Chapter 6 - How to lie with brain imaging
In this chapter, we explore the dark side of neuroimaging results. We discuss several fallacious arguments for which to watch out. In writing this, we are inspired by two classic books. One is called ‘How to lie with statistics’, which, of course, really tells you how you should not lie with statistics or at least how to avoid being fooled by those who do. The other book is Bob Cialdini’s terrific ‘Influence’, in which he claims that his own gullibility inspired him to study persuasive power and resistance. Accordingly, this is not really a chapter about how you can lie with brain imaging, in case you were wondering. It’s really a chapter about what not to believe.
Below, we describe five tricks to make your results look specific, strong, and compelling, and also to make them come out like your theory predicted. For example, if you have a theory that requires two psychological tasks to produce highly overlapping brain activity, we can help you make that happen. Or if your theory specifies that patients and controls engage very different brain systems, we can help with that too.
Of course, these are not the only ways to lie with brain images. There are the obvious ways - plain old making stuff up or engaging in a little self-deception like defining ‘a priori’ ROIs after peeking at the statistical maps (because you would have expected activation in the precuneus, right?). There are also techniques like ‘P-Hacking’, which include sleights of hand such as continuing data collection, adding and removing covariates, or transforming outcome measures until you have a significant result. We’ll discuss those more later. Here, we’re interested in techniques that are, at least in some cases, a little bit more subtle and that apply even to brain maps generated through otherwise valid means.
How to tell a story about the ``one brain region’’
The high-threshold
Most clinical disorders and many processes which psychology studies are likely distributed across multiple brain systems. How can we make such a bold claim? To be encapsulated in one brain region, a process must be relatively pure, which implies that localized lesions produce complete and specific deficits. This is true in a few cases: V1 lesions produce cortical blindness and specific inferior temporal lesions produce prosopagnosia, a face recognition deficit. But most processes, even evolutionarily conserved and sensory-driven ones like pain, are highly distributed. The trouble with this is that a neuropsychological tradition which focused on selected cases of specific deficits after focal lesions created a past ‘culture of modularity’. Prestigious journals like Nature and Science have historically vastly preferred simple results with one-point headliner messages like ‘this brain region implements this complex psychological process’ (we won’t pick on any specifics). So how do you get your results to tell that simple story?
The answer is very simple: the high-threshold. Simply raise the bar for statistical significance until you have one region (or very few) left in your map. Not only is this useful for writing a paper around a single brain region which enables emotion, goal setting, attention shifting, hypothesis testing, or whatever you’re studying but it is also really useful if you see significant activation in the white matter or the ventricles - places you shouldn’t see activation in artifact-free statistical maps. The antidote is to (a) choose the threshold a priori and (b) require researchers to show the entire map, including the ventricles (or at least to check it).
How to make your results look really strong
Strong results mean large effect sizes which include high correlations between healthy-sized, meaty-looking blobs with bright colors and brain measures and outcomes. There are two techniques to ensure your brain map looks as it should no matter how weak the effects actually are.
Circular selection (this technique is also known as the voodoo correlation)
Let’s face it: most complex personality traits and clinical symptoms are unlikely to strongly correlate with any one brain voxel. The reliability of both brain and outcome measures limit such correlations’ true values. The heterogeneity of outcome measures also limits them: there is no single reason why people feel depressed, experience neuropathic pain, or are schizophrenic, courageous, or optimistic. Additional limits include person-level factors which affect brain response magnitude unconnected to outcomes of interest: among these factors are individual differences in hemodynamic responses and vascular compliance, blood iron levels, alertness, and caffeine intake. However, isn’t it more convincing if your brain findings correlate with optimism or anxiety above 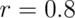 ?
?
Yes, virtually any study can achieve this. The procedure is simple: first run a correlation map across the whole brain, then select the peak region and test that region’s correlation. If your sample contains 16 participants, then any voxel with a p-value less than 0.005 will show a correlation of at least 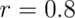 or so. Now, maybe you’re worried about not finding any voxels with such a low P-value…. but don’t be. If you test only 1,000 independent comparisons, you have a 99% chance to get at least one significant result, even with no true signal anywhere in the brain.
Add to this that brain maps can easily contain 100,000 voxels, though they are not independent. And, of course, if you have some voxels with more modest true correlations - say, in the
or so. Now, maybe you’re worried about not finding any voxels with such a low P-value…. but don’t be. If you test only 1,000 independent comparisons, you have a 99% chance to get at least one significant result, even with no true signal anywhere in the brain.
Add to this that brain maps can easily contain 100,000 voxels, though they are not independent. And, of course, if you have some voxels with more modest true correlations - say, in the 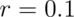 range - then the chances are even greater that you will select a voxel with an apparent
range - then the chances are even greater that you will select a voxel with an apparent 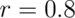 correlation, or higher. Small sample sizes will increase your success, too, because they are more variable across the brain. With only 8 participants, the average significant voxel at
correlation, or higher. Small sample sizes will increase your success, too, because they are more variable across the brain. With only 8 participants, the average significant voxel at 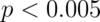 will correlate above
will correlate above 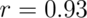 .
.
There is more good news as well: this technique will work for any effect size measure whether it is a correlation, a difference between experimental conditions, or a multivariate pattern analysis classification accuracy.
If you do not want others’ circular selection to fool you, you will need to know that (a) there was a priori selection of all tested regions and (b) the report includes all tested effects. And keep in mind that (c) if there are many tests, some will show large effects by chance.
The low-threshold extent correction
Circular selection will make your effects look really strong, but won’t create those large, fruit-colored blobs on your brain map. Such blobs are important because human minds naturally confuse ‘lots of reported areas’ with ‘strong effects’, even if the two are unrelated. The solution is to lower the statistical threshold until you get large blobs - and possibly to mask out the pesky white matter and ventricle activations that tend to appear at low thresholds. The problem is that reviewers are savvy and will ask you to report results with multiple comparisons correction.
There is a method to lower your statistical threshold and still claim rigorous multiple comparisons correction. How is this possible? Fortunately the technique called cluster extent-based correction lets you set as liberal a `primary threshold’ as you want (say, 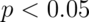 uncorrected) and then correct for multiple comparisons based on the extent of the blob . Among other problems, correction methods are too liberal with such low thresholds (http://www.ncbi.nlm.nih.gov/pubmed/24412399). The bonus is that your figures’ maps will show all the voxels significant at the liberal, uncorrected threshold even though you can at best actually only claim that the activated area has some true signal somewhere in the activated area.
uncorrected) and then correct for multiple comparisons based on the extent of the blob . Among other problems, correction methods are too liberal with such low thresholds (http://www.ncbi.nlm.nih.gov/pubmed/24412399). The bonus is that your figures’ maps will show all the voxels significant at the liberal, uncorrected threshold even though you can at best actually only claim that the activated area has some true signal somewhere in the activated area.
This antidote to this trick is to use more stringent primary thresholds, to clearly indicate each significant region’s identity in figures, and to make it evident that most voxels which appear in the figure may not actually be activated. Or, of course, to avoid extent-based thresholds altogether.
Overlapping processes: How to make two maps look the same
The overlap zoom-in
Let’s say that your theory focuses on overlap across two or more processes such as two types of emotion, pain, or cognitive control. You scan two tasks and compare each one’s activation maps with its respective control condition. To support your theory, simply focus on the overlapping voxels and assume non-overlapping ones are due to noise. Now even if the maps are 95% different across the brain, you can still claim support for your theory. You might also do a multivariate `searchlight’ analysis that looks explicitly for similar brain regions across the two processes. Anything significant in the map is positive evidence and the remaining brain areas in which the tasks are dissimilar are just inconclusive null results attributable to low power.
If you are not getting enough overlap, the low-threshold extent correction can greatly amplify the extent of your activation patterns and thus increase the apparent overlap. Hopefully most reviewers will not realize that this is not a valid test as your comparison is between two maps with `some true signal somewhere’ at each individual voxel, as though each voxel were significant. And, finally, to enhance any of these techniques, you can make a figure that focuses selectively on the overlap locations.
The antidote of this technique is to provide unbiased similarity measures across the whole brain including regions that might be shared or unique. Such approaches are not common in neuroimaging literature yet, which makes this technique particularly hard to counteract.
The low-level control
If the overlap zoom-in does not provide enough ‘evidence’ for overlapping activation, try this additional technique. Similarity is relative: an apple and a banana are dissimilar when compared to an orange but are quite similar when compared to roast beef. Likewise the technique for making the activity maps of two tasks very similar is to compare them to a very dissimilar control condition. Of course, reviewers might object if you compare your two tasks to a third which is very dissimilar. Fortunately, however, there is a perfect comparison condition that will not raise eyebrows, namely rest.
Imagine you have a theory that altruism is an automatic human response (which it actually may be). You posit that punishing others produces internal decision conflict even if they deserve it. Thus you would like to demonstrate that brain responses are similar when unfairly punishing others and within a cognitive ‘conflict’ task. No problem. Simply compare each to rest then look at the overlap of the resulting activation maps. Many low-level processes will activate in each map: processes involved in most cognitive tasks such as orienting attention, making basic motor decisions, and executing them. If your study is sufficiently powered, you will observe beautiful overlapping activation in areas including the anterior cingulate, the anterior insula, and the supplementary motor cortices.
The antidote to this technique is to require tight control of the tasks or, even better, to track parametric strength increases of each process in which you are trying to assess the overlap. Then the maps you compare will be more tightly constrained to reflect the cognitive processes of interest.
How to make two maps look really different
Now let’s assume that you have the opposite problem. Your theory dictates that different processes should be involved in two or more maps. Perhaps you suppose that children with attention deficit disorder process cognitive stimuli differently than those without the disorder. No matter how similar the underlying brain processes are, you can always conclude that the activation patterns are distinct if you so desire.
The high-threshold can come to your aid again here. Because every brain map is variable and the locations of significant voxels vary, the chances that any two maps will produce overlapping voxels decreases as the threshold increases. Alternatively the low-threshold extent correction can also be helpful as it will produce large blobs in mostly non-significant constituent voxels. If you focus on the differences in maps rather than similarities and zoom in on areas with apparent differences, then you will be able to convince most readers that the activation maps are quite distinct. If you analyze the spatial patterns, e.g. by correlating the maps across voxels, then the noisier your maps are, the more likely your maps will be uncorrelated.
The antidotes here involve spatial tests, analyses in which one generates a p-value for whether two tasks activate distinct brain locations, and treating participants as a random effect (we discuss this in more detail later). Without spatial tests, no principled null hypothesis exists for how many voxels should or should not overlap in two truly similar underlying processes, so you can essentially say whatever you want. However, if a reviewer should require you to do a spatial test, you would need to demonstrate statistically significant differences in the activated areas’ location or shape. This is a much higher bar to pass, especially considering that interpreting the voxel overlap heuristically is really no bar at all.
There are also antidotes which relate to spatial pattern tests. Reviewers may require you to demonstrate that each of the two patterns you correlate (a) are reliable, with high correlations with themselves or related within-task measures at re-test and (b) strongly correlate with a task state or outcome. If so, then the bar is again raised: a null correlation across tasks is contextually meaningful with positive correlations within-tasks.
Conclusions
With this chapter, we hope we have been able to show you that you can take valid, albeit noisy, statistical brain maps and shape their presentation to fit your theories in multiple ways, independently of the truth. Of course, we do not want you to actually do this (in case anyone missed that point). We want you to be aware of these deceptions and self-deceptions to ensure that your analyses are unbiased so data shapes theory rather than the opposite. The best way to make sure this happens is to care more about discovering something true than about finding supporting evidence for a particular view or theory. This is sometimes difficult when the truth does not line up with our publication goals and cherished beliefs, but it is the austere path of science.