Capítulo 9 - Git Internamente
Você pode ter pulado para este capítulo a partir de um capítulo anterior, ou você pode ter chegado aqui depois de ler o resto do livro — em ambos os casos, este é o lugar onde você vai conhecer o funcionamento interno e implementação do Git. Descobri que aprender esta informação era de fundamental importância para a compreensão de quanto o Git é útil e poderoso, mas outros argumentaram que pode ser confuso e desnecessariamente complexo para iniciantes. Assim, eu fiz essa discussão o último capítulo do livro para que você possa lê-lo mais cedo ou mais tarde, em seu processo de aprendizagem. Deixo isso para você decidir.
Agora que você está aqui, vamos começar. Primeiro, se ainda não for claro, o Git é fundamentalmente um sistema de arquivos de conteúdo endereçavel com uma interface de usuário VCS escrito em cima dele. Você vai aprender mais sobre o que isto significa daqui a pouco.
Nos primeiros dias do Git (principalmente antes da versão 1.5), a interface de usuário era muito mais complexa, pois enfatizou este sistema de arquivos, em vez de um VCS. Nos últimos anos, a interface do usuário tem sido aperfeiçoada até que ela se torne tão limpa e fácil de usar como qualquer outro sistema; mas, muitas vezes, o estereótipo persiste sobre a UI antiga do Git que era complexa e difícil de aprender.
A camada de sistema de arquivos de conteúdo endereçável é incrivelmente interessante, então eu vou falar dela primeiro neste capítulo; então, você vai aprender sobre os mecanismos de transporte e as tarefas de manutenção do repositório.
9.1 Git Internamente - Encanamento (Plumbing) e Porcelana (Porcelain)
Encanamento (Plumbing) e Porcelana (Porcelain)
Este livro aborda como usar o Git com 30 ou mais verbos como checkout, branch, remote, e assim por diante. Mas como o Git foi pensado inicialmente um conjunto de ferramentas para um VCS, em vez de apenas um VCS amigável, ele tem um grupo de verbos que fazem o trabalho de baixo nível e foram projetados para serem encadeados (usando pipe) no estilo UNIX ou chamados a partir de scripts. Estes comandos são geralmente referidos como comandos de “encanamento” (plumbing), e os comandos mais amigáveis são chamados de comandos “porcelana” (porcelain).
Os oito primeiros capítulos do livro tratam quase que exclusivamente com comandos porcelana. Mas, neste capítulo, você estará lidando principalmente com os comandos de nível inferior de encanamento, porque eles te dão acesso aos trabalhos internos do Git e ajudam a demonstrar como e por que o Git faz o que faz. Estes comandos não são destinados a ser usados manualmente na linha de comando, mas sim para serem usados como blocos de construção para novas ferramentas e scripts personalizados.
Quando você executa git init em um diretório novo ou existente, Git cria o diretório .git, que é onde quase tudo que o Git armazena e manipula está localizado. Se você deseja fazer o backup ou clonar seu repositório, copiar este diretório para outro lugar lhe dará quase tudo o que você precisa. Este capítulo inteiro trata basicamente do conteúdo deste diretório. Eis o que ele contém:
1 $ ls
2 HEAD
3 branches/
4 config
5 description
6 hooks/
7 index
8 info/
9 objects/
10 refs/
Você pode ver alguns outros arquivos lá, mas este é um novo repositório git init — é o que você vê por padrão. O diretório branches não é usado por versões mais recentes do Git, e o arquivo description só é usado pelo programa gitweb, então não se preocupe com eles. O arquivo config contém as opções de configuração específicas do projeto, e o diretório info contém um arquivo de exclusão global com padrões ignorados que você não deseja rastrear em um arquivo .gitignore. O diretório hooks contém os “hook scripts” de cliente ou servidor, que são discutidos em detalhes no Capítulo 7.
Isso deixa quatro entradas importantes: os arquivos HEAD e index e diretórios objects e refs. Estas são as peças centrais do Git. O diretório objects armazena todo o conteúdo do seu banco de dados, o diretório refs armazena os ponteiros para objetos de commit (branches), o arquivo HEAD aponta para o branch atual, e o arquivo index é onde Git armazena suas informações da área de preparação (staging area). Você vai agora ver cada uma dessas seções em detalhes para saber como o Git opera.
9.2 Git Internamente - Objetos do Git
Objetos do Git
Git é um sistema de arquivos de conteúdo endereçável. O que significa isso? Isso significa que o núcleo do Git armazena dados usando um simples mecanismo chave-valor. Você pode inserir qualquer tipo de conteúdo nele, e ele vai retornar uma chave que você pode usar para recuperar o conteúdo a qualquer momento. Para demonstrar, você pode usar o comando de encanamento hash-object, pega alguns dados, armazena eles em seu diretório .git, e retorna a chave dos dados armazenados. Primeiro, você inicializa um novo repositório Git e verifica se não há nada no diretório objects:
1 $ mkdir test
2 $ cd test
3 $ git init
4 Initialized empty Git repository in /tmp/test/.git/
5 $ find .git/objects
6 .git/objects
7 .git/objects/info
8 .git/objects/pack
9 $ find .git/objects -type f
10 $
Git inicializou o diretório objects e criou os subdiretórios pack e info, mas não existem arquivos comuns neles. Agora, armazene um texto em seu banco de dados Git:
1 $ echo 'test content' | git hash-object -w --stdin
2 d670460b4b4aece5915caf5c68d12f560a9fe3e4
O -w diz ao hash-object para armazenar o objeto; caso contrário, o comando simplesmente diz qual seria a chave. --stdin indica ao comando para ler o conteúdo da entrada padrão (stdin); se você não especificar isso, hash-object espera um caminho (path) para um arquivo. A saída do comando é uma soma hash de 40 caracteres. Este é o hash SHA-1 — uma soma de verificação do conteúdo que você está armazenando mais um cabeçalho, que você vai entender mais daqui a pouco. Agora você pode ver como o Git armazenou seus dados:
1 $ find .git/objects -type f
2 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Você pode ver um arquivo no diretório objects. Isto é como o Git armazena o conteúdo inicialmente — como um único arquivo por parte de conteúdo, nomeado com o checksum SHA-1 do conteúdo e seu cabeçalho. O subdiretório é nomeado com os 2 primeiros caracteres do SHA, e o arquivo é nomeado com os 38 caracteres restantes.
Você pode fazer um pull do conteúdo com o comando cat-file. Este comando é uma espécie de canivete suíço para inspecionar objetos Git. Passando -p para ele instrui o comando cat-file a descobrir o tipo de conteúdo e exibi-lo para você:
1 $ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
2 test content
Agora, você pode adicionar conteúdo no Git e fazer pull dele. Você também pode fazer isso com o conteúdo de arquivos. Por exemplo, você pode fazer algum controle de versão simples em um arquivo. Primeiro, crie um novo arquivo e salve seu conteúdo em seu banco de dados:
1 $ echo 'version 1' > test.txt
2 $ git hash-object -w test.txt
3 83baae61804e65cc73a7201a7252750c76066a30
Então, escreva algum conteúdo novo no arquivo e salve-o novamente:
1 $ echo 'version 2' > test.txt
2 $ git hash-object -w test.txt
3 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
Seu banco de dados contém as duas novas versões do arquivo, assim como o primeiro conteúdo que você armazenou lá:
1 $ find .git/objects -type f
2 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
3 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30
4 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Agora você pode reverter o arquivo de volta para a primeira versão
1 $ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
2 $ cat test.txt
3 version 1
ou a segunda versão:
1 $ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
2 $ cat test.txt
3 version 2
Mas, lembrar a chave SHA-1 para cada versão de seu arquivo não é prático; mais ainda, você não está armazenando o nome do arquivo em seu sistema — apenas o conteúdo. Esse tipo de objeto é chamado de blob. Você pode fazer o Git informar o tipo de objeto de qualquer objeto no Git, dada a sua chave SHA-1, com cat-file -t:
1 $ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
2 blob
Objetos Árvore
O próximo tipo que você verá é o objeto árvore, que resolve o problema de armazenar o nome do arquivo e também permite que você armazene um grupo de arquivos juntos. Git armazena o conteúdo de uma maneira semelhante a um sistema de arquivos UNIX, mas de forma um pouco simplificada. Todo o conteúdo é armazenado como árvore e objetos blob, com árvores correspondendo às entradas de diretório do UNIX e os blobs correspondendo mais ou menos a inodes ou conteúdo de arquivos. Um único objeto árvore contém uma ou mais entradas de árvores, cada uma das quais contém um ponteiro SHA-1 para um blob ou subárvore com seu modo associado, tipo e o nome do arquivo. Por exemplo, a árvore mais recente no projeto simplegit pode parecer algo como isto:
1 $ git cat-file -p master^{tree}
2 100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
3 100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
4 040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
A sintaxe master^{tree} especifica o objeto árvore que é apontado pelo último commit em seu branch master. Observe que o subdiretório lib não é um blob, mas sim, um ponteiro para outra árvore:
1 $ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
2 100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Conceitualmente, os dados que o Git está armazenando são algo como mostra a Figura 9-1.
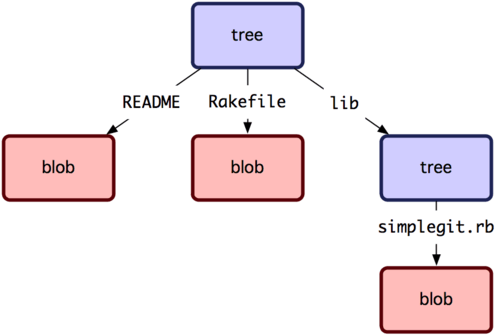
Figura 9-1. Versão simples do modelo de dados Git.
Você pode criar sua própria árvore. Git normalmente cria uma árvore, a partir do estado de sua área de seleção ou índice e escreve um objeto árvore a partir dele. Assim, para criar um objeto árvore, primeiro você tem que criar um índice colocando alguns arquivos na área de seleção (staging area). Para criar um índice com uma única entrada — a primeira versão do seu arquivo text.txt — você pode usar o comando plumbing update-index. Você pode usar este comando para adicionar artificialmente a versão anterior do arquivo test.txt em uma nova área de seleção. Você deve passar a opção --add porque o arquivo ainda não existe na sua área de seleção (você não tem sequer uma área de seleção criada ainda) e --cacheinfo porque o arquivo que você está adicionando não está em seu diretório, mas está em seu banco de dados. Então, você especifica o modo, o SHA-1, e o nome do arquivo:
1 $ git update-index --add --cacheinfo 100644 \
2 83baae61804e65cc73a7201a7252750c76066a30 test.txt
Neste caso, você está especificando um modo 100644, que significa que é um arquivo normal. Outras opções são 100755, que significa que é um arquivo executável, e 120000, que especifica um link simbólico. O modo é obtido a partir de modos normais do Unix, mas é muito menos flexível — estes três modos são os únicos que são válidas para arquivos (blobs) no Git (embora outros modos sejam usados para diretórios e submódulos).
Agora, você pode usar o comando write-tree para escrever a área de seleção em um objeto árvore. Nenhuma opção -w é necessária — chamando write-tree cria automaticamente um objeto árvore a partir do estado do índice se a árvore ainda não existe:
1 $ git write-tree
2 d8329fc1cc938780ffdd9f94e0d364e0ea74f579
3 $ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
4 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
Você também pode verificar que este é um objeto árvore:
1 $ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
2 tree
Você vai agora criar uma nova árvore com a segunda versão do test.txt e um novo arquivo também:
1 $ echo 'new file' > new.txt
2 $ git update-index test.txt
3 $ git update-index --add new.txt
Sua área de seleção agora tem a nova versão do test.txt bem como o novo arquivo new.txt. Escreva aquela árvore (grave o estado da área de seleção ou índice em um objeto árvore) e veja o que aparece:
1 $ git write-tree
2 0155eb4229851634a0f03eb265b69f5a2d56f341
3 $ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
4 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
5 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Note que esta árvore tem entradas de arquivos e também que o SHA de test.txt é a “versão 2” do SHA de antes (1f7a7a). Apenas por diversão, você vai adicionar a primeira árvore como um subdiretório nesta árvore. Você pode ler as árvores em sua área de seleção chamando read-tree. Neste caso, você pode ler uma árvore existente em sua área de seleção como uma subárvore usando a opção --prefix em read-tree:
1 $ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
2 $ git write-tree
3 3c4e9cd789d88d8d89c1073707c3585e41b0e614
4 $ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
5 040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
6 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
7 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Se você criou um diretório de trabalho da nova árvore que acabou de escrever, você teria os dois arquivos no nível mais alto do diretório de trabalho e um subdiretório chamado bak, que continha a primeira versão do arquivo teste.txt. Você pode pensar nos dados que o Git contém para estas estruturas como sendo parecidas com a Figura 9-2.
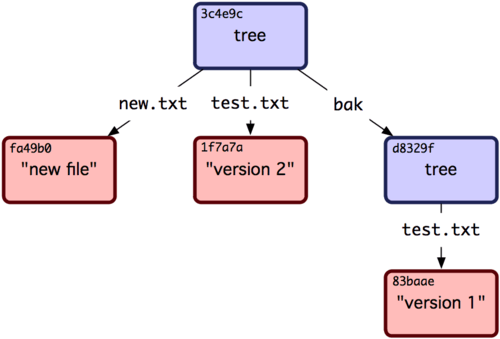
Figura 9-2. A estrutura de conteúdo de seus dados Git atuais.
Objetos de Commit
Você tem três árvores que especificam os diferentes snapshots de seu projeto que você deseja acompanhar, mas o problema anterior mantém-se: você deve se lembrar de todos os três valores SHA-1, a fim de recuperar os snapshots. Você também não tem qualquer informação sobre quem salvou os snapshots, quando eles foram salvos, ou por que eles foram salvos. Esta é a informação básica que os objetos commit armazenam para você.
Para criar um objeto commit, você chama commit-tree e especifica uma única árvore SHA-1 e quais objetos commit, se houverem, diretamente precederam ele. Comece com a primeira árvore que você escreveu:
1 $ echo 'first commit' | git commit-tree d8329f
2 fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Agora você pode ver o seu novo objeto commit com cat-file:
1 $ git cat-file -p fdf4fc3
2 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
3 author Scott Chacon <schacon@gmail.com> 1243040974 -0700
4 committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
5
6 first commit
O formato de um objeto commit é simples: ele especifica a árvore de nível superior para o snapshot do projeto nesse momento; a informação do author/committer (autor do commit) obtido de suas opções de configuração user.name e user.email, com a timestamp atual; uma linha em branco, e em seguida, a mensagem de commit.
Em seguida, você vai escrever os outros dois objetos commit, cada um referenciando o commit que veio diretamente antes dele:
1 $ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
2 cac0cab538b970a37ea1e769cbbde608743bc96d
3 $ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
4 1a410efbd13591db07496601ebc7a059dd55cfe9
Cada um dos três objetos commit apontam para uma das três árvores de snapshot criadas. Curiosamente, agora você tem um histórico Git real que você pode ver com o comando git log, se você executá-lo no último commit SHA-1:
1 $ git log --stat 1a410e
2 commit 1a410efbd13591db07496601ebc7a059dd55cfe9
3 Author: Scott Chacon <schacon@gmail.com>
4 Date: Fri May 22 18:15:24 2009 -0700
5
6 third commit
7
8 bak/test.txt | 1 +
9 1 files changed, 1 insertions(+), 0 deletions(-)
10
11 commit cac0cab538b970a37ea1e769cbbde608743bc96d
12 Author: Scott Chacon <schacon@gmail.com>
13 Date: Fri May 22 18:14:29 2009 -0700
14
15 second commit
16
17 new.txt | 1 +
18 test.txt | 2 +-
19 2 files changed, 2 insertions(+), 1 deletions(-)
20
21 commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
22 Author: Scott Chacon <schacon@gmail.com>
23 Date: Fri May 22 18:09:34 2009 -0700
24
25 first commit
26
27 test.txt | 1 +
28 1 files changed, 1 insertions(+), 0 deletions(-)
Incrível. Você acabou de fazer as operações de baixo nível para construir um histórico Git sem usar qualquer um dos front ends. Isso é essencialmente o que o Git faz quando você executa os comandos git add e git commit — ele armazena blobs dos arquivos que foram alterados, atualiza o índice, escreve árvores, e escreve objetos commit que fazem referência às árvores de nível superior e os commits que vieram imediatamente antes deles. Esses três objetos Git principais — o blob, a árvore, e o commit — são inicialmente armazenados como arquivos separados no seu diretório .git/objects. Aqui estão todos os objetos no diretório de exemplo agora, comentado com o que eles armazenam:
1 $ find .git/objects -type f
2 .git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
3 .git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
4 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
5 .git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
6 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
7 .git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
8 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
9 .git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
10 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
11 .git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Se você seguir todos os ponteiros internos, você tem um gráfico como o da Figura 9-3.
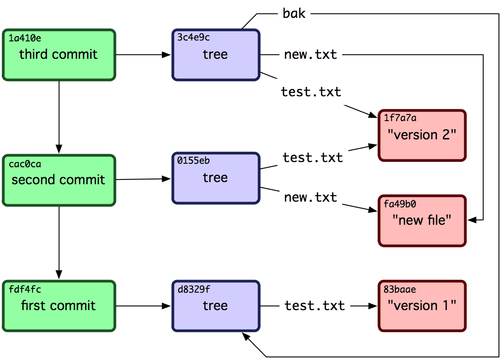
Figura 9-3. Todos os objetos em seu diretório Git.
Armazenamento de Objetos
Eu mencionei anteriormente que um cabeçalho é armazenado com o conteúdo. Vamos ver como Git armazena seus objetos. Você vai ver como armazenar um objeto blob — neste caso, a string “what is up, doc?” — interativamente na linguagem de script Ruby. Você pode iniciar o modo interativo Ruby com o comando irb:
1 $ irb
2 >> content = "what is up, doc?"
3 => "what is up, doc?"
Git constrói um cabeçalho que começa com o tipo do objeto, neste caso um blob. Em seguida, é adicionado um espaço seguindo-se a dimensão do conteúdo e, finalmente, um byte nulo:
1 >> header = "blob #{content.length}\0"
2 => "blob 16\000"
Git concatena o cabeçalho e o conteúdo original e, em seguida, calcula o checksum SHA-1 do novo conteúdo. Você pode calcular o valor SHA-1 em Ruby, incluindo a biblioteca SHA1 digest com o comando require e então chamar Digest::SHA1.hexdigest() passando a string:
1 >> store = header + content
2 => "blob 16\000what is up, doc?"
3 >> require 'digest/sha1'
4 => true
5 >> sha1 = Digest::SHA1.hexdigest(store)
6 => "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git comprime o conteúdo novo com zlib, o que você pode fazer em Ruby com a biblioteca zlib. Primeiro, você precisa incluir a biblioteca e, em seguida, executar Zlib::Deflate.deflate() no conteúdo:
1 >> require 'zlib'
2 => true
3 >> zlib_content = Zlib::Deflate.deflate(store)
4 => "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
Finalmente, você vai escrever o seu conteúdo “zlib-deflated” em um objeto no disco. Você vai determinar o caminho do objeto que você deseja escrever (os dois primeiros caracteres do valor SHA-1 serão o nome do subdiretório, e os últimos 38 caracteres serão o nome do arquivo dentro desse diretório). Em Ruby, você pode usar a função FileUtils.mkdir_p() para criar o subdiretório se ele não existir. Em seguida, abra o arquivo com File.open() e escreva o conteúdo anteriormente comprimido com zlib no arquivo com uma chamada a write() no identificador de arquivo resultante:
1 >> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
2 => ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
3 >> require 'fileutils'
4 => true
5 >> FileUtils.mkdir_p(File.dirname(path))
6 => ".git/objects/bd"
7 >> File.open(path, 'w') { |f| f.write zlib_content }
8 => 32
Isso é tudo — você criou um objeto Git blob válido. Todos os objetos do Git são armazenados da mesma maneira, só que com diferentes tipos — em vez da string blob, o cabeçalho vai começar com commit ou tree. Além disso, embora o conteúdo do blob possa ser pequeno, o commit e conteúdo da árvore são formatados muito especificamente.
9.3 Git Internamente - Referencias Git
Referencias Git
Você pode executar algo como git log 1a410e para ver seu histórico inteiro, mas você ainda tem que lembrar que 1a410e é o último commit, a fim de que o você possa navegar no histórico para encontrar todos os objetos. Você precisa de um arquivo no qual você possa armazenar o valor SHA-1 em um nome simples para que você possa usar esse ponteiro em vez do valor SHA-1.
No Git, eles são chamados de “referências” (references) ou “refs”; você pode encontrar os arquivos que contêm os valores SHA-1 no diretório .git/refs. No projeto atual, esse diretório não contém arquivos, mas contém uma estrutura simples:
1 $ find .git/refs
2 .git/refs
3 .git/refs/heads
4 .git/refs/tags
5 $ find .git/refs -type f
6 $
Para criar uma nova referência que irá ajudá-lo a se lembrar onde seu último commit está, você pode tecnicamente fazer algo tão simples como isto:
1 $ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/master
Agora, você pode usar a referência head que você acabou de criar em vez do valor SHA-1 em seus comandos do Git:
1 $ git log --pretty=oneline master
2 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
3 cac0cab538b970a37ea1e769cbbde608743bc96d second commit
4 fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Você não deve editar diretamente os arquivos de referência. Git oferece um comando mais seguro para fazer isso, se você deseja atualizar uma referência chamada update-ref:
1 $ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9
Isso é basicamente o que um branch em Git: um simples ponteiro ou referência para o head de uma linha de trabalho. Para criar um branch de volta ao segundo commit, você pode fazer isso:
1 $ git update-ref refs/heads/test cac0ca
Seu branch irá conter apenas o trabalho do commit abaixo:
1 $ git log --pretty=oneline test
2 cac0cab538b970a37ea1e769cbbde608743bc96d second commit
3 fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Agora, seu banco de dados Git conceitualmente é algo como a Figura 9-4.
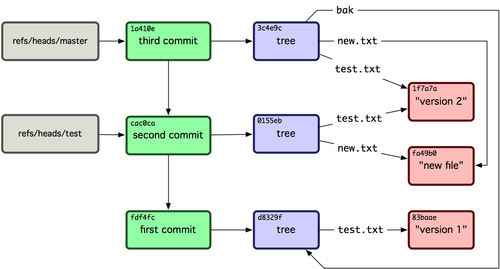
Figura 9-4. Objetos de diretório Git com referências ao branch head incluídas.
Quando você executar comandos como git branch (branchname), Git basicamente executa o comando update-ref para adicionar o SHA-1 do último commit do branch em que você está em qualquer nova referência que deseja criar.
O HEAD
A questão agora é, quando você executar git branch (branchname), como é que o Git sabe o SHA-1 do último commit? A resposta é o arquivo HEAD. O arquivo HEAD é uma referência simbólica para o branch em que você está no momento. Por referência simbólica, quer dizer que, ao contrário de uma referência normal, ele geralmente não contêm um valor SHA-1 mas sim um apontador para uma outra referência. Se você olhar no arquivo, você normalmente verá algo como isto:
1 $ cat .git/HEAD
2 ref: refs/heads/master
Se você executar git checkout test, Git atualiza o arquivo para ficar assim:
1 $ cat .git/HEAD
2 ref: refs/heads/test
Quando você executar git commit, ele crirá o objeto commit, especificando o pai desse objeto commit para ser o valor SHA-1 de referência apontada por HEAD.
Você também pode editar manualmente esse arquivo, mas um comando mais seguro existe para fazer isso: symbolic-ref. Você pode ler o valor de seu HEAD através deste comando:
1 $ git symbolic-ref HEAD
2 refs/heads/master
Você também pode definir o valor de HEAD:
1 $ git symbolic-ref HEAD refs/heads/test
2 $ cat .git/HEAD
3 ref: refs/heads/test
Você não pode definir uma referência simbólica fora do estilo refs:
1 $ git symbolic-ref HEAD test
2 fatal: Refusing to point HEAD outside of refs/
Tags
Você acabou de ver os três tipos de objetos principais do Git, mas há um quarto. O objeto tag é muito parecido com um objeto commit — contém um tagger (pessoa que cria a tag), uma data, uma mensagem e um ponteiro. A principal diferença é que um objeto tag aponta para um commit em vez de uma árvore. É como uma referência de branch, mas nunca se move — ele sempre aponta para o mesmo commit, mas te dá um nome mais amigável para ele.
Como discutido no Capítulo 2, existem dois tipos de tags: anotadas (annotated) e leves (lightweight). Você pode fazer uma tag leve executando algo como isto:
1 $ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d
Isso é tudo que uma tag leve é — um branch que nunca se move. Uma tag anotada é mais complexa. Se você criar uma tag anotada, Git cria um objeto tag e depois escreve uma referência para apontar para ela em vez de diretamente para um commit. Você pode ver isso através da criação de uma tag anotada (-a especifica que é uma tag anotada):
1 $ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 -m 'test tag'
Aqui está o valor SHA-1 do objeto que ele criou:
1 $ cat .git/refs/tags/v1.1
2 9585191f37f7b0fb9444f35a9bf50de191beadc2
Agora, execute o comando cat-file com este valor SHA-1:
1 $ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
2 object 1a410efbd13591db07496601ebc7a059dd55cfe9
3 type commit
4 tag v1.1
5 tagger Scott Chacon <schacon@gmail.com> Sat May 23 16:48:58 2009 -0700
6
7 test tag
Observe que a entrada do objeto aponta para o valor SHA-1 do commit que você taggeou. Também observe que ele não precisa apontar para um commit; você pode taggear qualquer objeto Git. No código-fonte Git, por exemplo, o mantenedor adicionou sua chave pública GPG como um objeto blob e depois taggeou ele. Você pode ver a chave pública, executando
1 $ git cat-file blob junio-gpg-pub
no repositório de código-fonte Git. O repositório do kernel Linux também tem um objeto tag que não aponta para um commit — a primeira tag criada aponta para a árvore inicial da importação do código fonte.
Remotos
O terceiro tipo de referência que você vai ver é uma referência remota. Se você adicionar um remoto e fazer um push para ele, Git armazena o valor de seu último push para esse remoto para cada branch no diretório refs refs/remotes. Por exemplo, você pode adicionar um remoto chamado origin e fazer um push do seu branch master nele:
1 $ git remote add origin git@github.com:schacon/simplegit-progit.git
2 $ git push origin master
3 Counting objects: 11, done.
4 Compressing objects: 100% (5/5), done.
5 Writing objects: 100% (7/7), 716 bytes, done.
6 Total 7 (delta 2), reused 4 (delta 1)
7 To git@github.com:schacon/simplegit-progit.git
8 a11bef0..ca82a6d master -> master
Então, você pode ver como era o branch master no remoto origin da última vez que você se comunicou com o servidor, verificando o arquivo refs/remotes/origin/master:
1 $ cat .git/refs/remotes/origin/master
2 ca82a6dff817ec66f44342007202690a93763949
Referências remotas diferem dos branches (referências refs/heads), principalmente no sentido de que não pode ser feito o checkout delas. Git move elas como indicadores para o último estado conhecido de onde os branches estavam nesses servidores.
9.4 Git Internamente - Packfiles
Packfiles
Vamos voltar para o banco de dados de objetos do seu repositório de testes Git. Neste momento, você tem 11 objetos — 4 blobs, 3 árvores, 3 commits, e 1 tag:
1 $ find .git/objects -type f
2 .git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
3 .git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
4 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
5 .git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
6 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
7 .git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag
8 .git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
9 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
10 .git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
11 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
12 .git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Git comprime o conteúdo desses arquivos com zlib, então todos estes arquivos ocupam coletivamente apenas 925 bytes. Você vai adicionar um conteúdo um pouco maior no repositório para demonstrar uma característica interessante do Git. Adicione o arquivo repo.rb da biblioteca Grit em que você trabalhou anteriormente — trata-se de um arquivo de código fonte de 12K:
1 $ curl http://github.com/mojombo/grit/raw/master/lib/grit/repo.rb > repo.rb
2 $ git add repo.rb
3 $ git commit -m 'added repo.rb'
4 [master 484a592] added repo.rb
5 3 files changed, 459 insertions(+), 2 deletions(-)
6 delete mode 100644 bak/test.txt
7 create mode 100644 repo.rb
8 rewrite test.txt (100%)
Se você olhar para a árvore resultante, você pode ver o valor SHA-1 que o arquivo repo.rb tem no objeto blob:
1 $ git cat-file -p master^{tree}
2 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
3 100644 blob 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e repo.rb
4 100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
Você pode então usar git cat-file para ver o quão grande esse objeto é:
1 $ git cat-file -s 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e
2 12898
Agora, modifique o arquivo um pouco, e veja o que acontece:
1 $ echo '# testing' >> repo.rb
2 $ git commit -am 'modified repo a bit'
3 [master ab1afef] modified repo a bit
4 1 files changed, 1 insertions(+), 0 deletions(-)
Verifique a árvore criada por este commit, e você verá algo interessante:
1 $ git cat-file -p master^{tree}
2 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
3 100644 blob 05408d195263d853f09dca71d55116663690c27c repo.rb
4 100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
O blob agora é um blob diferente, o que significa que, embora você tenha adicionado apenas uma única linha ao final de um arquivo de 400 linhas, Git armazenou esse novo conteúdo como um objeto completamente novo:
1 $ git cat-file -s 05408d195263d853f09dca71d55116663690c27c
2 12908
Você tem dois objetos de 12K quase idênticos em seu disco. Não seria bom se o Git pudesse armazenar um deles na íntegra, mas, o segundo objeto apenas como o delta entre ele e o primeiro?
Acontece que ele pode. O formato inicial em que Git salva objetos em disco é chamado de formato de objeto solto (loose object format). No entanto, ocasionalmente Git empacota vários desses objetos em um único arquivo binário chamado de packfile, a fim de economizar espaço e ser mais eficiente. Git faz isso, se você tem muitos objetos soltos, se você executar o comando git gc manualmente, ou se você fizer push para um servidor remoto. Para ver o que acontece, você pode manualmente pedir ao Git para arrumar os objetos chamando o comando git gc:
1 $ git gc
2 Counting objects: 17, done.
3 Delta compression using 2 threads.
4 Compressing objects: 100% (13/13), done.
5 Writing objects: 100% (17/17), done.
6 Total 17 (delta 1), reused 10 (delta 0)
Se você olhar em seu diretório de objetos, você vai descobrir que a maioria de seus objetos sumiram, e um novo par de arquivos apareceu:
1 $ find .git/objects -type f
2 .git/objects/71/08f7ecb345ee9d0084193f147cdad4d2998293
3 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
4 .git/objects/info/packs
5 .git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
6 .git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack
Os objetos que permanecem são os blobs que não são apontados por qualquer commit — neste caso, os blobs de exemplo “what is up, doc?” e o exemplo “test content” que você criou anteriormente. Como você nunca adicionou eles a qualquer commit, eles são considerados pendentes e não são embalados em sua nova packfile.
Os outros arquivos são o seu novo packfile e um índice. O packfile é um arquivo único contendo o conteúdo de todos os objetos que foram removidos do seu sistema de arquivos. O índice é um arquivo que contém offsets deste packfile assim você pode rapidamente buscar um objeto específico. O que é legal é que, embora os objetos em disco antes de executar o gc tinham coletivamente cerca de 12K de tamanho, o packfile novo tem apenas 6K. Você reduziu a utilização do disco pela metade empacotando seus objetos.
Como o Git faz isso? Quando Git empacota objetos, ele procura por arquivos que são nomeados e dimensionados de forma semelhante, e armazena apenas os deltas de uma versão do arquivo para a próxima. Você pode olhar dentro do packfile e ver o que o Git fez para economizar espaço. O comando plumbing git verify-pack permite que você veja o que foi empacotado:
1 $ git verify-pack -v \
2 .git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
3 0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 5400
4 05408d195263d853f09dca71d55116663690c27c blob 12908 3478 874
5 09f01cea547666f58d6a8d809583841a7c6f0130 tree 106 107 5086
6 1a410efbd13591db07496601ebc7a059dd55cfe9 commit 225 151 322
7 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 5381
8 3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 101 105 5211
9 484a59275031909e19aadb7c92262719cfcdf19a commit 226 153 169
10 83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 5362
11 9585191f37f7b0fb9444f35a9bf50de191beadc2 tag 136 127 5476
12 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e blob 7 18 5193 1 \
13 05408d195263d853f09dca71d55116663690c27c
14 ab1afef80fac8e34258ff41fc1b867c702daa24b commit 232 157 12
15 cac0cab538b970a37ea1e769cbbde608743bc96d commit 226 154 473
16 d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 5316
17 e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4352
18 f8f51d7d8a1760462eca26eebafde32087499533 tree 106 107 749
19 fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 856
20 fdf4fc3344e67ab068f836878b6c4951e3b15f3d commit 177 122 627
21 chain length = 1: 1 object
22 pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack: ok
Aqui, o blob 9bc1d, que se você se lembrar foi a primeira versão do seu arquivo repo.rb, faz referência ao blob 05408, que foi a segunda versão do arquivo. A terceira coluna da saída é o tamanho do objeto no pacote, assim você pode ver que 05408 ocupa 12K do arquivo, mas que 9bc1d ocupa apenas 7 bytes. O que também é interessante é que a segunda versão do arquivo é a que é armazenada intacta, enquanto que a versão original é armazenada como um delta — isso porque é mais provável a necessidade de acesso mais rápido para a versão mais recente do arquivo.
A coisa realmente interessante sobre isso é que ele pode ser reembalado a qualquer momento. Git irá ocasionalmente reembalar seu banco de dados automaticamente, sempre tentando economizar mais espaço. Você pode também manualmente reembalar a qualquer momento executando git gc.
9.5 Git Internamente - O Refspec
O Refspec
Ao longo deste livro, você usou um simples mapeamento de branches remotos para referências locais; mas eles podem ser mais complexos. Suponha que você adicione um remoto como este:
1 $ git remote add origin git@github.com:schacon/simplegit-progit.git
Ele adiciona uma seção em seu arquivo .git/config, especificando o nome do remoto (origin), a URL do repositório remoto, e o refspec a ser buscado:
1 [remote "origin"]
2 url = git@github.com:schacon/simplegit-progit.git
3 fetch = +refs/heads/*:refs/remotes/origin/*
O formato do refspec é um + opcional, seguido por <src>:<dst>, onde <src> é o padrão para referências no lado remoto e <dst> é onde essas referências serão escritas localmente. O + diz ao Git para atualizar a referência, mesmo que não seja um fast-forward.
No caso padrão que é automaticamente escrito por um comando git remote add, Git busca todas as referências em refs/heads/ no servidor e grava-os em refs/remotes/origin/ localmente. Então, se há um branch master no servidor, você pode acessar o log desse branch localmente através de
1 $ git log origin/master
2 $ git log remotes/origin/master
3 $ git log refs/remotes/origin/master
Eles são todos equivalentes, porque Git expande cada um deles em refs/remotes/origin/master.
Se você quiser que o Git só faça o pull do branch master toda vez, e não qualquer outro branch do servidor remoto, você pode alterar a linha fetch para
1 fetch = +refs/heads/master:refs/remotes/origin/master
Este é apenas o refspec padrão do git fetch para esse remoto. Se você quiser fazer algo apenas uma vez, você pode especificar o refspec na linha de comando também. Para fazer o pull do branch master do remoto até origin/mymaster localmente, você pode executar
1 $ git fetch origin master:refs/remotes/origin/mymaster
Você também pode especificar múltiplos refspecs. Na linha de comando, você pode fazer pull de vários branches assim:
1 $ git fetch origin master:refs/remotes/origin/mymaster \
2 topic:refs/remotes/origin/topic
3 From git@github.com:schacon/simplegit
4 ! [rejected] master -> origin/mymaster (non fast forward)
5 * [new branch] topic -> origin/topic
Neste caso, o pull do branch master foi rejeitado, porque não era uma referência fast-forward. Você pode evitar isso especificando o + na frente do refspec.
Você também pode especificar múltiplos refspecs em seu arquivo de configuração. Se você quer sempre buscar os branches master e experiment, adicione duas linhas:
1 [remote "origin"]
2 url = git@github.com:schacon/simplegit-progit.git
3 fetch = +refs/heads/master:refs/remotes/origin/master
4 fetch = +refs/heads/experiment:refs/remotes/origin/experiment
Você não pode usar globs parciais no padrão, então isto seria inválido:
1 fetch = +refs/heads/qa*:refs/remotes/origin/qa*
No entanto, você pode usar namespacing para realizar algo assim. Se você tem uma equipe de QA que faz push de uma série de branches, e você deseja obter o branch master e qualquer um dos branches da equipe de QA, mas nada mais, você pode usar uma seção de configuração como esta:
1 [remote "origin"]
2 url = git@github.com:schacon/simplegit-progit.git
3 fetch = +refs/heads/master:refs/remotes/origin/master
4 fetch = +refs/heads/qa/*:refs/remotes/origin/qa/*
Se você tem um fluxo de trabalho complexo que tem uma equipe de QA fazendo push de branches, desenvolvedores fazendo push de branches, e equipes de integração fazendo push e colaborando em branches remotos, você pode nomeá-los (namespace) facilmente desta forma.
Fazendo Push de Refspecs
É legal que você possa buscar referências nomeadas dessa maneira, mas como é que a equipe de QA obtêm os seus branches em um namespace qa/? Você consegue fazer isso utilizando refspecs para fazer o push.
Se a equipe de QA quer fazer push de seu branch master em qa/master no servidor remoto, eles podem executar
1 $ git push origin master:refs/heads/qa/master
Se eles querem que o Git faça isso automaticamente toda vez que executar git push origin, eles podem adicionar o valor push ao seu arquivo de configuração:
[remote “origin”] url = git@github.com:schacon/simplegit-progit.git fetch = +refs/heads/:refs/remotes/origin/ push = refs/heads/master:refs/heads/qa/master
Novamente, isso vai fazer com que git push origin faça um push do branch master local para o branch remoto qa/master por padrão.
Deletando Referencias
Você também pode usar o refspec para apagar referências do servidor remoto executando algo como isto:
1 $ git push origin :topic
Já que o refspec é <src>:<dst>, ao remover <src>, basicamente diz para enviar nada para o branch tópico no remoto, o que o exclui.
9.6 Git Internamente - Protocolos de Transferência
Protocolos de Transferência
Git pode transferir dados entre dois repositórios de duas maneiras principais: através de HTTP e através dos protocolos chamados inteligentes: file://, ssh:// e git://. Esta seção irá mostrar rapidamente como esses dois principais protocolos operam.
O Protocolo Burro
HTTP é muitas vezes referido como o protocolo burro, porque não requer código Git específico do lado servidor durante o processo de transporte. O processo de fetch é uma série de solicitações GET, onde o cliente pode assumir o layout do repositório Git no servidor. Vamos ver o processo http-fetch para obter a biblioteca simplegit:
1 $ git clone http://github.com/schacon/simplegit-progit.git
A primeira coisa que este comando faz é obter o arquivo info/refs. Este arquivo é escrito pelo comando update-server-info, é por isso que você precisa ativar ele como um hook post-receive para que o transporte HTTP funcione corretamente:
1 => GET info/refs
2 ca82a6dff817ec66f44342007202690a93763949 refs/heads/master
Agora você tem uma lista de referências remotas e os SHAs. Em seguida, você verifica qual é a referência HEAD para que você saiba o que deve ser obtido (check out) quando você terminar:
1 => GET HEAD
2 ref: refs/heads/master
Você precisa fazer o check out do branch master quando você tiver concluído o processo. Neste momento, você está pronto para iniciar o processo de “caminhada”. Como o seu ponto de partida é o objeto commit ca82a6 que você viu no arquivo info/refs, você começa obtendo ele:
1 => GET objects/ca/82a6dff817ec66f44342007202690a93763949
2 (179 bytes of binary data)
Você obtêm um objeto — este objeto é um “loose format” no servidor, e você o obteu a partir de uma conexão HTTP GET estática. Você pode descompactá-lo, retirar o cabeçalho, e ver o conteúdo do commit:
1 $ git cat-file -p ca82a6dff817ec66f44342007202690a93763949
2 tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
3 parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
4 author Scott Chacon <schacon@gmail.com> 1205815931 -0700
5 committer Scott Chacon <schacon@gmail.com> 1240030591 -0700
6
7 changed the version number
A seguir, você tem mais dois objetos para obter — cfda3b, que a árvore de conteúdo do commit que acabamos de obter referencia, e 085bb3, que é o commit pai:
1 => GET objects/08/5bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
2 (179 bytes of data)
Isso lhe dá o seu próximo objeto commit. Obtenha o objeto árvore:
1 => GET objects/cf/da3bf379e4f8dba8717dee55aab78aef7f4daf
2 (404 - Not Found)
Oops — parece que esse objeto árvore não está em “loose format” no servidor, então você recebe um erro 404. Há algumas razões para isso — o objeto pode estar em um repositório alternativo, ou poderia estar em um packfile neste repositório. Git verifica a existência de quaisquer alternativas listadas primeiro:
1 => GET objects/info/http-alternates
2 (empty file)
Se isso retornar uma lista de URLs alternativas, Git verifica a existência de “loose files” e packfiles lá — este é um mecanismo legal para projetos que são forks de um outro para compartilhar objetos no disco. No entanto, como não há substitutos listados neste caso, o objeto deve estar em um packfile. Para saber quais packfiles estão disponíveis neste servidor, você precisa obter o arquivo objects/info/packs, que contém uma lista deles (também gerado pelo update-server-info):
1 => GET objects/info/packs
2 P pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
Há apenas um packfile no servidor, então o seu objeto deve estar lá, mas você vai verificar o arquivo de índice para ter certeza. Isso também é útil se você tem vários packfiles no servidor, assim você pode ver qual packfile contém o objeto que você precisa:
1 => GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.idx
2 (4k of binary data)
Agora que você tem o índice do packfile, você pode ver se o seu objeto esta nele — porque o índice lista os SHAs dos objetos contidos no packfile e os deslocamentos (offsets) desses objetos. Seu objeto está lá, então vá em frente e obtenha todo o packfile:
1 => GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
2 (13k of binary data)
Você tem o seu objeto árvore, então você continua navegando em seus commits. Eles todos estão dentro do packfile que você acabou de baixar, então você não precisa fazer mais solicitações para o servidor. Git faz o check out de uma cópia de trabalho do branch master, que foi apontada pela referência HEAD que você baixou no início.
Toda a saída deste processo é parecida com isto:
1 $ git clone http://github.com/schacon/simplegit-progit.git
2 Initialized empty Git repository in /private/tmp/simplegit-progit/.git/
3 got ca82a6dff817ec66f44342007202690a93763949
4 walk ca82a6dff817ec66f44342007202690a93763949
5 got 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
6 Getting alternates list for http://github.com/schacon/simplegit-progit.git
7 Getting pack list for http://github.com/schacon/simplegit-progit.git
8 Getting index for pack 816a9b2334da9953e530f27bcac22082a9f5b835
9 Getting pack 816a9b2334da9953e530f27bcac22082a9f5b835
10 which contains cfda3bf379e4f8dba8717dee55aab78aef7f4daf
11 walk 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
12 walk a11bef06a3f659402fe7563abf99ad00de2209e6
O Protocolo Inteligente
O método HTTP é simples, mas um pouco ineficiente. Usar protocolos inteligentes é um método mais comum de transferência de dados. Estes protocolos têm um processo no sistema remoto que é inteligente em relação ao Git — ele pode ler dados locais e descobrir o que o cliente tem ou precisa e gera dados personalizados para ele. Existem dois conjuntos de processos de transferência de dados: um par para enviar dados (upload) e um par para download de dados.
Fazendo Upload de Dados
Para fazer upload de dados para um processo remoto, Git usa os processos send-pack e receive-pack. O processo send-pack é executado no cliente e se conecta a um processo receive-pack no lado remoto.
Por exemplo, digamos que você execute git push origin master em seu projeto, e origin é definido como uma URL que usa o protocolo SSH. Git executa o processo send-pack, que inicia uma conexão SSH ao seu servidor. Ele tenta executar um comando no servidor remoto através de uma chamada SSH que é parecida com isto:
1 $ ssh -x git@github.com "git-receive-pack 'schacon/simplegit-progit.git'"
2 005bca82a6dff817ec66f4437202690a93763949 refs/heads/master report-status delete-r\
3 efs
4 003e085bb3bcb608e1e84b2432f8ecbe6306e7e7 refs/heads/topic
5 0000
O comando git-receive-pack imediatamente responde com uma linha para cada referência que tem atualmente — neste caso, apenas o branch master e seu SHA. A primeira linha também tem uma lista de recursos do servidor (aqui, report-status e delete-refs).
Cada linha se inicia com um valor hexadecimal de 4 bytes especificando quão longo o resto da linha é. Sua primeira linha começa com 005B, que é 91 em hexadecimal, o que significa que 91 bytes permanecem nessa linha. A próxima linha começa com 003e, que é 62, então você leu os 62 bytes restantes. A próxima linha é 0000, ou seja, o servidor terminou com a sua lista de referências.
Agora que ele sabe o estado do servidor, o seu processo send-pack determina que commits ele tem mas que o servidor não tem. Para cada referência que este push irá atualizar, o processo send-pack diz essa informação ao processo receive-pack. Por exemplo, se você está atualizando o branch master e está adicionando um branch experiment, a resposta do send-pack pode ser parecida com esta:
1 0085ca82a6dff817ec66f44342007202690a93763949 15027957951b64cf874c3557a0f3547bd83\
2 b3ff6 refs/heads/master report-status
3 00670000000000000000000000000000000000000000 cdfdb42577e2506715f8cfeacdbabc092bf6\
4 3e8d refs/heads/experiment
5 0000
O valor SHA-1 de todos os ‘0’s significa que nada estava lá antes — porque você está adicionando a referência de experiment. Se você estivesse apagando uma referência, você veria o oposto: tudo ‘0’ no lado direito.
Git envia uma linha para cada referência que você está atualizando com o SHA antigo, o SHA novo, e a referência que está sendo atualizada. A primeira linha também tem as capacidades do cliente. Em seguida, o cliente faz upload de um packfile com todos os objetos que o servidor não tem ainda. Finalmente, o servidor responde com uma indicação de sucesso (ou falha):
1 000Aunpack ok
Fazendo Download de Dados
Quando você baixa os dados, os processos fetch-pack e upload-pack são usados. O cliente inicia um processo fetch-pack que se conecta a um processo upload-pack no lado remoto para negociar os dados que serão transferidos para a máquina local.
Existem diferentes maneiras de iniciar o processo upload-pack no repositório remoto. Você pode fazê-lo via SSH da mesma forma que o processo receive-pack. Você também pode iniciar o processo, através do daemon Git, que escuta em um servidor na porta 9418 por padrão. O processo fetch-pack envia dados que se parecem com isso para o servidor após se conectar:
1 003fgit-upload-pack schacon/simplegit-progit.git\0host=myserver.com\0
Ele começa com os 4 bytes que especificam a quantidade de dados enviados, seguido pelo comando a ser executado, seguido por um byte nulo e, em seguida, o hostname do servidor seguido por um ultimo byte nulo. O daemon Git verifica que o comando pode ser executado e que o repositório existe e tem permissões públicas. Se tudo estiver certo, ele aciona o processo upload-pack e envia o pedido para ele.
Se você estiver fazendo o fetch através de SSH, fetch-pack executa algo como isto:
1 $ ssh -x git@github.com "git-upload-pack 'schacon/simplegit-progit.git'"
Em todo caso, depois que fetch-pack conectar, upload-pack devolve algo como isto:
1 0088ca82a6dff817ec66f44342007202690a93763949 HEAD\0multi_ack thin-pack \
2 side-band side-band-64k ofs-delta shallow no-progress include-tag
3 003fca82a6dff817ec66f44342007202690a93763949 refs/heads/master
4 003e085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 refs/heads/topic
5 0000
Isto é muito semelhante a resposta de receive-pack, mas as funcionalidades são diferentes. Além disso, ele envia de volta a referência de HEAD para que o cliente saiba o que deve ser verificado (check out) se este for um clone.
Neste momento, o processo fetch-pack verifica quais objetos ele possui e responde com os objetos de que necessita através do envio de “want” e do SHA que quer. Ele envia todos os objetos que ele já tem com “have” e também o SHA. No final da lista, ele escreve “done” para iniciar o processo upload-pack para começar a enviar o packfile dos dados que ele precisa:
1 0054want ca82a6dff817ec66f44342007202690a93763949 ofs-delta
2 0032have 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
3 0000
4 0009done
Isto é um caso muito simples dos protocolos de transferência. Em casos mais complexos, o cliente suporta funcionalidades multi_ack ou side-band; mas este exemplo mostra o funcionamento de upload e download básico utilizado pelos processos de protocolo inteligentes.
9.7 Git Internamente - Manutenção e Recuperação de Dados
Manutenção e Recuperação de Dados
Ocasionalmente, você pode ter que fazer alguma limpeza — compactar um repositório, limpar um repositório importado, ou recuperar trabalhos perdidos. Esta seção irá mostrar alguns desses cenários.
Manutenção
Ocasionalmente, Git automaticamente executa um comando chamado “auto gc”. Na maioria das vezes, este comando não faz nada. No entanto, se houverem muitos objetos soltos (loose objects) (objetos que não estejam em um packfile) ou muitos packfiles, Git executa um verdadeiro comando git gc. O gc significa garbage collect (coleta de lixo), e o comando faz uma série de coisas: ele reúne todos os objetos soltos e os coloca em packfiles, consolida packfiles em um packfile maior, e remove objetos que não estejam ao alcance de qualquer commit e tem poucos meses de idade.
Você pode executar auto gc manualmente da seguinte forma:
1 $ git gc --auto
Mais uma vez, isso geralmente não faz nada. Você deve ter cerca de 7.000 objetos soltos ou mais de 50 packfiles para que o Git execute um comando gc real. Você pode modificar esses limites com as opções de configuração gc.auto e gc.autopacklimit, respectivamente.
A outra coisa que gc irá fazer é arrumar suas referências em um único arquivo. Suponha que seu repositório contém os seguintes branches e tags:
1 $ find .git/refs -type f
2 .git/refs/heads/experiment
3 .git/refs/heads/master
4 .git/refs/tags/v1.0
5 .git/refs/tags/v1.1
Se você executar git gc, você não terá mais esses arquivos no diretório refs. Git irá movê-los para um arquivo chamado .git/packed-refs que se parece com isto:
1 $ cat .git/packed-refs
2 # pack-refs with: peeled
3 cac0cab538b970a37ea1e769cbbde608743bc96d refs/heads/experiment
4 ab1afef80fac8e34258ff41fc1b867c702daa24b refs/heads/master
5 cac0cab538b970a37ea1e769cbbde608743bc96d refs/tags/v1.0
6 9585191f37f7b0fb9444f35a9bf50de191beadc2 refs/tags/v1.1
7 ^1a410efbd13591db07496601ebc7a059dd55cfe9
Se você atualizar uma referência, Git não edita esse arquivo, mas em vez disso, escreve um novo arquivo em refs/heads. Para obter o SHA apropriado para uma dada referência, Git checa a referência no diretório refs e então verifica o arquivo packed-refs como um último recurso. No entanto, se você não conseguir encontrar uma referência no diretório refs, ela está provavelmente em seu arquivo packed-refs.
Observe a última linha do arquivo, que começa com um ^. Isto significa que a tag diretamente acima é uma tag anotada (annotated tag) e que a linha é o commit que a tag anotada aponta.
Recuperação de Dados
Em algum ponto de sua jornada Git, você pode acidentalmente perder um commit. Geralmente, isso acontece porque você forçou a remoção (force-delete) de um branch que tinha informações nele, e depois se deu conta de que precisava do branch; ou você resetou (hard-reset) um branch, abandonando commits com informações importantes. Assumindo que isso aconteceu, como você pode obter o seu commit de volta?
Aqui está um exemplo que reseta (hard-resets) o branch master no seu repositório de teste para um commit antigo e depois recupera os commits perdidos. Primeiro, vamos rever onde seu repositório está neste momento:
1 $ git log --pretty=oneline
2 ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
3 484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
4 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
5 cac0cab538b970a37ea1e769cbbde608743bc96d second commit
6 fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Agora, mova o branch master de volta para o commit do meio:
1 $ git reset --hard 1a410efbd13591db07496601ebc7a059dd55cfe9
2 HEAD is now at 1a410ef third commit
3 $ git log --pretty=oneline
4 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
5 cac0cab538b970a37ea1e769cbbde608743bc96d second commit
6 fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Você efetivamente perdeu os dois primeiros commits — você não tem um branch de onde os commits são alcançáveis. Você precisa encontrar o SHA do último commit e em seguida, adicionar um branch que aponta para ele. O truque é encontrar o SHA do commit mais recente — você não o memorizou, certo?
Muitas vezes, a maneira mais rápida é usar uma ferramenta chamada git reflog. Quando você está trabalhando, Git silenciosamente registra onde está o HEAD cada vez que você mudá-lo. Cada vez que você fizer um commit ou alterar branches, o reflog é atualizado. O reflog também é atualizado pelo comando git update-ref, o que é mais um motivo para usá-lo em vez de apenas escrever o valor SHA em seus arquivos ref, como abordado anteriormente na seção “Referências Git” deste capítulo. Você pode ver onde você está, a qualquer momento, executando git reflog:
1 $ git reflog
2 1a410ef HEAD@{0}: 1a410efbd13591db07496601ebc7a059dd55cfe9: updating HEAD
3 ab1afef HEAD@{1}: ab1afef80fac8e34258ff41fc1b867c702daa24b: updating HEAD
Aqui podemos ver os dois commits que obtemos com check out, no entanto, não há muita informação aqui. Para ver a mesma informação de uma forma muito mais útil, podemos executar git log -g, que vai lhe dar uma saída de log normal do seu reflog.
1 $ git log -g
2 commit 1a410efbd13591db07496601ebc7a059dd55cfe9
3 Reflog: HEAD@{0} (Scott Chacon <schacon@gmail.com>)
4 Reflog message: updating HEAD
5 Author: Scott Chacon <schacon@gmail.com>
6 Date: Fri May 22 18:22:37 2009 -0700
7
8 third commit
9
10 commit ab1afef80fac8e34258ff41fc1b867c702daa24b
11 Reflog: HEAD@{1} (Scott Chacon <schacon@gmail.com>)
12 Reflog message: updating HEAD
13 Author: Scott Chacon <schacon@gmail.com>
14 Date: Fri May 22 18:15:24 2009 -0700
15
16 modified repo a bit
Parece que o commit de baixo é o que você perdeu, então você pode recuperá-lo através da criação de um novo branch neste commit. Por exemplo, você pode criar um branch chamado recover-branch naquele commit (ab1afef):
1 $ git branch recover-branch ab1afef
2 $ git log --pretty=oneline recover-branch
3 ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
4 484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
5 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
6 cac0cab538b970a37ea1e769cbbde608743bc96d second commit
7 fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Agora você tem um branch chamado recover-branch que é onde o seu branch master costumava estar, fazendo os dois primeiros commits acessíveis novamente. Em seguida, suponha que a sua perda por algum motivo não está no reflog — você pode simular isso ao remover recover-branch e apagar o reflog. Agora os dois primeiros commits não são acessíveis por qualquer coisa:
1 $ git branch -D recover-branch
2 $ rm -Rf .git/logs/
Como os dados do reflog são mantidos no diretório .git/logs/, você efetivamente não têm reflog. Como você pode recuperar aquele commit agora? Uma maneira é usar o utilitário git fsck, que verifica a integridade de seu banco de dados. Se você executá-lo com a opção --full, ele mostra todos os objetos que não são apontadas por outro objeto:
1 $ git fsck --full
2 dangling blob d670460b4b4aece5915caf5c68d12f560a9fe3e4
3 dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b
4 dangling tree aea790b9a58f6cf6f2804eeac9f0abbe9631e4c9
5 dangling blob 7108f7ecb345ee9d0084193f147cdad4d2998293
Neste caso, você pode ver o seu commit desaparecido após o commit pendente (dangling). Você pode recuperá-lo da mesma forma, adicionando um branch que aponta para seu SHA.
Removendo Objetos
Há um monte de coisas boas em relação ao Git, mas um recurso que pode causar problemas é o fato de que o git clone baixa todo o histórico do projeto, incluindo todas as versões de cada arquivo. Isso é bom se a coisa toda for código fonte, porque Git é altamente otimizado para comprimir os dados de forma eficiente. No entanto, se alguém, em algum momento adicionou um arquivo enorme, todo clone será forçado a baixar o arquivo grande, mesmo que ele tenha sido retirado do projeto no commit seguinte. Como ele é acessível a partir do histórico, ele sempre estará lá.
Isso pode ser um grande problema quando você está convertendo repositórios do Subversion ou Perforce para Git. Como você não baixa todo o histórico nesses sistemas, este tipo de adição traz poucas consequências. Se você fez uma importação de outro sistema ou descobriu que seu repositório é muito maior do que deveria ser, eis aqui como você pode encontrar e remover objetos grandes.
Esteja avisado: esta técnica é destrutiva para o seu histórico de commits. Ele reescreve a cada objeto commit da primeira árvore que você tem que modificar para remover uma referência de arquivo grande. Se você fizer isso, imediatamente após uma importação, antes que alguém tenha começado usar o commit, você ficará bem — caso contrário, você tem que notificar todos os contribuidores para que eles façam um rebase do trabalho deles em seus novos commits.
Para demonstrar, você vai adicionar um arquivo grande em seu repositório, removê-lo no próximo commit, encontrá-lo e removê-lo permanentemente a partir do repositório. Primeiro, adicione um objeto grande no seu histórico:
1 $ curl http://kernel.org/pub/software/scm/git/git-1.6.3.1.tar.bz2 > git.tbz2
2 $ git add git.tbz2
3 $ git commit -am 'added git tarball'
4 [master 6df7640] added git tarball
5 1 files changed, 0 insertions(+), 0 deletions(-)
6 create mode 100644 git.tbz2
Oops - você não queria adicionar um tarball enorme no seu projeto. Melhor se livrar dele:
1 $ git rm git.tbz2
2 rm 'git.tbz2'
3 $ git commit -m 'oops - removed large tarball'
4 [master da3f30d] oops - removed large tarball
5 1 files changed, 0 insertions(+), 0 deletions(-)
6 delete mode 100644 git.tbz2
Agora, use gc no seu banco de dados e veja quanto espaço você está usando:
1 $ git gc
2 Counting objects: 21, done.
3 Delta compression using 2 threads.
4 Compressing objects: 100% (16/16), done.
5 Writing objects: 100% (21/21), done.
6 Total 21 (delta 3), reused 15 (delta 1)
Você pode executar o comando count-objects para ver rapidamente quanto espaço você está usando:
1 $ git count-objects -v
2 count: 4
3 size: 16
4 in-pack: 21
5 packs: 1
6 size-pack: 2016
7 prune-packable: 0
8 garbage: 0
A entrada size-pack é do tamanho de seus packfiles em kilobytes, então você está usando 2MB. Antes do último commit, você estava usando quase 2K — claramente, removendo o arquivo do commit anterior não remove-o de seu histórico. Toda vez que alguém clonar este repositório, eles vão ter que clonar os 2MB para obter este projeto, porque você acidentalmente acrescentou um arquivo grande. Vamos nos livrar dele.
Primeiro você tem que encontrá-lo. Neste caso, você já sabe qual é o arquivo. Mas suponha que você não saiba; como você identifica o arquivo ou arquivos que estão ocupando tanto espaço? Se você executar git gc, todos os objetos estarão em um packfile; você pode identificar os objetos grandes, executando outro comando encanamento (plumbing) chamado git verify-pack e classificar pelo terceiro campo da saída, que é o tamanho do arquivo. Você também pode direcionar a saída (pipe) através do comando tail porque você está interessado apenas nos últimos poucos arquivos maiores:
1 $ git verify-pack -v .git/objects/pack/pack-3f8c0...bb.idx | sort -k 3 -n | tail \
2 -3
3 e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4667
4 05408d195263d853f09dca71d55116663690c27c blob 12908 3478 1189
5 7a9eb2fba2b1811321254ac360970fc169ba2330 blob 2056716 2056872 5401
O objeto grande está na parte inferior: 2MB. Para saber qual é o arquivo, você vai usar o comando rev-list, que você usou brevemente no Capítulo 7. Se você passar --objects para rev-list, ele lista todos os SHAs dos commits e também os SHAs dos blob com os caminhos de arquivos (paths) associados a eles. Você pode usar isso para encontrar o nome do blob:
1 $ git rev-list --objects --all | grep 7a9eb2fb
2 7a9eb2fba2b1811321254ac360970fc169ba2330 git.tbz2
Agora, você precisa remover o arquivo de todas as árvores em que ele estiver. Você pode facilmente ver quais commits modificaram este arquivo:
1 $ git log --pretty=oneline --branches -- git.tbz2
2 da3f30d019005479c99eb4c3406225613985a1db oops - removed large tarball
3 6df764092f3e7c8f5f94cbe08ee5cf42e92a0289 added git tarball
Você deve reescrever todos os commits desde 6df76 para remover completamente este arquivo do seu histórico Git. Para fazer isso, você usa filter-branch, que você já usou no capítulo 6:
1 $ git filter-branch --index-filter \
2 'git rm --cached --ignore-unmatch git.tbz2' -- 6df7640^..
3 Rewrite 6df764092f3e7c8f5f94cbe08ee5cf42e92a0289 (1/2)rm 'git.tbz2'
4 Rewrite da3f30d019005479c99eb4c3406225613985a1db (2/2)
5 Ref 'refs/heads/master' was rewritten
A opção --index-filter é semelhante a opção --tree-filter utilizada no Capítulo 6, exceto que em vez de passar um comando que modifica os arquivos que você fez check-out no disco, você está modificando sua área de seleção (staging area) ou índice. Em vez de remover um arquivo específico com algo como rm file, você tem que removê-lo com git rm --cached — você deve removê-lo do índice, não do disco. A razão para fazê-lo desta maneira é a velocidade — porque o Git não precisa fazer o check out de cada revisão no disco antes de executar o seu filtro, o processo pode ser muito mais rápido. Você pode realizar a mesma tarefa com --tree-filter se você quiser. A opção --ignore-unmatch do git rm diz a ele para não mostrar erros se o padrão que você está tentando remover não estiver lá. Finalmente, você pede a filter-branch para reescrever seu histórico apenas a partir do commit 6df7640, porque você sabe que é onde o problema começou. Caso contrário, ele vai começar desde o início e vai demorar mais tempo desnecessariamente.
Seu histórico já não contém uma referência para o arquivo. No entanto, seu reflog e um novo conjunto de refs que o git adicionou quando você fez o filter-branch em .git/refs/original ainda não, então você tem que removê-los e, em seguida, fazer um repack do banco de dados. Você precisa se livrar de qualquer coisa que tenha um ponteiro para aqueles commits antigos antes de fazer o repack:
1 $ rm -Rf .git/refs/original
2 $ rm -Rf .git/logs/
3 $ git gc
4 Counting objects: 19, done.
5 Delta compression using 2 threads.
6 Compressing objects: 100% (14/14), done.
7 Writing objects: 100% (19/19), done.
8 Total 19 (delta 3), reused 16 (delta 1)
Vamos ver quanto espaço você economizou.
1 $ git count-objects -v
2 count: 8
3 size: 2040
4 in-pack: 19
5 packs: 1
6 size-pack: 7
7 prune-packable: 0
8 garbage: 0
O tamanho do repositório compactado reduziu para 7K, que é muito melhor do que 2MB. Pelo tamanho você pode ver que o grande objeto ainda está em seus objetos soltos, portanto não foi eliminado; mas ele não será transferido em um clone ou push posterior, e isso é o que importa. Se você realmente quiser, você pode remover o objeto completamente executando git prune --expire.
9.8 Git Internamente - Resumo
Resumo
Você deve ter uma compreensão muito boa do que Git faz de verdade e, até certo ponto, como ele é implementado. Este capítulo mostrou uma série de comandos de encanamento (plumbing) — comandos que são de nível inferior e mais simples do que os comandos de porcelana (porcelain) que você aprendeu no resto do livro. Compreender como Git funciona em um nível inferior deve torná-lo mais fácil de entender porque ele está fazendo o que está fazendo e também para escrever suas próprias ferramentas e scripts para criar seu próprio fluxo de trabalho.
Git como um sistema de arquivos de conteúdo endereçável é uma ferramenta muito poderosa que você pode usar facilmente como mais do que apenas um VCS. Eu espero que você possa usar seu novo conhecimento do Git para implementar a sua própria aplicação a partir desta tecnologia e se sentir mais confortável usando Git de formas mais avançadas.