1. Testgetrieben in 10 Minuten
Laut Kent Beck, dem Erfinder bzw. Wiederentdecker des Test Driven Development besteht TDD aus drei Teilen (siehe Beck 2010):
- Entwickler schreiben automatisierte Tests während sie programmieren.
- Die Tests werden vor dem zugehörigen Produktionscode geschrieben.
- Design findet in kleinen Schritten statt.
Schauen wir uns diese drei Punkte nacheinander genauer an:
Dass automatisierte Entwicklertests unabdingbar sind, haben die meisten Entwickler im Laufe des vergangenen Jahrzehnts gelernt. Viele haben auch erfahren, dass diese Tests manchmal unerwartet Probleme aufzeigen und so deren Beseitigung erst möglich machen. Aus Management-Sicht ist eine umfangreiche Testautomatisierung – oft unter dem Stichwort Regressionstests – eine Investition, die sich durch einen geringeren manuellen Testaufwand und schnellere aussagekräftige Testergebnisse auszahlt.
Der zweite Bestandteil testgetriebener Entwicklung wird schon wesentlich kontroverser diskutiert. Warum sollte es einen Unterschied machen, ob ich meine Tests vor oder nach dem Produktionscode erstelle? Um die spätere Diskussion zusammenzufassen: In der Praxis macht es einen erheblichen Unterschied. Nachträgliche Tests werden häufiger weggelassen. Darüber hinaus ist Produktionscode, der ohne Rücksicht auf Testbarkeit entworfen wurde, oft schwer testbar und führt zu aufwändigerem Testcode. Entscheidend ist jedoch der Einfluss von frühzeitig erstellten Tests auf das Schnittstellendesign des Codes: Der Testcode dient als erster Verwender des Produktionscodes und gibt daher direkt Feedback über die Adäquatheit der Schnittstelle.
Und schließlich ist da noch der Gedanke, Design in kleinen Schritten vorzunehmen, und nicht nur einmal zu Beginn des Entwicklungsprojekts (siehe Kapitel xx). Inkrementell und evolutionär das Design entstehen zu lassen, ist das Gegenteil des Draufloshackens und erfordert diszipliniertes Arbeiten. Das Ziel ist es, Designentscheidungen so spät wie möglich zu treffen, denn später haben wir mehr Wissen. So entwerfen wir eine Schnittstelle dann, wenn wir sie das erste mal benötigen; nämlich beim Schreiben des ersten betroffenen Testfalls. Und wir passen das Design dann an, wenn ein weiterer Testfall uns zusätzliche Informationen liefert. In kleinen Schritten designen heißt eben auch ständig designen.
1.1 Mechanik
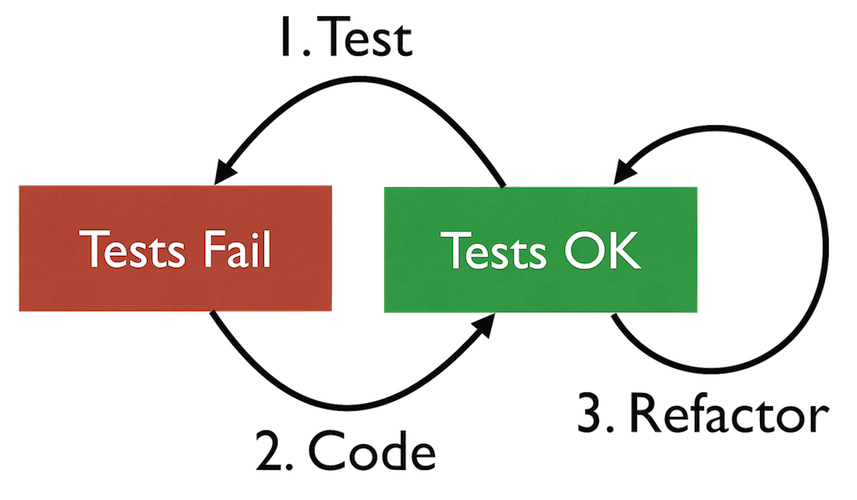
Test-Code-Refactor-Zyklus
Die innere Mechanik der testgetriebenen Entwicklung, beschreibt der Test-Code-Refactor-Zyklus. Ausgangspunkt ist immer ein Zustand, in dem alle existierenden Testfälle erfolgreich durchlaufen. Nur von hier aus begeben wir uns in die Weiterentwicklung und starten den nächsten Zyklus. Dieser besteht aus drei Schritten:
- Schreibe einen Testfall, der, sobald er ausgeführt wird, fehlschlägt. In diesem Schritt können sowohl existierende Schnittstellen, Funktionen und Objekte verwendet werden, oder neue geschaffen werden, die es geben sollte.
- Bringe den Test zum Erfolg, indem du den Produktionscode mit minimaler Implementierung dazu bringst, das im Test geforderte Verhalten zu erfüllen.
- Nun räume das Programm auf – und zwar nicht nur den neuen, sondern auch den bereits vorhandenen Code. Dieser Schritt wird typischerweise der Refactor-Schritt genannt, weil hier die Idee des Refaktorisierens zur Anwendung kommt: Verbessere den existierenden Code und das existierende Design ohne dabei das nach außen sichtbare Verhalten zu verändern.
Nun beginnt der Zyklus wieder von vorne mit einem neuen Test. Dies geschieht solange, bis für die vollständige Erfüllung der aktuelle Aufgabe kein neuer Testfall mehr notwendig ist.
Ein solcher Mikro-Zyklus dauert häufig nur wenige Minuten, nämlich immer dann, wenn weder die fachliche Anforderung noch die technische Umsetzung große Überraschungen bereithalten. Dies bedeutet, dass ein in TDD geübter Entwickler in der Lage sein muss, umzusetzende Features in sehr kleine Stücke zu zerschneiden.
1.2 Erste Praxis
Anhand eines einfachen Beispiels möchte ich diese Mechanik verdeutlichen. Greifen wir Kapitel 2 etwas vor und implementieren einen einfachen monoalphabetischen Substitutionschiffre auf testgetriebene Weise. Wir beginnen - natürlich - mit einem Testfall:
1 class ReplacementCipherTest {
2 @Test
3 void emptyTextIsEncryptedAsEmptyText() {
4 def cipher = new ReplacementCipher([:])
5 assert cipher.encrypt('') == ''
6 }
7 }
Aus funktionaler Sicht ist der Test sehr schwach, da er lediglich die Verschlüsselung eines leeren Klartexts in einen leeren Schlüsseltext spezifiziert. Allerdings mussten wir bei der Formulierung des Testcodes Schnittstellen-Design betreiben. Zu diesem Zeitpunkt arbeiten wir im “Wunsch-Modus”, d.h., wir entwerfen die Schnittstelle so, wie wir sie als Verwender gerne hätten. Es ist daher nicht verwunderlich, dass sich große Teile nicht (statisch) kompilieren lassen;
weder existiert die Klasse ReplacementCipher noch die encrypt-Methode, und auch der postulierte Konstruktor mit Map-Parameter der zu verschlüsselnden Buchstaben fehlt. Aber das lässt sich schnell beheben:
1 class ReplacementCipher {
2 ReplacementCipher(Map replacements) {}
3 def encrypt(clearText) {}
4 }
Nun können wir den Test anwerfen und das erwartete Ergebnis genießen:
Assertion failed:
assert cipher.encrypt('') == ''
| |
| null
ReplacementCipher@1661db97
Genießen? Jawohl, schließlich haben wir Schritt 1 des Test-Code-Refactor-Zyklus’ erfolgreich durchlaufen: Wir haben einen Testfall erstellt, der uns zeigt, welches kleine Stück Funktionalität wir als nächstes programmieren wollen.
Schritt 2, den Test mit minimalen Änderungen im Applikationscode zu erfüllen, ist jetzt ganz einfach:
1 class ReplacementCipher...
2 def encrypt(clearText) {
3 return ''
4 }
Die Änderung war trivial und wir sehen dem Code an, dass das noch nicht der Endzustand ist, wollen aber auch keine Logik hinzufügen, die nicht von Tests gefordert wird. Daher bleibt uns in Schritt 3 lediglich, den Parameter- und Rückgabe-Typ zu konkretisieren:
1 class ReplacementCipher...
2 String encrypt(String clearText) {...}
Zweiter Durchgang
Stürzen wir uns nun auf den zweiten Test-Code-Refactor-Durchgang und damit auf einen neuen Testfall:
1 class ReplacementCipherTest...
2 @Test
3 void replaceSingleMappedCharacter() {
4 def cipher = new ReplacementCipher(['a': 'A'])
5 assert cipher.encrypt('a') == 'A'
6 }
Wir nähern uns mit einem kleinen Schritt dem Ziel und fordern im Test die Ersetzung eines einzigen Buchstabens. Auch jetzt starten wir selbstverständlich den Test-Runner und sehen unseren Test wunschgemäß fehlschlagen.
Die nächste, möglichst einfache Code-Änderung muss nun nicht nur diese neue Anforderung umsetzen, sondern darf den vorherigen Test nicht versehentlich zerstören:
1 class ReplacementCipher...
2 String encrypt(String clearText) {
3 if (clearText.isEmpty())
4 return ''
5 return 'A'
6 }
Das ist wirklich schnell und schmutzig, bringt uns aber in den grünen Bereich, in dem alle Testfälle laufen und der Puls nach unten geht. Im Refactor-Schritt können wir nun schon ein klein wenig Abstraktion betreiben und statt des konstanten Rückgabewertes uns den hinterlegten Verschlüsselungswert greifen:
1 class ReplacementCipher...
2 private final Map replacements
3 ReplacementCipher(Map replacements) {
4 this.replacements = replacements
5 }
6 String encrypt(String clearText) {
7 if (clearText.isEmpty())
8 return ''
9 return replacements.get(clearText[0])
10 }
Dass das ein Schritt in die richtige Richtung ist, erkennen wir, wenn wir den Testfall leicht verändern und damit zeigen, dass der Applikationscode nicht mehr ganz so stark von den konkreten Testdaten abhängt:
1 class ReplacementCipherTest...
2 @Test
3 void replaceSingleMappedCharacter() {
4 def cipher = new ReplacementCipher(['z': 'X'])
5 assert cipher.encrypt('z') == 'X'
6 }
Dritter Durchgang
Bohren wir den Test so auf, dass er nicht nur das erste Vorkommen, sondern alle Vorkommen eines Buchstabens ersetzt:
1 class ReplacementCipherTest...
2 @Test
3 void replaceSingleMappedCharacterEverywhere() {
4 def cipher = new ReplacementCipher(['z': 'X'])
5 assert cipher.encrypt('z') == 'X'
6 assert cipher.encrypt('zzz') == 'XXX'
7 }
Neben der zusätzlichen Zeile, haben wir auch noch den Test umbenannt, um Intention und Umfang klarer zu beschreiben. Auch die Änderung im Anwendungscode ist etwas umfangreicher:
1 class ReplacementCipher...
2 String encrypt(String clearText) {
3 String encrypted = ""
4 for(int i = 0; i < clearText.size(); i++) {
5 encrypted += replacements.get(clearText[0])
6 }
7 return encrypted
8 }
Das Kernstück der Logik hat jedoch noch überlebt:
replacements.get(clearText[0])
Schlussrunde
Und erst ein weiterer - zunächst fehlschlagender - Test wird uns zur entscheidenden Verallgemeinerung zwingen:
1 class ReplacementCipherTest...
2 @Test
3 void replaceAllMappedCharactersEverywhere() {
4 def cipher = new ReplacementCipher(['a': 'X', 'b': 'Y'])
5 assert cipher.encrypt('ba') == 'YX'
6 assert cipher.encrypt('babbaa') == 'YXYYXX'
7 }
Um diesen Testfall zu erfüllen, müssen wir aus
encrypted += replacements.get(clearText[0])
ein
encrypted += replacements.get(clearText[i])
machen. Und das wiederum können wir im abschließenden Refactoring-Schritt ein wenig idiomatischer gestalten:
1 class ReplacementCipher...
2 String encrypt(String clearText) {
3 String encrypted = ""
4 for(letter in clearText) {
5 encrypted += replacements.get(letter)
6 }
7 return encrypted
8 }
Was haben wir erreicht?
In drei kurzen Durchläufen des Test-Code-Refactor-Zyklus haben wir eine Klasse ReplacementCipher ins Leben getestet, die bereits einen Text verschlüsseln kann, und deren augenblickliche Funktionalität durch die drei Testfälle dokumentiert und überprüft wird. Einige offene Enden, wie beispielsweise der Umgang mit unbekannten Buchstaben, existieren noch. Doch diese lassen sich durch eine Handvoll weiterer Test-Code-Refactor-Runden leicht schließen.
1.3 Was testgetriebene Entwicklung sein kann - und was nicht
TDD ist ein Vorgehen, das uns Softwareentwicklern dabei helfen möchte, Code und Design kontrolliert und mit hoher innerer Qualität zu erstellen und weiterzuentwickeln. Seine Effekte wirken dabei auf zahlreichen Ebenen; teilweise benutzt es die typischen menschlichen Schwächen, teilweise arbeitet es gegen unsere erworbene Intuition. So führt testgetriebene Entwicklung im Idealfall…
- zu einer hohen Abdeckung durch automatisierte Unit-Tests,
- zu einer durchgängig testbaren Codebasis,
- zu sparsam gekoppeltem Design und
- zu Programmeinheiten (engl. units) mit sinnvollem Namen.
Oder in drei Worten: zu dauerhaft wartbarer Software.
TDD kann jedoch nicht alle Wunder vollbringen, die ihm zuweilen zugeschrieben werden. Insbesondere ist TDD…
- kein ausfallsicherer Prozess, um das beste Design oder gar den besten Algorithmus zu entwickeln.
- keine Methode, um aus schlechten oder unerfahrenen Programmierern gute Entwickler zu machen.
- kein Vorgehen, das die Produktivität eines Softwareteams im Alleingang verdoppelt, verzehnfacht oder auch nur um 10% erhöht.
- kein Ersatz für ein gründliches Verständnis der fachlichen Probleme und der sinnvollen Lösungsansätze.
Testgetriebene Entwicklung ist ein äußerst wirksames taktisches Konzept. Jede Taktik muss jedoch zur gewählten Strategie passen, und nicht jede Strategie findet in TDD den richtigen Partner1.
- Die Frage, wann testgetriebenes Vorgehen nicht zur Strategie passt, wird später in einem eigenen Kapitel diskutiert.↩