Capítulo 3. Ramificação (Branching) no Git
Quase todos os VCS têm alguma forma de suporte a ramificação (branching). Criar um branch significa dizer que você vai divergir da linha principal de desenvolvimento e continuar a trabalhar sem bagunçar essa linha principal. Em muitas ferramentas VCS, este é um processo um pouco caro, muitas vezes exigindo que você crie uma nova cópia do seu diretório de código-fonte, o que pode levar um longo tempo para grandes projetos.
Algumas pessoas se referem ao modelo de ramificação em Git como sua característica “matadora”, e que certamente o destaca na comunidade de VCS. Por que ele é tão especial? A forma como o Git cria branches é inacreditavelmente leve, fazendo com que as operações com branches sejam praticamente instantâneas e a alternância entre os branches seja tão rápida quanto. Ao contrário de muitos outros VCSs, o Git incentiva um fluxo de trabalho no qual se fazem branches e merges com frequência, até mesmo várias vezes ao dia. Compreender e dominar esta característica lhe dará uma ferramenta poderosa e única e poderá literalmente mudar a maneira de como você desenvolve.
3.1 Ramificação (Branching) no Git - O que é um Branch
O que é um Branch
Para compreender realmente a forma como o Git cria branches, precisamos dar um passo atrás e examinar como o Git armazena seus dados. Como você pode se lembrar do capítulo 1, o Git não armazena dados como uma série de mudanças ou deltas, mas sim como uma série de snapshots.
Quando você faz um commit no Git, o Git guarda um objeto commit que contém um ponteiro para o snapshot do conteúdo que você colocou na área de seleção, o autor e os metadados da mensagem, zero ou mais ponteiros para o commit ou commits que são pais deste commit: nenhum pai para o commit inicial, um pai para um commit normal e múltiplos pais para commits que resultem de um merge de dois ou mais branches.
Para visualizar isso, vamos supor que você tenha um diretório contendo três arquivos, e colocou todos eles na área de seleção e fez o commit. Colocar na área de seleção cria o checksum de cada arquivo (o hash SHA-1 que nos referimos no capítulo 1), armazena esta versão do arquivo no repositório Git (o Git se refere a eles como blobs), e acrescenta este checksum à área de seleção (staging area):
1 $ git add README test.rb LICENSE
2 $ git commit -m 'commit inicial do meu projeto'
Quando você cria um commit executando git commit, o Git calcula o checksum de cada subdiretório (neste caso, apenas o diretório raiz do projeto) e armazena os objetos de árvore no repositório Git. O Git em seguida, cria um objeto commit que tem os metadados e um ponteiro para a árvore do projeto raiz, então ele pode recriar este snapshot quando necessário.
Seu repositório Git agora contém cinco objetos: um blob para o conteúdo de cada um dos três arquivos, uma árvore que lista o conteúdo do diretório e especifica quais nomes de arquivos são armazenados em quais blobs, e um commit com o ponteiro para a raiz dessa árvore com todos os metadados do commit. Conceitualmente, os dados em seu repositório Git se parecem como na Figura 3-1.
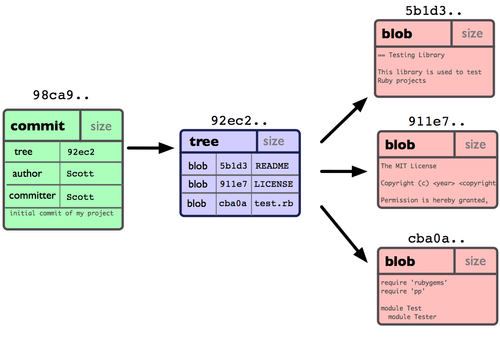
Figura 3-1. Dados de um repositório com um único commit.
Um branch no Git é simplesmente um leve ponteiro móvel para um desses commits. O nome do branch padrão no Git é master. Como você inicialmente fez commits, você tem um branch principal (master branch) que aponta para o último commit que você fez. Cada vez que você faz um commit ele avança automaticamente.
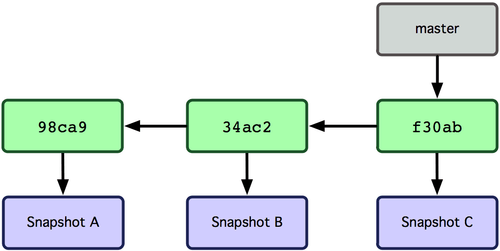
Figura 3-3. Branch apontando para o histórico de commits.
O que acontece se você criar um novo branch? Bem, isso cria um novo ponteiro para que você possa se mover. Vamos dizer que você crie um novo branch chamado testing. Você faz isso com o comando git branch:
1 $ git branch testing
Isso cria um novo ponteiro para o mesmo commit em que você está no momento (ver a Figura 3-4).
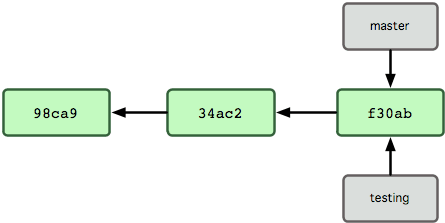
Figura 3-4. Múltiplos branches apontando para o histórico de commits.
Como o Git sabe o branch em que você está atualmente? Ele mantém um ponteiro especial chamado HEAD. Observe que isso é muito diferente do conceito de HEAD em outros VCSs que você possa ter usado, como Subversion e CVS. No Git, este é um ponteiro para o branch local em que você está no momento. Neste caso, você ainda está no master. O comando git branch só criou um novo branch — ele não mudou para esse branch (veja Figura 3-5).
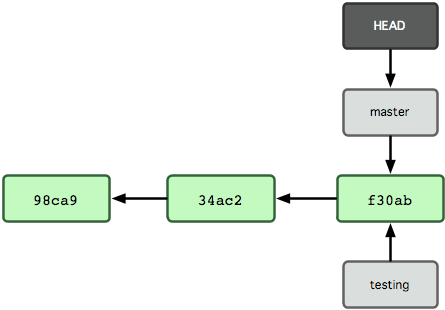
Figura 3-5. HEAD apontando para o branch em que você está.
Para mudar para um branch existente, você executa o comando git checkout. Vamos mudar para o novo branch testing:
1 $ git checkout testing
Isto move o HEAD para apontar para o branch de testes (ver Figura 3-6).
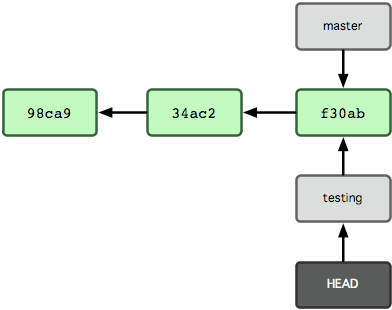
Figura 3-6. O HEAD aponta para outro branch quando você troca de branches.
Qual é o significado disso? Bem, vamos fazer um outro commit:
1 $ vim test.rb
2 $ git commit -a -m 'fiz uma alteração'
A figura 3-7 ilustra o resultado.
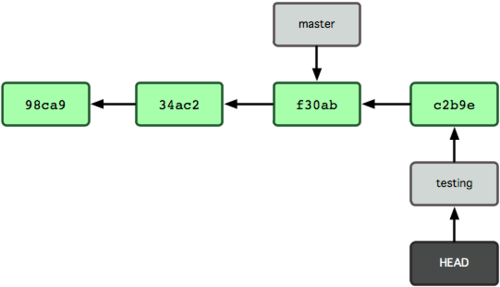
Figura 3-7. O branch para o qual HEAD aponta avança com cada commit.
Isso é interessante, porque agora o seu branch testing avançou, mas o seu branch master ainda aponta para o commit em que estava quando você executou git checkout para trocar de branch. Vamos voltar para o branch master:
1 $ git checkout master
A figura 3-8 mostra o resultado.
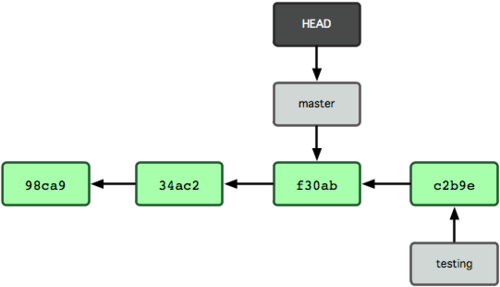
Figura 3-8. O HEAD se move para outro branch com um checkout.
Esse comando fez duas coisas. Ele alterou o ponteiro HEAD para apontar novamente para o branch master, e reverteu os arquivos em seu diretório de trabalho para o estado em que estavam no snapshot para o qual o master apontava. Isto significa também que as mudanças feitas a partir deste ponto em diante, irão divergir de uma versão anterior do projeto. Ele essencialmente “volta” o trabalho que você fez no seu branch testing, temporariamente, de modo que você possa ir em uma direção diferente.
Vamos fazer algumas mudanças e fazer o commit novamente:
1 $ vim test.rb
2 $ git commit -a -m 'fiz outra alteração'
Agora o histórico do seu projeto divergiu (ver Figura 3-9). Você criou e trocou para um branch, trabalhou nele, e então voltou para o seu branch principal e trabalhou mais. Ambas as mudanças são isoladas em branches distintos: você pode alternar entre os branches e fundi-los (merge) quando estiver pronto. E você fez tudo isso simplesmente com os comandos branch e checkout.
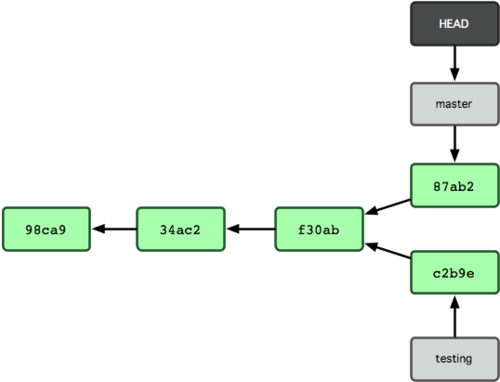
igura 3-9. O histórico dos branches diverge.
Como um branch em Git é na verdade um arquivo simples que contém os 40 caracteres do checksum SHA-1 do commit para o qual ele aponta, os branches são baratos para criar e destruir. Criar um novo branch é tão rápido e simples como escrever 41 bytes em um arquivo (40 caracteres e uma quebra de linha).
Isto está em nítido contraste com a forma com a qual a maioria das ferramentas VCS gerenciam branches, que envolve a cópia de todos os arquivos do projeto para um segundo diretório. Isso pode demorar vários segundos ou até minutos, dependendo do tamanho do projeto, enquanto que no Git o processo é sempre instantâneo. Também, porque nós estamos gravando os pais dos objetos quando fazemos commits, encontrar uma boa base para fazer o merge é uma tarefa feita automaticamente para nós e geralmente é muito fácil de fazer. Esses recursos ajudam a estimular os desenvolvedores a criar e utilizar branches com frequência.
Vamos ver por que você deve fazê-lo.
3.2 Ramificação (Branching) no Git - Básico de Branch e Merge
Básico de Branch e Merge
Vamos ver um exemplo simples de uso de branch e merge com um fluxo de trabalho que você pode usar no mundo real. Você seguirá esses passos:
- Trabalhar em um web site.
- Criar um branch para uma nova história em que está trabalhando.
- Trabalhar nesse branch.
Nesse etapa, você receberá um telefonema informando que outro problema crítico existe e precisa de correção. Você fará o seguinte:
- Voltar ao seu branch de produção.
- Criar um branch para adicionar a correção.
- Depois de testado, fazer o merge do branch da correção, e enviar para produção.
- Retornar à sua história anterior e continuar trabalhando.
Branch Básico
Primeiro, digamos que você esteja trabalhando no seu projeto e já tem alguns commits (veja Figura 3-10).
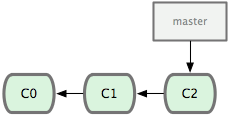
Figura 3-10. Um histórico de commits pequeno e simples.
Você decidiu que irá trabalhar na tarefa (issue) #53 do gerenciador de bugs ou tarefas que sua empresa usa. Para deixar claro, Git não é amarrado a nenhum gerenciador de tarefas em particular; mas já que a tarefa #53 tem um foco diferente, você criará um branch novo para trabalhar nele. Para criar um branch e mudar para ele ao mesmo tempo, você pode executar o comando git checkout com a opção -b:
1 $ git checkout -b iss53
2 Switched to a new branch "iss53"
Isso é um atalho para:
1 $ git branch iss53
2 $ git checkout iss53
Figura 3-11 ilustra o resultado.
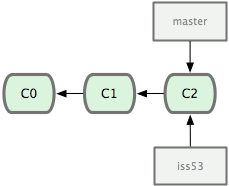
Figura 3-11. Criando um branch novo
Você trabalha no seu web site e faz alguns commits. Ao fazer isso o branch iss53 avançará, pois você fez o checkout dele (isto é, seu HEAD está apontando para ele; veja a Figura 3-12):
1 $ vim index.html
2 $ git commit -a -m 'adicionei um novo rodapé [issue 53]'
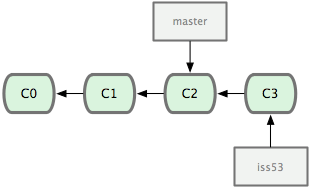
Figura 3-12. O branch iss53 avançou com suas modificações.
Nesse momento você recebe uma ligação dizendo que existe um problema com o web site e você deve resolvê-lo imediatamente. Com Git, você não precisa fazer o deploy de sua correção junto com as modificações que você fez no iss53, e você não precisa se esforçar muito para reverter essas modificações antes que você possa aplicar sua correção em produção. Tudo que você tem a fazer é voltar ao seu branch master.
No entanto, antes de fazer isso, note que seu diretório de trabalho ou área de seleção tem modificações que não entraram em commits e que estão gerando conflitos com o branch que você está fazendo o checkout, Git não deixará você mudar de branch. É melhor ter uma área de trabalho limpa quando mudar de branch. Existem maneiras de contornar esta situação (isto é, incluir e fazer o commit) que vamos falar depois. Por enquanto, você fez o commit de todas as suas modificações, então você pode mudar para o seu branch master:
1 $ git checkout master
2 Switched to branch "master"
Nesse ponto, o diretório do seu projeto está exatamente do jeito que estava antes de você começar a trabalhar na tarefa #53, e você se concentra na correção do erro. É importante lembrar desse ponto: Git restabelece seu diretório de trabalho para ficar igual ao snapshot do commit que o branch que você criou aponta. Ele adiciona, remove, e modifica arquivos automaticamente para garantir que sua cópia é o que o branch parecia no seu último commit nele.
Em seguida, você tem uma correção para fazer. Vamos criar um branch para a correção (hotfix) para trabalhar até a conclusão (veja Figura 3-13):
1 $ git checkout -b 'hotfix'
2 Switched to a new branch "hotfix"
3 $ vim index.html
4 $ git commit -a -m 'concertei o endereço de email'
5 [hotfix]: created 3a0874c: "concertei o endereço de email"
6 1 files changed, 0 insertions(+), 1 deletions(-)
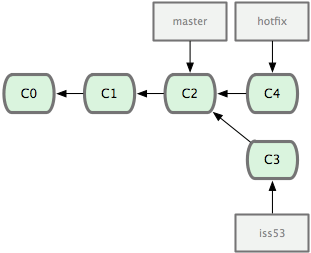
Figura 3-13. branch de correção (hotfix) baseado num ponto de seu branch master.
Você pode rodar seus testes, tenha certeza que a correção é o que você quer, e faça o merge no seu branch master para fazer o deploy em produção. Você faz isso com o comando git merge:
1 $ git checkout master
2 $ git merge hotfix
3 Updating f42c576..3a0874c
4 Fast forward
5 README | 1 -
6 1 files changed, 0 insertions(+), 1 deletions(-)
Você irá notar a frase “Fast forward” no merge. Em razão do branch que você fez o merge apontar para o commit que está diretamente acima do commit que você se encontra, Git avança o ponteiro adiante. Em outras palavras, quando você tenta fazer o merge de um commit com outro que pode ser alcançado seguindo o histórico do primeiro, Git simplifica as coisas movendo o ponteiro adiante porque não existe modificações divergente para fazer o merge — isso é chamado de “fast forward”.
Sua modificação está agora no snapshot do commit apontado pelo branch master, e você pode fazer o deploy (veja Figura 3-14).
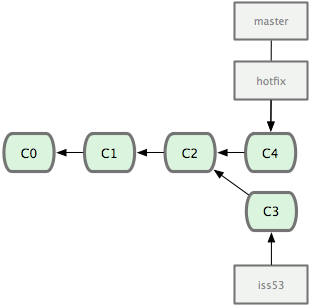
Figura 3-14. Depois do merge seu branch master aponta para o mesmo local que o branch hotfix.
Depois que a sua correção super importante foi enviada, você está pronto para voltar ao trabalho que estava fazendo antes de ser interrompido. No entanto, primeiro você apagará o branch hotfix, pois você não precisa mais dele — o branch master aponta para o mesmo local. Você pode excluí-lo com a opção -d em git branch:
1 $ git branch -d hotfix
2 Deleted branch hotfix (3a0874c).
Agora você pode voltar para o trabalho incompleto no branch da tafera #53 e continuar a trabalhar nele (veja Figura 3-15):
1 $ git checkout iss53
2 Switched to branch "iss53"
3 $ vim index.html
4 $ git commit -a -m 'novo rodapé terminado [issue 53]'
5 [iss53]: created ad82d7a: "novo rodapé terminado [issue 53]"
6 1 files changed, 1 insertions(+), 0 deletions(-)
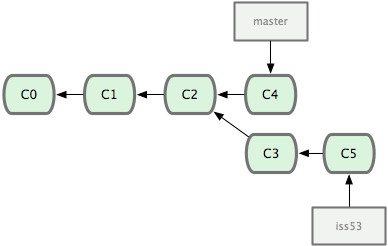
Figura 3-15. Seu branch iss53 pode avançar de forma independente.
Vale a pena lembrar aqui que o trabalho feito no seu branch hotfix não existe nos arquivos do seu branch iss53. Se você precisa incluí-lo, você pode fazer o merge do seu branch master no seu branch iss53 executando o comando git merge master, ou você pode esperar para integrar essas mudanças até você decidir fazer o pull do branch iss53 no master mais tarde.
Merge Básico
Suponha que você decidiu que o trabalho na tarefa #53 está completo e pronto para ser feito o merge no branch master. Para fazer isso, você fará o merge do seu branch iss53, bem como o merge do branch hotfix de antes. Tudo que você tem a fazer é executar o checkout do branch para onde deseja fazer o merge e então rodar o comando git merge:
1 $ git checkout master
2 $ git merge iss53
3 Merge made by recursive.
4 README | 1 +
5 1 files changed, 1 insertions(+), 0 deletions(-)
Isso parece um pouco diferente do merge de hotfix que você fez antes. Neste caso, o histórico do seu desenvolvimento divergiu em algum ponto anterior. Pelo fato do commit no branch em que você está não ser um ancestral direto do branch que você está fazendo o merge, Git tem um trabalho adicional. Neste caso, Git faz um merge simples de três vias, usando os dois snapshots apontados pelas pontas dos branches e o ancestral comum dos dois. A Figura 3-16 destaca os três snapshots que Git usa para fazer o merge nesse caso.
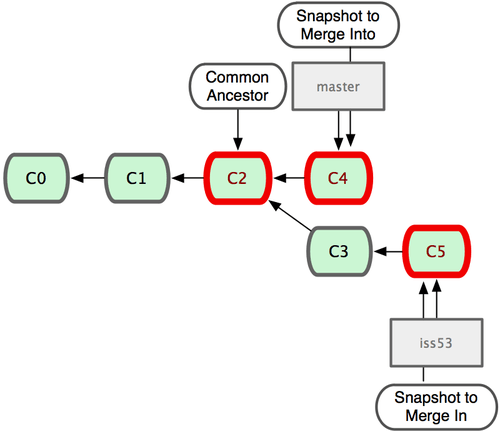
Figura 3-16. Git identifica automaticamente a melhor base ancestral comum para o merge do branch.
Em vez de simplesmente avançar o ponteiro do branch adiante, Git cria um novo snapshot que resulta do merge de três vias e automaticamente cria um novo commit que aponta para ele (veja Figura 3-17). Isso é conhecido como um merge de commits e é especial pois tem mais de um pai.
Vale a pena destacar que o Git determina o melhor ancestral comum para usar como base para o merge; isso é diferente no CVS ou Subversion (antes da versão 1.5), onde o desenvolvedor que está fazendo o merge tem que descobrir a melhor base para o merge por si próprio. Isso faz o merge muito mais fácil no Git do que nesses outros sistemas.
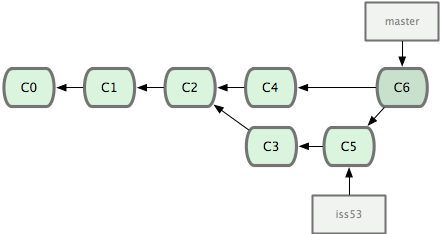
Figura 3-17. Git cria automaticamente um novo objeto commit que contém as modificações do merge.
Agora que foi feito o merge no seu trabalho, você não precisa mais do branch iss53. Você pode apagá-lo e fechar manualmente o chamado no seu gerenciador de chamados:
1 $ git branch -d iss53
Conflitos de Merge Básico
Às vezes, esse processo não funciona sem problemas. Se você alterou a mesma parte do mesmo arquivo de forma diferente nos dois branches que está fazendo o merge, Git não será capaz de executar o merge de forma clara. Se sua correção para o erro #53 alterou a mesma parte de um arquivo que hotfix, você terá um conflito de merge parecido com isso:
1 $ git merge iss53
2 Auto-merging index.html
3 CONFLICT (content): Merge conflict in index.html
4 Automatic merge failed; fix conflicts and then commit the result.
Git não criou automaticamente um novo commit para o merge. Ele fez uma pausa no processo enquanto você resolve o conflito. Se você quer ver em quais arquivos não foi feito o merge, em qualquer momento depois do conflito, você pode executar git status:
1 [master*]$ git status
2 index.html: needs merge
3 # On branch master
4 # Changes not staged for commit:
5 # (use "git add <file>..." to update what will be committed)
6 # (use "git checkout -- <file>..." to discard changes in working directory)
7 #
8 # unmerged: index.html
9 #
Qualquer coisa que tem conflito no merge e não foi resolvido é listado como “unmerged”. Git adiciona marcadores padrão de resolução de conflitos nos arquivos que têm conflitos, para que você possa abri-los manualmente e resolver esses conflitos. Seu arquivo terá uma seção parecida com isso:
1 <<<<<<< HEAD:index.html
2 <div id="footer">contato : email.support@github.com</div>
3 =======
4 <div id="footer">
5 por favor nos contate em support@github.com
6 </div>
7 >>>>>>> iss53:index.html
Isso significa que a versão em HEAD (seu branch master, pois era isso que você tinha quando executou o comando merge) é a parte superior desse bloco (tudo acima de =======), enquanto a versão no seu branch iss53 é toda a parte inferior. Para resolver esse conflito, você tem que optar entre um lado ou outro, ou fazer o merge do conteúdo você mesmo. Por exemplo, você pode resolver esse conflito através da substituição do bloco inteiro por isso:
1 <div id="footer">
2 por favor nos contate em email.support@github.com
3 </div>
Esta solução tem um pouco de cada seção, e eu removi completamente as linhas <<<<<<<, =======, e >>>>>>>. Depois que você resolveu cada uma dessas seções em cada arquivo com conflito, rode git add em cada arquivo para marcá-lo como resolvido. Colocar o arquivo na área de seleção o marcar como resolvido no Git. Se você quer usar uma ferramenta gráfica para resolver esses problemas, você pode executar git mergetool, que abre uma ferramenta visual de merge adequada e percorre os conflitos:
1 $ git mergetool
2 merge tool candidates: kdiff3 tkdiff xxdiff meld gvimdiff opendiff emerge vimdiff
3 Merging the files: index.html
4
5 Normal merge conflict for 'index.html':
6 {local}: modified
7 {remote}: modified
8 Hit return to start merge resolution tool (opendiff):
Se você quer usar uma ferramenta de merge diferente da padrão (Git escolheu opendiff para mim, neste caso, porque eu rodei o comando em um Mac), você pode ver todas as ferramentas disponíveis listadas no topo depois de “merge tool candidates”. Digite o nome da ferramenta que você prefere usar. No capítulo 7, discutiremos como você pode alterar esse valor para o seu ambiente.
Depois de sair da ferramenta de merge, Git pergunta se o merge foi concluído com sucesso. Se você disser ao script que foi, ele coloca o arquivo na área de seleção para marcá-lo como resolvido pra você.
Se você rodar git status novamente para verificar que todos os conflitos foram resolvidos:
1 $ git status
2 # On branch master
3 # Changes to be committed:
4 # (use "git reset HEAD <file>..." to unstage)
5 #
6 # modified: index.html
7 #
Se você está satisfeito com isso, e verificou que tudo que havia conflito foi colocado na área de seleção, você pode digitar git commit para concluir o commit do merge. A mensagem de commit padrão é algo semelhante a isso:
1 Merge branch 'iss53'
2
3 Conflicts:
4 index.html
5 #
6 # It looks like you may be committing a MERGE.
7 # If this is not correct, please remove the file
8 # .git/MERGE_HEAD
9 # and try again.
10 #
Você pode modificar essa mensagem com detalhes sobre como você resolveu o merge se você acha que isso seria útil para outros quando olharem esse merge no futuro — por que você fez o que fez, se não é óbvio.
3.3 Ramificação (Branching) no Git - Gerenciamento de Branches
Gerenciamento de Branches
Agora que você criou, fez merge e apagou alguns branches, vamos ver algumas ferramentas de gerenciamento de branches que serão úteis quando você começar a usá-los o tempo todo.
O comando git branch faz mais do que criar e apagar branches. Se você executá-lo sem argumentos, você verá uma lista simples dos seus branches atuais:
1 $ git branch
2 iss53
3 * master
4 testing
Note o caractere * que vem antes do branch master: ele indica o branch que você está atualmente (fez o checkout). Isso significa que se você fizer um commit nesse momento, o branch master irá se mover adiante com seu novo trabalho. Para ver o último commit em cada branch, você pode executar o comando git branch -v:
1 $ git branch -v
2 iss53 93b412c concertar problema em javascript
3 * master 7a98805 Merge branch 'iss53'
4 testing 782fd34 adicionar scott para a lista de autores nos readmes
Outra opção útil para saber em que estado estão seus branches é filtrar na lista somente branches que você já fez ou não o merge no branch que você está atualmente. As opções --merged e --no-merged estão disponíveis no Git desde a versão 1.5.6 para esse propósito. Para ver quais branches já foram mesclados no branch que você está, você pode executar git branch --merged:
1 $ git branch --merged
2 iss53
3 * master
Por você já ter feito o merge do branch iss53 antes, você o verá na sua lista. Os branches nesta lista sem o * na frente em geral podem ser apagados com git branch -d; você já incorporou o trabalho que existia neles em outro branch, sendo assim você não perderá nada.
Para ver todos os branches que contém trabalho que você ainda não fez o merge, você pode executar git branch --no-merged:
1 $ git branch --no-merged
2 testing
Isso mostra seu outro branch. Por ele conter trabalho que ainda não foi feito o merge, tentar apagá-lo com git branch -d irá falhar:
1 $ git branch -d testing
2 error: The branch 'testing' is not an ancestor of your current HEAD.
3 If you are sure you want to delete it, run `git branch -D testing`.
Se você quer realmente apagar o branch e perder o trabalho que existe nele, você pode forçar com -D, como a útil mensagem aponta.
3.4 Ramificação (Branching) no Git - Fluxos de Trabalho com Branches
Fluxos de Trabalho com Branches
Agora que você sabe o básico sobre criação e merge de branches, o que você pode ou deve fazer com eles? Nessa seção, nós vamos abordar alguns fluxos de trabalhos comuns que esse tipo de criação fácil de branches torna possível, então você pode decidir se você quer incorporá-lo no seu próprio ciclo de desenvolvimento.
Branches de Longa Duração Devido ao Git usar um merge de três vias, fazer o merge de um branch em outro várias vezes em um período longo é geralmente fácil de fazer. Isto significa que você pode ter vários branches que ficam sempre abertos e que são usados em diferentes estágios do seu ciclo de desenvolvimento; você pode regularmente fazer o merge de alguns deles em outros.
Muitos desenvolvedores Git tem um fluxo de trabalho que adotam essa abordagem, como ter somente código completamente estável em seus branches master — possivelmente somente código que já foi ou será liberado. Eles têm outro branch paralelo chamado develop ou algo parecido em que eles trabalham ou usam para testar estabilidade — ele não é necessariamente sempre estável, mas quando ele chega a tal estágio, pode ser feito o merge com o branch master. Ele é usado para puxar (pull) branches tópicos (topic, branches de curta duração, como o seu branch iss53 anteriormente) quando eles estão prontos, para ter certeza que eles passam em todos os testes e não acrescentam erros.
Na realidade, nós estamos falando de ponteiros avançando na linha de commits que você está fazendo. Os branches estáveis estão muito atrás na linha histórica de commits, e os branches de ponta (que estão sendo trabalhados) estão a frente no histórico.
Normalmente é mais fácil pensar neles como um contêiner de trabalho, onde conjuntos de commits são promovidos a um contêiner mais estável quando eles são completamente testados (veja figura 3-19).
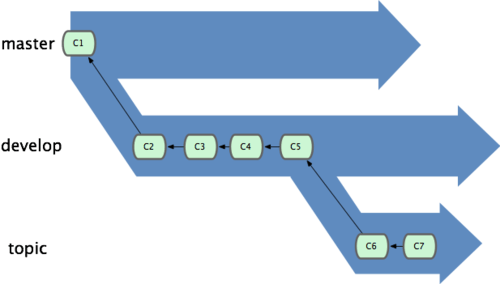
Figura 3-19. Pode ser mais útil pensar em seus branches como contêineres.
Você pode continuar fazendo isso em vários níveis de estabilidade. Alguns projetos grandes podem ter um branch ‘sugerido’ (proposed) ou ‘sugestões atualizadas’ (pu, proposed updates) que contém outros branches integrados que podem não estar prontos para ir para o próximo (next) ou branch master. A ideia é que seus branches estejam em vários níveis de estabilidade; quando eles atingem um nível mais estável, é feito o merge no branch acima deles. Repetindo, ter muitos branches de longa duração não é necessário, mas geralmente é útil, especialmente quando você está lidando com projetos muito grandes ou complexos.
Branches Tópicos (topic)
Branches tópicos, entretanto, são úteis em projetos de qualquer tamanho. Um branch tópico é um branch de curta duração que você cria e usa para uma funcionalidade ou trabalho relacionado. Isso é algo que você provavelmente nunca fez com um controle de versão antes porque é geralmente muito custoso criar e fazer merge de branches. Mas no Git é comum criar, trabalhar, mesclar e apagar branches muitas vezes ao dia.
Você viu isso na seção anterior com os branches iss53 e hotfix que você criou. Você fez commits neles e os apagou depois que fez o merge com seu branch principal. Tecnicamente, isso lhe permite mudar completamente e rapidamente o contexto — em razão de seu trabalho estar separado em contêineres onde todas as modificações naquele branch estarem relacionadas ao tópico, é fácil ver o que aconteceu durante a revisão de código. Você pode manter as mudanças lá por minutos, dias, ou meses, e mesclá-las quando estivem prontas, não importando a ordem que foram criadas ou trabalhadas.
Considere um exemplo onde você está fazendo um trabalho (no master), cria um branch para um erro (iss91), trabalha nele um pouco, cria um segundo branch para testar uma nova maneira de resolver o mesmo problema (iss91v2), volta ao seu branch principal e trabalha nele por um tempo, e cria um novo branch para trabalhar em algo que você não tem certeza se é uma boa ideia (dumbidea). Seu histórico de commits irá se parecer com a Figura 3-20.
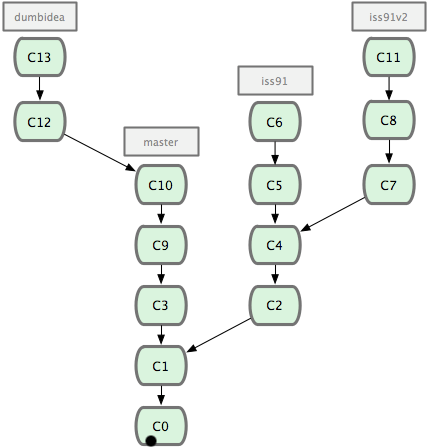
Figura 3-20. Seu histórico de commits com multiplos branches tópicos.
Agora, vamos dizer que você decidiu que sua segunda solução é a melhor para resolver o erro (iss91v2); e você mostrou seu branch dumbidea para seus colegas de trabalho, e ele é genial. Agora você pode jogar fora o branch original iss91 (perdendo os commits C5 e C6) e fazer o merge dos dois restantes. Seu histórico irá se parecer com a Figura 3-21.
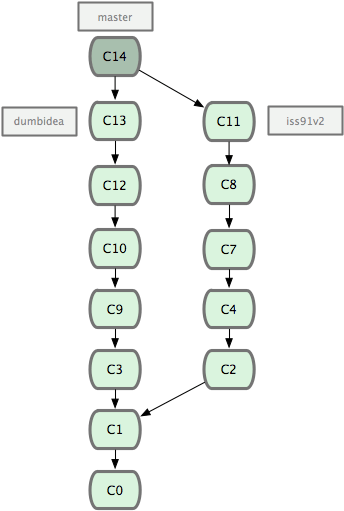
Figura 3-21. Seu histórico depois de fazer o merge de dumbidea e iss91v2.
É importante lembrar que você esta fazendo tudo isso com seus branches localmente. Quando você cria e faz o merge de branches, tudo está sendo feito somente no seu repositório Git — nenhuma comunicação com o servidor esta sendo feita.
3.5 Ramificação (Branching) no Git - Branches Remotos
Branches Remotos
Branches remotos são referências ao estado de seus branches no seu repositório remoto. São branches locais que você não pode mover, eles se movem automaticamente sempre que você faz alguma comunicação via rede. Branches remotos agem como marcadores para lembrá-lo onde estavam seus branches no seu repositório remoto na última vez que você se conectou a eles.
Eles seguem o padrão (remote)/(branch). Por exemplo, se você quer ver como o branch master estava no seu repositório remoto origin na última vez que você se comunicou com ele, você deve ver o branch origin/master. Se você estivesse trabalhando em um problema com um colega e eles colocassem o branch iss53 no repositório, você poderia ter seu próprio branch iss53; mas o branch no servidor iria fazer referência ao commit em origin/iss53.
Isso pode parecer um pouco confuso, então vamos ver um exemplo. Digamos que você tem um servidor Git na sua rede em git.ourcompany.com. Se você cloná-lo, Git automaticamente dá o nome origin para ele, baixa todo o seu conteúdo, cria uma referência para onde o branch master dele está, e dá o nome origin/master para ele localmente; e você não pode movê-lo. O Git também dá seu próprio branch master como ponto de partida no mesmo local onde o branch master remoto está, a partir de onde você pode trabalhar (veja Figura 3-22).
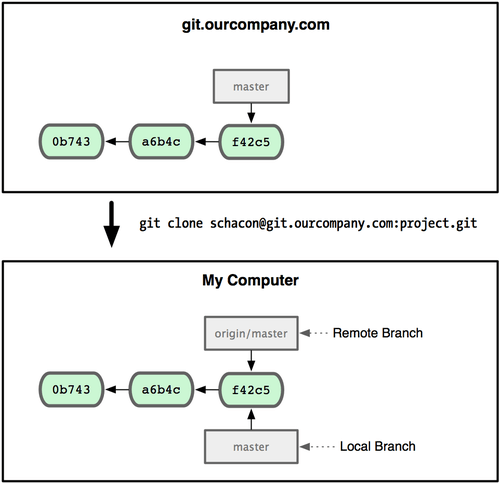
Figura 3-22. Um comando clone do Git dá a você seu próprio branch master e origin/master faz referência ao branch master original.
Se você estiver trabalhando no seu branch master local, e, ao mesmo tempo, alguém envia algo para git.ourcompany.com atualizando o branch master, seu histórico avançará de forma diferente. Além disso, enquanto você não fizer contado com seu servidor original, seu origin/master não se moverá (veja Figura 3-23).
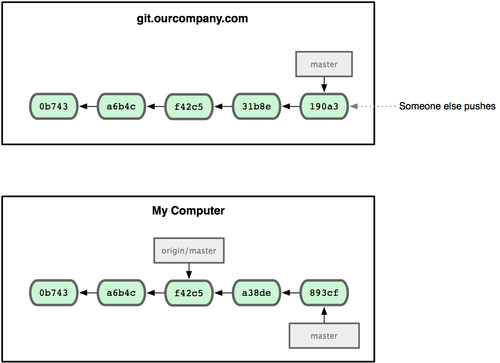
Figura 3-23. Ao trabalhar local e alguém enviar coisas para seu servidor remoto faz cada histórico avançar de forma diferente.
Para sincronizar suas coisas, você executa o comando git fetch origin. Esse comando verifica qual servidor “origin” representa (nesse caso, é git.ourcompany.com), obtém todos os dados que você ainda não tem e atualiza o seu banco de dados local, movendo o seu origin/master para a posição mais recente e atualizada (veja Figura 3-24).
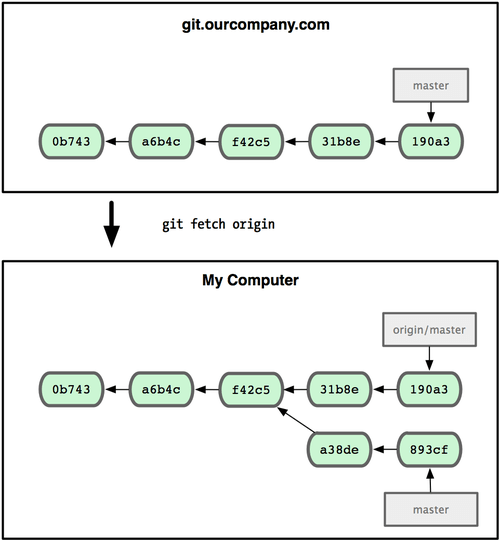
Figura 3-24. O comando git fetch atualiza suas referências remotas.
Para demostrar o uso de múltiplos servidores remotos e como os branches remotos desses projetos remotos parecem, vamos assumir que você tem outro servidor Git interno que é usado somente para desenvolvimento por um de seus times. Este servidor está em git.team1.ourcompany.com. Você pode adicioná-lo como uma nova referência remota ao projeto que você está atualmente trabalhando executando o comando git remote add como discutimos no capítulo 2. Dê o nome de teamone, que será o apelido para aquela URL (veja Figura 3-25).
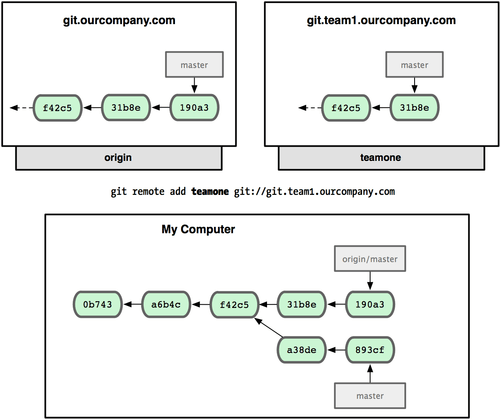
Figura 3-25. Adicionando outro servidor remoto.
Agora, você pode executar o comando git fetch teamone para obter tudo que o servidor teamone tem e você ainda não. Por esse servidor ter um subconjunto dos dados que seu servidor origin tem, Git não obtém nenhum dado, somente cria um branch chamado teamone/master que faz referência ao commit que teamone tem no master dele (veja Figura 3-26).
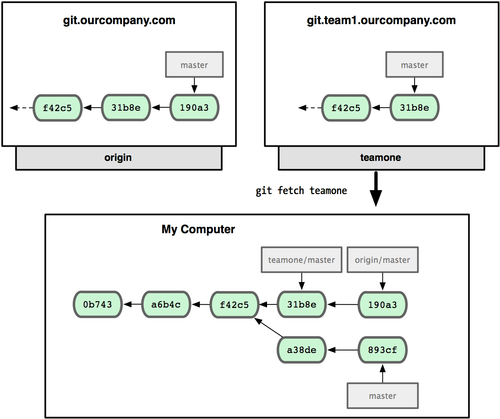
Figura 3-26. Você consegue uma referência local para a posição do branch master do teamone.
Enviando (Pushing)
Quando você quer compartilhar um branch com o mundo, você precisa enviá-lo a um servidor remoto que você tem acesso. Seus branches locais não são automaticamente sincronizados com os remotos — você tem que explicitamente enviar (push) os branches que quer compartilhar. Desta maneira, você pode usar branches privados para o trabalho que não quer compartilhar, e enviar somente os branches tópicos em que quer colaborar.
Se você tem um branch chamado serverfix e quer trabalhar com outros, você pode enviá-lo da mesma forma que enviou seu primeiro branch. Execute o comando git push (remote) (branch):
1 $ git push origin serverfix
2 Counting objects: 20, done.
3 Compressing objects: 100% (14/14), done.
4 Writing objects: 100% (15/15), 1.74 KiB, done.
5 Total 15 (delta 5), reused 0 (delta 0)
6 To git@github.com:schacon/simplegit.git
7 * [new branch] serverfix -> serverfix
Isso é um atalho. O Git automaticamente expande o branch serverfix para refs/heads/serverfix:refs/heads/serverfix, que quer dizer, “pegue meu branch local serverfix e envie para atualizar o branch serverfix no servidor remoto”. Nós vamos ver a parte de refs/heads/ em detalhes no capítulo 9, mas em geral você pode deixar assim. Você pode executar também git push origin serverfix:serverfix, que faz a mesma coisa — é como, “pegue meu serverfix e o transforme no serverfix remoto”. Você pode usar esse formato para enviar (push) um branch local para o branch remoto que tem nome diferente. Se você não quer chamá-lo de serverfix no remoto, você pode executar git push origin serverfix:awesomebranch para enviar seu branch local serverfix para o branch awesomebranch no projeto remoto.
Na próxima vez que um dos seus colaboradores obtiver dados do servidor, ele terá uma referência para onde a versão do servidor de serverfix está no branch remoto origin/serverfix:
1 $ git fetch origin
2 remote: Counting objects: 20, done.
3 remote: Compressing objects: 100% (14/14), done.
4 remote: Total 15 (delta 5), reused 0 (delta 0)
5 Unpacking objects: 100% (15/15), done.
6 From git@github.com:schacon/simplegit
7 * [new branch] serverfix -> origin/serverfix
É importante notar que quando você obtém dados que traz novos branches remotos, você não tem automaticamente copias locais e editáveis. Em outras palavras, nesse caso, você não tem um novo branch serverfix — você tem somente uma referência a origin/serverfix que você não pode modificar.
Para fazer o merge desses dados no branch que você está trabalhando, você pode executar o comando git merge origin/serverfix. Se você quer seu próprio branch serverfix para trabalhar, você pode se basear no seu branch remoto:
1 $ git checkout -b serverfix origin/serverfix
2 Branch serverfix set up to track remote branch refs/remotes/origin/serverfix.
3 Switched to a new branch "serverfix"
Isso dá a você um branch local para trabalhar que começa onde origin/serverfix está.
Branches Rastreados (Tracking branches)
Baixar um branch local a partir de um branch remoto cria automaticamente o chamado tracking branch (branches rastreados). Tracking branches são branches locais que tem uma relação direta com um branch remoto. Se você está em um tracking branch e digita git push, Git automaticamente sabe para que servidor e branch deve fazer o envio (push). Além disso, ao executar o comando git pull em um desses branches, é obtido todos os dados remotos e é automaticamente feito o merge do branch remoto correspondente.
Quando você faz o clone de um repositório, é automaticamente criado um branch master que segue origin/master. Esse é o motivo pelo qual git push e git pull funcionam sem argumentos. Entretanto, você pode criar outros tracking branches se quiser — outros que não seguem branches em origin e não seguem o branch master. Um caso simples é o exemplo que você acabou de ver, executando o comando git checkout -b [branch] [nomeremoto]/[branch]. Se você tem a versão do Git 1.6.2 ou mais recente, você pode usar também o atalho --track:
1 $ git checkout --track origin/serverfix
2 Branch serverfix set up to track remote branch refs/remotes/origin/serverfix.
3 Switched to a new branch "serverfix"
Para criar um branch local com um nome diferente do branch remoto, você pode facilmente usar a primeira versão com um nome diferente para o branch local:
1 $ git checkout -b sf origin/serverfix
2 Branch sf set up to track remote branch refs/remotes/origin/serverfix.
3 Switched to a new branch "sf"
Agora, seu branch local sf irá automaticamente enviar e obter dados de origin/serverfix.
Apagando Branches Remotos
Imagine que você não precise mais de um branch remoto — digamos, você e seus colaboradores acabaram uma funcionalidade e fizeram o merge no branch master remoto (ou qualquer que seja seu branch estável). Você pode apagar um branch remoto usando a sintaxe git push [nomeremoto] :[branch]. Se você quer apagar seu branch serverfix do servidor, você executa o comando:
1 $ git push origin :serverfix
2 To git@github.com:schacon/simplegit.git
3 - [deleted] serverfix
Boom. O branch não existe mais no servidor. Talvez você queira marcar essa página, pois precisará desse comando, e provavelmente esquecerá a sintaxe. Uma maneira de lembrar desse comando é pensar na sintaxe de git push [nomeremoto] [branchlocal]:[branchremoto] que nós vimos antes. Se tirar a parte [branchlocal], basicamente está dizendo, “Peque nada do meu lado e torne-o [branchremoto].”
3.6 Ramificação (Branching) no Git - Rebasing
Rebasing
No Git, existem duas maneiras principais de integrar mudanças de um branch em outro: o merge e o rebase. Nessa seção você aprenderá o que é rebase, como fazê-lo, por que é uma ferramenta sensacional, e em quais casos você não deve usá-la.
O Rebase Básico
Se você voltar para o exemplo anterior na seção de merge (veja Figura 3-27), você pode ver que você criou uma divergência no seu trabalho e fez commits em dois branches diferentes.
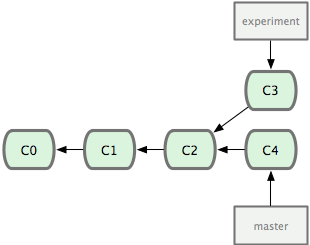
Figura 3-27. Divergência inicial no seu histórico de commits.
A maneira mais fácil de integrar os branches, como já falamos, é o comando merge. Ele executa um merge de três vias entre os dois últimos snapshots (cópias em um determinado ponto no tempo) dos branches (C3 e C4) e o mais recente ancestral comum aos dois (C2), criando um novo snapshot (e um commit), como é mostrado na Figura 3-28.
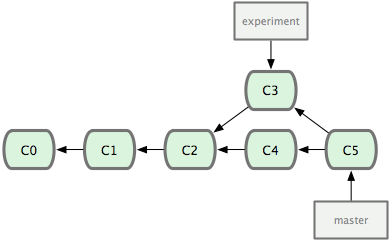
Figura 3-28. Fazendo o merge de um branch para integrar o trabalho divergente.
Porém, existe outro modo: você pode pegar o trecho da mudança que foi introduzido em C3 e reaplicá-lo em cima do C4. No Git, isso é chamado de rebasing. Com o comando rebase, você pode pegar todas as mudanças que foram commitadas em um branch e replicá-las em outro.
Nesse exemplo, se você executar o seguinte:
1 $ git checkout experiment
2 $ git rebase master
3 First, rewinding head to replay your work on top of it...
4 Applying: added staged command
Ele vai ao ancestral comum dos dois branches (no que você está e no qual será feito o rebase), pega a diferença (diff) de cada commit do branch que você está, salva elas em um arquivo temporário, restaura o brach atual para o mesmo commit do branch que está sendo feito o rebase e, finalmente, aplica uma mudança de cada vez. A Figura 3-29 ilustra esse processo.
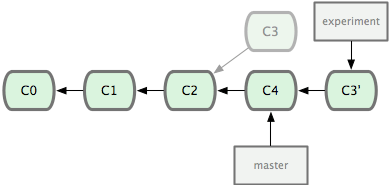
Figura 3-29. Fazendo o rebase em C4 de mudanças feitas em C3.
Nesse ponto, você pode ir ao branch master e fazer um merge fast-forward (Figura 3-30).
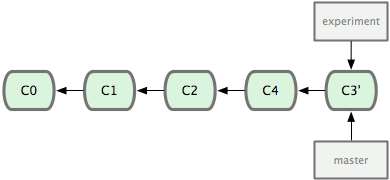
Figura 3-30. Fazendo um fast-forward no branch master.
Agora, o snapshot apontado por C3’ é exatamente o mesmo apontado por C5 no exemplo do merge. Não há diferença no produto final dessas integrações, mas o rebase monta um histórico mais limpo. Se você examinar um log de um branch com rebase, ele parece um histórico linear: como se todo o trabalho tivesse sido feito em série, mesmo que originalmente tenha sido feito em paralelo.
Constantemente você fará isso para garantir que seus commits sejam feitos de forma limpa em um branch remoto — talvez em um projeto em que você está tentando contribuir mas não mantém. Nesse caso, você faz seu trabalho em um branch e então faz o rebase em origin/master quando está pronto pra enviar suas correções para o projeto principal. Desta maneira, o mantenedor não precisa fazer nenhum trabalho de integração — somente um merge ou uma inserção limpa.
Note que o snapshot apontado pelo o commit final, o último commit dos que vieram no rebase ou o último commit depois do merge, são o mesmo snapshot — somente o histórico é diferente. Fazer o rebase reproduz mudanças de uma linha de trabalho para outra na ordem em que foram feitas, já que o merge pega os pontos e os une.
Rebases Mais Interessantes
Você também pode fazer o rebase em um local diferente do branch de rebase. Veja o histórico na Figura 3-31, por exemplo. Você criou um branch tópico (server) no seu projeto para adicionar uma funcionalidade no lado servidor e fez o commit. Então, você criou outro branch para fazer mudanças no lado cliente (client) e fez alguns commits. Finalmente, você voltou ao ser branch server e fez mais alguns commits.
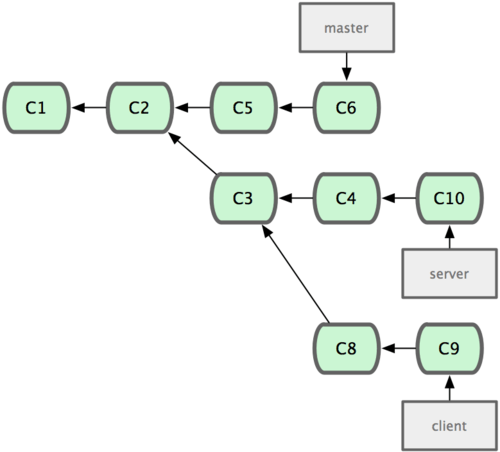
Figura 3-31. Histórico com um branch tópico a partir de outro.
Digamos que você decide fazer um merge das mudanças entre seu branch com mudanças do lado cliente na linha de trabalho principal para lançar uma versão, mas quer segurar as mudanças do lado servidor até que elas sejam testadas melhor. Você pode pegar as mudanças que não estão no servidor (C8 e C9) e incluí-las no seu branch master usando a opção --onto do git rebase:
1 $ git rebase --onto master server client
Isto basicamente diz, “Faça o checkout do branch client, verifique as mudanças a partir do ancestral em comum aos branches client e server, e coloque-as no master.” É um pouco complexo, mas o resultado, mostrado na Figura 3-32, é muito legal:
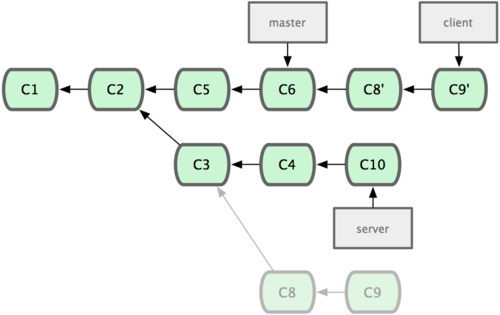
Figura 3-32. Fazendo o rebase de um branch tópico em outro.
Agora você pode avançar (fast-forward) seu branch master (veja Figura 3-33):
1 $ git checkout master
2 $ git merge client
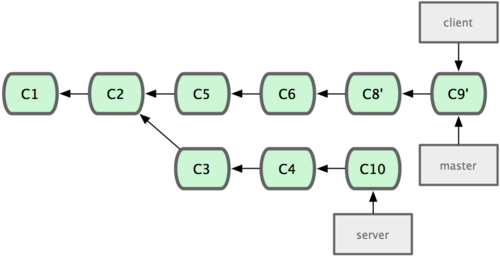
Figura 3-33. Avançando o seu branch master para incluir as mudanças do branch client.
Digamos que você decidiu obter o branch do seu servidor também. Você pode fazer o rebase do branch do servidor no seu branch master sem ter que fazer o checkout primeiro com o comando git rebase [branchbase] [branchtopico] — que faz o checkout do branch tópico (nesse caso, server) pra você e aplica-o no branch base (master):
1 $ git rebase master server
Isso aplica o seu trabalho em server após aquele existente em master, como é mostrado na Figura 3-34:
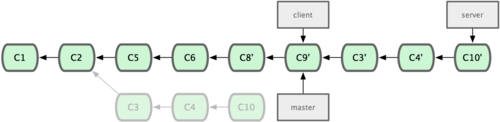
Figura 3-34. Fazendo o rebase do seu branch server após seu branch master.
Em seguida, você pode avançar seu branch base (master):
1 $ git checkout master
2 $ git merge server
Você pode apagar os branches client e server pois todo o trabalho já foi integrado e você não precisa mais deles, deixando seu histórico de todo esse processo parecendo com a Figura 3-35:
1 $ git branch -d client
2 $ git branch -d server

Figura 3-35. Histórico final de commits.
Os Perigos do Rebase
Ahh, mas apesar dos benefícios do rebase existem os inconvenientes, que podem ser resumidos em um linha:
Não faça rebase de commits que você enviou para um repositório público.
Se você seguir essa regra você ficará bem. Se não seguir, as pessoas te odiarão e você será desprezado por amigos e familiares.
Quando você faz o rebase, você está abandonando commits existentes e criando novos que são similares, mas diferentes. Se fizer o push de commits em algum lugar e outros pegarem e fizerem trabalhos baseado neles e você reescrever esses commits com git rebase e fizer o push novamente, seus colaboradores terão que fazer o merge de seus trabalhos novamente e as coisas ficarão bagunçadas quando você tentar trazer o trabalho deles de volta para o seu.
Vamos ver um exemplo de como o rebase funciona e dos problemas que podem ser causados quando você torna algo público. Digamos que você faça o clone de um servidor central e faça algum trabalho em cima dele. Seu histórico de commits parece com a Figura 3-36.
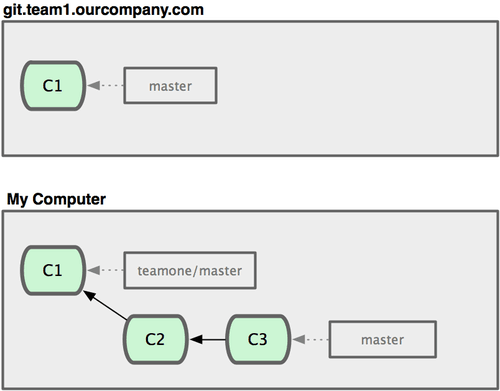
Figura 3-36. Clone de um repositório e trabalho a partir dele.
Agora, outra pessoa faz modificações que inclui um merge e envia (push) esse trabalho para o servidor central. Você o obtêm e faz o merge do novo branch remoto no seu trabalho, fazendo com que seu histórico fique como na Figura 3-37.
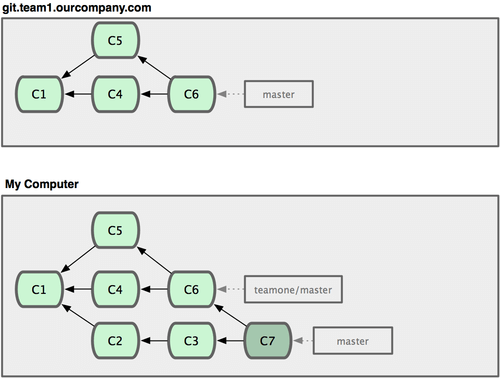
Figura 3-37. Obtêm mais commits e faz o merge deles no seu trabalho.
Em seguida, a pessoa que enviou o merge voltou atrás e fez o rebase do seu trabalho; eles executam git push --force para sobrescrever o histórico no servidor. Você então obtêm os dados do servidor, trazendo os novos commits.
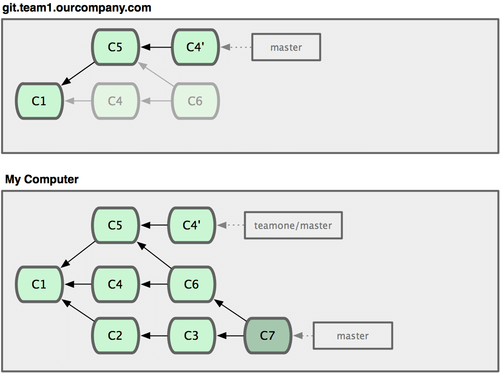
Figura 3-38. Alguém envia commits com rebase, abandonando os commits que você usou como base para o seu trabalho.
Nesse ponto, você tem que fazer o merge dessas modificações novamente, mesmo que você já o tenha feito. Fazer o rebase muda o código hash SHA-1 desses commits, então para o Git eles são commits novos, embora você já tenha as modificações de C4 no seu histórico (veja Figura 3-39).
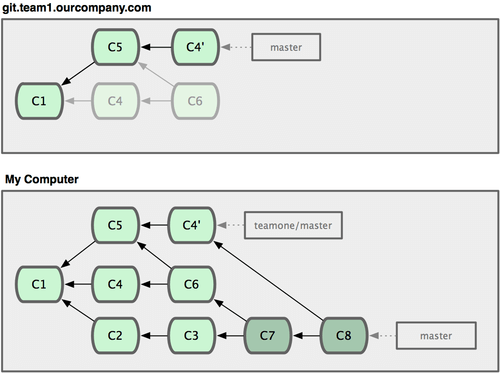
Figura 3-39. Você faz o merge novamente das mesmas coisas em um novo commit.
Você tem que fazer o merge desse trabalho em algum momento para se manter atualizado em relação ao outro desenvolvedor no futuro. Depois de fazer isso, seu histórico de commits terá tanto o commit C4 quanto C4’, que tem códigos hash SHA-1 diferentes mas tem as mesmas modificações e a mesma mensagem de commit. Se você executar git log quando seu histórico está dessa forma, você verá dois commits que terão o mesmo autor, data e mensagem, o que será confuso. Além disso, se você enviar (push) esses histórico de volta ao servidor, você irá inserir novamente todos esses commits com rebase no servidor central, o que pode mais tarde confundir as pessoas.
Se você tratar o rebase como uma maneira de manter limpo e trabalhar com commits antes de enviá-los, e se você faz somente rebase de commits que nunca foram disponíveis publicamente, você ficará bem. Se você faz o rebase de commits que já foram enviados publicamente, e as pessoas podem ter se baseado neles para o trabalho delas, então você poderá ter problemas frustrantes.
3.7 Ramificação (Branching) no Git - Sumário
Sumário
Nós abrangemos o básico do branch e merge no Git. Você deve se sentir confortável ao criar e mudar para novos branches, mudar entre branches e fazer o merge de branches locais. Você deve ser capaz de compartilhar seus branches enviando eles a um servidor compartilhado, trabalhar com outros em branches compartilhados e fazer o rebase de seus branches antes de compartilhá-los.