Introdução ao Node.js
Node.js não é uma linguagem de programação, tampouco um framework. A definição mais apropriada seria: um ambiente de runtime para Javascript que roda em cima de uma engine conhecida como Google v8. O Node.js nasceu de uma ideia do Ryan Dahl que buscava uma solução para o problema de acompanhar o progresso de upload de arquivos sem ter a necessidade de fazer pooling no servidor. Em 2009 na JSConf EU ele apresentou o Node.js e introduziu o Javascript server-side com I/O não bloqueante, ganhando assim o interesse da comunidade que começou a contribuir com o projeto desde a versão 0.x.
A primeira versão do NPM (Node Package Manager), o gerenciador de pacotes oficial do Node.js, foi lançada em 2011 permitindo aos desenvolvedores a criação e publicação de suas próprias bibliotecas e ferramentas. O NPM é tão importante quanto o próprio Node.js e desempenha um fator chave para o sucesso do mesmo.
Nessa época não era fácil usar o Node. A frequência com que breaking changes eram incorporadas quase impossibilitava a manutenção dos projetos. O cenário se estabilizou com o lançamento da versão 0.8, que se manteve com baixo número de breaking changes. Mesmo com a frequência alta de atualizações, a comunidade se manteve ativa. Frameworks como Express e Socket.IO já estavam em desenvolvimento desde 2010 e acompanharam, lado a lado, as versões da tecnologia.
O crescimento do Node.js foi rápido e teve altos e baixos, como a saída do Ryan Dahl em 2012 e a separação dos core committers do Node.js em 2014, causada pela discordância dos mesmos com a forma como a Joyent (empresa na qual Ryan trabalhava antes de sair do projeto) administrava o projeto. Os core committers decidiram fazer um fork do projeto e chamá-lo de IO.js com a intenção de prover releases mais rápidas e acompanhar as melhorias do Google V8.
Essa separação trouxe dor de cabeça para a comunidade, que não sabia qual dos dois projetos deveria usar. Então, Joyent e outras grandes empresas como IBM, Paypal e Microsoft se uniram para ajudar a comunidade Node.js, criando a Node.js Foundation. A [Node.js Foundation] tem como missão a administração transparente e o encorajamento da participação da comunidade. Com isso, os projetos Node.js e IO.js se fundiram e foi lançada a primeira versão estável do Node.js, a versão 4.0.
O Google V8
O V8 é uma engine (motor) criada pela Google para ser usada no browser chrome. Em 2008 a Google tornou o V8 open source e passou a chamá-lo de Chromium project. Essa mudança possibilitou que a comunidade entendesse a engine em sí, além de compreender como o javascript é interpretado e compilado pela mesma.
O javascript é uma linguagem interpretada, o que o coloca em desvantagem quando comparado com linguagens compiladas, pois cada linha de código precisa ser interpretada enquanto o código é executado. O V8 compila o código para linguagem de máquina, além de otimizar drasticamente a execução usando heurísticas, permitindo que a execução seja feita em cima do código compilado e não interpretado.
Entendendo o Node.js single thread
A primeira vista o modelo single thread parece não fazer sentido, qual seria a vantagem de limitar a execução da aplicação em somente uma thread? Linguagens como Java, PHP e Ruby seguem um modelo onde cada nova requisição roda em uma thread separada do sistema operacional. Esse modelo é eficiente mas tem um custo de recursos muito alto, nem sempre é necessário todo o recurso computacional aplicado para executar uma nova thread. O Node.js foi criado para solucionar esse problema, usar programação assíncrona e recursos compartilhados para tirar maior proveito de uma thread.
O cenário mais comum é um servidor web que recebe milhões de requisições por segundo; Se o servidor iniciar uma nova thread para cada requisição vai gerar um alto custo de recursos e cada vez mais será necessário adicionar novos servidores para suportar a demanda. O modelo assíncrono single thread consegue processar mais requisições concorrentes do que o exemplo anterior, com um número bem menor de recursos.
Ser single thread não significa que o Node.js não usa threads internamente, para entender mais sobre essa parte devemos primeiro entender o conceito de I/O assíncrono não bloqueante.
I/O assíncrono não bloqueante
Trabalhar de forma não bloqueante facilita a execução paralela e o aproveitamento de recursos, essa provavelmente é a característica mais poderosa do Node.js, Para entender melhor vamos pensar em um exemplo comum do dia a dia. Imagine que temos uma função que realiza várias ações, entre elas uma operação matemática, a leitura de um arquivo de disco e em seguida transforma o resultado em uma String. Em linguagens bloqueantes, como PHP e Ruby, cada ação será executada apenas depois que a ação anterior for encerrada. No exemplo citado a ação de transformar a String precisa esperar uma ação de ler um arquivo de disco, que pode ser uma operação pesada, certo? Vamos ver um exemplo de forma síncrona, ou seja, bloqueante:
1 const fs = require('fs');
2 let fileContent;
3 const someMath = 1+1;
4
5 try {
6 fileContent = fs.readFileSync('big-file.txt', 'utf-8');
7 console.log('file has been read');
8 } catch (err) {
9 console.log(err);
10 }
11
12 const text = `The sum is ${ someMath }`;
13
14 console.log(text);
A linha 14 do exemplo acima, com o console.log, imprimirá o resultado de 1+1 somente após a função readFileSync do módulo de file system executar, mesmo não possuindo ligação alguma com o resultado da leitura do arquivo.
Esse é o problema que o Node.js se propôs a resolver, possibilitar que ações não dependentes entre sí sejam desbloqueadas. Para solucionar esse problema o Node.js depende de uma funcionalidade chamada high order functions. As high order functions possibilitam passar uma função por parâmetro para outra função, as funções passadas como parâmetro serão executadas posteriormente, como no exemplo a seguir:
1 const fs = require('fs');
2
3 const someMath = 1+1;
4
5 fs.readFile('big-file.txt', 'utf-8', function (err, content) {
6 if (err) {
7 return console.log(err)
8 }
9 console.log(content)
10 });
11
12 const text = `The response is ${ someMath }`;
13
14 console.log(text);
No exemplo acima usamos a função readFile do módulo file system, assíncrona por padrão. Para que seja possível executar alguma ação quando a função terminar de ler o arquivo é necessário passar uma função por parâmetro, essa função será chamada automaticamente quando a função readFile finalizar a leitura.
Funções passadas por parâmetro para serem chamadas quando a ação é finalizada são chamadas de callbacks. No exemplo acima o callback recebe dois parâmetros injetados automaticamente pelo readFile: err, que em caso de erro na execução irá possibilitar o tratamento do erro dentro do callback, e content que é a resposta da leitura do arquivo.
Para entender como o Node.js faz para ter sucesso com o modelo assíncrono é necessário entender também o Event Loop.
Event Loop
O Node.js é uma linguagem guiada por eventos. O conceito de Event Driven é bastante aplicado em interfaces para o usuário, o javascript possui diversas APIs baseadas em eventos para interações com o DOM como por exemplo eventos como click, scroll, change são muito comuns no contexto do front-end com javascript.
Event Driven é um fluxo de controle determinado por eventos ou alterações de estado, a maioria das implementações possuem um core (núcleo) que escuta todos os eventos e chama seus respectivos callbacks quando eles são lançados (ou tem seu estado alterado), esse é o resumo do Event Loop do Node.js.
Separadamente, a responsabilidade do Event Loop parece simples mas quando nos aprofundamos no funcionamento do Node.js notamos que o Event Loop é a peça chave para o sucesso do modelo event driven. Nos próximos tópicos vamos entender cada um dos componentes que formam o ambiente do Node.js, como funcionam e como se conectam.
Call Stack
A stack (pilha) é um conceito bem comum no mundo das linguagens de programação, frequentemente se ouve algo do tipo: “Estourou a pilha!”. No Node.js, e no javascript em geral, esse conceito não se difere muito de outras linguagens, sempre que uma função é executada ela entra na stack, que executa somente uma coisa por vez, ou seja, o código posterior ao que está rodando precisa esperar a função atual terminar de executar para seguir adiante. Vamos ver um exemplo:
1 function generateBornDateFromAge(age) {
2 return 2016 - age;
3 }
4
5 function generateUserDescription(name, surName, age) {
6 const fullName = `${name} ${surName}`;
7 const bornDate = generateBornDateFromAge(age);
8
9 return `${fullName} is ${age} old and was born in ${bornDate}`;
10 }
11
12 generateUserDescription("Waldemar", "Neto", 26);
Para quem já é familiarizado com javascript não há nada especial acontecendo aqui. A função generateUserDescription é chamada recebendo nome, sobrenome e idade de um usuário e retorna uma sentença com as informações colhidas. A função generateUserDescription depende da função generateBornDateFromAge para calcular o ano que o usuário nasceu. Essa dependência será perfeita para entendermos como a stack funciona.
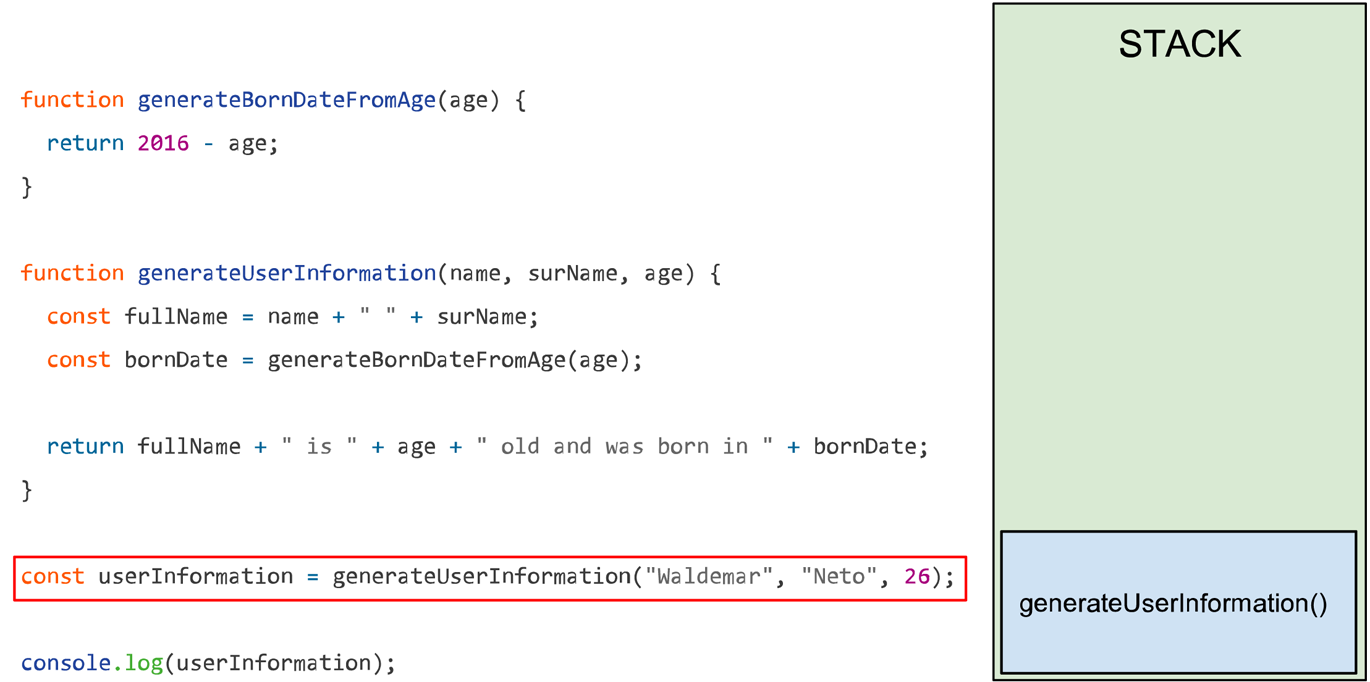
No momento em que a função generateUserInformation é invocada ela vai depender da função generateBornDateFromAge para descobrir o ano em que o usuário nasceu com base no parâmetro age. Quando a função generateBornDateFromAge for invocada pela função generateUserInformation ela será adicionada a stack como no exemplo a seguir:

Conforme a função generateUserInformation vai sendo interpretada os valores vão sendo atribuídos às respectivas variáveis dentro de seu escopo, como no exemplo anterior. Para atribuir o valor a variável bornDate foi necessário invocar a função generateBornDateFromAge que quando invocada é imediatamente adicionada a stack até que a execução termine e a resposta seja retornada.
Após o retorno a stack ficará assim:
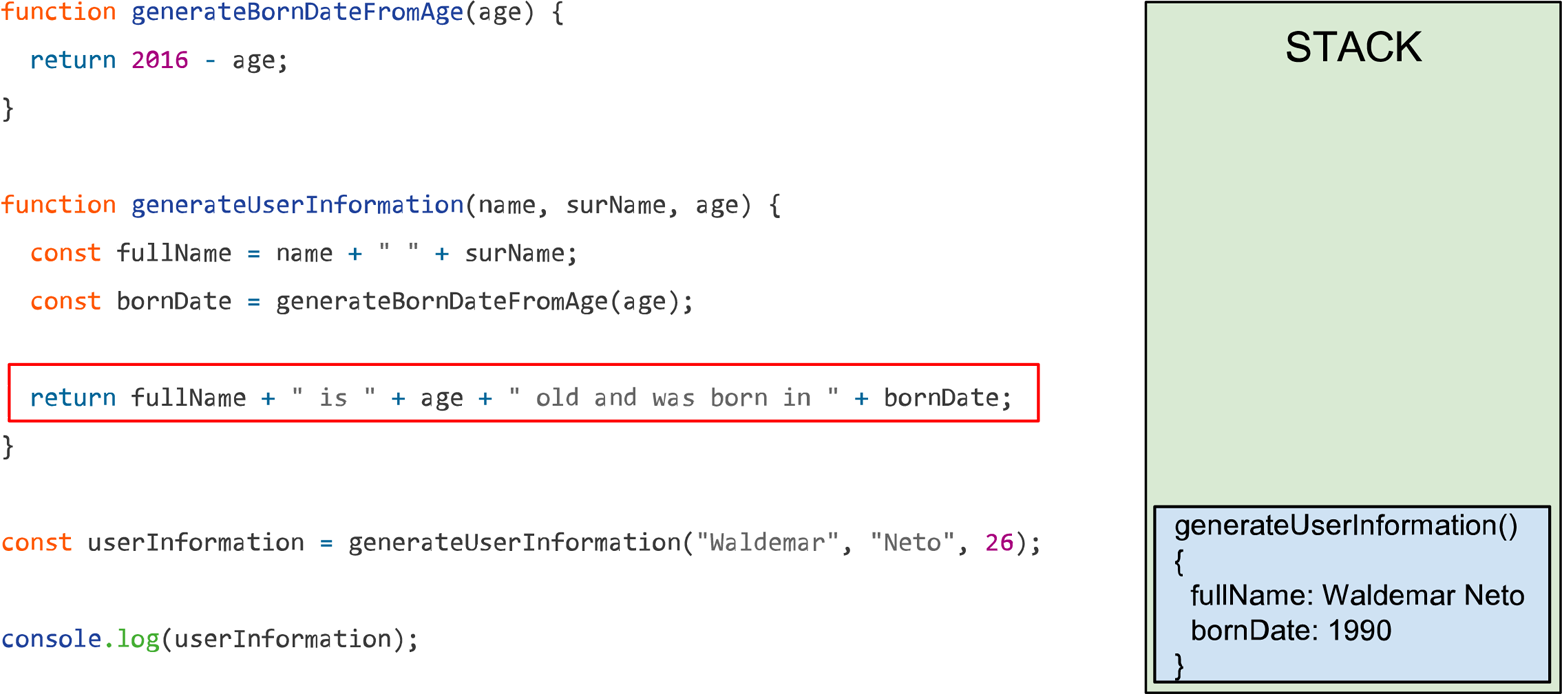
O último passo da função será concatenar as variáveis e criar uma frase, isso não irá adicionar mais nada a stack. Quando a função generateUserInformation terminar, as demais linhas serão interpretadas. No nosso exemplo o console.log será executado e vai imprimir o valor da variável userInformation.
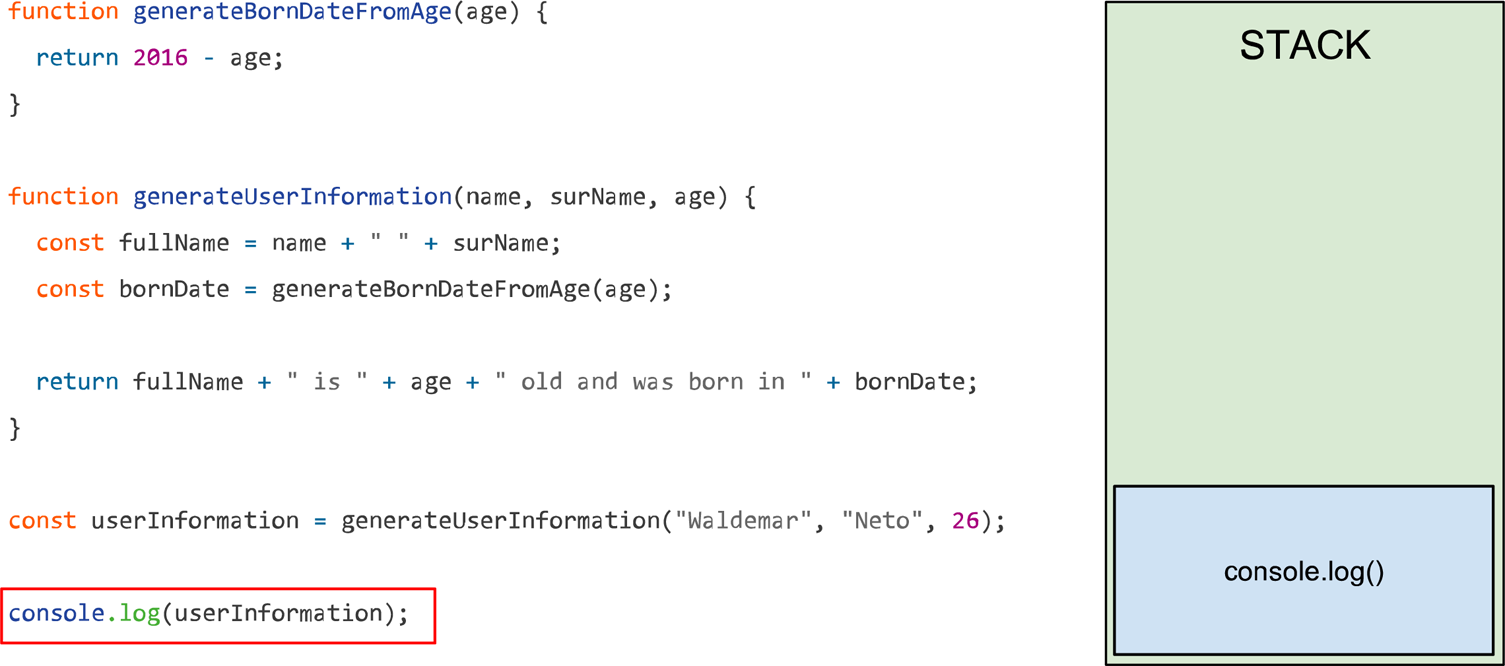
Como a stack só executa uma tarefa por vez foi necessário esperar que a função anterior executasse e finalizasse, para que o console.log pudesse ser adicionado a stack.
Entendendo o funcionamento da stack podemos concluir que funções que precisam de muito tempo para execução irão ocupar mais tempo na stack e assim impedir a chamada das próximas linhas.
Multithreading
Mas o Node.js não é single thread? Essa é a pergunta que os desenvolvedores Node.js provavelmente mais escutam. Na verdade quem é single thread é o V8. A stack que vimos no capitulo anterior faz parte do V8, ou seja, ela é single thread. Para que seja possível executar tarefas assíncronas o Node.js conta com diversas outras APIs, algumas delas providas pelos próprios sistemas operacionais, como é o caso de eventos de disco, sockets TCP e UDP. Quem toma conta dessa parte de I/O assíncrono, de administrar múltiplas threads e enviar notificações é a libuv.
A libuv é uma biblioteca open source multiplataforma escrita em C, criada inicialmente para o Node.js e hoje usada por diversos outros projetos como Julia e Luvit.
O exemplo a seguir mostra uma função assíncrona sendo executada:
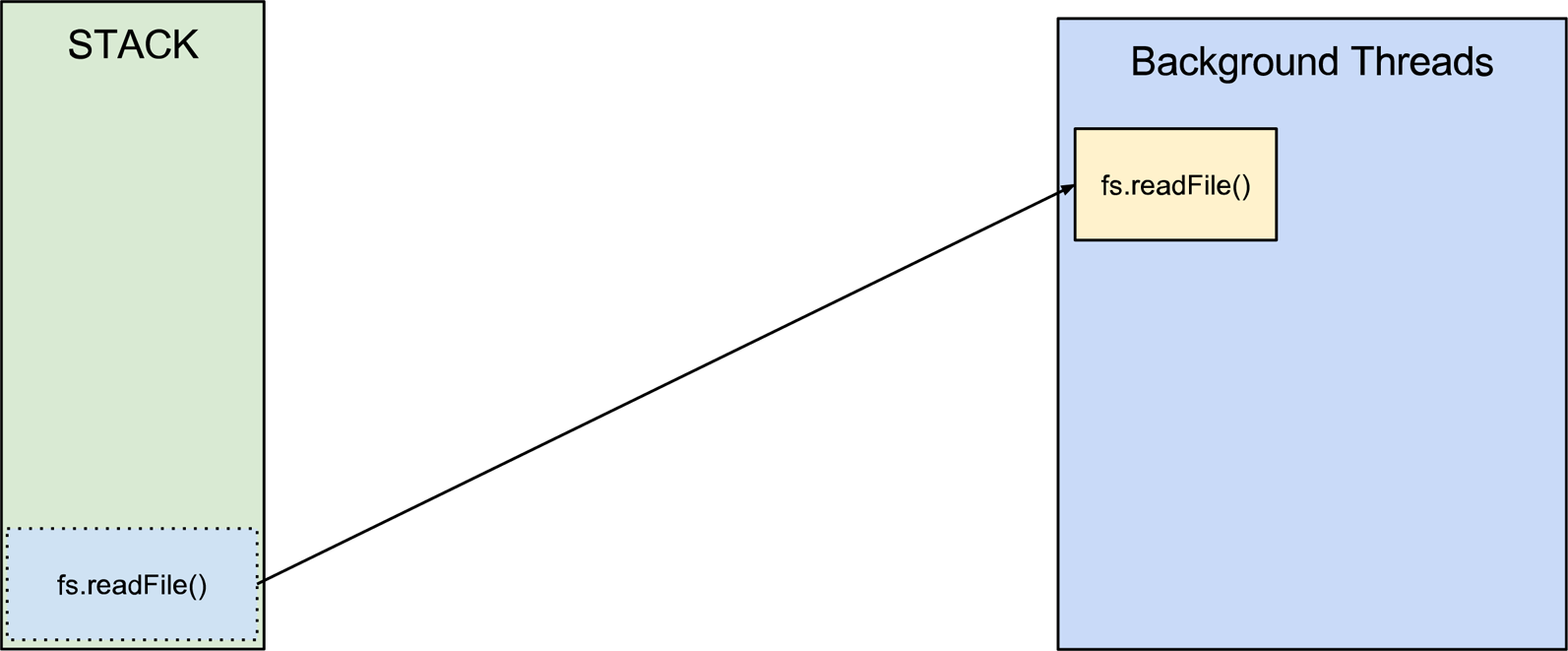
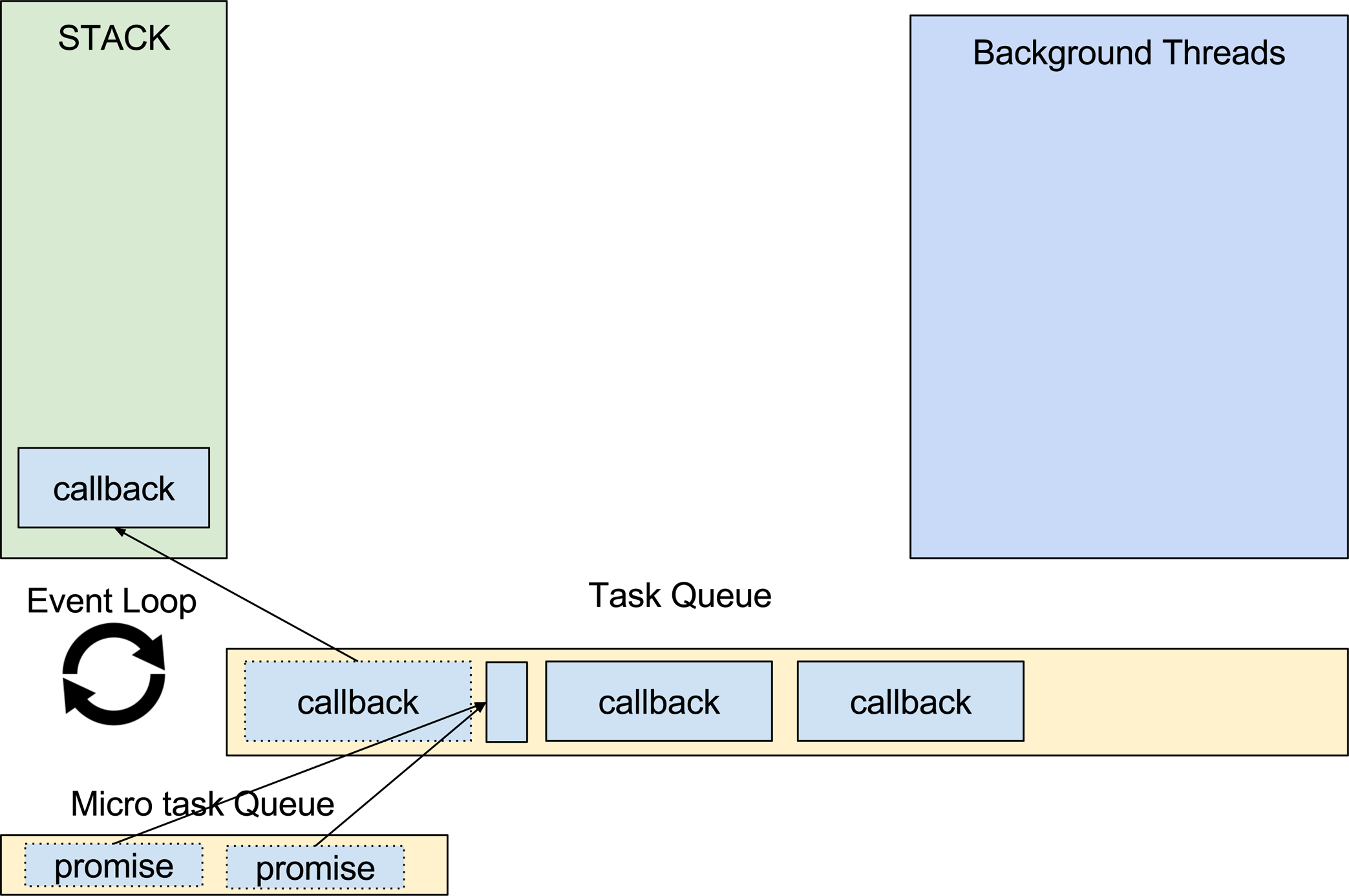
Nesse exemplo a função readFile do módulo de file system do Node.js é executada na stack e jogada para uma thread, a stack segue executando as próximas funções enquanto a função readFile está sendo administrada pela libuv em outra thread. Quando ela terminar, o callback sera adicionado a uma fila chamada Task Queue para ser executado pela stack assim que ela estiver livre.
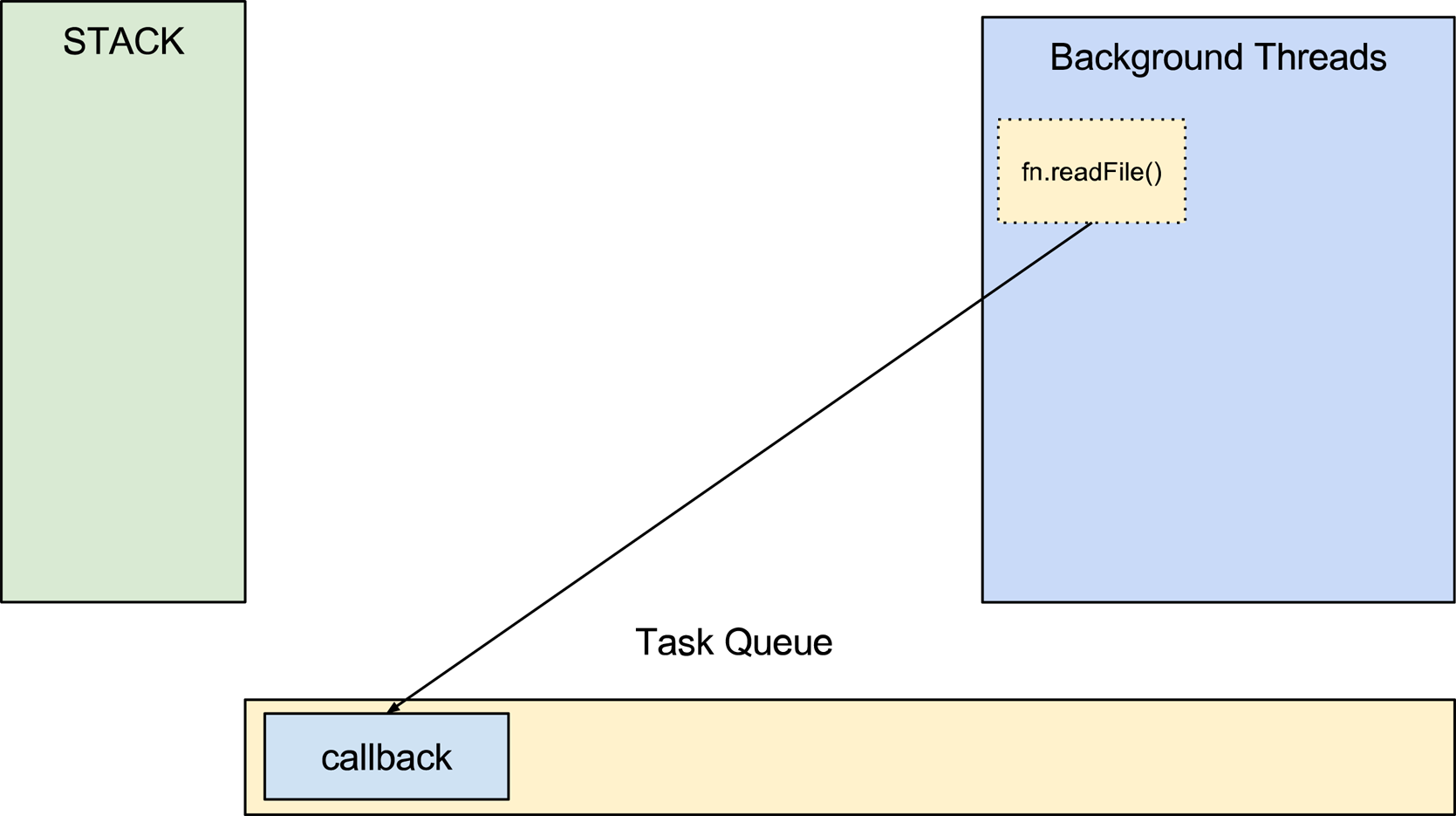
Task Queue
Como vimos no capítulo anterior, algumas ações como I/O são enviadas para serem executadas em outra thread permitindo que o V8 siga trabalhando e a stack siga executando as próximas funções. Essas funções enviadas para que sejam executadas em outra thread precisam de um callback. Um callback é basicamente uma função que será executada quando a função principal terminar. Esses callbacks podem ter responsabilidades diversas, como por exemplo, chamar outras funções e executar alguma lógica. Como o V8 é single thread e só existe uma stack, os callbacks precisam esperar a sua vez de serem chamados. Enquanto esperam, os callbacks ficam em um lugar chamado task queue ou fila de tarefas. Sempre que a thread principal finalizar uma tarefa, o que significa que a stack estará vazia, uma nova tarefa é movida da task queue para a stack onde será executada. Para entender melhor vamos ver a imagem abaixo:
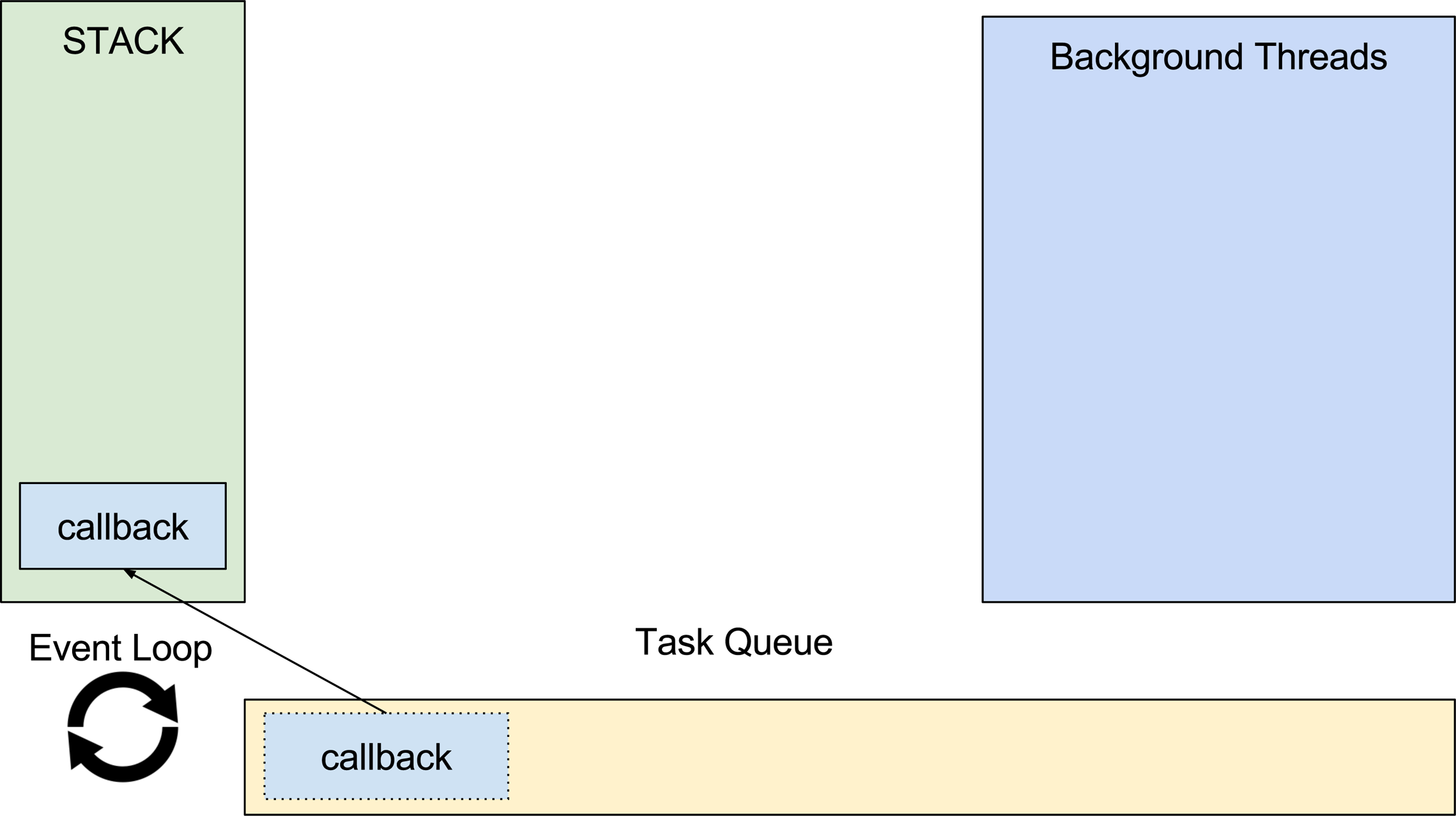
Esse loop, conhecido como Event Loop, é infinito e será responsável por chamar as próximas tarefas da task queue enquanto o Node.js estiver rodando.
Micro e Macro Tasks
Até aqui vimos como funciona a stack, o multithread e também como são enfileirados os callbacks na task queue. Agora vamos conhecer os tipos de tasks (tarefas) que são enfileiradas na task queue, que podem ser micro tasks ou macro tasks.
Macro tasks
Alguns exemplos conhecidos de macro tasks são: setTimeout, I/O, setInterval. Segundo a especificação do WHATWG somente uma macro task deve ser processada em um ciclo do Event Loop.
Micro tasks
Alguns exemplos conhecidos de micro tasks são as promises e o process.nextTick. As micro tasks normalmente são tarefas que devem ser executadas rapidamente após alguma ação, ou realizar algo assíncrono sem a necessidade de inserir uma nova task na task queue. A especificação do WHATWG diz que após o Event Loop processar a macro task da task queue todas as micro tasks disponíveis devem ser processadas e, caso elas chamem outras micro tasks, essas também devem ser resolvidas para que somente então ele chame a próxima macro task.
O exemplo abaixo demonstra como funciona esse fluxo: