Section I: Programming Basics
There was something amazingly enticing about programming—Vint Cerf
This section is for readers who are learning to program. If you’re an experienced programmer, skip forward to Summary 1 and Summary 2.
Introduction
This book is for dedicated novices and experienced programmers.
You’re a novice if you don’t have prior programming knowledge, but “dedicated” because we give you just enough to figure it out on your own. When you’re finished, you’ll have a solid foundation in programming and in Kotlin.
If you’re an experienced programmer, skip forward to Summary 1 and Summary 2, then proceed from there.
The “Atomic” part of the book title refers to atoms as the smallest indivisible units. In this book, we try to introduce only one concept per chapter, so the chapters cannot be further subdivided—thus we call them atoms.
Concepts
All programming languages consist of features. You apply these features to produce results. Kotlin is powerful—not only does it have a rich set of features, but you can usually express those features in numerous ways.
If everything is dumped on you too quickly, you might come away thinking Kotlin is “too complicated.”
This book attempts to prevent overwhelm. We teach you the language carefully and deliberately, using the following principles:
- Baby steps and small wins. We cast off the tyranny of the chapter. Instead, we present each small step as an atomic concept or simply atom, which looks like a tiny chapter. We try to present only one new concept per atom. A typical atom contains one or more small, runnable pieces of code and the output it produces.
- No forward references. As much as possible, we avoid saying, “These features are explained in a later atom.”
- No references to other programming languages. We do so only when necessary. An analogy to a feature in a language you don’t understand isn’t helpful.
- Show don’t tell. Instead of verbally describing a feature, we prefer examples and output. It’s better to see a feature in code.
- Practice before theory. We try to show the mechanics of the language first, then tell why those features exist. This is backwards from “traditional” teaching, but it often seems to work better.
If you know the features, you can work out the meaning. It’s usually easier to understand a single page of Kotlin than it is to understand the equivalent code in another language.
Where Is the Index?
This book is written in Markdown and produced with Leanpub. Unfortunately, neither Markdown nor Leanpub supports indexes. However, by creating the smallest-possible chapters (atoms) consisting of a single topic in each atom, the table of contents acts as a kind of index. In addition, the eBook versions allow for electronic searching across the book.
Cross-References
A reference to an atom in the book looks like this: Introduction, which in this case refers to the current atom. In the various eBook formats, this produces a hyperlink to that atom.
Formatting
In this book:
- Italics introduce a new term or concept, and sometimes emphasize an idea.
-
Fixed-width fontindicates program keywords, identifiers and file names. The code examples are also in this font, and are colorized in the eBook versions of the book. - In prose, we follow a function name with empty parentheses, as in
func(). This reminds the reader they are looking at a function. - To make the eBook easy to read on all devices and allow the user to increase the font size, we limit our code listing width to 47 characters. At times this requires compromise, but we feel the results are worth it. To achieve these widths we may remove spaces that might otherwise be included in many formatting styles—in particular, we use two-space indents rather than the standard four spaces.
“Pause”
Occasionally you will see:
- -
This indicates a pause, or a kind of small reset. In this book it often appears before a brief summary of the current subsection, but where a “Summary” subhead would be overkill. Some books use a mechanism like this to indicate that an idea is complete and we are starting something new, but it’s still within the same topic and not big enough to warrant a subsection or a new section. The markdown in Leanpub is quite limited, and using one or more dots (my original attempt) isn’t possible. Putting two dashes in the markdown produces a dot and a dash. There might be a better way to do this but I haven’t found it, so I settled on that.
Sample the Book
We provide a free sample of the electronic book at AtomicKotlin.com. The sample includes the first two sections in their entirety, along with several subsequent atoms. This way you can try out the book and decide if it’s a good fit for you.
The complete book is for sale, both as a print book and an eBook. If you like what we’ve done in the free sample, please support us and help us continue our work by paying for what you use. We hope the book helps, and we appreciate your sponsorship.
In the age of the Internet, it doesn’t seem possible to control any piece of information. You’ll probably find the electronic version of this book in numerous places. If you are unable to pay for the book right now and you do download it from one of these sites, please “pay it forward.” For example, help someone else learn the language once you’ve learned it. Or help someone in any way they need. Perhaps in the future you’ll be better off, and then you can pay for the book.
Exercises and Solutions
Most atoms in Atomic Kotlin are accompanied by a handful of small exercises. To improve your understanding, we recommend solving the exercises immediately after reading the atom. Most of the exercises are checked automatically by the JetBrains IntelliJ IDEA integrated development environment (IDE), so you can see your progress and get hints if you get stuck.
You can find the following links at http://AtomicKotlin.com/exercises/.
To solve the exercises, install IntelliJ IDEA with the Edu Tools plugin by following these tutorials:
- Install IntelliJ IDEA and the EduTools Plugin.
- Open the Atomic Kotlin course and solve the exercises.
In the course, you’ll find solutions for all exercises. If you’re stuck on an exercise, check for hints or try peeking at the solution. We still recommend implementing it yourself.
If you have any problems setting up and running the course, please read The Troubleshooting Guide. If that doesn’t solve your problem, please contact the support team as mentioned in the guide.
If you find a mistake in the course content (for example, a test for a task produces the wrong result), please use our issue tracker to report the problem with this pre-filled form. Note that you’ll need to log in into YouTrack. We appreciate your time in helping to improve the course!
Seminars
You can find information about live seminars and other learning tools at AtomicKotlin.com.
Conferences
Bruce creates Open-Spaces conferences such as the Winter Tech Forum. Join the mailing list at AtomicKotlin.com to stay informed about our activities and where we are speaking.
Support Us
This was a big project. It took time and effort to produce this book and accompanying support materials. If you enjoy this book and want to see more things like it, please support us:
- Blog, tweet, etc. and tell your friends. This is a grassroots marketing effort so everything you do will help.
- Purchase an eBook or print version of this book at AtomicKotlin.com.
- Check AtomicKotlin.com for other support products or events.
About Us
Bruce Eckel is the author of the multi-award-winning Thinking in Java and Thinking in C++, and a number of other books on computer programming including Atomic Scala. He’s given hundreds of presentations throughout the world and puts on alternative conferences and events like the Winter Tech Forum and developer retreats. Bruce has a BS in applied physics and an MS in computer engineering. His blog is at www.BruceEckel.com and his consulting, training and conference business is Mindview LLC.
Svetlana Isakova began as a member of the Kotlin compiler team, and is now a developer advocate for JetBrains. She teaches Kotlin and speaks at conferences worldwide, and is coauthor of the book Kotlin in Action.
Acknowledgements
- The Kotlin Language Design Team and contributors.
- The developers of Leanpub, which made publishing this book so much easier.
- James Ward for converting the Gradle build to Kotlin, and being generally awesome.
Dedications
For my beloved father, E. Wayne Eckel. April 1, 1924—November 23, 2016. You first taught me about machines, tools, and design.
For my father, Sergey Lvovich Isakov, who passed away so early and who we will always miss.
About the Cover
Daniel Will-Harris designed the cover based on the Kotlin logo.
Why Kotlin?
Programs must be written for people to read, and only incidentally for machines to execute.—Harold Abelson, coauthor, Structure and Interpretation of Computer Programs.
This atom is an overview of the historical development of programming languages so you can understand where Kotlin fits and why you might want to learn it. We introduce some topics which, if you are a novice, might seem too complicated right now. Feel free to skip this atom and come back to it after you’ve read more of the book.
Programming language design is an evolutionary path from serving the needs of the machine to serving the needs of the programmer.
A programming language is invented by a language designer and implemented as one or more programs that act as tools for using the language. The implementer is usually the language designer, at least initially.
Early languages focused on hardware limitations. As computers become more powerful, newer languages shift toward more sophisticated programming with an emphasis on reliability. These languages can choose features based on the psychology of programming.
Every programming language is a collection of experiments. Historically, programming language design has been a succession of guesses and assumptions about what will make programmers more productive. Some of those experiments fail, some are mildly successful and some are very successful.
We learn from the experiments in each new language. Some languages address issues that turn out to be incidental rather than essential, or the environment changes (faster processors, cheaper memory, new understanding of programming and languages) and that issue becomes less important or even inconsequential. If those ideas become obsolete and the language doesn’t evolve, it fades from use.
The original programmers worked directly with numbers representing processor machine instructions. This approach produced numerous errors, and assembly language was created to replace the numbers with mnemonic opcodes—words that programmers could more easily remember and read, along with other helpful tools. However, there was still a one-to-one correspondence between assembly-language instructions and machine instructions, and programmers had to write each line of assembly code. In addition, each computer processor used its own distinct assembly language.
Developing programs in assembly language is exceedingly expensive. Higher-level languages help solve that problem by creating a level of abstraction away from low-level assembly languages.
Compilers and Interpreters
The instructions of an interpreted language are executed directly by a program called an interpreter. Kotlin is compiled rather than interpreted. The source code of a compiled language is converted into a different representation that runs as its own program, either directly on a hardware processor or on a virtual machine that emulates a processor:
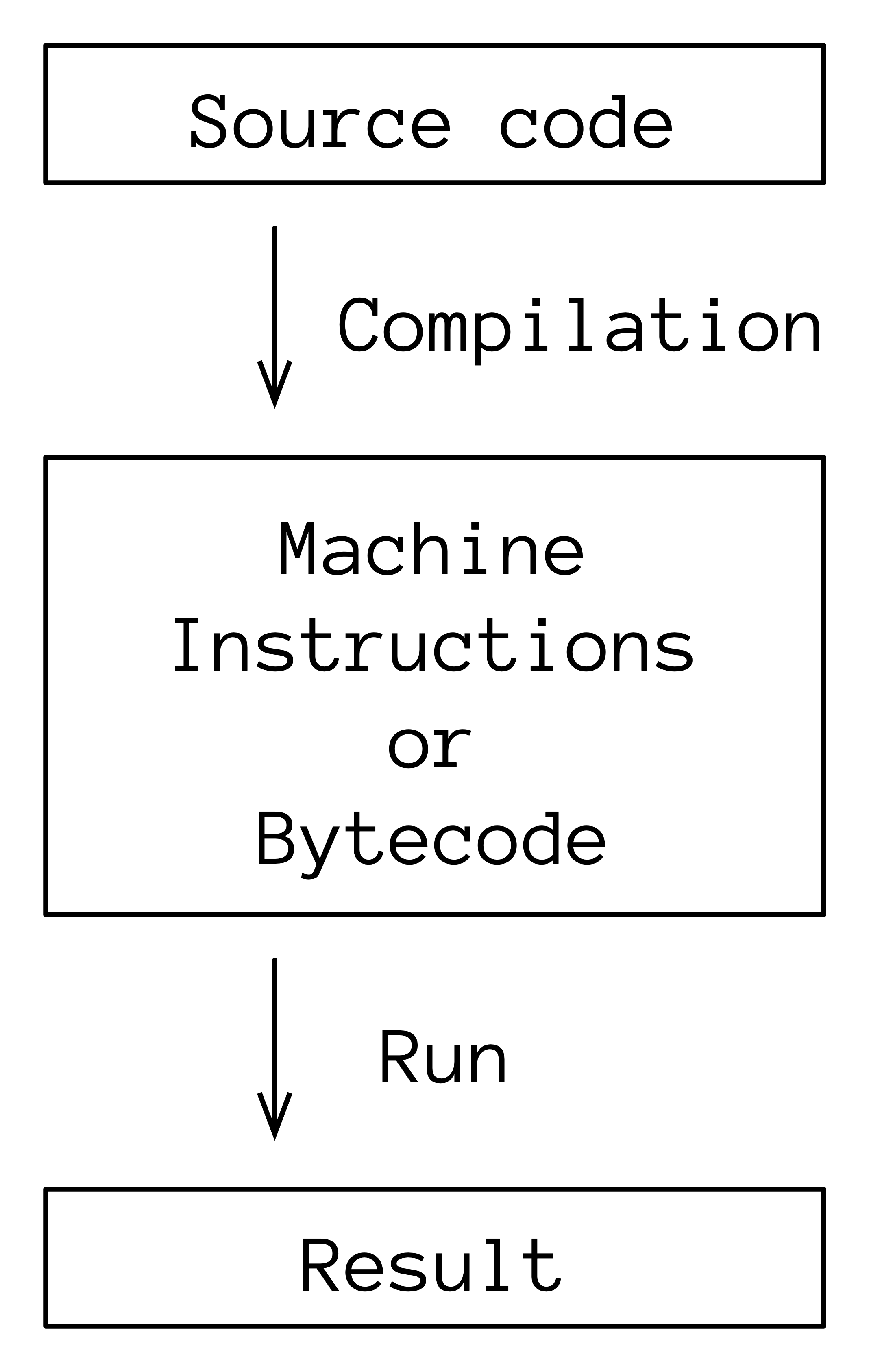
Languages such as C, C++, Go and Rust compile into machine code that runs directly on the underlying hardware central processing unit (CPU). Languages like Java and Kotlin compile into bytecode which is an intermediate-level format that doesn’t run directly on the hardware CPU, but instead on a virtual machine, which is a program that executes bytecode instructions. Programs produced by the JVM version of Kotlin run on the Java Virtual Machine (JVM).
Portability is an important benefit of a virtual machine. The same bytecode can run on every computer that has a virtual machine. Virtual machines can be optimized for particular hardware and to solve speed problems. The JVM contains many years of such optimizations, and has been implemented on many platforms.
At compile time, the code is checked by the compiler to discover compile-time errors. (IntelliJ IDEA and other development environments highlight these errors when you input the code, so you can quickly discover and fix any problems). If there are no compile-time errors, the source code will be compiled into bytecode.
A runtime error cannot be detected at compile time, so it only emerges when you run the program. Typically, runtime errors are more difficult to discover and more expensive to fix. Statically-typed languages like Kotlin discover as many errors as possible at compile time, while dynamic languages perform their safety checks at runtime (some dynamic languages don’t perform as many safety checks as they might).
Languages that Influenced Kotlin
Kotlin draws its ideas and features from many languages, and those languages were influenced by earlier languages. It’s helpful to know some programming-language history to gain perspective on how we got to Kotlin. The languages described here are chosen for their influence on the languages that followed them. All these languages ultimately inspired the design of Kotlin, sometimes by being an example of what not to do.
FORTRAN: FORmula TRANslation (1957)
Designed for use by scientists and engineers, Fortran’s goal was to make it easier to encode equations. Finely-tuned and tested Fortran libraries are still in use today, but they are typically “wrapped” to make them callable from other languages.
LISP: LISt Processor (1958)
Rather than being application-specific, LISP embodied essential programming concepts; it was the computer scientist’s language and the first functional programming language (You’ll learn about functional programming in this book). The tradeoff for its power and flexibility was efficiency: LISP was typically too expensive to run on early machines, and only in recent decades have machines become fast enough to produce a resurgence in the use of LISP. For example, the GNU Emacs editor is written entirely in LISP, and can be extended using LISP.
ALGOL: ALGOrithmic Language (1958)
Arguably the most influential of the 1950’s languages because it introduced syntax that persisted in many subsequent languages. For example, C and its derivatives are “ALGOL-like” languages.
COBOL: COmmon Business-Oriented Language (1959)
Designed for business, finance, and administrative data processing. It has an English-like syntax, and was intended to be self-documenting and highly readable. Although this intent generally failed—COBOL is famous for bugs introduced by a misplaced period—the US Department of Defense forced widespread adoption on mainframe computers, and systems are still running (and requiring maintenance) today.
BASIC: Beginners’ All-purpose Symbolic Instruction Code (1964)
BASIC was one of the early attempts to make programming accessible. While very successful, its features and syntax were limited, so it was only partly helpful for people who needed to learn more sophisticated languages. It is predominantly an interpreted language, which means that to run it you need the original code for the program. Despite that, many useful programs were written in BASIC, in particular as a scripting language for Microsoft’s “Office” products. BASIC might even be thought of as the first “open” programming language, as people made numerous variations of it.
Simula 67, the Original Object-Oriented Language (1967)
A simulation typically involves many “objects” interacting with each other. Different objects have different characteristics and behaviors. Languages that existed at the time were awkward to use for simulations, so Simula (another “ALGOL-like” language) was developed to provide direct support for creating simulation objects. It turns out that these ideas are also useful for general-purpose programming, and this was the genesis of Object-Oriented (OO) languages.
Pascal (1970)
Pascal increased compilation speed by restricting the language so it could be implemented as a single-pass compiler. The language forced the programmer to structure their code in a particular way and imposed somewhat awkward and less-readable constraints on program organization. As processors became faster, memory cheaper, and compiler technology better, the impact of these constraints became too costly.
An implementation of Pascal, Turbo Pascal from Borland, initially worked on CP/M machines and then made the move to early MS-DOS (precursor to Windows), later evolving into the Delphi language for Windows. By putting everything in memory, Turbo Pascal compiled at lightning speeds on very underpowered machines, dramatically improving the programming experience. Its creator, Anders Hejlsberg, later went on to design both C# and TypeScript.
Niklaus Wirth, the inventor of Pascal, created subsequent languages: Modula, Modula-2 and Oberon. As the name implies, Modula focused on dividing programs into modules, for better organization and faster compilation. Most modern languages support separate compilation and some form of module system.
C (1972)
Despite the increasing number of higher-level languages, programmers were still writing assembly language. This is often called systems programming, because it is done at the level of the operating system, but it also includes embedded programming for dedicated physical devices. This is not only arduous and expensive (Bruce began his career writing assembly language for embedded systems), but it isn’t portable—assembly language can only run on the processor it is written for. C was designed to be a “high-level assembly language” that is still close enough to the hardware that you rarely need to write assembly. More importantly, a C program runs on any processor with a C compiler. C decoupled the program from the processor, which solved a huge and expensive problem. As a result, former assembly-language programmers could be vastly more productive in C. C has been so effective that recent languages (notably Go and Rust) are still attempting to usurp it for systems programming.
Smalltalk (1972)
Designed from the beginning to be purely object-oriented, Smalltalk significantly moved OO and language theory forward by being a platform for experimentation and demonstrating rapid application development. However, it was created when languages were still proprietary, and the entry price for a Smalltalk system could be in the thousands. It was interpreted, so you needed a Smalltalk environment to run programs. Open-source Smalltalk implementations did not appear until after the programming world had moved on. Smalltalk programmers have contributed great insights benefitting later OO languages like C++ and Java.
C++: A Better C with Objects (1983)
Bjarne Stroustrup created C++ because he wanted a better C and he wanted support for the object-oriented constructs he had experienced while using Simula-67. Bruce was a member of the C++ Standards Committee for its first eight years, and wrote three books on C++ including Thinking in C++.
Backwards-compatibility with C was a foundational principle of C++ design, so C code can be compiled in C++ with virtually no changes. This provided an easy migration path—programmers could continue to program in C, receive the benefits of C++, and slowly experiment with C++ features while still being productive. Most criticisms of C++ can be traced to the constraint of backwards compatibility with C.
One of the problems with C was the issue of memory management. The programmer must first acquire memory, then run an operation using that memory, then release the memory. Forgetting to release memory is called a memory leak and can result in using up the available memory and crashing the process. The initial version of C++ made some innovations in this area, along with constructors to ensure proper initialization. Later versions of the language have made significant improvements in memory management.
Python: Friendly and Flexible (1990)
Python’s designer, Guido Van Rossum, created the language based on his inspiration of “programming for everyone.” His nurturing of the Python community has given it the reputation of being the friendliest and most supportive community in the programming world. Python was one of the first open-source languages, resulting in implementations on virtually every platform including embedded systems and machine learning. Its dynamism and ease-of-use makes it ideal for automating small, repetitive tasks but its features also support the creation of large, complex programs.
Python is a true “grass-roots” language; it never had a company promoting it and the attitude of its fans was to never push the language, but simply to help anyone learn it who wants to. The language continues to steadily improve, and in recent years its popularity has skyrocketed.
Python may have been the first mainstream language to combine functional and OO programming. It predated Java with automatic memory management using garbage collection (you typically never have to allocate or release memory yourself) and the ability to run programs on multiple platforms.
Haskell: Pure Functional Programming (1990)
Inspired by Miranda (1985), a proprietary language, Haskell was created as an open standard for pure functional programming research, although it has also been used for products. Syntax and ideas from Haskell have influenced a number of subsequent languages including Kotlin.
Java: Virtual Machines and Garbage Collection (1995)
James Gosling and his team were given the task of writing code for a TV set-top box. They decided they didn’t like C++ and instead of creating the box, created the Java language. The company, Sun Microsystems, put an enormous marketing push behind the free language (still a new idea at the time) to attempt domination of the emerging Internet landscape.
This perceived time window for Internet domination put a lot of pressure on Java language design, resulting in a significant number of flaws (The book Thinking in Java illuminates these flaws so readers are prepared to cope with them). Brian Goetz at Oracle, the current lead developer of Java, has made remarkable and surprising improvements in Java despite the constraints he inherited. Although Java was remarkably successful, an important Kotlin design goal is to fix Java’s flaws so programmers can be more productive.
Java’s success came from two innovative features: a virtual machine and garbage collection. These were available in other languages—for example, LISP, Smalltalk and Python have garbage collection and UCSD Pascal ran on a virtual machine—but they were never considered practical for mainstream languages. Java changed that, and in doing so made programmers significantly more productive.
A virtual machine is an intermediate layer between the language and the hardware. The language doesn’t have to generate machine code for a particular processor; it only needs to generate an intermediate language (bytecode) that runs on the virtual machine. Virtual machines require processing power and, before Java, were believed to be impractical. The Java Virtual Machine (JVM) gave rise to Java’s slogan “write once, run everywhere.” In addition, other languages can be more easily developed by targeting the JVM; examples include Groovy, a Java-like scripting language, and Clojure, a version of LISP.
Garbage collection solves the problem of forgetting to release memory, or if it’s difficult to know when a piece of storage is no longer used. Projects have been significantly delayed or even cancelled because of memory leaks. Although garbage collection appears in some prior languages, it was believed to produce an unacceptable amount of overhead until Java demonstrated its practicality.
JavaScript: Java in Name Only (1995)
The original Web browser simply copied and displayed pages from a Web server. Web browsers proliferated, becoming a new programming platform that needed language support. Java wanted to be this language but was too awkward for the job. JavaScript began as LiveScript and was built into NetScape Navigator, one of the first Web browsers. Renaming it to JavaScript was a marketing ploy by NetScape, as the language has only a vague similarity to Java.
As the Web took off, JavaScript became tremendously important. However, the behavior of JavaScript was so unpredictable that Douglas Crockford wrote a book with the tongue-in-cheek title JavaScript, the Good Parts, where he demonstrated all the problems with the language so programmers could avoid them. Subsequent improvements by the ECMAScript committee have made JavaScript unrecognizable to an original JavaScript programmer. It is now considered a stable and mature language.
Web assembly (WASM) was derived from JavaScript to be a kind of bytecode for web browsers. It often runs much faster than JavaScript and can be generated by other languages. At this writing, the Kotlin team is working to add WASM as a target.
C#: Java for .NET (2000)
C# was designed to provide some of the important abilities of Java on the .NET (Windows) platform, while freeing designers from the constraint of following the Java language. The result included numerous improvements over Java. For example, C# developed the concept of extension functions, which are heavily used in Kotlin. C# also became significantly more functional than Java. Many C# features clearly influenced Kotlin design.
Scala: SCALAble (2003)
Martin Odersky created Scala to run on the Java virtual machine: To piggyback on the work done on the JVM, to interact with Java programs, and possibly with the idea that it might displace Java. As a researcher, Odersky and his team used Scala as a platform to experiment with language features, notably those not included in Java.
These experiments were illuminating and a number of them found their way into
Kotlin, usually in a modified form. For example, the ability to redefine
operators like + for use in special cases is called operator overloading.
This was included in C++ but not Java. Scala added operator overloading but
also allows you to invent new operators by combining any sequence of
characters. This often produces confusing code. A limited form of operator
overloading is included in Kotlin, but you can only overload operators that
already exist.
Scala is also an object-functional hybrid, like Python but with a focus on pure functions and strict objects. This helped inspire Kotlin’s choice to also be an object-functional hybrid.
Like Scala, Kotlin runs on the JVM but it interacts with Java far more easily than Scala does (see Appendix B). In addition, Kotlin targets JavaScript, the Android OS, and it generates native code for other platforms.
Atomic Kotlin evolved from the ideas and material in Atomic Scala.
Groovy: A Dynamic JVM Language (2007)
Dynamic languages are appealing because they are more interactive and concise than static languages. There have been numerous attempts to produce a more dynamic programming experience on the JVM, including Jython (Python) and Clojure (a dialect of Lisp). Groovy was the first to achieve wide acceptance.
At first glance, Groovy appears to be a cleaned-up version of Java, producing a more pleasant programming experience. Most Java code will run unchanged in Groovy, so Java programmers can be quickly productive, later learning the more sophisticated features that provide notable programming improvements over Java.
The Kotlin operators ?. and ?: that deal with the problem of emptiness first
appeared in Groovy.
There are numerous Groovy features that are recognizable in Kotlin. Some of those features also appear in other languages, which probably pushed harder for them to be included in Kotlin.
Why Kotlin? (Introduced 2011, Version 1.0: 2016)
Just as C++ was initially intended to be “a better C,” Kotlin was initially oriented towards being “a better Java.” It has since evolved significantly beyond that goal.
Kotlin pragmatically chooses only the most successful and helpful features from other programming languages—after those features have been field-tested and proven especially valuable.
Thus, if you are coming from another language, you might recognize some features of that language in Kotlin. This is intentional: Kotlin maximizes productivity by leveraging tested concepts.
Readability
Readability is a primary goal in the design of the language. Kotlin syntax is concise—it requires no ceremony for most scenarios, but can still express complex ideas.
Tooling
Kotlin comes from JetBrains, a company that specializes in developer tooling. It has first-class tooling support, and many language features were designed with tooling in mind.
Multi-Paradigm
Kotlin supports multiple programming paradigms, which are gently introduced in this book:
- Imperative programming
- Functional programming
- Object-oriented programming
Multi-Platform
Kotlin source code can be compiled to different target platforms:
-
JVM. The source code compiles into JVM bytecode (
.classfiles), which can then be run on any Java Virtual Machine (JVM). -
Android. Android has its own runtime called
ART (the predecessor was
called Dalvik). The Kotlin source code is compiled into Dalvik Executable Format
(
.dexfiles). - JavaScript, to run inside a web browser.
- Native Binaries by generating machine code for specific platforms and CPUs.
This book focuses on the language itself, using the JVM as the only target platform. Once you know the language, you can apply Kotlin to different application and target platforms.
Two Kotlin Features
This atom does not assume you are a programmer, which makes it hard to explain most of the benefits of Kotlin over the alternatives. There are, however, two topics which are very impactful and can be explained at this early juncture: Java interoperability and the issue of indicating “no value.”
Effortless Java Interoperability
To be “a better C,” C++ must be backwards compatible with the syntax of C, but Kotlin does not have to be backwards compatible with the syntax of Java—it only needs to work with the JVM. This frees the Kotlin designers to create a much cleaner and more powerful syntax, without the visual noise and complication that clutters Java.
For Kotlin to be “a better Java,” the experience of trying it must be pleasant and frictionless, so Kotlin enables effortless integration with existing Java projects. You can write a small piece of Kotlin functionality and slip it in amidst your existing Java code. The Java code doesn’t even know the Kotlin code is there—it just looks like more Java code.
Companies often investigate a new language by building a standalone program with that language. Ideally, this program is beneficial but nonessential, so if the project fails it can be terminated with minimal damage. Not every company wants to spend the kind of resources necessary for this type of experimentation. Because Kotlin seamlessly integrates into an existing Java system (and benefits from that system’s tests), it becomes very cheap or even free to try Kotlin to see whether it’s a good fit.
In addition, JetBrains, the company that creates Kotlin, provides IntelliJ IDEA in a “Community” (free) version, which includes support for both Java and Kotlin along with the ability to easily integrate the two. It even has a tool that takes Java code and (mostly) rewrites it to Kotlin.
Appendix B covers Java interoperability.
Representing Emptiness
An especially beneficial Kotlin feature is its solution to a challenging programming problem.
What do you do when someone hands you a dictionary and asks you to look up a word that doesn’t exist? You could guarantee results by making up definitions for unknown words. A more useful approach is just to say, “There’s no definition for that word.” This demonstrates a significant problem in programming: How do you indicate “no value” for a piece of storage that is uninitialized, or for the result of an operation?
The null reference was invented in 1965 for ALGOL by Tony Hoare, who later called it “my billion-dollar mistake.” One problem was that it was too simple—sometimes being told a room is empty isn’t enough. You might need to know, for example, why it is empty. This leads to the second problem: the implementation. For efficiency’s sake, it was typically just a special value that could fit in a small amount of memory, and what better than the memory already allocated for that information?
The original C language did not automatically initialize storage, which caused numerous problems. C++ improved the situation by setting newly-allocated storage to all zeroes. Thus, if a numerical value isn’t initialized, it is simply a numerical zero. This didn’t seem so bad but it allowed uninitialized values to quietly slip through the cracks (newer C and C++ compilers often warn you about these). Worse, if a piece of storage was a pointer—used to indicate (“point to”) another piece of storage—a null pointer would point at location zero in memory, which is almost certainly not what you want.
Java prevents accesses to uninitialized values by reporting such errors at runtime. Although this discovers uninitialized values, it doesn’t solve the problem because the only way you can verify that your program won’t crash is by running it. There are swarms of these kinds of bugs in Java code, and programmers waste huge amounts of time finding them.
Kotlin solves this problem by preventing operations that might cause null errors at compile time, before the program can run. This is the single-most celebrated feature by Java programmers adopting Kotlin. This one feature can minimize or eliminate Java’s null errors, saving your project significant amounts of time and money.
An Abundance of Benefits
The two features we were able to explain here (without requiring more programming knowledge) make a huge difference whether or not you’re a Java programmer. If Kotlin is your first language and you end up on a project that needs more programmers, it is much easier to recruit one of the many existing Java programmers into Kotlin.
Kotlin has many other benefits, which we cannot explain until you know more about programming. That’s what the rest of the book is for.
- -
Languages are often selected by passion, not reason… I’m trying to make Kotlin a language that is loved for a reason.—Andrey Breslav, Kotlin Lead Language Designer.
Hello, World!
“Hello, world!” is a program commonly used to demonstrate the basic syntax of programming languages.
We develop this program in several steps so you understand its parts.
First, let’s examine an empty program that does nothing at all:
// HelloWorld/EmptyProgram.kt
fun main() {
// Program code here ...
}
The example starts with a comment, which is illuminating text that is ignored
by Kotlin. // (two forward slashes) begins a comment that goes to the end of
the current line:
// Single-line comment
Kotlin ignores the // and everything after it until the end of the line. On
the following line, it pays attention again.
The first line of each example in this book is a comment starting with the name
of the the subdirectory containing the source-code file (Here, HelloWorld)
followed by the name of the file: EmptyProgram.kt. The example subdirectory
for each atom corresponds to the name of that atom.
keywords are reserved by the language and given special meaning. The keyword
fun is short for function. A function is a collection of code that can be
executed using that function’s name (we spend a lot of time on functions
throughout the book). The function’s name follows the fun keyword, so in this
case it’s main() (in prose, we follow the function name with parentheses).
main() is actually a special name for a function; it indicates the “entry
point” for a Kotlin program. A Kotlin program can have many functions with
many different names, but main() is the one that’s automatically called when
you execute the program.
The parameter list follows the function name and is enclosed by parentheses.
Here, we don’t pass anything into main() so the parameter list is empty.
The function body appears after the parameter list. It begins with an opening
brace ({) and ends with a closing brace (}). The function body contains
statements and expressions. A statement produces an effect, and an
expression yields a result.
EmptyProgram.kt contains no statements or expressions in the body, just a
comment.
Let’s make the program display “Hello, world!” by adding a line in the main()
body:
// HelloWorld/HelloWorld.kt
fun main() {
println("Hello, world!")
}
/* Output:
Hello, world!
*/
The line that displays the greeting begins with println(). Like main(),
println() is a function. This line calls the function, which executes its
body. You give the function name, followed by parentheses containing one or
more parameters. In this book, when referring to a function in the prose, we add
parentheses after the name as a reminder that it is a function. Here, we say
println().
println() takes a single parameter, which is a String. You define a String
by putting characters inside quotes.
println() moves the cursor to a new line after displaying its parameter, so
subsequent output appears on the next line. You can use print() instead,
which leaves the cursor on the same line.
Unlike some languages, you don’t need a semicolon at the end of an expression in Kotlin. It’s only necessary if you put more than one expression on a single line (this is discouraged).
For some examples in the book, we show the output at the end of the listing,
inside a multiline comment. A multiline comment starts with a /* (a forward
slash followed by an asterisk) and continues—including line breaks (which we
call newlines)—until a */ (an asterisk followed by a forward slash) ends
the comment:
/* A multiline comment
Doesn't care
about newlines */
It’s possible to add code on the same line after the closing */ of a
comment, but it’s confusing, so people don’t usually do it.
Comments add information that isn’t obvious from reading the code. If comments only repeat what the code says, they become annoying and people start ignoring them. When code changes, programmers often forget to update comments, so it’s good practice to use comments judiciously, mainly for highlighting tricky aspects of your code.
Exercises and solutions can be found at www.AtomicKotlin.com.
var & val
When an identifier holds data, you must decide whether it can be reassigned.
You create identifiers to refer to elements in your program. The most basic decision for a data identifier is whether it can change its contents during program execution, or if it can only be assigned once. This is controlled by two keywords:
-
var, short for variable, which means you can reassign its contents. -
val, short for value, which means you can only initialize it; you cannot reassign it.
You define a var like this:
var identifier = initialization
The var keyword is followed by the identifier, an equals sign and then the
initialization value. The identifier begins with a letter or an underscore,
followed by letters, numbers and underscores. Upper and lower case are
distinguished (so thisvalue and thisValue are different).
Here are some var definitions:
// VarAndVal/Vars.kt
fun main() {
var whole = 11 // [1]
var fractional = 1.4 // [2]
var words = "Twas Brillig" // [3]
println(whole)
println(fractional)
println(words)
}
/* Output:
11
1.4
Twas Brillig
*/
In this book we mark lines with commented numbers in square brackets so we can refer to them in the text like this:
-
[1] Create a
varnamedwholeand store11in it. -
[2] Store the “fractional number”
1.4in thevar fractional. -
[3] Store some text (a
String) in thevar words.
Note that println() can take any single value as an argument.
As the name variable implies, a var can vary. That is, you can change the
data stored in a var. We say that a var is mutable:
// VarAndVal/AVarIsMutable.kt
fun main() {
var sum = 1
sum = sum + 2
sum += 3
println(sum)
}
/* Output:
6
*/
The assignment sum = sum + 2 takes the current value of sum, adds two, and
assigns the result back into sum.
The assignment sum += 3 means the same as sum = sum + 3. The += operator
takes the previous value stored in sum and increases it by 3, then assigns
that new result back to sum.
Changing the value stored in a var is a useful way to express changes.
However, when the complexity of a program increases, your code is clearer,
safer and easier to understand if the values represented by your identifiers
cannot change—that is, they cannot be reassigned. We specify an unchanging
identifier using the val keyword instead of var. A val can only be
assigned once, when it is created:
val identifier = initialization
The val keyword comes from value, indicating something that cannot
change—it is immutable. Choose val instead of var whenever possible.
The Vars.kt example at the beginning of this atom can be rewritten using
vals:
// VarAndVal/Vals.kt
fun main() {
val whole = 11
// whole = 15 // Error // [1]
val fractional = 1.4
val words = "Twas Brillig"
println(whole)
println(fractional)
println(words)
}
/* Output:
11
1.4
Twas Brillig
*/
-
[1] Once you initialize a
val, you can’t reassign it. If we try to reassignwholeto a different number, Kotlin complains, saying “Val cannot be reassigned.”
Choosing descriptive names for your identifiers makes your code easier to
understand and often reduces the need for comments. In Vals.kt, you have no
idea what whole represents. If your program is storing the number 11 to
represent the time of day when you get coffee, it’s more obvious to others if
you name it coffeetime and easier to read if it’s coffeeTime (following
Kotlin style, we make the first letter lowercase).
- -
vars are useful when data must change as the program is running. This sounds
like a common requirement, but turns out to be avoidable in practice. In
general, your programs are easier to extend and maintain if you use vals.
However, on rare occasions it’s too complex to solve a problem using only
vals. For that reason, Kotlin gives you the flexibility of vars. However,
as you spend more time with vals you’ll discover that you almost never need
vars and that your programs are safer and more reliable without them.
Exercises and solutions can be found at www.AtomicKotlin.com.
Data Types
Data can have different types.
To solve a math problem, you write an expression:
5.9 + 6
You know that adding those numbers produces another number. Kotlin knows that
too. You know that one is a fractional number (5.9), which Kotlin calls a
Double, and the other is a whole number (6), which Kotlin calls an Int.
You know the result is a fractional number.
A type (also called data type) tells Kotlin how you intend to use that data. A type defines the set of values an expression of that type may produce. A type also defines the operations that can be performed on the data, the meaning of the data, and how values of that type can be stored.
Kotlin uses types to verify that your expressions are correct. In the above
expression, Kotlin creates a new value of type Double to hold the result.
Kotlin tries to adapt to what you need. If you ask it to do something that
violates type rules, it produces an error message. For example, try adding a
String and a number:
// DataTypes/StringPlusNumber.kt
fun main() {
println("Sally" + 5.9)
}
/* Output:
Sally5.9
*/
Types tell Kotlin how to use them correctly. In this case, the type rules tell
Kotlin how to add a number to a String: by appending the two values and
creating a String to hold the result.
Now try multiplying a String and a Double by changing the + in
StringPlusNumber.kt to a *:
"Sally" * 5.9
Combining types this way doesn’t make sense to Kotlin, so it gives you an error.
In var & val, we stored several types. Kotlin figured out
the types for us, based on how we used them. This is called type inference.
We can be more verbose and specify the type:
val identifier: Type = initialization
You start with the val or var keyword, followed by the identifier, a colon,
the type, an =, and the initialization value. So instead of saying:
val n = 1
var p = 1.2
You can say:
val n: Int = 1
var p: Double = 1.2
We’ve told Kotlin that n is an Int and p is a Double, rather than
letting it infer the type.
Here are some of Kotlin’s basic types:
// DataTypes/Types.kt
fun main() {
val whole: Int = 11 // [1]
val fractional: Double = 1.4 // [2]
val trueOrFalse: Boolean = true // [3]
val words: String = "A value" // [4]
val character: Char = 'z' // [5]
val lines: String = """Triple quotes let
you have many lines
in your string""" // [6]
println(whole)
println(fractional)
println(trueOrFalse)
println(words)
println(character)
println(lines)
}
/* Output:
11
1.4
true
A value
z
Triple quotes let
you have many lines
in your string
*/
-
[1] The
Intdata type is an integer, which means it only holds whole numbers. -
[2] To hold fractional numbers, use a
Double. -
[3] A
Booleandata type only holds the two special valuestrueandfalse. -
[4] A
Stringholds a sequence of characters. You assign a value using a double-quotedString. -
[5] A
Charholds one character. -
[6] If you have many lines and/or special characters, surround them with
triple-double-quotes (this is a triple-quoted
String).
Kotlin uses type inference to determine the meaning of mixed types. When mixing
Ints and Doubles during addition, for example, Kotlin decides the type for
the resulting value:
// DataTypes/Inference.kt
fun main() {
val n = 1 + 1.2
println(n)
}
/* Output:
2.2
*/
When you add an Int to a Double using type inference, Kotlin determines
that the result n is a Double and ensures that it follows all the rules
for Doubles.
Kotlin’s type inference is part of its strategy of doing work for the programmer. If you leave out the type declaration, Kotlin can usually infer it.
Exercises and solutions can be found at www.AtomicKotlin.com.
Functions
A function is like a small program that has its own name, and can be executed (invoked) by calling that name from another function.
A function combines a group of activities, and is the most basic way to organize your programs and to re-use code.
You pass information into a function, and the function uses that information to calculate and produce a result. The basic form of a function is:
fun functionName(p1: Type1, p2: Type2, ...): ReturnType {
lines of code
return result
}
p1 and p2 are the parameters: the information you pass into the function.
Each parameter has an identifier name (p1, p2) followed by a colon and the
type of that parameter. The closing parenthesis of the parameter list is
followed by a colon and the type of result produced by the function. The lines
of code in the function body are enclosed in curly braces. The expression
following the return keyword is the result the function produces when it’s
finished.
A parameter is how you define what is passed into a function—it’s the placeholder. An argument is the actual value that you pass into the function.
The combination of name, parameters and return type is called the function signature.
Here’s a simple function called multiplyByTwo():
// Functions/MultiplyByTwo.kt
fun multiplyByTwo(x: Int): Int { // [1]
println("Inside multiplyByTwo") // [2]
return x * 2
}
fun main() {
val r = multiplyByTwo(5) // [3]
println(r)
}
/* Output:
Inside multiplyByTwo
10
*/
-
[1] Notice the
funkeyword, the function name, and the parameter list consisting of a single parameter. This function takes anIntparameter and returns anInt. -
[2] These two lines are the body of the function. The final line returns
the value of its calculation
x * 2as the result of the function. -
[3] This line calls the function with an appropriate argument, and
captures the result into
val r. A function call mimics the form of its declaration: the function name, followed by arguments inside parentheses.
The function code is executed by calling the function, using the function name
multiplyByTwo() as an abbreviation for that code. This is why functions are
the most basic form of simplification and code reuse in programming. You can
also think of a function as an expression with substitutable values (the
parameters).
println() is also a function call—it just happens to be provided by Kotlin.
We refer to functions defined by Kotlin as library functions.
If the function doesn’t provide a meaningful result, its return type is Unit.
You can specify Unit explicitly if you want, but Kotlin lets you omit it:
// Functions/SayHello.kt
fun sayHello() {
println("Hallo!")
}
fun sayGoodbye(): Unit {
println("Auf Wiedersehen!")
}
fun main() {
sayHello()
sayGoodbye()
}
/* Output:
Hallo!
Auf Wiedersehen!
*/
Both sayHello() and sayGoodbye() return Unit, but sayHello() leaves out
the explicit declaration. The main() function also returns Unit.
If a function is only a single expression, you can use the abbreviated syntax of an equals sign followed by the expression:
fun functionName(arg1: Type1, arg2: Type2, ...): ReturnType = expression
A function body surrounded by curly braces is called a block body. A function body using the equals syntax is called an expression body.
Here, multiplyByThree() uses an expression body:
// Functions/MultiplyByThree.kt
fun multiplyByThree(x: Int): Int = x * 3
fun main() {
println(multiplyByThree(5))
}
/* Output:
15
*/
This is a short version of saying return x * 3 inside a block body.
Kotlin infers the return type of a function that has an expression body:
// Functions/MultiplyByFour.kt
fun multiplyByFour(x: Int) = x * 4
fun main() {
val result: Int = multiplyByFour(5)
println(result)
}
/* Output:
20
*/
Kotlin infers that multiplyByFour() returns an Int.
Kotlin can only infer return types for expression bodies. If a function has
a block body and you omit its type, that function returns Unit.
- -
When writing functions, choose descriptive names. This makes the code easier to read, and can often reduce the need for code comments. We can’t always be as descriptive as we would prefer with the function names in this book because we’re constrained by line widths.
Exercises and solutions can be found at www.AtomicKotlin.com.
if Expressions
An
ifexpression makes a choice.
The if keyword tests an expression to see whether it’s true or false and
performs an action based on the result. A true-or-false expression is called a
Boolean, after the mathematician George Boole who invented the logic behind
these expressions. Here’s an example using the > (greater than) and < (less
than) symbols:
// IfExpressions/If1.kt
fun main() {
if (1 > 0)
println("It's true!")
if (10 < 11) {
println("10 < 11")
println("ten is less than eleven")
}
}
/* Output:
It's true!
10 < 11
ten is less than eleven
*/
The expression inside the parentheses after the if must evaluate to true or
false. If true, the following expression is executed. To execute multiple
lines, place them within curly braces.
We can create a Boolean expression in one place, and use it in another:
// IfExpressions/If2.kt
fun main() {
val x: Boolean = 1 >= 1
if (x)
println("It's true!")
}
/* Output:
It's true!
*/
Because x is Boolean, the if can test it directly by saying if(x).
The Boolean >= operator returns true if the expression on the left side of
the operator is greater than or equal to that on the right. Likewise, <=
returns true if the expression on the left side is less than or equal to
that on the right.
The else keyword allows you to handle both true and false paths:
// IfExpressions/If3.kt
fun main() {
val n: Int = -11
if (n > 0)
println("It's positive")
else
println("It's negative or zero")
}
/* Output:
It's negative or zero
*/
The else keyword is only used in conjunction with if. You are not limited
to a single check—you can test multiple combinations by combining else and
if:
// IfExpressions/If4.kt
fun main() {
val n: Int = -11
if (n > 0)
println("It's positive")
else if (n == 0)
println("It's zero")
else
println("It's negative")
}
/* Output:
It's negative
*/
Here we use == to check two numbers for equality. != tests for inequality.
The typical pattern is to start with if, followed by as many else if
clauses as you need, ending with a final else for anything that doesn’t match
all the previous tests. When an if expression reaches a certain size and
complexity you’ll probably use a when expression instead. when is described
later in the book, in when Expressions.
The “not” operator ! tests for the opposite of a Boolean expression:
// IfExpressions/If5.kt
fun main() {
val y: Boolean = false
if (!y)
println("!y is true")
}
/* Output:
!y is true
*/
To verbalize if(!y), say “if not y.”
The entire if is an expression, so it can produce a result:
// IfExpressions/If6.kt
fun main() {
val num = 10
val result = if (num > 100) 4 else 42
println(result)
}
/* Output:
42
*/
Here, we store the value produced by the entire if expression in an
intermediate identifier called result. If the condition is satisfied, the
first branch produces result. If not, the else value becomes result.
Let’s practice creating functions. Here’s one that takes a Boolean parameter:
// IfExpressions/TrueOrFalse.kt
fun trueOrFalse(exp: Boolean): String {
if (exp)
return "It's true!" // [1]
return "It's false" // [2]
}
fun main() {
val b = 1
println(trueOrFalse(b < 3))
println(trueOrFalse(b >= 3))
}
/* Output:
It's true!
It's false
*/
The Boolean parameter exp is passed to the function trueOrFalse(). If the
argument is passed as an expression, such as b < 3, that expression is first
evaluated and the result is passed to the function. trueOrFalse() tests exp
and if the result is true, line [1] is executed, otherwise line [2] is
executed.
-
[1]
returnsays, “Leave the function and produce this value as the function’s result.” Notice thatreturncan appear anywhere in a function and does not have to be at the end.
Rather than using return as in the previous example, you can use the else
keyword to produce the result as an expression:
// IfExpressions/OneOrTheOther.kt
fun oneOrTheOther(exp: Boolean): String =
if (exp)
"True!" // No 'return' necessary
else
"False"
fun main() {
val x = 1
println(oneOrTheOther(x == 1))
println(oneOrTheOther(x == 2))
}
/* Output:
True!
False
*/
Instead of two expressions in trueOrFalse(), oneOrTheOther() is a single
expression. The result of that expression is the result of the function, so the
if expression becomes the function body.
Exercises and solutions can be found at www.AtomicKotlin.com.
String Templates
A
Stringtemplate is a programmatic way to generate aString.
If you put a $ before an identifier name, the String template will insert
that identifier’s contents into the String:
// StringTemplates/StringTemplates.kt
fun main() {
val answer = 42
println("Found $answer!") // [1]
println("printing a $1") // [2]
}
/* Output:
Found 42!
printing a $1
*/
-
[1]
$answersubstitutes the value ofanswer. -
[2] If what follows the
$isn’t recognizable as a program identifier, nothing special happens.
You can also insert values into a String using concatenation (+):
// StringTemplates/StringConcatenation.kt
fun main() {
val s = "hi\n" // \n is a newline character
val n = 11
val d = 3.14
println("first: " + s + "second: " +
n + ", third: " + d)
}
/* Output:
first: hi
second: 11, third: 3.14
*/
Placing an expression inside ${} evaluates it. The return value is converted
to a String and inserted into the resulting String:
// StringTemplates/ExpressionInTemplate.kt
fun main() {
val condition = true
println(
"${if (condition) 'a' else 'b'}") // [1]
val x = 11
println("$x + 4 = ${x + 4}")
}
/* Output:
a
11 + 4 = 15
*/
-
[1]
if(condition) 'a' else 'b'is evaluated and the result is substituted for the entire${}expression.
When a String must include a special character, such as a quote, you can either
escape that character with a \ (backslash), or use a String literal in
triple quotes:
// StringTemplates/TripleQuotes.kt
fun main() {
val s = "value"
println("s = \"$s\".")
println("""s = "$s".""")
}
/* Output:
s = "value".
s = "value".
*/
With triple quotes, you insert a value of an expression the same way you do it
for a single-quoted String.
Exercises and solutions can be found at www.AtomicKotlin.com.
Number Types
Different types of numbers are stored in different ways.
If you create an identifier and assign an integer value to it, Kotlin infers
the Int type:
// NumberTypes/InferInt.kt
fun main() {
val million = 1_000_000 // Infers Int
println(million)
}
/* Output:
1000000
*/
For readability, Kotlin allows underscores within numerical values.
The basic mathematical operators for numbers are the ones available in most
programming languages: addition (+), subtraction (-), division (/),
multiplication (*) and modulus (%), which produces the remainder from
integer division:
// NumberTypes/Modulus.kt
fun main() {
val numerator: Int = 19
val denominator: Int = 10
println(numerator % denominator)
}
/* Output:
9
*/
Integer division truncates its result:
// NumberTypes/IntDivisionTruncates.kt
fun main() {
val numerator: Int = 19
val denominator: Int = 10
println(numerator / denominator)
}
/* Output:
1
*/
If the operation had rounded the result, the output would be 2.
The order of operations follows basic arithmetic:
// NumberTypes/OpOrder.kt
fun main() {
println(45 + 5 * 6)
}
/* Output:
75
*/
The multiplication operation 5 * 6 is performed first, followed by the
addition 45 + 30.
If you want 45 + 5 to happen first, use parentheses:
// NumberTypes/OpOrderParens.kt
fun main() {
println((45 + 5) * 6)
}
/* Output:
300
*/
Now let’s calculate body mass index (BMI), which is weight in kilograms
divided by the square of the height in meters. If you have a BMI of less than
18.5, you are underweight. Between 18.5 and 24.9 is normal weight. BMI of
25 and higher is overweight. This example also shows the preferred formatting
style when you can’t fit the function’s parameters on a single line:
// NumberTypes/BMIMetric.kt
fun bmiMetric(
weight: Double,
height: Double
): String {
val bmi = weight / (height * height) // [1]
return if (bmi < 18.5) "Underweight"
else if (bmi < 25) "Normal weight"
else "Overweight"
}
fun main() {
val weight = 72.57 // 160 lbs
val height = 1.727 // 68 inches
val status = bmiMetric(weight, height)
println(status)
}
/* Output:
Normal weight
*/
-
[1] If you remove the parentheses, you divide
weightbyheightthen multiply that result byheight. That’s a much larger number, and the wrong answer.
bmiMetric() uses Doubles for the weight and height. A Double holds very
large and very small floating-point numbers.
Here’s a version using English units, represented by Int parameters:
// NumberTypes/BMIEnglish.kt
fun bmiEnglish(
weight: Int,
height: Int
): String {
val bmi =
weight / (height * height) * 703.07 // [1]
return if (bmi < 18.5) "Underweight"
else if (bmi < 25) "Normal weight"
else "Overweight"
}
fun main() {
val weight = 160
val height = 68
val status = bmiEnglish(weight, height)
println(status)
}
/* Output:
Underweight
*/
Why does the result differ from bmiMetric(), which uses Doubles? When you
divide an integer by another integer, Kotlin produces an integer result. The
standard way to deal with the remainder during integer division is
truncation, meaning “chop it off and throw it away” (there’s no rounding). So
if you divide 5 by 2 you get 2, and 7/10 is zero. When Kotlin
calculates bmi in expression [1], it divides 160 by 68 * 68 and gets
zero. It then multiplies zero by 703.07 to get zero.
To avoid this problem, move 703.07 to the front of the calculation. The
calculations are then forced to be Double:
val bmi = 703.07 * weight / (height * height)
The Double parameters in bmiMetric() prevent this problem. Convert
computations to the desired type as early as possible to preserve accuracy.
All programming languages have limits to what they can store within an integer.
Kotlin’s Int type can take values between -231 and +231-1, a constraint
of the Int 32-bit representation. If you sum or multiply two Ints that are
big enough, you’ll overflow the result:
// NumberTypes/IntegerOverflow.kt
fun main() {
val i: Int = Int.MAX_VALUE
println(i + i)
}
/* Output:
-2
*/
Int.MAX_VALUE is a predefined value which is the largest number an Int can
hold.
The overflow produces a result that is clearly incorrect, as it is both negative and much smaller than we expect. Kotlin issues a warning whenever it detects a potential overflow.
Preventing overflow is your responsibility as a developer. Kotlin can’t always detect overflow during compilation, and it doesn’t prevent overflow because that would produce an unacceptable performance impact.
If your program contains large numbers, you can use Longs, which accommodate
values from -263 to +263-1. To define a val
of type Long, you can specify the type explicitly or put L at the end of a
numeric literal, which tells Kotlin to treat that value as a Long:
// NumberTypes/LongConstants.kt
fun main() {
val i = 0 // Infers Int
val l1 = 0L // L creates Long
val l2: Long = 0 // Explicit type
println("$l1 $l2")
}
/* Output:
0 0
*/
By changing to Longs we prevent the overflow in IntegerOverflow.kt:
// NumberTypes/UsingLongs.kt
fun main() {
val i = Int.MAX_VALUE
println(0L + i + i) // [1]
println(1_000_000 * 1_000_000L) // [2]
}
/* Output:
4294967294
1000000000000
*/
Using a numeric literal in both [1] and [2] forces Long calculations,
and also produces a result of type Long. The location where the L appears
is unimportant. If one of the values is Long, the resulting expression is
Long.
Although they can hold much larger values than Ints, Longs still have size
limitations:
// NumberTypes/BiggestLong.kt
fun main() {
println(Long.MAX_VALUE)
}
/* Output:
9223372036854775807
*/
Long.MAX_VALUE is the largest value a Long can hold.
Exercises and solutions can be found at www.AtomicKotlin.com.
Booleans
ifExpressions demonstrated the “not” operator!, which negates aBooleanvalue. This atom introduces more Boolean Algebra.
We start with the operators “and” and “or”:
-
&&(and): Producestrueonly if theBooleanexpression on the left of the operator and the one on the right are bothtrue. -
||(or): Producestrueif either the expression on the left or right of the operator istrue, or if both aretrue.
In this example, we determine whether a business is open or closed, based on
the hour:
// Booleans/Open1.kt
fun isOpen1(hour: Int) {
val open = 9
val closed = 20
println("Operating hours: $open - $closed")
val status =
if (hour >= open && hour < closed) // [1]
true
else
false
println("Open: $status")
}
fun main() = isOpen1(6)
/* Output:
Operating hours: 9 - 20
Open: false
*/
main() is a single function call, so we can use an expression body as
described in Functions.
The if expression in [1] Checks whether hour is between the opening
time and closing time, so we combine the expressions with the Boolean &&
(and).
The if expression can be simplified. The result of the expression
if(cond) true else false is just cond:
// Booleans/Open2.kt
fun isOpen2(hour: Int) {
val open = 9
val closed = 20
println("Operating hours: $open - $closed")
val status = hour >= open && hour < closed
println("Open: $status")
}
fun main() = isOpen2(6)
/* Output:
Operating hours: 9 - 20
Open: false
*/
Let’s reverse the logic and check whether the business is currently closed. The
“or” operator || produces true if at least one of the conditions is
satisfied:
// Booleans/Closed.kt
fun isClosed(hour: Int) {
val open = 9
val closed = 20
println("Operating hours: $open - $closed")
val status = hour < open || hour >= closed
println("Closed: $status")
}
fun main() = isClosed(6)
/* Output:
Operating hours: 9 - 20
Closed: true
*/
Boolean operators enable complicated logic in compact expressions. However,
things can easily become confusing. Strive for readability and specify your
intentions explicitly.
Here’s an example of a complicated Boolean expression where different
evaluation order produces different results:
// Booleans/EvaluationOrder.kt
fun main() {
val sunny = true
val hoursSleep = 6
val exercise = false
val temp = 55
// [1]:
val happy1 = sunny && temp > 50 ||
exercise && hoursSleep > 7
println(happy1)
// [2]:
val sameHappy1 = (sunny && temp > 50) ||
(exercise && hoursSleep > 7)
println(sameHappy1)
// [3]:
val notSame =
(sunny && temp > 50 || exercise) &&
hoursSleep > 7
println(notSame)
}
/* Output:
true
true
false
*/
The Boolean expressions are sunny, temp > 50, exercise, and
hoursSleep > 7. We read happy1 as “It’s sunny and the temperature is
greater than 50 or I’ve exercised and had more than 7 hours of sleep.” But
does && have precedence over ||, or the opposite?
The expression in [1] uses Kotlin’s default evaluation order. This produces the same result as the expression in [2] because, without parentheses, the “ands” are evaluated first, then the “or”. The expression in [3] uses parentheses to produce a different result. In [3], we’re only happy if we get at least 7 hours of sleep.
Exercises and solutions can be found at www.AtomicKotlin.com.
Repetition with while
Computers are ideal for repetitive tasks.
The most basic form of repetition uses the while keyword. This repeats a
block as long as the controlling Boolean expression is true:
while (Boolean-expression) {
// Code to be repeated
}
The Boolean expression is evaluated once at the beginning of the loop and again before each further iteration through the block.
// RepetitionWithWhile/WhileLoop.kt
fun condition(i: Int) = i < 100 // [1]
fun main() {
var i = 0
while (condition(i)) { // [2]
print(".")
i += 10 // [3]
}
}
/* Output:
..........
*/
-
[1] The comparison operator
<produces aBooleanresult, so Kotlin infersBooleanas the result type forcondition(). -
[2] The conditional expression for the
whilesays: “repeat the statements in the body as long ascondition()returnstrue.” -
[3] The
+=operator adds10toiand assigns the result toiin a single operation (imust be avarfor this to work). This is equivalent to:
i = i + 10
There’s a second way to use while, in conjunction with the do keyword:
do {
// Code to be repeated
} while (Boolean-expression)
Rewriting WhileLoop.kt to use a do-while produces:
// RepetitionWithWhile/DoWhileLoop.kt
fun main() {
var i = 0
do {
print(".")
i += 10
} while (condition(i))
}
/* Output:
..........
*/
The sole difference between while and do-while is that the body of the
do-while always executes at least once, even if the Boolean expression
initially produces false. In a while, if the conditional is false the
first time, then the body never executes. In practice, do-while is less
common than while.
The short versions of assignment operators are available for all the arithmetic
operations: +=, -=, *=, /=, and %=. This uses -= and %=:
// RepetitionWithWhile/AssignmentOperators.kt
fun main() {
var n = 10
val d = 3
print(n)
while (n > d) {
n -= d
print(" - $d")
}
println(" = $n")
var m = 10
print(m)
m %= d
println(" % $d = $m")
}
/* Output:
10 - 3 - 3 - 3 = 1
10 % 3 = 1
*/
To calculate the remainder of the integer division of two natural numbers, we
start with a while loop, then use the remainder operator.
Adding 1 and subtracting 1 from a number are so common that they have their
own increment and decrement operators: ++ and --. You can replace i += 1
with i++:
// RepetitionWithWhile/IncrementOperator.kt
fun main() {
var i = 0
while (i < 4) {
print(".")
i++
}
}
/* Output:
....
*/
In practice, while loops are not used for iterating over a range of numbers.
The for loop is used instead. This is covered in the next atom.
Exercises and solutions can be found at www.AtomicKotlin.com.
Looping & Ranges
The
forkeyword executes a block of code for each value in a sequence.
The set of values can be a range of integers, a String, or, as you’ll see later
in the book, a collection of items. The in keyword indicates that you are
stepping through values:
for (v in values) {
// Do something with v
}
Each time through the loop, v is given the next element in values.
Here’s a for loop repeating an action a fixed number of times:
// LoopingAndRanges/RepeatThreeTimes.kt
fun main() {
for (i in 1..3) {
println("Hey $i!")
}
}
/* Output:
Hey 1!
Hey 2!
Hey 3!
*/
The output shows the index i receiving each value in the range from 1 to 3.
A range is an interval of values defined by a pair of endpoints. There are two basic ways to define ranges:
// LoopingAndRanges/DefiningRanges.kt
fun main() {
val range1 = 1..10 // [1]
val range2 = 0 until 10 // [2]
println(range1)
println(range2)
}
/* Output:
1..10
0..9
*/
-
[1] Using
..syntax includes both bounds in the resulting range. -
[2]
untilexcludes the end. The output shows that10is not part of the range.
Displaying a range produces a readable format.
This sums the numbers from 10 to 100:
// LoopingAndRanges/SumUsingRange.kt
fun main() {
var sum = 0
for (n in 10..100) {
sum += n
}
println("sum = $sum")
}
/* Output:
sum = 5005
*/
You can iterate over a range in reverse order. You can also use a step value
to change the interval from the default of 1:
// LoopingAndRanges/ForWithRanges.kt
fun showRange(r: IntProgression) {
for (i in r) {
print("$i ")
}
print(" // $r")
println()
}
fun main() {
showRange(1..5)
showRange(0 until 5)
showRange(5 downTo 1) // [1]
showRange(0..9 step 2) // [2]
showRange(0 until 10 step 3) // [3]
showRange(9 downTo 2 step 3)
}
/* Output:
1 2 3 4 5 // 1..5
0 1 2 3 4 // 0..4
5 4 3 2 1 // 5 downTo 1 step 1
0 2 4 6 8 // 0..8 step 2
0 3 6 9 // 0..9 step 3
9 6 3 // 9 downTo 3 step 3
*/
-
[1]
downToproduces a decreasing range. -
[2]
stepchanges the interval. Here, the range steps by a value of two instead of one. -
[3]
untilcan also be used withstep. Notice how this affects the output.
In each case the sequence of numbers form an arithmetic progression.
showRange() accepts an IntProgression parameter, which is a built-in type
that includes Int ranges. Notice that the String representation of each
IntProgression as it appears in output comment for each line is often
different from the range passed into showRange()—the IntProgression is
translating the input into an equivalent common form.
You can also produce a range of characters. This for iterates from a to z:
// LoopingAndRanges/ForWithCharRange.kt
fun main() {
for (c in 'a'..'z') {
print(c)
}
}
/* Output:
abcdefghijklmnopqrstuvwxyz
*/
You can iterate over a range of elements that are whole quantities, like integers and characters, but not floating-point values.
Square brackets access characters by index. Because we start counting
characters in a String at zero, s[0] selects the first character of the
String s. Selecting s.lastIndex produces the final index number:
// LoopingAndRanges/IndexIntoString.kt
fun main() {
val s = "abc"
for (i in 0..s.lastIndex) {
print(s[i] + 1)
}
}
/* Output:
bcd
*/
Sometimes people describe s[0] as “the zeroth character.”
Characters are stored as numbers corresponding to their Unicode values, so adding an integer to a character produces a new character corresponding to the new code value:
// LoopingAndRanges/AddingIntToChar.kt
fun main() {
val ch: Char = 'a'
println(ch + 25)
println(ch < 'z')
}
/* Output:
z
true
*/
The second println() shows that you can compare character codes.
A for loop can iterate over Strings directly:
// LoopingAndRanges/IterateOverString.kt
fun main() {
for (ch in "Jnskhm ") {
print(ch + 1)
}
}
/* Output:
Kotlin!
*/
ch receives each character in turn.
In the following example, the function hasChar() iterates over the String s
and tests whether it contains a given character ch. The return in the
middle of the function stops the function when the answer is found:
// LoopingAndRanges/HasChar.kt
fun hasChar(s: String, ch: Char): Boolean {
for (c in s) {
if (c == ch) return true
}
return false
}
fun main() {
println(hasChar("kotlin", 't'))
println(hasChar("kotlin", 'a'))
}
/* Output:
true
false
*/
The next atom shows that hasChar() is unnecessary—you can use built-in
syntax instead.
If you simply want to repeat an action a fixed number of times, you may use
repeat() instead of a for loop:
// LoopingAndRanges/RepeatHi.kt
fun main() {
repeat(2) {
println("hi!")
}
}
/* Output:
hi!
hi!
*/
repeat() is a standard library function, not a keyword. You’ll see how it was
created much later in the book.
Exercises and solutions can be found at www.AtomicKotlin.com.
The in Keyword
The
inkeyword tests whether a value is within a range.
// InKeyword/MembershipInRange.kt
fun main() {
val percent = 35
println(percent in 1..100)
}
/* Output:
true
*/
In Booleans, you learned to check bounds explicitly:
// InKeyword/MembershipUsingBounds.kt
fun main() {
val percent = 35
println(0 <= percent && percent <= 100)
}
/* Output:
true
*/
0 <= x && x <= 100 is logically equivalent to x in 0..100. IntelliJ IDEA
suggests automatically replacing the first form with the second, which is
easier to read and understand.
The in keyword is used for both iteration and membership. An in inside the
control expression of a for loop means iteration, otherwise in checks
membership:
// InKeyword/IterationVsMembership.kt
fun main() {
val values = 1..3
for (v in values) {
println("iteration $v")
}
val v = 2
if (v in values)
println("$v is a member of $values")
}
/* Output:
iteration 1
iteration 2
iteration 3
2 is a member of 1..3
*/
The in keyword is not limited to ranges. You can also check whether a
character is a part of a String. The following example uses in instead of
hasChar() from the previous atom:
// InKeyword/InString.kt
fun main() {
println('t' in "kotlin")
println('a' in "kotlin")
}
/* Output:
true
false
*/
Later in the book you’ll see that in works with other types, as well.
Here, in tests whether a character belongs to a range of characters:
// InKeyword/CharRange.kt
fun isDigit(ch: Char) = ch in '0'..'9'
fun notDigit(ch: Char) =
ch !in '0'..'9' // [1]
fun main() {
println(isDigit('a'))
println(isDigit('5'))
println(notDigit('z'))
}
/* Output:
false
true
true
*/
-
[1]
!inchecks that a value doesn’t belong to a range.
You can create a Double range, but you can only use it to check for
membership:
// InKeyword/FloatingPointRange.kt
fun inFloatRange(n: Double) {
val r = 1.0..10.0
println("$n in $r? ${n in r}")
}
fun main() {
inFloatRange(0.999999)
inFloatRange(5.0)
inFloatRange(10.0)
inFloatRange(10.0000001)
}
/* Output:
0.999999 in 1.0..10.0? false
5.0 in 1.0..10.0? true
10.0 in 1.0..10.0? true
10.0000001 in 1.0..10.0? false
*/
You can only use .. to define a floating-point range in Kotlin.
You can check whether a String is a member of a range of Strings:
// InKeyword/StringRange.kt
fun main() {
println("ab" in "aa".."az")
println("ba" in "aa".."az")
}
/* Output:
true
false
*/
Here Kotlin uses alphabetic comparison.
Exercises and solutions can be found at www.AtomicKotlin.com.
Expressions & Statements
Statements and expressions are the smallest useful fragments of code in most programming languages.
There’s a basic difference: a statement has an effect, but produces no result. An expression always produces a result.
Because it doesn’t produce a result, a statement must change the state of its surroundings to be useful. Another way to say this is “a statement is called for its side effects” (that is, what it does other than producing a result). As a memory aid:
A statement changes state.
One definition of “express” is “to force or squeeze out,” as in “to express the juice from an orange.” So
An expression expresses.
That is, it produces a result.
The for loop is a statement in Kotlin. You cannot assign it because there’s
no result:
// ExpressionsStatements/ForIsAStatement.kt
fun main() {
// Can't do this:
// val f = for(i in 1..10) {}
// Compiler error message:
// for is not an expression, and
// only expressions are allowed here
}
A for loop is used for its side effects.
An expression produces a value, which can be assigned or used as part of another expression, whereas a statement is always a top-level element.
Every function call is an expression. Even if the function returns Unit and
is called only for its side effects, the result can still be assigned:
// ExpressionsStatements/UnitReturnType.kt
fun unitFun() = Unit
fun main() {
println(unitFun())
val u1: Unit = println(42)
println(u1)
val u2 = println(0) // Type inference
println(u2)
}
/* Output:
kotlin.Unit
42
kotlin.Unit
0
kotlin.Unit
*/
The Unit type contains a single value called Unit, which you can return
directly, as seen in unitFun(). Calling println() also returns Unit. The
val u1 captures the return value of println() and is explicitly declared as
Unit while u2 uses type inference.
if creates an expression, so you can assign its result:
// ExpressionsStatements/AssigningAnIf.kt
fun main() {
val result1 = if (11 > 42) 9 else 5
val result2 = if (1 < 2) {
val a = 11
a + 42
} else 42
val result3 =
if ('x' < 'y')
println("x < y")
else
println("x > y")
println(result1)
println(result2)
println(result3)
}
/* Output:
x < y
5
53
kotlin.Unit
*/
The first output line is x < y, even though result3 isn’t displayed until
the end of main(). This happens because evaluating result3 calls
println(), and the evaluation occurs when result3 is defined.
Notice that a is defined inside the block of code for result2. The result
of the last expression becomes the result of the if expression; here, it’s
the sum of 11 and 42. But what about a? Once you leave the code block (move
outside the curly braces), you can’t access a. It is temporary and is
discarded once you exit the scope of that block.
The increment operator i++ is also an expression, even if it looks like a
statement. Kotlin follows the approach used by C-like languages and provides
two versions of increment and decrement operators with slightly different
semantics. The prefix operator appears before the operand, as in ++i, and
returns the value after the increment happens. You can read it as “first do the
increment, then return the resulting value.” The postfix operator is placed
after the operand, as in i++, and returns the value of i before the
increment occurs. You can read it as “first produce the result, then do the
increment.”
// ExpressionsStatements/PostfixVsPrefix.kt
fun main() {
var i = 10
println(i++)
println(i)
var j = 20
println(++j)
println(j)
}
/* Output:
10
11
21
21
*/
The decrement operator also has two versions: --i and i--. Using increment
and decrement operators within other expressions is discouraged because it can
produce confusing code:
// ExpressionsStatements/Confusing.kt
fun main() {
var i = 1
println(i++ + ++i)
}
Try to guess what the output will be, then check it.
Exercises and solutions can be found at www.AtomicKotlin.com.
Summary 1
This atom summarizes and reviews the atoms in Section I, starting at Hello, World! and ending with Expressions & Statements.
If you’re an experienced programmer, this should be your first atom. New programmers should read this atom and perform the exercises as a review of Section I.
If anything isn’t clear to you, study the associated atom for that topic (the sub-headings correspond to atom titles).
Hello, World
Kotlin supports both // single-line comments, and /*-to-*/ multiline
comments. A program’s entry point is the function main():
// Summary1/Hello.kt
fun main() {
println("Hello, world!")
}
/* Output:
Hello, world!
*/
The first line of each example in this book is a comment containing the name of
the atom’s subdirectory, followed by a / and the name of the file. You can
find all the extracted code examples through
AtomicKotlin.com.
println() is a standard library function which takes a single String
parameter (or a parameter that can be converted to a String). println()
moves the cursor to a new line after displaying its parameter, while print()
leaves the cursor on the same line.
Kotlin does not require a semicolon at the end of an expression or statement. Semicolons are only necessary to separate multiple expressions or statements on a single line.
var & val, Data Types
To create an unchanging identifier, use the val keyword followed by the
identifier name, a colon, and the type for that value. Then add an equals sign
and the value to assign to that val:
val identifier: Type = initialization
Once a val is assigned, it cannot be reassigned.
Kotlin’s type inference can usually determine the type automatically, based on the initialization value. This produces a simpler definition:
val identifier = initialization
Both of the following are valid:
val daysInFebruary = 28
val daysInMarch: Int = 31
A var (variable) definition looks the same, using var instead of val:
var identifier1 = initialization
var identifier2: Type = initialization
Unlike a val, you can modify a var, so the following is legal:
var hoursSpent = 20
hoursSpent = 25
However, the type can’t be changed, so you get an error if you say:
hoursSpent = 30.5
Kotlin infers the Int type when hoursSpent is defined, so it won’t accept
the change to a floating-point value.
Functions
Functions are named subroutines:
fun functionName(arg1: Type1, arg2: Type2, ...): ReturnType {
// Lines of code ...
return result
}
The fun keyword is followed by the function name and the parameter list in
parentheses. Each parameter must have an explicit type because Kotlin cannot
infer parameter types. The function itself has a type, defined in the same way
as for a var or val (a colon followed by the type). A function’s type is the
type of the returned result.
The function signature is followed by the function body contained within curly
braces. The return statement provides the function’s return value.
You can use an abbreviated syntax when the function consists of a single expression:
fun functionName(arg1: Type1, arg2: Type2, ...): ReturnType = result
This form is called an expression body. Instead of an opening curly brace, use an equals sign followed by the expression. You can omit the return type because Kotlin infers it.
Here’s a function that produces the cube of its parameter, and another that adds
an exclamation point to a String:
// Summary1/BasicFunctions.kt
fun cube(x: Int): Int {
return x * x * x
}
fun bang(s: String) = s + "!"
fun main() {
println(cube(3))
println(bang("pop"))
}
/* Output:
27
pop!
*/
cube() has a block body with an explicit return statement. bang() is an
expression body producing the function’s return value. Kotlin infers bang()’s
return type to be String.
Booleans
For Boolean algebra, Kotlin provides operators such as:
-
!(not) logically negates the value (turnstruetofalseand vice-versa). -
&&(and) returnstrueonly if both conditions aretrue. -
||(or) returnstrueif at least one of the conditions istrue.
// Summary1/Booleans.kt
fun main() {
val opens = 9
val closes = 20
println("Operating hours: $opens - $closes")
val hour = 6
println("Current time: " + hour)
val isOpen = hour >= opens && hour < closes
println("Open: " + isOpen)
println("Not open: " + !isOpen)
val isClosed = hour < opens || hour >= closes
println("Closed: " + isClosed)
}
/* Output:
Operating hours: 9 - 20
Current time: 6
Open: false
Not open: true
Closed: true
*/
isOpen’s initializer uses && to test whether both conditions are true.
The first condition hour >= opens is false, so the result of the entire
expression becomes false. The initializer for isClosed uses ||, producing
true if at least one of the conditions is true. The expression hour <
opens is true, so the whole expression is true.
if Expressions
Because if is an expression, it produces a result. This result can be
assigned to a var or val. Here, you also see the use of the else keyword:
// Summary1/IfResult.kt
fun main() {
val result = if (99 < 100) 4 else 42
println(result)
}
/* Output:
4
*/
Either branch of an if expression can be a multiline block of code surrounded
by curly braces:
// Summary1/IfExpression.kt
fun main() {
val activity = "swimming"
val hour = 10
val isOpen = if (
activity == "swimming" ||
activity == "ice skating") {
val opens = 9
val closes = 20
println("Operating hours: " +
opens + " - " + closes)
hour >= opens && hour < closes
} else {
false
}
println(isOpen)
}
/* Output:
Operating hours: 9 - 20
true
*/
A value defined inside a block of code, such as opens, is not accessible
outside the scope of that block. Because they are defined globally to the
if expression, activity and hour are accessible inside the if
expression.
The result of an if expression is the result of the last expression of the
chosen branch. Here, it’s hour >= opens && hour <= closes which is true.
String Templates
You can insert a value within a String using String templates. Use a $
before the identifier name:
// Summary1/StrTemplates.kt
fun main() {
val answer = 42
println("Found $answer!") // [1]
val condition = true
println(
"${if (condition) 'a' else 'b'}") // [2]
println("printing a $1") // [3]
}
/* Output:
Found 42!
a
printing a $1
*/
-
[1]
$answersubstitutes the value contained inanswer. -
[2]
${if(condition) 'a' else 'b'}evaluates and substitutes the result of the expression inside${}. -
[3] If the
$is followed by anything unrecognizable as a program identifier, nothing special happens.
Use triple-quoted Strings to store multiline text or text with special
characters:
// Summary1/ThreeQuotes.kt
fun json(q: String, a: Int) = """{
"question" : "$q",
"answer" : $a}"""
fun main() {
println(json("The Ultimate", 42))
}
/* Output:
{
"question" : "The Ultimate",
"answer" : 42
}
*/
You don’t need to escape special characters like " within a triple-quoted
String. (In a regular String you write \" to insert a double quote). As
with normal Strings, you can insert an identifier or an expression using $
inside a triple-quoted String.
Number Types
Kotlin provides integer types (Int, Long) and floating point types
(Double). A whole number constant is Int by default and Long if you
append an L. A constant is Double if it contains a decimal point:
// Summary1/NumberTypes.kt
fun main() {
val n = 1000 // Int
val l = 1000L // Long
val d = 1000.0 // Double
println("$n $l $d")
}
/* Output:
1000 1000 1000.0
*/
An Int holds values between -231 and +231-1. Integral
values can overflow; for example, adding anything to Int.MAX_VALUE produces
an overflow:
// Summary1/Overflow.kt
fun main() {
println(Int.MAX_VALUE + 1)
println(Int.MAX_VALUE + 1L)
}
/* Output:
-2147483648
2147483648
*/
In the second println() statement we append L to 1, forcing the whole
expression to be of type Long, which avoids the overflow. (A Long can hold
values between -263 and +263-1).
When you divide an Int with another Int, Kotlin produces an Int result,
and any remainder is truncated. So 1/2 produces 0. If a Double is
involved, the Int is promoted to Double before the operation, so 1.0/2
produces 0.5.
You might expect d1 in the following to produce 3.4:
// Summary1/Truncation.kt
fun main() {
val d1: Double = 3.0 + 2 / 5
println(d1)
val d2: Double = 3 + 2.0 / 5
println(d2)
}
/* Output:
3.0
3.4
*/
Because of evaluation order, it doesn’t. Kotlin first divides 2 by 5, and
integer math produces 0, yielding an answer of 3.0. The same evaluation
order does produce the expected result for d2. Dividing 2.0 by 5
produces 0.4. The 3 is promoted to a Double because we add it to a
Double (0.4), which produces 3.4.
Understanding evaluation order helps you to decipher what a program does, both with logical operations (Boolean expressions) and with mathematical operations. If you’re unsure about evaluation order, use parentheses to force your intention. This also makes it clear to those reading your code.
Repetition with while
A while loop continues as long as the controlling Boolean-expression
produces true:
while (Boolean-expression) {
// Code to be repeated
}
The Boolean expression is evaluated once at the beginning of the loop and again before each further iteration.
// Summary1/While.kt
fun testCondition(i: Int) = i < 100
fun main() {
var i = 0
while (testCondition(i)) {
print(".")
i += 10
}
}
/* Output:
..........
*/
Kotlin infers Boolean as the result type for testCondition().
The short versions of assignment operators are available for all mathematical
operations (+=, -=, *=, /=, %=). Kotlin also supports the increment
and decrement operators ++ and --, in both prefix and postfix form.
while can be used with the do keyword:
do {
// Code to be repeated
} while (Boolean-expression)
Rewriting While.kt:
// Summary1/DoWhile.kt
fun main() {
var i = 0
do {
print(".")
i += 10
} while (testCondition(i))
}
/* Output:
..........
*/
The sole difference between while and do-while is that the body of the
do-while always executes at least once, even if the Boolean expression
produces false the first time.
Looping & Ranges
Many programming languages index into an iterable object by stepping through
integers. Kotlin’s for allows you to take elements directly from iterable
objects like ranges and Strings. For example, this for selects each character
in the String "Kotlin":
// Summary1/StringIteration.kt
fun main() {
for (c in "Kotlin") {
print("$c ")
// c += 1 // error:
// val cannot be reassigned
}
}
/* Output:
K o t l i n
*/
c can’t be explicitly defined as either a var or val—Kotlin
automatically makes it a val and infers its type as Char (you can provide
the type explicitly, but in practice this is rarely done).
You can step through integral values using ranges:
// Summary1/RangeOfInt.kt
fun main() {
for (i in 1..10) {
print("$i ")
}
}
/* Output:
1 2 3 4 5 6 7 8 9 10
*/
Creating a range with .. includes both bounds, but until excludes the top
endpoint: 1 until 10 is the same as 1..9. You can specify an increment
value using step: 1..21 step 3.
The in Keyword
The same in that provides for loop iteration also allows you to check
membership in a range. !in returns true if the tested value isn’t in the
range:
// Summary1/Membership.kt
fun inNumRange(n: Int) = n in 50..100
fun notLowerCase(ch: Char) = ch !in 'a'..'z'
fun main() {
val i1 = 11
val i2 = 100
val c1 = 'K'
val c2 = 'k'
println("$i1 ${inNumRange(i1)}")
println("$i2 ${inNumRange(i2)}")
println("$c1 ${notLowerCase(c1)}")
println("$c2 ${notLowerCase(c2)}")
}
/* Output:
11 false
100 true
K true
k false
*/
in can also be used to test membership in floating-point ranges, although
such ranges can only be defined using .. and not until.
Expressions & Statements
The smallest useful fragment of code in most programming languages is either a statement or an expression. These have one basic difference:
- A statement changes state.
- An expression expresses.
That is, an expression produces a result, while a statement does not. Because it doesn’t return anything, a statement must change the state of its surroundings (that is, create a side effect) to do anything useful.
Almost everything in Kotlin is an expression:
val hours = 10
val minutesPerHour = 60
val minutes = hours * minutesPerHour
In each case, everything to the right of the = is an expression, which
produces a result that is assigned to the identifier on the left.
Functions like println() don’t seem to produce a result, but because they are
still expressions, they must return something. Kotlin has a special Unit
type for these:
// Summary1/UnitReturn.kt
fun main() {
val result = println("returns Unit")
println(result)
}
/* Output:
returns Unit
kotlin.Unit
*/
Experienced programmers should go to Summary 2 after working the exercises for this atom.
Exercises and solutions can be found at www.AtomicKotlin.com.