To-do list project
In this outside-in development section, we will carry out a small project which consists in an API for a to-do list application.
Essentially, we want to implement the following functionalities:
US 1
- As a User
- I want to add tasks to a to-do list
- So that, I can organize my task
US 2
- As a User
- I want to see the task in my to-do list
- So that, I can know what I have to do next
US 3
- As a User
- I want to check a task when it is done
- So that, I can see my progress
Test examples
- Write a test that fails (done)
- Write Production code that makes the test pass
- Refactor if there is opportunity
Endpoints, payloads and responses
1 POST /api/todo
2 [task:Write a test that fails]
3 201. Created
4
5 POST /api/todo
6 [task:Write Production code that makes the test pass]
7 201. Created
8
9 POST /api/todo
10 [task:Refactor if there is opportunity]
11 201. Created
12
13 PATCH /api/todo/1
14 [done:true]
15 200. Ok
16
17 GET /api/todo
18 [√] 1. Write a test that fails
19 [ ] 2. Write Production code that makes the test pass
20 [ ] 3. Refactor if there is opportunity
21 200. Ok
For simplicity, the expected to-do list will be an array of strings with formatted task data.
Design
In order to develop outside-in, it’s necessary to do prior design to a certain extent. Of course, it’s not a matter of generating all of the components’ specifications down to the last detail, but rather of setting a general idea about the architecture model that we’re going to follow, and the large components that we expect to develop.
This will help us place the various elements and understand their relationships and dependencies. It provides us with a context about how the application cycle works and how its components are organized and communicated.
Layers
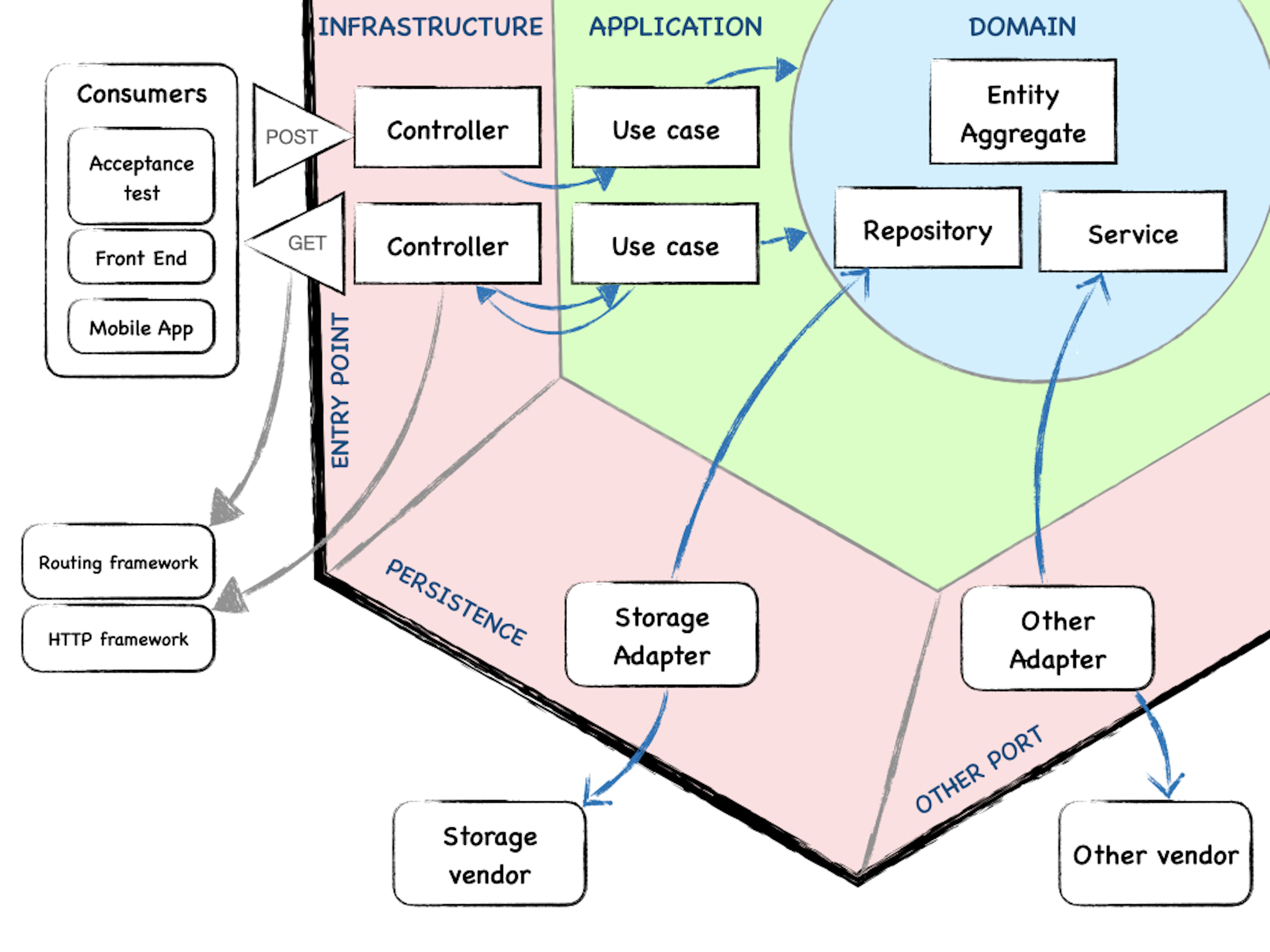
Our application will be organized in layers:
- Domain: contains the domain entities, the heart of the application itself, in which the business concepts, processes and rules are represented.
- Application: the application’s different use cases, representing its consumer’s intentions.
-
Infrastructure: the necessary concrete implementations so that the application functions. In turn, this layer has various ports:
* Entry points, as can be the API, which contains the controllers that interact with the consumers. In this case, the console commands and others would go here as well.
* Persistence: the persistence technology adapters that we need to implement the repository.
* Other adapters if needed.
+ Vendor or Lib, they contain the third-party resources that the application needs to function.
The dependencies always point towards the domain.
Application flow
When doing an HTTP request to an endpoint, a controller gathers the necessary data and passes them to an instance of the corresponding use case. It collects the response, if there’s any, and transforms it to deliver it to the consumer.
The use case instantiates or claims the necessary domain entities from the repository, and uses the domain services to perform its task.
The use cases can take the shape of commands or queries. In the first case, they cause an effect on the system. In the second one, they return a response. To accommodate the response to the controller’s demand, they may use some kind of data transformer, so that the domain objects never reach the controller, but a representation instead. By means of a Strategy pattern, we can make the controller decide in which concrete representation it’s interested.
Architecture
We will build the application using the hexagonal architecture1 approach with a three-layer structure: domain, application and infrastructure, just as we’ve detailed above. The development will begin with an acceptance test, which acts as a consumer of the API, which will lead us to implementing the controllers in the first place.
This a generic schematic of the architecture type that we’ll have in mind when developing this application.