так? Чтобы ответить на этот вопрос, давайте разберёмся в приоритете операций.
Для простоты обозначим все коды возврата команды буквами латинского алфавита. Утилита cp возвращает код A. Первая команда echo вернёт B, а вторая — C. Тогда команду можно записать в виде следующего выражения:
В Bash приоритет операторов && и || одинаковый. Выражение вычисляется слева направо. В таком случае говорят, что операторы левоассоциативны. Учитывая это, перепишем наше выражение в следующем виде:
Добавление скобок ничего не меняет. По-прежнему сначала вычисляется выражение (A && B). Затем при необходимости вычисляется операнд C.
Итак, что произойдёт, если A равно истине? В этом случае оператор && вычислит свой правый операнд B. Тогда в лог-файл будет записана строка “OK”. Далее Bash обработает оператор ||. В этот момент уже известно значение его левой части (A && B). Оно равно истине. Поэтому на значение всего выражения правый операнд не повлияет. Его вычислять не нужно. Для логического ИЛИ всё выражение истинно, если хотя бы один из операндов истинен. Поэтому строка “Error” не запишется в лог-файл.
Если значение A ложь, выражение (A && B) также будет ложным. При этом вычислять операнд B не нужно. Поэтому вывода “OK” в лог-файле не будет. Bash перейдёт к следующему оператору ||. Интерпретатору уже известно, что левый операнд ложный. Поэтому для вычисления всего выражения надо узнать значение его правой части. В результате выполнится вторая команда echo и строка “Error” запишется в лог-файл.
Принцип работы логических операторов и короткого замыкания неочевиден. Возможно, вам понадобится время, чтобы в нём разобраться. Это важно. В каждом современном языке программирования встречаются логические выражения. Поэтому понимание правил их вычисления пригодится вам в дальнейшем.
Команды в языке Bash можно сочетать не только конвейерами и логическими операторами. Они объединяются и точкой с запятой. Команды следующие друг за другом через ; выполняются по порядку без каких-либо условий.
Рассмотрим пример. Предположим, что вы копируете два каталога по разны целевым путям. Одним вызовом утилиты cp этого не сделать. Но можно объединить два вызова в одну команду. Например, так:
; cp -R ~/photo ~/photo-backup
В результате утилита cp вызывается дважды независимо от результата копирования каталога docs. Даже если произойдёт ошибка, каталог photo всё равно скопируется.
Отличается ли поведение команд следующих через ; от конвейера? Ошибка выполнения первой части команды не повлияет на работу второй. То есть в обоих случаях получается линейный алгоритм. В примере с копированием каталогов разницы никакой нет. Утилита cp игнорирует входные данные на потоке ввода. Следующая команда с конвейером выполняет тот же самый алгоритм копирования:
| cp -R ~/photo ~/photo-backup
Однако, в общем случае различие есть. Команды, следующие через ; выполняются независимо друг от друга. Если используется конвейер, зависимость возникает. Стандартный поток вывода первой команды передаётся на вход второй. Это может изменить её поведение.
Сравните следующие две команды:
1 ls /usr/share/doc/bash | grep "README" * -
2 ls /usr/share/doc/bash ; grep "README" * -
Параметр - утилиты grep добавляет данные со стандартного потока ввода в конец команды.
Иллюстрация 2-28 демонстрирует результаты обеих команд.
Отличается даже поведение утилиты ls. При использовании конвейера её результат не выводится на экран, а перенаправляется на вход grep.
Разберёмся с выводом команд. Второй параметр grep — это шаблон “*”. Поэтому сначала утилита обработает все файлы в текущем каталоге. Слово “README” встречается в файле xz.txt. Поэтому на экран выводится следующая строка:
Далее grep обрабатывает вывод ls, полученный из потока ввода. В этих данных тоже встречается слово “README”. Об этом сообщает следующий вывод:
(standard input):README
Таким образом утилита grep обработала и файлы текущего каталога, и вывод ls.
В варианте команды с ; утилита ls выводит свой результат на экран. После этого вызывается утилита grep. Она обработает все файлы текущего каталога и поток ввода. Но теперь данных на потоке ввода нет. Поэтому grep найдёт слово “README” только в файле xz.txt.