2. Why JPA and Hibernate matter
Although JDBC does a very good job of exposing a common API that hides the database vendor-specific communication protocol, it suffers from the following shortcomings:
- The API is undoubtedly verbose, even for trivial tasks.
- Batching is not transparent from the data access layer perspective, requiring a specific API than its non-batched statement counterpart.
- Lack of built-in support for explicit locking and optimistic concurrency control.
- For local transactions, the data access is tangled with transaction management semantics.
- Fetching joined relations requires additional processing to transform the
ResultSetinto Domain Models or DTO (Data Transfer Object) graphs.
Although the primary goal of an ORM (Object-Relational Mapping) tool is to automatically translate object state transitions into SQL statements, this chapter aims to demonstrate that Hibernate can address all the aforementioned JDBC shortcomings.
2.1 The impedance mismatch
When a relational database is manipulated through an object-oriented program, the two different data representations start conflicting.
In a relational database, data is stored in tables, and the relational algebra defines how data associations are formed. On the other hand, an object-oriented programming (OOP) language allows objects to have both state and behavior, and bidirectional associations are permitted.
The burden of converging these two distinct approaches has generated much tension, and it has been haunting enterprise systems for a very long time.
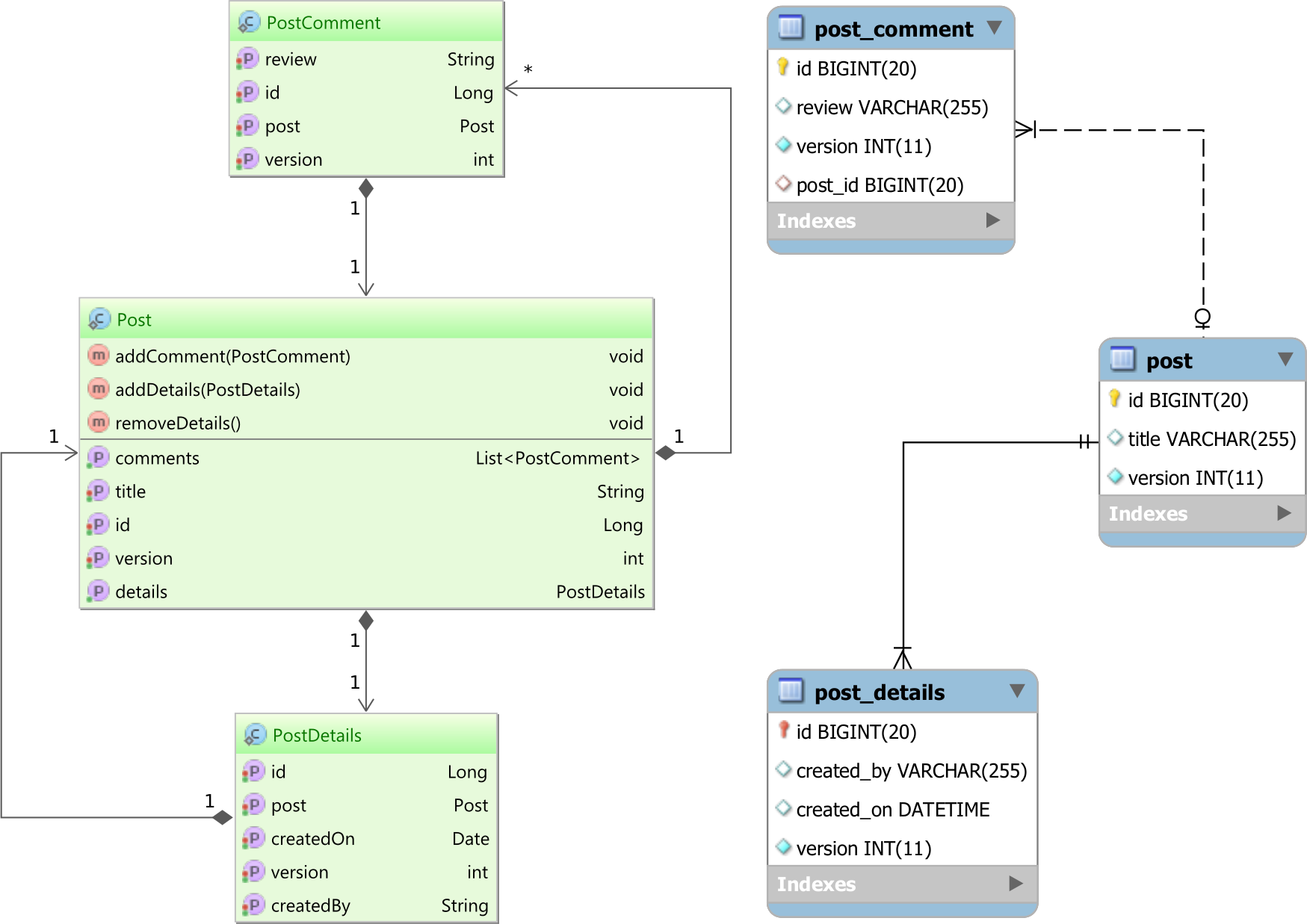
The above diagram portrays the two different schemas that the data access layer needs to correlate. While the database schema is driven by the SQL standard specification, the Domain Model comes with an object-oriented schema representation as well.
The Domain Model encapsulates the business logic specifications and captures both data structures and the behavior that governs business requirements. OOP facilitates Domain Modeling, and many modern enterprise systems are implemented on top of an object-oriented programming language.
Because the underlying data resides in a relational database, the Domain Model must be adapted to the database schema and the SQL-driven communication protocol. The ORM design pattern helps to bridge these two different data representations and close the technological gap between them. Every database row is associated with a Domain Model object (Entity in JPA terminology), and so the ORM tool can translate the entity state transitions into DML statements.
From an application development point of view, this is very convenient since it is much easier to manipulate Domain Model relationships rather than visualizing the business logic through its underlying SQL statements.
2.2 JPA vs. Hibernate
JPA is only a specification. It describes the interfaces that the client operates with and the standard object-relational mapping metadata (Java annotations or XML descriptors). Beyond the API definition, JPA also explains (although not exhaustively) how these specifications are ought to be implemented by the JPA providers. JPA evolves with the Java EE platform itself (Java EE 6 featuring JPA 2.0 and Java EE 7 introducing JPA 2.1).
Hibernate was already a full-featured Java ORM implementation by the time the JPA specification was released for the first time. Although it implements the JPA specification, Hibernate retains its native API for both backward compatibility and to accommodate non-standard features.
Even if it is best to adhere to the JPA standard, in reality, many JPA providers offer additional features targeting a high-performance data access layer requirements. For this purpose, Hibernate comes with the following non-JPA compliant features:
- extended identifier generators (hi/lo, pooled, pooled-lo)
- transparent prepared statement batching
- customizable CRUD (
@SQLInsert,@SQLUpdate,@SQLDelete) statements - static/dynamic entity/collection filters (e.g.
@FilterDef,@Filter,@Where) - mapping attributes to SQL fragments (e.g.
@Formula) - immutable entities (e.g.
@Immutable) - more flush modes (e.g.
FlushMode.MANUAL,FlushMode.ALWAYS) - querying the second-level cache by the natural key of a given entity
- entity-level cache concurrency strategies
(e.g.Cache(usage = CacheConcurrencyStrategy.READ_WRITE)) - versioned bulk updates through HQL
- exclude fields from optimistic locking check (e.g.
@OptimisticLock(excluded = true)) - versionless optimistic locking (e.g.
OptimisticLockType.ALL,OptimisticLockType.DIRTY) - support for skipping (without waiting) pessimistic lock requests
- support for Java 8 Date and Time and
stream() - support for multitenancy
The JPA implementation details leak and ignoring them might hinder application performance or even lead to data inconsistency issues. As an example, the following JPA attributes have a peculiar behavior, which can surprise someone who is familiar with the JPA specification only:
- The FlushModeType.AUTO does not trigger a flush for native SQL queries like it does for JPQL or Criteria API.
- The FetchType.EAGER might choose a SQL join or a secondary select whether the entity is fetched directly from the
EntityManageror through a JPQL (Java Persistence Query Language) or a Criteria API query.
That is why this book is focused on how Hibernate manages to implement both the JPA specification and its non-standard native features (that are relevant from an efficiency perspective).
2.3 Schema ownership
Because of data representation duality, there has been a rivalry between taking ownership of the underlying schema. Although theoretically, both the database and the Domain Model could drive the schema evolution, for practical reasons, the schema belongs to the database.
An enterprise system might be too large to fit into a single application, so it is not uncommon to split in into multiple subsystems, each one serving a specific goal. As an example, there can be front-end web applications, integration web services, email schedulers, full-text search engines and back-end batch processors that need to load data into the system. All these subsystems need to use the underlying database, whether it is for displaying content to the users or dumping data into the system.
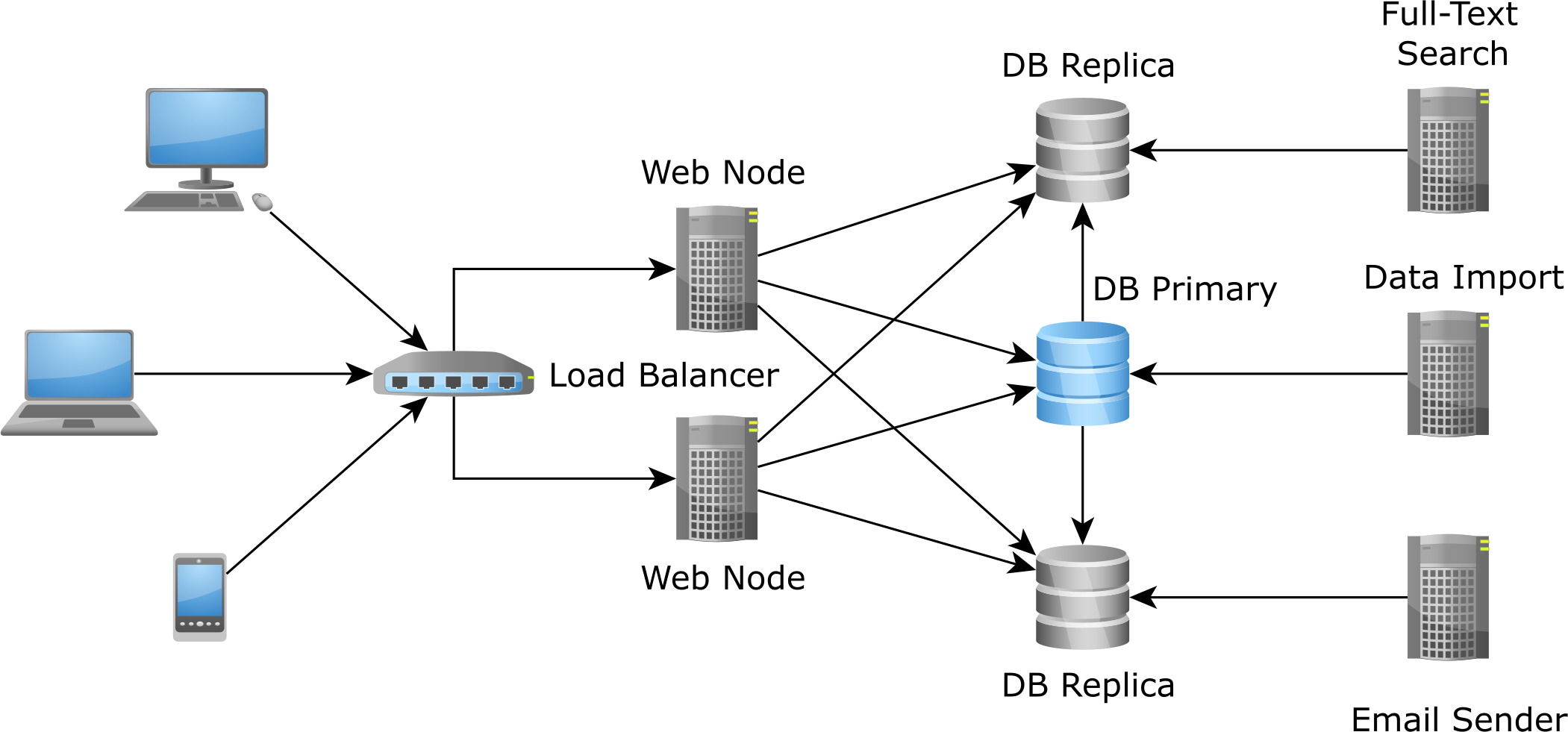
Although it might not fit any enterprise system, having the database as a central integration point can still be a choice for many reasonable size enterprise systems.
The relational database concurrency models offer strong consistency guarantees, therefore having a significant advantage to application development. If the integration point does not provide transactional semantics, it will be much more difficult to implement a distributed concurrency control mechanism.
Most database systems already offer support for various replication topologies, which can provide more capacity for accommodating an increase in the incoming request traffic. Even if the demand for more data continues to grow, the hardware is always getting better and better (and cheaper too), and database vendors keep on improving their engines to cope with more data.
For these reasons, having the database as an integration point is still a relevant enterprise system design consideration.
No matter what architecture style is chosen, there is still need to correlate the transient Domain Model with the underlying persistent data.
The data schema evolves along the enterprise system itself, and so the two different schema representations must remain congruent at all times.
Even if the data access framework can auto-generate the database schema, the schema must be migrated incrementally, and all changes need to be traceable in the VCS (Version Control System) as well. Along with table structure, indexes and triggers, the database schema is, therefore, accompanying the Domain Model source code itself. A tool like Flywaydb can automate the database schema migration, and the system can be deployed continuously, whether it is a test or a production environment.
2.4 Entity state transitions
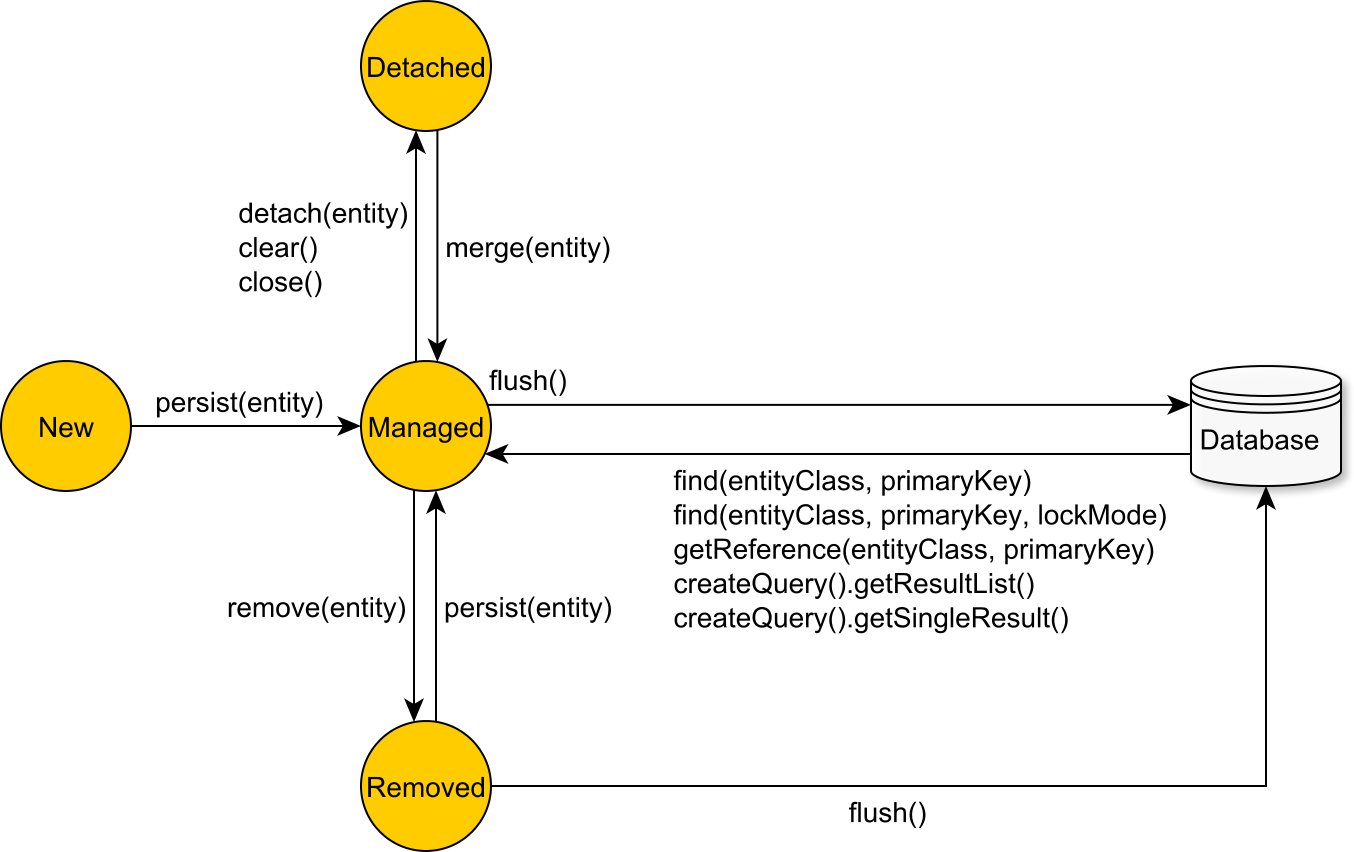
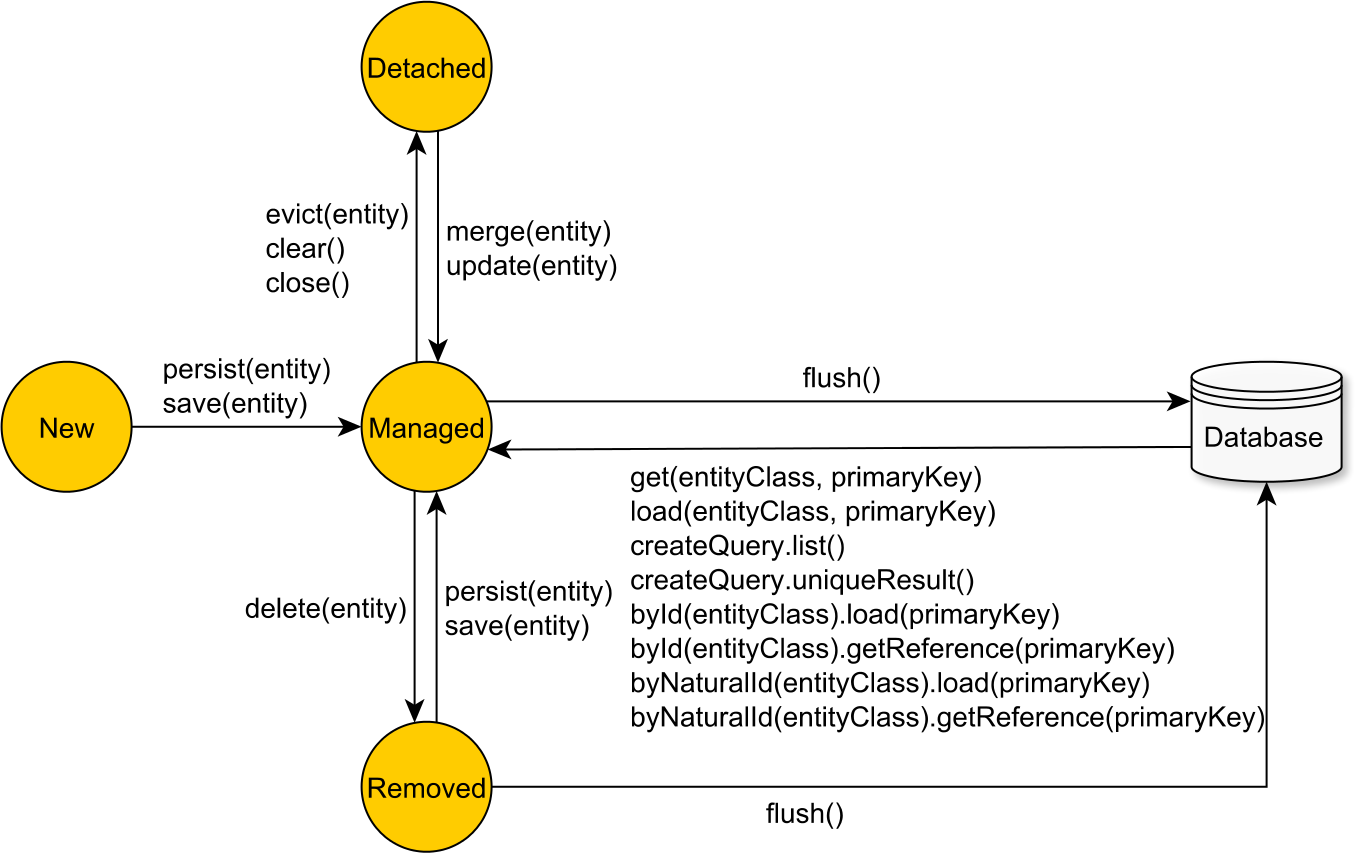
JPA shifts the developer mindset from SQL statements to entity state transitions. An entity can be in one of the following states:
| State | Description |
|---|---|
| New (Transient) | A newly created entity which is not mapped to any database row is considered to be in the New or Transient state. Once it becomes managed, the Persistence Context issues an insert statement at flush time. |
| Managed (Persistent) | A Persistent entity is associated with a database row, and it is being managed by the currently running Persistence Context. State changes are detected by the dirty checking mechanism and propagated to the database as update statements at flush time. |
| Detached | Once the currently running Persistence Context is closed, all the previously managed entities become detached. Successive changes are no longer tracked, and no automatic database synchronization is going to happen. |
| Removed | A removed entity is only scheduled for deletion, and the actual database delete statement is executed during Persistence Context flushing. |
The Persistence Context captures entity state changes, and, during flushing, it translates them into SQL statements.
The JPA EntityManager and the Hibernate Session (which includes additional methods for moving an entity from one state to the other) interfaces are gateways towards the underlying Persistence Context,
and they define all the entity state transition operations.
2.5 Write-based optimizations
2.6 Read-based optimizations
Following the SQL standard, the JDBC ResultSet is a tabular representation of the underlying fetched data.
The Domain Model being constructed as an entity graph, the data access layer must transform the flat ResultSet into a hierarchical structure.
Although the goal of the ORM tool is to reduce the gap between the object-oriented Domain Model and its relational counterpart, it is very important to remember that the source of data is not an in-memory repository, and the fetching behavior influences the overall data access efficiency.
In the following example, the posts records are fetched along with all their associated comments. Using JDBC, this task can be accomplished using the following code snippet:
doInJDBC(connection -> {
try (PreparedStatement statement = connection.prepareStatement(
"SELECT * " +
"FROM post AS p " +
"JOIN post_comment AS pc ON p.id = pc.post_id " +
"WHERE " +
" p.id BETWEEN ? AND ? + 1"
)) {
statement.setInt(1, id);
statement.setInt(2, id);
try (ResultSet resultSet = statement.executeQuery()) {
List<Post> posts = toPosts(resultSet);
assertEquals(expectedCount, posts.size());
}
} catch (SQLException e) {
throw new DataAccessException(e);
}
});
When joining many-to-one or one-to-one associations, each ResultSet record corresponds to a pair of entities, so both the parent and the child can be resolved in each iteration.
For one-to-many or many-to-many relationships, because of how the SQL join works, the ResultSet contains a duplicated parent record for each associated child.
Constructing the hierarchical entity structure requires manual ResultSet transformation, and, to resolve duplicates, the parent entity references are stored in a Map structure.
List<Post> toPosts(ResultSet resultSet) throws SQLException {
Map<Long, Post> postMap = new LinkedHashMap<>();
while (resultSet.next()) {
Long postId = resultSet.getLong(1);
Post post = postMap.get(postId);
if(post == null) {
post = new Post(postId);
postMap.put(postId, post);
post.setTitle(resultSet.getString(2));
post.setVersion(resultSet.getInt(3));
}
PostComment comment = new PostComment();
comment.setId(resultSet.getLong(4));
comment.setReview(resultSet.getString(5));
comment.setVersion(resultSet.getInt(6));
post.addComment(comment);
}
return new ArrayList<>(postMap.values());
}
The JDBC 4.2 PreparedStatement supports only positional parameters, and the first ordinal starts from 1.
JPA allows named parameters as well, which are especially useful when a parameter needs to be referenced multiple times, so the previous example can be rewritten as follows:
doInJPA(entityManager -> {
List<Post> posts = entityManager.createQuery(
"select distinct p " +
"from Post p " +
"join fetch p.comments " +
"where " +
" p.id BETWEEN :id AND :id + 1", Post.class)
.setParameter("id", id)
.getResultList();
assertEquals(expectedCount, posts.size());
});
In both examples, the object-relation transformation takes place either implicitly or explicitly. In the JDBC use case, the associations must be manually resolved, while JPA does it automatically (based on the entity schema).
2.7 Wrap-up
Bridging two highly-specific technologies is always a difficult problem to solve. When the enterprise system is built on top of an object-oriented language, the object-relational impedance mismatch becomes inevitable. The ORM pattern aims to close this gap although it cannot completely abstract it out.
In the end, all the communication flows through JDBC and every execution happens in the database engine itself. A high-performance enterprise application must resonate with the underlying database system, and the ORM tool must not disrupt this relationship.
Just like the problem it tries to solve, Hibernate is a very complex framework with many subtleties that require a thorough knowledge of both database systems, JDBC, and the framework itself. This chapter is only a summary, meant to present JPA and Hibernate into a different perspective that prepares the reader for high-performance object-relational mapping. There is no need to worry if some topics are not entirely clear because the upcoming chapters analyze all these concepts in greater detail.