2 Asynchronous Dataflow Implementation
Asynchronous Dataflow is characterized by nodes that fire whenever one of their fire rules are satisfied.
Implementations commonly have a few standard components. An activation unit that determines what nodes can fire, an execution unit that controls how the nodes are executed, a token transmission unit that moves tokens from one node to another and finally storage for nodes and tokens.
This is just the bird’s eye view of asynchronous dataflow. There are many different ways to design the system. In the rest of this chapter we will look at the design of a typical asynchronous implementation that you can you as a reference to understand the details of asynchronous dataflow systems.
2.1 Architecture Overview
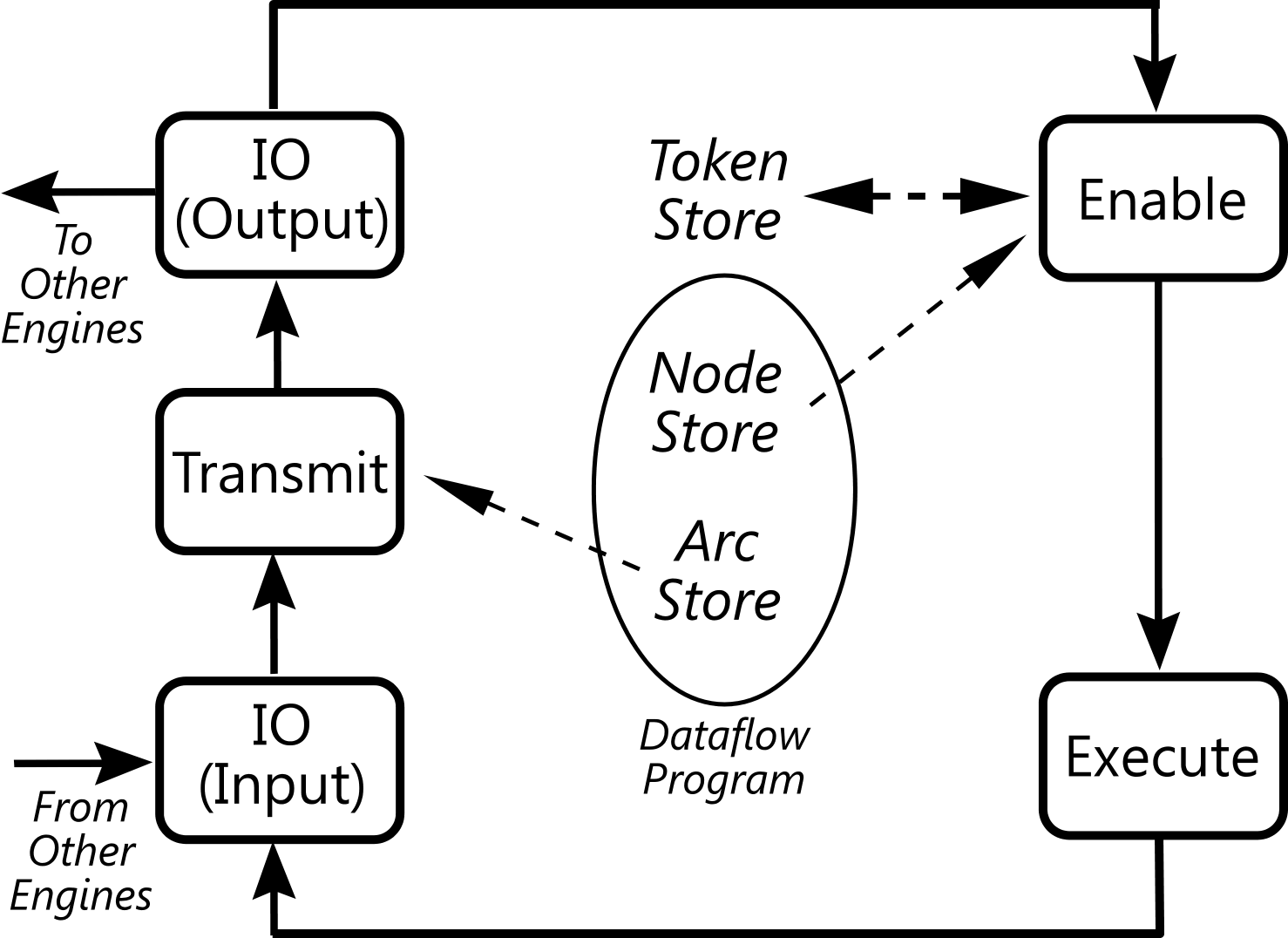
Top Level Architecture of the Example Implementation
This figure shows the architecture of our asynchronous dataflow system. It uses a simple pipeline dataflow architecture to define a system that runs other, dynamic, asynchronous dataflow programs. It is modeled after a dataflow processor from the early 1980’s, the Manchester Prototype Dataflow Computer.
Most asynchronous dataflow processors use some version of this basic architecture. The Manchester Processor design had demands on its design due to the physical nature of computer processors. As software doesn’t share in those burdens, I have changed the design to be more general purpose.
Using the features of dataflow we examined earlier in the book, this implementation can be described as:
- Dynamic
- Asynchronous Activations
- Multiple Inputs and Outputs
- Cycles Allowed
- Functional Nodes
- Uses Per-Node Fire Patterns
- Pushes Data
- Arc Capacity > 1
- Arcs May Join and Split
- Single Token Per Arc Per Activation
2.2 Implementation Walk-Through
The four main components are:
- IO: Communication with other engines and the world
- Transmit: “Moves” a token by changing its location address to the next port’s address
- Enable: Determines what nodes can fire
- Execute: Executes nodes
Tokens come into the system through the input side of the IO unit. Its job is to keep any tokens with addresses inside this engine and to pass on all other tokens.
Tokens then are sent to the Transmit unit. It looks at the token’s address and compares it to a look-up table of connections in the system. If it finds that the new token’s address is on an output port, then it will make a copy of the token and give it the address of the input port(s). Effectively, moving the token from one output port to another input port. If the token’s address is already on an input port, then it keeps the address the same.
The tokens with the new addresses are sent from the Transmit unit to the output side of the IO unit. Its job is to send any tokens with external addresses and to keep those with internal addresses.
Our local tokens then move to the Enable unit. It looks at the incoming tokens and compares them to a store of waiting tokens to see if any nodes can now fire due to the new token. If not, it will save the new token in the Token Store for later use. If a node can now be activated, it creates a new token called an Execute Token. It packages together all the data tokens for the inputs of the node and a way to invoke the node itself.
The Execute unit receives these Execute Tokens and runs the node. Any output tokens are passed back around to the input IO unit again to start over.
2.3 Main Data Types
Besides the Fire Pattern data type below, all of these can be implemented as classes in an Object Oriented languages, a struct in C or the equivalent in your language of choice. The itemized elements under each data type are the members of the type.
2.3.1 Port Address
Defines a unique location (combination of node ID and port ID) of a port within this engine
- Node Id - Unique to engine
- Port Id - Unique to node only
2.3.2 Data Token
A container for the data value and its location
- Value - Any data value
- Port Address - Current location (port) of token
2.3.3 Execute Token
Combines everything needed to fire a node
- Data Tokens - A collection of all tokens on inputs of node
- Node - A means to activate the node
2.3.4 Node
A run-time node combines the Node Definition and a unique Node ID
- Node Definition - Defines how to activate the node
- Node Id - Engine wide, unique id
2.3.5 Node Definition
A node declaration and definition. A single Node Definition may be used to define many run-time nodes that all act the same as the Node Definition – just with different Node IDs.
- Node’s activation function - Function that does the real work
- List of Ports - All the ports on this node
- Fire Patterns - A collection of Fire Patterns
2.3.6 Arc
An Arc is a connection between to two ports
- Source Port Address - Address of the output port
- Sink Port Address - Address of the input port
2.3.7 Fire Pattern
This is a union type in C/C++, a sum type in Haskell, or, in object oriented languages, a base class of Fire Pattern with one sub-class for Exists, one for Empty and so on. This could also be implemented as an enumeration.
A Fire Pattern for a single port is one of the following:
- Exists - A token must exist on this input
- Empty - Input must be empty
- Don’t Care - Doesn’t matter if a token is available or not
- Always - Ignores all other patterns, and forces the whole fire pattern to match
The pattern for the whole node is simply a collection of the all the Fire Patterns for that node.
2.3.8 Token Store
A collection of all the Data Tokens in the system. Read and written to by the Enable Unit only. The tokens in here represent the complete state of the program.
2.3.9 Node Store
A collection of all the nodes in the system. Note changing this at run-time allows for dynamic node redefinitions.
2.3.10 Arc Store
A collection of all the connections in the system. Note changing this at run-time allows for dynamic graphs.
2.3.11 Dataflow Program
The Node Store and Arc Store together are everything needed to define a dataflow program. This is loaded into the engine before execution.
- Node Store - A collection of all the nodes in the program.
- Arc Store - A collection of all the arcs in the program.
2.4 Implementation Components
2.4.1 IO Unit
Input: Data Token
Local Output: Data Token
External Output: Data Token
The IO Unit is the interface to the engine. Tokens arriving at the input port with internal addresses are directed to the “local” port of the component and those with external addresses are directed to the “external” port.
2.4.2 Transmit Unit
Input: Data Token
Output: Data Token
Token movement along arcs are implemented with this unit. The Transmit Unit looks at the tokens address and compares it to a look-up table of connections in the system (Arc Store). If it finds that the new token’s address is on an output port, then it will make one copy of the token for each input port and give it the address of that input port. This action is equivalent to moving the token along the arc and sending a copy down each path.
The look-up table is an encoding of all the connections in the program. Changing the values in this table changes the graph at run-time.
2.4.3 Enable Unit
Input: Data Token
Output: Execute Token
The Enable Unit looks at the incoming tokens and compares them to a store of waiting tokens. The Token Store holds all the tokens currently moving through the program. By comparing the waiting tokens with the node’s fire pattern (pulled from the Token Store), the Enable Unit can determine if a node can fire.
For activated nodes, it creates and sends an Execute Token that packages together all the data tokens for the inputs of the node and a way to invoke the node itself. The tokens are removed from the Token Store and the node definition is copied from the Node Store.
If the incoming token does not cause a node to activate, then it will save the new token in the Token Store for later use.
This implementation allows for per-node firing patterns. The original Manchester Processor design had one firing pattern for every node… all inputs must have tokens waiting before the node can activate. And since all nodes in the original design only had 1 or 2 inputs, the Manchester architecture’s Enable Unit didn’t need access to the node’s definition.
Due to the addition of per-node firing patterns and more than 2 inputs allowed per node, this design requires Enable to connect to the Node Store and the Token Store while the Manchester design only needed a connection to the Token Store.
The Enable Unit is the only component that writes to the Token Store so no special locking is needed for multithreaded operation.
2.4.4 Execute Unit
Input: Execute Token
Output: Data Token
With the contents of the Execute Token, this unit has everything it needs fire nodes.
It takes the collection of data tokens from the Execute Token and passes it to the node definition for evaluation. In this implementation the node definition is simply a function that takes a collection of tokens and returns another (possibly empty) collection of output tokens.
The node’s function only deals with what I call, “local tokens.” They are just like the regular data tokens (that I refer to in this context as a “global token”) without the Node ID field. Nodes should be isolated and not have to know anything about the outside world. The node’s ID is external to the definition of the node itself. It doesn’t matter if there are 10 nodes, all with the same definition and different node IDs, they should all operate exactly the same. What the node does know about is its Port IDs. Port IDs are unique to the node definition. The node’s function returns a collection of local tokens with addresses of output ports that exist on the node.
The Execute Unit must first convert a global token to a local token. It does this by simply stripping off the node’s ID but retaining the port ID and data value. It calls the function with the locals (input tokens) and gets back a collection of locals (output tokens). The unit converts these to globals by adding the current node’s ID back to the tokens along with the port ID and data value.
In the original Manchester design, nodes were defined by an op-code in the same way that assembly language instructions in a typical microprocessor are given numeric identifiers. The Execute Unit knew how to execute an op-code it received so the Execute Token only needed to include an op-code number instead of the full node definition like this implementation requires. In software it costs the same to pass an integer as it does to pass the full node definition and makes the design more general.
2.5 Program Execution Example
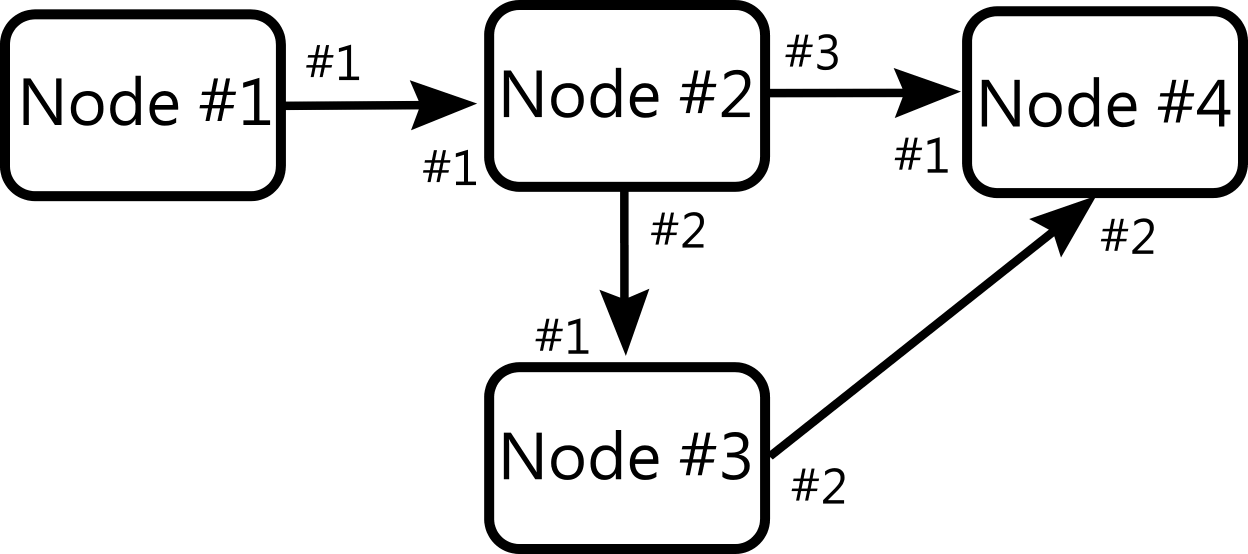
Example Program. The number next to the port is the Port Id
We will assume that the dataflow program is already loaded into the engine. Node #1 is the first node to activate. When it is done, the node pushes a new token to its output port (#1) with the address of (Node #1, Port #1). This states that the token is currently on the output end of the arc between nodes #1 and #2. Then Node #2 fires since it has a token on its input.
For that sequence to happen, the engine has to do the following…
Immediately after starting the engine with the example dataflow program, there are no tokens in the program. The Enable Unit normally first looks at its incoming tokens to see if a node can be executed due to the new token. In this case, there are no input tokens to the Enable Unit but it finds that Node #1 is a source node so that means it can fire all the time. So the Enable Unit creates a new Execution Token with Node #1’s definition as its contents and sends it to the Execute Unit.
The Execute unit sees that it has a new Execute Token waiting so it consumes the token and fires the Node Definition found in the Execute Token. As mentioned above, activating Node #1 pushes a new token to its output. The Execute Unit gets the token, produced from Node #1, and sends that to the input IO Unit which immediately sends it to the Transmit Unit.
Remember that the token’s address is (Node #1, Port #1)… The Transmit Unit looks in the collection of all arcs in the system to find where the token should be sent. Node #1’s output arc connects to Node #2’s input port #1. So the Transmit Unit changes the address of the token to (Node #2, Port #1) saying that the token has been moved to the input port of Node #2. The token with the updated address is passed to the output IO Unit. Since the address of the token is local to this engine, it send the token to the Enable Unit.
Now the Enable Unit will look at the incoming token and see that now Node #2 can fire because a token is waiting on its input. It takes the token and places it into a another Execute Token along with the Node Definition for Node #2.
The Execute Unit then activates Node #2 just like it did before with Node #1 and the cycles continue.
2.6 Preparing a Program for Execution
This example implementation does not include any means to convert a human friendly format (program text) to the engine’s representation. Besides parsing and validating the program text, which is the same for every programming language, the only other thing required is to generate a unique ID for every node in the program.
This is the run-time identifier that uniquely identifies every node in the engine.
The best choice is to use Universally Unique IDs (UUIDs also called GUIDs). Second best is to use unique integers. UUIDs take up 128 bits each so space could be an issue for some designs.
UUIDs are best because they only need to be defined once and allow us to change the graph at run-time without worrying about generating duplicate integer IDs. They also can be used to refer to a specific version of a node. If you generate a new UUID anytime a breaking change is made to a node, all existing code referring to the old UUID will continue to work as expected.
Choose wisely because the type of ID impacts the maximum number of nodes you can have in the engine at any one time and thus restricts maximum program size.
The end result of the preparation phase is a filled in Node Store and Arc Store that is passed to the engine to execute.
2.7 Multiple Dataflow Engines
The Manchester architecture was designed to be easy to combine with other processors. Simply connect the IO units of a few of them to a bus so they can communicate. The tokens will be sent anywhere the address specifies.
This design does not handle multi-engine configurations as well as it could. The addition of a engine ID to the Port Address type would allow you to easily move nodes around to other engines to balance the load. It only takes changing the addresses on the arcs and a few other minor changes.
With multiple engines, some sort of overseer is necessary to balance the load and move code from one engine to another. This implementation was designed as an example of an asynchronous dataflow engine so no effort was spent on external components to make it easy to combine with other engines.
- Harel, D., & Pnueli, A. (1985). “On the development of reactive systems” (pp. 477-498). Springer Berlin Heidelberg. Chicago ↩
- Gerard Berry (1989). “Real Time Programming: Special Purpose or General Purpose Languages” (pp.11-17) IFIP Congress↩
- Johnston, W. M., Hanna, J. R., & Millar, R. J. (2004). Advances in dataflow programming languages. ACM Computing Surveys (CSUR), 36(1), 1-34. Chicago ↩
- John L. Kelly Jr., Carol Lochbaum, V. A. Vyssotsky (1961). “A Block Diagram Compiler”. Bell System Technical Journal, pages 669-678↩
- ibid↩
- Sutherland, W. R. (1966). ON-LINE GRAPHICAL SPECIFICATION OF COMPUTER PROCEDURES (No. TR-405). LINCOLN LAB MASS INST OF TECH LEXINGTON. Chicago ↩
- Dennis, J. B. (1974, January). First version of a data flow procedure language. In Programming Symposium (pp. 362-376). Springer Berlin Heidelberg. Chicago ↩