01 - Die Anforderung-Logik Lücke
Um die Softwareentwicklung vom Kopf auf die Füße zu stellen, d.h. ihr einen Rahmen für Nachhaltigkeit zu geben, ist es hilfreich, wenn wir ihr Produkt genauer betrachten. Woraus bestehen “die Maschinen”, die du in der Softwareentwicklung produzierst, von denen sich der Auftraggeber so viel Hilfe verspricht?
Logik - Der Stoff aus dem Verhalten entsteht
Die offensichtlichen Anforderungen des Auftraggebers sind die Verhaltensanforderungen an Software. Verhalten wird durch Code hergestellt - aber nicht der gesamte Code ist dafür verantwortlich.
Hier als Beispiel eine Software, die eine Datei als Hex Dump ausgeben soll wie in diesem Bild dargestellt (Quelle: C# von Kopf bis Fuß):
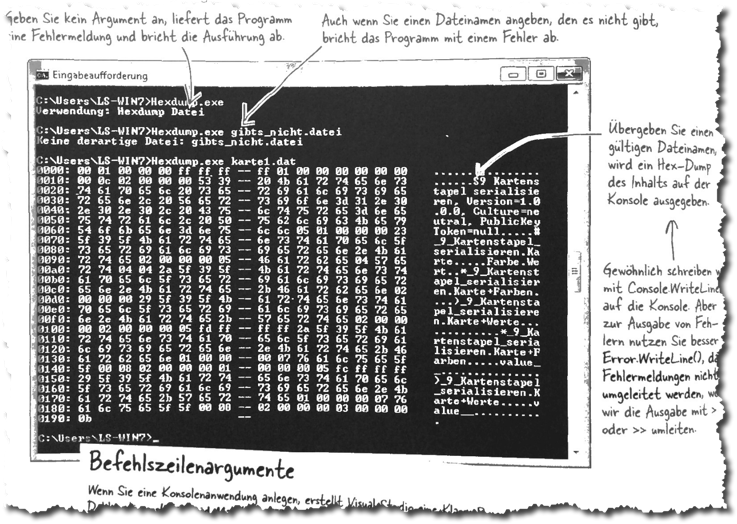
Der C#-Code dafür sieht im Ausschnitt so aus:
1 using System;
2 using System.IO;
3 using System.Text;
4
5 namespace hexdump
6 {
7 // source: "C# von Kopf bis Fuß"
8 class MainClass
9 {
10 public static void Main (string[] args)
11 {
12 if (args.Length != 1) {
13 Console.Error.WriteLine ("Usage: hexdump <dateiname>");
14 Environment.Exit (1);
15 }
16
17 if (!File.Exists(args[0])) {
18 Console.Error.WriteLine("No such file: {0}", args[0]);
19 Environment.Exit(2);
20 }
21
22 using (var input = File.OpenRead (args [0])) {
23 int position = 0;
24 var buffer = new byte[16];
25
26 while (position < input.Length) {
27 var charsRead = input.Read (buffer, 0, buffer.Length);
28 if (charsRead > 0) {
29 Console.Write ("{0}: ", string.Format ("{0:x4}", position));
30 position += charsRead;
31
32 for (int i = 0; i < 16; i++) {
33 if (i < charsRead) {
34 var hex = string.Format ("{0:x2}", buffer [i]);
35 Console.Write (hex + " ");
36 } else {
37 Console.Write (" ");
38 }
39 ...
Erkennst du, welche Zeilen des Code verhaltensrelevant sind? Die Veränderung welcher Zeilen würde für einen Anwender unmittelbar spürbar sein?
Könnte using System gelöscht werden, ohne dass sich das Programmverhalten ändert?1 Nein, das Programmverhalten würde sich nicht ändern.
Sind die Leerzeilen oder der Kommentar relevant für das Programmverhalten? Nein.
Spürt ein Anwender, ob es die Funktion Main() gibt? Nein.2
Aber wenn eine Zeile mit Console.Error.WriteLine(...) fehlen würde, dann würde der Anwender das (in manchen Fällen) bemerken.
Oder wenn die Zeile if (i < charsRead) fehlen würde oder darin das < durch ein > ersetzt würde, dann würde das zu einem anderen Verhalten des Programms führen.
Code ist also nicht gleich Code. Mancher Code/manche Codezeilen sind für das Verhalten relevant, manche nicht.
Logik besteht aus
- Transformationen/Operatoren, z.B.
<,++,args.Length - Kontrollstrukturen, z.B.
if-else,for,try-catch - I/O- bzw. allgemeiner API-Calls, z.B.
Console.Write(),File.OpenRead()
Wenn nun das für Auftraggeber so wichtige Verhalten - Funktionalität + Effizienz - nur durch Logik hergestellt wird, stellt sich die Frage, was der übrige Code für Zweck hat. Welche Anforderungen hilft er erfüllen? Warum solltest du irgendetwas anderes codieren als Logik?
Einige Beispiele:
- Namespaces reduzieren das Rauschen im Code, das lange Namen mit redundanten Anteilen verursachen. Sie erhöhen die Ordnung.
- Leerzeilen strukturieren den Code vertikal, indem sie unterschiedliche inhaltliche Kohäsion anzeigen. Sie erhöhen die Ordnung.
- Funktionen “komponieren” Logik zu Funktionseinheiten, die Aspekte eines Verhaltens unter einem Namen zusammenfassen. Sie erhöhen die Ordnung und die Testbarkeit.
- Klassen aggregieren Funktionen (und Daten) und stellen damit zweckvolle Einheiten zusammen. Sie erhöhen die Ordnung.
Funktionalität
Die erste Kunst bei der Herstellung (oder Entwicklung) von Logik ist, sie so zu wählen, dass sie die gewünschte Funktionalität hat. Das lernst du auf alle Fälle in jedem Buch einer Programmiersprache oder einem Programmierkurs.
Logik, die die Zahlen in einem Array summiert, sieht dann z.B. so aus:
1 static int Sum(int[] numbers) {
2 var sum = 0;
3 foreach(var n in numbers)
4 sum += n;
5 return sum;
6 }
Logik, die die Zahlen in einem Array sortiert, sieht hingegen z.B. so aus:
1 // Quelle: https://www.geeksforgeeks.org/bubble-sort/
2 static void BubbleSort(int []arr)
3 {
4 int n = arr.Length;
5 for (int i = 0; i < n - 1; i++)
6 for (int j = 0; j < n - i - 1; j++)
7 if (arr[j] > arr[j + 1])
8 {
9 int temp = arr[j];
10 arr[j] = arr[j + 1];
11 arr[j + 1] = temp;
12 }
13 }
Welche Logik-Bausteine du aus den von deiner Programmiersprachen, deinen Bibliotheken und Frameworks angebotenen auswählst und wie du sie in Beziehung setzt, macht den Unterschied, ob das eine oder das andere Verhalten entsteht.
Auch Code, der nur aus Logik besteht, hat insofern eine Struktur. Im BubbleSort-Beispiel ist die augenfällig durch die Schachtelung der Kontrollstrukturen.
Effizienz I - Effizienz durch Algorithmen und Datenstrukturen
Logik so zu strukturieren, dass sie die gewünschte Funktionalität hat, ist jedoch nicht alles. Sie soll auch z.B. performant sein. Logik über die Funktionalität hinaus auch noch mit Effizienzen auszustatten, ist die zweite Kunst, die du lernen musst, wenn du programmieren willst.
Hier ein Beispiel dafür, wie anders Logik aussehen kann, nur weil sie mehr Effizienz bieten soll. Bubblesort ist ein bekanntermaßen imperformanter Sortieralgorithmus. Radixsort soll diesen Makel beseitigen:4
1 // Quelle: https://www.geeksforgeeks.org/radix-sort/
2 static void Radixsort(int[] arr, int n)
3 {
4 int mx = arr[0];
5 for (int i = 1; i < n; i++)
6 if (arr[i] > mx)
7 mx = arr[i];
8
9 for (int exp = 1; mx/exp > 0; exp *= 10)
10 {
11 int[] output = new int[n];
12
13 int i;
14 int[] count = new int[10];
15
16 for(i = 0; i < 10; i++)
17 count[i] = 0;
18
19 for (i = 0; i < n; i++)
20 count[ (arr[i]/exp)%10 ]++;
21
22 for (i = 1; i < 10; i++)
23 count[i] += count[i - 1];
24
25 for (i = n - 1; i >= 0; i--)
26 {
27 output[count[ (arr[i]/exp)%10 ] - 1] = arr[i];
28 count[ (arr[i]/exp)%10 ]--;
29 }
30
31 for (i = 0; i < n; i++)
32 arr[i] = output[i];
33 }
34 }
Logik (und zugehörige Datenstrukturen) für Effizienz-Anforderungen passend zu wählen, erfordert also mehr als die Kenntnis von Logik-Bausteinen. Dass du dir z.B. der algorithmischen Komplexität deiner Logik bewusst bist, gehört dazu, wenn du mit Logik den Auftraggeber umfassend erfreuen willst. Es kommt auf die Auswahl und Zusammenstellung der Logik-Bausteine an, auf ihre Komposition.
Effizienz II - Effizienz durch Verteilung
Performance und Skalierbarkeit oder auch andere Effizienzanforderungen lassen sich allerdings nicht immer allein durch Auswahl und Anordnug von Logik erfüllen. Dann ist zusätzlich Verteilung gefragt, d.h. die Ausführung von Logik verteilt auf mehrere Threads.
Als simples Beispiel mag die Sortierung von zwei Arrays dienen. Eine Lösung nur mit Logik kann das auch mit dem schnelleren Algorithmus nur sequenziell bewerkstelligen:
1 Radixsort(arr1, arr1.Length);
2 Radixsort(arr2, arr2.Length);
Die Gesamtlaufzeit ist dann die Summe der Laufzeiten der einzelnen Aufrufe der Funktion, die die Sortierlogik kapselt.
Wenn die Sortierung jedoch parallel, d.h. auf zwei Threads (verschiedener Prozessorkerne) stattfinden kann…
1 var t1 = Task.Factory.StartNew(() => Radixsort(arr1, arr1.Length));
2 var t2 = Task.Factory.StartNew(() => Radixsort(arr2, arr2.Length));
3 Task.WaitAll(new[] {t1, t2});
…dann entspricht die Gesamtlaufzeit (ungefähr) nur der des Funktionsaufrufs, der länger gebraucht hat.
Logik mit mehr Effizienz auszustatten durch Verteilung ist traditionell ein Teil der Disziplin Softwarearchitektur. Sie kannst du als die dritte Kunst der Softwareentwicklung ansehen.
Hierarchie der Hosts
Softwarearchitektur verteilt Logik, indem sie sie in Hosts ausführt. So nenne ich geschachtelte Laufzeit-Kontexte/Container, die mit mehr oder weniger Infrastruktur aufgesetzt, betrieben und in Verbindung gebracht werden.
- Thread: Multithreading ist der erste Schritt, um Latenz zu verbergen oder zu verringern oder den Durchsatz zu erhöhen. Die Kommunikation schon zwischen Logik auf verschiedenen Threads ist aber nicht mehr direkt, d.h. langsamer als die zwischen Logik auf demselben Thread. Vorsicht ist geboten, wenn Threads auf die selben Daten zugreifen.
- Process: Logik parallel in verschiedenen Betriebssystemprozessen zu betreiben, entkoppelt sie stärker, was zur Robustheit beiträgt. Dass es keinen gemeinsamen Hauptspeicher mehr gibt, reduziert das Risiko von Fehlern. Allerdings ist die Kommunikation deutlich aufwändiger zwischen Prozessen.
- Machine: Logik in mehreren Threads verteilt auf mehrere Prozesse auf verschiedenen (physischen oder virtuellen) Maschinen auszuführen, ermöglicht ein scale-out oder auch die Ansiedelung von Logik näher an Ressourcen. Allerdings ist die Kommunikation zwischen Maschinen noch langsamer als zwischen Prozessen, so dass sehr auf Häufigkeit und Granularität der Nachrichtenübermittlung geachtet werden muss.
- Network: Logik auf Maschinen in verschiedenen Netzwerken zu verteilen, ist allemal unvermeidbar, wenn Speicher- und Prozessorressourcen flexibel genutzt werden sollen (Stichwort “Cloud Computing”). Der Nutzen bei der Skalierbarkeit ist mit den Gefahren für die Sicherheit abzuwägen. Und die Kommunikationsgeschwindigkeit sinkt abermals.
Effizienz durch Verteilung steigern zu müssen, ist oft unvermeidbar. Simpel ist das jedoch nicht. Die Zahl der hilfreichen Technologien nimmt jeden Tag zu und erfordert von dir ein fleißiges Studium, wenn du mithalten willst. Vorsicht ist dennoch weiterhin ganz grundsätzlich gegenüber den fallacies of distributed computing geboten.
Im Weiteren spielen Hosts als Container für Logik jedoch keine größere Rolle mehr. Die Darstellungen hier drehen sich nicht um die Herstellung von Effizienzen, sondern vor allem um die Qualitäten Wert, Korrektheit und Ordnung für die Anforderung Produktivität. Du wirst es mit Strukturen zu tun bekommen, aber nur vergleichsweise wenigen Strukturen bestehend aus mehreren Hosts.
Zusammenfassung
Logik und ihre Verteilung ist das, was für den Auftraggeber unmittelbar spürbar ist. Mit Logik und Verteilung Verhalten herzustellen, sind die grundlegenden Künste der Programmierung. In ihnen können Softwareentwickelnde ständig reifen; für sie werden ständig neue Paradigmen, Technologien und Produkte entwickelt.
Logik und Verteilung in hoher Qualität herzustellen, ist auch bei guten Spezifikationen ein komplexes Unterfangen. Umso naheliegender sollte es sein, dass du diese Transformation systematisch betreibst.
Von den Anforderungen zur Logik
Angesichts des großen, bewussten und verständlichen Bedarfs an Softwareverhalten, den Auftraggeber haben, ist es kein Wunder, dass sie großen Druck auf die Logik-Produktion ausüben. Du sollst möglichst schnell Features mit Logik umsetzen - alles andere ist dem Kunden wenn schon nicht egal, dann doch meistens nur wenig bewusst. Auf alles andere achtet er insofern wenig oder kann es sogar nicht einmal beurteilen.
Logik schwer definierbar
Doch leider “ergibt sich” Logik nicht “einfach so”. Sie liegt nicht auf der Hand. Funktionale und effiziente Logik zu finden, ist für dich auch mit viel Erfahrung eine komplexe Angelegenheit. Schon eine sehr simple Aufgabe macht das deutlich:
Welche Logik ist dafür nötig?
Diese Frage wirst du für deine Programmiersprache sicher aus dem Stand beantworten können. In C# sieht sie so aus:5
1 Console.WriteLine("Hello, World!");
Das Programm selbst ist umfangreicher, weil noch eine Klasse und eine Funktion “als Verpackung” erforderlich sind, aber die reine Logik ist so trivial.
Auf zur nächsten Iteration:
Welche Logik brauchst du dafür?
Auch diese Frage wirst du wahrscheinlich aus dem Stand beantworten können, wenn auch vielleicht mit ein wenig Unsicherheit, wofür solch einfache Problemstellungen gut sein sollen. Ein Verhalten wie das Folgende zu erzeugen, ist nun wirklich kein Hexenwerk:

Natürlich ist das keine große Herausforderung an deine Kunst, Logik für Funktionalität zu finden.
Aber was, wenn dieses Verhalten nicht den Qualitätsanforderungen in puncto Benutzbarkeit entspricht? Das stellt der Auftraggeber fest, wenn du ihm deine neue Lösung vorstellst. Eine Anwenderin kann zwar dem Programm den Namen “mitteilen”, muss dazu aber wissen, dass das auf der Kommandozeile zu geschehen hat. Das hatte der Auftraggeber nicht im Sinn mit seiner obigen Spezifikation; wie selbstverständlich hatte er gedacht, dass eine Anwenderin natürlich nach ihrem Namen gefragt wird, um ihn dann mitzuteilen.6
“Gedacht” hatte sich der Auftraggeber ein solches Verhalten:

Das passt genauso zur verbalen Spezifikation. Die Logik dafür sieht jedoch ganz anders aus als für die erste Implementation!
1 // Variante 1
2 Console.WriteLine("Hello, {0}!", args[0]);
3
4 // Variante 2
5 Console.Write("Name: ");
6 var name = Console.ReadLine();
7 Console.WriteLine($"Hello, {name}!");
Und damit ist die Lösung immer noch nicht in trockenen Tüchern! Denn was geschieht, wenn ein Anwender keinen Namen eingibt und nur ENTER drückt? Dann passiert dies bei Variante 2:

Ist das ein erwünschtes Verhalten aus Sicht des Auftraggebers? Nein. Der hatte sich bei der Formulierung “mitteilen … kann” gedacht, dass ohne Name weiterhin mit “Hello, World!” begrüßt wird. Es gilt allerdings: “Gedacht ist nicht gemacht!” Auftraggeber müssen mehr, als sich Anforderungen denken oder darauf vertrauen, dass du “als Fachmann” schon weißt, was gemeint sein könnte. Sieh durch den Honig durch, den dir solche Formulierungen um den Bart schmieren: “Sie haben doch Erfahrung. Sie wissen doch, wie man das macht und was ich meine.” Nein, weiß du nicht! Du kannst dir zwar eine Menge denken - nur bedeutet das nicht, dass es dasselbe ist, wie sich der Auftraggeber denkt oder was ihm am Ende gefällt, was Wert darstellt. Wenn du hörst “Sie als Fachmann”, ist Gefahr im Verzug! Dann musst du die Anstrengungen verdoppeln, den Kunden aus der Unklarheit zu locken - oder ihm ganz klar sagen, dass du nur Vorläufiges programmieren kannst.
Eine oder drei oder auch fünf Zeilen Logik zu finden, ist in diesem Szenario nicht das Problem. Doch schon bei dieser Größenordnung fehlt es eben an Klarheit, was überhaupt Wert für den Auftraggeber darstellt.
Mit iterativem Vorgehen lässt sich der Schaden jedoch begrenzen. Wenn du dem Auftraggeber nicht vorgaukelst, dass du seine Wünsche direkt umsetzen kannst, sondern Feedback-Schleifen benötigst, führen Kontraste zwischen Wunsch und Lieferung nicht zu Konflikten, sondern zu Informationen. Motto: “Gut, dass wir darüber gesprochen haben!”
Nach zwei Iterationen kann die Lösung dann so aussehen:
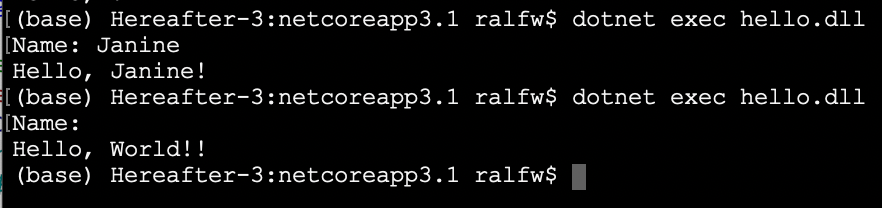
Und die Logik hat dir natürlich keine Probleme gemacht. Wenn klar ist, was gewünscht ist, ergibt sie sich quasi von selbst und sieht z.B. so aus:
1 Console.Write("Name: ");
2 var name = Console.ReadLine();
3 if (string.IsNullOrWhiteSpace(name)) name = "World";
4 Console.WriteLine($"Hello, {name}!");
Vielmehr war es der Kunde mit der unklaren Spezifikation, der zu einem Umweg geführt hat. Garbage in, garbage out: Das gilt auch bei der Softwareentwicklung.
Was nun? Sind die Anforderungen wieder unklar? Eher nicht. Es ließen sich zwar noch ein paar Fragen stellen, wie sich das Programm verhalten soll, wenn verschiedene Gäste denselben Namen haben. Doch diese Restunklarheit ist bei dieser Iteration nicht das Problem. Vertrau mir.
Bei dieser Iteration liegt vielmehr die Logik selbst bei klaren Anforderungen nicht mehr auf der Hand. Sie mag am Ende 10 oder 20 Zeilen umfassen - viel wäre das allerdings immer noch nicht. Dennoch wirst du bei dieser Iteration eine deutlich größere Unsicherheit verspüren. Du siehst keinen geraden Weg mehr zur Logik; sie springt dir nicht vor dein geistiges Auge. Deine Gedanken kreisen… du kannst jetzt nicht einfach codieren, sondern musst zuerst nachdenken.
Die Funktionalität selbst stellt jetzt schon ein Problem dar, obwohl das Szenario immer noch trivial ist. Und deshalb wird auch die Korrektheit relevant. Denn wo unklar ist, welche Logik die passende ist, ist sehr schnell auch unklar, ob die ausgewählte tatsächlich die Anforderungen erfüllt.
Darüber hinaus aber kommst du nicht mehr ohne Ordnung im Code aus. Deine kreisenden Gedanken suchen nicht nur die Logik für das Verhalten, sondern auch nach einer ordentlichen Struktur, in der du die Logik aufhängen kannst, um deine eigene Lösung zu verstehen.7
Diese Struktur wird jedoch nicht durch die Logik gebildet, es geht also nicht um den Algorithmus. Vielmehr geht es um einen Rahmen um Logik herum, also um Nicht-Logik Code. Wenn du dabei an Funktionen und Klassen (oder allgemeiner: Module) denkst, hast du die richtige Intuition.
Die Phasen der Programmierung
Zwischen den Anforderungen des Auftraggebers und der Logik, die zumindest die spürbaren Verhaltensanforderungen erfüllt, klafft eine gewaltige Lücke: die Anforderung-Logik Lücke. Schon in sehr simplen Szenarien wie dem vorgestellten liegt Logik nicht auf der Hand, sondern will gewissenhaft erarbeitet werden.
Wie die Iterationen des Beispiels zeigen sollten, geschieht das in drei Phasen, die strickt aufeinander folgen. Immer. Auch bei dir. Selbst, wenn du das nicht wahrnimmst oder nicht glaubst. Und auch wenn sie iterativ, also mehrfach durchlaufen werden, tut das dem Vorhandensein und der Reihenfolge der Phasen keinen Abbruch.
1. Phase: Analyse
Konfrontiert mit Anforderungen ist die Softwareentwicklung aufgerufen, zunächst eine für sie relevante Analyse zu machen. Diese Analyse hat als Ziel, Verständnis zu erzeugen. Nur wenn du wirklich verstanden hast, solltest du dich auf den Pfad der Code-Entwicklung machen. Ansonsten ist zu befürchten, dass das Resultat keinen Wert hat und/oder inkorrekt ist.
Das weiß jeder, der eine Mathematik-Prüfung (aus eigenen Kräften) bestanden oder auch nicht bestanden hat.
Ein konkreteres Beispiel: Wer versteht, wie Fibonacci-Zahlen berechnet werden, der kann die Folge 1, 1, 2, 3, 5, 8 beliebig fortsetzen. Der weiß, welche Zahl auf 8 folgt, der weiß, welche Zahl auf 21 folgt; der weiß auch, ob 35 eine Fibonacci-Zahl ist oder nicht.
Der unzweideutige formale Ausdruck von Verständnis besteht deshalb in “Beispielaufgaben” für dich als Entwickler bzw. für die von dir zu entwickelnde Software. Nur Software, die diese “Beispielaufgaben” fehlerfrei löst, kann als anforderungskonform und korrekt akzeptiert werden.
Vorgelegt werden die “Beispielaufgaben” natürlich in Form von automatisierten Testfällen. Andernfalls ist nicht zu erwarten, dass sie verlässlich und nachvollziehbar und personenunabhängig überprüft werden.
Automatisierte Tests sind die erste Bastion im Kampf gegen den Morast der schleichend wachsenden Unwandelbarkeit, der deine Produktivität in die Knie zwingt.
Der automatisierte Test hat allerdings eine Voraussetzung: Es muss auch klar sein, wie ein Test “an Logik angelegt” werden kann. Wie bekommt der Test Zugang zur zu testenden Logik? Das geschieht vor allem durch Aufruf von Funktionen.
Verständnis als Resultat der Analyse drückt sich aus in einer Reihe von Tupeln der Form (Testfall, Funktion).
Für das Beispiel der Fibonacci-Zahlen könnte das so aussehen:
- Funktion:
int[] Fib(int n) - Testfälle:
- Input:
n=0, erwartetes Resultat:[] - Input:
n=1, erwartetes Resultat:[1] - Input:
n=4, erwartetes Resultat:[1,1,2,3,]
- Input:
Daraus folgt:
Das Ergebnis der Analyse sind Akzeptanztests für die zu entwickelnde Logik. Ohne Erfüllung ihrer Akzeptanztests ist Logik nicht reif; Akzeptanztests sind die Reifetests “an der Außenhaut” von Software. Und ohne unausgesetzte Erfüllung bisheriger Akzeptanztests ist Logik nicht stabil. Beides ist inakzeptabel im Sinne dauerhaft hoher Produktivität.
Der zweiten Iteration des obigen Programms fehlte es an formalem, dokumentiertem Verständnis. Deshalb ist die Entwicklung in die falsche Richtung gelaufen und hat auch noch den Eindruck der Inkorrektheit gemacht.
2. Phase: Entwurf
Die dritte Iteration im Beispiel hat natürlich auch noch unter einem Mangel an dokumentiertem Verständnis gelitten. Darüber hinaus waren die Anforderungen aber so umfangreich, dass sich auch gutes Verständnis nicht mehr “einfach so” in Logik hat umsetzen lassen.
Das Nachdenken über Code vor der Codierung in der IDE, das die dritte Iteration erzwungen hat, ist das, was ich Design oder Entwurf nenne. Diese Phase ist die zentrale Provokation der Softwareentwicklung, scheint mir. Ihr müssen sich alle Entwickelnden stellen, hier ist echte Kreativität gefragt. Und hier gibt es den größten Widerstand seit Anfang der 2000er. Entwurf scheint überflüssig, hinderlich, verlangsamend. Meine Erkenntnis ist allerdings gegenteilig: Ich sehe, dass die Produktivität leidet, weil Entwicklungsteams einen Entwurf vernachlässigen.
Entwurf findet immer statt. Du kannst ihn sehr bewusst oder ganz unbewusst durchführen. Erfolgt er bewusst, ist er allerdings noch nicht notwendig auch systematisch. Deshalb lässt die Ordnung der “entworfenen” Strukturen oft zu wünschen übrig.
Das heißt, im Entwurf steht keine Logik zur Verfügung. Entwurf liefert keine Algorithmen, sondern plant ein Modell.
Das Modell als Ergebnis des Entwurfs besteht aus einer Reihe von Funktionen die in Tupeln der Form (Funktion1, Funktion2, Beziehungen) verbunden sind.
Beispielhafte Beziehungen zwischen Funktionen f und g des Modells sind:
-
fruftgauf (Abhängigkeit) -
gfolgt auff(Sequenz) -
fspezialisiertg(Vererbung) -
fundghaben inhaltlich etwas gemeinsam (sie verfolgen den selben Zweck) -
fundgbenutzen gemeinsamen Zustand
Das mag abstrakt klingen und Modelle müssen auch nicht in Form von 3-spaltigen Excel-Blättern geliefert werden. Ein Klassendiagramm, ein Datenfluss, eine Zustandsmaschine… das und mehr sind hilfreiche Ausdrucksformen für Modelle - die sich allerdings alle auf die obige sehr allgemeine Definition zurückführen lassen.
Zentral beim Entwurf eines Modells ist, dass es ganz bewusst von konkretem Code abstrahiert. Die Feinheiten einer Programmiersprache oder eines Framework und der Detailreichtum von Logik stehen nicht zur Verfügung. Der Lösungsansatz ist “mit einfacheren Mitteln” zu finden.
Diese freiwillige Selbstbeschränkung hat mehrere Gründe:
- Weniger Details erlauben eine schnellere Lösungsfindung - auf hohem Abstraktionsnivau in Form eines Durchstichs.
- Eine deklarative Lösung erlaubt die einfachere visuelle Darstellung und damit Kommunikation zwischen Teammitgliedern. Mentale Modelle lassen sich externalisieren.
- Visuelle, abstrakte Lösungsansätze lassen sich in größerer Vielfalt gegenüberstellen, was der Findung besserer Lösungen dient.
- Einen Lösungsansatz zu finden erfordert andere geistige Aktivität/Fähigkeit als die Codierung eines Lösungsansatzes. Die explizite Modellierung vor einer Codierung dient mithin der Entzerrung des Entwicklungsprozesses; es wird ermüdendes, verlangsamendes und fehlerträchtiges Multitasking vermieden.
Ein bewusster und systematischer Entwurf stellt ein Modell her, das nicht nur die Lösung der Verhaltensanforderungen repräsentiert, sondern auch noch der Forderung nach Ordnung genügt.
Wo die Analyse eine Bastion gegen Wertarmut und Inkorrektheit ist, da ist der Entwurf eine Bastion gegen Unordnung.
3. Phase: Codierung
Die Codierung schließlich setzt den Entwurf um in Code. Du übersetzt ein Modell mit einer Programmiersprache in Funktionen, die du mit konkreter Logik ausfüllst.
Ist das Modell gut, kann dieser Phase durchaus eine gewisse Langeweile anhaften. Das Problem ist ja (theoretisch) gelöst. Die Spannung ist raus aus den Anforderungen. Insofern ist mein Ziel mit Programming with Ease, dir die Codierung etwas zu verleiden. Du sollst sie am Ende als mechanische Arbeit auffassen, bei der nur noch relativ wenig Kreativität nötig ist. Ok, vielleicht übertreibe ich ein wenig, aber so ungefähr stelle ich mir das vor, weil ich es selbst so erfahren habe. Je leichter ich mir die Programmierung gemacht habe, desto unspannender wurde die Codierung.
Nachlässigkeit darf sich deshalb jedoch nicht einschleichen. Die Codierung hat ihre eigenen Probleme, die noch gelöst werden wollen. Hier schlägt die Stunde des Handwerkers, der seine Technologien beherrscht.
Das Ergebnis der Codierung ist - wie sollte es anders sein - Code. Aber nicht irgendein Code, sondern Code, der erstens der Ordnung des Modells folgt und zweitens in den Detail-Ebenen unterhalb des Modells ebenfalls Ordnung walten lässt.
Darüber hinaus ist die Codierung die Phase, in der du die automatisierten Prüfungen der Korrektheit implementierst.
Ordnung und Korrektheit dürfen bei der Codierung auf den letzten Metern nicht kompromittiert werden. Das ist kein kleines Kunststück unter dem üblicherweise herrschenden Druck von Lieferterminen.
Zusammenfassung
Die Übersetzung von Anforderungen in Code ist eine komplexe Tätigkeit, die nur systematisch verlässlich alle Qualitäten herstellt: Wert in Form von Funktionalität + Effizienz, Korrektheit und Ordnung.
Die minimale Systematik, die ich dir mit Programming with Ease insgesamt vermitteln will, besteht darin, für gegebene Anforderungen eine für dich als Entwickler relevante Analyse durchzuführen, die nachvollziehbares Verständnis nicht nur dokumentiert, sondern auch automatisiert überprüfbar macht.
Ausgehend von diesem Verständnis wird dann im nächsten Schritt ein Lösungsansatz modelliert, der von den Feinheiten der Codierung bewusst abstrahiert für mehr Überblick, bessere Kommunizierbarkeit und größere Flexibilität.
Erst nach diesen Vorarbeiten kann alles bereit sein, um das zu tun, was man gemeinhin als die vordringliche Aufgabe von Softwareentwicklung sieht: die Codierung.

Analyse → Entwurf → Codierung (AEC): Dieser Prozess ist unverbrüchlich, gar unvermeidbar. Daran glaube ich fest; das zu verstehen, hat mir die Softwareentwicklung erheblich erleichtert.
Das bedeutet jedoch nicht, dass Softwareentwicklung deshalb “im Wasserfall” oder nach BDUF (Big Design Up-Front) verlaufen müsste. Die Phasen AEC können beliebig häufig und beliebig schnell durchlaufen werden. Sie sollten lediglich dem Umfang und Schwierigkeitsgrad der anliegenden Anforderungen entsprechen.
Auf diese Weise wird die Lücke zwischen Anforderungen und Code systematisch und nachvollziehbar und teamfähig überwunden.
Übungsaufgaben
Übung macht den Meister! Deshalb gibt es zu (fast) jedem Kapitel Übungsaufgaben, die du in deiner Geschwindigkeit lösen kannst. Kein Druck, keine Anprüche, die andere dabei an dich haben könnten. Mach es dir gemütlich damit.
Zu allen Übungsaufgaben findest du im Anhang auch Musterlösungen. Mit denen möchte ich dir das Selbststudium erleichtern; versuche also nicht zu luschern, während du die Übungsaufgaben löst. Und bitte verstehe die Musterlösungen auch nicht als Abkürzung, mit denen du dir die eigene Lösung der Übungsaufgaben (er)sparst.
Wenn du wirklich, wirklich daran interessiert bist, zu lernen, d.h. deine Gewohnheiten zu verändern, dann brauchst du eigene Praxis. Du musst nach dem Lesen etwas tun mit dem Gelesenen. Gern kannst du natürlich die Anwendung in deinem Projektalltag versuchen; früher oder später musst du diesen Sprung ja ohnehin machen. Aber erstens sind die Probleme in deinem Projektalltag weniger überschaubar, so dass dir weniger klar ist, wie und wo mit dem Transfer des Gelesenen du anfangen kannst. Zweitens wirst du durch Anwendung des Neuen erstmal langsamer, weil du noch unsicher bist; das kann dir schnell scheele Blicke von den Kollegen einbringen und du fällst in alte Gewohnheiten zurück. Drittens kann ich dir keinerlei Feedback geben, noch nicht einmal in Form einer monologischen Musterlösung. Feedback ist aber extrem wichtig, wenn du eine neue Fähigkeit erwirbst.
Deshalb empfehle ich dir sehr, die Übungen zu machen als erste Anwendung des Lernstoffs “in einer Sandkiste”. Die Aufgaben sind überschaubar, keiner redet dir rein und macht druck und mit den Musterlösungen bekommst du zumindest eine gewisse Form von Feedback bzw. Kontrast zum Nachdenken.
Um deine Lösungen der Übungsaufgaben zu dokumentieren, lege für dich ein Git-Repository an, in dem du all deine Arbeitsergebnisse speicherst. Committe häufig und vergiss am Ende das Push nicht.8
Ein Git-Repository ist das unterste und einfachste Sicherheitsnetz, das du für deine Programmierung spannen kannst. Never code without it.9