MVP for Gen Z Dev
This section will try to define what should be the MVP for a Generation Z Developer.
MVP is a term used regularly in the software development industry to mean Minimum Viable Product, and it represents the minimum set of features and capabilities that a particular product/release/version should have in order to add value to the end users/customers.
From a Gen Z Dev point of view (i.e. you the reader), the technologies and workflows described in this section are key to make you highly productive and effective team player.
Although you might not use them all in your day-to-day activities, it is very important to understand what they are and why they where created in the first place.
In this section I will try to give you ideas on practical steps you can take, and here is first one:
TASK: Write blog posts with your experiments and challenges in understanding and using these ideas, technologies or workflows.
Drop me a link to these posts so that you have at least one reader :)
Note: Best way to do it is via a twitter mention (i.e. tweet with a link to the article and my twitter handle tag @DinisCruz)
Creative Commons
Deciding which license you choose to share your work with is one of the most important decisions you make in your professional life.
You can either go down a path where you think everything you create (outside paid work) is super precious and needs protecting or you soon realise that your ability to think about ideas, and (more importantly) to execute upon those ideas, is extremely valuable.
Often, with the former approach you may be afraid that your ideas will be copied so you don’t share them. In the latter approach you are happy to share your ideas as much as possible.
The best way to share your ideas and way of thinking is to release your content and ideas under a Creative Commons Copyright License
So what is Creative Commons (CC)?
Let’s start by looking at the definition of Creative Commons from Wikipedia:
A Creative Commons (CC) license is one of several public copyright licenses that enable the free distribution of an otherwise copyrighted work. A CC license is used when an author wants to give people the right to share, use, and build upon a work that they have created. CC provides an author flexibility (for example, they might choose to allow only non-commercial uses of their own work) and protects the people who use or redistribute an author’s work from concerns of copyright infringement as long as they abide by the conditions that are specified in the license by which the author distributes the work
Basically, this license defines the rules of the game that are applied to the content that you publish. By releasing your content under this license (and your code under Open Source) you are sending a strong message of your values and positioning. You are also maximizing the potential for your ideas to be far reaching and impactful. Like Steve Jobs said in his Stanford Commencement address in 2005 “…you can’t connect the dots looking forward; you can only connect them looking backward. So you have to trust that the dots will somehow connect in your future…“ , you could be generating a number of opportunities for your future self, or you could even be teaching something to your future self (it’s amazing how much we forget over time)
Creative Commons license variations and this book
This book is released under the Creative Commons Attribution 4.0 International (CC BY 4.0) which defines the following terms (see website):
You are free to:
- Share — copy and redistribute the material in any medium or format
- Adapt — remix, transform, and build upon the material for any purpose, even commercially.
Under the following terms: - Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your intended use as licensee.
The licensor cannot revoke these freedoms as long as you follow the license terms.
No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
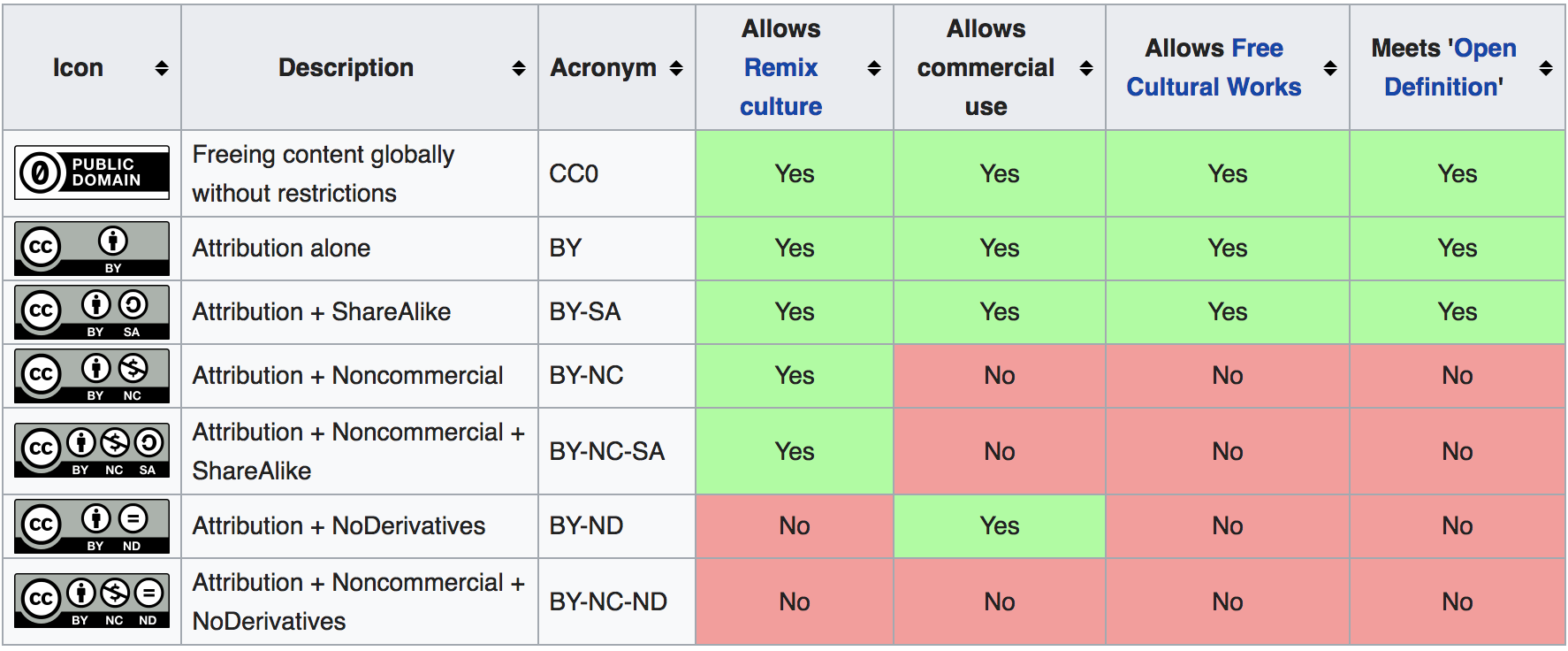
Although all CC licenses allow content to be shared, some have more restrictions:
- Attribution-ShareAlike 4.0 - need to attribute and use the same CC license (this has a ‘viral’ effect since it forces changes to also have a CC license)
- Attribution-NoDerivatives 4.0 - need to attribute and prohibits the sharing of adaptations of the material
- Attribution-NonCommercial-NoDerivatives 4.0 - need to attribute, prohibits sharing of adaptations of the material and requires approval/permission from the rights holder before being permitted to be used commercially
I don’t like the licenses above since they put restrictions on how the content can be used (which is against my views of sharing) but for companies or individuals that are new to CC, these are good first steps.
For reference here is a table which shows the various types of Creative Commons licenses:
Obscurity is your biggest threat
Tim O’Reilly on Piracy is Progressive Taxation, and Other Thoughts on the Evolution of Online Distribution provides this amazing quite: ‘For a typical author, obscurity is a far greater threat than piracy.’.
What this means is that you have more to lose by not publishing your ideas, music, or art.
Creative Commons is changing science
Ironically, the majority of modern science was built on the principle of sharing ideas, cross-verification and healthy challenges of assumptions/theories. But for a while, science (due to a number of reasons) started to become a closed world, with large amounts of information and data only being available to a selected few.
Good news is, in the last decade this has started to change. I think a big part of it was caused by the cross fertilization of practices brought to science by developers who were exposed to the Open Source workflow (and culture and effectiveness) and help to push for a much more open and collaborative environment between teams. See for example the collaboration of code and data-sets that is happening on areas like cancer research.
Also, amazing is the massive amount of data that is being shared today by government agencies. See these books for amazing info-graphics created from this data:
- Information is Beautiful
- Visualize This: The FlowingData Guide to Design, Visualization, and Statistics
- Knowledge is Beautiful
See the https://data.gov.uk/ website for data-sets provided by the UK Government (released under the Open Government Licence which is compatible with Creative Commons Attribution License 4.0 )
It is key that you learn how to play in this world where massive amounts of data is available. Increasingly so, there is a moral and technical argument that all data created by government should be released under a Creative Commons license, and all code paid by the government should be released under an open source license. Think about the implications that this would have on industries and professions that rely on data to make decisions.
The importance of creating commercially viable models
Note that this doesn’t mean that there should not be any financial return from sharing your ideas or content.
I’m a big believer that for any trend to scale and become sustainable, there needs to be a working economic and financial model behind those open workflows.
Basically, authors should be paid for their work.
Also, it is key that the operational teams that support those authors are also paid (for example Wikipedia or Mozilla have highly skilled and well paid professionals working as employees).
Sometimes the payment is hard cash (i.e. the authors/teams are paid to create that content). Sometimes the ‘payment’ happens in terms of: future opportunities, personal development or karma points (i.e. doing the right thing or sharing knowledge with others the same way it was shared with you).
One of the big myths behind open source and Creative Commons is that its authors are all working for free in their bedroom by amateurs. In reality most of the value is created during paid jobs, by highly skilled professionals, with companies supporting the creation of the released code or content.
It is harder than it looks
Don’t let your perception prevent you from publishing content you deem of little value. This Impostor Syndrome effect can be very damaging and paralyzing, and you need to take a pragmatic view of what would happen if you do share.
- If what you wrote is not that interesting or valuable to others, then you will have a small number of readers but will have gained valuable knowledge and experience which you can use to help you write your next publication
- If what you have created does get some readers and more importantly, feedback or comments, then you gained a bit and moved the needle a little bit (remember that it is all about incremental gains, and there is no such thing as ‘overnight success’)
The bottom line is: publishing your research under a CC license is harder than it looks.
You actually have to do it, and remember that taking the first step is often the hardest part.
Doing that journey under a Creative Commons path, means that you have shifted your paradigm from closed to open. It means that you now view your value as someone who can execute ideas (and is happy to share your creations).
Anybody can have ideas, execution is the hard part.
Align your future with Creative Commons
Finally, when choosing which company to work for, take into account their current Creative Commons and Open Source strategy culture for internally developed technology ideas. This should have an impact on your choices.
In most companies, only a very small part of what they create should be closed and proprietary. The rest should released under open licenses.
Remember that in these modern times, especially in technology, it is not uncommon to change jobs regularly. You really want to make sure you still have access to those ideas and code when you move; there is nothing more soul-destroying than having to re-do something you have already created or not having access to good ideas you had in the past.
Open Source
The first thing to learn about Open Source is that it is not just a licence to release software or a way to get code for free (as in no cost).
Open Source is a way of thinking about code and applications, in a way that there isn’t an explicit ‘lock-in’ on the user by the creator. When code is released under an Open Source license, the consumer of that code (namely the developer) gains a number of very important freedoms which have been proven to create very effective and powerful development environments.
You use Open Source applications and code everyday, can you name them?
There is nothing you can do today on the Internet that doesn’t touch some Open Source code, and the amount of code that is currently available to you under an Open Source is insane.
An Open Source licence is a copyright license that gives you the right to access, modify and distribute source code. This is a variation of what has been called an Copyleft license. Copyleft is actually an Copyright license based on the idea of giving away rights to the user, instead of the most common use of Copyright, which takes right’s away.
Think and behave in an Open Source way
As with the Creative Commons license, Open Source is a way of thinking and behaving about code.
You as a developer should be releasing everything you do with an Open Source license. This will make sure that your ‘future self’ can still access that code, while maximizing the potential usage and exposure of that code.
You should also be an active contributor to Open Source projects!
Not only you will learn a lot, that participation can really help you in finding a job.
If you are able to get your code changes approved and merged into the code-based of popular Open Source projects, you show the world the quality of your work and communication skills. I can guarantee to you that adding to your CV mentions of these contributions will immediately give you a lot of respect by your peers and interviewees. In fact a great way to get a job in a company is to contribute to an Open Source project hosted by that company.
Who uses Open Source

As you can see from the image above just about everybody is using Open Source these days, on all sorts of industries and use cases. Even Microsoft who used to call Open Source a cancer, eventually changed paradigm and now claims to ‘love linux’ and has recently bought GitHub.
History
Open Source is an idea created 20 years ago (in a meeting on February 3rd, 1998) with a number of heavy weights of the Free Software movement, who had the objective to create a common language and framework (and license) to be used by the community.
This lead to the creation of the Open Source Initiative who approves multiple community created Open Source Licenses.
One of the challenges that the Open Source license tried to address, was the more aggressive and viral nature of the GPL (General Public License). GPL requires that the developer’s release under the same GPL license, all code that uses or modifies the original GPL code.
Basically, once you add some GPL code to you app, you also need to release that app under GPL. In practice this proved to be to restrictive to the adoption of lots of libraries and applications. Even worse, that limitation went against what most Open Source creators want, which is the wide and seamless use of their code
Here is an definition of Open Source software from Wikipedia:
Open-source software (OSS) is a type of computer software whose source code is released under a license in which the copyright holder grants users the rights to study, change, and distribute the software to anyone and for any purpose. Open-source software may be developed in a collaborative public manner
If you look at the arc of history, there is a tendency for code to be open, even when there are massive forces that don’t want that (i.e. the companies selling proprietary/closed-source software).
In addition to efficiency, innovation, reduced lock-in and better collaboration, Security is one of the reasons we need the code to be open.
At least when code is open and available, we have the ability to check what is going on, and be much more effective when reviewing its security (see Reflections on Trusting Trust for more on trust chains).
Note that this doesn’t mean that Open Source software is auto-magically secure just by being Open Source (we still need an ecosystem that rewards or pays for security reviews and secure development practices)
Another major evolution in the history of open source was its effect on companies like Google and Facebook, where Open Source applications and code where a major contributor to their scalability and success.
Open source business models
It is amazing to see the change in the industry and thinking around Open Source. In early days of Open Source, me and many others were called ‘communists’, just by defending that code and ideas should be shared and made free.
These days there are tons of business models that have been proven to work on top of an Open Source models. For example here are 12 examples :
- Software Support Business Model, Software Services Business Model, Software as a Service (SaaS) Model
- AdWare Business Model
- Consulting Services, Independent Contractors/Developers, Indirect Services & Accessories
- Proprietary Software Model, Premium Software Model, Dual Licensing Model, Hybrid Model, Public Domain Model
- Platform Integration Services, Hardware Integration Model
- Non-Profit Business Models
- Defensive Business Model/Strategy
For Open Source to scale and be sustainable in the long term, it has to be supported by an viable economic model (one where there is a positive feedback loop of value for its creators and maintainers). These examples of Open Source business models (and the successful companies/services that use them) are behind a significant number of the open source contributions that we see today. Of course that there are other forms of receiving value form contributing to Open Source, namely learning something new, contributor brand enhancement or even just purely the joy we get from sharing knowledge.
In a weird way, the Open Source revolution has happened, most of the key battles have been won, but a large number of Gen Z are not aware of it (and are not poised to benefit from these business models and strategies). The danger is that there is still a lot of to do in the Open Source world and we need the Gen Z to be a big driver and innovator.
Releasing code under an Open Source license
Question: ‘Why don’t you open source your code?’. I bet the answer is a combination of:
- “I don’t think my code is good enough”
- “I’m embarrassed about my code”
- “Nobody will want to use my code”
The first thing to understand is that I have heard these same excuses from all sorts of developers and companies, for code in all sorts of quality and completeness.
This is your Lizard brain in action (making excuses of why you shouldn’t do something)
The key is to just do it!
Create a GitHub or BitBucket repo, add the license and start building your community.
So how do you Open Source some code?
- Create a repo and add code to it
- Add file containing an Open Source license
- That’s it!
And then, after you Open Sourced your app or code, what will happen next is: Nothing!
The reality is that it is very hard to create a community around an open source project (most open source projects have been created and are maintained by a very small number of developers)
What you will have done by adding the license file to your code, is to create future opportunities for that code and sent a strong message about your agenda (i.e. you are not going to lock in the future the users that are using your current code today):
- you are allowing somebody (which could be you) in the future to use your code
- you are also protecting your research, so that if you move companies, you can still use that code (there is nothing worse for a programmer than to having to rewrite something that was working ok (specially when it is a framework that supports a particular workflow)
I believe that we have moral imperative to share our ideas. I don’t want to be the one that close ideas and don’t let other benefit and learn from them. These days everything you do is a variation of what somebody has done before (i.e. you are adding an incremental change), after all you are sitting in shoulders of the giants that come before you.
Open Source as a way for companies to collaborate and find talent
There has been big success stories of companies collaborating internally externally (i.e. internal collaboration between different teams via open source code)
Ironically, although most developers have internal access to all code, the number of cross-team pull requests is very low. Publishing the same code under an Open Source license will help a lot in its internal reach, usage and collaboration.
This also means that by allowing others to use their code, cleaver companies are creating a great way to find programmers to hire (or companies to buy). As a developer you should take advantage of this and be an active contributor on the open source projects of the companies you want to work for (this is a great way to meet the key developers from those organizations, which might turn up to be key decision makers in your job application)
Open Source as a way to define the agenda
When I see code (or applications) that are not released under an Open Source license, namely the scenarios when the application is provided for ‘free; (as in zero cost, not as in freedom), I always think ‘What is their agenda?’, ‘Why are they not Open Sourcing the code?’, ‘Is this a plan to hook the users, make the dependent on the technology and then start charging at a later stage?’.
When the companies (or authors) release code under an Open Source license they allow their users to have the ability (if they want) to control their own destiny.
Although hard to quantify, I have seen lots of examples where much better engineering decisions have been made due to the fact that ability to lock the user in restrictive licenses is not there.
The Cathedral and the Bazaar
As with many others, my paradigm shift into an Open Source mindset happened 20 years ago after I read the The Cathedral and the Bazaar essay and book, where Eric Raymond provides 19 lessons which are still as relevant today (2018) as when they were published (1998).
Here are some of the best ones:
- Every good work of software starts by scratching a developer’s personal itch.
- Good programmers know what to write. Great ones know what to rewrite (and reuse).
- Release early. Release often. And listen to your customers.
- Given a large enough beta-tester and co-developer base, almost every problem will be characterized quickly and the fix obvious to someone.
- If you treat your beta-testers as if they’re your most valuable resource, they will respond by becoming your most valuable resource.
- To solve an interesting problem, start by finding a problem that is interesting to you.
In the book Eric compares the creation of proprietary applications to an Cathedral and the development of open source to an Bazaar.
In Eric’s view, Cathedrals are: massive and expensive undertakings, take ages to create, don’t have much innovation (apart from a couple major areas), have all sorts of top-down management problems, are super expensive , don’t usually work very well (for the intended purposes) and don’t usually turn up the way they were originally designed.
On the other hand the Bazaars behave like living organisms, always innovating and with always somebody somewhere trying something new.
I actually prefer to see the beauty in both Cathedrals and Bazaars. Each has it magic and situations when they are exactly what is required.
What I find interesting about this analogy, is that with the understanding that we now have of developing software in ways that are super-effective, that promote continuous refactoring and that are constantly deploying one small/medium change at the time (which is what we get from effective TDD and DevOps environments), we can actually ‘build amazing Cathedrals out of Bazaar’ (i.e. create an Cathedrals by continuously refactor and improve what started has an Bazaar).
This goes to the heart of what I have noticed in effective development environments with crazy-high code coverage: ‘the more code and capabilities are added to the application, the faster changes can be made’ (which is the opposite of what happens in a lot of projects, where the higher the quantity of code, the slower everything becomes).
Docker
As a developer it is critical that you understand how Docker works and how it became so successful and widely used. Docker is one of those revolutions that occur regularly in the IT industry where the right product comes at the right time and meets a number of very specific pain points for developers.
From a practical point of view, Docker makes it very easy for you to try and use a wide variety of applications and environments. For example you can start a local (fully working) instance of the ELK Stack (Elastic search + Logstash + Kibana) in Docker, simply by running the sudo Docker pull sebp/elk command (without installing anything on your host machine).
The first time I saw and used Docker, I was massively impressed by its simplicity and its potential to change how applications are developed and deployed.
To understand Docker and its power, the first concept to master is how Docker is a “process that exposes a multi-layered file system as an fully isolated OS”
It is easy to see Docker as just a faster VM environment or a faster Vagrant (which is a way to programmatically create VMs). I’ve seen companies that having automated VM deployments to a significant extent (i.e. they become really good at automating the creation and deployment of multi-gigabyte VMs) completely dismissed Docker as just another IT fad.
The problem is that Docker is much more than just a faster VM and by fast, I mean super-fast. VMs typically take several minutes to fully boot in to a ‘ready state’; Docker can give you a fully functional Ubuntu instance with Node installed in sub-second start time (just run Docker run -it node bash and when inside the Docker container run node -e 'console.log(20+22)').
Docker starts in second(s) because it is just a process. The magic sauce is created by:
- a number of Linux kernel technologies that are able create a sandboxed environment for that process (for files and network access and other key parts of the OS)
- a layered file system, where each layer contains a diff of the previous layer. This is a powerful graph db, where each file location is dynamically calculated when you are inside the Docker image. Basically what is happening is that each layer is immutable, and when a file is changed inside Docker it is either a) saved as a new Docker image or b) discarded when the Docker image stops. A final ‘Docker image’ is just a collection of multiple images, all stacked up, one on top of the other.
Kubernetes
Say you want to:
- use multiple Docker images in parallel (for example an image for the web server, an image for file system and an image with a database) or
- Start multiple images at the same time (for example a web server behind a load balancer)
You will need to start looking at what are called ‘orchestration technologies’.
The Docker team has published light orchestration frameworks called Docker Compose and Docker Swarm. Whilst both solutions are relatively effective and have their share of pros and cons,Kubernetes is by far the most widely used container orchestration mechanism in production environments.
Kubernetes (sometimes also called K8) was actually developed by Google and was inspired by Google’s Borg. The Borg is one of the key reasons why Google was able to massively scale services like its web search and Gmail. Everything at Google is a container and as early as 2014 Google claimed to be starting two billion containers per week
Kubernetes allows the codification of an application environment thus addressing requirements such as deployment strategy, scalability, container hygiene and tracking etc.
This is very powerful, since it allows you to basically say: “I want x number of pods (i.e. web servers and database) to always be available, and if they stop, make sure they are restarted (and configured accordingly)”
The reason why it is so important to understand this is because you need to evolve from creating environments by manual ‘button clicking’ to codifying your service delivery environment (which is just a higher level of programming abstraction layer).
Note that you also get a similar workflow with tools like AWS CloudFormation
One easy way to give Kubernetes a test drive is to use AWS EKS
Security advantages
From a security point of view, Docker has clear advantages.
The first is an explicit mapping of what needs to be installed and what resources (e.g. ports) need to be made available.
Docker also makes it possible to safely run 3rd party code in isolated (i.e. sandboxed) environments, where malicious code running inside a Docker container, would not have access to the current host user’s data. This is actually the future of desktop and server-side apps where simple external (or even mission critical) service/code is executed inside containers.
Testing and visualizing Docker
One area where we are still quite immature, as an industry, is the testing of Docker images and Kubernetes setups.
There aren’t enough good tools, IDEs and Test Runners for Docker and Kubernetes. Basically we need a Test Driven Development (TDD) workflow for Docker development!
If I were you, this would definitely be an area I would focus my research on (while blogging about your efforts).
Another great research area is the visualization and mapping of Kubernetes environments (i.e. who is speaking to who, and how is that traffic authenticated and authorized). See Weave Scope - Troubleshooting & Monitoring for Docker & Kubernetes for an interesting Open Source project in this space.
You would have a big competitive advantage in the market place if you understood these concepts and had practical experience at implementing them.
It all stated with physical containers
For a great introduction to Containers see MAYA Design’s Containerization animation, and the Wendover Productions’ Containerization: The Most Influential Invention That You’ve Never Heard Of video
To see what is coming next see MAYA Design’s Trillions - video and the Trillions: Thriving in the Emerging Information Ecology book
Jira
Jira is a web application that is widely used by development, engineering and technical teams to manage their day to day tasks and activities.
There is massive worldwide adoption by all types of companies, and we (at Photobox Group Security) use Jira extensively in our day-to-day. We use it for example to manage: vulnerabilities, risks, task management, incident handling, OKRs management, asset register, threat modeling, data journeys and even to create an pseudo org chart for the stakeholders of risks.
To make this work we are very advanced users of Jira, where we create tons of custom Workflows and even write custom applications that consume Jira’s APIs.
We basically use Jira as an graph database and Confluence as a way to display the information stored in JIRA. See the Creating a Graph Based Security Organization presentation for more ideas on how we do this.
The key point I want to make here is: in order to make the tools that we use in the enterprise work, they need to be customized and extended.
Being able to write these customization’s and understanding at a much deeper level what is possible with these tools, when compared to ‘normal’ or ‘power’ users, is a massive competitive advantage. Customizing and extending tools should not be seen as an exception, it should be the rule.
The reason this scales is due to the compound effect (i.e. increased returns) of the features implemented. The changes/features we make today, will make us more productive tomorrow, which will help us to make more changes, which make us even more productive.
In fact as a developer, if you are able to write custom JIRA workflows that are usable by your team, that will be another competitive advantage for you, and it will make you highly employable today.
Reality is the complex one
It is important to note that once the complexities and interconnections of reality start to be mapped in Jira, it can be very overwhelming.
For example we use Jira heavily in our incident handling process, where we can easily create 100+ issues during an incident, with each issue being a relevant question or action to be answers or executed during the incident. It is easy to look at that setup and think that it is too complex and a massive bureaucracy. But in reality that combination of issues (of type: Incident, Task, Vulnerability and Epics) is an accurate representation of the complex reality and massive amount of information that is created during an incident. The alternative are completely unmanageable and unreadable email, slack threads or word docs).
All the work comes together via powerful up-to-date Confluence pages (which we convert to PDFs and distribute via slack/email) to answer the key questions of: ‘What has happened?’, ‘What are the facts?’, ‘What are the hypothesis we are exploring?’, ‘What is happening now?’ and ‘What are the next steps?’. This is how we keep everybody involved in sync, and how we provide regular management updates.
The other big advantage of this setup is that it allows us to do very effective post-incident analysis and to create playbooks with predefined tasks to be executed when a similar incident occurs in the future. Basically our playbooks are not a word document with tasks and actions, our playbooks are a lists of Jira Tasks that are used to populate the incident set of tasks.
For more ideas about this topic see the SecDevOps Risk Workflow book that I’m also writing and the SecDevOps Risk Workflow - v0.6 presentation .
Use Jira in your life
Create Jira projects for your life activities, with Epics to track group of tasks.
Create a Kanban board for your personal tasks and Epics.
Create custom workflows and learn how to manage Jira. This will give you tons of confidence when using Jira in the real world or when intervening.
And since Atlassian has evaluation version for their cloud version of Jira, there isn’t any cost to try this. You have no excuse for not using Jira before, at a level more advanced that most corporate users and the developers interviewing you.
What makes Jira so powerful
Although Jira has tons of really annoying features and bugs, its feature set is very powerful. With finely tunned process and customization’s it will make the difference on your productivity and will change how you work.
Here are some of Jira’s really powerful features:
- Issues - that can be easily linked to each other (i.e. nodes and edges)
- Links - which can be named, and allow the creation of named edges, for example ‘RISK-111 is-created-by VULN-222’
- Workflows - state machine environment where the issue’s status can be visually mapped and powerful buttons be created, for example for status transitions like ‘Accept Risk’
- Activity logging - ability to log every change and status transition
- Labels - ability to apply all sorts of loosely created labels/tags to issues (we use this to help managing specific workflows, for example by adding the ‘Needs_Risk_Mapping’ label to an issue)
- Components - ability to map issues to components which map directly into business’ areas or applications
- Kanban boards - powerful way to view the current tasks and what status they are
- Dashboards - ability to create all sorts of diagrams and tables from Jira data (although we tend to use Confluence for data visualization)
Its all about People, Process and Technology
In order to create a successful Jira environment, the ‘Technology’ part, we have to start with the ‘People’ part (in this case you). It is the mindset of the individual user that helps to kickstart these workflows.
The ‘Process’ of how things work is the other key element. I found it’s very hard for participants to really ‘get’ these processes and to really understand at a deeper level how the hyperlinked graph-based architecture works. By nature there will be a lot of changes, not only of past workflows, but of existing workflows. Change is the only constant.
Ironically this means that Jira is not key to make this work.
I have built similar systems using GitHub.
Although GitHub doesn’t have some of the most advanced features of Jira (like workflows), the fact that GitHub has native Markdown support, that all content is managed using git and that it is super fast, makes it also an effective graph database.
With the right People and Process, lots of Technologies can be used to make this work. As long as they can be used a Graph Database with every piece of data being available in an hyperlinkable way
OWASP
OWASP (the Open Web Application Security Project) is a worldwide organization focused on Application Security. We are the good guys that are trying to make the world a safer place :)
I have been heavily involved in OWASP for a long time, and it is one of the more open, friendly, knowledgeable and carer-enhancing communities you can find. I’ve meet some of my best friends in the industry though OWASP and what I’ve learned from its projects and events is too long to list here :)
There are many ways that actively participating in OWASP will make you a better developer and enhance your carer. Part of building your brand, skills and network is the participation in Open Source communities, and OWASP is a a perfect place to do that.
The first place to start is your local Owasp Chapter. With 100s of chapters worldwide, you shouldn’t be to far from one (if not then start one, the London Chapter started many years ago over beers in a London pub). Attend a chapter meeting, learn something new and create connections.
Next step is to check out the OWASP projects and see which ones are relevant to your current work/research, and more importantly, which ones you should be involved as a contributor. Most OWASP projects, even the bigger and most successful ones, are usually maintained by only a couple individuals, and ALL projects are desperate for contributors and help! It is not that hard to start, just fork the project in GitHub, see the open issues and start sending the Pull Requests.
Check out the main OWASP Conferences and events like the Open Security Summit which are amazing places to learn and meet highly talented professionals, all happy to share knowledge and teach.
Finally, join up OWASP Slack where you will find everybody and 100s of channels dedicated to everything OWASP related (projects, chapters, conferences, topics)
Find jobs via OWASP contributions
Due to its open nature and focus on finding solutions for hard problems (related to application security), OWASP’s community is made by the ‘doers’, i.e. the ones that actually get things done at companies and know what they are doing.
This means that regardless if you want to want to get a job in an security team, active participation in OWASP projects is a perfect and very effective way to meet individuals that can help you find the job you want.
That said, there is a massive skills shortage in the market for Application Security specialists. The main reason is because you can’t really do Application Security unless you have a developer background. My advise to all developers I meet, is to seriously consider an Application Security carer. Not only it is an industry that is on a massive growth curve, it really needs new talent, energy , development skill and ideas.
Python
Python is great language to master since it contains a large number of the key development paradigms that you need to know, while being easy to learn and read.
Python started in 1991 by Guido van Rossum when he was 35 and the key focus was in making a simple but powerful language.
A great feature added early on was the REPL (Read Eval Print Loop) environment. This is what you see when you run python from the command line and get an interactive shell that allows the execution of Python code. That said, I don’t use the Python command line very often, since I have a similar (and more powerful) REPL environment using Python tests (and TDD)
Use Python for AWS automation
Even if you are not using Python as your main development language, due to it massive adoption and powerful ability to write small apps/function, you should use it often (for all sorts of automation tasks).
A perfect example of the power of Python is in the development of Serverless functions (executed as an AWS Lambda function) or in advanced customization’s of event-driven workflows (like the one provided by Zapier Python support)
The AWS SDK for python (boto3) is something you should spend quite a lot of time with and really explore its capabilities (while learning to take python into another level).
This API gives you access to just about everything you can do in AWS, and as a developer you need to really start thinking of AWS as an ‘app’ that you code your application on top of its capabilities. You need to get into the practice of writing code (driven by tests) vs clicking on things.
For example here is a code snippet that starts a virtual machine in AWS:
1 import boto3
2 ec2 = boto3.client('ec2')
3 instance_id = sys.argv[2]
4 response = ec2.start_instances(InstanceIds=[inst\
5 ance_id])
6 print(response)
Don’t click on things
Clicking on an UI with your mouse, is a non-repeatable, non-automated and non-scalable way to perform a specific task. What you want to do is to write tools, APIs and DSLs that allow the easy and automated execution of those tasks.
For example here is a python script that tests the execution of an Lambda function
1 def test_hello_world(self):
2 handler = 'lambdas.s3.hello_world.r\
3 un'
4 payload = {"name": "lambda-runner"}
5 expected_result = 'hello {0}'.format(payloa\
6 d.get('name'))
7
8 self.aws.lambda_create_function(self.name, \
9 self.role, handler, self.s3_bucket, self.s3_key)
10 result = self.aws.lambda_invoke_function(se\
11 lf.name, payload)
12 assert result == expected_result
Python for data parsing and analysis
Another really powerful use of Python is to perform all sorts of data parsing, modeling and analysis.
As a very practical real world scenario, if somebody sends me multiple excel documents with data to analyse, the first thing I do is to:
- export it to csv,
- use python to normalize the raw data into json file(s)
- use an data visualizing tool or API (for example ELK, Neo4J or visjs).
This is not very hard to do, and is faster then trying to make sense of the excel documents (namely when needing to do data correlation between different excel sheets or files)
Slack and ChatOps
It is easy to underestimate Slack’s capabilities, not realise that Slack is a massive agent for change, and that Slack’s empowered workflows will play a big part in your future as a developer.
Initially Slack might look like just an evolution of instant messaging tools like: Skype, MSN Messenger, SMS, ICQ, IRC or Smoke Signals.
The reason why Slack in a relative short period (5 years) gained such adoption and traction, is because its features enable organizations and communities to not only to change how they communicate, but how they behave. Namely how they understand what is going on and how they respond to events.
Effective Communication and alignment are not only key competitive advantages of successful organizations, but are usually the reason they succeed or fail (see “Aligning vectors” presentation for more details).
Slack provides an Asynchronous data/information exchange environment that can be at the epicenter of the multiple actors involved in the organization ecosystem: humans, bots, servers, applications, services and events.
The potential for change is enormous, although at the moment, most companies are only taking advantage of about 10% of Slack’s capabilities. In most organizations Slack is at the ‘replacing email’ stage, which quickly is followed by the ‘too many channels’ and ‘how do find what is going on without having to read a gigantic slack thread’ phases (which can have diminishing returns)
The important question for you is: “Are you going to take an active and proactive role in making Slack work for an organization?”. I can guarantee you that if you have hands on experience in the ideas and techniques described in this chapter, you have just increased your competitive advantage and employability.
Why was Slack successful?
Slack’s success is a great case study of the power of marginal gains, where a large number of 1% improvements created an spectacular platform (for another great example 1% marginal gains the see the British’ cycle success on How 1% Performance Improvements Led to Olympic Gold where they talk about the power of marginal gains, based on 3 areas: strategy, human performance and continuous improvement).
Here are some of the features that Slack added that (in aggregation) made a massive difference:
- Copy and Paste of images - this ‘simple’ feature massively improves the user’s workflow and ability to communicate (It still amazes me how companies don’t realise that there is a massive usability difference between copy and pasting an image and having to upload an image). If I remember correctly this was one of the reasons I started to like Slack
- Effective use of Emojis - not only for emotions (happy/sad/angry/laughing face) but for actions/decisions (yes/no, ok, ‘read document’, ‘need more details’)
- Great desktop application - with seamless integration with web and mobile (the desktop app is built of top of Electron)
- Effective search and shortcuts
- Drag and drop of documents - with ability to preview them in slack (for example pdfs)
- Auto previews of links dropped - like web pages, twitter links, videos
- Buttons and forms to drive actions - which allow the expansion/improvement of Slack’s UI by 3rd party apps/services
- 3rd party integrations and Native support for Bots
- Smooth and regular deployment of new features (audio and voice conferencing, single channel users, message reminders, message threads). Here is an example of a Same day fix which highlights the power of DevOps and Continuous Deployment
- Scalable backend with very few outages
- Application Security and Security usability
- Great culture and focus - see the Dear Microsoft Ad they run in Nov 2016 and the internal memo from July 2013 We Don’t Sell Saddles Here
All of the above combined (can) create a super productive environment. Your task is to be a ‘Slack master’ and lead the revolution :)
The big lesson here is that:
- high focus on where you add value, speed of delivery and adaptability of the direction of travel
beats
- a highly defined strategy
For a great example of changing directions, if you check out Slack’s history you will see that Slack actually started as an internal tool created by the company Tiny Speck while they were working on the Glitch game
Learn how to use Slack
As with every tool, you need to spend time in learning how to use it in order to be effective. It is very important to initially not be overwhelmed by the large number of channels and messages that you will get.
Fun fact, when things get quite heavy, sometimes we call it ‘Slack Tennis’ since there is so much stuff bouncing around in multiple channels that it fells like you are playing Tennis inside Slack.
Some practical tips:
- remove most Slack notifications
- mute chatty channels that don’t provide important information for your day to day activities
- do to not be afraid to leave a channel, since if you are needed, it is easy for others to bring you in with a mention of your name
- consume Slack under your terms, not when a message arrives and you receive a dopamine kick
Think of Slack as asynchronous communications, where there is a gap of time between when:
- a message is sent
- a message is received
- a message is processed (with our without a reply)
As with just about everything, the challenges are one of People, Process and Technology:
- People - you and and who/what you are communicating with
- Process - how Slack is used (conversions, workflows, human behaviors, response’s protocols/expectations, new users on-boarding, documentation)
- Technology - Slack and its integrations
The good news is that you have direct control over these three, and there is nothing stopping you from learning.
This is why your understanding and use of Slack is a major sign of your own values and skills.
There is no cost in learning and using slack in the ways I describe in this chapter.
If you don’t learn how to effectively use Slack, what is that telling about your drive, priorities, energy, desire to learn and ability to effectively use new technologies. Basically your competitive advantages in the marketplace is directly related to how you use Slack.
ChatOps
Let’s go up a gear and start looking at what makes Slack so powerful. I’m talking about Bot Integration.
Bots are basically applications (ideally setup in a serverless pipeline) that react or generate events. For example we could have a bot that:
- receives a notification from an live server (an CPU Spike, new deployment, or an particular user action) or from an 3rd party service (like email, twitter or CI pipeline)
- processes and (optionally) transforms it
- sends a follow-up slack message to a particular channel (based on a pre-defined set of rules)
- gets response from user (simple acknowledgement or action)
- reacts to that response
The concept that clearly explains this workflow is the ‘ChatOps’ idea, which was initially shared in the amazing ‘Chatops At GitHub presentation (see video here). For more recent presentations see Real World ChatOps , Revolutionize Your Workflow with ChatOps and Accelerating DevOps with ChatOps
One of the definitions of ChatOps is “a collaboration model that connects people, tools, process, and automation into a transparent workflow” that creates a Culture of Automation, Measurement and Sharing (CAMS). This basically means that ChatOps is at the epicenter of information and decisions flows.
A real world example is when you (as a developer) use Slack as a communication medium for what is going on (in your live servers, test’s execution or even build). But even more interesting, not only you can get data into Slack, you can issue back commands and influence what is going on.
Getting started
The best way to learn is by doing it.
Your first step is to create a Slack workspace so that you have a playground for your ideas. There is no cost to create new Slack Workspace, so what are you waiting for?
Make sure you invite your friends and colleagues to participate, so that you have a wide set of scenarios to play with.
To get you going here are a couple scenarios:
- write code that sends messages to a slack channel (simple HTTP POST requests with your Slack API key)
- follow GitHub’s footsteps and deploy and customize Hubot. Errbot is a Python alternative, and Slack’s tutorial shows an integration using Botkit
- write bot integrations with services like Zapier or IFTTT. See Zapier’s How to Build Your Own Slack Bot in 5 minutes guide
- write a serverless Slack integration using AWS API Gateway and Lambda functions
- write a Slack integration that automates one area of your life (maybe something to do with a task you do every day)
Join the OWASP Slack Community
OWASP (Open Web Application Security Project) is an very friendly open source community that has migrated a large part of its digital interactions to Slack (see OWASP chapter for more details).
I strongly advise you to join the Owasp Slack using this registration form.
Not only you will see examples of these integrations in real-world scenarios, in that workspace you will find a multiple Slack experts, who will be more than happy to help you. You can also find multiple opportunities (in OWASP project or chapters) to put your Slack integration skills in action.
When you join in, drop me a message saying Hi. I should be easy to find :)
Talking to yourself via Slack
As I mention in the Talking to yourself digitally chapter, the practice of capturing your thoughts and workflows is super important.
Slack is a great medium to do this, since it massively improves the workflow that we we usually have when using Word docs (or services like Evernote) to capture notes about what we are doing.
Here is the workflow I usually use:
- in Slack describe what I am going to try next
- do it
- take screenshot of the latest change
- in Slack paste the screenshot
- go back to 1.
This workflow is really powerful, because what you are doing is capturing how you are thinking about the problem you are solving (including all the tangents that you tried and didn’t work). And yes, very often, you will find that it is only you that (initially): asks questions, provides answers, learn from failures and celebrates successes.
One way to keep sanity is to remember that this information will be super useful one day to your ‘future self’, and that you now have the raw data / screenshots for a great blog post. This will help others to understand the steps you took, the challenges you had, the solutions that didn’t work, the solutions that did work, and how to arrived at the final result/conclusion.
This is also how you scale your knowledge and avoid having to answer the same question twice (specially when you create a blog post which makes it really easy to find that content)
A simpler version of this pattern is when you:
- ask a question in Slack
- find the answer
- reply to your own message with the solution
Use Slack when debugging code (as a log collector)
When you have a bug in your code that you don’t understand the root cause, a common practice is to use a Debugger, which will provide features like breakpoints and code stepping.
This just about works when you have direct access to the execution environment and you are looking at simple applications.
But as soon as you start working on distributed systems with lots of moving parts (for example with multiple web services and serverless functions), you stop having the ability to really understand what is going on (namely the exact sequence of events and what the data looks like in those intermediate states)
Slack gives you an environment to receive logs/messages from those internal execution flow and states. To make this scale, you should create helper APIs that make it easy to send and receive data from Slack.
As simple example, here is a Python method that I wrote to help me understand and debug AWS Lambda function’s execution:
1 send_to_slack('there are {0} missing ips'.format(le\
2 n(missing)))
3
4 ...(do something)...
5
6 send_to_slack('resolving {0} missing ips'.format(le\
7 n(missing)))
8
9 ...(do something)...
10
11 send_to_slack('resolved {0} ipdata ips'.format(len(\
12 ipdatas)))
Hugo
Hugo IO is a SWG (Static Website Generator that represents a very interesting twist on the development stack of a website (another popular Static Website Generator is Jekyll )
In addition to having a great environment to create content (and to maintain it), what hugo creates is a completely different paradigm shift on how to create and publish websites.
Basically an SWG pre-generates all possible web pages during the build stage …. and that’s it!
Once the build is finished (usually in less than a second), the entire content of the website is available in an local/CI folder, that can be easily deployed/copied/synced with any server or service that is able to host static files (for example AWS S3)
In practice this means that you have a website running from vanilla web pages, with no backed and no moving parts. Not only this is massively secure (no server-side code to hack), this has amazing performance implications (i.e. the site is super fast, when compared with dynamically generated sites).
“Why no backend?” Well … ask yourself the question: “Why do you need a database?” (i.e. What is the database actually doing, that you can’t pre-generated all in one go?)
It is amazing how in any real-world scenarios a database is not actually needed!
That said, Hugo is actually using a very efficient and scalable database and cache: The file system :)
I really like the pattern of using the file system as a database, specially when combined with git for deployment, and GitHub for CMS (Content Management System)
Hugo also makes it really easy to create (and understand) an CD (Continuous Deployment) environment. Since it covers the key steps required:
- build the site
- edit the site
- see changes
- publish/sync the generated files (to a server/service serving static files)
- (ideally you should also be writing tests, which I would do using: NodeJS, CoffeeScript, Mocha, Cheerio and WallabyJS)
Another key feature is the integration with LiveReload (which very important to experience in a practical/personal way). Assuming you have the editor and web browser side-by-side in your screen, Hugo+LiveReload creates an environment where you can see your content changes immediately reflected in the browser, in an quasi-real-time way (i.e as soon as the file is saved, the browser is reloaded and the new content in rendered)
Hugo is also a great case-study of how modern development techniques, technologies, and open source innovation create products/apis that are miles ahead of the competition, with killer features.
After using and developing all sorts of CMS (Content Management Systems), I have to say that it gives me a spectacular and highly-productive content creation/editing workflow.
I use Hugo a lot these days, in all sort of internal and external sites, here are some examples:
- The Open Security Summit 2018 website (https://open-security-summit.org/) is a highly complex data driven website (which will look like a database-powered site) that is entirely built on top of Hugo. All source code is available on this GitHub repo and the Hugo setup enabled 157 contributors to create 3575 commits
- The Photobox Group Security Site (https://pbx-group-security.com/) is a simpler example of a fully working Hugo site in action
- This book you are reading uses Hugo in two ways: 1) locally hosted website with a number of extra pages that helps to improve my productivity when writing the book (for example: an hugo-based search, and print-friendly pages), 2) markdown generation for Leanpub publishing (which adds a couple extra features like the ability to create the MVP table from the content of its child pages)
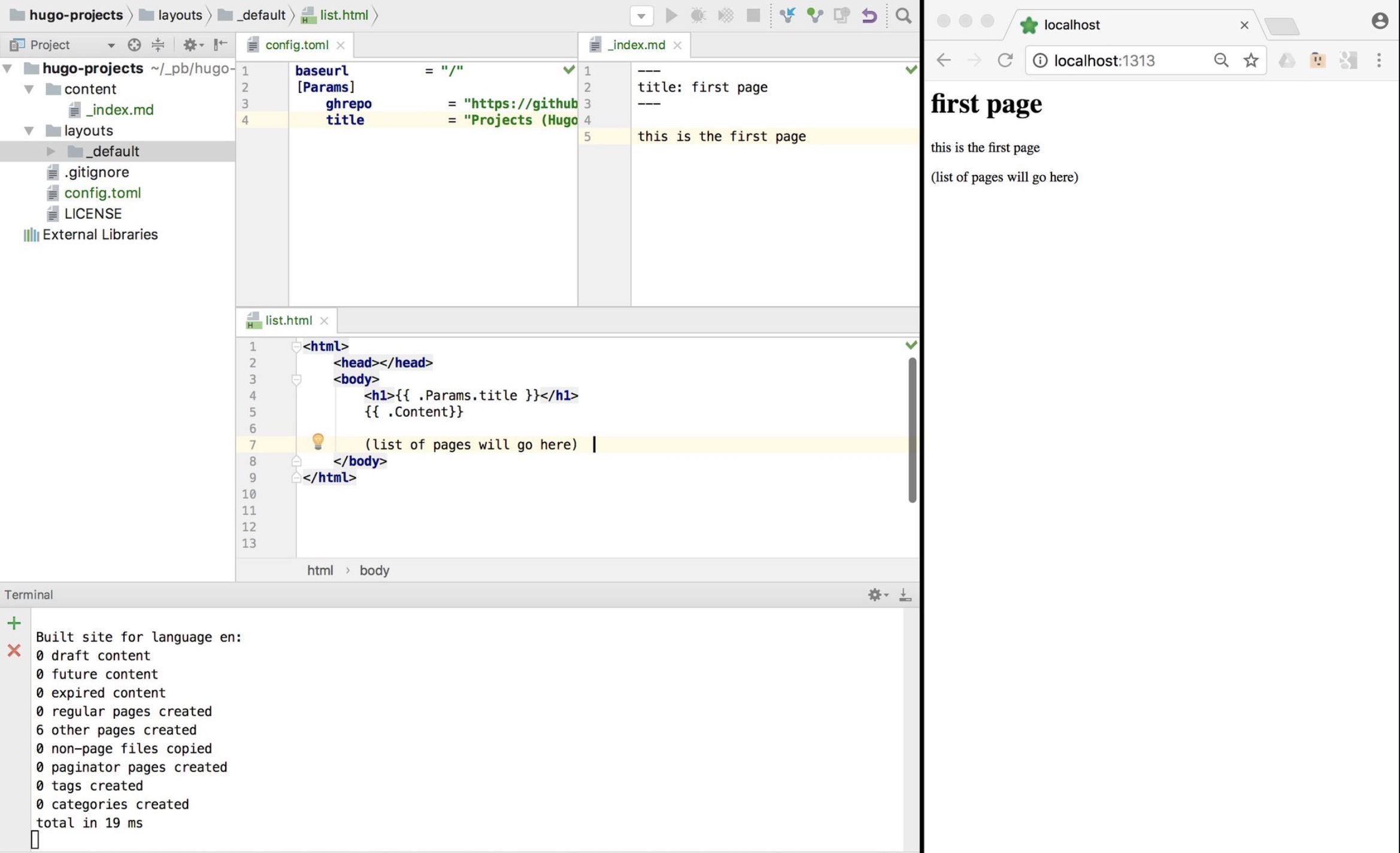
Simple example (MVP)
Here is simple example of my very first test of using Hugo where changes on the left are shown automagically on the right. I always start learning a new technology by creating the simplest possible version that works, i.e. an MVP.
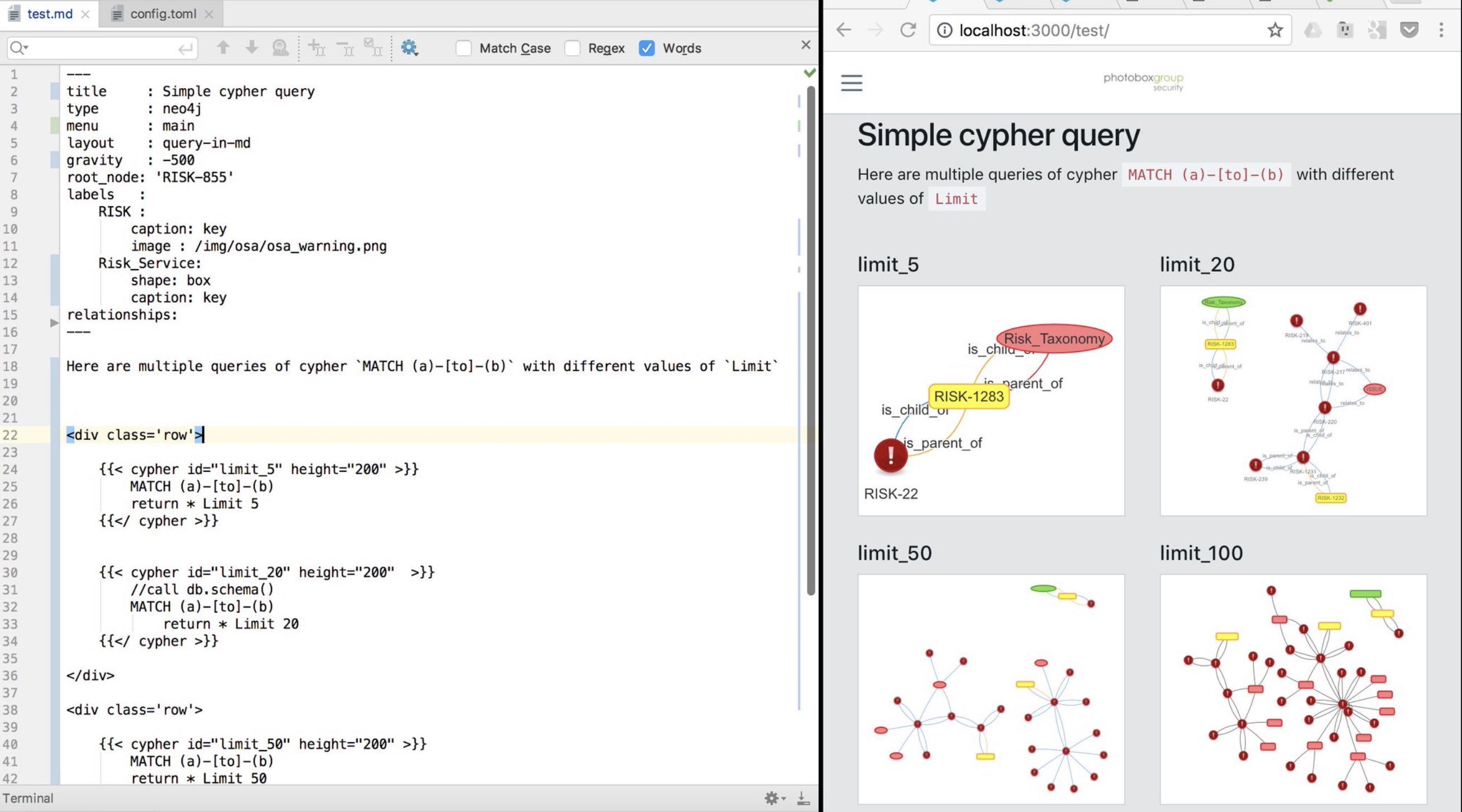
More advanced example (with graphs)
Here is a more advanced usage of Hugo, where we are using Hugo to create VisJs visualizations of Neo4J graphs populated from JIRA data
Do Static Site Generators scale?
Although I prefer Hugo to Jekyll, here are two amazing examples of using Jekyll at scale:
- HealthCare.gov - see It’s Called Jekyll, and It Works
- Obama’s fundraising website - see Meet the Obama campaign’s $250 million fundraising platform
Google Search, GDD and SRE
As a developer one of the most important skills you need to learn is how to GDD.
GDD stands for is Google Driven Development, and it is how every professional developer codes these days. Google’s search engine is so powerful and effective that when coding (and learning), Google’s Search Engine can point to the correct answers much better than anyone or anything else.
Why is Google Search so good?
Google’s search magic is created by the WebGraph inspired PageRank algorithm, which decides the order of the search results. One of the first major innovations of this algorithm was the use of a number of links to point to particular page as an indicator of the page relevance. The other major innovation was the feedback loop between what the users are clicking and the position of the link in the page. This means that every time you click on a link in Google, you are voting with your answer and teaching Google’s PageRank algorithm. To see this in action, notice when you copy the link of a Google Search result, the link is not to the page you want to see. The link is to a google service that will capture and store your choice. It is the capture of this data that allows Google to benefit from network effects and provide custom search results to each user. Yes, when you search for a particular topic you will get different results from somebody else.
Here is a challenge for you: “how can you prove that google shows different results for different users and in different geographical locations?”. To answer this question effectively, in fact based way, you need to programmatically detect changes in google’s behavior. To do this, write using a Cloud environment, an api /tool or set of serverless functions that: - is able to use Google.com to search for results from multiple IPs and geographical regions (in an pure anonymous way, and in ways that Google search engine can track each one of you ‘test users’) - captures the responses, namely the order of the link’s titles (my preference is to use services like S3 as a data store, for the raw data and any transformations done into JSON files) - visualizes and compare the results (my preference is to use ELK and Neo4J as visualization and analysis engines) - presents the data in easy to consume ways (my preference is to use Hugo to create a site that allows the easy navigation of the ‘story you want to tell’)
Also very interesting is the evolution of Google’s Search technology into an Knowledge Graph (which has been happening since 2010). The real power in Google’s search engine is the gigantic and hyperlinked graph (powered by machine learning) that is able to understand the meaning and intent of the queries made.
For Google Search, you are the product
The clever part of Google Search business model is their turning of the product (i.e. the users doing the searches) into actual ‘workers’ for Google. Remember that for Google, you are not the client. Google’s primary focus and center of gravity is not you.
Google Adwords is the system that allows everybody to buy (and bid for) the placement of Ads on a particular Google search keyword. Adwords is by far the highest income stream for Google, with $94 Billion in revenue in 2017. A key problem with Ad based services that are ‘free’ but generate billions for the owners of the network, is the reality that you (the user) are the product. You are the ‘goods’ that Google sells to their real customers (the companies buying the ads).
This is why Google’s business model is at odds with privacy. From Google’s (and Facebook, Twitter, LinkedIn, etc..) point of view, the less Privacy you have, the more they know about you, the more a valuable asset you become (an asset that they will sell to the highest bidder).
My view is that this business model is reaching its peak and two major changes will happen in this space in the short to medium term. The move to make the user the real customer and the move to reward the users that add value to networks:
- Once the balance shifts back to the user and the protection of user data (with Privacy elevated to a Human right and something companies want to provide for their employees), the protection and anonymization of user’s data will be an area with massive growth. And in ways that make the process of sharing and using personal data more secure, efficient and even more profitable.
- Jaron Lanier in You are not a Gadget defends the idea that creators of digital value should be paid for their contributions (in micro-payments). If you look at the income of Google and other community/Ad driven companies, you can see that the rewards and financial returns for the value created by the product (i.e. the users) is today very one sided (with small exception for areas like YouTubers and Medium Writers).
You would be very wise to spend time researching and learning about these paradigm shifts, namely how it will impact development practices and the code that you write.
Do know how to use Google’s Search Engine?
How much do you really know about how to search Google for text (images, ideas, videos, books) in the most efficient and effective way?
Have you spent time to learn how to search using Google? Google is just another tool, and you need to spend time learning how to use it and become a master at how to access and query the wealth of information that it stores.
A great place to start is the Advanced Search page and this great list of Google Search Operators.
Once you’ve done that, take a look at Google Dorks which is a Google Hacking technique that searches for sensitive data exposed by Google’s Crawlers. To get an idea of what is possible check out the Google Hacking Database which has sections like: Sensitive Directories, Files Containing Passwords, Sensitive Online Shopping Info , Network or Vulnerability Data and much more. You will be surprised, amazed and horrified with what you will discover.
I always find that the best way to learn a technology is using the techniques and patterns used to exploit it; because security tends to go deeper into what is ‘really possible’, not just how it is ‘supposed to be used’. In this case, the Google Hacking Database will give you tons of examples of WTF!, how is this data exposed to the internet? More interesting and relevant to your quest into becoming a better developer, this data will make you ask the questions: ‘How did that search query work?’ and ‘How did Google Crawlers found that data?’ (which is the best way to learn)
Google’s history and scale
Google is one of the best Software engineering companies in the world, and one of the first companies to do ‘Internet Scale’ really well.
Google is also massive in open source with highly successful hundreds of projects projects like Angular JS, Android or Kubernetes. Google hires some of the best Open Source developers to work on internal projects related to their passion, for example Guido van Rossum who is Python’s founder and lead developer, worked at Google. By the way, being hired to work on Open Source projects is a very common practice by companies that actively use a particular technology or language. This is a great way to get a dream job: write an Open Source tool/package and get hired by a company that uses it.
Google’s profits from the Search Engine are so high that it was able to fund a large number ideas and industries. It got so big that in 2015 the founders of Google created the Alphabet parent company. This is a really cleaver move since it will make each division (from self-driving cars, to drone deliveries) more accountable and focused.
Learn from Google’s focus on engineering and SRE
Part of the reason Google has gained massive amounts of market share is due to its ability to experiment and then execute at Scale. Google allows employees to spend 20% of their time on ideas they are passionate about, which sounds crazy at first, but there is solid data that says that this practice is highly effective and that it empowers developers to create new products and services. For example Google services like AdSense, Gmail, Google Maps, Google News or Google Talk where initially developed under the 20% research time.
Google also has a very high bar for quality and engineering. Two good books that explore their practices is the How Google Tests Software and the Site Reliability Engineering.
The SRE (Site Reliability Engineering) is an amazing concept, that you as a developer really need to spend time learning and understanding how it works (especially how SREs behave). At Google, the SRE teams are the ones that deploy and maintain applications. There are many lessons that we can learn from Google’s experience of deploying things at scale. For example I really like the SRE idea to spend 50% on ‘doing X’ and 50% in improving the process + tools required to effective do that ‘X’. ‘Error Budgets’ are another SRE concept which can make a massive difference in how applications are developed and tested. The SRE idea of ‘Error Budget’ is that each application or service needs to provides a clear and objective metric of how unreliable that service is allowed to be within a single period of time.
Google also puts a lot of effort in understanding from a scientific point of view, and how to create great teams. See ‘Work Rules’ book, Not A Happy Accident: How Google Deliberately Designs Workplace Satisfaction and Why Google defined a new discipline to help humans make decisions (which introduces the role of Chief Decision Officer and the field of Decision Intelligence Engineering)
Xcode and Swift
If don’t have a Mac computer you can ignore this chapter (or use MacinCloud to rent one).
With a Mac there is nothing stopping you from being hours away from your first Mac or iPhone application.
Xcode is Apple’s main development environment, and you can download it for free from the Apple store. Xcode contains everything you need you develop an Mac or iPhone application, namely an IDE, an Debugger and an execution Simulator (iOS, iPad and MacBooks)
Swift is the modern Open Source language developed by Apple that I highly recommend that you use. Swift dramatically simplifies the creation of applications for macOS, iOS, watchOS and tvOS.
Creating your own application is a major milestone in your programming career. You should do it even if you don’t want to become an mobile developer. Not only you will learn a large number of key concepts, you will also gain an understanding of how relatively easy it is to go from an idea in your head into a deployed application.
First application
To kickstart your development and experiments, start with step-by-step tutorials like the Hello World! Build Your First App in Swift which will guide you through the code and technologies required to make it happen.
After building your first application, your next objective is to think of an use-case that will help you to do something better in your life. This is an App for you and the only thing that matters is that it is useful enough that you use it regularly.
One of the key reasons why it is important at this stage that this application is only used by you (or a couple of your friends) is because that way, you can use the Xcode simulators to execute it (i.e. you don’t have to release it to the AppStore).
By using the application everyday, you will get direct feedback from what works, what doesn’t what and what need improvement. Initially, try to release a new version at least once a week (or once a day). It is important to create a process for this release (ideally with as much automation as possible).
Make sure you release your application under an Open Source license like Apache 2.0 and that you share it on a GitHub repository. This will allow you to expand your user base and gain more users.
Write tests and create a CI pipeline
Other key workflows that you need to adopt is writing tests and executing them in a CI (Continuous Integration) environment.
See Writing Test Classes and Methods for an integration on how to write tests in Swift.
Once you have a number of tests written, it is time to start looking at cloud/SaaS based build solutions. Travis is one of my favorites, but also check out BuddyBuild, AWS Device Farm, BrowserStack or SauceLabs.
Experiment with Machine Learning
Apple has released Core ML 2 which is described in Apple’s site) as an ‘machine learning framework used across Apple products, including Siri, Camera, and QuickType. Core ML 2 delivers blazingly fast performance with easy integration of machine learning models, enabling you to build apps with intelligent features using just a few lines of code’.
This means that you can easily add features like Vision or Natural Language to your application. If you do this, make sure to write blog posts about your experiments, since I’m sure any potential employer would be very interested in reading them.
Publish to AppStore
If you want to take this up a level, you should try to get your application published in the AppStore. This will have some costs, but they will be worth it for the learnings that you will get.
This would also be highly impressive for any potential employer, since it will show that you were able to meet Apple’s quality bar.
Dot Language
As a new developer joining the market, one of the real-world patterns that will surprise you the most, is the lack of up-to-date documentation and diagrams about how the applications, services and even code behave (and even when documentation does exists, they are usually out-of-date and not used on day-to-day decisions and coding).
When you take a step back and think about this, you should realise that it is insane. What we do when developing software is to create large interconnected and complex structures without accurate maps, without a solid understanding of what already exists and what we are supposed to be building.
This doesn’t happen because developers, architects or managers don’t understand or value good up-to-date documentation. In fact they are usually the first ones to complain about these gaps. The problem is that most patterns and technologies used to create these diagrams are highly inefficient, time-consuming, complex and isolated.
DOT is a text based representation of graphs which is a key part of the solution.
With DOT you describe the graph/diagram in text which is then transformed (by tools like Graphwiz or vis.js) into a diagram.
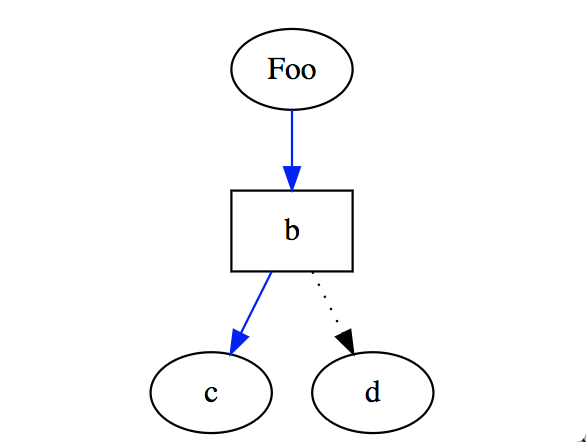
Here is an example of DOT Language:
1 digraph G {
2 size="2";
3 a [label="Foo"];
4 b [shape=box];
5 a -> b -> c [color=blue]
6 b -> d [style=dotted];
7 }
Which looks like this when rendered (try this online at GraphvizOnline
What I’m talking about is ‘Diagrams as code’, which is a major paradigm shift that very few developers and professionals have been able to make.
As you will see below, text-based representation of reality using diagrams is an area that still needs a lot of innovation and usage. I strongly recommend you to get your head around how to use DOT language for diagraming, since that will give you a strong competitive advantage.
Why we need diagrams
One of the key challenges that exist when working in a team with multiple stake-holders and areas of expertise, is the alignment of what are the objectives and what will be delivered. Don’t underestimate how hard this is. Without a graphical representation of the plan and reality, it is very hard to have that alignment. Actually what we really need are Maps, but starting with diagrams is a good start.
Diagrams provide an lingua franca to communicate between team members, where they makes it much easier to synchronize expectations, making sure that every stake holder understands the diagram’s reality and action plans.
Version control graphs using Git
A key advantage of storing diagram data in a text format, is that you are able to use git to version control them.
The benefits are tremendous, since now you are able to manage your diagrams as you manage your code:
- commit every change
- branches for new features
- tags to mark releases/sprints
- easily collaborate between multiple team members
- diff between versions (and actually see and understand what changed between versions)
Diff graphs and animate evolution
Your brain is really good at understanding patterns, but due to the highly efficient and hyperlinked way our brains work, what we think we remember from a diagram reviewed a couple days (or weeks) ago, is not usually a good representation of what we actually saw (or think we saw). This becomes a major problem when reviewing diagrams for a 2nd, 3rd or nth time, since unless we are presented with ‘what changed since the last review’, our brains will really struggle to figure it out.
One of the nice side effects of storing diagram data in a text based format, is that diffing versions becomes possible (i.e. it is possible to create text and graphical representations of those changes).
Diffing Diagrams (and making it as easy and smooth process), is is another area that we need quite a bit of innovation and a good area for you to become a player.
Why Visio doesn’t scale
But why not use Visio, or one of its online/offline variations (like draw.io or Lucidchart)?
Visio diagrams are the current industry standard for creating detailed technical and workflow diagrams. The reality is that Visio diagrams can look really good (specially if its creator has good design sense and good taste).
The irony is that Visio’s main features are actually its main drawbacks. Due to the fact that Visio allows the creation of very detailed diagrams means that it is:
- very time consuming - it is normal to take hours (if not days) to create detailed diagrams
- created from somebody’s interpretation of reality - the author of the Visio diagram will have a massive impact on the design, taxonomies, conventions and depth of detail, which means that it’s personal bias and agenda will be reflected in the diagram
- a work of art - yes some diagrams look really beautiful, but the point of a diagram is to help with data communication, understanding and collaboration. The point should be to empower decisions, not to look good
- not created from dynamic data - all elements in the Visio diagram are manually added, which means that once the original data/scenario/architecture changes, the diagram will be out-of-data
- layout is pixel based - which means that moving anything can become really hard because the actually location of a particular element is ‘hard-coded’ to a particular location in the page (i.e. its pixel). This is one of the reasons why changes are so hard, since it is easy to hit clashes between elements, when moving/adding new elements
- locked to a particular design convention - due to the fact that the design is hard-coded and the creator of the Visio diagram has enormous scope for applying its creative interpretation to the diagram’s data, what ever convention the author used, becomes the one that everybody has to use. This becomes a massive issue when it is required to see the diagram’s data from different points of view or different levels of abstraction
- very easy to mix abstraction layers - another common problem with Visio, is the use of multiple abstractions in the same diagram (for example mixing network flows, with application flows, with user journey flows). This tends to be an side-effect of not being able to reuse part of the diagram in new diagrams for example focused on a particular use-case or user-journey.
- stored in binary or xml format (very hard to diff) - not only these files are hard/impossible to diff, some of the file formats are proprietary (i.e. not open) and sometimes on online services the data is not even available.
- mixes data and design in same file - to effectively diff data, it is key to store the data and the design in different files. Not only this will make the version diffing possible, it allows the creation of standard design templates (which will create a consistency of design, making it easier to consume)
- very hard to update - once a diagram grows to a particular size, simple changes, can required considerate amounts of time (and big changes even more). This creates situations where the diagram authors become ‘alergic’ to making changes (since they might not have the time required to make the changes)
- not an accurate representation of reality - due to the fact that these diagrams are hard to update, even in the unlikely situation that the diagrams were accurate on day 0 (i.e. when they were completed for the first time), due to the natural rate of change in development and systems, it is inevitable that the diagrams will start to go out of date. Then, unless they are significant efforts put in maintaining those diagrams, they stop being sources of truth (and valuable for teams)
- not used everyday (by developers, architects or managers) - usually the reason for all the properties listed above, is the simple fact that the diagram’s created are not part of the multiple day-to-day conversations and decisions that occur between the multiple players
- they are usually not maps - finally the worse part of 99% of the diagrams out there is that that are not Maps. Although diagrams tend to be visual, have context (i.e. specific to purpose / perspective) and are mode of components , they miss the key mapping properties of: anchor, position (relative to anchor) and consistency of movement.
Not being able to control the layout is a feature
When you start using text based diagraming tools (like DOT) one of the behaviors that will drive you crazy is the fact that you can’t control the diagram layout (in the same way you do in Visio). Text based diagrams are dynamically rendered based on a set of predefined strategies. This means that the exact location of components will vary with most changes (note that some engines allow the fixation of components, which allows the creation of anchors and special areas).
This limitation is actually the best feature of text base diagrams!
It is only when you stop caring about the exact layout that you realise that it doesn’t really matter, since as long as you understand the diagram’s context, they are easy to read and consume.
The other positive site effect of this lack of control, is the fact that changes (big or small) are easy to make, which means that it is easy to keep the diagrams up-to-date.
Automatic generation of graphs for code
So what is the solution to make diagrams scale so that they are:
- a correct representation of reality
- easy to create and maintain
- able to provide multiple views from the same data
- able to separate code and data
- easy to diff (between versions)
The solution is to auto-generate the diagrams (from source-code, config files, data-analysis, logs, or other data sources). Only then will we have something that can be maintained and correctly represents reality.
But doesn’t this mean that we need a way to parse the (for example) config files, understand its structure and find a way to create information from it?
Yes
And what is wrong with being able to do that ?
What is crazy is to make decisions based on shadows of reality (or even worse, what somebody thinks reality is)
Infrastructure as Code
One of the good things of codifying the infrastructure (vs clicking on things or running a bunch of scripts), is that it provides the opportunity to use the config/recipe files to generate diagrams that represent what they create.
A good example is the visualization of the relationships between multiple running Docker containers. In Docker based environments, when this visualization of running containers is not available (in quasi real-time), eventually, it will become really hard to understand what is really going on. This this is reason why system failures caused by cascading set of events, start to become a common occurrence.
Use Threat Models as a way to create diagrams
Threat Models are a technique used by application security professionals to map out the security implications of a particular design. There are multiple schools of though on how to do threat models.
I like the simple one where we create a set of architecture/flow diagrams and map a number of threads to it: Authentication, Authorization, Data Validation, Secrets Management, Resilience and Privacy. To scale the creation of the Threat Models needs to be done by Security Champions (which are usually developers embedded in a particular team)
The trick here is to use Threat Models as a way to create diagrams that not only represent reality, but are kept up-to-date (by the Security Champion)
And why do teams find the time to do Threat Models, when they struggle to get management/business-buy-in for doing documentation?
Because doing documentation feels like a ‘low/medium priority’ task (when compared with the latest feature requested by the business), which is easy to keep pushing to one of the ‘next sprints’. This is a typical technical debt problem, where the real impact of not doing something will only happen in the future (usually when the ones making the current decisions are not there any more)
But NOT doing a Threat Model, means that that team (namely the business and technical owners) have taken an active step to ‘Not understand the security implications of the current design or latest set of changes’. This is a much higher risk and one that if you have a mature risk based workflow, will create a set of vulnerabilities and risks for those technical and management owners to accept (which is exactly what we do at Photobox Group Security).
The crazy idea that in Agile you don’t need documentation
…To go fast, you can go alone
…To go far, you need to go in a team
…To go fast and far, you need to go in a team and have real-time understanding/visualization of what is being created/executed
One of the very dangerous ideas that started to happen in Agile teams that were able to deploy fast to production, was the idea that you don’t need to document and diagrams things (since that will just slow things down).
This is a crazy idea and very short-sighted!
The quality of the test code and ability to create diagrams from what actually exists, are critical factors in creating highly productive, effective and rewarding environments.
People, Process and Technology
The biggest challenge in adopting (for example) DOT Language, are the People and Process part.
Although there still are some limitations in the Technology part (for example DOT diagrams need to have better support for icons, and provide better control of the positioning/anchor of key components), what I find is the hardest part, is for the People to do the paradigm shifts mentioned in this chapter.
Once they do, the Processes will evolve around the existing tech stack (for reference the tech stack I use is: DOT Language, Git, GitHub, Vis.js and Hugo)
Evolution of Diagrams into Maps
What is very frustrating is that in most development teams, we are still at the ‘Why do we need up-to-date diagrams?’ phase.
Where the question that we should be looking at is ‘How can we make our diagrams every better and more valuable?’
And the answer is Maps, which are diagrams with the following properties
- are visual
- have context (i.e. specific to purpose / perspective)
- are mode of components
- have at least one anchor
- have a position (relative to anchor)
- have a consistency of movement
For a great introduction to this kind of maps see Wardley Mapping, which was created by Simon Wardley who is writing a book about it at Medium.
Explore Vis.js Javascript engine
If you are looking for a great javascript-based DOT language visualization engine, then vis.js network is the one I recommend you spend a lot of time learning and customizing (see my neovis fork for an example of what those customization can look like)
Mermaid and WebSequenceDiagrams.com
Another good example of diagram as code is the open source Mermaid tool, which is designed to help with chart generation.
Here is what a Sequence Diagram code looks like in Mermaid
1 sequenceDiagram
2 participant Alice
3 participant Bob
4 Alice->John: Hello John, how are you?
5 loop Healthcheck
6 John->John: Fight against hypochondria
7 end
8 Note right of John: Rational thoughts <br/>prev\
9 ail...
10 John-->Alice: Great!
11 John->Bob: How about you?
12 Bob-->John: Jolly good!
Which looks like this when rendered:
An alternative is the proprietary https://www.websequencediagrams.com service, which more feature rich that mermaid and has a nicer design (the free version is already very usable and practical):
1 title Authentication Sequence
2
3 Alice->Bob: Authentication Request
4 note right of Bob: Bob thinks about it
5 Bob->Alice: Authentication Response
Will look like this
The Diagram in R integration page contains a great video of DOT in action:
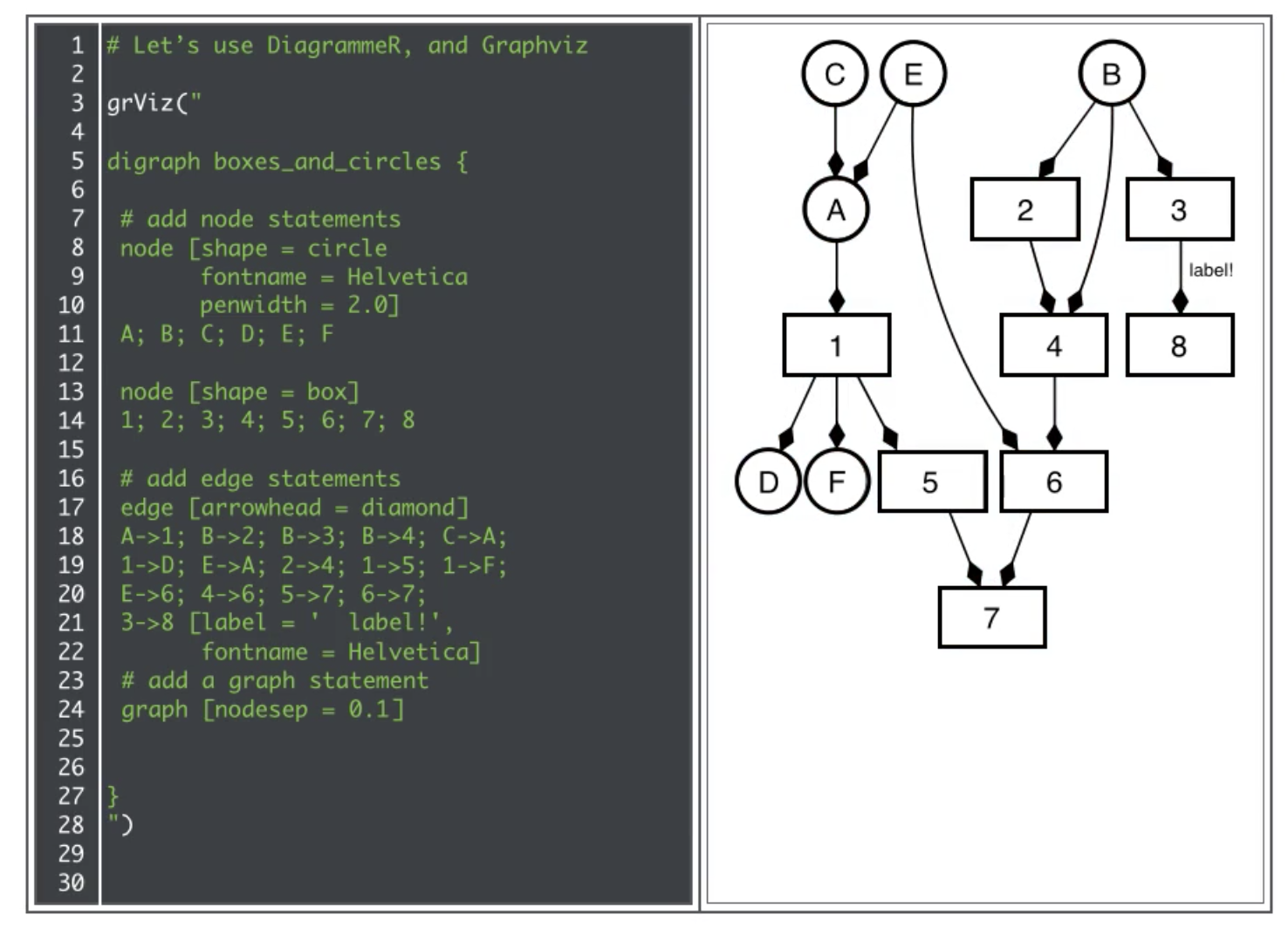
Btw, if you have not learned how to code in R, you definitely should, since it is a great way to manipulate and visualise data).
Try it! (learn DOT and Mermaid with real-time preview)
A good tech stack to learn DOT Language (and mermaid) is the Atom editor with the Markdown Preview Enhanced package installed.
This is create an REPL environment where you have an highly effective and productive split screen (on the left you have the markdown page, and on the right the rendered page/diagram). Once you make a code change, you will see the rendered diagram in less than a second. This workflow makes it really easy to learn and to create diagrams in real-time.
I have done Threat Modeling sessions in the past, where we have the UI described above projected on a wall, which allow us to create the diagrams in real-time, based on the information provided by the meeting attendees.
Wallaby and NCrunch
WallabyJS is a an Integrated Continuous Testing Tool for JavaScript that represents the best TDD (Test Driven Development) environment that I’ve seen, because it allows the creation of a highly productive and efficient development workflow. NCrunch is very similar for .NET and all the concepts below also apply to it (my experience is that wallaby is a bit faster). Unfortunately there isn’t an equivalent for the other languages (some IDEs do have the ability to automatically execute tests, but they only have subset of the features I describe below and the development experience is not the same)
WallabyJS is an plugin/add-on for the most popular IDEs (WebStorm, IntelliJ IDEA, PhpStorm, Rider, RubyMine, PyCharm, Visual Studio , Atom Text Editor, Sublime Text) that enables the execution of Unit Tests immediately. The loop from detection to ‘test execution completion’, usually takes less than 1 sec, which give it a feel of real-time test execution.
The proof of a good piece of technology is when it dramatically improves the productivity of its users by changing how they behave and operate (while making them awesome). WallabyJS and NCrunch are such technologies, and it is key that you as a developer understand why, and learn how to use it (or its patterns).
All developers test their code
One key concept that I always try to make to developers, is that they are already testing their code changes. Then tend to do these tests in a highly inefficient way, but they are still testing their code and their changes.
For example when developers make a change in a particular web page or back-end service, they will fire up a browser or PostMan and click a number of times until their reach the location where the change they made can be seen in action.
The problem is that in most cases the ways they test their changes:
- Are highly inefficient
- Can take many seconds or event minutes to test one change
- Are hard to repeat and Ephemeral
- Are limited in their scope (i.e. not testing most/all real-world moving parts affected by the changes)
- Tend to focus on a very narrow set of use-cases
- Lose the history of the multiple tests scenario tested
- Make the developer switch context in their mind
- Do not show the code coverage (in the IDE) of the changes made (seconds after the test complete)
The reality is that developing using workflows that don’t have the capabilities enabled by WallabyJS is highly expensive, inefficient, unproductive, slow, and frustrating for everybody involved (namely the developers who pay the price of that inefficiency every time they code, and the users who don’t get a fast turn around for the features they want)
Key WallabyJS features
As with everything, the key is in the People, Process and Technology ecosystem.
WallabyJS is a Technology that enables a massive paradigm shift in the People involved, that leads to massive changes in the Process of testing and developing applications.
Here are the key features that WallabyJS has (that I wished every IDE had by default):
- Automatic execution of tests - as soon as you make a change to the code (or save it), the tests runs automatically (WallabyJS is so fast, that some tests actually execute in between your key stokes)
- Execution of only affected tests - part of making the automatic execution of tests scale is the ability to only execute the tests that were changed. The ability to detect this also means that there is no need to keep configuring the test runner
- Execution of only tests affected by code changes - this feature answers the question “what is the impact of the code change I just made”. Using code coverage, it is possible to know the tests that are currently able to hit the lines that where changed (and then only execute those). This is such a simple concept, but makes a massive difference, since the alternative is to run all tests or to try to manually find the tests that can be executed.
- Code coverage in the IDE after execution - Another feature highly underestimated is the power of seeing in the IDE the status of the test’s execution. Not only this clearly shows the areas of the code that are currently not being reached, the way WallabyJS (and NCrunch) do it is very cleaver, since they show the paths of pass and fail (i.e. you see in green the lines that were executed by passing tests, and in red the lines affected by failed tests). This allows for really powerful workflows, including a massive reduction of the need to ‘debug’ code using a ‘debugger’. In many projects that I was involved in, after a while, we realized that me and development team stopped using the debugger when coding! Wallaby or NCrunch gave us enough visibility to understand where the bug was (this allowed us to not have to deal with all the inefficient of having to maintain a salad of breakpoints and hundreds of ‘Step Into’ or ‘Step Over’ clicks)
-
Feedback of values in IDE - A nice little feature of WallabyJS is that it has a number of ways to get feedback from the tests being executed. This goes from simple
console.logoutputs to expressions and even variable transformations, that are showed directly in the IDE and in context. - Crazy fast execution - Is easy to underestimate the speed of execution of WallabyJS, and fail to realise that it is one of the core reasons that makes WallabyJS so effective and empowering. In fact I thought that NCrunch was fast, but after using WallabyJS for a while, NCrunch felt really slow, and using normal test runners just kills my brain. We have quite a lot of data on how page speed affects users experience (see Why Performance Maters) and it is the same for test execution and the developer’s brain. When tests execute automatically and in less than a second, there is a flow and effectiveness that occurs, which dramatically improves productivity and focus.
Aim for 100% code coverage
My view of code coverage is that if you make a change in the code and a test didn’t break, you are making random changes (where you don’t really understand the side effects of your changes).
Even when you are doing refactoring, you should break a number of tests until you arrive back a test passing state.
This means that you need to aim for 100% code coverage, since that means that all of your code is covered by tests. I know that this high-code-coverage percentage can be gamed, and there are many horror stories on companies that abused this metric (which always are indicators of bigger problems within the development culture and management).
If fact, what you want is much more than code coverage. What you want is to make sure that the tests that are executed, correctly represent your understanding of what the code changed is doing.
This means that the question is not “When I made this change, did a test break?” but it should be instead “When I made this change, did the tests that failed represent my understanding of the change I made”.
The bottom line is that if you make changes to parts of your code that are not reflected in tests, then how do you know that your changes/fixes worked as expected?
The only way to achieve this level of code coverage is to expose the developer to real-time code-coverage in the IDE (i.e. the developer is able to see exactly what lines and code have coverage, and even more interesting, which ones have been affected by the code changes)
Wallaby represents the real TDD
One of the unfortunate side-effects of the horror stories of high code coverage exercises (namely the ones that created massive white-elephants that were completely unusable and very expensive to maintain), is the allergic reaction that TDD (Test Driven Development) can sometimes have today.
What ended up happening is that everybody agrees that TDD is very important, that TDD is should be used by all developers, that TDD is an important factor in the hiring and candidate selection process, but when we look at where TDD is actually used, we tend to see that it happens on low level ‘pure’ Unit Tests, and code coverages of 80%+ are seen as a success.
Part of the problem is how TDD is perceived to work. The bad (in my point of view) workflow that tends to be described as TDD is:
- Start with a passing state
- Write a failed test with the smallest possible feature
- make a code change that makes that test pass
- back to 1 (until the function does what it is supposed to do)
The problem is that this is only useful and relevant in a couple of the TDD scenarios.
The way I do TDD is
- Start with a passing state
- Make a change (in production code or in an test)
- Fix the code or tests (so that we are back into the passing state)
- Back to 1 (until the feature does what it is supposed to do)
Although the 1st and last steps are the same, the middle bit is very important.
I like to view it as I’m pair programming with myself, where I loop back and forward from code and tests.
What matters is that the code changes are made in the location that matters the most at that moment in time. Also important is that I use this workflow for everything, from tests that affect a stand alone function (traditional called an Unit Tests), to tests that require quite a bit of code and state to be executed in order to really test the changes (traditionally called Integration Tests).
For me a Test is the confirmation that a particular behavior exists in a particular scenario (which can be a function, an web service, an website, an CI pipeline, an Docker container, an Cloud setup, etc..). Basically a Test is an answer to an Question. The more questions you have the better you will be. The objective is to achieve the widest possible range of scenarios and code coverage. In fact a really good measure would be to track how much code a test actually touched (the higher value, the better)
A good sign that TDD has lost is mojo, is the fact that code coverage effectiveness is not usually mapped to an team’s deliverables or OKRs (Objectives and Key Results). Development teams will respond to the reward’s systems set in place. If we don’t reward the creation of highly effective test environments with high degrees of code coverage, then we shouldn’t be surprised when that doesn’t happen.
I keep trying to find a better name for the workflow that WallabyJs enables, but TDD still feels like the correct term, since when I code using WallabyJS I am really doing Test Driven Development.
FDD (Feedback Driven Development) is a close alternately, but TDD is still the one I like the most.
Test code is as important as production code
I will argue that focusing on the quality of your test code is as important as focusing on the quality of the code that you actually run in production.
Why? because the more effective and productive your test code and test environment is, the better your production code will be. But the opposite is not true (i.e. the better your production code is, doesn’t mean that the better your test code will be ).
If your team doesn’t not have the same amount of care and craftsmanship with test code as they have with production code (including testing the test pipeline), then you will never achieve the speeds and quality of development that are desired.
Part of the problem seems to be the horror stories caused by big and cumbersome test environments that actually slowed teams down (where a couple minutes ‘code changes’ required hours of ‘test changes’). This is a symptom of badly engineered test environments and lack of time spending on improving the test infrastructure and effectiveness.
As a developer, your test environment (and executing workflow) is one of the most important capabilities that you need to work on (and improve). Just like successful athletes put a massive amount of energy and focus in their supporting equipment, you as a developer need to make sure that the code that helps you to write good production code, is as effective and robust as possible (see How 1% Performance Improvements Led to Olympic Gold)
You have to try it to believe it
As with everything, the best way to learn is to experience it, so download one of the Open Source editors (like Atom or VS Code), install the Evaluation version of WallabyJS and give it a good test drive.
Try it in some of the apps that you are coding, or write something new. What is important is that you experience the power of ‘real-time test execution and code coverage’.
Another good use of WallabyJS is to understand how an API works. One of the patterns I follow when learning how to use a new API, is to write tests that invoke its capabilities. Not only this allows me to gain a much better understanding of how that API works, the tests I leave behind, represent my understanding of that API at that moment in time, and more importantly, how I expected that API to behave. This is very important in helping to detect future bugs caused by modifications in that API’s behavior (caused by upgrades or security fixes)
When learning how to use WallabyJS you are exploring the concept Bret Victor mentions in his Inventing on principle presentation which is the ‘The need for inventors to be close to what they create and have quick feedback’
Why isn’t wallabyJS more widely used
For me, once I saw and experienced NCrunch and then WallabyJS, I knew that I would never be able to code in .Net or Javascript without having access to those capabilities.
But the question that really puzzles me, is why its adoption is still quite low?
Why aren’t more developers using it and why aren’t they demanding the IDE’s developers to add those features? This is one of the reasons why IDE support for these workflows is so low, there isn’t enough market pressure.
One reason could be a general lack of investment in tools for developers. In some companies that is seen as a cost, instead of an investment. I’ve seen companies that are happy to hire a new developer for £60k, but don’t seem to have the budget to spend the same amount in tools for existing developers (where that £60k would have a much bigger impact)
But even in companies what are ok with investing on developer’s tools (and wallaby isn’t that expensive, since it costs $100 per named developer or $240 for a company license), I still don’t see developers asking for those licenses. Why is that?
My only logical explanation is the natural resistance to change, an lack of understanding of the power of these kind of testing environments/workflows, and a lack of time to make WallabyJS work in the current application.
Usually the argument is that ‘It sounds good but we are too busy to improve the test environment’, which is a self fulfilling tragedy, since until the test environment is improved, everybody is always going to be busy and reactive.
As a new developer, this blind spot is a massive opportunity for you. If you are able to make these paradigm changes, and behave in a real TDD way, you just gained a massive competitive advantage in the market place.
We need an Wallaby for the Cloud
One of the side effects of current lack of efforts in making new technologies easy to test (I mean in an WallabyJS-like workflow, since we have moved a long way from the old completely un-testable APIs, like the early versions of .NET or Java web stacks), is that we are not adding these ‘real-time test and code-coverage’ capabilities to the new tech stacks.
For example who is writing tests for their ‘Infrastructure as Code’ scripts?
- How do we know that code used to setup an cloud environment is actually working as expected?
- How do we know that the Auto-Scaling set-up is actually working as expected?
- How do we know that an DNS change is not causing massive side effects in an unrelated part of the application?
- How do we know that the upgrade, crash or misbehavior of Service X, actually causes an unexpected massive disruption in Service Y? (which btw is one of the questions that Chaos Engineering tries to answer)
- Who is writing tests for Serverless functions, for example Lambdas? I don’t mean tests that run locally, I mean tests that actually run on the Serverless environment?
What is really nice about making the paradigm shifts mentioned in the chapter, is that your brain will refuse to program in any other way. So when recently I had to write some Lambda functions in Python, after realising that the maturity of the Lambda TDD environment was really low, I spend a bit of time creating an environment where using the AWS boto3’s API (which wraps most AWS capabilities in easy to use Python functions) I was able to create an environment in PyCharm where I could execute lambdas (written locally) in AWS in less than 1 sec.
Since PyCharm has a feature to auto execute the last test after a couple seconds of a code change, I was able to create an workflow where 2 seconds after making a code change, the affected Lambda was executed in AWS (with execution times under 1 second). Ok it is not as effective as WallabyJS and I don’t get code coverage, but it is much better than anything else I saw (from tools that created local simulated AWS Lambda environments in Docker, to tools like Serverless that used CloudFormation to deploy the Lambdas and took almost 1 minute to run)
The problem of switching context
Part of the reason WallabyJS-Driven-Development makes such a difference, is because it prevents your brain from doing Context Switching.
Our brains are not very good at switching context, which is why even a couple seconds interruption can be so damaging.
When we program, what we are doing is creating in our brains a whole set of model models about the problem/issue we are addressing. This is why sometimes we can be super productive, and other times, we just can’t make it work. This is key in programing since the impact of bad/inefficient code can be enormous. Sometimes it’s much better not to code, than to write code that will cause so many side-effects at later stage, that those code changes actually had a negative value (i.e. like when somebody is trying to help, but they are actually ‘anti-help’).
This is also why it is very important to have un-interrupted periods of time for coding (ideally blocks of 2 or 4 hours), since it takes a while to build these mental models and gain speed.
When we code in an non WallabyJS-Driven-Development environnement, what happens is that we are forced to switch context every time we want to test an code change. Even if that is only a couple seconds of mouse clicks or keyboard strokes, the compound effect of that interruption is enormous. This is way worse when the time that it takes to start the test is more than 10 seconds or even minutes (the impact of productivity is enormous)
With an WallabyJS-Driven-Development environment, what happens is that you get into a groove (or flow), where you are able to focus 100% on the code that you are writing. You will also start to use the visual feedback that you get from WallabyJS as part of your development. You need to experience this to understand but, when you get this right, this is what being the ‘coding zone’ really feels like, and the productivity that you achieve is really something incredible.
One question I’m asked quite a lot is How can I code and learn so fast. The answer is in how I code and the time I spend in creating productive environments that allow me to code and learn in the ‘Zone’.
As a developer if you can behave like this, you will have a massive competitive advantage in the marketplace, specially when applying for new jobs. It is very common these days to ask job applicants to write some tests during an job interview. Guess who will stand out in those interviews and get the job?
One to watch: LightTable
As a final idea, if I were you, I would spend some time with the experimental LightTable Open Source IDE (ideally even becoming a contributor)
I need to give this tool a better test drive, but it looks really promising. since it has implemented a number of the features presented in Bret Victor’s Inventing on principle video, namely the real time feedback of code changes and showing the values in the IDE.
One area I would like to see more examples/use-cases is how LightTable can be to applied to testing, which is a good area for you to focus your research on :)