2 Herausforderung Arbeitsorganisation
Software zu entwickeln ist meist eine komplexe Angelegenheit. Software im Team zu entwickeln ist immer eine komplexe Angelegenheit. Das liegt daran, dass neben den Herausforderungen, die das eigentliche Entwickeln der Software ohnehin schon mit sich bringt, weitere Herausforderungen hinzu kommen. Um Software mit mehreren Menschen im Team zu entwickeln, müssen diese Menschen zunächst einmal ein Team bilden. Das ist nicht so selbstverständlich, wie es klingen mag. Zwar ist es heute üblich, Software mit mehreren Personen gemeinsam zu entwickeln, doch häufig entsteht dabei lediglich eine Gruppe und noch kein Team. Der wesentliche Unterschied zwischen Gruppe und Team liegt in der Selbstorganisation. Entwickelt sich die Selbstorganisation so weit, dass eine gemeinsame Verantwortung entsteht, spricht man von einem Team. In einer Gruppe dagegen ist jeder Einzelne für seine (Teil-)Ergebnisse verantwortlich. Nur im Team wird das Ergebnis als gemeinsames Ergebnis betrachtet, während in Gruppen noch die Einzelergebnisse im Vordergrund stehen.
Desweiteren ergeben sich durch Teamarbeit Herausforderungen im technischen Sinne. Schon dadurch, dass mehrere Personen an der Software arbeiten, entsteht schneller ein größeres System, als bei einer Einzelperson: es kommt in gleicher Zeit mehr Code zusammen. Vor allem muss nun aber die Zusammenarbeit so organisiert werden, dass nur geringe Reibungsverluste entstehen. Teams die einfach drauf los entwickeln, werden schnell die Grenzen einer ad-hoc Arbeitsorganisation feststellen.
2.1 Feature Developer vs. Feature Team
Eine der wichtigsten Fragen der Arbeitsorganisation lautet, wie die Zuständigkeit für ein Feature organisiert ist. Dabei ist ein Feature ein kleiner Ausschnitt aus den gesamten Anforderungen. Für die weitere Betrachtung ist eine trennscharfe Definition von Feature von geringerer Bedeutung. Es genügt, sich ein Feature als Teilfunktionalität oder Ausschnitt aus den Anforderungen vorzustellen. Nun gibt es zwei Möglichkeiten, die Umsetzung eines Features zu organisieren: es kann entweder jedes Feature einem einzelnen Entwickler zugeordnet werden, oder das gesamte Team setzt Feature für Feature gemeinsam um. Im ersten Fall spricht man von Feature Developer. Jeder Entwickler arbeitet an „seinem“ Feature. Eine wirkliche Zusammenarbeit findet nicht statt. Zwangsläufig ergibt sich für eine Gruppe von Entwicklern daraus die Konsequenz, dass jeweils mehrere Features gleichzeitig in Bearbeitung sind. Übrigens ergibt sich aus der Organisation mehrerer Feature Developer auch die Notwendigkeit für Daily-Standups in Scrum. Die Entwickler müssen nicht miteinander reden, solange jeder an „seinem“ Code arbeitet. Logischerweise muss man dann das Reden im Team organisieren, da es sich nicht von selbst ergibt. Für mich ist das höchstens die zweitbeste Lösung. Natürlich hilft organisiert vereinbartes Reden dem Team dabei, zusammen zu wachsen. Doch viel wichtiger ist es, die Arbeit so zu organisieren, dass wirklich zusammen gearbeitet wird. Dann entsteht die Notwendigkeit oder sogar der Wunsch, miteinander zu Reden, ganz natürlich von alleine.
Arbeitet das komplette Team gemeinsam an einem einzigen Feature, spricht man von einem Feature Team. Damit ein Team in der Lage ist, parallel am selben Feature zu arbeiten, muss die Arbeit natürlich so organisiert sein, dass dies überhaupt effizient möglich ist. Es bedarf vor allem einiger technischer Lösungen, weil das gesamte Feature natürlich in geeigneter Weise zerlegt werden muss, so dass Einzelteile entstehen, die jeweils von einer Einzelperson umgesetzt werden können. An dieser Stelle kommen die Komponenten ins Spiel. Sie bilden in einem Team die größte Einheit, an der ein Entwickler alleine arbeiten kann. Doch bevor ich zur Lösung übergehe, möchte ich noch darauf eingehen, warum die Organisation der Arbeit in Form von Feature Teams unbedingt erstrebenswert ist.
Wir sind heute Rechner gewohnt, deren Prozessor mehrere Kerne enthält. Dadurch ist inzwischen echtes Multitasking möglich, also das wirklich parallele Abarbeiten von Programmen. Doch obwohl mehrere Kerne zur Verfügung stehen, sind auch heute in der Regel mehr Programme gleichzeitig aktiv, als Kerne zur Verfügung stehen. Der Trick dabei: der Prozessor wird reihum mehr oder weniger gleichmäßig auf die diversen anstehenden Aufgaben verteilt. Zu einem Zeitpunkt bearbeitet der Prozessor ein Programm. Durch den schnellen Wechsel entsteht für uns Anwender der Eindruck, die Programme würden parallel ablaufen. Dagegen ist nichts einzuwenden. Es entsteht aber die Frage, ob dies die beste Strategie ist, wenn eine der Aufgaben besonders schnell abgearbeitet werden soll. Übertragen wir die Analogie auf ein Entwicklerteam. Das Team hat die Möglichkeit, pseudo-gleichzeitig an mehreren Features gleichzeitig zu arbeiten. Dadurch entsteht für den Betrachter außerhalb des Teams der Eindruck, alle Features wären in Arbeit. Doch wird dabei jedes Feature in bestmöglicher Zeit fertig? Ganz klar: nein. Ein Feature, das so schnell wie möglich fertig werden soll, muss als einziges Feature vom gesamten Team bearbeitet werden. Es muss das einzige Feature sein, das überhaupt in Bearbeitung ist. Aus dieser Betrachtung ergibt sich eine Frage: Sollte ein Team jeweils ein einzelnes Feature in bestmöglicher Zeit fertigstellen, oder sollte es gleichzeitig an mehreren Features arbeiten, die dann jedes für sich nicht in optimaler Zeit fertig werden? Bei der Beantwortung der Frage hilft ein Blick zur Theorie of Constraints1. Aus ihr ergibt sich die Konsequenz, dass eine lokale Optimierung nicht zwingend zum globalen Optimum führt. Ob also ein Entwickler gerade Leerlaufzeit hat oder nicht, spielt eine untergeordnete Rolle. Dieses lokale „Problem“ zu beseitigen, in dem ein Team an mehreren Features arbeitet, erhöht nicht die Wahrscheinlichkeit, dass das Gesamtsystem optimal arbeitet. Im Gegenteil: meist führt die lokale Optimierung zu großen Problemen, die unerkannt bleiben. Schon daraus lässt sich ableiten, dass Teams gut daran tun, immer nur ein Feature in Bearbeitung zu haben und dies erst vollständig fertigstellen, bevor sie das nächste beginnen.
Eine weitere Betrachtung mag helfen, sich von der Organisation als Feature Developer zu verabschieden. Sobald mehrere Features gleichzeitig in Bearbeitung sind und ein systematischer Fehler entdeckt wird, ist die Wahrscheinlichkeit hoch, dass der Fehler mehrfach begangen wurde. Nehmen wir eine Architekturentscheidung als Beispiel. Wurde zu Beginn entschieden, für die Persistenz eine relationale Datenbank einzusetzen, dann kann sich während der Implementation herausstellen, dass eine der nicht-funktionalen Anforderungen auf diese Weise nicht oder nur schwer umsetzbar ist. Beispielsweise könnte der geforderte Durchsatz an Benutzertransaktionen pro Zeiteinheit nicht erreichbar sein. Sind nun bereits mehrere Features in Bearbeitung, wirkt sich diese Erkenntnis möglicherweise auf mehrere dieser Features aus. Vermutlich muss dann an mehreren Features eine Änderung vorgenommen werden. Wäre nur ein einzelnes Feature in Bearbeitung, hätte die Erkenntnis geringere Auswirkungen, denn dann würde sich die Nachbesserung in engeren Grenzen bewegen. Vor allem könnte die Erkenntnis dann bei den anderen Features sofort von Anfang an bedacht und genutzt werden.
Am Ende steht also als klare Erkenntnis: Software sollte im Team so entwickelt werden, dass immer ein Feature nach dem anderen bearbeitet wird. Es gibt keine angefangene Arbeit, die „auf Halde“ liegt, sondern ein begonnenes Feature wird erst vollständig bearbeitet, bevor mit dem nächsten begonnen wird.
2.2 Typische Herausforderungen
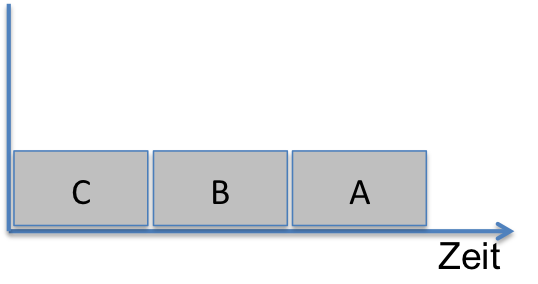
Damit ein Team von Entwicklern gemeinsam an einem Feature arbeiten kann, muss das Feature in kleinere Teile zerlegt werden. Diese kleineren Teile bezeichne ich ganz abstrakt zunächst als Funktionseinheiten. Konkrete Ausprägung einer Funktionseinheit können sein, eine Methode, eine Klasse, eine Assembly, eine Komponente, ein Programm, etc. Die im folgenden geschilderten Herausforderungen sollen aufzeigen, welche Anforderungen an Funktionseinheiten gestellt werden, die von einem Team parallel entwickelt werden. Es ist klar, dass es dabei auf die Komponente als zentralen Begriff dieses Buches hinausläuft. Doch ohne die Lösung gleich parat zu haben, welche Herausforderungen bietet denn diese Form eines gemeinschaftlichen Entwicklungsprozesses? ### Vorgegebene zeitliche Entwicklungsreihenfolge durch Abhängigkeiten Sobald eine Funktionseinheit in kleinere Funktionseinheiten zerlegt wird, ergibt sich die Frage nach den Abhängigkeiten. Manchmal lassen sie sich vermeiden, aber am Ende bleiben immer Abhängigkeiten. Abhängigkeiten können die Reihenfolge der Implementation vorgeben. Dazu ein Beispiel: die Abbildung zeigt drei Funktionseinheiten A, B und C. Diese sind voneinander abhängig. A hängt ab von B, B hängt ab von C.

In manchen Fällen mag die erzwungene Reihenfolge der Implementation unkritisch sein. Handelt es sich beispielsweise um Methoden, stellt das aufgrund des Codeumfangs kein Problem dar. Sind die Funktionseinheiten A,B und C jedoch Teile, an denen mehrere Entwickler gleichzeitig arbeiten sollen, dann behindert die vorgegebene Reihenfolge einen flüssigen Entwicklungsprozess. Aus den in der Abbildung gezeigten Abhängigkeiten ergibt sich für A, B und C folgende Entwicklungsreihenfolge:
Die Lösung der Herausforderungen: Komponenten benötigen Kontrakte. Durch diese wird die Reihenfolge der Entwicklung von den Abhängigkeiten entkoppelt.

Durch die Kontrakte ergibt sich für die Komponenten eine beliebige Reihenfolge bei der Implementation. Zeitlich gesehen müssen erst die Kontrakte realisiert werden. Die Reihenfolge für die Realisierung der Kontrakte ist mehr oder weniger willkürlich, weil zwischen ihnen keine Abhängigkeiten bestehen. Es können lediglich Abhängigkeiten zu Datentypen existieren, die im Kontrakt stehen. Die Kontrakte sind vergleichsweise schnell umgesetzt, weil hierzu lediglich Interfaces erstellt werden müssen. Im Anschluss können die Komponenten in beliebiger Reihenfolge, vor allem auch zeitgleich, erstellt werden. In der folgenden Abbildung ist das dadurch deutlich gemacht, dass die Komponenten übereinander über einander angeordnet sind und somit zum gleichen Zeitpunkt realisiert werden können.
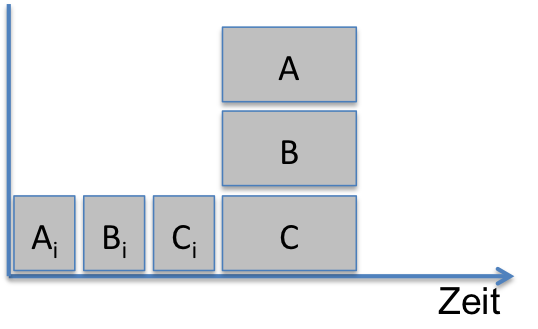
Lösung: Kontrakte
2.2.1 Wildwuchs von Abhängigkeiten, ungeplante Abhängigkeiten
Abhängigkeiten lassen sich in Softwaresystemen nicht vermeiden. Entwickeln sie sich jedoch ungeplant, entsteht ein Wildwuchs von Abhängigkeiten, der nicht mehr zu durchschauen ist. Insofern muss ein Entwicklerteam stets Sorge tragen, dass sich die Abhängigkeiten in einer geordneten Art und Weise entwickeln. Werden die Abhängigkeiten sozusagen sich selbst überlassen, verstärkt sich das Problem selbst. Sogar bei gutem Willen ist es dann irgendwann nicht mehr möglich, an der Situation etwas zu ändern. Die Lösung kann daher nur darin liegen, die Abhängigkeiten zu planen. Statt drauf los zu programmieren und zuzuschauen, wie sich die Abhängigkeiten entwickeln, muss ein Team die Abhängigkeiten vor der Umsetzung planen. Des weiteren muss während der Umsetzung sichergestellt werden, dass die Abhängigkeiten nicht vom Entwurf abweichen.
Lösung: contract-first
2.2.2 Keine Übersicht über die Abhängigkeiten
Eine Konsequenz aus der ungeplanten Entwicklung von Abhängigkeiten ist die Unübersichtlichkeit. Sobald Abhängigkeiten einfach so entstehen, weil ein Entwickler sie nach Bedarf herstellt, geht die Übersicht verloren. Der Blick auf das große Ganze ist nur möglich, wenn Strukturen existieren, die abstrakter sind als Quellcode. Schon aus diesem Grund sind Kontrakte notwendig. Doch für die Übersicht ist es erforderlich, die Kontrakte vor der Umsetzung zu entwerfen.
Lösung: contract-first
2.2.3 Konflikte bei der Quellcodeorganisation
Sobald mehrere Entwickler beginnen, gemeinsam an einer Quellcodebasis zu arbeiten, steht das Risiko von Konflikten beim Zugriff im Raum. Selbstverständlich wird dabei natürlich ein Versionskontrollsystem eingesetzt. Doch selbst beim Einsatz eines noch so leistungsfähigen Merge-Tools ist die effizientere Alternative stets, ohne Konflikte auszukommen. Einerseits soll das Team gemeinsam an einem Feature arbeiten, andererseits sollen dabei aber keine Konflikte auf Quellcodeebene auftreten. Dieser scheinbare Widerspruch wird aufgelöst, in dem jede Komponente eine abgeschlossene Einheit bildet, auch auf Quellcodeebene. Für .NET bedeutet das konkret, jede Komponente in einer eigenen Solution abzulegen. Innerhalb der Solution befinden sich dann die benötigten Projekte: in der Regel mindestens eines für die Implementation der Komponente, sowie ein weiteres für die zugehörigen Tests. Ergebnis dieser so genannten Komponentenwerkbank ist eine Assembly, die an anderer Stelle weiterverwendet wird. Die Details zur Ausgestaltung einer Komponentenwerkbank folgen im Kapitel Verzeichnisstruktur und Projektorganisation.
Lösung: Komponentenwerkbänke
2.2.4 Zu breiter Scope, zu geringer Fokus
Jeder Entwickler hat schon die sprichwörtliche Situation erlebt, vor lauter Bäumen den Wald nicht mehr zu sehen. Plötzlich hat man so viele Dinge im Kopf, dass man nicht mehr weiß, wo man anfangen soll. Gibt der Quellcode dann keinen Rahmen vor, verliert man sich schnell und wird völlig unproduktiv. Statt im Quellcode jeweils alles zu sehen, sollte der Scope deutlich enger gefasst sein und dadurch Fokus bieten. Auch diese Herausforderung wird mit Hilfe von Komponentenwerkbänken gemeistert. In einer Komponentenwerkbank sehe ich jeweils nur den Quellcode, der genau zu dieser einen Komponente gehört. Das schafft Klarheit und bietet Fokus.
Lösung: Komponentenwerkbänke
2.3 Arten von Abhängigkeiten
Bis hier her wurde nun bereits mehrfach betont, dass Abhängigkeiten in einem Softwaresystem unvermeidbar sind. Im weiteren Verlauf wird mit der Komponentenorientierung eine Lösung beschrieben, wie damit auf der Ebene der Arbeitsorganisation umzugehen ist. Doch zuvor soll noch auf zwei grundsätzlich unterschiedliche Formen von Abhängigkeiten eingegangen werden. Daraus lassen sich hilfreiche Schlüsse für den Umgang mit Abhängigkeiten ziehen. Es gibt zwei grundsätzlich verschiedene Arten von Abhängigkeiten: • Viele Funktionseinheiten sind von einer anderen Funktionseinheit abhängig. • Eine Funktionseinheit ist von vielen anderen Funktionseinheiten abhängig. Natürlich gibt es dazwischen alle möglichen Varianten. Dennoch hilft es, sich Gedanken zu machen über diese beiden Extremfälle.
2.3.1 Variante 1: X1, X2, X3 sind von A abhängig
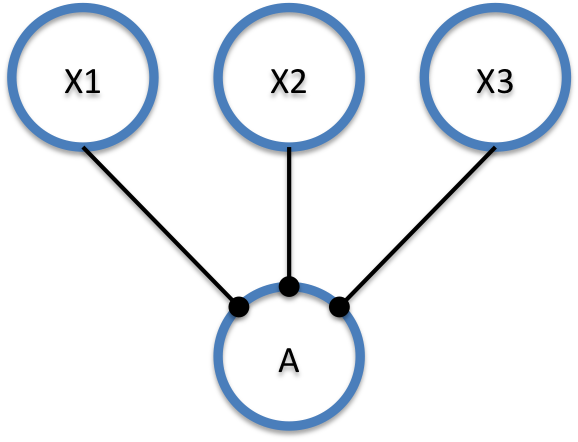
Bei Variante 1 sind X1, X2 und X3 von A abhängig und dadurch potentiell von jeder Änderung an A betroffen. Da viele von A abhängig sind, haben Änderungen an A jeweils starke Auswirkungen. Nun geht es nicht darum, diese Form der Abhängigkeit zu verteufeln mit dem Ziel, sie zu vermeiden. Es gibt immer wieder gute Gründe dafür, dass Abhängigkeiten in dieser Weise auftreten. Wenn das der Fall ist, sollten wir jedoch eine Konsequenz daraus ziehen: wir sollten uns fragen, ob wir an der Beschaffenheit der X1, X2 und X3 und des A etwas tun können, so dass die Auswirkungen keine große Bedeutung haben. Zu betrachten sind dabei zwei Aspekte: die Häufigkeit mit der A geändert wird, sowie das Maß der Auswirkung auf X1, X2 und X3.
Vereinfacht gesagt erhöht sich die Wahrscheinlichkeit, dass an A Änderungen vorgenommen werden müssen, mit dem Codeumfang. Je mehr Code A enthält, desto häufiger ist A von Änderungen betroffen. Und desto häufiger sind auch die X1, X2 und X3 von den Änderungen betroffen. Folglich sollte es bei dieser Konstellation der Abhängigkeiten erstrebenswert sein, A so einfach wie möglich zu halten. Im Idealfall enthält A überhaupt keinen Logikcode sondern ist lediglich eine Datenstruktur. Betrachten wir auch den anderen Aspekt, das Maß der Auswirkungen auf X1, X2 und X3. Auch hier gilt, dass die Auswirkungen deutlich sind, je mehr Logikcode A enthält. Denn je mehr Logik in A steckt, desto größer ist die Wahrscheinlichkeit, dass die X1, X2 und X3 an Änderungen dieser Logik angepasst werden müssen. Auch hier lautet also die Folgerung, dass A möglichst einfach gehalten sein soll, weil dann die Auswirkungen auf X1, X2 und X3 nicht so groß sind.
2.3.2 Variante 2: X ist von A1, A2, A3 abhängig
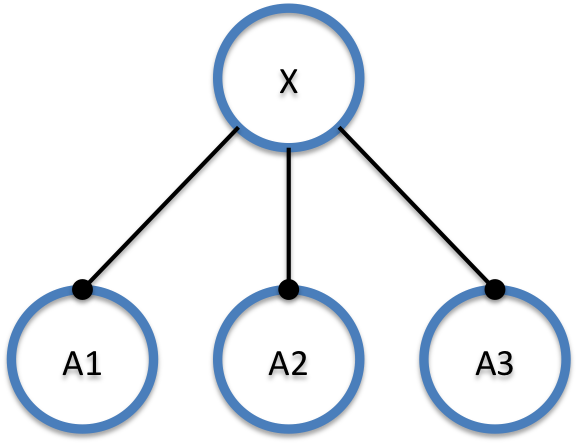
Im zweiten Fall häufen sich die Abhängigkeiten in der anderen Richtung. Ein X ist von vielen anderen Funktionseinheiten abhängig. Damit muss X immer dann angepasst werden, wenn sich bei A1, A2 oder A3 etwas ändert. Auch hier können wir überlegen, welche Forderungen sich daraus ergeben. An der Struktur der Abhängigkeiten wollen wir auch hier nicht rütteln. Die Anzahl der Abhängigkeiten zu verändern, scheidet somit als Strategie aus. Daraus ergibt sich, dass X von den Änderungen an den A1 – A3 immer betroffen ist, egal wie wir uns drehen und wenden. Zu überlegen ist daher, wie X beschaffen sein sollte, damit die Auswirkungen dieser Änderungen leicht beherrschbar bleiben.
Betrachten wir, was passiert, wenn X komplizierte Logik enthält. Diese Logik muss potentiell bei einer Änderung an einem der A1, A2, A3 angepasst werden. Ist die Logik kompliziert, fällt die Anpassung vermutlich schwierig aus. Ist darüber hinaus auch noch sehr viel Logik enthalten, steigt die Wahrscheinlichkeit weiter, dass X tatsächlich angepasst werden muss. Die Lösung besteht also darin, X möglichst einfach zu halten. Im Idealfall enthält X keine Logik, denn dann haben die Änderungen an A1, A2 oder A3 keinen Einfluss auf X. Wenn denn „keine Logik“ nicht vorstellbar ist, dann sollte die Logik wenigstens sehr einfach gehalten sein.
Zu erwähnen sei hier noch, dass sich die Betrachtung der enthaltenen Logik immer auf dieselbe Domäne beziehen muss. Enthalten die A’s und X’s beispielsweise Logik aus dem Bereich der Anwendungslogik, gilt oben gesagtes uneingeschränkt. Ein anderer Fall liegt allerdings in folgendem Beispiel vor: ein IoC Container ist dafür zuständig, die Abhängigkeiten zwischen Funktionseinheiten während der Laufzeit aufzulösen. Dazu muss der Container zwangsläufig alle Funktionseinheiten kennen, die zur Erfüllung von Abhängigkeiten zur Verfügung stehen. Somit liegt hier also der Fall vor, dass ein Container A von vielen Typen X1, X2 und X3 abhängig ist. Die Folgerung wäre somit, den Container A so einfach wie möglich zu gestalten. Doch ein Container ist ein ziemlich kompliziertes Stück Software und enthält daher sehr viel Logik. Dieser scheinbare Widerspruch löst sich auf, sobald man sich klarmacht, dass es hier um zwei unterschiedliche Domänen geht. Die Typen, die vom Container verwaltet werden, enthalten zwar möglicherweise ebenfalls sehr viel Logik. Diese gehört jedoch nicht zur Domäne des Containers. Gegenstand der Betrachtung sollten Abhängigkeiten sein, in denen die Logik von Abhängigen und Unabhängigen sich in derselben Domäne befinden.